







Mechanistic Understandings of Representation Vulnerabilities and Engineering Robust Vision Transformers

这篇文章应该还没有完成,方法部分有缺失。
Vision Transformers(ViTs)在计算机视觉领域取得显著成果,但易受对抗攻击。本文深入剖析其表征漏洞,发现对抗扰动在早期层影响微弱,随后在网络中传播并放大。基于此,提出 NeuroShield-ViT 防御机制,通过选择性中和早期层脆弱神经元来抵御攻击。实验表明,NeuroShield-ViT 在多种攻击下表现出色,尤其在强迭代攻击中优势明显,零样本泛化能力强,在不同数据集和模型上均提升了对抗攻击的鲁棒性,优于传统防御方法。
摘要-Abstract
While transformer-based models dominate NLP and vision applications, their underlying mechanisms to map the input space to the label space semantically are not well understood. In this paper, we study the sources of known representation vulnerabilities of vision transformers (ViT), where perceptually identical images can have very different representations and semantically unrelated images can have the same representation. Our analysis indicates that imperceptible changes to the input can result in significant representation changes, particularly in later layers, suggesting potential instabilities in the performance of ViTs. Our comprehensive study reveals that adversarial effects, while subtle in early layers, propagate and amplify through the network, becoming most pronounced in middle to late layers. This insight motivates the development of NeuroShield-ViT, a novel defense mechanism that strategically neutralizes vulnerable neurons in earlier layers to prevent the cascade of adversarial effects. We demonstrate NeuroShield-ViT’s effectiveness across various attacks, particularly excelling against strong iterative attacks, and showcase its remarkable zero-shot generalization capabilities. Without fine-tuning, our method achieves a competitive accuracy of 77.8% on adversarial examples, surpassing conventional robustness methods. Our results shed new light on how adversarial effects propagate through ViT layers, while providing a promising approach to enhance the robustness of vision transformers against adversarial attacks. Additionally, they provide a promising approach to enhance the robustness of vision transformers against adversarial attacks.
虽然基于Transformer的模型在自然语言处理和视觉应用领域占据主导地位,但其在语义上将输入空间映射到标签空间的潜在机制尚未得到充分理解。在本文中,我们研究了视觉Transformer(ViT)已知的表征漏洞的来源,在这一过程中,感知上相同的图像可能具有截然不同的表征,而语义上不相关的图像却可能具有相同的表征。