







Downstream Transfer Attack: Adversarial Attacks on Downstream Models with Pre-trained Vision Transformers

随着视觉 Transformer(ViTs)和自监督学习技术发展,预训练大模型被广泛应用于下游任务,但 ViTs 易受对抗攻击。本文研究对抗漏洞从预训练 ViT 模型到下游任务的迁移性,提出下游迁移攻击(DTA)方法。DTA 利用预训练 ViT 模型生成对抗样本攻击下游微调模型,通过平均token余弦相似度(ATCS)确定最脆弱层以实现高度可迁移性攻击。实验表明其平均攻击成功率超 90%,远超现有方法,且用 DTA 生成的对抗样本进行对抗训练可提升模型鲁棒性,同时发现参数高效迁移学习方法(如 LoRA)使下游模型更易受攻击。
摘要-Abstract
With the advancement of vision transformers (ViTs) and self-supervised learning (SSL) techniques, pre-trained large ViTs have become the new foundation models for computer vision applications. However, studies have shown that, like convolutional neural networks (CNNs), ViTs are also susceptible to adversarial attacks, where subtle perturbations in the input can fool the model into making false predictions. This paper studies the transferability of such an adversarial vulnerability from a pre-trained ViT model to downstream tasks. We focus on sample-wise transfer attacks and propose a novel attack method termed Downstream Transfer Attack (DTA). For a given test image, DTA leverages a pre-trained ViT model to craft the adversarial example and then applies the adversarial example to