







Rethinking the Self-Attention in Vision Transformers

本文对视觉 Transformer 中自注意力机制进行研究。通过分析发现其在图像(ImageNet1K)和视频(Kinetics-400)理解的推理中极为稀疏。提出用掩码机制对注意力图计算进行稀疏化处理,介绍了 6 种掩码模式生成方法。实验表明,手动设计或数据驱动的掩码优于随机掩码,且视觉 Transformer 模型在 95% 稀疏度下性能损失小于 2 点,但当前掩码模型的 FLOPs 减少存在上限,在 DeiT-base 和 TimeSFormer ST 中分别最多为 4% 和 25% 。
摘要-Abstract
Self-attention is a corner stone for transformer models. However, our analysis shows that self-attention in vision transformer inference is extremely sparse. When applying a sparsity constraint, our experiments on image (ImageNet1K) and video (Kinetics-400) understanding show we can achieve 95% sparsity on the self-attention maps while maintaining the performance drop to be less than 2 points. This motivates us to rethink the role of self-attention in vision transformer models.
自注意力机制是 Transformer 模型的基石。然而,我们的分析表明,视觉Transformer在推理过程中的自注意力极为稀疏。在施加稀疏性约束时,我们针对图像(ImageNet1K)和视频(Kinetics-400)理解的实验显示,我们可以在自注意力图上实现 95% 的稀疏度,同时将性能下降控制在 2 个百分点以内。这促使我们重新思考自注意力机制在视觉 Transformer 模型中的作用。
引言-Introduction
这部分内容主要介绍了研究背景和研究目的。
- 研究背景:Transformer 在自然语言处理领域取得成功后,被应用于计算机视觉领域,在图像分类(如 ViT)和动作分类(如 TimeSFormer )等任务中取得了不错的成果。但自注意力机制存在可扩展性问题,其计算复杂度与 token 数量呈二次方关系,处理视频输入时,由于增加了时间维度,浮点运算次数(FLOPs)会大幅增加。
- 研究目的:提出在注意力图计算中应用掩码机制,使元素比较稀疏化。基于早期层中一些 Transformer 头倾向于关注局部区域而非全局的观察,计算所有比较元素的相似性分数会造成计算资源浪费。通过找到最优掩码模式(高掩码/稀疏率),在最小化性能损失的同时降低计算量。实验表明,基于数据驱动的掩码的 ViT 模型即使在稀疏率为 95% 的情况下,性能损失也能保持在 2 点以内。
ViT 自注意力机制分析-Analysis on the self-attention of ViTs
该部分主要对视觉 Transformer(ViT)的自注意力机制进行分析,分别从图像分类模型和视频分类模型入手,通过计算平均注意力图得出了一系列重要结论。