我们的分析表明,对输入进行难以察觉的改变可能会导致显著的表征变化,尤其是在较靠后的层中,这表明ViT的性能可能存在不稳定性。我们的全面研究揭示,对抗效应在早期层中虽然很微弱,但会在网络中传播并放大,在中间层到后期层中表现得最为明显。这一见解促使我们开发了NeuroShield-ViT,这是一种新颖的防御机制,它通过策略性地中和早期层中的脆弱神经元来防止对抗效应的级联放大。我们展示了NeuroShield-ViT在各种攻击下的有效性,尤其是在抵御强迭代攻击方面表现出色,并展示了其卓越的零样本泛化能力。在不对模型进行微调的情况下,我们的方法在对抗样本上达到了具有竞争力的77.8%的准确率,超越了传统的鲁棒性方法。我们的研究结果为对抗效应如何在ViT各层中传播提供了新的见解,同时为增强视觉Transformer对对抗攻击的鲁棒性提供了一种有前景的方法。此外,它们还为增强视觉Transformer对对抗攻击的鲁棒性提供了一种有前景的方法。
引言-Introduction
这部分内容主要介绍了研究背景和意义,以及本文的两大主要贡献,具体如下:
- 研究背景和意义:Vision Transformers(ViTs)基于Transformer架构在计算机视觉领域取得显著成果,在图像分类、语义分割和目标检测等任务中表现卓越,并被广泛应用于多模态模型。然而,ViTs存在对抗攻击的脆弱性,需要有效的防御机制。当前对ViTs内部机制的理解仍有待加深,特别是在对抗扰动图像的情况下,分析其表征处理和传播机制对提升模型鲁棒性、推动计算机视觉领域发展和开发可靠AI系统至关重要。
- 本文贡献
- 表征漏洞的机制分析:系统研究对抗扰动对ViTs内部表征的影响,聚焦于感知相同图像的表征差异和语义无关图像的表征相似性问题。
- 提出NeuroShield-ViT:引入一种全新的防御机制NeuroShield-ViT,通过动态激活修改,有策略地中和对抗神经元,缓解ViTs的表征漏洞,且无需进行对抗训练。
相关工作-Related Work
这部分内容主要介绍了Transformer和Vision Transformers(ViTs)的研究进展,以及ViTs在对抗攻击和防御方面的相关工作,具体如下:
- Transformer和ViTs的研究进展:Transformer通过自注意力机制和架构,在自然语言处理、计算机视觉和语音识别等多领域提升了性能。当前研究致力于优化其内部表征,增强准确性、鲁棒性和行为可控性。ViTs将Transformer模型扩展到视觉任务,已有研究分析其捕捉类特定特征和处理高维嵌入空间中输入图像的能力。本文在此基础上,探究对抗攻击对ViTs层表征的影响。