attack a fine-tuned version of the model on a downstream dataset. During the attack, DTA identifies and exploits the most vulnerable layers of the pre-trained model guided by a cosine similarity loss to craft highly transferable attacks. Through extensive experiments with pre-trained ViTs by 3 distinct pre-training methods, 3 fine-tuning schemes, and across 10 diverse downstream datasets, we show that DTA achieves an average attack success rate (ASR) exceeding 90%, surpassing existing methods by a huge margin. When used with adversarial training, the adversarial examples generated by our DTA can significantly improve the model’s robustness to different downstream transfer attacks.
随着视觉Transformer(ViT)和自监督学习(SSL)技术的发展,预训练的大型ViT已成为计算机视觉应用的新型基础模型。然而,研究表明,与卷积神经网络(CNN)一样,ViT也容易受到对抗攻击,输入中的细微扰动就能使模型做出错误预测。本文研究了这种对抗漏洞从预训练ViT模型到下游任务的迁移性。我们专注于样本级迁移攻击,并提出了一种名为下游迁移攻击(DTA)的新攻击方法。对于给定的测试图像,DTA利用预训练的ViT模型生成对抗样本,然后将该对抗样本应用于攻击在下游数据集上微调后的模型。在攻击过程中,DTA以余弦相似度损失为指导,识别并利用预训练模型中最脆弱的层来生成高度可迁移的攻击。通过对采用3种不同预训练方法的预训练ViT模型、3种微调方案以及10个不同的下游数据集进行广泛实验,我们发现DTA的平均攻击成功率(ASR)超过90%,大幅超越现有方法。当与对抗训练结合使用时,我们的DTA生成的对抗样本可以显著提高模型对不同下游迁移攻击的鲁棒性。
引言-Introduction
这部分内容主要介绍了研究背景、存在的问题以及本文的研究重点和贡献,具体如下:
