







Focus on Hiders: Exploring Hidden Threats for Enhancing Adversarial Training
本文 “Focus on Hiders: Exploring Hidden Threats for Enhancing Adversarial Training”指出传统对抗训练专注于对抗样本存在局限性,提出 “隐藏者(hiders)” 概念,即先前训练中能正确分类或防御,但后续训练中变得脆弱的样本。同时提出聚焦隐藏者的对抗训练算法(HFAT),该算法通过迭代进化优化策略和辅助模型,有效提升模型的鲁棒性和准确性。
速览总结
- 本文提出了 “隐藏者(hiders)” 的概念,指的是对抗训练前期能被正确防御或者分类,而在后期表现不佳的样本,这些样本影响了模型的鲁棒性与准确性;
- 由此提出了聚焦“隐藏者”的对抗训练(HFAT),包括正常对抗训练和辅助模型对抗训练两个分支,迭代过程中综合考虑两个分支的优化方向;
摘要-Abstract
Adversarial training is often formulated as a min-max problem, however, concentrating only on the worst adversarial examples causes alternating repetitive confusion of the model, i.e., previously defended or correctly classified samples are not defensible or accurately classifiable in subsequent adversarial training. We characterize such nonignorable samples as “hiders”, which reveal the hidden high-risk regions within the secure area obtained through adversarial training and prevent the model from finding the real worst cases. We demand the model to prevent hiders when defending against adversarial examples for improving accuracy and robustness simultaneously. By rethinking and redefining the min-max optimization problem for adversarial training, we propose a generalized adversarial training algorithm called Hider-Focused Adversarial Training (HFAT). HFAT introduces the iterative evolution optimization strategy to simplify the optimization problem and employs an auxiliary model to reveal hiders, effectively combining the optimization directions of standard adversarial training and prevention hiders. Furthermore, we introduce an adaptive weighting mechanism that facilitates the model in adaptively adjusting its focus between adversarial examples and hiders during different training periods. We demonstrate the effectiveness of our method based on extensive experiments, and ensure that HFAT can provide higher robustness and accuracy.