- 图像分类模型分析:选用在 ImageNet-1K 上预训练的 DeiT-Base 模型,对 128 万个训练样本计算平均注意力图。结果发现注意力图很稀疏,且存在三种不同类型的注意力模式:
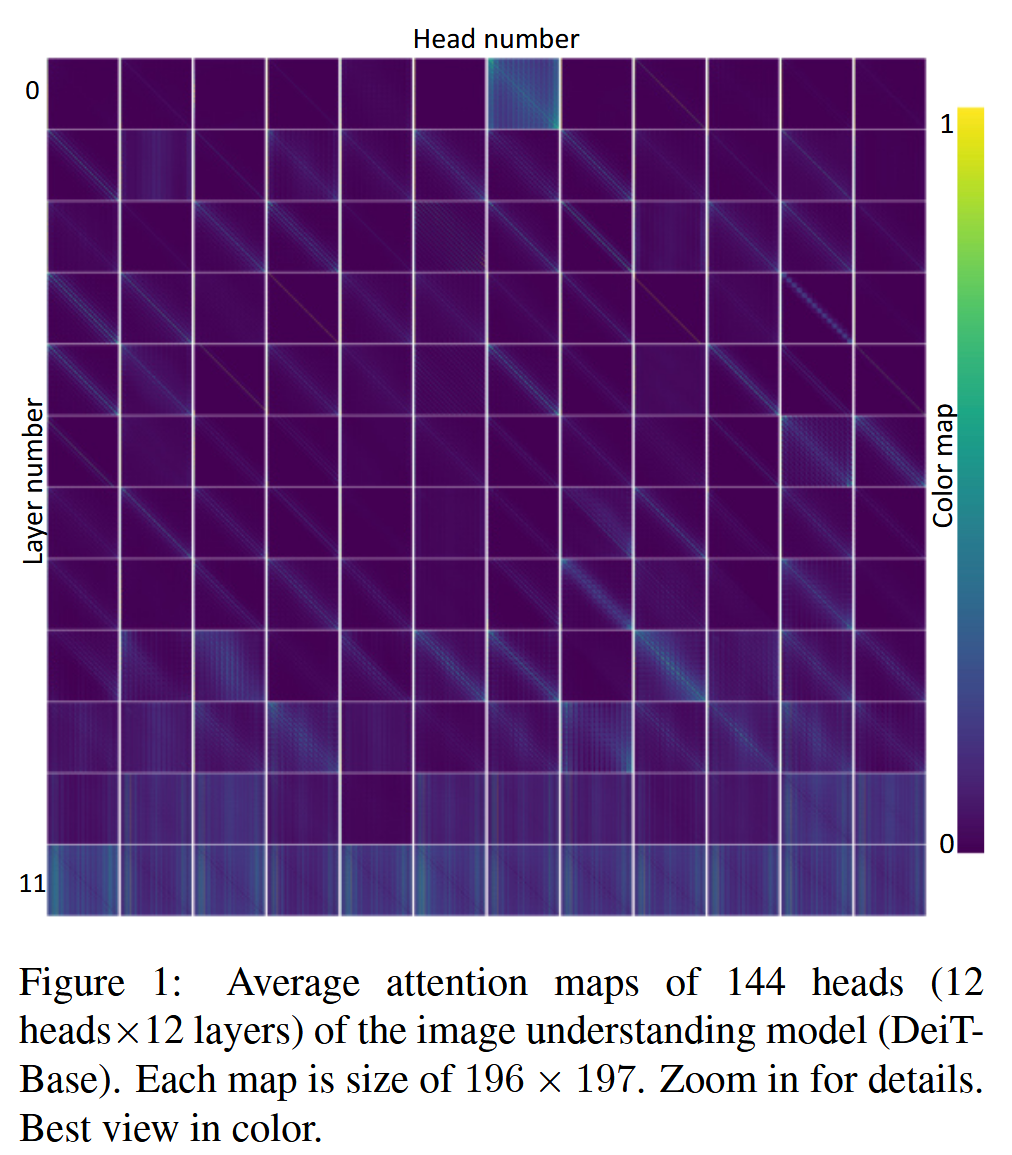
图1:图像理解模型(DeiT-Base)144 个头(12 个头×12 层)的平均注意力图。每张图的大小为 196×197。请放大查看细节,彩色查看效果最佳。- 基于相对位置的注意力:以 Head 4-2 和 1-7 为例,Head 4-2 专门关注下方的 token,当下方无 token 时则关注 cls token;Head 1-7 呈现类似卷积的模式,在水平和垂直邻域有高激活分数,这类注意力通常关注查询附近的局部区域,产生稀疏的注意力图。
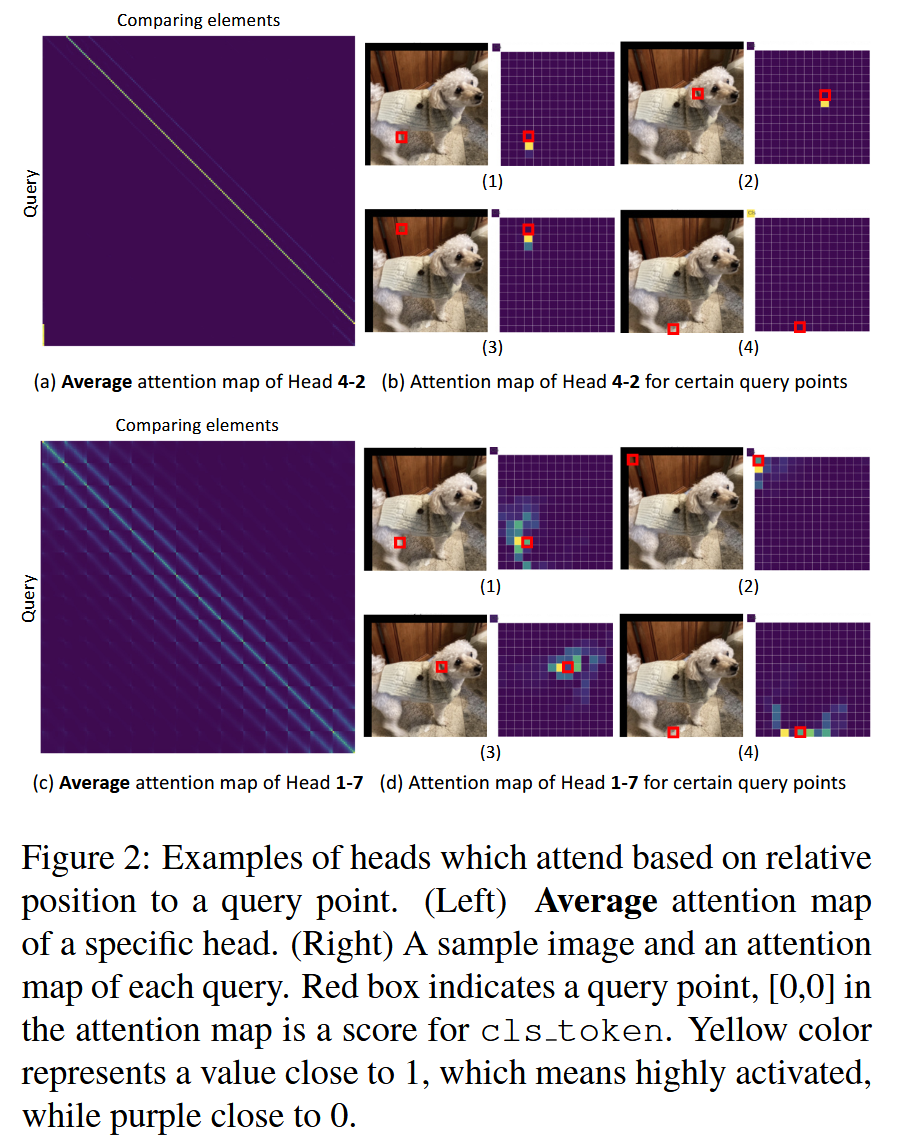
图2:基于相对于查询点的相对位置进行关注的头的示例。(左)特定头的平均注意力图。(右)一个样本图像以及每个查询的注意力图。红色框表示查询点,注意力图中的 [0,0] 是 cls token 的分数。黄色表示值接近 1,意味着高度激活,而紫色接近 0。 - 基于绝对位置的注意力:如 Head 0-7,所有查询对特定 token(cls token)都有极高的激活分数,这是因为 ViT 模型中每个 token 都添加了位置嵌入,所以可以识别特定位置的 token 并赋予高分。
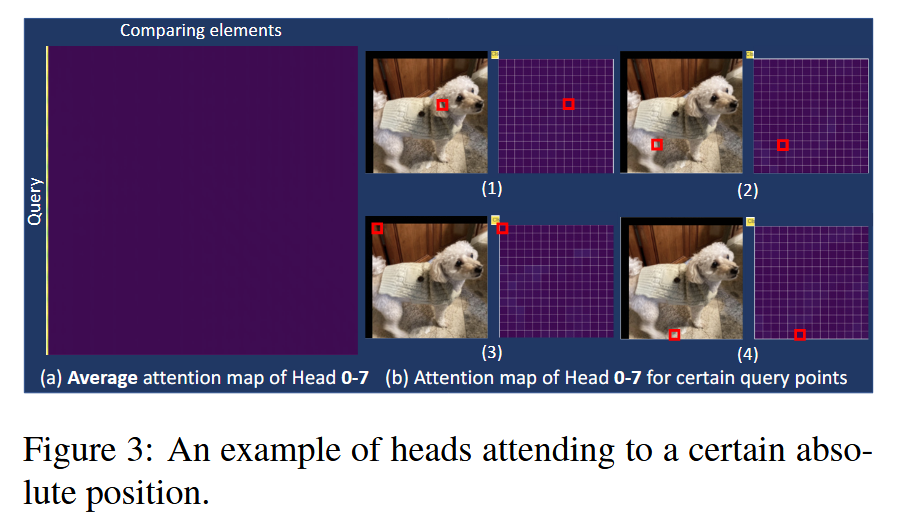
图3:关注特定绝对位置的头的示例。 - 内容基于的注意力:Head 9-1 的查询在显著物体附近有高激活分数,有些查询关注整个物体,有些关注物体特定部分,平均注意力图的分数在较广的 token 范围内分布,而非集中在局部稀疏区域。

