







Data-free Universal Adversarial Perturbation with Pseudo-semantic Prior
本文 “Data-free Universal Adversarial Perturbation with Pseudo-semantic Prior” 提出了 PSP-UAP 方法,利用 UAP 固有语义信息生成伪语义先验,通过样本重加权和输入变换,提升了无数据通用对抗扰动在黑盒攻击中的性能,在多种 CNN 模型上超越了现有方法。
摘要-Abstract
Data-free Universal Adversarial Perturbation (UAP) is an image-agnostic adversarial attack that deceives deep neural networks using a single perturbation generated solely from random noise, without any data priors. However, traditional data-free UAP methods often suffer from limited transferability due to the absence of semantic information in random noise. To address this, we propose a novel data-free universal attack approach that generates a pseudo-semantic prior recursively from the UAPs, enriching semantic contents within the data-free UAP framework. Our method is based on the observation that UAPs inherently contain latent semantic information, enabling the generated UAP to act as an alternative data prior, by capturing a diverse range of semantics through region sampling. We further introduce a sample reweighting technique to emphasize hard examples by focusing on samples that are less affected by the UAP. By leveraging the semantic information from the pseudo-semantic prior, we also incorporate input transformations, typically ineffective in data-free UAPs due to the lack of semantic content in random priors, to boost black-box transferability. Comprehensive experiments on ImageNet show that our method achieves state-of-the-art performance in average fooling rate by a substantial margin, significantly improves attack transferability across various CNN architectures compared to existing data-free UAP methods, and even surpasses data-dependent UAP methods.
无数据通用对抗扰动(UAP)是一种与图像无关的对抗攻击方式,它利用仅从随机噪声生成的单一扰动来欺骗深度神经网络,且不依赖任何数据先验信息。然而,传统的无数据UAP方法往往由于随机噪声中缺乏语义信息,导致其迁移性有限。为解决这一问题,我们提出了一种新颖的无数据通用攻击方法,该方法从UAP中递归生成伪语义先验,在无数据UAP框架内丰富语义内容。我们的方法基于这样一个观察结果:UAP本身固有潜在的语义信息,通过区域采样捕捉多种语义,可使生成的UAP作为替代数据先验。我们进一步引入样本重加权技术,聚焦受UAP影响较小的样本,突出难样本的重要性。利用伪语义先验中的语义信息,我们还融入了输入变换(通常在无数据UAP中因随机先验缺乏语义内容而效果不佳),以提升黑盒转移性。在ImageNet上进行的全面实验表明,我们的方法在平均愚弄率方面取得了显著领先的最先进性能,与现有的无数据UAP方法相比,显著提高了跨各种CNN架构的攻击转移性,甚至超越了依赖数据的UAP方法。
引言-Introduction
这部分内容主要介绍了研究背景、面临的问题、提出的方法及主要贡献,具体如下:
- 研究背景:深度神经网络(DNNs)在计算机视觉领域广泛应用且成果显著,但易受输入数据中精心设计的微小扰动影响,导致模型做出错误预测,这为其在关键领域的应用带来挑战,推动了对抗攻击研究。
- 面临的问题
- 为制作具有高迁移性的对抗样本,虽有基于特定目标图像的攻击方法,但这些方法为每个目标图像生成独特扰动,耗时且缺乏通用性。
- 通用对抗扰动(UAP)可生成单一扰动攻击多种未知图像,现有数据相关UAP依赖大规模数据样本及其标签,获取目标域数据先验往往不切实际。
- 无数据UAP方法虽避免数据依赖,但现有方法多依赖缺乏语义信息的随机先验(如高斯噪声等),导致转移能力有限;部分利用辅助数据的方法,又存在对代理模型过拟合的问题。