对抗训练通常被表述为一个极小极大问题,然而,仅关注最坏的对抗样本会导致模型出现交替重复的混淆情况,即先前在对抗训练中能够被防御或正确分类的样本,在后续的对抗训练中却无法被防御或准确分类。我们将这类不可忽视的样本称为 “隐藏者(hiders)”,它们揭示了通过对抗训练获得的安全区域内隐藏的高风险区域,并且阻碍模型找到真正的最坏情况。我们要求模型在抵御对抗样本的同时防范隐藏者,以同时提高准确性和鲁棒性。通过重新思考和重新定义对抗训练的极小极大优化问题,我们提出了一种广义的对抗训练算法,称为聚焦隐藏者的对抗训练(HFAT)。HFAT引入了迭代进化优化策略来简化优化问题,并使用一个辅助模型来揭示隐藏者,有效地结合了标准对抗训练和防范隐藏者的优化方向。此外,我们引入了一种自适应加权机制,使模型能够在不同的训练阶段自适应地调整其在对抗样本和隐藏者之间的关注重点。我们通过大量实验证明了我们方法的有效性,并确保HFAT能够提供更高的鲁棒性和准确性。
引言-Introduction
这部分内容主要指出传统对抗训练仅关注最坏情况的对抗样本存在问题,进而定义了“隐藏者”,并提出新算法HFAT,具体内容如下:
- 研究背景:深度神经网络(DNNs)易受对抗样本攻击,对抗训练是防御对抗攻击的有效方法。但现有对抗训练方法遵循极小极大优化问题,仅聚焦于最坏情况的对抗样本以获得最优解,忽视了安全区域中潜在的漏洞,导致模型的鲁棒性和准确性受损。
- 问题表现:只关注最坏情况的对抗样本会使模型产生交替重复的混淆,先前成功防御或准确分类的样本在后续训练中变得难以防御或分类。这种现象在所有训练时期普遍存在,且随着时期间隔增加,受影响样本增多,还呈现间歇性,阻碍模型识别真正的最坏情况,影响模型性能。
- 定义与算法:将那些在前一阶段对抗训练中成功防御或正确分类,但在后期表现出强大攻击能力或被误分类的样本定义为“隐藏者”。提出聚焦隐藏者的对抗训练(HFAT)算法,该算法通过防范隐藏者所在的潜在脆弱区域,在抵御对抗样本的同时增强模型的鲁棒性和准确性。
- 具体做法与贡献:重新定义极小极大优化问题,提出迭代进化优化策略简化问题;利用辅助模型揭示隐藏者,整合标准对抗训练和防范隐藏者的优化方向;设计自适应加权机制,动态调整对隐藏者和对抗样本的关注重点。通过这些方法,有效缓解隐藏者带来的潜在威胁,提升模型性能。
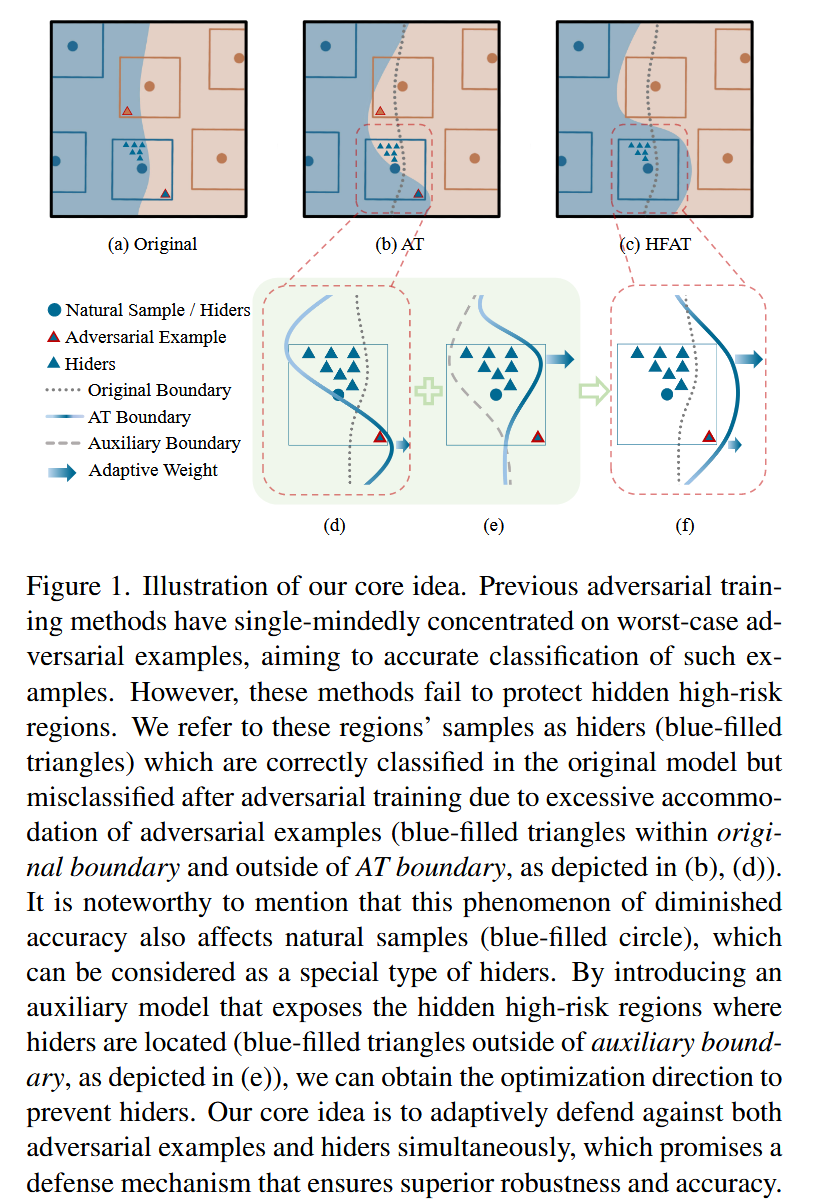
图 1. 我们核心思想的示意图。以往的对抗训练方法一味地专注于最坏情况的对抗样本,旨在对这类样本进行准确分类。然而,这些方法未能保护隐藏的高风险区域。我们将这些区域的样本称为 “隐藏者”(蓝色填充的三角形),它们在原始模型中能被正确分类,但由于在对抗训练中过度适应对抗样本,在训练后被误分类(如(b)、(d)中所示,位于原始边界内且在对抗训练边界外的蓝色填充三角形)。值得注意的是,这种准确率下降的现象也会影响自然样本(蓝色填充的圆形),自然样本可被视为一种特殊类型的隐藏者。通过引入一个辅助模型来暴露隐藏者所在的隐藏高风险区域(如(e)中所示,位于辅助边界外的蓝色填充三角形),我们可以获得防范隐藏者的优化方向。我们的核心思想是同时自适应地抵御对抗样本和隐藏者,这保证了一种防御机制,能够确保卓越的鲁棒性和准确性。
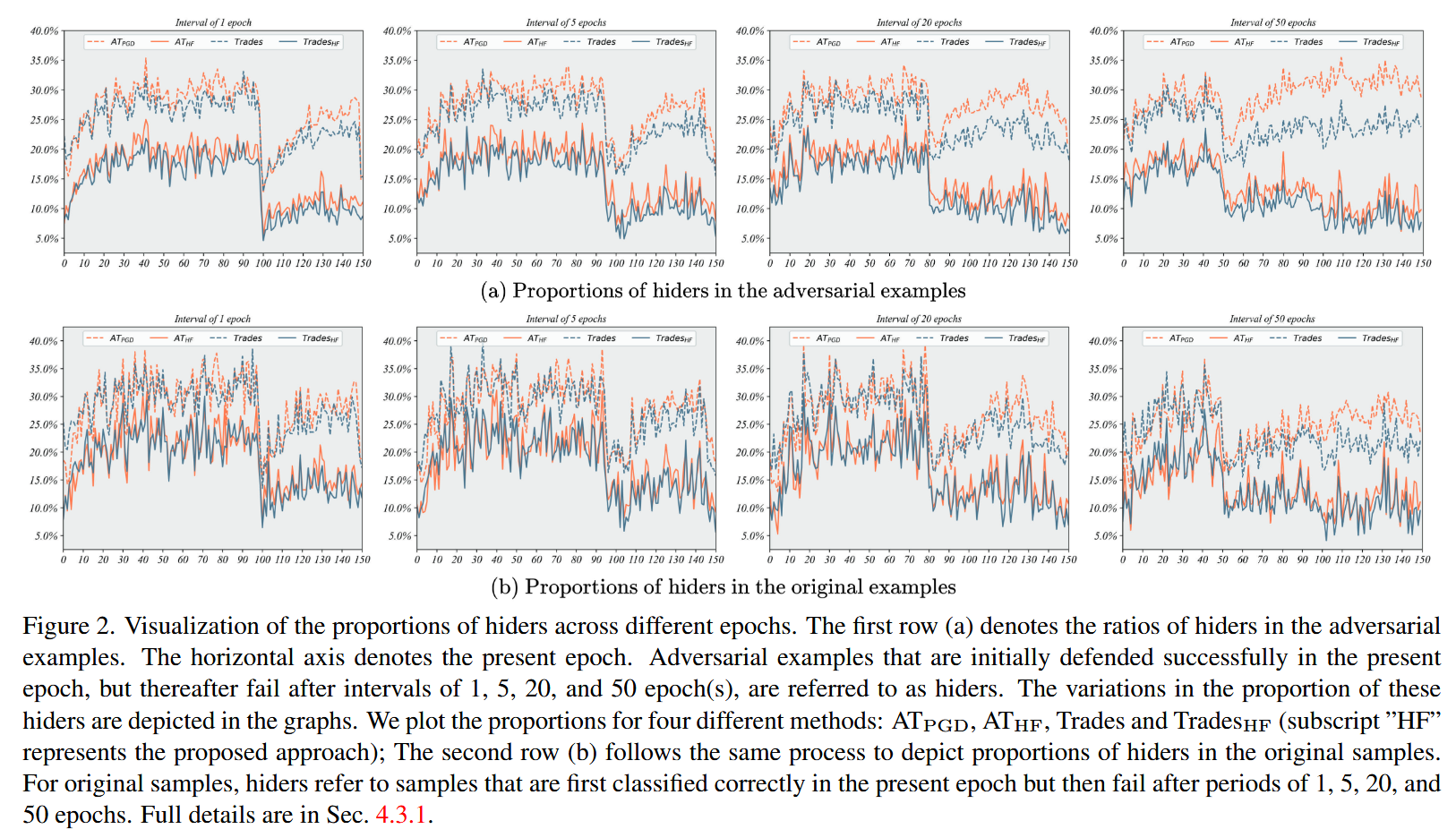
图2. 不同训练轮次中隐藏者比例的可视化。第一行(a)表示对抗样本中隐藏者的比例。横轴表示当前训练轮次。在当前轮次中最初成功防御,但在间隔1轮、5轮、20轮和50轮后防御失败的对抗样本被称为隐藏者。这些隐藏者比例的变化在图中展示。我们绘制了四种不同方法的比例:AT
P
G
D
_{PGD}
PGD、AT
H
F
_{HF}
HF、TRADES和TRADES
H
F
_{HF}
HF(下标“HF”表示本文提出的方法);第二行(b)采用相同的方式描绘原始样本中隐藏者的比例。对于原始样本,隐藏者指的是在当前轮次中最初分类正确,但在1轮、5轮、20轮和50轮后分类失败的样本。详细内容见4.3.1节。
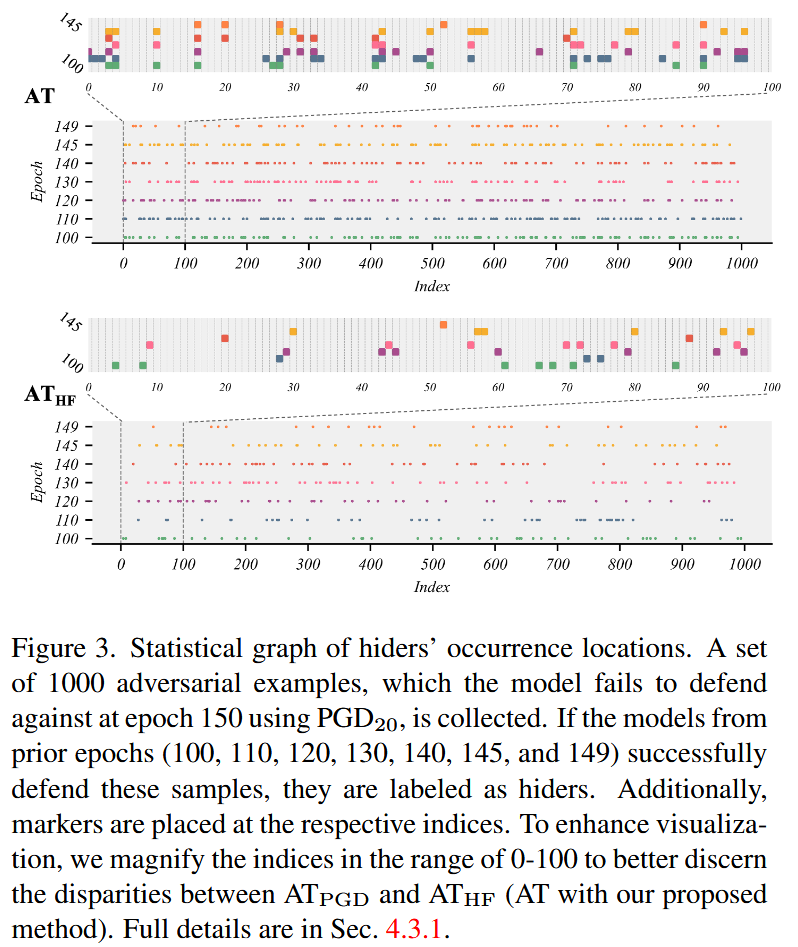
图3. 隐藏者出现位置的统计图。收集了一组1000个对抗样本,模型在第150个训练轮次使用PGD
20
_{20}
20攻击时无法防御这些样本。如果之前轮次(第100、110、120、130、140、145和149轮)的模型成功防御了这些样本,那么这些样本就被标记为隐藏者。此外,还在相应的索引位置放置了标记。为了增强可视化效果,我们将0 - 100范围内的索引进行了放大,以便更好地辨别AT
P
G
D
_{PGD}
PGD和AT
H
F
_{HF}
HF(采用我们所提方法的对抗训练)之间的差异。详细内容见4.3.1节。