图4:基于内容进行关注的头的示例。
- 基于相对位置的注意力:以 Head 4-2 和 1-7 为例,Head 4-2 专门关注下方的 token,当下方无 token 时则关注 cls token;Head 1-7 呈现类似卷积的模式,在水平和垂直邻域有高激活分数,这类注意力通常关注查询附近的局部区域,产生稀疏的注意力图。
- 视频分类模型分析:采用在 Kinetics-400 上预训练的 TimeSFormer (ST) 模型,由于视频模型有时间维度,token 数量更多。为便于分析,分别展示空间和时间维度的注意力图分布,通过对特定维度进行求和与平均运算来降低维度。
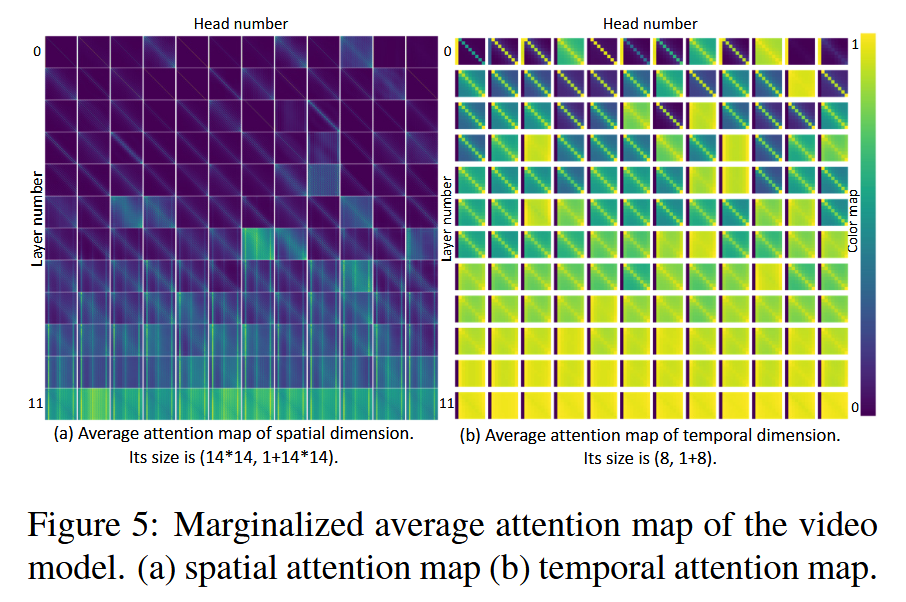
图5:视频模型的边缘化平均注意力图。(a) 空间注意力图 (b) 时间注意力图。 - 综合观察结论:多数注意力图稀疏,早期层的头倾向于关注局部稀疏区域,随着层数加深逐渐全局关注;发现相对位置基于的注意力、绝对位置基于的注意力和推测为基于内容的密集注意力这几种模式,早期层的头呈现类似卷积模式或在特定绝对位置有高激活分数,深层的头大多基于内容关注,且关注区域分散在图像中。
注意力图上的掩码机制-Mask Mechanism on Attention Map
这部分内容主要介绍了在注意力图上应用掩码机制的原因、面临的设计挑战,以及具体的六种掩码模式生成方法。
- 掩码机制应用原因:Transformer 的全注意力机制需要对 token 进行成对比较,计算量与 token 数量呈二次方关系,在处理高分辨率图像或长视频时计算成本极高。而前面分析发现很多注意力图,尤其是早期层的注意力图具有高稀疏性,意味着成对比较在多数情况下并非必要,是对计算资源的浪费,因此可以通过掩码机制在注意力图中显式地引入稀疏性约束。