- 提出的方法:本文提出PSP - UAP方法,利用UAP固有语义信息生成伪语义先验。通过随机裁剪和调整UAP区域生成语义样本,引入样本重加权技术聚焦难样本,还将输入变换融入无数据UAP框架,以提升攻击迁移性。
- 主要贡献
- 提出PSP - UAP方法,训练时将UAP固有语义信息作为替代数据源生成伪语义先验。
- 样本重加权方法在UAP训练中对难样本优先处理,减少无信息样本的影响。
- 首次将输入变换融入无数据UAP框架,利用伪语义先验提升跨CNN架构的黑盒转移性。
- 该方法性能卓越,大幅超越现有无数据UAP方法,甚至优于部分数据相关UAP方法。

图1. 真实图像和通用对抗扰动(UAP)中的多样语义内容:
(a) 来自ImageNet数据集的一幅完整图像(上)以及我们从DenseNet - 121生成的无数据UAP(下),展示的是训练阶段第900次迭代时的结果。每张图像下方显示了Top - 1类别及其得分。
(b) 从完整图像(上)和我们的UAP(下)裁剪出的区域。这些区域包含与原始图像类别不同的多样语义。
相关工作-Related Work
该部分主要介绍了与本文研究相关的三类工作,包括数据相关通用攻击、无数据通用攻击以及输入变换攻击,分析了各类方法的原理、特点和局限性,具体内容如下:
- 数据相关通用攻击:旨在生成能误导任何图像样本的单一扰动。UAP首次提出使用DeepFool方法,在每一步寻找最小通用对抗扰动;SPGD-UAP将随机梯度法与投影梯度下降(PGD)攻击方法相结合;SGA-UAP利用小批量随机梯度聚合解决梯度消失和量化误差问题;AT-UAP整合特定图像和与图像无关的攻击,提高通用扰动的鲁棒性;NAG和GAP运用生成对抗框架制作扰动。虽然这些方法提高了黑盒攻击的转移性,但都需要训练数据集,在攻击者没有目标域先验知识的情况下不实用。
- 无数据通用攻击:目标是在无需训练数据集的情况下制作UAP,以缓解数据相关通用攻击中对数据访问的要求,更适用于实际应用。Fast Feature Fool (FFF)率先提出通过最大化所有CNN层的特征激活值来进行无数据通用对抗攻击;Generalizable Data-free UAP (GDUAP)在训练阶段采用饱和检查策略改进了FFF的攻击方法;AT-UAP也进行了无数据方式的实验,对随机噪声应用对抗攻击;Prior-Driven Uncertainty Approximation (PD-UA)通过最大化模型不确定性近似来训练UAP;Cosine-UAP提出通过最小化余弦相似度以自监督方式制作UAP;AAA利用logits制作类印象来训练生成模型以优化UAP;TRM-UAP增加浅层卷积层的正负激活比例并采用课程学习,稳定提升攻击转移性。然而,这些方法由于缺乏目标模型和域的信息,且严重依赖随机先验生成UAP,辅助数据还直接利用标签信息,容易导致对代理模型的过拟合。