背景和相关工作-Background and Related Work
该部分主要介绍了对抗攻击和对抗训练的相关背景知识,具体内容如下:
- 对抗攻击
- 攻击目标:利用模型在决策边界附近的脆弱性,通过对输入引入微小且难以察觉的扰动,使模型产生错误分类或预测。
- 攻击方法:PGD通过迭代优化对抗扰动;C&W以最少的扰动实现模型误分类为目标构建优化问题;MIM通过引入动量项提升传统迭代优化效果;AutoAttack包含多种攻击方法,用于全面评估模型的鲁棒性。这些攻击方法的成功使对抗防御工作意义重大。
- 对抗训练
- 训练方式:是增强深度学习模型对抗攻击鲁棒性的重要方法,通过在训练数据集中加入对抗样本,让模型学习防御对抗威胁,其基于极小极大优化框架。
- 已有方法:许多研究在对抗训练框架下提出了不同方法。Madry等人的 AT P G D _{PGD} PGD 专注提升模型鲁棒性;Rice等人提出的 AT P G D _{PGD} PGD 早期停止变体有显著改进;Zhang等人的TRADES探索标准准确率和对抗鲁棒性之间的权衡;Wu等人的AWP通过研究权重损失景观增强模型鲁棒性;Wang等人的MART改进了对抗样本生成过程;Jia等人的LAS-AT则通过学习自动生成更好的攻击策略提升模型鲁棒性。然而,这些方法都过度强调对抗样本,忽视了安全区域内隐藏的威胁,导致模型受“隐藏者”影响,鲁棒性和准确性受限。
方法-Methodology
隐藏者-Hiders
这部分内容主要对“隐藏者”进行了定义和分析,具体如下:
- “隐藏者”的定义:“隐藏者”揭示了模型决策边界内的隐藏威胁,指在之前对抗训练 epoch 中能正确分类或防御,但在后续 epoch 中无法准确分类或防御的样本,一些自然样本也具有“隐藏者”特征。具体定义为,样本 ( x , y ) (x, y) (x,y) 在当前第 i i i 个 epoch 的“隐藏者” x ^ = x + δ ^ j \hat{x}=x+\hat{\delta}^{j} x^=x+δ^j 满足 D ( f θ i ( x ^ ) ) = y D\left(f_{\theta^{i}}(\hat{x})\right)=y D(fθi(x^))=y 且 D ( f θ j ( x ^ ) ) ≠ y D\left(f_{\theta^{j}}(\hat{x})\right) \neq y D(fθj(x^))=y( i , j ∈ { 1 , 2 , . . . } i, j \in\{1,2, ...\} i,j∈{1,2,...}, j > i j>i j>i),其中 δ ^ j ∈ B ( ϵ ) ∩ S i \hat{\delta}^{j} \in B(\epsilon) \cap S_{i} δ^j∈B(ϵ)∩Si, S i S_{i} Si 是第 i i i 个 epoch 决策边界内部, D D D 是将概率分布 f θ i ( x ^ ) f_{\theta^{i}}(\hat{x}) fθi(x^) 映射到概率最高类别 y y y 的分类函数。对于第 i i i 个 epoch 的模型,还存在最坏情况的“隐藏者” x ^ ∗ = x + δ ^ ∗ \hat{x}^{*}=x+\hat{\delta}^{*} x^∗=x+δ^∗,通过公式 ( j ∗ , δ ^ ∗ ) = a r g m a x j , δ ^ j L C E ( f θ j ( x + δ ^ j ) , y ) \left(j^{*}, \hat{\delta}^{*}\right)=\underset{j, \hat{\delta}^{j}}{argmax} \mathcal{L}_{CE}\left(f_{\theta^{j}}\left(x+\hat{\delta}^{j}\right), y\right) (j∗,δ^∗)=j,δ^jargmaxLCE(fθj(x+δ^j),y) 确定 ,其表示当前决策边界内未来 epoch 中攻击性能上限最高的样本。
- 隐藏者的经验概率分布:“隐藏者”的威胁具有延迟性,难以确定最坏情况的“隐藏者”,且其分布依赖于自然样本和模型。研究发现“隐藏者”与自然样本、对抗样本的相对位置关系在不同对抗训练方法和阶段有显著相似性,因此用高斯分布
G
G
G 对“隐藏者”的相对位置信息进行建模。通过比较“隐藏者”和对抗样本到原始样本的距离得到相对位置比
r
r
r,对多个防御模型的大量样本分析发现,随着 epoch 数增加,生成的“隐藏者”的
r
r
r 的均值和方差也增加,该分布特征具有普遍性,
r
r
r 可作为先验知识辅助防御“隐藏者”.
