







Transformer Interpretability Beyond Attention Visualization

本文提出一种基于深度泰勒分解原理计算 Transformer 网络相关性的新方法,通过设计相关性传播规则、归一化项,整合注意力和相关性分数来应对 Transformer 中跳跃连接和注意力机制带来的挑战。在视觉 Transformer 网络和文本分类问题的基准测试中,该方法在定性评估、正负扰动测试、分割测试和语言推理任务上均优于现有可解释性方法,为 Transformer 的可解释性提供了有效解决方案。
摘要-Abstract
Self-attention techniques, and specifically Transformers, are dominating the field of text processing and are becoming increasingly popular in computer vision classification tasks. In order to visualize the parts of the image that led to a certain classification, existing methods either rely on the obtained attention maps or employ heuristic propagation along the attention graph. In this work, we propose a novel way to compute relevancy for Transformer networks. The method assigns local relevance based on the Deep Taylor Decomposition principle and then propagates these relevancy scores through the layers. This propagation involves attention layers and skip connections, which challenge existing methods. Our solution is based on a specific formulation that is shown to maintain the total relevancy across layers. We benchmark our method on very recent visual Transformer networks, as well as on a text classification problem, and demonstrate a clear advantage over the existing explainability methods.
自注意力技术,尤其是Transformer,在文本处理领域占据主导地位,并且在计算机视觉分类任务中也越来越受欢迎。为了可视化导致特定分类的图像部分,现有方法要么依赖获得的注意力图,要么沿注意力图进行启发式传播。在这项工作中,我们提出了一种计算Transformer网络相关性的新方法。该方法基于深度泰勒分解原理分配局部相关性,然后在各层传播这些相关性分数。这种传播涉及注意力层和跳跃连接,这对现有方法构成了挑战。我们的解决方案基于一种特定的公式,该公式能够在各层保持总相关性。我们在最新的视觉Transformer网络以及文本分类问题上对我们的方法进行了基准测试,结果表明它相较于现有的可解释性方法具有明显优势。
引言-Introduction
Transformer及其衍生方法在自然语言处理(NLP)领域取得了显著成果,并且在计算机视觉任务中也逐渐受到青睐,其广泛应用使得对其决策过程的可视化变得十分必要。这不仅有助于调试模型、验证模型的公平性与无偏性,还能为下游任务提供支持。
- 现有可视化方法的问题:Transformer网络的核心组件是自注意力层,当前可视化Transformer模型的常见做法是将注意力视为相关性分数,但这种方式存在诸多问题。例如,简单平均多层注意力会模糊信号,无法考虑各层的不同作用;rollout方法虽有改进,但依赖简单假设,常突出无关标记。此外,许多现有方法在处理Transformer时,无法在所有层传播注意力,只是部分应用。
- Transformer网络带来的挑战:Transformer网络高度依赖跳跃连接和注意力算子,这两者都会混合两个激活图,给现有相关性传播方法带来独特挑战。同时,Transformer使用的非线性激活函数(如GELU)会产生正负特征,若处理不当,跳跃连接会导致数值不稳定,像LRP这类方法在这种情况下往往会失效。自注意力层也使得相关性传播难以维持总相关性。
- 本文方法的优势:本文提出一种新的计算Transformer网络相关性的方法,该方法基于深度泰勒分解原理分配局部相关性,并在各层传播相关性分数。通过引入适用于正负归因的相关性传播规则、针对非参数层的归一化项,以及整合注意力和相关性分数,有效解决了上述挑战。此外,本文方法在设计上实现了基于类别的分离,这是其他Transformer可视化方法所不具备的特性。
- 研究目标与基准测试:在可解释性研究中,相关概念定义并不统一,一些理论框架依赖特定假设,在实际数据上表现不佳。本文采用机械主义方法,旨在通过多种计算机视觉和NLP基准测试来提升性能。这些基准测试包括ImageNet数据集子集上的图像分割、ImageNet验证集上的正负扰动测试,以及NLP中的公共可解释性基准测试。