- 研究背景:预训练大模型因强大的表征能力,在自然语言处理和计算机视觉领域,通过微调应用于下游任务已成为普遍做法。借助大预训练模型,下游模型能以更少数据和时间获得更好性能,参数高效迁移学习方法(PETL),如LoRA和AdaptFormer,可加速微调过程并取得优异性能。
- 存在问题:深度神经网络(包括CNN和ViT)易受对抗样本攻击,现有攻击方法分白盒攻击和黑盒攻击。其中,迁移攻击针对真实商业API更易实施,现有迁移攻击多关注基于相同数据集训练模型间的对抗样本迁移性,而在预训练 - 微调范式下,下游模型常基于与预训练不同的数据集微调,这种下游迁移设置下的攻击研究较少。
- 研究重点:聚焦于从预训练ViT到微调下游模型的迁移攻击,提出新攻击方法DTA,该方法利用预训练ViT模型生成高度可迁移的对抗攻击,通过最小化干净样本和对抗样本在预训练模型最脆弱层的平均余弦相似度实现。
- 主要贡献:一是研究了当前预训练-微调范式的对抗漏洞,提出DTA攻击方法;二是发现干净样本和对抗样本token间的余弦相似度可衡量下游迁移性,并据此确定预训练ViT最脆弱层,实验证明DTA性能强大,且PETL方法会使下游模型更易受攻击;三是探索用DTA改进对抗训练防御,发现其生成的对抗样本可显著提升模型对不同下游迁移攻击的鲁棒性。
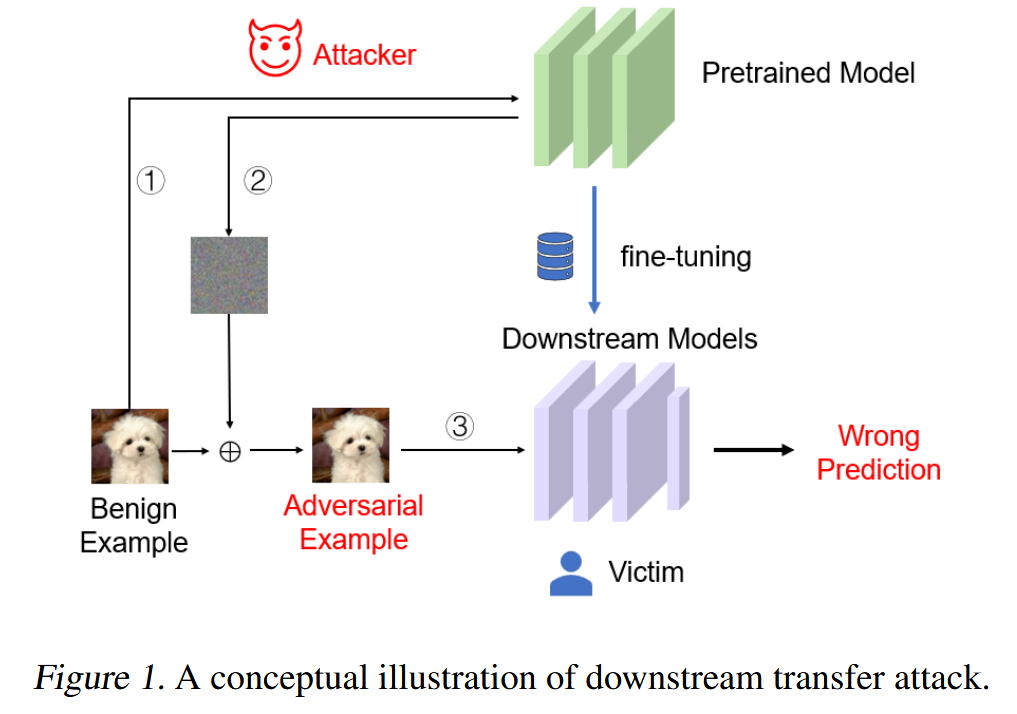
图1. 下游迁移攻击的概念示意图。
相关工作-Related Work
该部分主要回顾了与本文研究相关的工作,包括预训练和微调、可迁移对抗攻击、下游迁移攻击这三个方面,具体内容如下:
- 预训练和微调:在大规模数据集上对大模型进行预训练,能使其具备从输入中提取各级特征的基础能力。预训练方法主要分为监督学习和自监督学习(SSL),其中SSL可让模型直接从无标签的网络规模数据中学习,成为大规模预训练的常用选择,它又可进一步分为对比学习方法和生成方法。微调则是通过在下游数据集上训练,使预训练模型适应特定的下游任务。随着预训练模型规模增大,传统全量微调面临效率和存储限制,因此出现了参数高效迁移学习(PETL)方法,如LoRA和AdaptFormer,这些方法在冻结预训练模型权重的基础上引入可微调模块,能在减少参数更新和存储的同时,取得与全量微调相当的性能。
- 可迁移对抗攻击:可迁移对抗攻击是黑盒攻击的一种,利用对抗样本的跨模型迁移性。现有研究大多关注基于相同训练数据集训练的替代模型生成攻击,其迁移技术涉及网络的标签或中间层特征图,如通过中间特征图确定图像重要区域或直接扰动中间层特征来生成可迁移对抗样本。通用对抗扰动(UAPs)也属于跨样本迁移攻击,它通过在不同样本上累积对抗扰动生成,还可与跨数据集(任务)迁移性结合,生成能迁移到下游模型的UAPs。