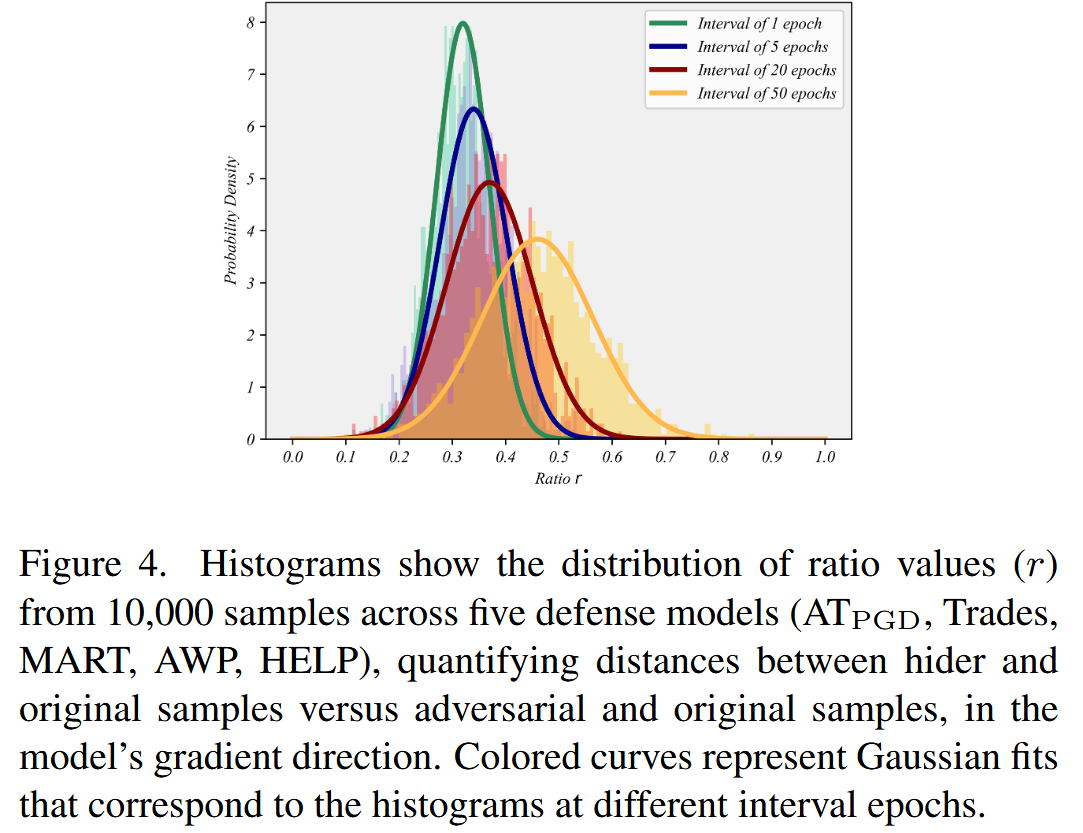
图4展示了来自五个防御模型(AT P G D _{PGD} PGD、TRADES、MART、AWP、HELP)的10000个样本的比率值( r r r)分布直方图,该比率值量化了在模型梯度方向上,隐藏者与原始样本之间的距离和对抗样本与原始样本之间的距离。彩色曲线表示在不同间隔轮次下,与直方图对应的高斯拟合曲线。
聚焦隐藏者的对抗训练-Hider-Focused Adversarial Training (HFAT)
这部分内容主要介绍了聚焦隐藏者的对抗训练(HFAT)算法,包括优化目标、迭代进化优化策略、辅助模型、自适应加权机制和训练策略,具体如下:
- 优化目标:为提升模型的鲁棒性和准确性,HFAT的目标是同时主动防御涉及对抗样本和“隐藏者”的最坏情况,其优化目标可表示为
m i n [ m a x δ ∈ B ( ϵ ) L C E ( f θ i ( x + δ ) , y ) + m a x j , δ ^ j ∈ S i L C E ( f θ j ( x + δ ^ j ) , y ) ] \begin{aligned} min [& max _{\delta \in \mathcal{B}(\epsilon)} \mathcal{L}_{CE} (f_{\theta^{i}}(x+\delta), y)+ \\ & max _{j, \hat{\delta}^{j} \in S^{i}} \mathcal{L}_{CE} (f_{\theta^{j}} (x+\hat{\delta}^{j}), y)] \end{aligned} min[maxδ∈B(ϵ)LCE(fθi(x+δ),y)+maxj,δ^j∈SiLCE(fθj(x+δ^j),y)] 其中前一项针对对抗样本进行优化,后一项用于防范隐藏者的潜在危险, j j j 表示最坏情况的隐藏者在第 j j j 个 epoch 达到最大损失值。 - 迭代进化优化策略:优化目标的第二项需要寻找样本在未来所有 epoch 中的最大损失值,计算复杂。为此提出迭代进化优化策略,根据定理1,可通过仅考虑下一个 epoch 的最坏情况来优化目标,将原优化目标简化为
m i n [ m a x δ ∈ B ( ϵ ) L C E ( f θ i ( x + δ ) , y ) + m a x δ ^ i + 1 ∈ S i L C E ( f θ i + 1 ( x + δ ^ i + 1 ) , y ) ] \begin{aligned} min [& max _{\delta \in \mathcal{B}(\epsilon)} \mathcal{L}_{CE}\left(f_{\theta^{i}}(x+\delta), y\right)+ \\ & max _{\hat{\delta}^{i+1} \in S^{i}} \mathcal{L}_{CE}\left(f_{\theta^{i+1}}\left(x+\hat{\delta}^{i+1}\right), y\right)] \end{aligned} min[maxδ∈B(ϵ)LCE(fθi(x+δ),y)+maxδ^i+1∈SiLCE(fθi+1(x+δ^i+1),y)] 定理1的证明在补充材料中。 - 辅助模型:优化目标的第二项旨在让当前模型防御当前决策边界内的隐藏威胁区域,但直接优化存在困难,因为无法计算该项关于当前模型权重参数
θ
i
\theta^{i}
θi 的导数,且直接用当前模型下隐藏者的损失函数近似会导致传统梯度下降法难以优化。为解决该问题,通过从经验概率分布
G
G
G 中采样得到隐藏者的相对位置比
r
r
r,利用位置变换函数
T
T
T 确定隐藏者最可能出现的区域,通过反向训练得到辅助模型
f
θ
^
f_{\hat{\theta}}
fθ^,公式为
θ
^
i
←
θ
i
+
η
∇
θ
i
L
C
E
(
f
θ
i
(
T
(
x
,
x
a
d
v
,
r
)
)
,
y
)
,
r
∼
G
1
\hat{\theta}^{i} \leftarrow \theta^{i}+\eta \nabla_{\theta^{i}} \mathcal{L}_{CE}\left(f_{\theta^{i}}\left(T\left(x, x_{adv }, r\right)\right), y\right), r \sim G_{1}
θ^i←θi+η∇θiLCE(fθi(T(x,xadv,r)),y),r∼G1,其中
η
\eta
η 为学习率,训练过程中加入少量
ϵ
\epsilon
ϵ 内的噪声增加随机性。对辅助模型进行对抗训练,可得到防御隐藏威胁区域的梯度方向,作为优化目标第二项的近似,引入该梯度方向作为模型
f
θ
i
f_{\theta^{i}}
fθi 训练的动量
p
p
p,即
p i = ∇ θ ˙ i ( L C E ( f θ ˙ i ( x + δ ∗ ) , y ) ) , δ ∗ = m a x δ ∗ ∈ B ( ϵ ) L C E ( f θ ^ i ( x + δ ∗ ) , y ) \begin{aligned} p^{i} & =\nabla_{\dot{\theta}^{i}}\left(\mathcal{L}_{CE}\left(f_{\dot{\theta}^{i}}\left(x+\delta^{*}\right), y\right)\right), \\ \delta^{*} & =max _{\delta^{*} \in \mathcal{B}(\epsilon)} \mathcal{L}_{CE}\left(f_{\hat{\theta}^{i}}\left(x+\delta^{*}\right), y\right) \end{aligned} piδ∗=∇θ˙i(LCE(fθ˙i(x+δ∗),y)),=maxδ∗∈B(ϵ)LCE(fθ^i(x+δ∗),y) - 自适应加权机制:HFAT可看作由标准对抗训练和辅助模型对抗训练两个分支组成。考虑到对抗样本和“隐藏者”对模型的威胁强度在不同样本和训练阶段不同,设计自适应加权机制,以提高两个对抗训练分支的耦合度。利用自然样本和对抗样本输出之间的差异作为衡量分支重要性的指标,用 KL 散度量化这种差异,自适应加权机制表示为 λ A = e K L ( f θ ~ ( x ) ∥ f θ ~ ( x ′ ) ) e K L ( f θ ( x ) ∥ f θ ( x ′ ) ) + e K L ( f θ ~ ( x ) ∥ f θ ~ ( x ′ ) ) \lambda_{A}=\frac{e^{KL\left(f_{\tilde{\theta}}(x) \| f_{\tilde{\theta}}\left(x'\right)\right)}}{e^{KL\left(f_{\theta}(x) \| f_{\theta}\left(x'\right)\right)}+e^{KL\left(f_{\tilde{\theta}}(x) \| f_{\tilde{\theta}}\left(x'\right)\right)}} λA=eKL(fθ(x)∥fθ(x′))+eKL(fθ~(x)∥fθ~(x′))eKL(fθ~(x)∥fθ~(x′)),其中 λ A \lambda_{A} λA 是辅助模型分支动量 p p p 的权重,标准对抗训练分支的权重为 λ S = 1 − λ A \lambda_{S}=1-\lambda_{A} λS=1−λA.
