







NAPGuard: Towards Detecting Naturalistic Adversarial Patches
本文 “NAPGuard: Towards Detecting Naturalistic Adversarial Patches” 提出 NAPGuard 框架,通过训练时对齐攻击特征、推理时抑制自然特征,有效检测自然对抗图块,还构建了 GAP 数据集。实验显示该方法在检测 NAPs 上大幅超越现有方法,为对抗图块检测研究提供了新方向。
摘要-Abstract
Recently, the emergence of naturalistic adversarial patch (NAP), which possesses a deceptive appearance and various representations, underscores the necessity of developing robust detection strategies. However, existing approaches fail to differentiate the deep-seated natures in adversarial patches, i.e., aggressiveness and naturalness, leading to unsatisfactory precision and generalization against NAPs. To tackle this issue, we propose NAPGuard to provide strong detection capability against NAPs via the elaborated critical feature modulation framework. For improving precision, we propose the aggressive feature aligned learning to enhance the model’s capability in capturing accurate aggressive patterns. Considering the challenge of inaccurate model learning caused by deceptive appearance, we align the aggressive features by the proposed pattern alignment loss during training. Since the model could learn more accurate aggressive patterns, it is able to detect deceptive patches more precisely. To enhance generalization, we design the natural feature suppressed inference to universally mitigate the disturbance from different NAPs. Since various representations arise in diverse disturbing forms to hinder generalization, we suppress the natural features in a unified approach via the feature shield module. Therefore, the models could recognize NAPs within less disturbance and activate the generalized detection ability. Extensive experiments show that our method surpasses state-of-the-art methods by large margins in detecting NAPs (improve 60.24% AP@0.5 on average).
最近,自然对抗图块(NAP)的出现凸显了开发强大检测策略的必要性,这类对抗图块具有欺骗性外观和多种表现形式。然而,现有方法无法区分对抗图块的深层本质,即攻击性和自然性,这导致在检测自然对抗图块时,精度和泛化能力都不尽人意。为解决这一问题,我们提出了NAPGuard,通过精心设计的关键特征调制框架,实现对自然对抗图块的强大检测能力。为提高检测精度,我们提出了攻击特征对齐学习方法,以增强模型捕捉准确攻击模式的能力。考虑到欺骗性外观会导致模型学习不准确这一挑战,我们在训练过程中通过提出的模式对齐损失来对齐攻击特征。由于模型能够学习到更准确的攻击模式,因此它能够更精确地检测出具有欺骗性的图块。为增强泛化能力,我们设计了自然特征抑制推理方法,以普遍减轻不同自然对抗图块带来的干扰。由于多种表现形式会以不同的干扰方式出现,从而阻碍泛化,我们通过特征屏蔽模块以统一的方式抑制自然特征。这样一来,模型能够在较少的干扰下识别自然对抗图块,并激活其泛化检测能力。大量实验表明,我们的方法在检测自然对抗图块方面,大幅超越了当前最先进的方法(平均AP@0.5提高了60.24%)。
引言-Introduction
这部分主要介绍了研究背景、问题、解决方法及贡献,具体内容如下:
- 研究背景:深度神经网络(DNNs)在实际场景应用广泛,但易受对抗攻击,其中对抗图块作为物理对抗攻击的重要形式,对计算机视觉模型和应用安全构成严重威胁。为应对这一问题,研究人员开展了大量物理对抗图块检测的研究,当前检测方法主要分为图像分析方法和模型辅助方法两类。