- 下游迁移攻击:此前已有对从预训练模型到下游模型的下游迁移攻击设置的研究,但主要集中在UAPs方面。例如,Ban和Dong提出的Pre-trained Adversarial Perturbation(PAP),基于预训练数据集生成UAPs来攻击不同下游模型;Zhou等人提出的AdvEncoder攻击则采用生成式方法来制作与下游任务无关的UAPs。此外,传统基于特征的迁移攻击,如Feature Disruptive Attack(FDA)和Neural Representation Distortion Method(NRDM)也可应用于下游模型攻击。本文聚焦于从在视觉数据集上预训练的ViT到下游分类器的典型下游迁移设置,但与以往研究不同的是,本文关注样本级迁移攻击而非UAPs。
下游迁移攻击-Downstream Transfer Attack
威胁模型-Threat Model
这部分主要定义了下游迁移攻击中的威胁模型,明确了攻击者的目标、能力和限制,以及攻击的具体方式和目标,具体内容如下:
- 攻击目标:在下游迁移攻击场景下,攻击者旨在攻击从预训练模型 f θ f_{\theta} fθ 微调得到的目标模型 f θ ∗ f_{\theta^{*}} fθ∗。微调方式包括全量微调或使用PETL方法,且微调所使用的下游数据集与预训练数据集不同。
- 攻击者能力与限制:攻击者能够完全访问预训练模型(通常为大型开源模型),并且可以获取下游数据集的测试图像 x c x_c xc。然而,攻击者对下游模型的微调过程、微调参数以及架构一无所知,只能通过查询目标模型来实施攻击。
- 攻击方式与目标:攻击者利用预训练模型,针对测试图像 x c x_c xc 生成满足攻击预算 ∥ δ ∥ p ≤ ϵ \|\delta\|_{p} ≤\epsilon ∥δ∥p≤ϵ 的对抗扰动 δ \delta δ,得到对抗样本 x ′ = x + δ x' = x + \delta x′=x+δ. 然后将对抗样本输入下游模型 f θ ∗ f_{\theta^{*}} fθ∗,其目标是最大化下游模型的损失。在图像分类任务中,该目标可定义为误分类误差,即 m a x 1 ( F θ ′ ( x + δ ) ≠ y ) , s . t . ∥ δ ∥ p ≤ ϵ max \mathbb{1}\left(F_{\theta'}(x+\delta) \neq y\right), s.t. \| \delta\| _{p} \leq \epsilon max1(Fθ′(x+δ)=y),s.t.∥δ∥p≤ϵ,其中 1 ( ⋅ ) \mathbb{1}(\cdot) 1(⋅) 为指示函数, y y y 为真实标签。