- 设计挑战:一是生成最优掩码模式并非易事;二是需要对掩码模式的稀疏率进行微调,以实现理想的精度 - 效率权衡。
- 掩码模式生成方法
- 随机掩码生成:按照特定的稀疏率 S S S 随机生成掩码图,每个头的掩码图不同。
- 结构化掩码生成:生成类似 1/2/3D 卷积的掩码图,所有头共享该掩码图。
- 基于数据驱动的比率掩码生成:依据截止稀疏率 S S S 生成掩码。如当 S S S 和 token 数量确定时,每个查询基于平均相似性分数选择固定数量的比较元素。
- 基于数据驱动的幅度掩码生成:根据 top-1 注意力分数确定选择元素的数量。通过对 top-1 注意力分数 A A A 进行处理(如 A ′ = c l i p ( ( A + τ ) , m i n = 1 / ( 1 + T H W ) , m a x = 1 A' = clip((A + τ), min = 1/(1 + THW), max = 1 A′=clip((A+τ),min=1/(1+THW),max=1) ,其中 τ τ τ 为温度因子),进而确定选择 1 / A ′ 1/A' 1/A′ 个元素。
- 基于数据驱动的信息掩码生成:当排序后的相似性分数累积和等于或大于信息数量 I I I 时截止选择,每个查询选择的元素数量不同。
- 基于数据驱动的标准差掩码生成:计算每个查询相似性向量的均值 m m m 和标准差 σ σ σ,选择值大于等于 m + C σ m + Cσ m+Cσ( C C C 为 sigma 系数)的比较元素。后三种基于数据驱动的方法,每个查询选择的比较元素数量不同,在确定保留的比较元素数量时会考虑稀疏程度。
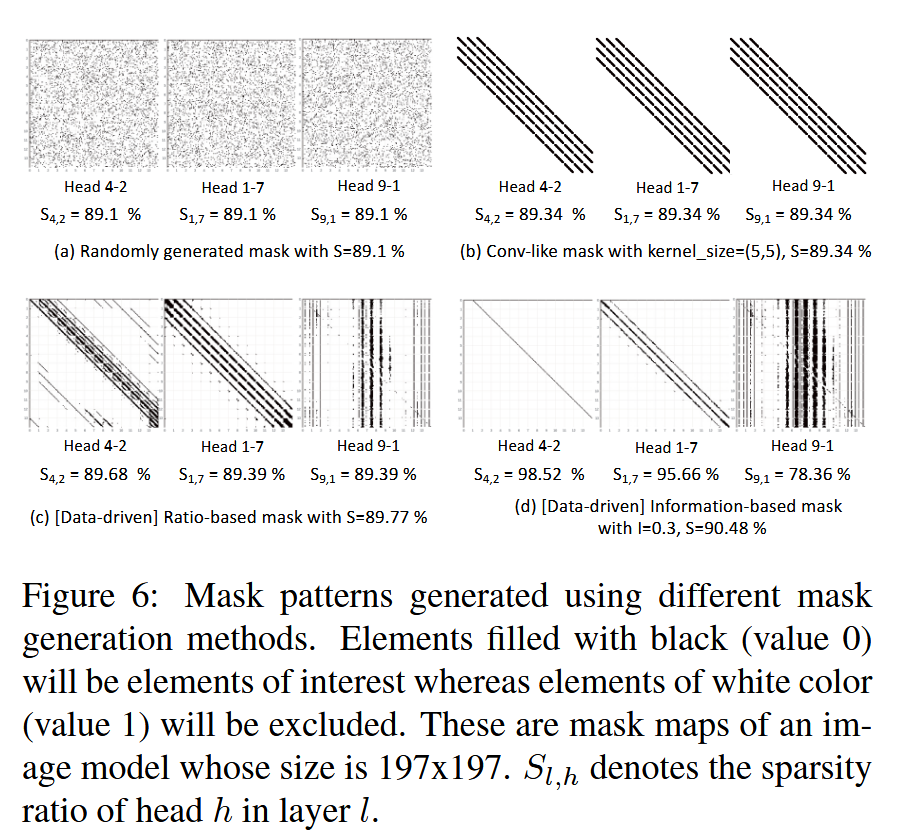