- 存在问题:现有检测方法在检测自然对抗图块(NAPs)时存在明显局限,即精度低和泛化性不足。NAPs具有欺骗性外观和多种表示形式两个突出特点,然而当前防御方法未充分考虑这些特性,难以有效检测NAPs。
- 解决方法:提出NAPGuard,通过精心设计的关键特征调制框架,实现对NAPs的强大检测能力。一方面,采用攻击特征对齐学习策略,在训练过程中通过模式对齐损失对齐攻击特征,提高模型捕捉准确攻击模式的能力,进而提升检测精度;另一方面,引入自然特征抑制推理策略,利用特征屏蔽模块统一抑制自然特征,减轻不同NAPs的干扰,增强模型泛化能力。
- 主要贡献:首次从攻击特征和自然特征的角度探索该问题,重新审视NAPs的本质;提出NAPGuard框架,分别在训练和推理过程中对齐攻击特征和抑制自然特征,有效检测NAPs;构建首个广义对抗图块检测(GAP)数据集,推动物理对抗补丁检测领域的研究;实验表明该方法在检测NAPs上远超现有方法,平均AP@0.5提升60.24%。
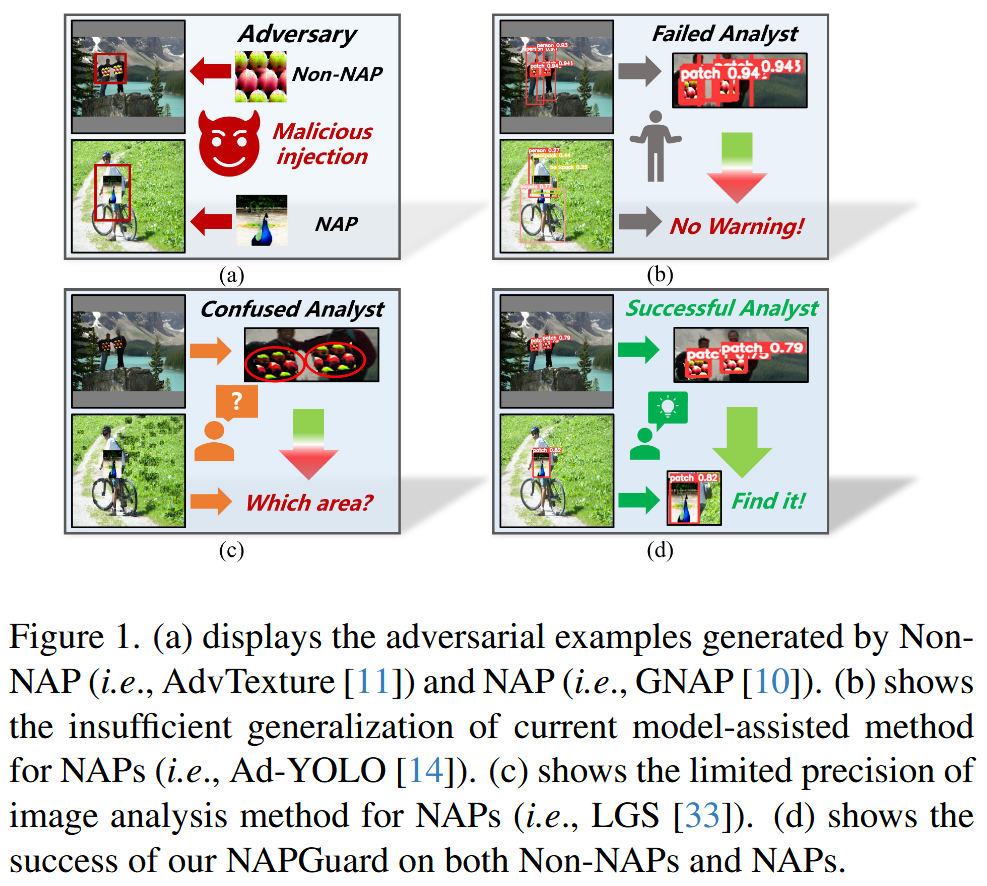
图1. (a)展示了由非自然对抗图块(即AdvTexture)和自然对抗图块(即GNAP)生成的对抗样本。(b)显示了当前针对自然对抗图块的模型辅助方法(即Ad - YOLO)泛化能力不足。(c)显示了针对自然对抗图块的图像分析方法(即LGS)精度有限。(d)展示了我们的NAPGuard在检测非自然对抗图块和自然对抗图块方面均取得成功。
相关工作-Related Work
这部分主要介绍了物理对抗图块攻击和物理对抗图块检测两方面的相关研究进展,具体内容如下:
- 物理对抗补丁攻击:大量研究表明DNNs易受对抗图块攻击,早期研究主要在数字世界生成局部对抗图块,如今该技术已应用于现实场景,如结合图像扭曲方法生成类似“隐形斗篷”的可穿戴物理对抗图块。此外,自然性成为另一个研究热点,研究者借助生成网络,如生成对抗网络(GAN)和扩散模型,生成更逼真、更易躲避人眼检测的对抗图块,显著提升了对抗图块的隐蔽性,这也使得NAPs对现有防御策略构成巨大挑战。
- 物理对抗补丁检测:研究人员针对对抗攻击开展了诸多探索并开发了多种防御方法。在对抗图块检测方面,早期方法主要聚焦于检测对抗样本,缺乏对补丁的精确定位。当前方法主要致力于在模型输入前检测图块,可分为两类主流方法:一是图像分析方法,通过分析图像的异常成分,如梯度、特征、熵等来检测对抗补丁;二是模型辅助方法,借助训练深度学习模型(如图像分割模型或目标检测模型)辅助检测对抗图块。然而,现有检测方法无法区分对抗补丁的攻击性和自然性,在检测NAPs时效果不佳,本文则聚焦于这些深层特性,设计有效检测NAPs的框架。
方法-Methodology
问题定义-Problem Definition
这部分主要定义了对抗样本、对抗补丁攻击以及对抗补丁检测模型的训练和推理过程,具体内容如下:
- 对抗样本定义:给定受害者模型 F θ F_{\theta} Fθ、输入的干净图像 I I I 及其真实标签 y y y,对抗样本 I a d v I_{adv} Iadv 会误导模型做出错误预测,即 F θ ( I a d v ) ≠ y \mathbb{F}_{\theta}(I_{adv}) ≠y Fθ(Iadv)=y.
- 对抗图块攻击定义:在对抗图块攻击中,用 P P P 表示对抗图块,攻击者通过应用器 A A A,对输入图像 I I I 应用对抗补丁 P P P,并进行如旋转、缩放等变换 t ∈ T t \in T t∈T,得到的对抗样本可表示为 I a d v = A ( I , P , t ) I_{adv}=A(I, P, t) Iadv=A(I,P,t).
- 对抗补图块检测模型训练定义:通过将常用的目标检测模型的类别 0 重新定义为“图块”类别,舍弃其他类别,并使用对抗样本数据集进行训练,从而获得对抗补丁检测模型(即“检测器”)。给定具有损失函数 c c c 的图块检测器 M θ M_{\theta} Mθ,以及包含对抗样本 x 1 , x 2 , . . . , x n {x_{1}, x_{2},..., x_{n}} x1,x2,...,xn 及其真实标签 y 1 , y 2 , . . . , y n {y_{1}, y_{2},..., y_{n}} y1,y2,...,yn 的训练集 X X X,训练过程定义为 m i n θ E x i ∼ X [ L ( M θ ( x i ) , y i ) ] min _{\theta} E_{x_{i} \sim \mathcal{X}}\left[\mathcal{L}\left(\mathbb{M}_{\theta}\left(x_{i}\right), y_{i}\right)\right] minθExi∼X[L(Mθ(xi),yi)].
- 对抗补丁检测模型推理定义:对于来自现实世界的图像 x ∗ x^{*} x∗,推理过程定义为 M θ ( x ∗ ) = y ∗ \mathbb{M}_{\theta}(x^{*})=y^{*} Mθ(x∗)=y∗,其中 y ∗ y^{*} y∗ 表示补丁的位置。本文综合考虑训练和推理过程,以提供针对NAPs的全面检测框架。
框架总览-Framework Overview
这部分主要介绍了NAPGuard框架的总体思路,通过划分特征空间,分别采用不同策略提升检测精度和泛化能力,具体如下:
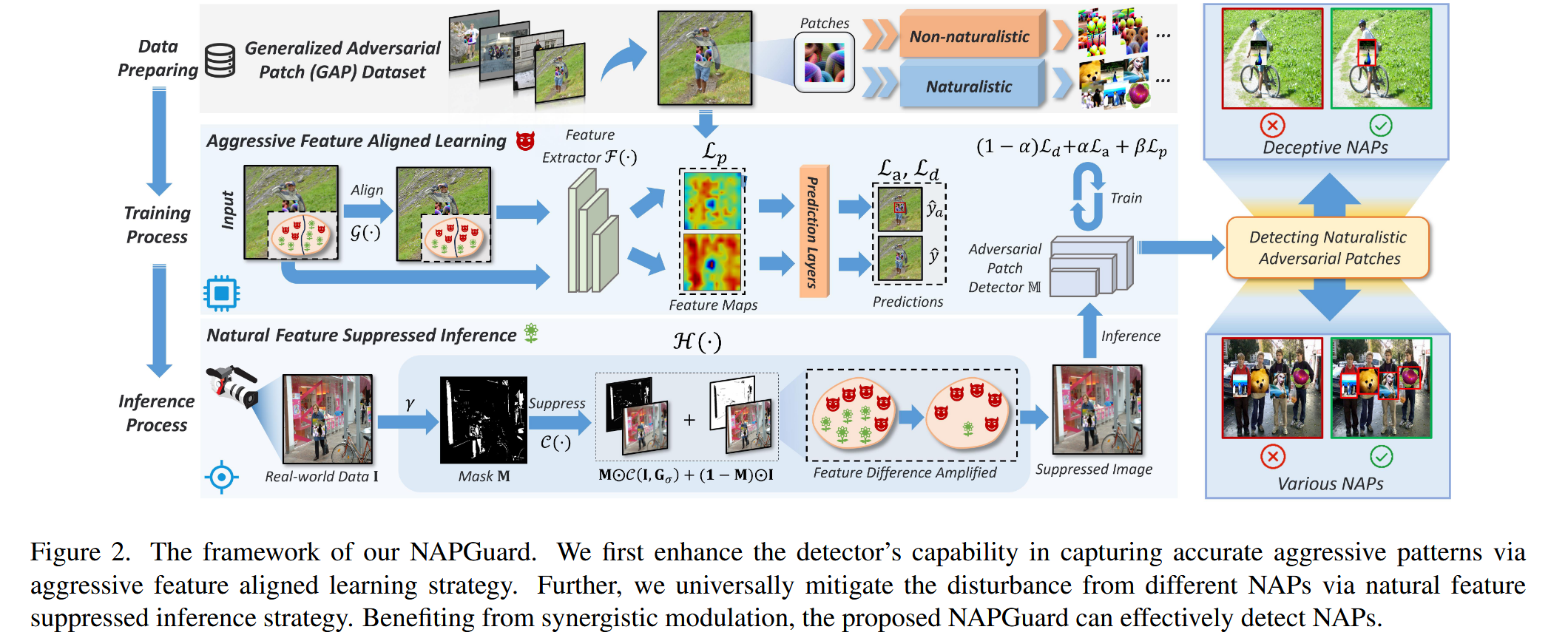
图2. 我们的NAPGuard框架。我们首先通过攻击特征对齐学习策略,增强检测器捕捉准确攻击模式的能力。进一步地,我们通过自然特征抑制推理策略,普遍减轻不同自然对抗图块(NAPs)带来的干扰。得益于协同调制,所提出的NAPGuard能够有效地检测自然对抗图块。