- 与现有威胁模型的关系:此威胁模型是PAP和AdvEncoder威胁模型的扩展,在这些模型基础上,本文的威胁模型允许攻击者生成样本级迁移攻击,而PAP和AdvEncoder只能生成UAPs。此外,该模型也可看作是跨域迁移攻击的特殊情况,与跨模态迁移攻击相关,但本文聚焦于从大规模数据集预训练的ViT到包括图像分类、目标检测和语义分割等下游任务的迁移。
方法-Methodology
该部分主要介绍了下游迁移攻击(DTA)的方法,包括确定可迁移性指标、计算平均token余弦相似度(ATCS)以及寻找最脆弱层的策略,具体内容如下:
- 可迁移性指标:设计可迁移攻击的关键是找到合适的可迁移性指标。传统跨模型迁移设置中,在源模型上生成的强攻击往往过拟合源模型,难以迁移到其他模型。在下游迁移攻击中,由于微调模型参数变化大,同样存在该问题。因此,本文提出用平均token余弦相似度(ATCS)作为下游可迁移性指标和对抗目标,并引入层选择策略来寻找预训练ViT中对下游模型最脆弱且可迁移的层。
- 平均token余弦相似度(ATCS):由于预训练模型不一定有分类头,所以将对抗目标定义在其中间层输出(特征)上。典型的ViT模型由一系列相同的变压器层组成,每个变压器层输出是一系列维度相同的token。ATCS先计算干净样本与对抗样本特征token间的余弦相似度,再对所有token求平均得到最终结果。其计算公式为
L
A
T
C
S
k
(
x
,
x
′
)
=
1
∣
T
∣
∑
t
∈
T
c
o
s
(
f
θ
k
(
x
)
t
,
f
θ
k
(
x
′
)
t
)
\mathcal{L}_{ATCS}^{k}\left(x, x'\right)=\frac{1}{|T|} \sum_{t \in T} cos \left(f_{\theta}^{k}(x)_{t}, f_{\theta}^{k}\left(x'\right)_{t}\right)
LATCSk(x,x′)=∣T∣1∑t∈Tcos(fθk(x)t,fθk(x′)t),其中
f
θ
k
(
x
)
f_{\theta}^{k}(x)
fθk(x) 是第
k
k
k 层特征图输出,
f
θ
k
(
x
)
t
f_{\theta}^{k}(x)_{t}
fθk(x)t 是其第
t
t
t 个token,
∣
T
∣
|T|
∣T∣ 是token总数。相较于传统在扁平token上计算的余弦相似度,ATCS能缓解高维输出导致的维度诅咒问题。
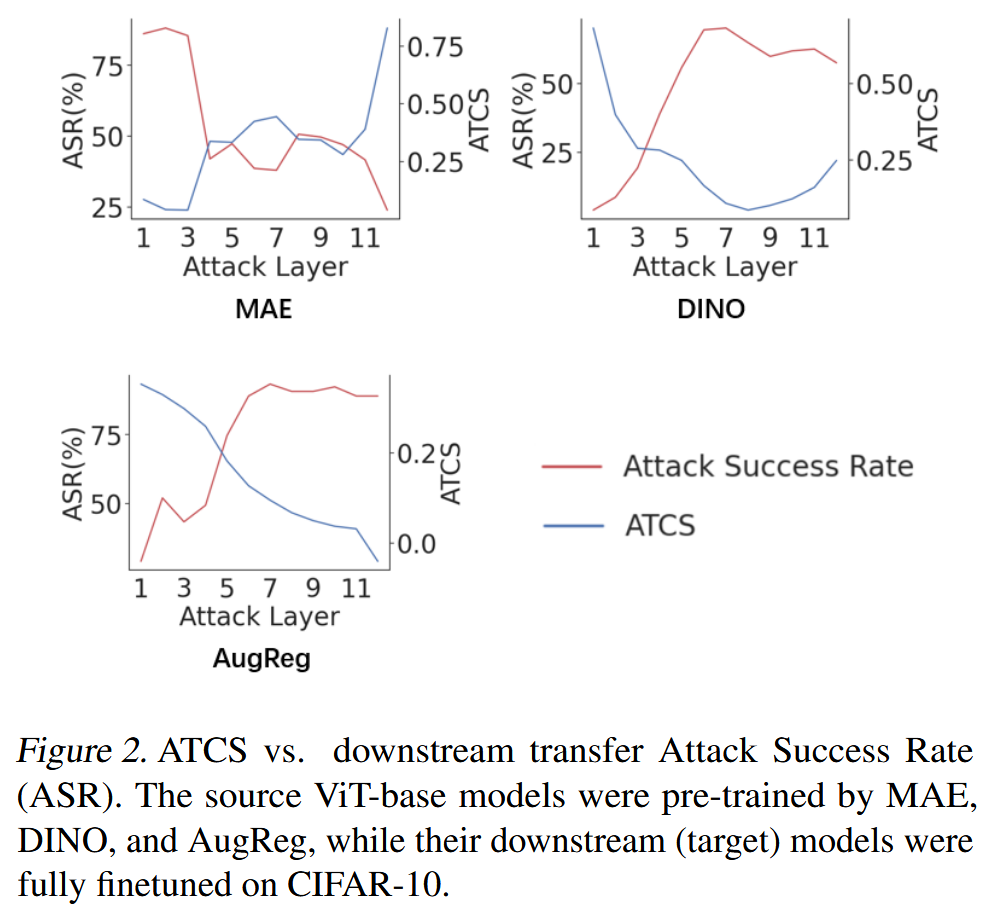