- ViTs的对抗攻击方法:ViTs易受对抗攻击,多种攻击方法已被应用于针对ViTs的研究,包括基于优化的方法、基于梯度的技术和转移攻击等。此外,还有基于表示空间的技术,如自监督学习和token梯度正则化等,以及新型优化技术,如可转移触发器和梯度正则化松弛等,这些都增强了对ViTs的攻击能力。
- ViTs的防御策略:研究人员致力于开发在不牺牲准确性的前提下提升模型鲁棒性的防御方法。常见的防御策略包括对抗训练、随机纠缠token、对噪声输入进行预测平均、利用小感受野和掩码减少扰动影响,以及修改表示空间等。本文提出的方法通过在ViTs中引入神经元中和机制来增强对抗鲁棒性,无需对抗训练,且在少量数据集上表现优于传统方法。
视觉Transformer中对抗效应传播分析-Analysis Of Adversarial Effect Propagation In Vision Transformers
该部分主要从全局token表征分析、空间token扰动动态和神经元敏感性与激活模式分析三个关键视角,对视觉Transformer(ViT)中对抗效应的传播进行了深入剖析,具体内容如下:
- 分析背景与设置:为深入理解ViT中表征漏洞的机制,采用基于迭代优化的对抗攻击方法,利用目标图像的表征嵌入创建输入图像的扰动版本,以精确操控模型内部表征。实验选用在ImageNet-1K上预训练的ViT-base模型,从该数据集中选取100个类,每类5张图像,随机选择目标类和目标图像,应用迭代梯度优化(IGO)攻击创建500对输入和扰动图像样本。
- 全局token表征分析:通过计算干净图像和对抗图像在各层CLS token表征的余弦相似度,分析相似度轨迹以确定对抗效应显著的关键层。结果显示:早期层(0-2),输入和扰动图像的CLS token表征相似度高,对抗扰动对模型表征影响微弱;中间层(3-8),相似度逐渐下降,扰动影响开始放大;后期层(9-11),相似度急剧下降,且与目标类的相似度增加。这表明早期网络中已编码导致误分类的关键变化,在早期层处理对抗效应可能更有助于维持模型性能。
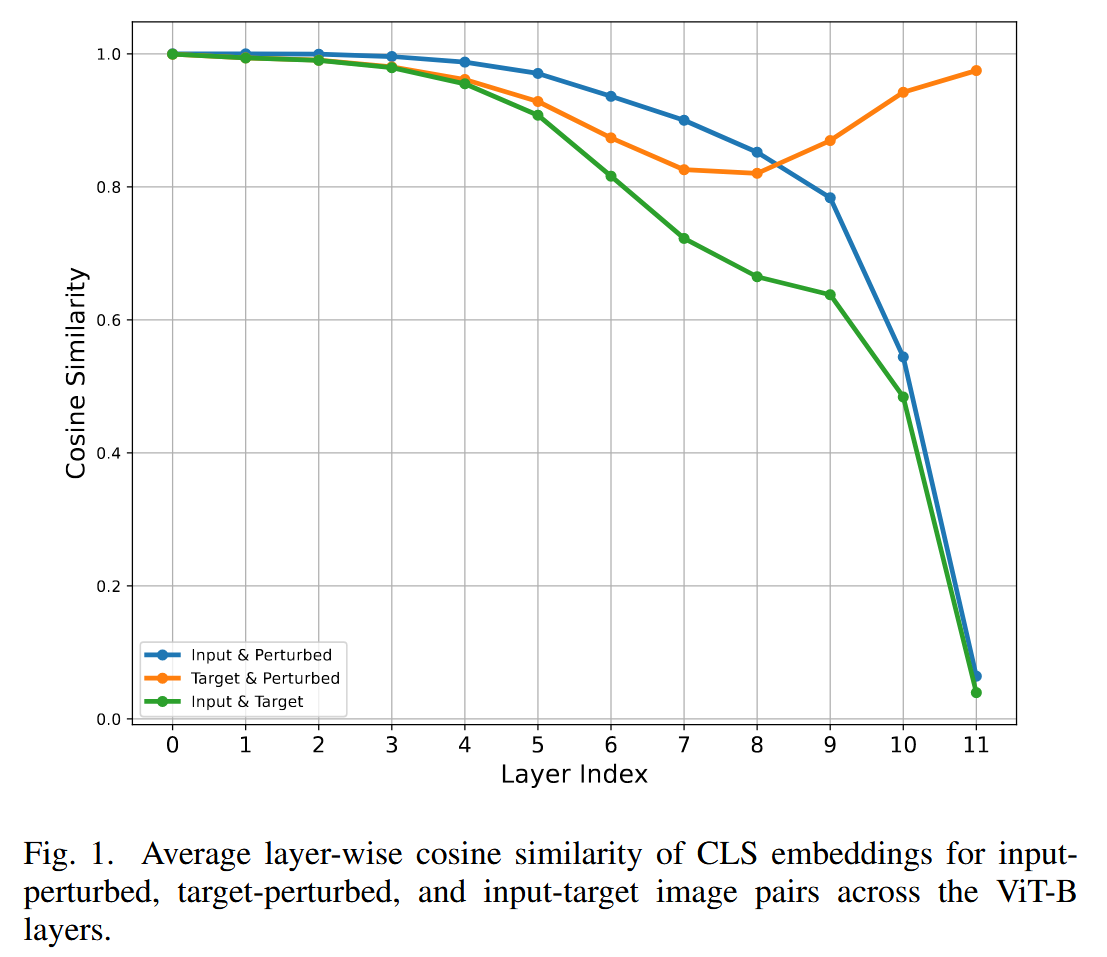
图1. ViT-B各层中,输入-扰动、目标-扰动和输入-目标图像对的CLS嵌入的平均层间余弦相似度。 - 空间token扰动动态:从全局表征延伸到局部特征,研究单个图像patch的嵌入。针对每个Transformer块的注意力投影、前馈网络输出和残差连接输出这三个关键组件,计算干净和对抗嵌入的成对余弦相似度。结果表明:早期层(0-2),各块相似度高,80-100%的嵌入相似度在0.8-1.0范围内;中间层(3-8),MLP块开始出现明显差异,扰动开始放大;后期层(9-11),注意力投影块差异显著,大量嵌入相似度降低,但残差连接在后期仍保持较高相似度。这说明对抗效应在网络组件中传播并不均匀,MLP块对扰动更敏感。