相关工作-Related Work
这部分主要介绍了计算机视觉领域和Transformer模型相关的可解释性方法,分析了各类方法的原理、特点、优势和不足,为后续阐述本文方法的创新性和优势做铺垫,具体内容如下:
- 计算机视觉中的可解释性方法
- 梯度方法:基于各层输入的梯度计算,通过反向传播实现。像Gradient*Input将梯度与输入激活相乘;Integrated Gradients计算输入与其导数的乘积,不过是基于平均梯度和输入的线性插值;SmoothGrad可视化输入的平均梯度,并通过添加随机高斯噪声进行平滑处理;FullGrad则更全面,除了考虑输入的梯度,还考虑了偏置项的梯度。但这些方法在实际应用中大多是类别无关的,即无论计算哪个类别的梯度,输出结果相似。GradCAM是类别特定的方法,结合了网络层的输入特征和梯度,被用于下游应用,如弱监督语义分割,但它仅基于最深层的梯度计算,通过上采样低空间分辨率层得到的结果比较粗糙。
- 归因传播方法:以深度泰勒分解(DTD)框架为理论依据,递归地将网络的决策分解为前层的贡献,一直追溯到网络输入元素。例如Layer - wise Relevance Propagation(LRP)方法,依据DTD原理将相关性从预测类反向传播到输入图像,但它假设使用修正线性单元(ReLU)非线性激活函数,而Transformer通常使用其他类型的激活函数,所以本文方法需对DTD进行不同应用。其他归因方法如RAP、AGF、DeepLIFT和DeepSHAP等,部分存在类别无关的问题。Contrastive - LRP(CLRP)和Softmax - GradientLRP(SGLRP)通过对比不同类别的LRP传播结果来产生类别相关的热图,但本文方法是在构建过程中就实现了类别特定,无需额外对比阶段。
- 其他方法:包括基于显著性的方法、激活最大化、激发反向传播、扰动方法和Shapley值方法等。扰动方法直观且适用于黑箱模型,但生成热图的计算成本高,在处理Transformer中的离散标记(如文本)时应用方式不明确。Shapley值方法理论依据扎实,但计算复杂度高,准确性也常不如其他方法 。
- Transformer的可解释性研究:目前针对Transformer可视化的研究较少,多数研究直接使用注意力分数,忽略了注意力组件和网络其他计算部分。将自注意力头简化为仅关注查询和键的内积(即注意力分数)过于短视,没有考虑其他层。LRP在应用于Transformer时存在局限性,仅部分传播相关性分数,且未直接评估相关性分数,仅用于可视化注意力头的相对重要性和修剪不太相关的注意力头。rollout方法假设注意力是线性组合的,沿成对注意力图考虑路径,但这常导致强调无关标记,且无法区分对决策的正负贡献。Abnar等人提出的attention flow方法考虑了成对注意力图上的最大流问题,有时与通过掩码或输入梯度获得的相关性分数相关性更强,但计算速度慢,本文未对其进行评估。并且,之前的研究未在与BERT网络无关的基准测试中评估这些方法,也未与除原始注意力分数外的相关性分配方法进行比较。
方法-Method
相关性与梯度-Relevance and gradients
这部分主要介绍了在Transformer模型中计算相关性和梯度的方法,为后续分析模型各层对分类决策的贡献提供了基础,具体内容如下:
- 符号定义与梯度传播:在分类任务中,设分类头的类别数为 c c c,要可视化的类别为 t t t( t ∈ 1 … ∣ C ∣ t \in 1 \ldots |C| t∈1…∣C∣)。按照惯例,用 x ( n ) x^{(n)} x(n)表示第 n n n层( n ∈ [ 1 … N ] n \in[1 \ldots N] n∈[1…N], N N N为网络总层数)的输入, x ( N ) x^{(N)} x(N)是网络的输入, x ( 1 ) x^{(1)} x(1)是网络的输出。根据链式法则,相对于分类器在类别 t t t的输出 y t y_{t} yt,对 x j ( n ) x_{j}^{(n)} xj(n)的梯度传播公式为 ∇ x j ( n ) : = ∂ y t ∂ x j ( n ) = ∑ i ∂ y t ∂ x i ( n − 1 ) ∂ x i ( n − 1 ) ∂ x j ( n ) \nabla x_{j}^{(n)}:=\frac{\partial y_{t}}{\partial x_{j}^{(n)}}=\sum_{i} \frac{\partial y_{t}}{\partial x_{i}^{(n - 1)}} \frac{\partial x_{i}^{(n - 1)}}{\partial x_{j}^{(n)}} ∇xj(n):=∂xj(n)∂yt=∑i∂xi(n−1)∂yt∂xj(n)∂xi(n−1),其中 j j j对应 x ( n ) x^{(n)} x(n)中的元素, i i i对应 x ( n − 1 ) x^{(n - 1)} x(n−1)中的元素。