- 训练策略:引入辅助模型和自适应加权机制后,HFAT的权重参数更新公式为 θ i + 1 ← θ i − η ( λ S ∇ θ i L C E ( f θ i ( x + δ ) , y ) + λ A p i ) \theta^{i+1} \leftarrow \theta^{i}-\eta\left(\lambda_{S} \nabla_{\theta^{i}} \mathcal{L}_{CE}\left(f_{\theta^{i}}(x+\delta), y\right)+\lambda_{A} p^{i}\right) θi+1←θi−η(λS∇θiLCE(fθi(x+δ),y)+λApi),通过该公式在训练过程中综合考虑两个分支的优化方向,实现对模型的有效训练。
实验-Experiments
实验设置-Experimental setting
这部分主要介绍了实验的设置情况,涵盖数据集、网络架构、基线以及训练细节四个关键方面,具体如下:
- 数据集:研究选用CIFAR10、CIFAR - 100和SVHN这三个数据集开展广泛实验,并且针对这三个数据集,统一设定扰动预算为8/255。
- 网络架构:为了在选定的数据集上进行模型训练,采用了两种网络架构。其中一种是标准网络Pre - ResNet18,另一种是先进的大规模网络WideResNet - 3410。
- 基线:实验选取了标准防御基线AT P G D _{PGD} PGD,同时引入四个强大的防御基线,分别是TRADES、MART、AWP和HELP。通过与这些基线对比,来验证在不同条件下模型的泛化能力。
- 训练细节:所有参与实验的防御方法均采用随机梯度下降(SGD)进行200个epoch的训练。训练过程中,动量设为0.9,权重衰减设为 5 × 1 0 − 4 5×10^{-4} 5×10−4,初始学习率设为0.1. 在训练的第100个epoch和第150个epoch,学习率会下降为原来的十分之一。此外,在所有方法的训练过程中,均采用了简单的数据增强技术,包括对32×32图像进行4像素填充的随机裁剪以及随机水平翻转操作。
性能分析-Performance analysis
该部分主要从鲁棒性、准确性以及黑盒攻击下的性能这两个方面,对模型进行了性能分析,具体内容如下:
-
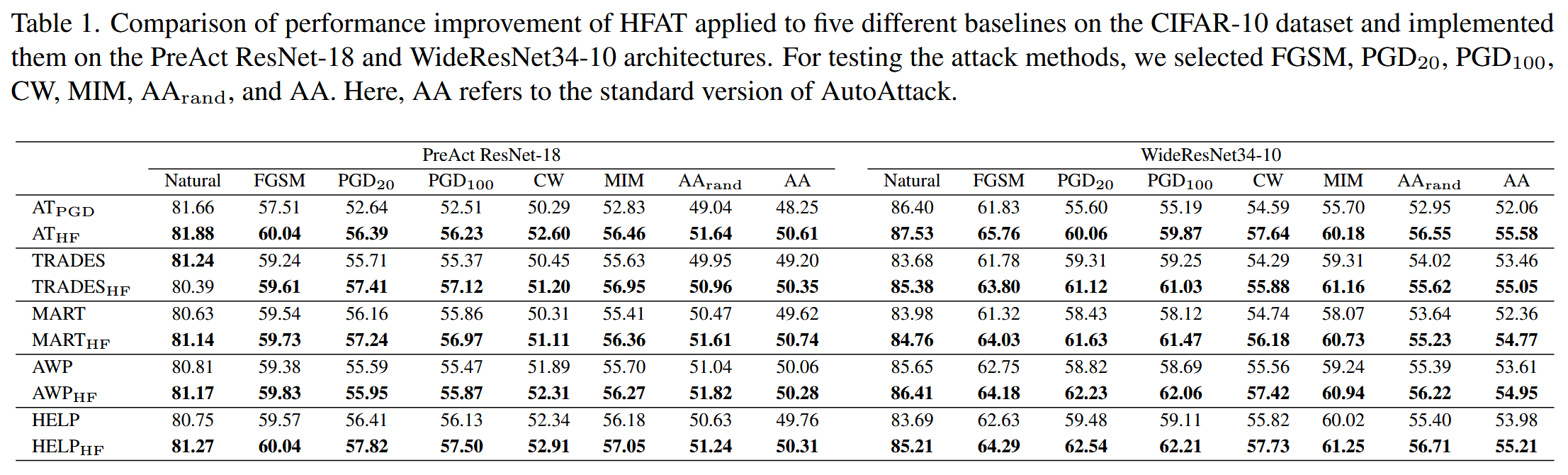
鲁棒性和准确性方面的性能:运用FGSM、PGD这两种标准攻击方法,以及C&W、MIM、AA r a n d _{rand} rand、AA s t a n d a r d _{standard} standard 这四种强攻击方法对模型展开测试。在CIFAR10数据集上,将HFAT应用于五个不同的基线模型进行实验,结果表明HFAT几乎在所有攻击方法下,都提升了模型的自然准确率和鲁棒准确率。CIFAR100和SVHN数据集上的结果在补充材料中展示。这一实验结果充分证实了HFAT策略的有效性和适用性。