- 特征空间划分:为有效检测自然对抗图块(NAPs),将特征空间划分为两类:一类是促成对抗行为的攻击特征;另一类是与自然性相关的自然特征。
- 框架核心策略
- 提升精度:攻击特征对齐学习(AFAL):由于欺骗性外观会导致模型学习不准确,提出AFAL策略。基于以往研究发现对抗样本的攻击特征主要存在于高频分量,在训练过程中从高频角度出发,利用提出的模式对齐损失来对齐攻击特征。通过这种方式,检测器能够更好地识别攻击模式,从而提高精确检测更具欺骗性NAPs的能力。
- 增强泛化:自然特征抑制推理(NFSI):考虑到不同NAPs的多种表示形式会产生多样的干扰形式,提出NFSI策略。采用统一的方法抑制自然特征,以减轻不同NAPs带来的干扰。受生物学中弹出效应的启发,设计特征屏蔽模块,放大自然特征和攻击特征之间的差异。在推理过程中应用该模块,为模型创造一个干扰较少的环境,使其能够更好地捕捉攻击特征,进而激活对各种NAPs的泛化检测能力。
攻击特征对齐学习-Aggressive Feature Aligned Learning
这部分内容主要介绍了攻击特征对齐学习(AFAL)策略,目的是提高模型检测自然对抗图块(NAPs)的精度,具体如下:
- 设计思路:基于前人研究发现,对抗样本的攻击特征主要存在于高频分量,且NAPs的高频分量与周围环境更相似,导致模型学习不准确。因此,若检测器能在与自然对抗样本(NAEs)对齐的环境中识别攻击模式,可能更好地检测欺骗性NAPs。于是考虑在训练过程中通过对齐攻击特征,增强检测器捕捉准确攻击模式的能力。
- 实现方法:对训练集中的对抗样本,利用拉普拉斯算子 ∇ 2 \nabla^{2} ∇2 增强图像高频分量,增加对抗图块与周围环境的相似性。引入模式对齐损失,其基于均方误差(MSE),衡量正常图像和对齐图像特征图之间的差异,公式为 L p = 1 n ∑ i = 1 n ∥ F ( x i ) − F ( G ( x i , ∇ 2 ) ) ∥ 2 \mathcal{L}_{p}=\frac{1}{n} \sum_{i=1}^{n}\left\| \mathcal{F}\left(x_{i}\right)-\mathcal{F}\left(\mathcal{G}\left(x_{i}, \nabla^{2}\right)\right)\right\| ^{2} Lp=n1∑i=1n F(xi)−F(G(xi,∇2)) 2,其中 G ( x i , ∇ 2 ) = x i − ∇ 2 x i \mathcal{G}\left(x_{i}, \nabla^{2}\right)=x_{i}-\nabla^{2} x_{i} G(xi,∇2)=xi−∇2xi。通过最小化 L p \mathcal{L}_{p} Lp,帮助检测器从与NAEs对齐的环境中准确捕捉攻击模式。
- 优化训练:将 G ( x i , ∇ 2 ) \mathcal{G}\left(x_{i}, \nabla^{2}\right) G(xi,∇2) 作为辅助分支输入检测器,并将其检测损失 L a = L d ( G ( x i , ∇ 2 ) ) \mathcal{L}_{a}=\mathcal{L}_{d}\left(\mathcal{G}\left(x_{i}, \nabla^{2}\right)\right) La=Ld(G(xi,∇2)) 纳入现有优化过程。最终通过最小化 m i n ( 1 − α ) L d + α L a + β L p min (1-\alpha) \mathcal{L}_{d}+\alpha \mathcal{L}_{a}+\beta \mathcal{L}_{p} min(1−α)Ld+αLa+βLp 训练更强的检测器,其中 L d \mathcal{L}_{d} Ld 是检测器原始检测损失, α \alpha α 和 β \beta β 分别控制 L a \mathcal{L}_{a} La 和 L p \mathcal{L}_{p} Lp 的贡献。
自然特征抑制推理-Natural Feature Suppressed Inference
这部分内容主要介绍了自然特征抑制推理(NFSI)策略,目的是增强模型检测自然对抗图块(NAPs)的泛化能力,具体如下:
- 策略背景:随着对抗图块攻击技术的发展,未来会出现更多具有多种表示形式的NAPs,它们会给检测器带来未知且多样的干扰,挑战其泛化检测能力。为提升泛化性,需在推理过程中统一抑制自然特征,减轻这些干扰。
- 实现方法:鉴于攻击特征主要存在于高频分量,从低频域入手抑制自然特征。受生物学中弹出效应启发,设计特征屏蔽模块 H ( ⋅ ) H(\cdot) H(⋅). 对真实场景中采样的图像,先通过二维快速傅里叶变换(FFT)得到其频域表示 F ( u , v ) F(u, v) F(u,v),再与圆形低通滤波器 R L ( u , v ) R_{L}(u, v) RL(u,v) 进行逐元素相乘,分离出低频分量,经过逆FFT得到滤波后的图像 I l o w ( x , y ) I_{low }(x, y) Ilow(x,y),即 F ( u , v ) = T ( I ( x , y ) ) F(u, v)=\mathcal{T}(I(x, y)) F(u,v)=T(I(x,y)), I l o w ( x , y ) = T − 1 ( F ( u , v ) ⊙ R L ( u , v ) ) I_{low }(x, y)=\mathcal{T}^{-1}\left(F(u, v) \odot R_{L}(u, v)\right) Ilow(x,y)=T−1(F(u,v)⊙RL(u,v)).