- 相关性传播:相关性传播遵循通用的深度泰勒分解(Deep Taylor Decomposition)公式 R j ( n ) = G ( X , Y , R ( n − 1 ) ) = ∑ i X j ∂ L i ( n ) ( X , Y ) ∂ X j R i ( n − 1 ) L i ( n ) ( X , Y ) R_{j}^{(n)}=\mathcal{G}\left(X, Y, R^{(n - 1)}\right)=\sum_{i} X_{j} \frac{\partial L_{i}^{(n)}(X, Y)}{\partial X_{j}} \frac{R_{i}^{(n - 1)}}{L_{i}^{(n)}(X, Y)} Rj(n)=G(X,Y,R(n−1))=∑iXj∂Xj∂Li(n)(X,Y)Li(n)(X,Y)Ri(n−1),该公式满足守恒规则 ∑ j R j ( n ) = ∑ i R i ( n − 1 ) \sum_{j} R_{j}^{(n)}=\sum_{i} R_{i}^{(n - 1)} ∑jRj(n)=∑iRi(n−1)。LRP方法假设使用ReLU非线性激活函数,在这种情况下相关性传播规则为 R j ( n ) = G ( x + , w + , R ( n − 1 ) ) = ∑ i x j + w j i + ∑ j ′ x j ′ + w j ′ i + R i ( n − 1 ) R_{j}^{(n)}=\mathcal{G}\left(x^{+}, w^{+}, R^{(n - 1)}\right)=\sum_{i} \frac{x_{j}^{+} w_{j i}^{+}}{\sum_{j'} x_{j'}^{+} w_{j' i}^{+}} R_{i}^{(n - 1)} Rj(n)=G(x+,w+,R(n−1))=∑i∑j′xj′+wj′i+xj+wji+Ri(n−1) ,其中 x + x^{+} x+和 w + w^{+} w+表示取正值操作(即 v + = max ( 0 , v ) v^{+} = \max(0, v) v+=max(0,v))。然而,Transformer使用的如GELU等非线性激活函数会输出正负值,对此,通过构建索引子集 q = ( i , j ) ∣ x j w j i ≥ 0 q={(i, j) | x_{j} w_{j i} \geq 0} q=(i,j)∣xjwji≥0,修改LRP传播公式为 R j ( n ) = G q ( x , w , q , R ( n − 1 ) ) = ∑ { i ∣ ( i , j ) ∈ q } x j w j i ∑ { j ′ ∣ ( j ′ , i ) ∈ q } x j ′ w j ′ i R i ( n − 1 ) R_{j}^{(n)}=\mathcal{G}_{q}\left(x, w, q, R^{(n - 1)}\right)=\sum_{\{i |(i, j) \in q\}} \frac{x_{j} w_{j i}}{\sum_{\left\{j' |\left(j', i\right) \in q\right\}} x_{j'} w_{j' i}} R_{i}^{(n - 1)} Rj(n)=Gq(x,w,q,R(n−1))=∑{i∣(i,j)∈q}∑{j′∣(j′,i)∈q}xj′wj′ixjwjiRi(n−1),即只考虑具有正加权相关性的元素。
- 相关性传播初始化:为启动相关性传播过程,将初始相关性 R ( 0 ) R^{(0)} R(0)设为 1 t \mathbb{1}_{t} 1t ,这是一个指示目标类别 t t t的one - hot向量,它表示初始时所有相关性都集中在目标类别上,后续通过各层的传播来分配和调整相关性。
非参数相关性传播-Non parametric relevance propagation
这部分聚焦于Transformer模型中两类特殊算子(跳跃连接和矩阵乘法)的相关性传播问题,提出了针对性的解决策略,确保相关性在传播过程中的合理性与稳定性,具体内容如下:
- 特殊算子的相关性传播需求:Transformer模型中的跳跃连接和矩阵乘法这两个算子,涉及两个特征图张量的混合(区别于特征图与学习张量的运算)。在进行相关性传播时,需要同时通过这两个输入张量进行传播。由于矩阵乘法中两个张量的形状可能不同,这进一步增加了相关性传播的复杂性。
- 相关性传播的计算方式:对于这类处理两个操作数的二元算子,计算其相关性传播的方式为 R j u ( n ) = G ( u , v , R ( n − 1 ) ) R_{j}^{u^{(n)}}=\mathcal{G}\left(u, v, R^{(n - 1)}\right) Rju(n)=G(u,v,R(n−1))和 R k v ( n ) = G ( v , u , R ( n − 1 ) ) R_{k}^{v^{(n)}}=\mathcal{G}\left(v, u, R^{(n - 1)}\right) Rkv(n)=G(v,u,R(n−1)),分别得到两个张量 u u u和 v v v的相关性 R j u ( n ) R_{j}^{u^{(n)}} Rju(n)与 R k v ( n ) R_{k}^{v^{(n)}} Rkv(n) ,但这些操作的结果会产生正负值。
- 相关性守恒的差异:研究发现,对于加法操作(如跳跃连接),相关性传播满足守恒规则,即 ∑ j R j u ( n ) + ∑ k R k v ( n ) = ∑ i R i ( n − 1 ) \sum_{j} R_{j}^{u^{(n)}}+\sum_{k} R_{k}^{v^{(n)}}=\sum_{i} R_{i}^{(n - 1)} ∑jRju(n)+∑kRkv(n)=∑iRi(n−1);而对于矩阵乘法操作,通常情况下该守恒规则并不成立。文中通过引理1进行了理论说明,并在补充材料中给出详细证明。