图2. 平均token余弦相似度(ATCS)与下游迁移攻击成功率(ASR)的关系。源ViT - base模型分别由MAE、DINO和AugReg进行预训练,而它们的下游(目标)模型在CIFAR - 10数据集上进行了全量微调。 - 寻找最脆弱层:利用ATCS寻找预训练模型最脆弱层时发现,不同预训练方法(如MAE、DINO、AugReg)得到的模型,其最脆弱(可迁移)层差异较大。直观的单独攻击每层来寻找最脆弱层的方法,复杂度会随层数线性增加,且可能遗漏组合层的重要漏洞。基于攻击中间和深层可得到类似单独攻击的结果这一观察,本文提出如下层选择策略:先攻击模型的浅层(第一层),检查得到的ATCS。若ATCS低于特定阈值
γ
\gamma
γ,则认为攻击成功,无需再攻击中间或深层;否则,一起攻击
⌊
M
/
3
⌋
M
\lfloor M / 3\rfloor ~ M
⌊M/3⌋ M 层,使用组合损失函数
∑
k
=
⌊
M
/
3
⌋
M
L
A
T
C
S
k
\sum_{k=\lfloor M / 3\rfloor}^{M} L_{ATCS }^{k}
∑k=⌊M/3⌋MLATCSk。然后根据
L
A
T
C
S
k
L_{ATCS }^{k}
LATCSk 指示的ATCS值对这些层进行排序,选择ATCS值最低的前
N
N
N 层作为最脆弱层,再次攻击这些层以获得最终的对抗样本。
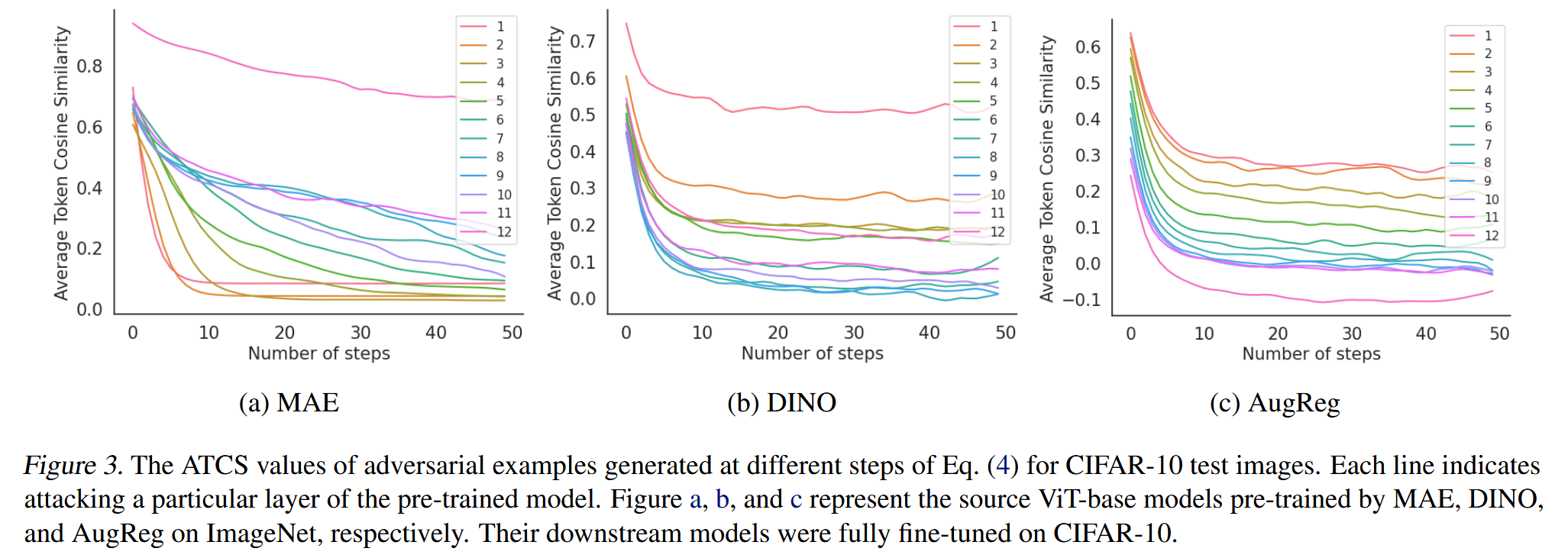
图3. 针对CIFAR-10测试图像,在公式(4)不同步骤生成的对抗样本的平均token余弦相似度(ATCS)值。每条线表示对预训练模型特定层的攻击。图a、b和c分别代表在ImageNet上由MAE、DINO和AugReg预训练的源ViT-base模型。它们的下游模型在CIFAR-10上进行了全量微调。

实验-Experiments
这部分主要介绍了针对下游迁移攻击(DTA)所开展的实验,旨在验证DTA的有效性和优越性,具体内容如下:
-
实验设置
- 模型和数据集:选用由AugReg(监督预训练方法)、DINO(对比学习方法)、MAE(掩码图像建模方法)这3种代表性方法预训练的模型,采用全量微调、LoRA、AdaptFormer这3种代表性微调方式,并使用10个下游数据集进行评估,实验前对图像进行尺寸调整。
- 基线方法:选取PAP和NRDM作为基线方法。PAP用于生成与图像无关的扰动来攻击微调模型;NRDM是一种样本级攻击方法,最初用于多种任务的黑盒攻击,根据经验设置其攻击层。
- 攻击设置:重点研究 l ∞ l_{\infty} l∞ 范数对抗攻击,设置攻击预算、攻击步长、阈值和攻击层数等参数,并对所有攻击方法调优超参数以获取最佳结果。
- 评估指标:在图像分类任务中,使用攻击成功率(ASR)评估,即微调模型在整个下游测试数据集上的分类错误比例;在目标检测和语义分割任务中,分别使用平均精度均值(mAP)和平均交并比(mIoU)进行评估。
-
