




SATA: Spatial Autocorrelation Token Analysis for Enhancing the Robustness of Vision Transformers

本文 “SATA: Spatial Autocorrelation Token Analysis for Enhancing the Robustness of Vision Transformers” 提出空间自相关 token 分析(SATA)方法提升视觉 Transformer(ViT)的鲁棒性和性能。SATA 利用 token 特征间空间关系,在自注意力机制的前馈网络(FFN)块前对 token 按空间自相关得分分析分组,无需重新训练或微调就能集成到现有预训练 ViT 中,还降低 FFN 计算负载。实验显示,SATA 增强的 ViT 在 ImageNet-1K 分类中达到 94.9% 的 top-1 准确率,在多个鲁棒性基准测试中也取得新的最优成绩。
摘要-Abstract
Over the past few years, vision transformers (ViTs) have consistently demonstrated remarkable performance across various visual recognition tasks. However, attempts to enhance their robustness have yielded limited success, mainly focusing on different training strategies, input patch augmentation, or network structural enhancements. These approaches often involve extensive training and fine-tuning, which are time-consuming and resource-intensive. To tackle these obstacles, we introduce a novel approach named Spatial Autocorrelation Token Analysis (SATA). By harnessing spatial relationships between token features, SATA enhances both the representational capacity and robustness of ViT models. This is achieved through the analysis and grouping of tokens according to their spatial autocorrelation scores prior to their input into the Feed-Forward Network (FFN) block of the self-attention mechanism. Importantly, SATA seamlessly integrates into existing pre-trained ViT baselines without requiring retraining or additional fine-tuning, while concurrently improving efficiency by reducing the computational load of the FFN units. Experimental results show that the baseline ViTs enhanced with SATA not only achieve a new state-of-the-art top-1 accuracy on ImageNet-1K image classification (94.9%) but also establish new state-of-the-art performance across multiple robustness benchmarks, including ImageNet-A (top-1=63.6%), ImageNet-R (top-1=79.2%), and ImageNet-C (mCE=13.6%) , all without requiring additional training or fine-tuning of baseline models.
在过去几年里,视觉 Transformer(ViTs)在各种视觉识别任务中始终展现出卓越的性能。然而,增强其鲁棒性的尝试所取得的成果有限,主要集中在不同的训练策略、输入 patch 增强或网络结构改进上。这些方法通常需要大量的训练和微调,既耗时又耗费资源。为了解决这些难题,我们引入了一种名为空间自相关 Token 分析(SATA)的新方法。通过利用 token 特征之间的空间关系,SATA 增强了 ViT 模型的表征能力和鲁棒性。这是通过在将 token 输入到自注意力机制的前馈网络(FFN)模块之前,根据它们的空间自相关分数对 token 进行分析和分组来实现的。重要的是,SATA可以无缝集成到现有的预训练 ViT 基线模型中,无需重新训练或额外微调,同时通过降低 FFN 单元的计算负载来提高效率。实验结果表明,使用 SATA 增强的基线 ViT 不仅在 ImageNet-1K 图像分类任务上达到了新的最先进的 94.9% 的 Top-1 准确率,而且在多个鲁棒性基准测试中也建立了新的最先进性能,包括 ImageNet-A(Top-1准确率为63.6%)、ImageNet-R(Top-1准确率为79.2%)和ImageNet-C(平均腐败误差mCE为13.6%),且所有这些都无需对基线模型进行额外的训练或微调。
引言-Introduction
这部分主要介绍研究背景与动机,引出 SATA 方法并概述其优势和实验效果,具体内容如下:
- ViTs 的发展与挑战:近年来,ViTs 在计算机视觉应用中表现卓越,它借鉴自然语言处理中 Transformer 架构的成果,通过自注意力层捕捉图像 patch(token)间关系以完成视觉识别任务。尽管有研究表明 ViTs 因自注意力机制比卷积网络(ConvNets)更具鲁棒性,但这一观点受到质疑,有研究指出精心构建的 ConvNet 在泛化性和鲁棒性上可超越 ViTs。
- 增强 ViT 鲁棒性的现有方法及问题:当前提升 ViT 鲁棒性的技术,如 patch 增强、对比学习策略和网络调整等,虽有一定前景,但都存在显著缺陷,即需要在大规模数据集上进行大量重新训练或微调,对于大规模 ViT 架构而言,这一过程既耗时又耗资源。
- SATA 方法的提出:受卷积神经网络(CNNs)特征图存在空间相关性且随着网络层加深空间自相关性降低这一发现的启发,本文作者探究了 ViT 架构中的空间自相关性及其对性能和鲁棒性的影响,并提出 SATA 方法。该方法根据 token 的空间自相关分数对其进行分析和分组,防止不必要的 token 输入到自注意力机制的 FFN 模块。
- SATA 方法的优势与实验效果:SATA 可无缝集成到现有预训练 ViT 基线模型中,无需重新训练或额外微调,在增强鲁棒性的同时提高推理效率。实验显示,SATA 增强的 ViT 在 ImageNet-1K 图像分类任务以及多个鲁棒性基准测试中均取得优异成绩,达到了新的最先进水平。