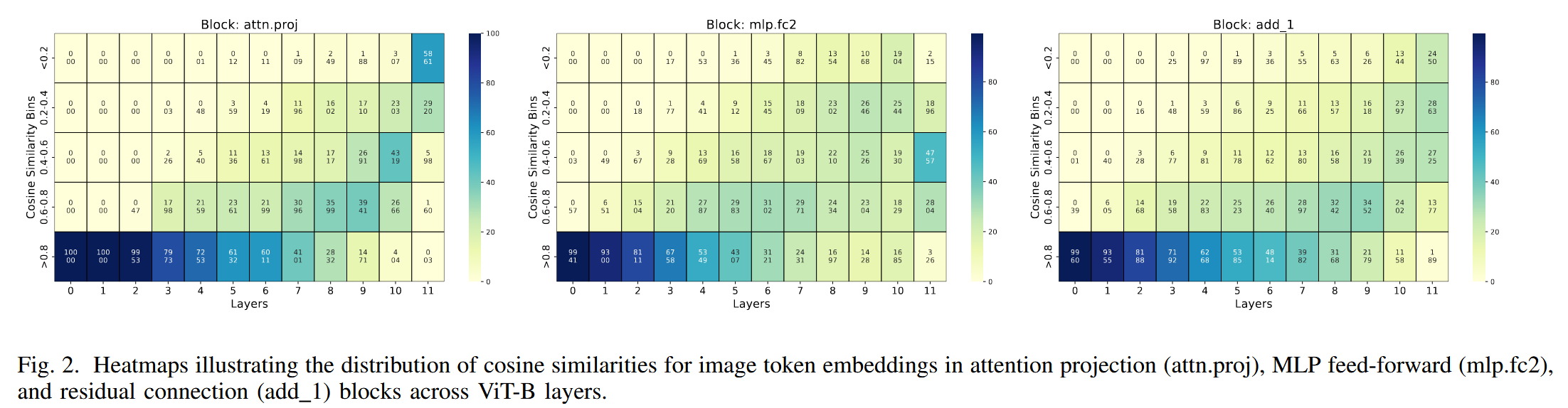
图2. 热图展示了ViT-B各层中,图像令牌嵌入在注意力投影(attn.proj)、多层感知器前馈(mlp.fc2)和残差连接(add 1)模块中的余弦相似度分布情况。 - 神经元敏感性和激活模式分析:对ViT不同层和块的单个神经元激活进行细致分析,通过计算神经元重要性确定对扰动输入重要的神经元。结果显示:早期层(0-2),对抗神经元比例低,对抗效应局部化;中间层(3-8),对抗神经元比例显著增加,尤其当p≥1%时;后期层(9-11),对抗神经元比例进一步上升,p=2%时达到60 - 70%,随后在最后一层急剧下降。MLP块中的对抗神经元比注意力块扩散更早且更明显。这种早期层对抗效应的局部化表明,控制早期受影响神经元的影响,有助于抑制后期的级联效应。
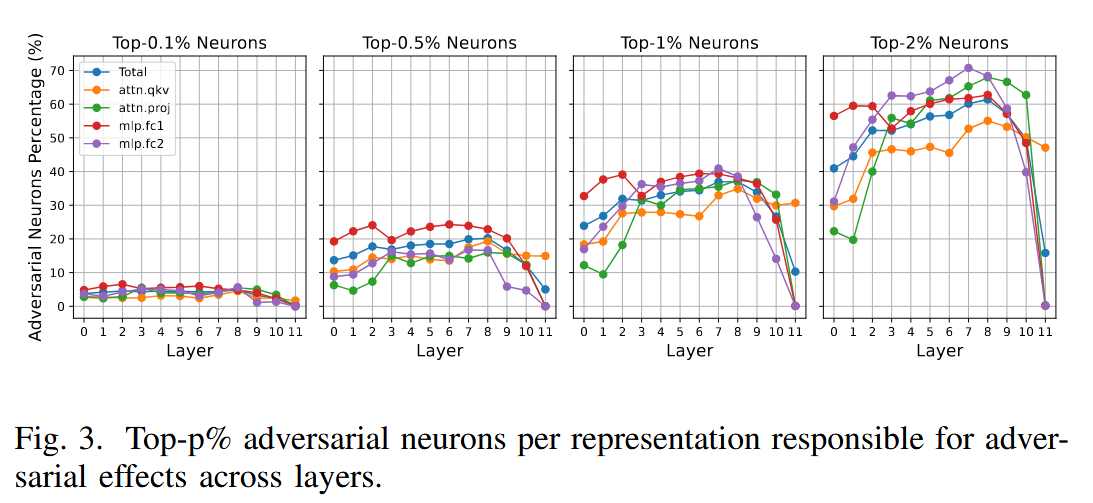
图3. 各层中对对抗效应有贡献的、占比为前p%的对抗神经元(按表征划分)。
方法-Methodology
这部分内容主要介绍了一种名为NeuroShield-ViT的防御方法,用于减轻视觉Transformer(ViT)中的对抗扰动,具体如下:
- 防御方法:选择性神经元中和:NeuroShield-ViT是一种全新的防御机制,其核心是通过策略性地修改ViT中脆弱神经元的激活来减轻对抗扰动。该算法首先加载预训练的ViT模型和输入-扰动图像对数据集,接着利用激活值和梯度计算神经元重要性,分别确定输入图像和扰动图像中每个表征上前p%最重要的神经元,通过计算这两个神经元集合的差集,找出对对抗示例具有独特重要性的神经元。
- 选择性中和操作:对找出的对抗神经元,NeuroShield-ViT应用一个在[0, 0.5)范围内的中和系数来修改其激活。在指定的层和块中进行这一操作后,算法对修改后的网络执行前向传递,从而得到更鲁棒的分类结果。这种有针对性的方法能够有效降低对表征漏洞贡献最大的神经元的影响,进而增强ViT模型在各种攻击下的整体鲁棒性。

实验和结果-Experiments And Results