表1. 在CIFAR-10数据集上,将HFAT应用于五种不同基线模型,并在PreAct ResNet-18和WideResNet34-10架构上实现时的性能提升对比。为测试攻击方法,我们选择了FGSM、PGD 20 _{20} 20、PGD 100 _{100} 100、C&W、MIM、AA r a n d _{rand} rand和AA。此处,AA指的是标准版本的AutoAttack。
-
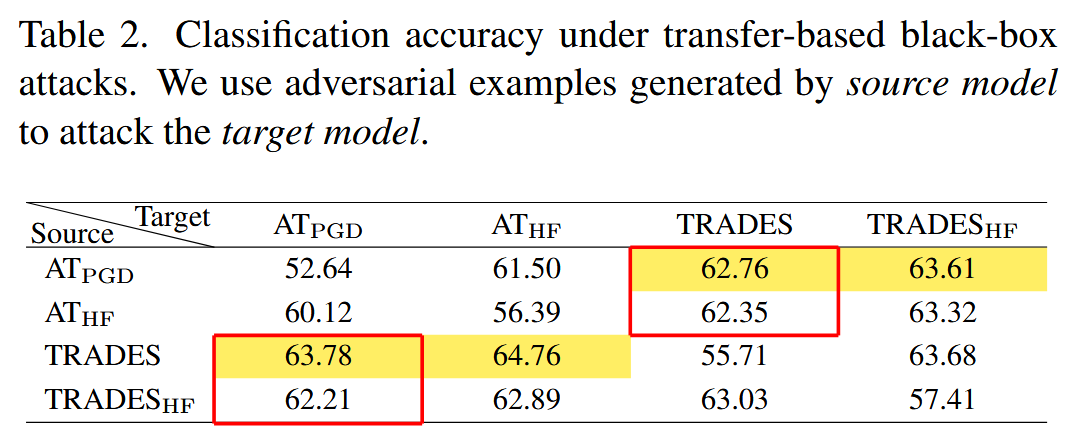
黑盒攻击下的性能:除了在AA s t a n d a r d _{standard} standard中包含的黑盒攻击外,进一步采用基于转移的黑盒攻击(使用PGD - 20)来评估模型性能。实验利用源模型生成的对抗样本攻击目标模型,结果显示HFAT改进后的模型在对抗攻击中展现出更好的转移性,在攻击相同目标模型时成功率更高;同时,在防御来自相同源模型的对抗样本时,也表现出更高的准确率。这表明HFAT改进的模型在黑盒攻击场景下,无论是攻击能力还是防御能力都有出色表现。
表2. 基于迁移的黑盒攻击下的分类准确率。我们使用源模型生成的对抗样本攻击目标模型。
对“隐藏者”的分析-Analysis of hidders
这部分内容主要从防御性能和损失景观两个方面对隐藏者进行了分析,以探究HFAT算法对隐藏者的防御效果,具体如下:
- 防御性能
- 减少隐藏者比例:通过计算并绘制不同间隔(间隔1、5、20和50个epoch)下隐藏者的比例(图2),对比HFAT与AT P G D _{PGD} PGD和Trades单独防御的情况。发现HFAT显著降低了隐藏者的比例,且随着间隔值增加,AT P G D _{PGD} PGD和Trades的对抗隐藏者比例上升,而HFAT几乎无差异。这表明HFAT以1个epoch为间隔进行经验分布采样训练模型是合理的,能更好地防御间隔值更大的隐藏者。
- 防止重复威胁:通过可视化隐藏者出现的具体索引位置(图3),观察到 A T P G D AT_{PGD} ATPGD中隐藏者有重复出现的现象,且呈现间歇性和交替性;而在 A T H F AT_{HF} ATHF中,隐藏者通常不会重复出现,说明HFAT能有效且持续地防御隐藏者。
- 损失景观:通过可视化损失景观来验证HFAT的有效性。在输入附近的梯度方向和随机方向上进行扰动,结果显示,相较于
A
T
P
G
D
AT_{PGD}
ATPGD,HFAT使损失景观更显著地变平坦,这表明HFAT提供了更好的鲁棒性。沿着隐藏者方向和随机方向可视化损失景观时,AT
P
G
D
_{PGD}