- 掩码处理与特征抑制:为实现对自然特征的定向平滑,改进高斯模糊函数,通过阈值操作选择富含自然特征的区域生成掩码 M ( i , j ) M(i,j) M(i,j),公式为 τ = μ l o w + γ σ l o w \tau=\mu_{low }+\gamma \sigma_{low } τ=μlow+γσlow, M ( i , j ) : = { 1 , i f ∣ I l o w ( x , y ) ∣ > τ 0 , o t h e r w i s e M(i, j):=\left\{\begin{array}{l} 1, if \left|I_{l o w}(x, y)\right|>\tau \\ 0, otherwise \end{array}\right. M(i,j):={1,if∣Ilow(x,y)∣>τ0,otherwise,其中 μ l o w \mu_{low } μlow 和 σ l o w \sigma_{low } σlow 是 I l o w I_{low } Ilow 的均值和标准差, γ \gamma γ 是控制阈值的经验权重。最后根据掩码抑制自然特征,得到抑制后的图像 I s = H ( I ) = M ⊙ C ( I , G σ ) + ( 1 − M ) ⊙ I I_{s}=\mathcal{H}(I)=M \odot \mathcal{C}\left(I, G_{\sigma}\right)+(1-M) \odot I Is=H(I)=M⊙C(I,Gσ)+(1−M)⊙I,其中 C \mathcal{C} C 是二维卷积, G σ G_{\sigma} Gσ 是由标准差参数 σ \sigma σ 确定的高斯核。
- 策略效果:在推理过程中利用特征屏蔽模块 H ( ⋅ ) H(\cdot) H(⋅),以统一方式抑制自然特征,使检测器更易识别NAPs,提升模型的泛化性能。
泛化对抗图块数据集-Generalized Adversarial Patch Dataset
这部分主要介绍了泛化对抗图块数据集(GAP),包括其构建原则和数据属性,为后续的对抗图块检测研究提供了重要的评估基准,具体内容如下:
- 构建原则
- 数据合法性:数据集中所有图像和对抗图块均来自公开数据集和已发表论文,严格遵守数据合法性规定。其中图像来源于INRIA-Person和MS COCO数据集的测试集。
- 广泛多样性:GAP数据集包含来自8种方法的25种不同对抗补丁,其中15种为NAPs,10种为Non-NAPs。这些补丁类型丰富,能全面评估模型在各类对抗图块上的泛化性能。
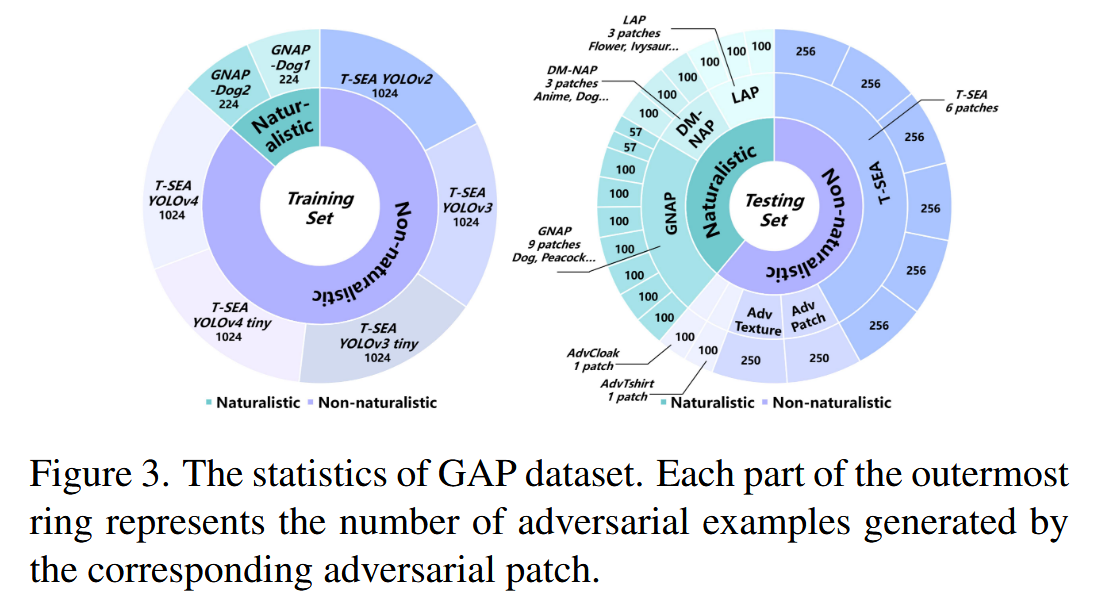
图3. GAP数据集的统计信息。最外环的每一部分代表由相应对抗补丁生成的对抗样本数量。 - 专业注释:数据集中的对抗图块均经过专业标注,确保标注准确可靠,为评估对抗图块检测方法提供了高质量的资源。