- 输入变换攻击:是提高特定图像对抗攻击迁移性的有效方式。DIM、TIM 和 SIM 揭示了DNN模型在梯度计算前对缩放、平移和缩放等变换的不变性属性;SIA 在保持输入图像整体结构的同时应用各种变换;Admix 通过将不同类别的少量图像混合到输入图像中创建混合图像;Block shuffle and rotation (BSR) 随机打乱和旋转输入图像的子块,减少不同模型注意力热图的方差;L2T 利用强化学习选择最优变换组合,增加变换图像的多样性。本文将输入变换融入无数据UAP方法,以进一步增强黑盒转移性。
方法-Methodology
无数据UAP的预备知识-Preliminaries of data-free UAP
这部分主要介绍了无数据通用对抗扰动(UAP)的基本概念和相关损失函数,为理解后续提出的方法奠定基础。
- 无数据UAP的目标:通用对抗攻击旨在利用一个模型优化出单一扰动,该扰动能有效欺骗目标域数据集中的大多数样本,同时其像素强度受约束参数限制。在无数据场景下,由于无法获取目标数据集,UAP通常使用简单随机先验(如高斯噪声或拼图图像)进行训练。
- GD-UAP的激活最大化损失函数:GD-UAP引入了一种激活最大化损失函数,其目的是在没有输入图像的情况下,过度激活代理网络多个卷积层提取的特征,从而干扰CNN模型的特征提取过程,使模型做出错误预测。该损失函数表达式为 L = ∑ i = 1 l E z ∼ p z [ ∥ A i f ( z ) ∥ 2 ] \mathcal{L}=\sum_{i = 1}^{l}\mathbb{E}_{z\sim p_{z}}\left[\left\|\mathcal{A}_{i}^{f}(z)\right\|_{2}\right] L=∑i=1lEz∼pz[ Aif(z) 2],其中 A i f ( z ) \mathcal{A}_{i}^{f}(z) Aif(z) 表示代理网络 f f f 第 i i i 层的激活, l l l 是网络 f f f 的层数, z z z 是从简单随机先验分布 p z p_{z} pz 中采样的伪数据。
伪语义先验-Pseudo-Semantic Prior
这部分内容主要介绍了伪语义先验的提出原因、生成方式及其作用,具体如下:
- 提出原因:无数据UAP方法使用的随机先验(如高斯噪声或人工拼图)缺乏语义信息,且UAP在训练时易过度拟合代理模型,仅依赖代理网络的激活或输出优化UAP,会降低其对真实图像在未知模型中的干扰效果,导致黑盒转移性下降。而此前研究表明生成的UAP存在主导标签,具有一定语义信息,因此本文受启发,利用UAP的固有语义信息来解决上述问题。
- 生成方式:将UAP和随机噪声的组合视为单个图像,即伪语义先验。从伪语义先验中生成伪数据样本,即语义样本。具体做法是对UAP进行随机裁剪和调整大小操作,将其作为语义样本 x n x_{n} xn,公式为 x n = S ( p x ) x_{n}=\mathcal{S}(p_{x}) xn=S(px),其中 p x p_{x} px 是伪语义先验,由 p x = z + δ t p_{x}=z + \delta_{t} px=z+δt 得到( z z z 是随机噪声, δ t \delta_{t} δt 是第 t t t 次迭代时正在训练的UAP), S \mathcal{S} S 是采样器,通过对 p x p_{x} px 应用裁剪和调整大小操作来抽取语义样本。