PGD 存在局部峰值,证实了隐藏者的存在;而HFAT有效抑制了隐藏者的出现。
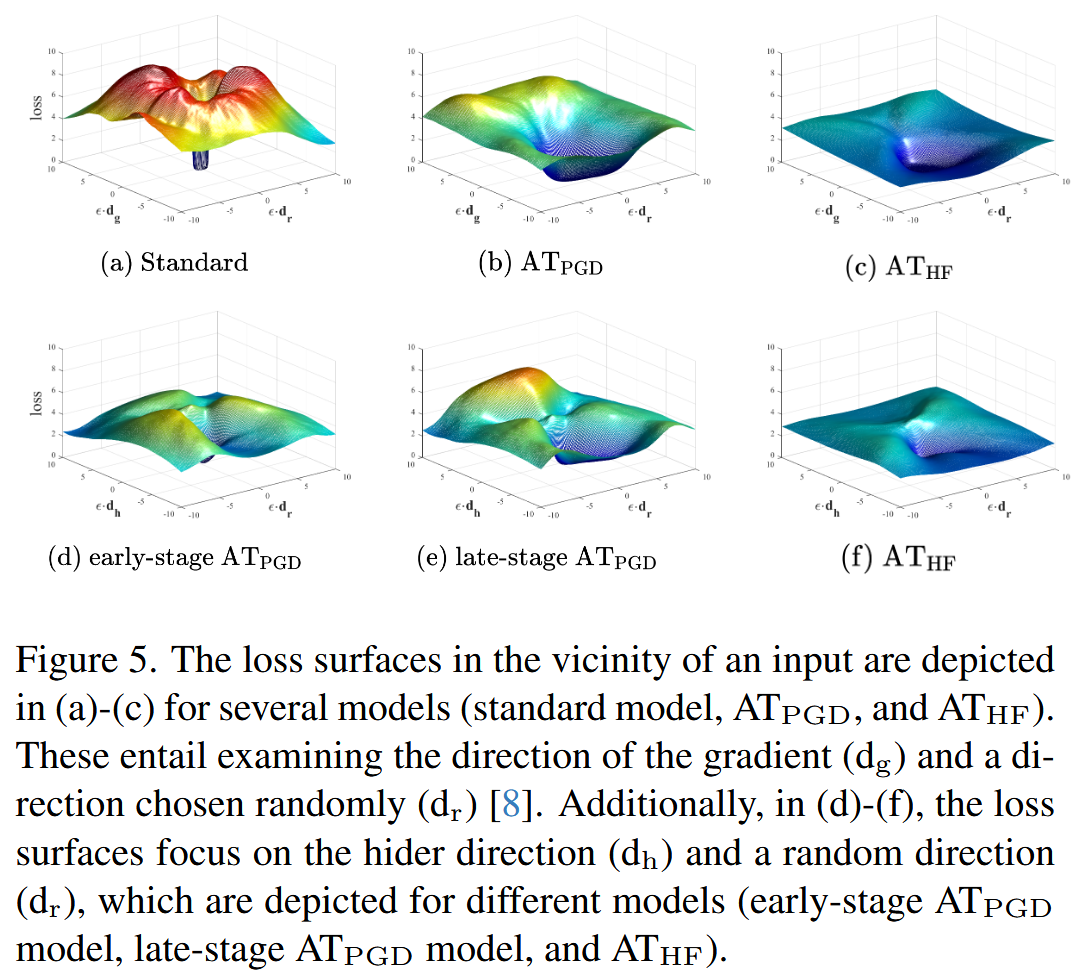
图5. (a) - (c)展示了几个模型(标准模型、AT P G D _{PGD} PGD和AT H F _{HF} HF)在输入附近的损失曲面。这些图涉及考察梯度方向( d g d_{g} dg)和随机选择的方向( d r d_{r} dr)。此外,在(d) - (f)中,损失曲面聚焦于隐藏者方向( d h d_{h} dh)和随机方向( d r d_{r} dr),这些是针对不同模型(早期的AT P G D _{PGD} PGD模型、晚期的AT P G D _{PGD} PGD模型和AT H F _{HF} HF)绘制的。
消融研究-Ablation Stydies
这部分主要通过消融实验,研究了辅助模型、自适应加权机制以及辅助模型步长对模型性能的影响,具体内容如下:
-
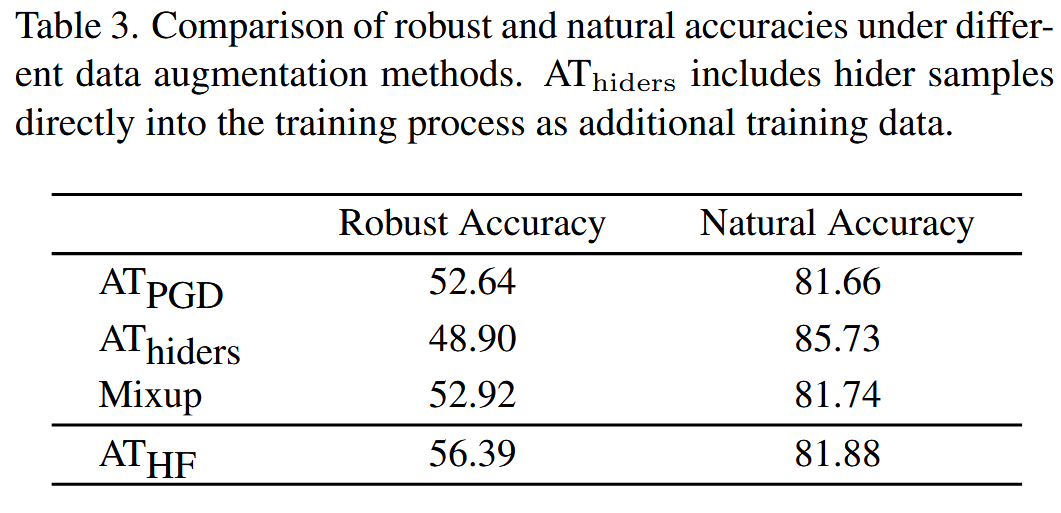
辅助模型的消融实验:对比直接将通过位置比信息计算的样本作为数据增强、使用Mixup数据增强方法以及利用辅助模型获取优化方向这三种方式对模型的影响。实验结果表明,直接将隐藏者样本纳入训练虽能大幅提升自然准确率,但会显著降低鲁棒准确率;Mixup方法提升效果有限;而使用辅助模型的 HFAT 能显著提升模型的鲁棒性和准确性。这是因为在当前训练 epoch 下,由相对位置信息计算的样本攻击性能不显著,不能直接用于训练取得良好效果。
表3. 不同数据增强方法下鲁棒准确率和自然准确率的对比。AT h i d e s _{hides } hides(隐藏者对抗训练)将隐藏者样本直接作为额外的训练数据纳入训练过程。
-
自适应加权机制的消融实验:研究自适应权重 λ \lambda λ 对模型性能的影响,以 λ A \lambda_{A} λA 表示辅助模型分支的权重, λ S \lambda_{S} λS 表示标准对抗训练分支的权重。固定 λ S = 1 \lambda_{S}=1 λS=1,调整 λ A \lambda_{A} λA 为不同值( λ A = 0.0 , 0.01 , 0.1 , 1 , 2 , 3 , 5 \lambda_{A}=0.0,0.01,0.1,1,2,3,5 λA=0.0,0.01,0.1,1,2,3,5)并在实验前进行归一化,使用 PGD 20 _{20} 20 和MIM攻击评估模型鲁棒准确率。结果发现,随着 λ A \lambda_{A} λA 增加,模型鲁棒性逐渐提升,在 λ A = 2 \lambda_{A}=2 λA=2 或 3 3 3 时达到峰值,随后下降。且自适应权重方案相比固定权重,性能提升显著。
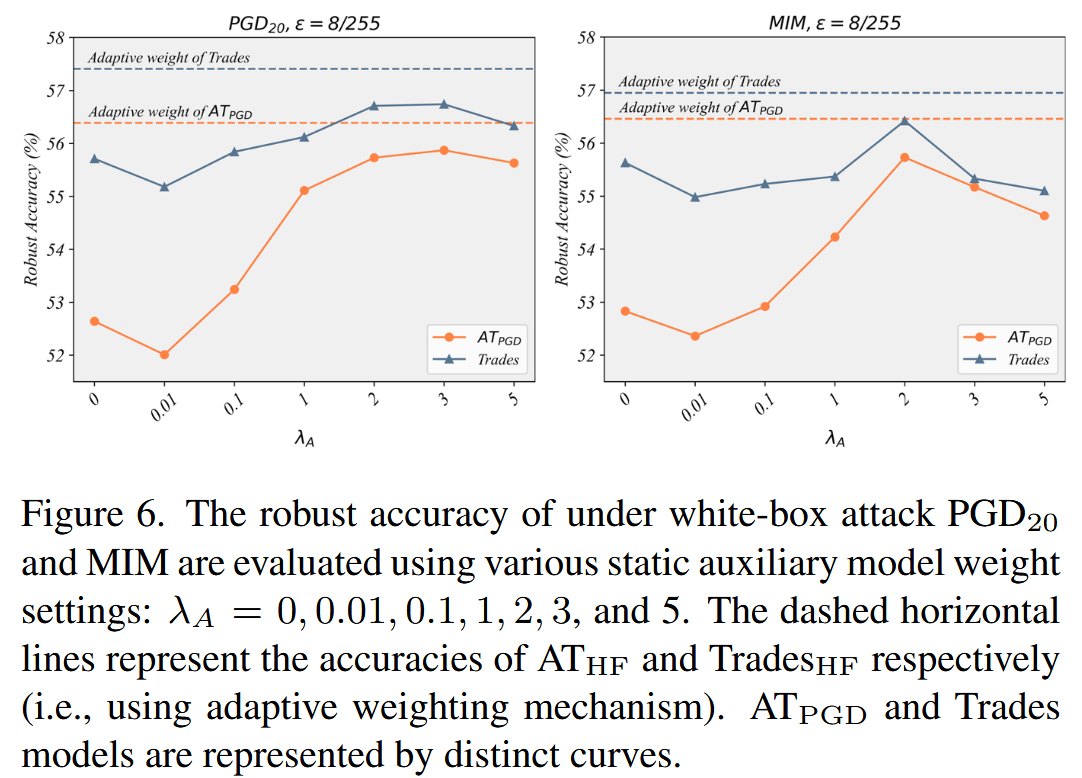