- 数值不稳定问题及解决:在传播跳跃连接的相关性时,尽管从理论上加法操作满足相关性守恒,但实际计算中仍会出现数值不稳定的情况。例如,在特定示例中,相关性分数可能会出现数值爆炸。为解决矩阵乘法导致的注意力机制中相关性不守恒,以及跳跃连接的数值问题,文章提出对 R j u ( n ) R_{j}^{u^{(n)}} Rju(n)和 R k v ( n ) R_{k}^{v^{(n)}} Rkv(n)进行归一化处理,公式分别为 R ‾ j u ( n ) = R j u ( n ) ∣ ∑ j R j u ( n ) ∣ ∣ ∑ j R j u ( n ) ∣ + ∣ ∑ k R k v ( n ) ∣ ⋅ ∑ i R i ( n − 1 ) ∑ j R j u ( n ) \overline{R}_{j}^{u^{(n)}}=R_{j}^{u^{(n)}} \frac{\left|\sum_{j} R_{j}^{u^{(n)}}\right|}{\left|\sum_{j} R_{j}^{u^{(n)}}\right|+\left|\sum_{k} R_{k}^{v^{(n)}}\right|} \cdot \frac{\sum_{i} R_{i}^{(n - 1)}}{\sum_{j} R_{j}^{u^{(n)}}} Rju(n)=Rju(n) ∑jRju(n) + ∑kRkv(n) ∑jRju(n) ⋅∑jRju(n)∑iRi(n−1)和 R ‾ k v ( n ) = R k v ( n ) ∣ ∑ k R k v ( n ) ∣ ∣ ∑ j R j u ( n ) ∣ + ∣ ∑ k R k v ( n ) ∣ ⋅ ∑ i R i ( n − 1 ) ∑ k R k v ( n ) \overline{R}_{k}^{v^{(n)}}=R_{k}^{v^{(n)}} \frac{\left|\sum_{k} R_{k}^{v^{(n)}}\right|}{\left|\sum_{j} R_{j}^{u^{(n)}}\right|+\left|\sum_{k} R_{k}^{v^{(n)}}\right|} \cdot \frac{\sum_{i} R_{i}^{(n - 1)}}{\sum_{k} R_{k}^{v^{(n)}}} Rkv(n)=Rkv(n) ∑jRju(n) + ∑kRkv(n) ∑kRkv(n) ⋅∑kRkv(n)∑iRi(n−1) 。通过引理2证明了该归一化技术能够维持相关性守恒规则,并且对每个张量的相关性和进行了有效约束,确保 0 ≤ ∑ j R ‾ j u ( n ) , ∑ k R ‾ k v ( n ) ≤ ∑ i R i ( n − 1 ) 0 \leq \sum_{j} \overline{R}_{j}^{u^{(n)}}, \sum_{k} \overline{R}_{k}^{v^{(n)}} \leq \sum_{i} R_{i}^{(n - 1)} 0≤∑jRju(n),∑kRkv(n)≤∑iRi(n−1) ,详细证明过程见补充材料。
相关性与梯度扩散-Relevance and gradient diffusion
这部分主要介绍了Transformer模型中相关性和梯度扩散的计算方式,以及与其他方法的对比,具体内容如下:
- Transformer模型结构与相关计算:Transformer模型 M M M由 B B B个模块组成,每个模块 b b b包含自注意力层、跳跃连接以及其他线性和归一化层。模型输入是长度为 S S S、维度为 d d d的序列,还有用于分类的特殊标记[CLS],输出是长度为 c c c的分类概率向量 y y y。自注意力模块在嵌入维度 d d d的子空间 d h d_{h} dh上操作, h h h为头数且 h d h = d h d_{h}=d hdh=d 。其计算过程包括计算注意力图 A ( b ) = s o f t m a x ( Q ( b ) ⋅ K ( b ) T d h ) A^{(b)} = softmax(\frac{Q^{(b)} \cdot K^{(b)^{T}}}{\sqrt{d_{h}}}) A(b)=softmax(dhQ(b)⋅K(b)T)和输出 O ( b ) = A ( b ) ⋅ V ( b ) O^{(b)} = A^{(b)} \cdot V^{(b)} O(b)=A(b)⋅V(b) ,其中 Q ( b ) Q^{(b)} Q(b) 、 K ( b ) K^{(b)} K(b) 、 V ( b ) V^{(b)} V(b)是自注意力模块的输入投影, A ( b ) A^{(b)} A(b)是注意力图。
- 相关性和梯度的传播与整合:在相关性和梯度的传播过程中,每个注意力图
A
(
b
)
A^{(b)}
A(b)都有相对于目标类
t
t
t的梯度
∇
A
(
b
)
\nabla A^{(b)}
∇A(b)和相关性
R
(
n
b
)
R^{(n_{b})}
R(nb) ,
n
b
n_{b}
nb是与模块
b
b
b中softmax操作对应的层。最终输出
C
C
C由加权注意力相关性定义,公式为
A
‾
(
b
)
=
I
+
E
h
(
∇
A
(
b
)
⊙
R
(
n
b
)
)
+
\overline{A}^{(b)} = I + \mathbb{E}_{h}(\nabla A^{(b)} \odot R^{(n_{b})})^{+}
A(b)=I+Eh(∇A(b)⊙R(nb))+ ,
C
=
A
‾
(
1
)
⋅
A
‾
(
2
)
⋅
.