- 作用:利用UAP不同区域嵌入的语义信息,能为成功攻击目标特征提供更有效的指导,相较于仅依赖随机噪声,丰富了无数据UAP训练中的语义内容,有助于提升UAP的性能。
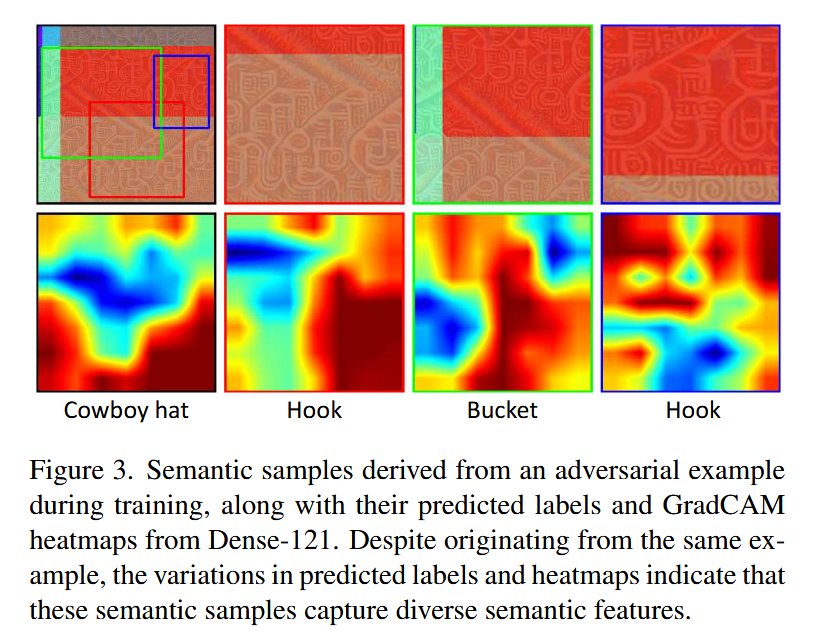
图3. 训练过程中从一个对抗样本衍生出的语义样本,以及它们的预测标签和来自Dense-121的GradCAM热图。尽管这些语义样本源自同一个样本,但预测标签和热图的差异表明,它们捕捉到了多样的语义特征。
样本重加权-Sample Reweighting
这部分内容主要介绍了样本重加权的提出原因、计算方法和作用,具体如下:
- 提出原因:从伪语义先验中随机抽取的语义样本,因语义内容不同存在难度不平衡的问题,部分样本容易被UAP欺骗,而部分样本则较难欺骗。为解决该问题,提出新的样本重加权方法,对难欺骗样本赋予更高权重,以优化UAP训练。
- 计算方法:在训练过程中,通过计算原始输入和对抗样本之间的KL散度来确定每个样本的权重。对于每个语义样本 x n x_{n} xn 及其对应的由当前UAP生成的对抗样本 x n + δ t x_{n}+\delta_{t} xn+δt,分别定义原始分布 p ( x n ) p(x_{n}) p(xn) 和对抗分布 p ( x n + δ t ) p(x_{n}+\delta_{t}) p(xn+δt). KL散度值大,表明UAP显著改变了样本分布;值小,则意味着攻击效果不佳。因此,取KL散度值的倒数,为攻击后分布变化最小的语义样本分配更大权重,即 w n = 1 K L ( p ( x n ) ∥ p ( x n + δ t ) ) w_{n}=\frac{1}{KL(p(x_{n})\parallel p(x_{n}+\delta_{t}))} wn=KL(p(xn)∥p(xn+δt))1.
- 作用:利用该权重对语义样本进行重加权,在优化UAP时考虑每个采样样本受UAP的影响,能够更有效地优化UAP,提升攻击性能。
输入变换-Input Transformation
这部分内容主要介绍了输入变换在本文方法中的应用,包括应用原因、具体变换方式和作用,具体如下:
- 应用原因:输入变换常用于特定图像对抗攻击以提升攻击迁移性,但在无数据UAP中,因随机先验语义信息有限,其应用较少。而本文方法中从伪语义先验生成的语义样本包含多种语义线索,使得输入变换在无数据场景下更有效,故将其引入以增强黑盒攻击转移性。