图6. 使用不同的静态辅助模型权重设置( λ A = 0 \lambda_{A}=0 λA=0、 0.01 0.01 0.01、 0.1 0.1 0.1、 1 1 1、 2 2 2、 3 3 3和 5 5 5)评估在白盒攻击PGD 20 _{20} 20和MIM下的鲁棒准确率。水平虚线分别代表AT H F _{HF} HF和Trades H F _{HF} HF(即使用自适应加权机制)的准确率。AT P G D _{PGD} PGD和Trades模型由不同曲线表示。 -
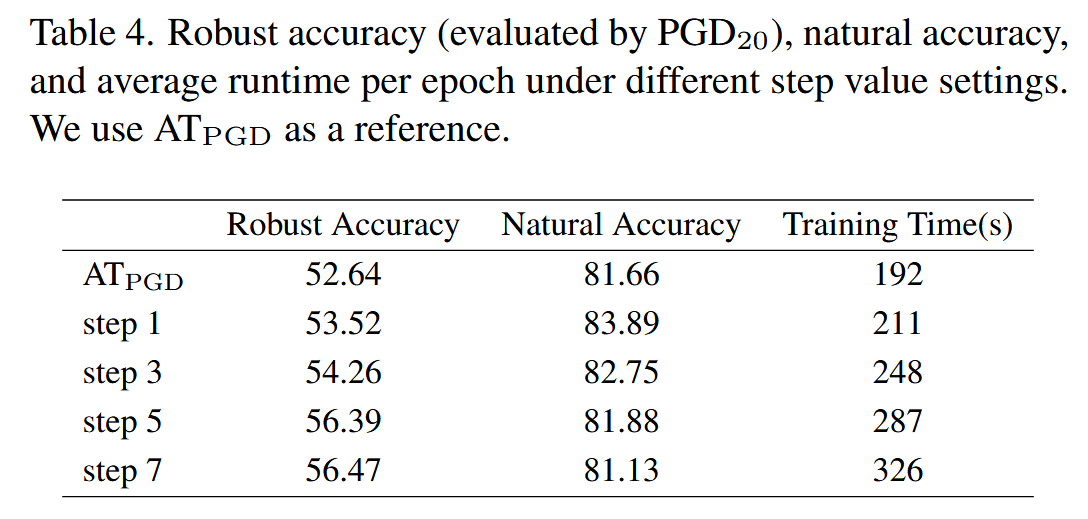
辅助模型步长的消融实验:讨论引入辅助模型带来的额外计算开销,通过改变辅助模型生成对抗样本的步长进行实验。较大步长计算耗时更长,随着步长增加,模型的鲁棒准确率和自然准确率逐渐提升,在步长为 5 5 5 时达到最佳平衡;步长为 7 7 7 时,自然准确率明显下降。实验中报告的训练时间包含辅助模型和标准对抗训练模型的顺序计算时间。
表4. 在不同步长值设置下,通过 PGD 20 _{20} 20 评估的鲁棒准确率、自然准确率以及每个训练轮次的平均运行时间。我们以 AT P G D _{PGD} PGD 作为参考。
分析自适应加权机制-Analysis of adaptive weighting mechanism
这部分主要分析了自适应加权机制,通过可视化自适应权重在训练过程中的变化,证明引入辅助模型的有效性,具体内容如下:
- 可视化自适应权重变化:为验证引入辅助模型的有效性,对训练过程中自适应权重值的变化进行可视化展示。从图7中可以观察到,标准对抗训练模型的平均权重
λ
S
\lambda_{S}
λS 在训练早期约为0.5 ,到训练后期逐渐下降至约0.1;而辅助模型的梯度权重
λ
A
\lambda_{A}
λA 则从0.5逐渐上升至0.9。
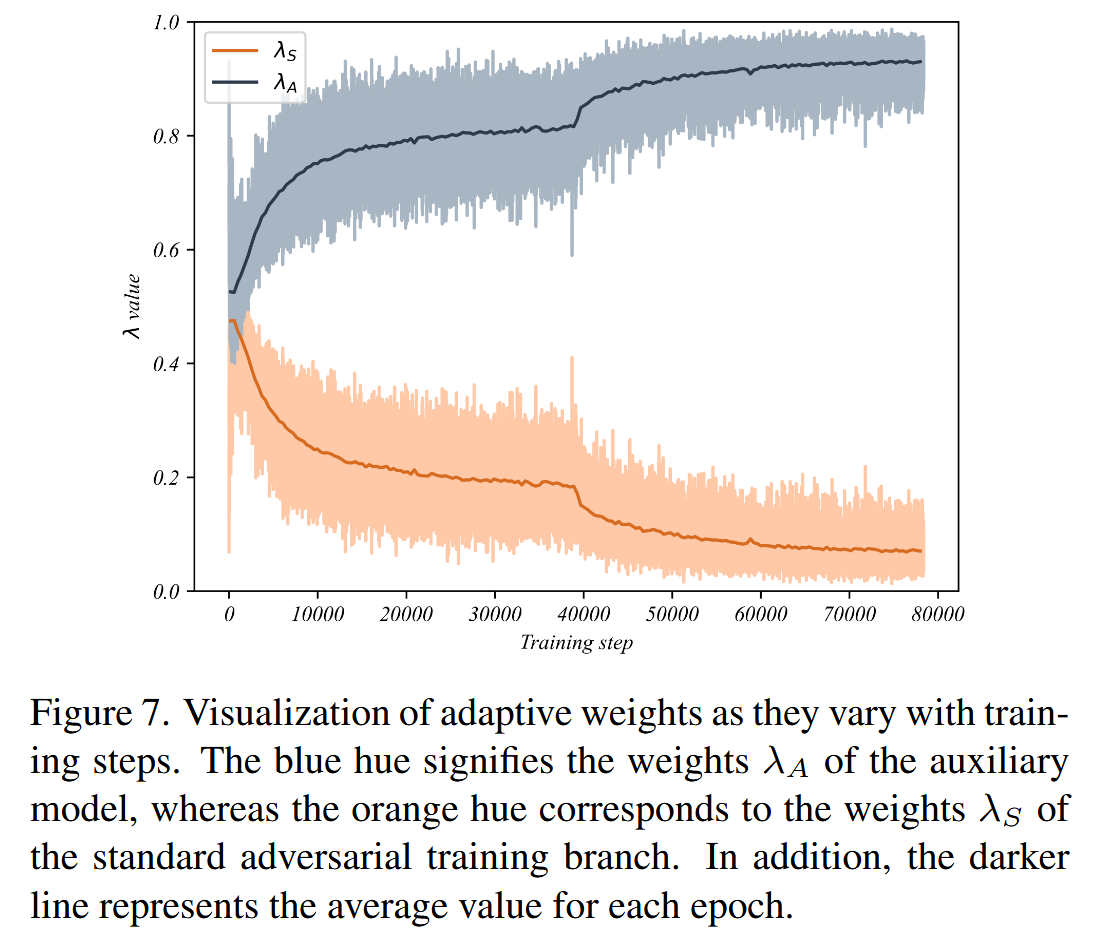
图7. 自适应权重随训练步骤变化的可视化。蓝色表示辅助模型的权重 λ A \lambda_{A} λA,而橙色对应标准对抗训练分支的权重 λ S \lambda_{S} λS. 此外,较深的线代表每个训练轮次的平均值。 - 分析权重变化意义:这种权重变化趋势表明,随着训练的推进,辅助模型的梯度贡献在训练过程中变得越来越重要。这意味着在模型训练的后期阶段,防御隐藏者对于提升模型性能的重要性日益凸显,进一步证明了自适应加权机制能够使模型在不同训练时期,根据对抗样本和隐藏者对模型的威胁程度,自适应地调整对两者的关注重点,从而有效提升模型的鲁棒性和准确性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