.
.
⋅
A
‾
(
B
)
C = \overline{A}^{(1)} \cdot \overline{A}^{(2)} \cdot... \cdot \overline{A}^{(B)}
C=A(1)⋅A(2)⋅...⋅A(B) 。这里
⊙
\odot
⊙是哈达玛积,
E
h
\mathbb{E}_{h}
Eh是在“头”维度上求平均,计算加权注意力相关性时只考虑梯度 - 相关性乘积的正值,同时添加单位矩阵
I
I
I来处理Transformer模块中的跳跃连接,避免自抑制。
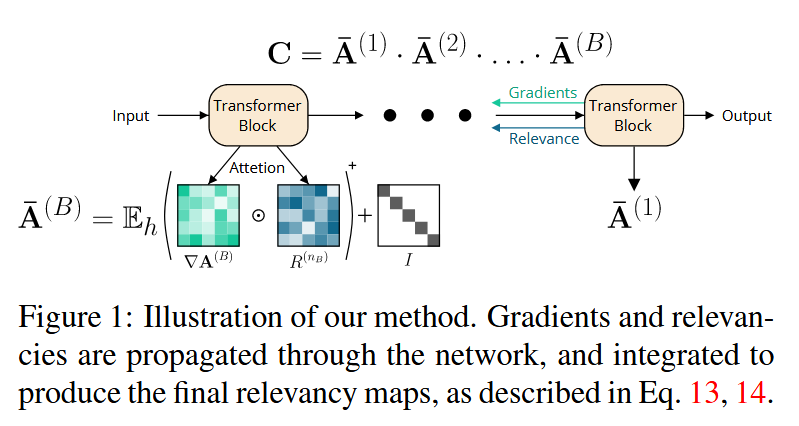
图1:我们方法的示意图。如公式13和14所述,梯度和相关性在网络中传播,并进行整合以生成最终的相关性图。 - 与rollout方法的对比:rollout方法计算为 A ^ ( b ) = I + E h A ( b ) \hat{A}^{(b)} = I + \mathbb{E}_{h} A^{(b)} A^(b)=I+EhA(b) , r o l l o u t = A ^ ( 1 ) ⋅ A ^ ( 2 ) ⋅ . . . ⋅ A ^ ( B ) rollout = \hat{A}^{(1)} \cdot \hat{A}^{(2)} \cdot... \cdot \hat{A}^{(B)} rollout=A^(1)⋅A^(2)⋅...⋅A^(B) 。rollout方法的结果仅取决于输入样本,与要可视化的目标类无关,并且除了成对注意力分数外,不考虑任何其他信号。而本文方法综合考虑了相关性和梯度信息,能够根据目标类生成不同的结果,更全面地反映模型决策过程。
获取图像相关性图-Obtaining the image relevance map
这部分内容主要介绍了如何基于前文所述的方法获得图像相关性图,这是将模型内部的相关性计算结果转化为可直观理解的图像解释的关键步骤,具体内容如下:
- 相关性矩阵与[CLS]标记处理:通过前文方法得到的解释结果是一个大小为 s × s s×s s×s的矩阵 C C C ,其中 s s s代表输入到Transformer的序列长度。按照注意力计算的惯例,矩阵 C C C的每一行对应一个标记相对于其他标记的相关性图。由于研究聚焦于分类模型,所以仅考虑封装分类解释的[CLS]标记。从矩阵 C C C中提取与[CLS]标记对应的行 C [ C L S ] ∈ R s C_{[CLS]} \in \mathbb{R}^{s} C[CLS]∈Rs,这一行的分数用于评估每个标记对分类标记的影响。