这部分主要介绍了针对NeuroShield-ViT展开的一系列实验及结果,验证了该方法在提升视觉Transformer对抗攻击鲁棒性方面的有效性,具体内容如下:
-
实验设置
- 数据集和模型:选用mini ImageNet-1K、Imagenette和CIFAR-10等数据集,从每个数据集中随机选取200个样本生成对抗扰动图像用于测试,并生成相同数量的图像对确定神经元重要性(NeuroShield Calibration Set,NCS)。分析涉及ViT-S、ViT-B、DeiT-S和DeiT-B四种视觉Transformer变体,以ViT-B为主要研究模型。
- 对抗攻击:采用快速梯度符号法(FGSM)、投影梯度下降(PGD-20和PGD-100)、迭代梯度优化(IGO)等多种对抗攻击方法评估模型鲁棒性。
- 实现与评估:基于PyTorch框架,利用2x NVIDIA RTX A5000 GPU加速计算,以准确率为主要评估指标。
-
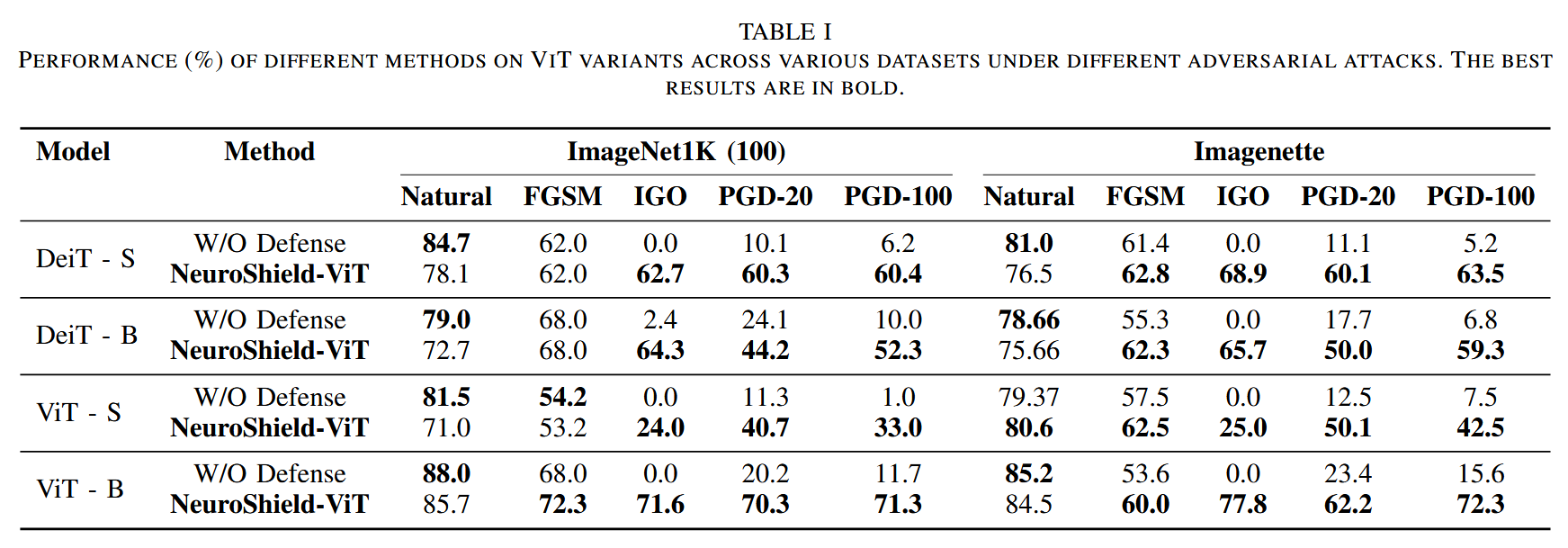
NeuroShield-ViT性能评估:在实验中仅使用25%的NCS数据,设置top p值为0.5,中和系数为0.1。结果显示,NeuroShield-ViT显著提升了视觉Transformer在多种对抗攻击下的鲁棒性,尤其在面对如IGO、PGD-20和PGD-100等较强攻击时表现突出。在ImageNet1K (100)数据集上,针对IGO攻击,ViT-B的准确率从0%提升到71.6%;针对PGD-100攻击,从11.7%提升到71.3%。在保持自然准确率方面,该方法在大多数情况下仅有适度下降,在Imagenette数据集的一种配置下甚至略有提升。不过,在应对FGSM攻击时,其准确率提升不明显甚至在部分情况下略有下降。
表1. 不同方法在不同对抗攻击下,于多种数据集上针对不同视觉Transformer(ViT)变体的性能表现(%)。最优结果以粗体显示。
-
消融研究:通过层中和分析发现,仅中和后期层对模型准确率提升效果不佳,而中和第一层就能获得较高准确率,且随着更多早期层被中和,准确率保持稳定。这表明聚焦早期层进行中和操作,对在减轻对抗效应的同时维持模型性能最为有效。
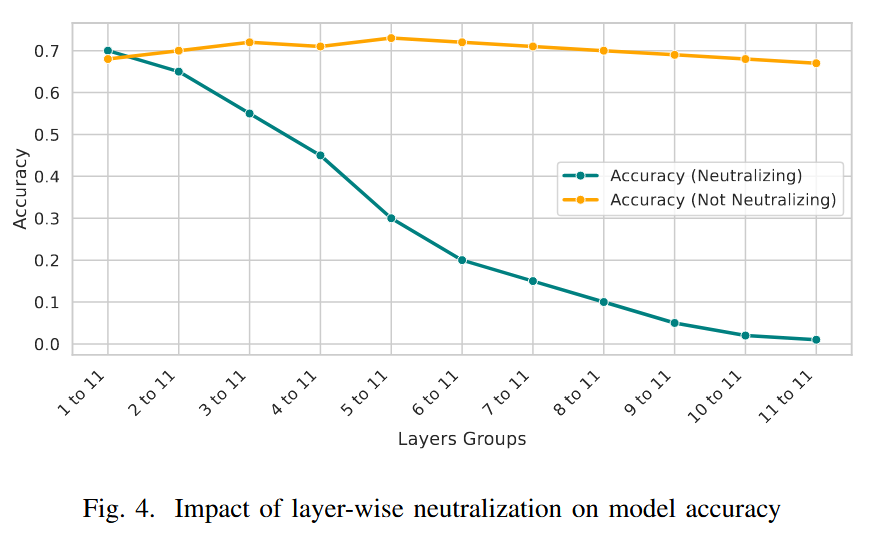
图4. 逐层中和对模型准确率的影响 -
敏感性分析
- 数据比例影响:随着NCS子集大小从5%增加到100%,模型准确率不断提高,top-p 2%的设置在各子集大小下表现均优于top-p 1%。在较小子集(5 - 20)上,子集大小的增加对准确率提升效果明显;在较大子集(60 - 100)上,提升效果逐渐趋于平稳。这表明NeuroShield-ViT在不需要完整数据集的情况下也能实现较好性能,在计算效率和对抗鲁棒性之间取得了平衡。