图6:使用不同掩码生成方法生成的掩码模式。黑色填充的元素(值为 0)是关注元素,而白色元素(值为 1)将被排除。这些是尺寸为 197×197 的图像模型的掩码图。
S
l
,
h
S_{l, h}
Sl,h 表示第
l
l
l 层中第
h
h
h 个头的稀疏率。
实验-Experiments
这部分主要展示了对不同掩码生成方法下掩码 ViT 模型的实验结果,通过对比分析得出了重要结论,具体如下:
- 实验设置:在训练掩码图像模型时,以 ImageNet-1K 预训练权重为基础,结合掩码对权重进行微调;对于视频模型(包括未使用掩码的模型),以 ImageNet-21K 预训练权重为起点,按照特定方式微调 30 个 epoch。
- 实验结果分析
- 掩码效果对比:手动设计或数据驱动的掩码在性能上优于随机生成的掩码。这一结果表明自注意力机制的运行存在特定模式,随机掩码破坏了这些模式,进而导致模型性能下降。
- 数据驱动掩码比较:不同数据驱动的掩码在性能上差异较小。其中,基于信息的掩码在各项数据驱动掩码中,似乎略微占据优势,但这种优势并不明显。
- 稀疏率与性能关系:使用掩码的 ViT 模型即便在稀疏率高达 95% 的情况下,性能损失仍能控制在小于 2 点。这意味着在实际运行中,当 token 数量为 197 时,注意力机制平均仅使用 9 个 token 进行计算,说明稀疏注意力机制在一定程度上能够保留原始模型的表达能力,保证模型性能。
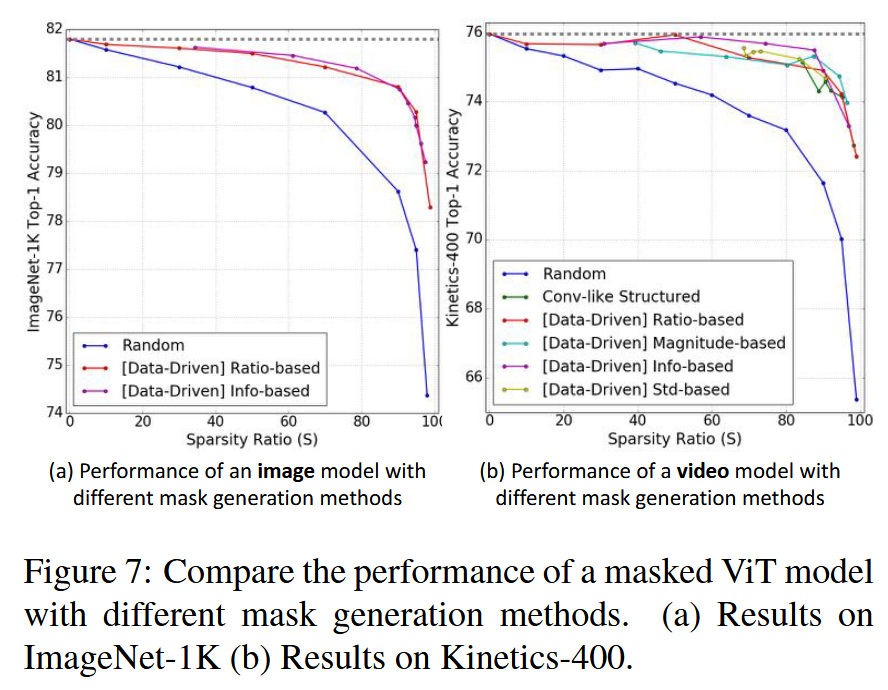
图7:比较不同掩码生成方法下掩码视觉 Transformer (ViT) 模型的性能。(a) 在ImageNet-1K上的结果 ; (b) 在 Kinetics-400 上的结果。
局限性-Limitation