- 实际输入标记筛选与处理:在处理过程中,只考虑对应实际输入的标记,排除特殊标记,如[CLS]标记和其他分隔符。在像ViT这样的视觉模型中,内容标记代表图像补丁。
- 生成最终相关性图:为了得到最终的相关性图,需要将序列重塑为补丁网格大小。例如对于正方形图像,补丁网格大小为 s − 1 × s − 1 \sqrt{s - 1}×\sqrt{s - 1} s−1×s−1 。之后,利用双线性插值将这个相关性图上采样回原始图像大小,从而得到可以直观展示图像中各部分对分类结果影响的最终相关性图。
实验-Experiments
这部分主要描述了对所提方法进行实验验证的相关内容,涵盖实验设置、评估指标、实验结果和消融研究等方面,通过与多种基线方法对比,全面评估了本文方法在视觉和语言任务中的性能,具体如下:
- 实验设置
- 模型选择:在语言分类任务中,选用BERT - base模型作为分类器,输入最多512个标记,使用[CLS]标记作为分类头的输入;视觉分类任务则采用预训练的ViT - base模型,将输入图像划分为16×16的非重叠补丁,经展平和线性层处理后,在序列开头添加[CLS]标记用于分类。
- 基线方法:分为注意力图方法(如rollout和原始注意力)、相关性传播方法(如LRP及其部分应用变体)和梯度方法(如GradCAM)。排除计算成本过高和原理差异大的黑箱方法(如Perturbation和Shapely值方法)。
- 评估指标
- 视觉领域:采用正负扰动测试和分割测试。正负扰动测试分两步,先利用预训练网络提取ImageNet验证集的可视化结果,再逐步掩蔽输入图像像素,测量网络的平均top - 1准确率。正扰动从高相关性像素开始掩蔽,期望模型性能大幅下降;负扰动从低相关性像素开始掩蔽,好的解释应保持模型准确率。通过计算擦除10% - 90%像素时的曲线下面积(AUC)评估。分割测试将可视化结果视为图像的软分割,与ImageNet - Segmentation数据集的真实分割对比,用像素准确率、平均交并比(mIoU)和平均精度(mAP)衡量性能。