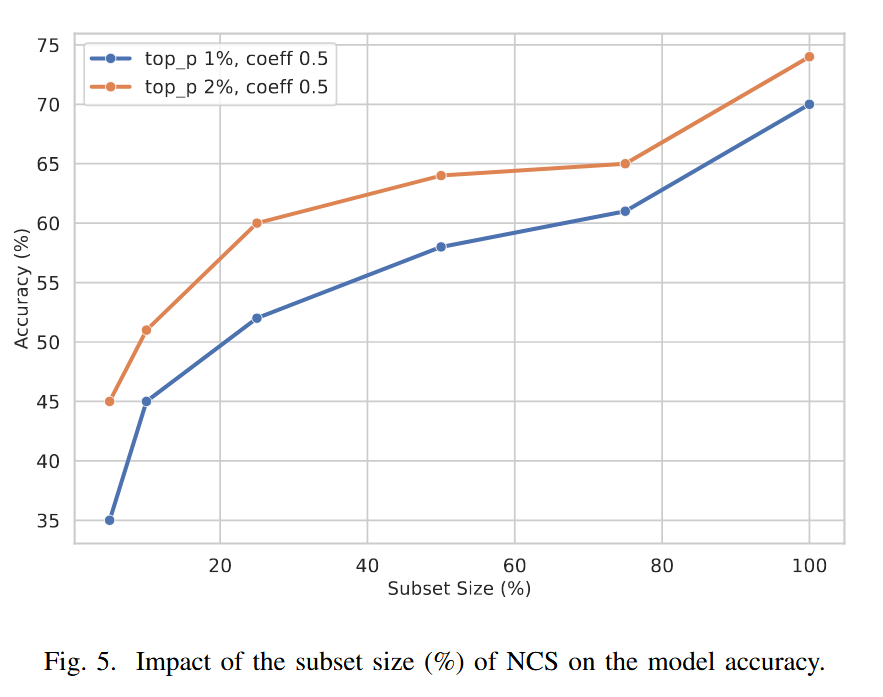
图5. NeuroShield校准集(NCS)子集大小(%)对模型准确率的影响。 - 参数敏感性评估:对ViT-B/16 - 224在ImageNet1k上的实验表明,较小子集(如大小为5)在较低top-p值(0.5% - 1.0%)和中等中和系数(0.1 - 0.2)下可获得较高准确率;较大子集和完整数据集则在较高top-p值(2.0%)和中和系数0.5时性能最佳。使用高top-p值和低中和系数可能会因过度中和重要特征而降低准确率,凸显了仔细调整参数以平衡对抗鲁棒性和模型性能的重要性。
- 数据比例影响:随着NCS子集大小从5%增加到100%,模型准确率不断提高,top-p 2%的设置在各子集大小下表现均优于top-p 1%。在较小子集(5 - 20)上,子集大小的增加对准确率提升效果明显;在较大子集(60 - 100)上,提升效果逐渐趋于平稳。这表明NeuroShield-ViT在不需要完整数据集的情况下也能实现较好性能,在计算效率和对抗鲁棒性之间取得了平衡。
-
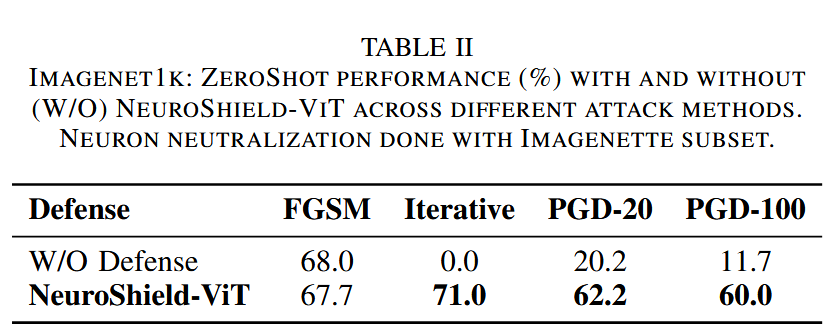
泛化研究:跨类泛化评估显示,NeuroShield-ViT在零样本场景下表现出色。在基于10类Imagenette NCS数据进行神经元中和后,应用于ImageNet1K的100类子集时,模型鲁棒性显著提升。针对迭代攻击,准确率从0%提升到71%;针对PGD-100攻击,从11.7%提升到60%。这表明该方法能识别和中和跨不同类集的对抗神经元,捕捉到视觉Transformer表征漏洞的基本特征,在不同数据集上均具有有效性。
表2. ImageNet1K数据集:在不同攻击方法下,使用和不使用(W/O)NeuroShield-ViT的零样本性能(%)对比。神经元中和操作基于Imagenette子集数据完成。
-
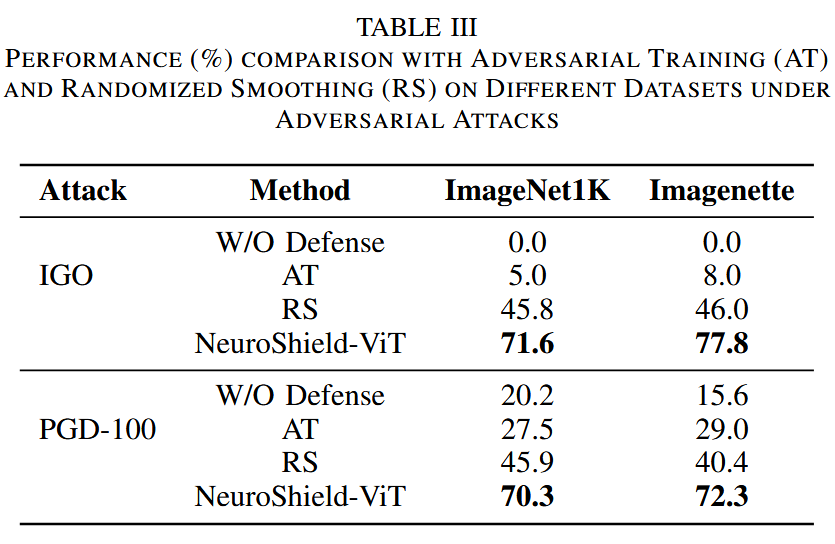
对比分析:与传统对抗训练(AT)和随机平滑方法相比,NeuroShield-ViT在仅使用25% NCS数据的情况下,准确率提升幅度更大。传统对抗训练在ImageNet1K和Imagenette数据集上,针对IGO和PGD-100攻击的准确率提升有限;随机平滑虽有一定效果,但NeuroShield-ViT的表现远超二者,展现出其作为一种高效防御机制的潜力。