主要结果:DTA在所有预训练方法和微调数据集上的攻击成功率远超基线方法。在全量微调时,DTA平均ASR达93.11%,比NRDM和PAP分别高出10%和40%以上;在LoRA和AdaptFormer微调时,DTA的ASR均超95%。同时发现,PETL微调的模型比全量微调的模型更易受下游迁移攻击,且基线方法在不同预训练模型上的效果差异大、不稳定。
表1. 不同攻击方法对从不同预训练模型全量微调得到的下游ViT-base模型的攻击成功率(%)。Avg. 1是对数据集求平均,而Avg. 2是对数据集和预训练方法求平均。
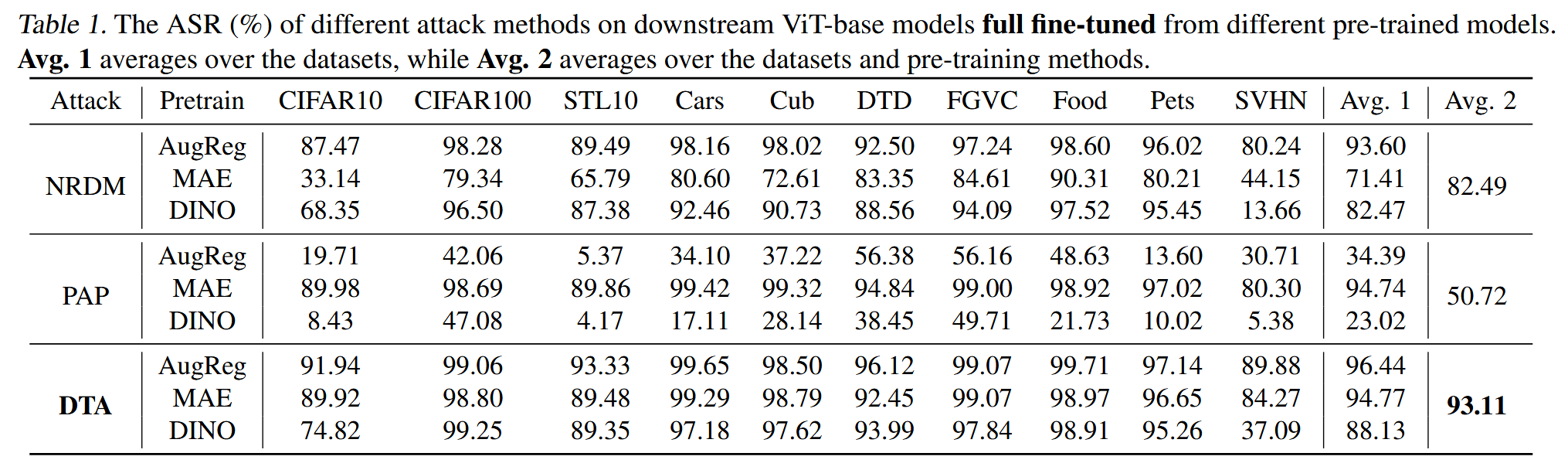
表2. 不同攻击方法对经LoRA微调的下游ViT-base模型的攻击成功率(%)。Avg.1和Avg.2的计算方式与表1相同。
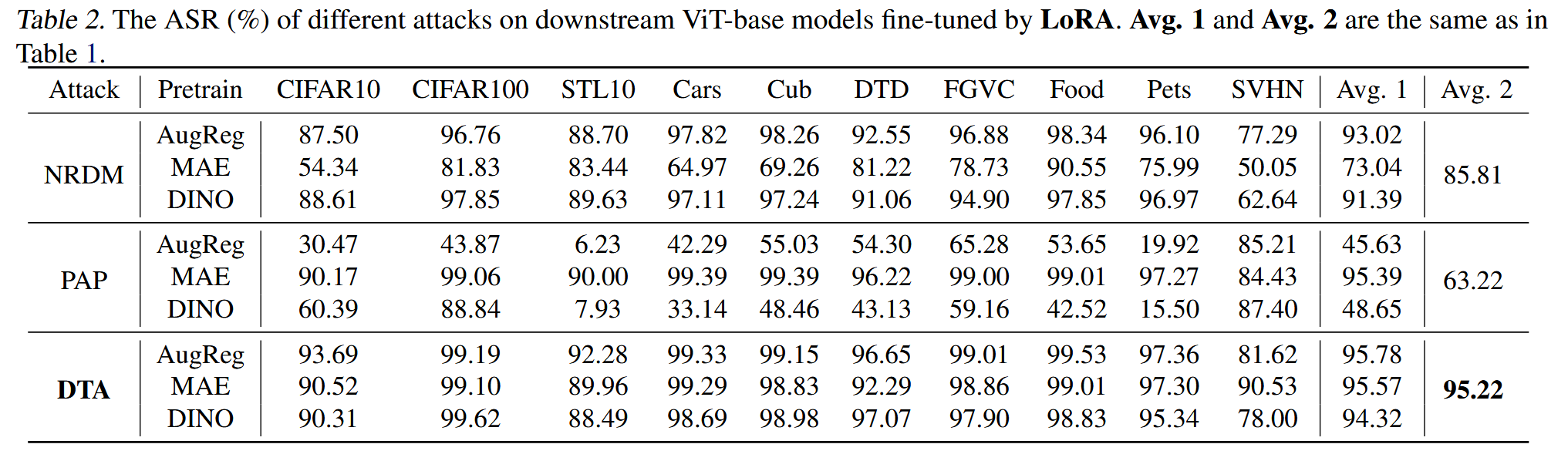
表3. 不同攻击方法对经AdaptFormer微调的下游ViT-base模型的攻击成功率(%)。Avg.1和Avg.2与表1中的计算方式相同。
-
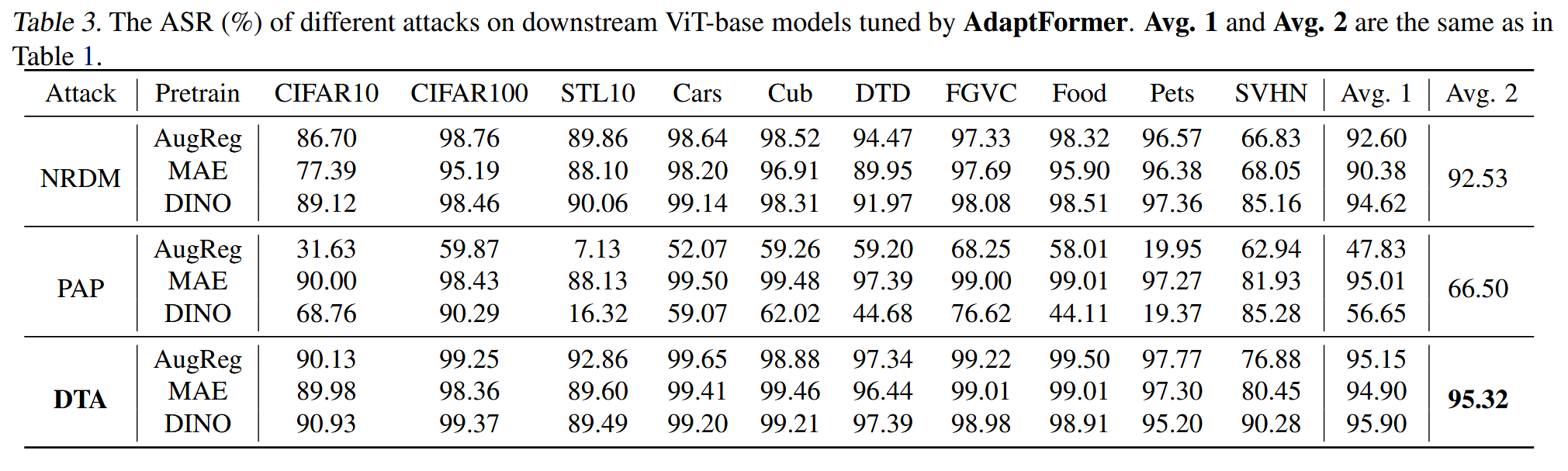
大规模ViTs评估:在不同规模的预训练模型上评估,DTA优势显著。其平均ASR为85.52%,分别比NRDM和PAP高10.92%和71.46%;在ViT-Large模型上,DTA平均ASR为75.25%,远超基线方法。基线方法在不同模型规模下的敏感性和不稳定性高,限制了其实用性。
表4. 不同攻击方法对不同规模模型的攻击成功率(%)。所有模型均由AugReg进行预训练,然后进行全量微调。Avg.1是对数据集求平均,Avg.2是对数据集和模型求平均。
-
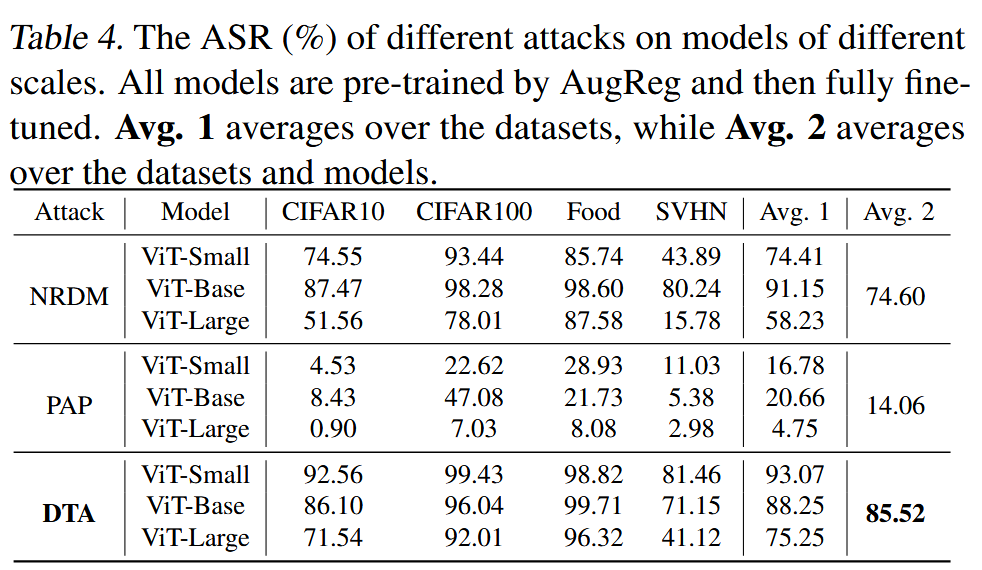
对抗预训练ViTs评估:在对抗预训练模型上,所有攻击的ASR均大幅下降,但DTA仍比其他方法更有效。研究还发现,尽管LoRA和全量微调的模型在干净数据上准确率相似,但LoRA微调的模型在面对下游迁移攻击时更脆弱,其ASR比全量微调的模型高近10%。
图4. 对抗预训练模型上的攻击成功率(%)。所有下游模型均是在ImageNet-1k数据集上,从对抗预训练的XCiT-base模型( ϵ = 8 / 255 \epsilon = 8/255 ϵ=8/255)微调得到的。 -
攻击目标检测和分割:在目标检测任务(选用ViTDet模型在COCO2017数据集上微调)和语义分割任务(选用UPerNet模型在ADE20k数据集上微调)中,DTA均使模型性能下降最多,证明其可有效攻击不同类型的下游任务。
表5. 在COCO2017数据集上攻击目标检测模型的结果。
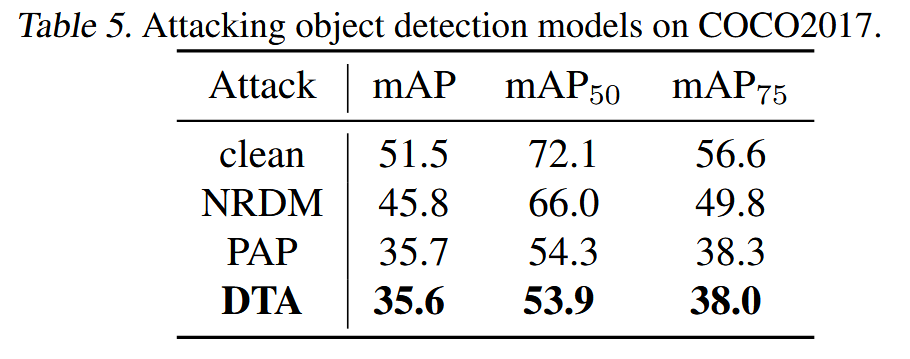