- 明确任务:数据集的构建紧密围绕待解决的具体问题,为更好地评估模型对NAPs的泛化检测能力,根据泛化性能将测试集分为三个子集,分别命名为Generalization Level 1(GL1)、Generalization Level 2(GL2)和Generalization Level 3(GL3),等级越高表示泛化性能越差。
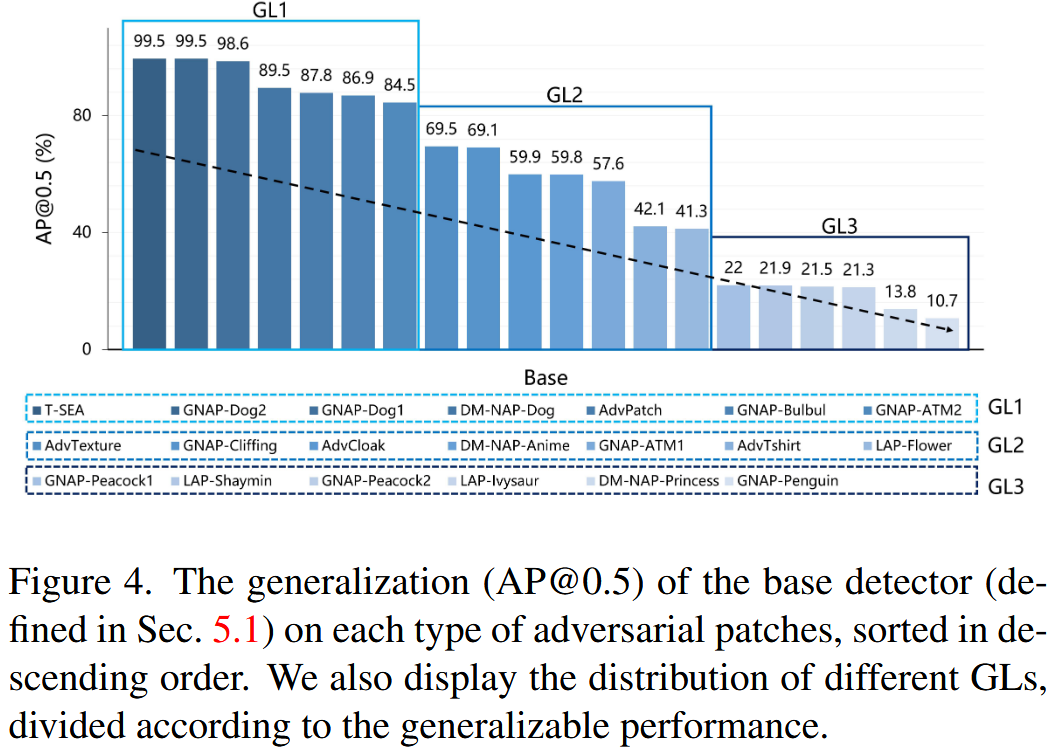
图4. 基础检测器对每种对抗补丁的泛化能力(AP@0.5),按降序排列。我们还展示了根据泛化性能划分的不同泛化等级(GLs)的分布情况。
- 数据属性:GAP数据集共包含9266张图像和25种对抗图块,每个对抗图块都有边界框标注。数据集中图像均以PNG格式存储,通过填充或调整大小为固定的416×416像素。数据集按6:4的比例划分为训练集(5617张图像)和测试集(3649张图像),这种划分方式是为了在测试集中涵盖更多样的对抗图块,以全面评估模型的泛化性能。
实验结果-Experimental Results
实验设置-Experimental Settings
这部分主要介绍了实验设置,涵盖模型与数据集的选择、对比基线的确定以及详细的实验参数设定,为后续实验结果的准确性和可靠性提供保障,具体内容如下:
- 模型与数据集:实验基于所构建的GAP数据集进行。模型方面,将常用的目标检测模型YOLOv5转换为单类模型,并在GAP数据集上进行训练,得到用于检测对抗补丁的模型。其中,“Base”模型是直接在GAP数据集上训练的图块检测器,作为实验的基线模型。评估指标选取检测任务中广泛使用的平均精度(AP@0.5),该指标能同时反映交并比(IoU)和精度信息。
- 对比基线:选择了几种当前先进的对抗图块防御方法作为对比基线,包括LGS、Ad - YOLO、APE、SAC和PatchZero。针对不同方法的特点进行相应处理:Ad - YOLO与本文方法类似,将任务视为目标检测任务,使用YOLOv5作为网络架构,并在调整后的GAP数据集上训练;LGS作为图像分析方法,设置其块大小为15、重叠为5、阈值为0.17、平滑因子为2.3,直接在GAP数据集上评估;APE保持原始设置在GAP数据集上评估;SAC和PatchZero因需要像素级注释的图像分割数据集,与GAP数据集不匹配,故使用原始设置进行训练,对于生成掩码的方法,将生成的掩码转换为边界框来计算AP@0.5。