表3. 在对抗攻击下,不同数据集上NeuroShield-ViT与对抗训练(AT)、随机平滑(RS)的性能(%)对比
讨论-Discussion
这部分主要讨论了研究成果、NeuroShield-ViT的优势与局限性,以及对未来研究方向的展望,具体如下:
- 研究成果总结:通过对视觉Transformer(ViT)表征漏洞的全面分析,发现对抗效应在早期层较为微弱,但会在网络中传播并放大,在中间到后期层最为显著。这一发现为理解ViT的脆弱性提供了关键依据。
- NeuroShield-ViT的优势:基于上述发现开发的NeuroShield-ViT,通过策略性地中和早期层的脆弱神经元,有效阻止了对抗效应的级联放大。与对抗训练等当前最先进的方法相比,NeuroShield-ViT在各种攻击下表现出更优越的鲁棒性,尤其是在应对强迭代攻击时效果显著。其在零样本场景下的有效性,进一步证明了它能够捕捉到表征漏洞的基本特征。
- NeuroShield-ViT的局限性:NeuroShield-ViT依赖预先识别的脆弱神经元,这可能限制了它对新型攻击类型的适应性。因为新型攻击可能利用不同的神经元或机制来干扰模型,而预先确定的脆弱神经元可能无法应对这些新情况。
- 未来研究方向:未来的工作应探索动态神经元识别技术,以提高对新型攻击的适应性。同时,研究该方法在视觉任务之外的其他Transformer架构中的适用性,拓展其应用范围。此外,通过分析和中和层内特定块而非整个层,可以降低计算成本并提高方法的运行速度。
结论-Conclusion
这部分内容总结了研究成果,强调了研究对提升AI系统安全性的意义以及对未来神经网络架构设计的潜在影响,具体如下:
- 研究成果总结:本文全面深入地阐释了视觉Transformer(ViT)中表征漏洞的机制,并提出NeuroShield-ViT这一针对对抗攻击的有效防御机制。该机制聚焦于增强早期层的弹性和对神经元的选择性操控,在无需大量重新训练的情况下,展现出打造更安全AI系统的潜力。
- 研究意义:NeuroShield-ViT背后的原理不仅适用于计算机视觉领域,还能为提升机器学习各个领域的模型可靠性提供思路。在AI广泛应用于关键领域的当下,这些研究成果为开发更值得信赖的系统奠定了基础,有望影响未来神经网络架构的设计方向,使其更加注重对对抗威胁的内在鲁棒性。


















 739
739

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