- 具体变换方式:参考L2T方法,选择旋转、缩放和打乱这三种对提升攻击转移性特别有效的变换。在优化过程中,对每个语义样本随机选择其中一种变换进行应用。旋转时,角度从截断正态分布 [ − 1 0 ∘ , 1 0 ∘ ] [-10^{\circ}, 10^{\circ}] [−10∘,10∘] 中抽取;缩放操作在 [ 0.8 , 1.25 ] [0.8, 1.25] [0.8,1.25] 的均匀分布范围内进行;打乱则是随机重新排列图像块。
- 作用:在PSP-UAP优化过程中,对语义样本应用输入变换,增加了语义样本的多样性,进而提升了黑盒攻击的转移性,使UAP能更好地攻击未知模型。
整体损失-Overall Loss
这部分主要介绍了PSP-UAP的整体损失函数,通过整合多种技术实现有效优化,具体内容如下:
- 损失函数定义:将伪语义先验、样本重加权和输入变换整合到公式中,定义PSP-UAP的最终损失函数为 L = − E x ∼ p x ∑ n = 1 N ∑ i = 1 l log ( w n ∥ A i f ( T ( x n + δ t ) ) ∥ 2 ) \mathcal{L}=-\mathbb{E}_{x \sim p_{x}} \sum_{n=1}^{N} \sum_{i=1}^{l} \log \left(w_{n}\left\|\mathcal{A}_{i}^{f}\left(T\left(x_{n}+\delta_{t}\right)\right)\right\| _{2}\right) L=−Ex∼px∑n=1N∑i=1llog(wn Aif(T(xn+δt)) 2) . 在该公式里, A i f \mathcal{A}_{i}^{f} Aif 代表网络 f f f 中第 i i i 层的激活; x n x_{n} xn 是从伪语义先验 p x p_{x} px 中提取的第 n n n 个语义样本; δ t \delta_{t} δt 表示第 t t t 次迭代时的UAP; w n w_{n} wn 是根据样本重加权计算得到的权重; l l l 是用于计算激活和的卷积层数量; T T T 是随机选择的输入变换; N N N 是从一个伪语义先验中提取的语义样本数量。
- 损失函数作用:通过优化这个整体损失函数,PSP-UAP能够充分利用生成的语义样本作为数据,即便在没有目标域先验知识的情况下,也能产生具有高转移性的UAP。这一损失函数的设计,将PSP-UAP中的各个关键技术有机结合,实现了对UAP的有效优化,提升了攻击性能。
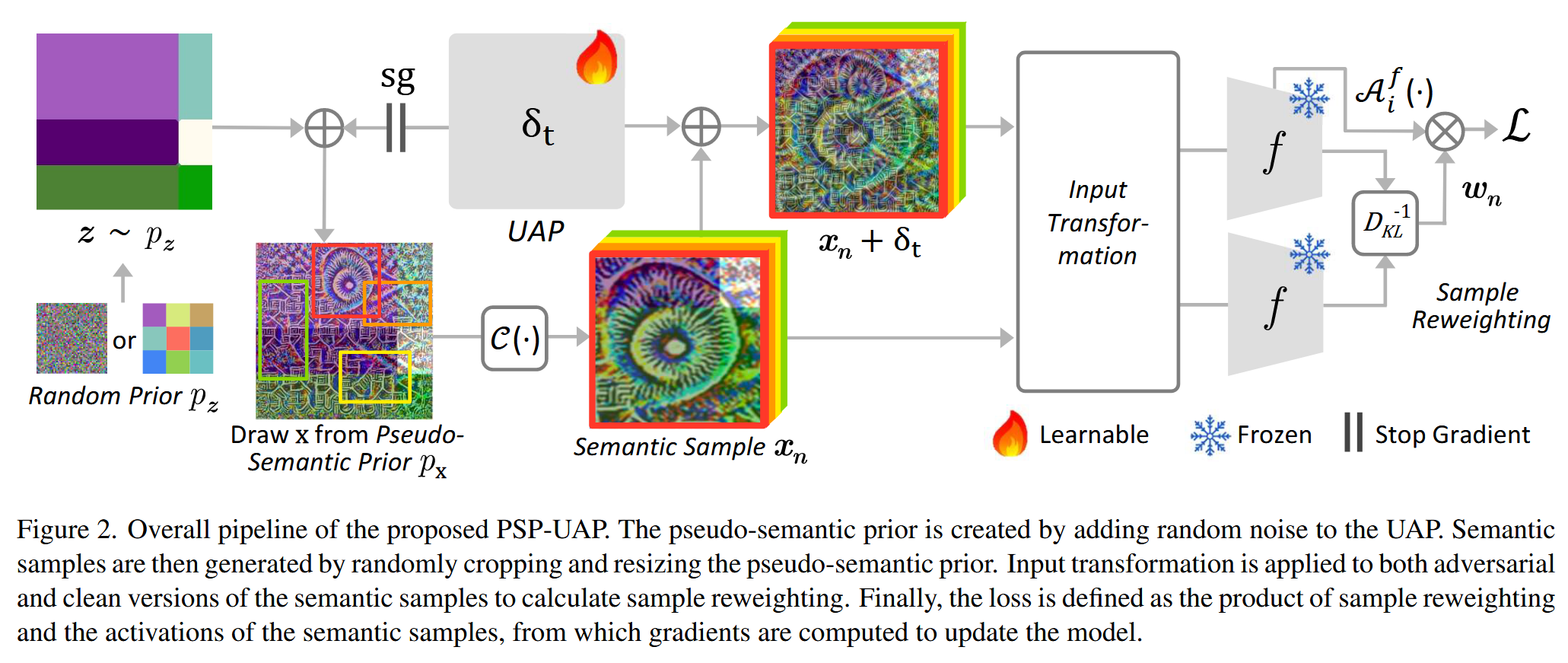
图2. 所提出的PSP-UAP整体流程。伪语义先验是通过在UAP上添加随机噪声创建的。然后,通过对伪语义先验进行随机裁剪和调整大小来生成语义样本。对语义样本的对抗版本和干净版本都应用输入变换,以计算样本重加权。最后,损失被定义为样本重加权与语义样本激活值的乘积,通过计算该损失的梯度来更新模型。

实验-Experiments
这部分主要介绍了实验的设置、评估指标、对比基线,从白盒攻击、黑盒攻击等方面对PSP-UAP方法进行评估,并开展消融实验探究各组件效果,具体如下:
- 实验设置:沿用现有无数据通用攻击的实验设置,在ImageNet验证集上,使用五个ImageNet预训练的CNN模型(AlexNet、VGG16、VGG19、ResNet152、GoogleNet)评估PSP-UAP,还额外探索了DenseNet121、MobileNet-v3-Large、ResNet50、Inception-v3这四个模型。实验基于PyTorch框架,使用单个NVIDIA A6000 GPU,设置了多项超参数。
- 评估指标与基线:采用愚弄率评估攻击性能,愚弄率指应用UAP后标签改变的样本比例。将PSP-UAP与多种无数据通用攻击方法(FFF、GD-UAP、PD-UA、Cosine-UAP、AT-UAP、TRM-UAP )对比,还与数据相关的SGA-UAP进行比较。
- 实验结果
- 白盒攻击评估:PSP-UAP在白盒攻击下,虽然在AlexNet和GoogleNet上的愚弄率略低于其他方法,但在所有通用攻击方法中平均愚弄率最高,在ResNet152上提升显著,表明其在复杂CNN模型上表现优异。
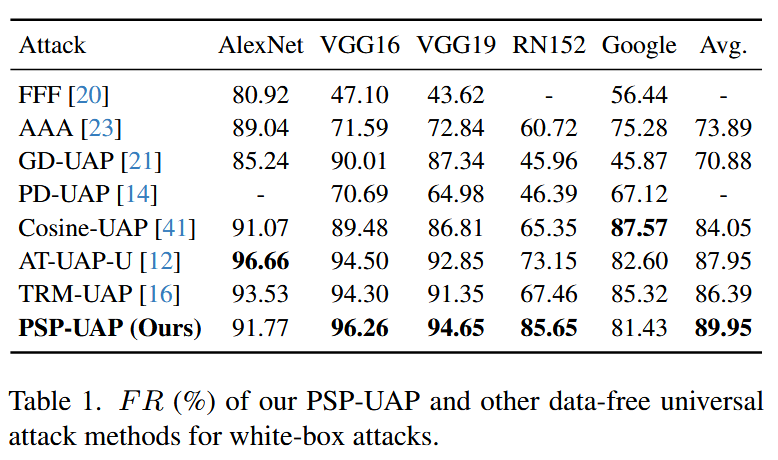
表1. 我们的PSP-UAP和其他无数据攻击方法在白盒攻击中的愚弄率(%)。 - 黑盒攻击评估:与其他无数据UAP方法相比,PSP-UAP在大多数模型上黑盒攻击转移性表现更优,在严格黑盒设置下平均愚弄率达70.1%,超过TRM-UAP的69.6%。在额外CNN模型实验中,PSP-UAP也大幅超越TRM-UAP。与数据相关UAP方法相比,PSP-UAP在黑盒设置下具有更好的转移性,在多数模型上平均愚弄率更高。
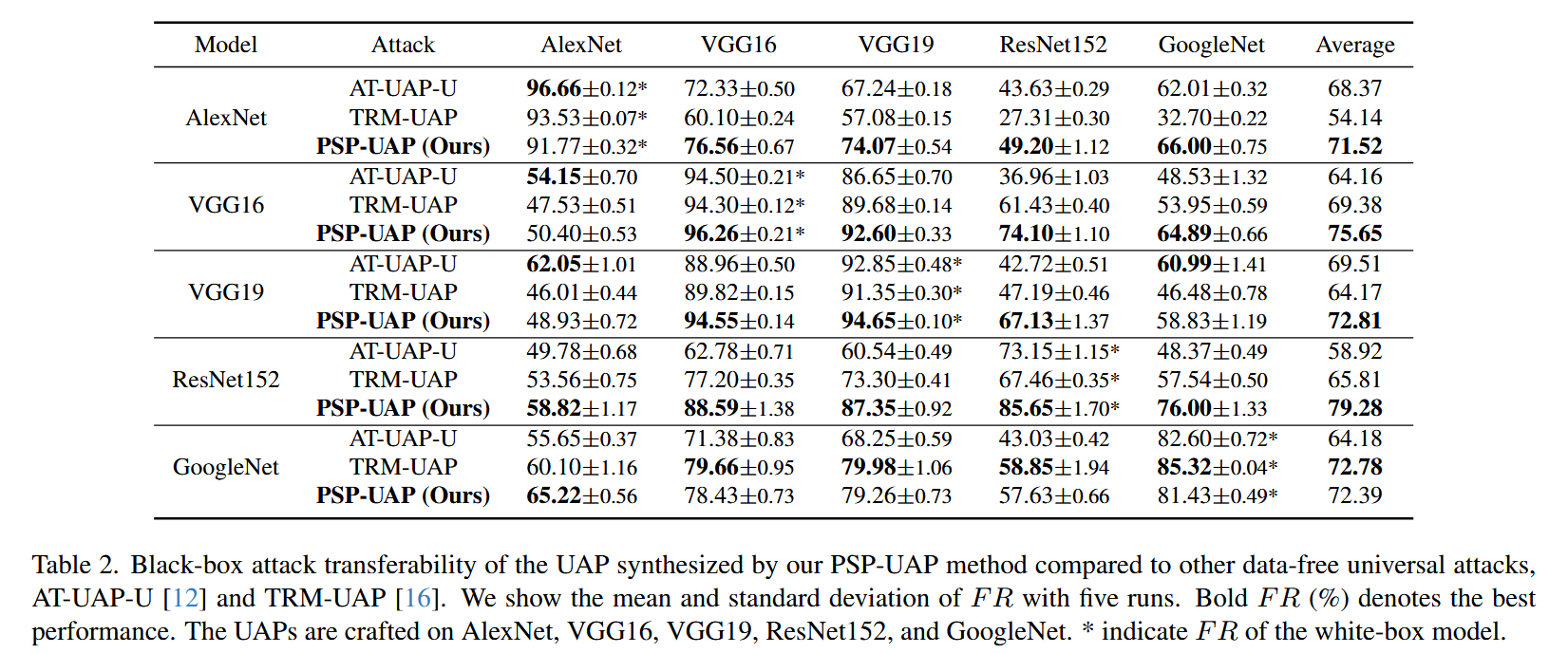
表2. 将我们的PSP-UAP方法合成的UAP与其他无数据通用攻击方法(AT-UAP-U 和TRM-UAP )进行对比,展示其在黑盒攻击中的转移性。我们给出了五次运行的平均值和标准差。加粗的(%)表示最佳性能。UAP是在AlexNet、VGG16、VGG19、ResNet152和GoogleNet上制作的。 ∗ * ∗ 表示白盒模型的情况。
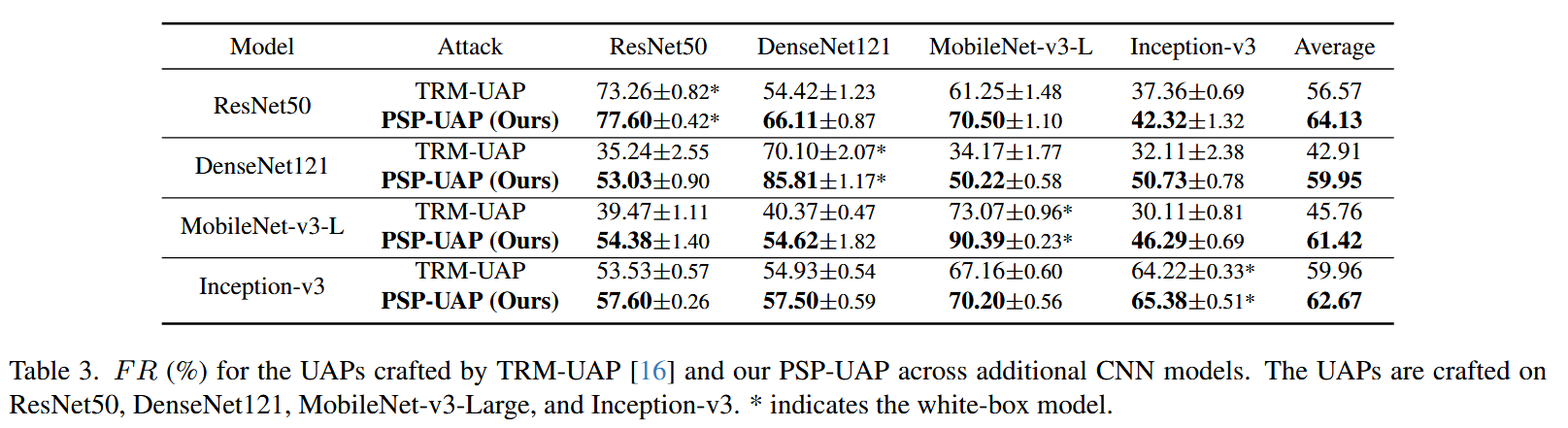
表3. 由TRM-UAP 和我们的PSP-UAP针对额外的CNN模型制作的UAP的愚弄率(%)。这些UAP是在ResNet50、DenseNet121、MobileNet-v3-Large和Inception-v3上制作的。 ∗ * ∗ 表示白盒模型。
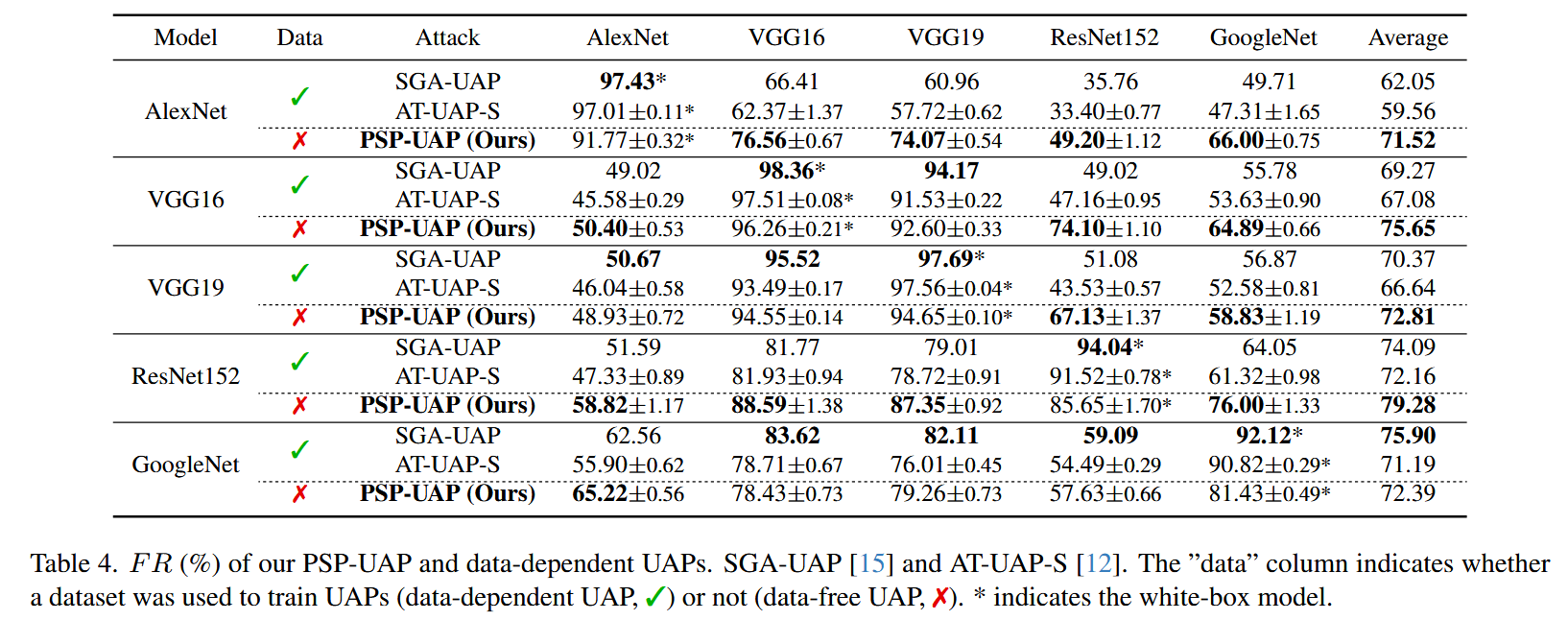