- 详细实验设置:训练过程中,经验性地设定 α = 0.4 \alpha = 0.4 α=0.4, β = 10 \beta = 10 β=10,使用随机梯度下降(SGD)优化器,初始学习率为0.01,动量值为0.937,权重衰减为0.0005,批处理大小为16,检测器最多训练200个epoch。推理阶段,经验性地设定 γ = 2 \gamma = 2 γ=2 ,3×3高斯核的标准差 σ = 3 \sigma = 3 σ=3,圆形低通滤波器 R L R_{L} RL 的半径设置为图像宽度的四分之一。所有代码基于Python 3.7,使用PyTorch框架实现,实验在NVIDIA GeForce RTX 2080Ti GPU集群上进行。
针对对抗图块的检测性能-Detection Performance on Adversarial Patches
这部分主要评估了NAPGuard方法在对抗补丁检测上的性能,通过与基线方法对比,展示了该方法在检测NAPs和Non-NAPs时的优势,具体内容如下:
-
评估方式:将测试集按攻击方法划分为8个子集,对NAPGuard与基线方法的检测结果进行可视化(见图5),并以AP@0.5为指标进行详细评估(见表1)。

图5. 我们提出的方法与对比基线的检测结果。(a):从GAP数据集中采样的原始对抗样本。(b)和(h):LGS方法及其掩码。(c)和(i):SAC方法及其掩码。(d)和(j):PatchZero方法及其掩码。(e)和(k):APE方法及其掩码。(f):Ad-YOLO方法。(g):基础检测器。(l):我们的方法。我们的NAPGuard能够精确检测自然对抗图块(NAPs),效果最佳。
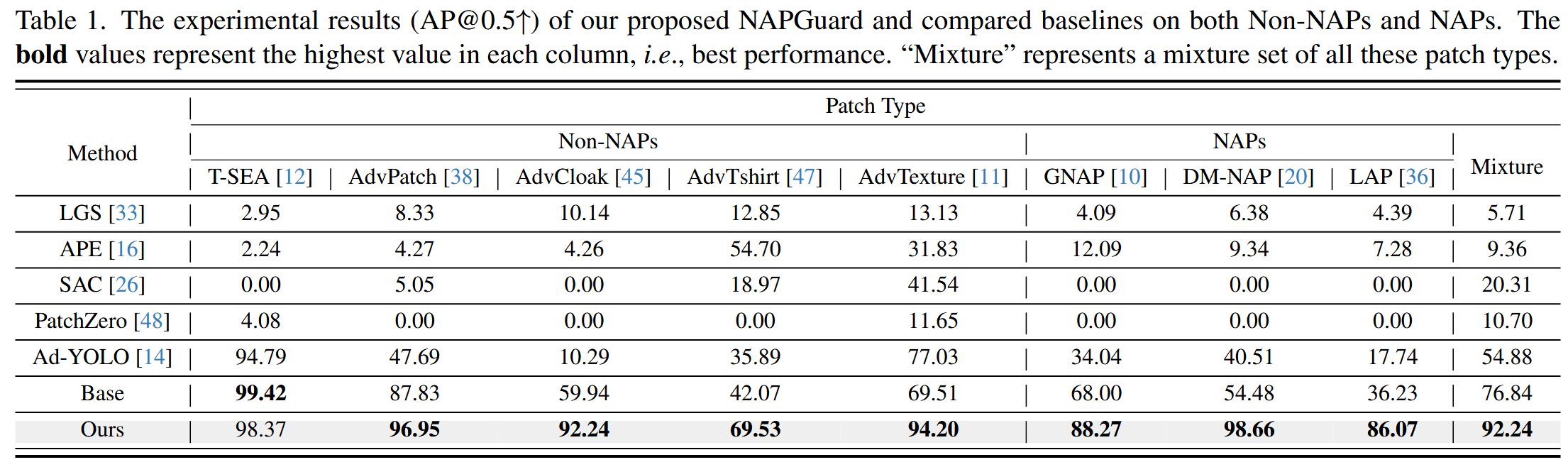
表1. 我们提出的NAPGuard与对比基线方法在非自然对抗图块(Non-NAPs)和自然对抗图块(NAPs)上的实验结果(AP@0.5)。加粗值表示每列中的最高值,即最佳性能。“混合”代表所有这些补丁类型的混合集。
-
NAPs检测结果:相比基础检测器,NAPGuard在NAPs检测上性能显著提升,平均提高38.10%。例如在DM-NAP和LAP上,泛化性能分别提升44.18%和49.84%。与基线方法相比,NAPGuard优势明显,平均AP@0.5提升60.24%。而LGS和APE在非补丁区域生成大量掩码,导致精度受限,NAPs平均AP@0.5仅4.95%;SAC和PatchZero在检测Non-NAPs时有一定效果,但受NAPs欺骗性外观影响,难以泛化到NAPs检测;Ad-YOLO在GAP调整数据集上训练,虽能检测其他类别,但在NAPs上平均AP@0.5仅30.76%,低于基础检测器的52.09%,原因是其学习过程包含多种类别,影响了对攻击模式的准确捕捉。相比之下,NAPGuard在NAPs检测上平均AP@0.5最高,达91.00%。
-
Non-NAPs检测结果:在Non-NAPs检测方面,NAPGuard较基础检测器也有显著改进,如在AdvCloak和AdvTshirt上分别提升32.30%和27.46%,表明该方法对Non-NAPs同样有效且具有强泛化能力。