表6. 在ADE20k数据集上攻击分割模型的结果。

-
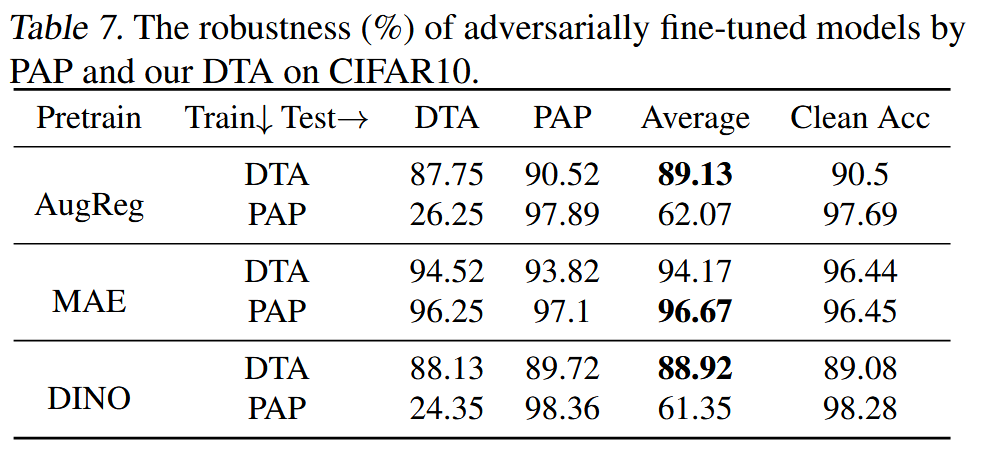
改进对抗训练:通过实验表明,DTA可用于提升对抗训练效果,增强模型对不同下游迁移攻击的鲁棒性。使用DTA进行对抗训练的模型,在面对不同测试攻击时表现更优,而使用PAP训练的模型只能防御PAP攻击,对DTA攻击防御效果差。
表7. 通过PAP和我们的DTA方法在CIFAR10数据集上进行对抗微调后的模型的鲁棒性(%)。
-
消融研究:对损失函数、攻击层和阈值 γ \gamma γ 进行消融研究。结果表明,ATCS损失函数在大多数情况下优于其他替代损失函数;DTA的攻击层选择策略比固定层攻击或全层攻击效果更好;阈值 γ \gamma γ 在0.2时,攻击成功率达到峰值,且该趋势在不同下游数据集上一致。
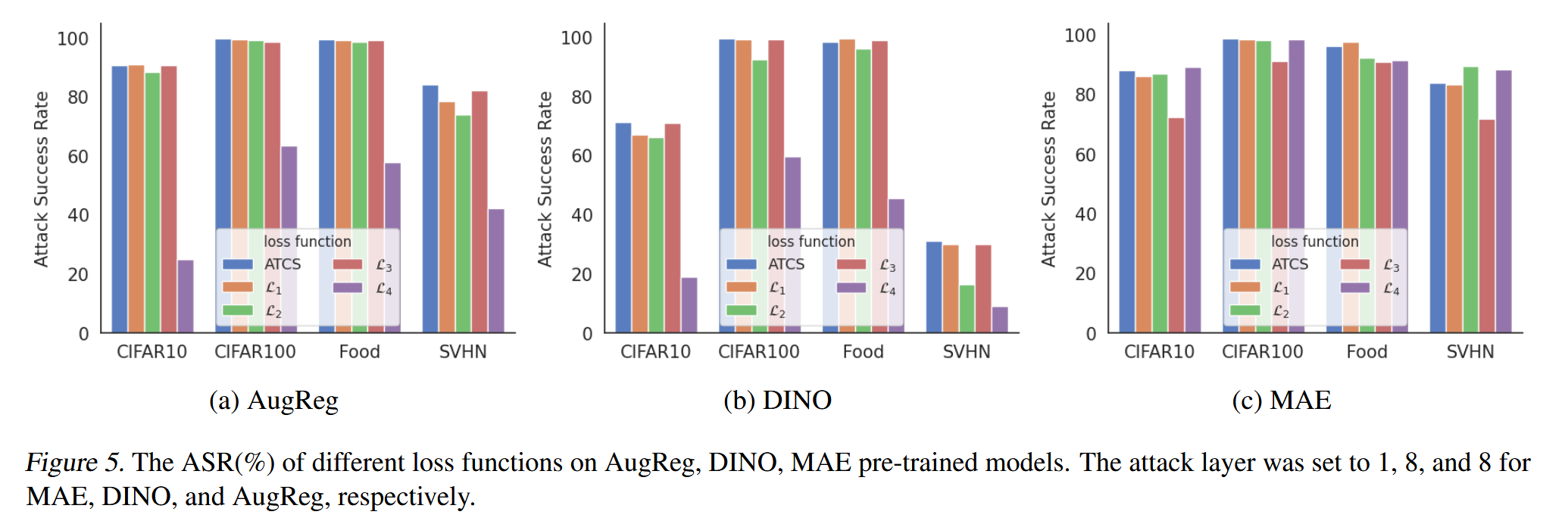
图5. 不同损失函数在由AugReg、DINO、MAE预训练模型上的攻击成功率(%)。对于MAE、DINO和AugReg预训练模型,攻击层分别设置为1、8和8。
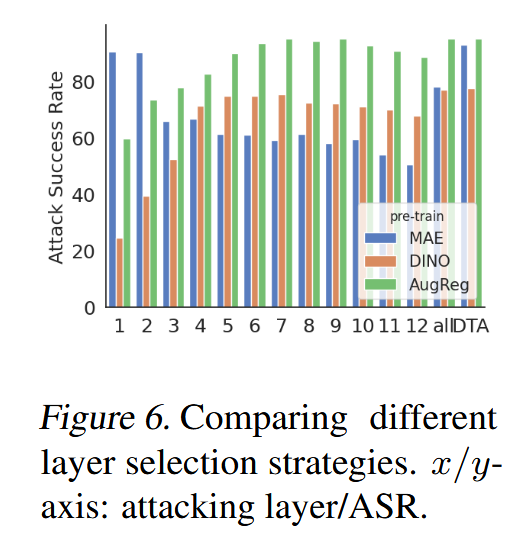
图6. 不同层选择策略的比较。x轴/y轴:攻击层/攻击成功率(ASR) 。
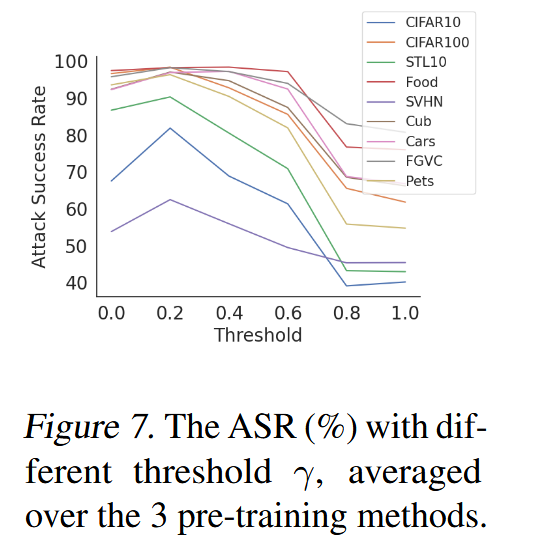
图7. 不同阈值 γ \gamma γ 下的攻击成功率,在 3 种预训练方法上的平均结果。
结论-Conclusion
这部分内容主要总结了研究成果,强调了DTA攻击的有效性、对模型脆弱性的发现以及在对抗训练中的作用,具体如下:
- DTA攻击效果显著:本文研究了下游迁移攻击问题,提出用平均token余弦相似度(ATCS)作为对抗目标。通过实验证明,DTA能找到预训练模型的最脆弱层,生成高度可迁移的对抗样本,在多种预训练方法、微调技术和下游数据集上攻击成功率超90%,比现有攻击方法更有效。
- PETL方法增加模型脆弱性:研究发现,像LoRA这样的新兴参数高效迁移学习(PETL)方法,虽然在微调模型时具有一定优势,但会使下游模型对基于预训练模型的迁移攻击更加敏感,即这些模型更容易受到攻击。
- DTA提升对抗训练效果:当DTA与对抗训练结合使用时,其生成的对抗样本可显著提升模型对不同下游迁移攻击的抗性,这表明DTA在增强模型对抗下游迁移攻击的鲁棒性方面具有独特价值,突出了样本级迁移攻击相较于通用对抗扰动(UAPs)的优势。


















 144
144

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