该部分主要讨论了当前带掩码模型存在的局限性,即模型在 FLOPs(浮点运算次数)减少方面存在上限,且该上限不够大。具体内容如下:
- FLOPs 减少上限情况:通过表格展示了单个 Transformer 模块的 FLOP 计算以及特定模型配置下的实际 GFLOPs。在 DeiT-base 和 TimeSFormer ST 模型中,能从掩码机制受益的 “注意力图计算” 和 “加权和计算” 部分,分别仅占总计算量的 4% 和 25%。这表明在这两个模型中,通过掩码机制所能实现的最大 FLOPs 减少比例分别为 4% 和 25%。
- 存在上限的原因:模型中 token 数量远小于 FFN(前馈神经网络)中的通道维度。例如在上述两个模型中,token 数量为 197 或 1569,而 dim MLP(FFN 中多层感知机的维度)为 3072 。这种数量差异使得在 ViT 模型中,当 num_tokens < dim_MLP 时,调整 FFN 部分(如 dim MLP)成为控制总 FLOPs 的有效方法,而掩码机制的作用相对受限。
- 掩码机制的应用前景:掩码机制在 token 数量较大时可能会更有效。因为当前模型中 token 数量与 FFN 通道维度的差异限制了掩码机制对 FLOPs 的优化效果,所以从理论上讲,当 token 数量增大时,掩码机制能发挥更大作用,更有效地减少模型计算量。
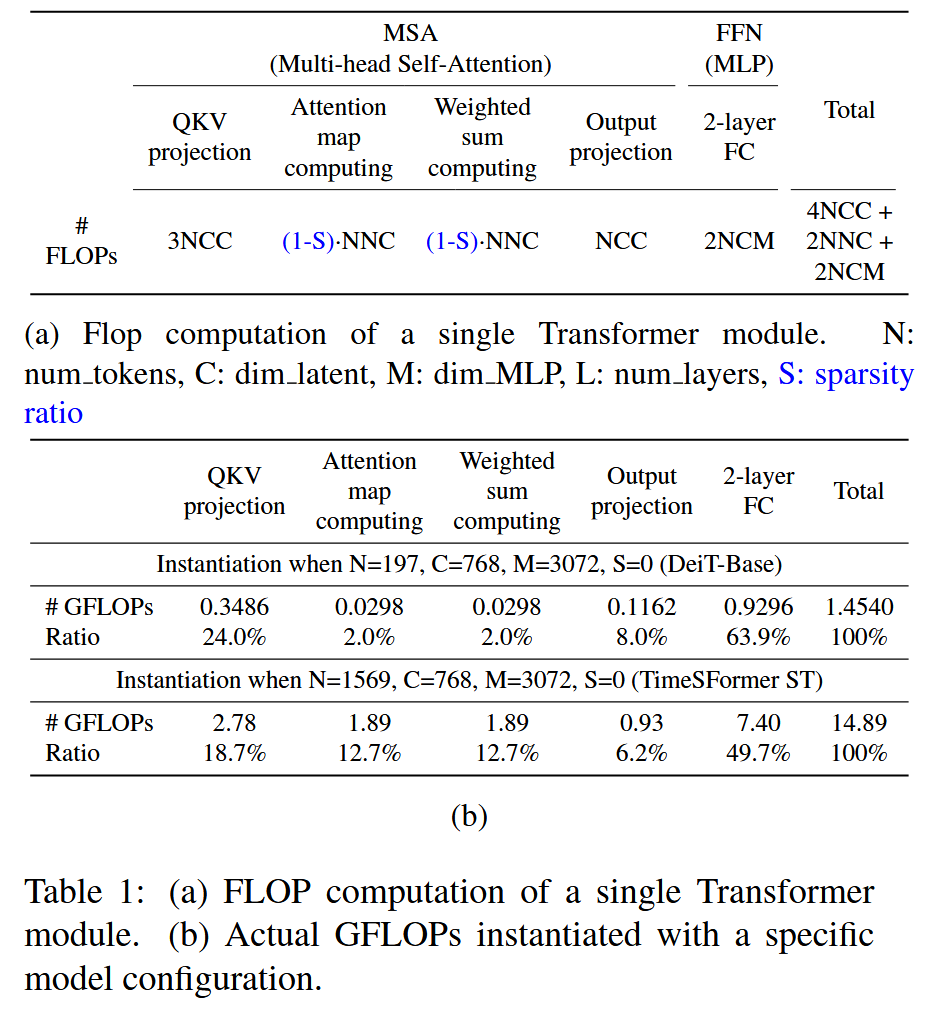
表1:(a) 单个 Transformer 模块的浮点运算次数(FLOP)计算。(b) 特定模型配置下的实际十亿次浮点运算次数(GFLOP)。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