表4. 我们的PSP-UAP与依赖数据的UAP(SGA-UAP 和AT-UAP-S )的愚弄率(%)对比。“数据” 列表明训练UAP时是否使用了数据集(使用数据集的依赖数据UAP,标记为✓;未使用数据集的无数据UAP,标记为✗)。 ∗ * ∗ 表示白盒模型。 - 消融实验:探究了PSP-UAP各组件的影响,发现伪语义先验比随机先验效果好,样本重加权和输入变换都能提升攻击性能,两者结合提升最大。将输入变换应用于其他无数据UAP(TRM-UAP)的随机噪声时,其愚弄率下降,而应用于PSP-UAP的语义样本时愚弄率上升。语义样本数量为10时PSP-UAP攻击性能最佳,且即使样本数量较少也优于其他无数据方法。此外,通过可视化UAP,验证了伪语义先验能捕获多种固有模式。
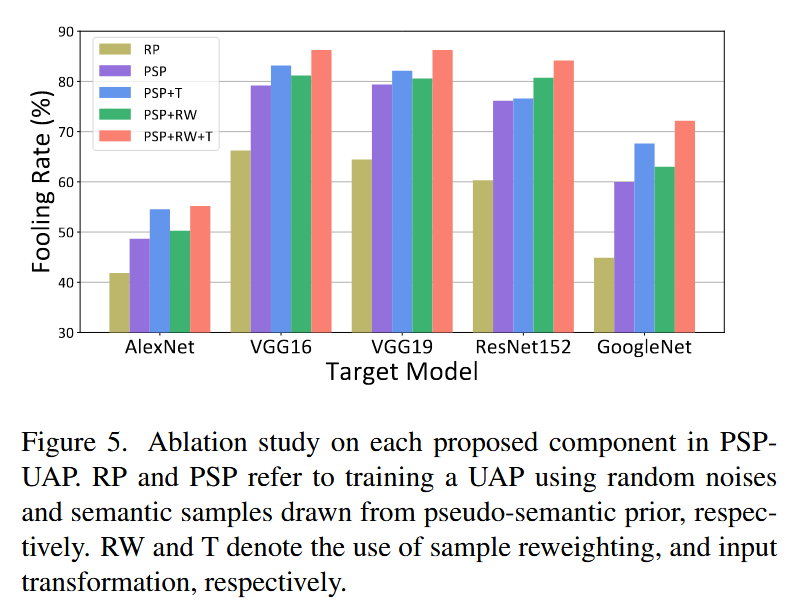
图5. PSP-UAP中各组件的消融研究。RP和PSP分别指使用随机噪声和从伪语义先验中抽取的语义样本训练UAP。RW和T分别表示使用样本重加权和输入变换。
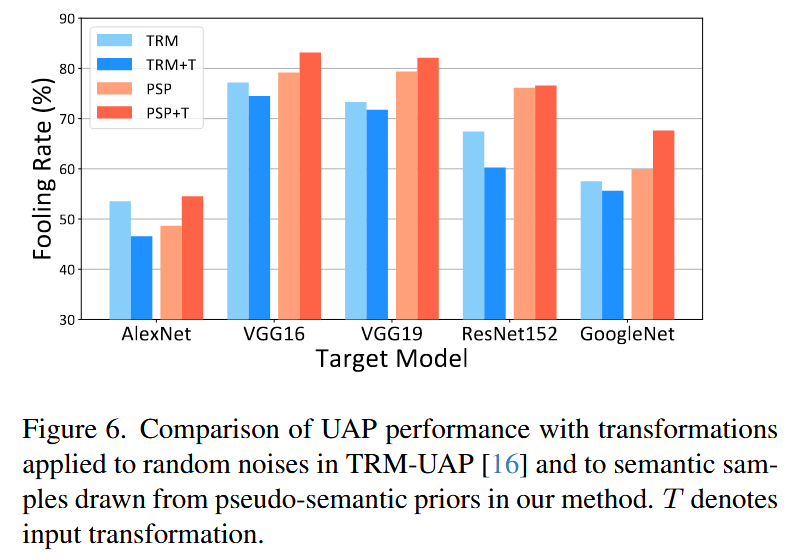
图6. 在TRM-UAP中对随机噪声应用变换,以及在我们的方法中对从伪语义先验中抽取的语义样本应用变换后的UAP性能对比。 表示输入变换。
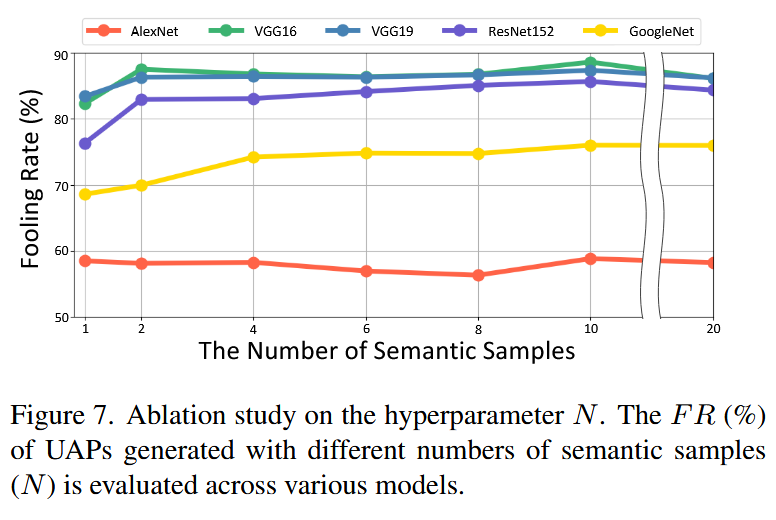
图7. 关于超参数 N N N 的消融研究。针对不同数量的语义样本( N N N )生成的UAP的愚弄率(%)在多种模型上进行了评估。

图4. 在DenseNet121、ResNet152和AlexNet上训练期间,由PSP-UAP生成的通用对抗扰动(UAP)的可视化结果。从左到右,展示的UAP分别是在第100次、第900次、第1700次迭代时,以及训练后的最终UAP。像素值已缩放到[0, 255]。
- 白盒攻击评估:PSP-UAP在白盒攻击下,虽然在AlexNet和GoogleNet上的愚弄率略低于其他方法,但在所有通用攻击方法中平均愚弄率最高,在ResNet152上提升显著,表明其在复杂CNN模型上表现优异。
结论-Conclusion
在这部分内容中,作者总结了PSP-UAP方法的核心要点、实验成果和研究价值,具体如下:
- 方法概述:提出了一种名为PSP-UAP的新型无数据通用攻击方法。该方法将UAP作为富含语义信息的先验,直接从伪语义先验中提取语义样本,以此解决目标域缺乏先验知识的问题。同时,引入样本重加权策略,确保对不同语义样本的攻击更加均衡。此外,将输入变换攻击方法应用于语义样本,进一步增强了UAP的转移性。
- 实验成果:通过在ImageNet验证数据集上,将PSP-UAP与无数据和数据相关的通用攻击方法在多种CNN模型上进行比较,充分展示了该方法卓越的转移性。实验结果表明,PSP-UAP在平均愚弄率等指标上表现出色,在跨模型攻击转移性方面具有显著优势。
- 研究价值:PSP-UAP为无数据通用对抗扰动的研究提供了新的思路和方法,有效提升了无数据条件下对抗攻击的性能,在相关领域具有重要的理论和实践意义。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