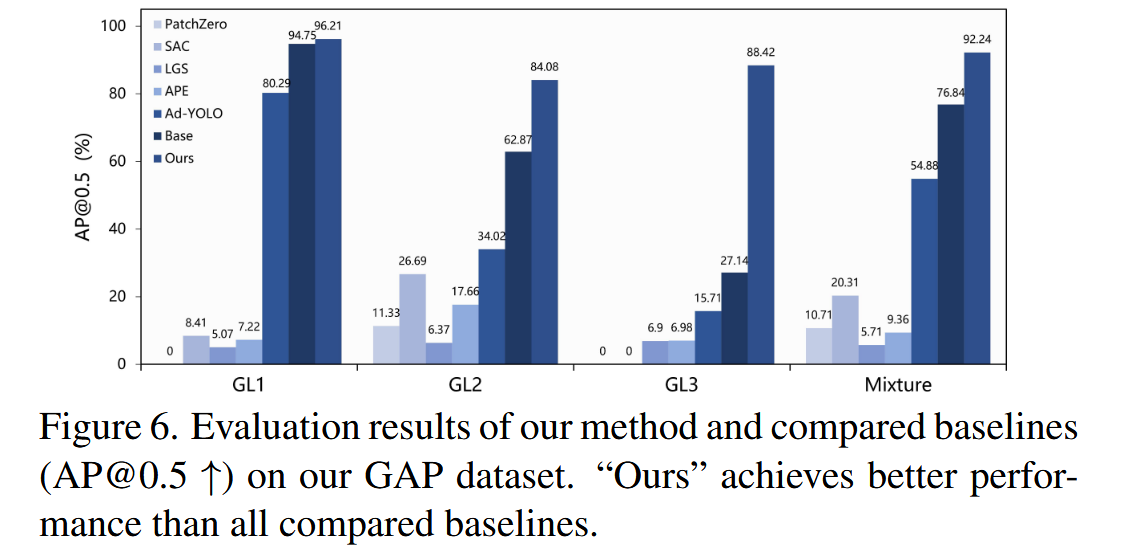
图6. 我们的方法与对比基线在GAP数据集上的评估结果(AP@0.5)。“我们的方法”比所有对比基线表现更优。 -
综合性能:NAPGuard在NAPs、Non-NAPs及混合数据集上均表现出色,平均AP@0.5分别为91.00%、90.26%和92.24%,大幅超越对比的基线方法。
讨论和分析-Discussion and Analysis
这部分主要在GAP数据集上对NAPGuard方法进行了深入评估、对其训练和推理策略展开分析,并提出了一种替代特征屏蔽模块,具体内容如下:
- GAP数据集评估:通过在GAP数据集不同泛化等级(GL)上实验评估方法的泛化性。随着GL增加,检测方法性能显著下降,这证明了GAP数据集在评估泛化性方面的有效性。NAPGuard在泛化性能上表现优异,相比基础检测器,在GL2上提升21.21%,在GL3上提升61.28%,明显优于其他对比方法。
- 训练策略分析:首先验证了对抗补丁的攻击特征主要存在于高频分量。通过对比发现,与非自然对抗样本(Non-NAEs)相比,自然对抗样本(NAEs)的高频分量与干净图像更相似,意味着NAPs与周围环境更接近。从高频域提供可视化证据,表明通过攻击特征对齐学习(AFAL)策略成功增强了对抗补丁与周围环境高频分量的相似性。利用CAM方法对比基础检测器和采用AFAL策略训练的检测器的视觉注意力模式,结果显示AFAL策略成功提升了检测器识别欺骗性补丁中攻击模式的能力。
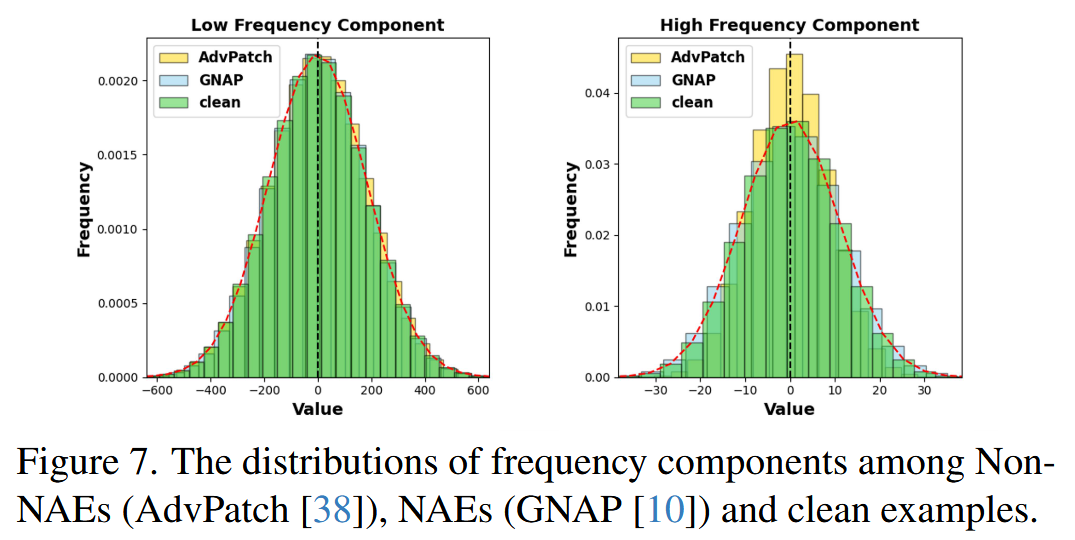
图7. 非自然对抗样本(AdvPatch)、自然对抗样本(GNAP)和干净示例之间的频率分量分布情况。

图9. 攻击特征对齐学习(AFAL)策略实施前后高频分量的可视化结果。
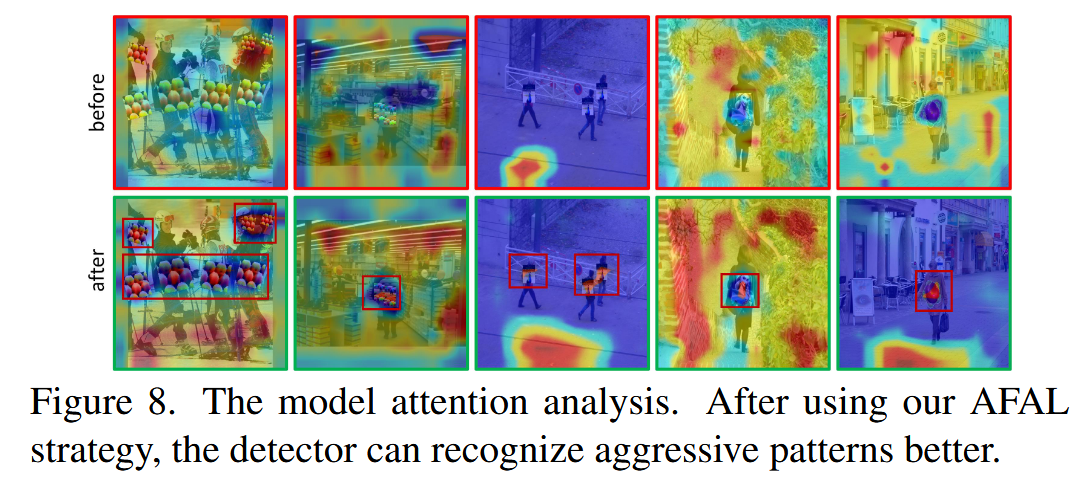
图8. 模型注意力分析。在使用我们的攻击特征对齐学习(AFAL)策略后,检测器能够更好地识别攻击模式。 - 推理策略分析:运用t-SNE方法展示自然特征抑制推理(NFSI)策略的有效性。对基础检测器从NAE(如GNAP)提取的特征在应用NFSI策略前后进行可视化,并与对应干净图像的特征对比。结果表明,应用NFSI策略后,特征与干净图像的偏差更大,说明该策略有效抑制了图像中的自然特征。
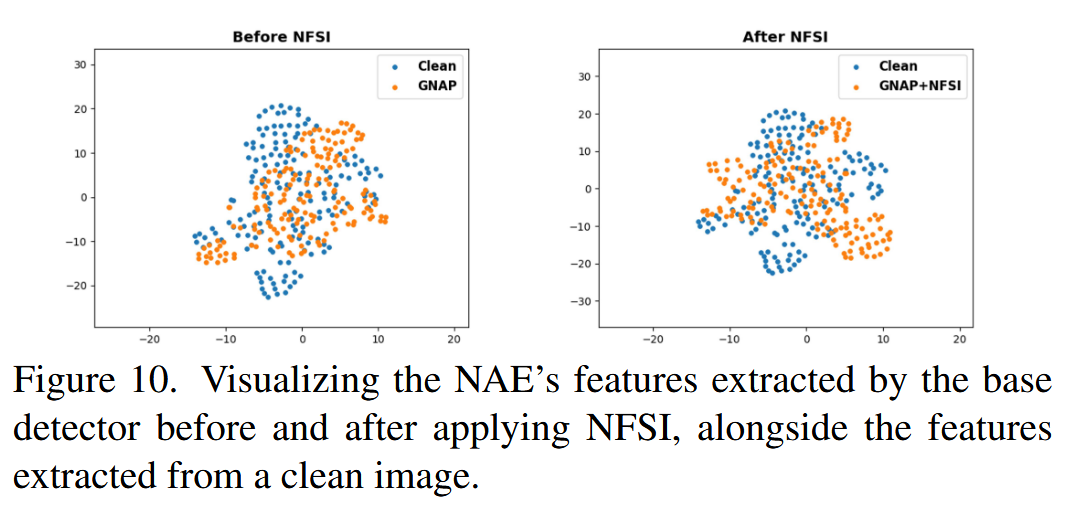
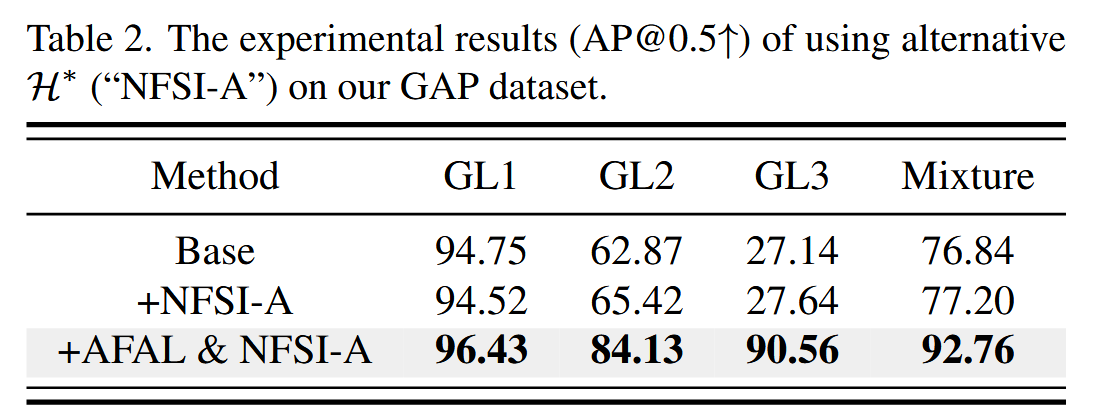
图10. 展示了基础检测器在应用自然特征抑制推理(NFSI)策略前后从自然对抗样本(NAE)中提取的特征,以及从干净图像中提取的特征。 - 替代特征屏蔽模块:在NFSI策略中探索利用高频分量进行区域选择的可能性。将低通滤波器替换为高通滤波器,调整阈值并修改掩码,得到替代模块