- 语言领域:遵循ERASER基准的评估设置,在电影评论数据集上对BERT模型微调,应用不同评估方法处理测试集结果,通过计算token - F1分数评估,展示k从10到80(步长为10)时的结果,避免阈值选择对方法性能评估的影响。
- 实验结果
- 定性评估:可视化对比显示,本文方法的结果更清晰、一致,其他基线方法性能参差不齐。在多物体图像且不同类别的可视化中,除GradCAM外,其他方法对不同类别的可视化相似,而本文方法能提供准确且不同的可视化结果。
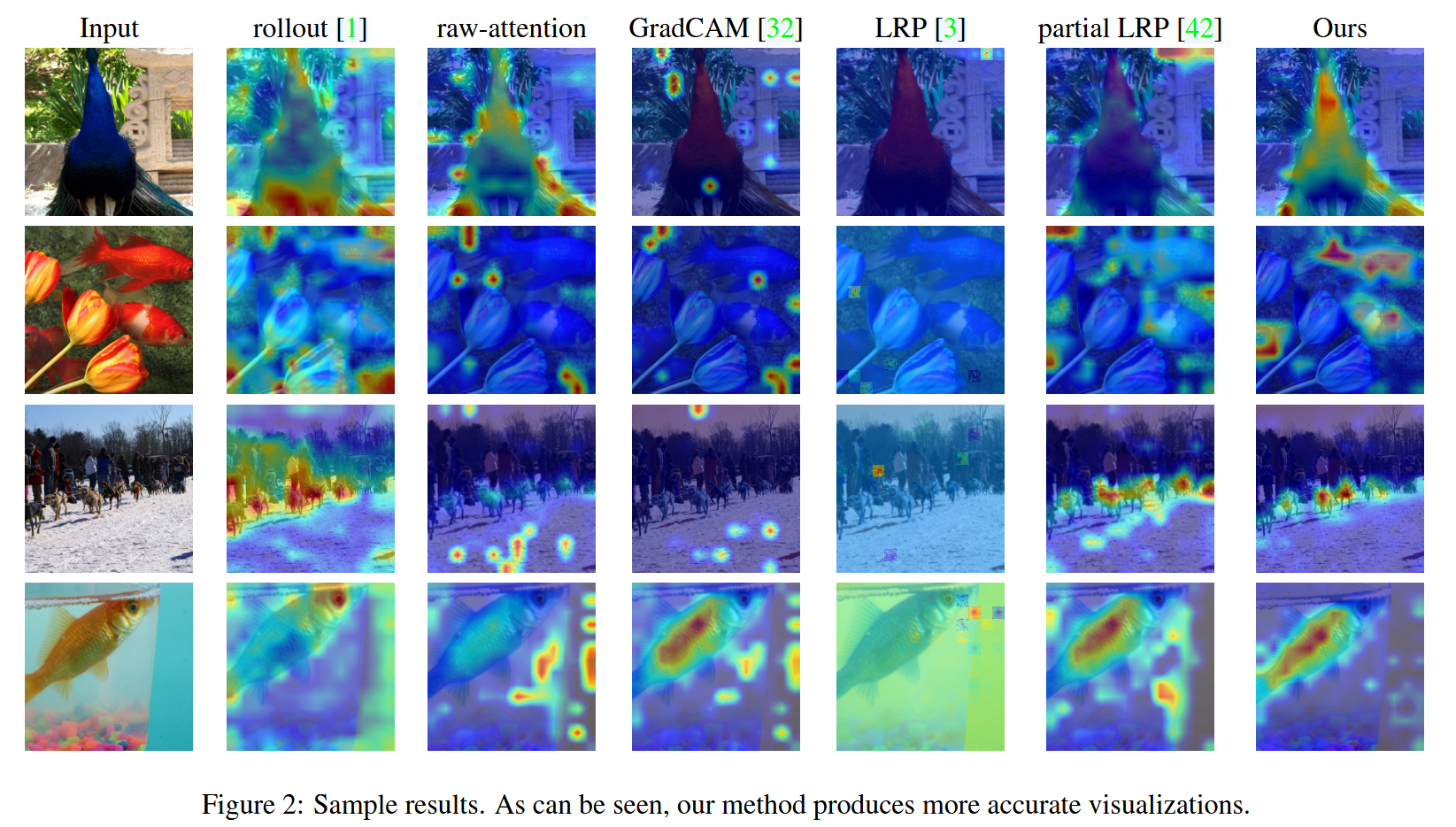
图2:示例结果。可以看出,我们的方法能生成更精确的可视化结果。

图3:特定类别的可视化结果。对于每一幅图像,我们展示了两个不同类别的结果。GradCam是唯一能生成不同映射图的方法。然而,其结果并不具有说服力。 - 定量评估:扰动测试中,本文方法在正负扰动测试的预测类和目标类上,AUC指标均大幅优于基线方法(rollout和原始注意力因结果与目标类无关,未参与目标类测试)。分割测试里,本文方法在像素准确率、mAP和mIoU上显著超越所有基线。语言推理任务中,随着token数量增加,所有方法性能提升,但本文方法始终优于基线。
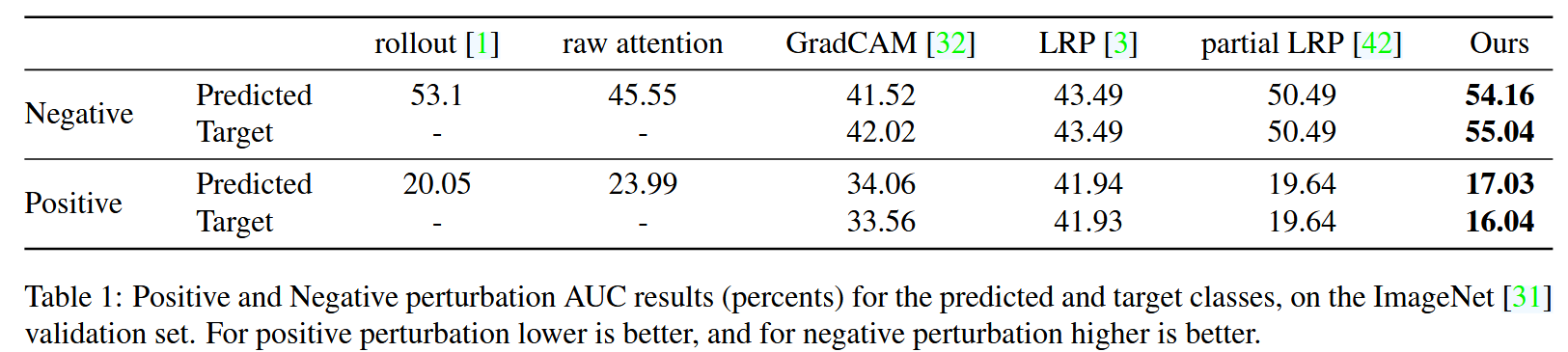
表1:ImageNet验证集上预测类和目标类的正负扰动AUC结果(百分比)。正扰动中,数值越低越好;负扰动中,数值越高越好。

表2:在ImageNet-Segmentation数据集上的分割性能(百分比)。数值越高越好。
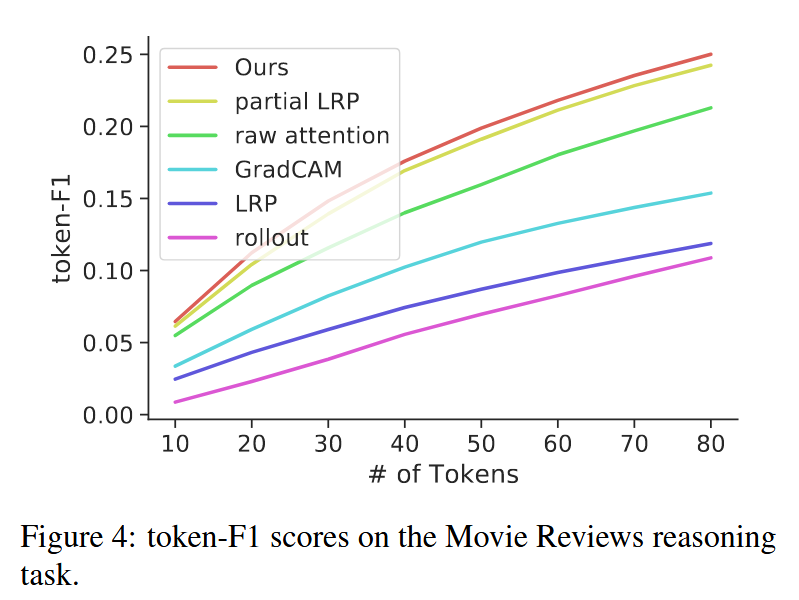
图4:电影评论推理任务中的token-F1分数。
- 定性评估:可视化对比显示,本文方法的结果更清晰、一致,其他基线方法性能参差不齐。在多物体图像且不同类别的可视化中,除GradCAM外,其他方法对不同类别的可视化相似,而本文方法能提供准确且不同的可视化结果。
- 消融研究:研究本文方法的三种变体,分别为Ours w/o
∇
A
(
b
)
∇A^{(b)}
∇A(b)(用
A
(
b
)
A^{(b)}
A(b)替代
∇
A
(
b
)
\nabla A^{(b)}
∇A(b) )、
∇
A
(
1
)
R
(
n
1
)
∇A^(1)R^{(n_1)}
∇A(1)R(n1)(仅在最接近输出的第1个模块应用方法,去除rollout组件)和
∇
A
(
B
−
1
)
R
(
n
B
−
1
)
\nabla A^{(B - 1)} R^{(n_{B - 1})}
∇A(B−1)R(nB−1) (仅在接近输入的第
B
−
1
B - 1
B−1个模块应用方法)。结果表明,去除rollout组件的∇A(1)R(n1)导致性能适度下降;两个单模块可视化中,靠近输出的第1个模块的注意力梯度和相关性组合更具信息性,且该单模块应用方法优于部分基线方法,证明本文方法的优势源于相关性计算和注意力图梯度的组合。
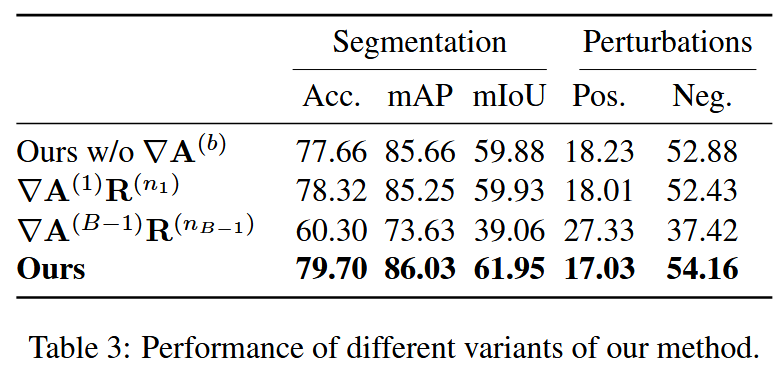
表3:我们方法不同变体的性能。
结论-Conclusion
这部分内容总结了Transformer可解释性研究的现状,强调了本文方法的贡献与优势,具体如下:
- Transformer注意力机制的局限性:虽然Transformer的自注意力机制将每个标记与[CLS]标记相连,直观上注意力强度可指示标记对分类的贡献,但实际上注意力值仅反映了Transformer网络或自注意力头的一个方面。通过在微调的BERT模型(用于NLP任务)和ViT模型上的实验表明,基于注意力的解释存在碎片化且竞争力不足的问题。
- Transformer可解释性研究的现状:尽管Transformer模型非常重要,但相关可解释性研究较少。与卷积神经网络(CNNs)相比,Transformer使用非正激活函数、频繁的跳跃连接,以及自注意力中的矩阵乘法难以建模等因素,使得为其他神经网络开发的可解释性方法(不包括计算成本高的黑箱方法)难以应用于Transformer。
- 本文方法的优势与成果:本文提出的方法针对上述挑战提供了具体解决方案。在与Transformer文献中的方法、LRP方法和GradCam方法对比时,本文方法在多个基准测试中取得了最先进的结果,为Transformer的可解释性研究提供了有效的途径。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