H
∗
H^{*}
H∗,相应修改图像抑制公式。在GAP数据集上的实验表明,
H
∗
H^{*}
H∗ 能提升泛化性,在GL2上提升2.55%,与AFAL策略结合时在GL3上提升62.92%,证明其是可行的替代模块。
表2. 在我们的广义对抗补丁数据集(GAP)上使用替代的 H ∗ H^{*} H∗(“自然特征抑制推理 - 替代方案(NFSI - A)”)的实验结果(平均精度,交并比为0.5时的值,即AP@0.5)。
消融研究-Ablation Study
这部分通过消融研究,探究了NAPGuard中不同策略对检测性能的贡献,主要内容如下:
- 研究目的:进一步研究不同策略对模型性能的影响,明确攻击特征对齐学习(AFAL)策略和自然特征抑制推理(NFSI)策略在检测自然对抗图块(NAPs)过程中的具体贡献。
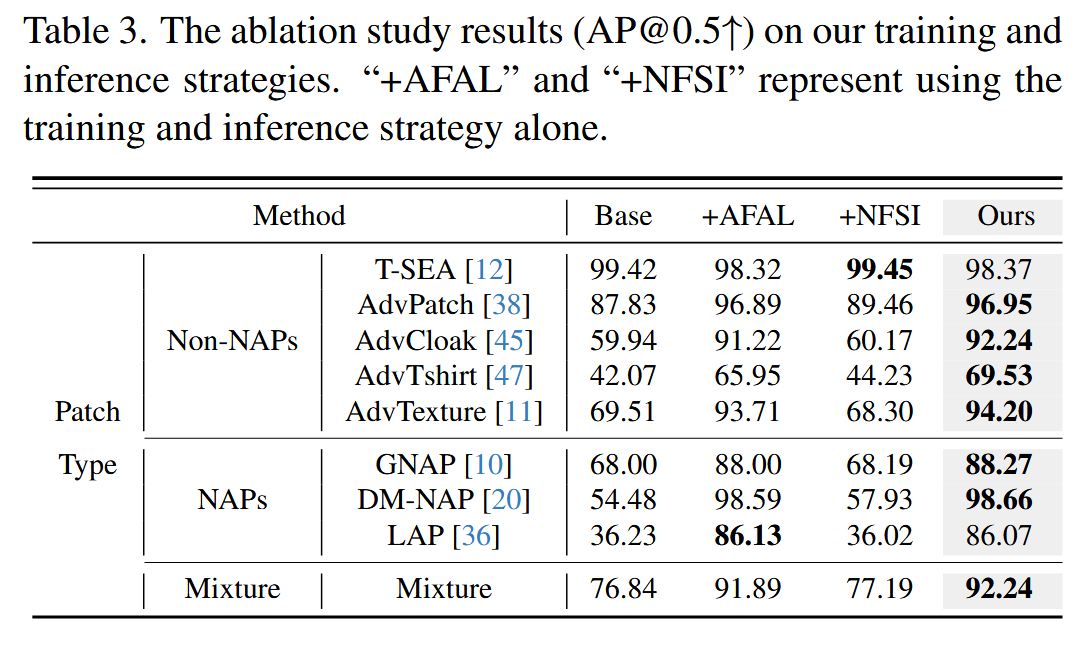
- 研究方法与结果:通过对比不同策略组合下模型在NAPs和Non - NAPs检测任务中的平均精度(AP@0.5)指标变化,分析各策略作用。实验结果显示,AFAL策略对提升检测精度效果显著,在NAPs检测上AP@0.5提升了38.01%;NFSI策略对提升泛化能力有一定作用,在Non - NAPs和NAPs检测上,AP@0.5分别提升了0.56%和1.14%。当两种策略结合时,模型性能进一步提升,这表明两种策略具有协同效应。此外,还对不同损失项和超参数选择进行了消融研究。
表3. 关于我们的训练和推理策略的消融研究结果(平均精度,交并比为0.5时的值,即AP@0.5)。“+攻击特征对齐学习(AFAL)”和“+自然特征抑制推理(NFSI)”分别表示单独使用训练策略和推理策略。
结论-Conclusion
这部分主要总结了研究成果、指出框架存在的局限,并对未来研究方向进行了展望,具体内容如下:
- 研究成果总结:提出NAPGuard框架,通过在训练和推理过程中分别对攻击特征和自然特征进行定向调制,有效检测自然对抗图块(NAPs)。构建首个广义对抗补丁检测(GAP)数据集,推动了对抗补丁检测的研究。大量实验表明,该方法在NAPs检测上性能卓越,大幅超越现有方法,平均AP@0.5提升60.24%。
- 框架局限性:尽管NAPGuard框架取得了显著成果,但仍存在一定局限性。
- 未来研究方向:计划将NAPGuard框架应用于多种模型,进一步扩展GAP数据集,构建该领域更全面的基准。探索框架在现实场景中的检测能力,评估其鲁棒性。尝试将NAPGuard框架作为现有防御方法(如图像去噪)的预处理步骤,提升整体防御效果。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