图1:在 ImageNet-1K 上预训练的 Deit-Base/16 模型,其三层的类别 token 注意力图与空间自相关得分图的可视化对比。干净图像取自 ImageNet-1K 数据集的“金翅雀”类别,其对应的、具有最高严重程度 (5) 的损坏版本图像取自 ImageNet-C 数据集。
δ
δ
δ 表示在每个模块中,损坏图像的注意力图或空间自相关得分图与其对应的干净版本之间的余弦相似度。
相关工作-Related Work
这部分内容主要回顾了视觉 Transformer(ViT)和 ViT 鲁棒性相关的研究工作,分析了现有研究的成果与不足,为 SATA 方法的提出做了铺垫,具体内容如下:
- Vision Transformer
- 性能提升方向:ViTs 在计算机视觉任务中取得显著成功,多数改进集中于提升其精度或效率。通过特定的数据增强、先进的自注意力结构,以及设计混合模型(如 CvT 引入卷积层、CeiT 改进前馈网络)、多尺度特征学习模型(如 CrossViT、ViTAE)等方式,ViTs 展现出与卷积神经网络(CNNs)相比有竞争力或更优的性能。
- 效率优化方向:为创建高效的 ViT,部分研究聚焦于 token 的剪枝或合并。例如 ResT 使用重叠深度卷积构建高效自注意力模块,T2T-ViT 通过 Tokens-to-Token 模块进行 token 聚合,PiT 利用池化层减小空间尺寸,Dynamic-ViT 在推理时动态剪枝 token,CaiT 通过层缩放和类注意力机制优化 ViT 架构,还有研究提出简单的 token 合并技术且可能无需重新训练。
- ViTs 的鲁棒性
- 鲁棒性争议:关于 ViTs 与 CNNs 鲁棒性的比较,近期研究结果不一。部分研究认为 ViTs 对各种扰动和分布变化更具鲁棒性,但也有研究表明精心设计的 CNNs 在泛化和鲁棒性上可超越 ViTs。
- 增强鲁棒性的方法及问题:为提升 ViT 鲁棒性,已提出多种方法,包括网络结构调整(如 RVT 引入卷积茎和 token 池化、FAN 采用注意力通道处理设计)、抑制背景影响(如 RobustViT)、训练策略改进(如利用温度缩放平滑注意力权重、基于 patch 操作的负增强、引入注意力多样化损失)等。然而,这些方法大多需要大量训练或微调,且常以牺牲性能为代价来换取效率。相比之下,本文提出的 SATA 方法可应用于基线 ViT,无需额外训练且不会降低性能。
预备知识-Preliminaries
这部分主要介绍了理解后续 SATA 方法所需的预备知识,包括视觉 Transformer 中的多头自注意力机制以及地理空间自相关的概念,为 SATA 方法的提出和理解奠定了理论基础,具体内容如下:
- Vision Transformer 的多头自注意力机制:标准 ViT 将输入图像划分为 N N N 个 patch(token),并转换为 token 嵌入张量 X ∈ R N × d X \in \mathbb{R}^{N ×d} X∈RN×d,然后通过一系列 Transformer 块进行处理。Transformer 块利用自注意力机制聚合全局信息,具体过程为:对输入的 token 嵌入张量 X X X,分别应用参数为 W K W_{K} WK、 W Q W_{Q} WQ、 W V W_{V} WV 的线性变换,得到键 K = W K X K = W_{K}X K=WKX、查询 Q = W Q X Q = W_{Q}X Q=WQX 和值 V = W V X V = W_{V}X V=WVX ;接着利用 K K K 和 Q Q Q 生成成对的注意力图 M a t t = Softmax ( Q K t / d ) \text{M}_{att} = \text{Softmax} \left(Q K^{t} / \sqrt{d}\right) Matt=Softmax(QKt/d);最后根据注意力图 M a t t \text{M}_{att} Matt 聚合 token 特征 Self-Attention ( Q , K , V ) = M a t t V \text{Self-Attention} (Q, K, V)=\text{M}_{att} V Self-Attention(Q,K,V)=MattV. 为获得丰富的特征层次,Transformer 块采用多个自注意力头并行处理,其输出经前馈网络(FFN)进一步变换,FFN 输出的 N × d N ×d N×d 张量作为多头自注意力(MHSA)块的最终输出。
- 地理空间自相关:在地理建模中,空间自相关用于评估实体基于位置和值的空间相互依赖关系。正空间自相关表示相邻观测值相似,负空间自相关表示相邻观测值相反。通常有全局和局部两种测量方式,本文采用莫兰指数(Moran’s metric)来研究 ViT 中 token(patch)的空间依赖关系。对于由嵌入向量
x
i
∈
R
d
x_{i} \in \mathbb{R}^{d}
xi∈Rd 表示的
N
N
N 个观测值(token)集合
x
x
x,其相关属性为
a
a
a,局部莫兰指数
I
l
=
[
d
i
a
g
(
z
z
t
W
)
]
N
×
1
I_{l}=\left[diag\left(z z^{t} W\right)\right]_{N × 1}
Il=[diag(zztW)]N×1,其中
W
W
W 是空间权重矩阵,
z
=
a
−
μ
σ
z=\frac{a-\mu}{\sigma}
z=σa−μ 为归一化的 token 属性值,
μ
\mu
μ 和
σ
\sigma
σ 分别是
a
a
a 的均值和标准差。
最终的局部空间自相关描述符 s = I l − μ I l σ I l s=\frac{I_{l}-\mu_{I_{l}}}{\sigma_{I_{l}}} s=σIlIl−μIl,其中 μ I i \mu_{I_{i}} μIi 和 σ I l \sigma_{I_{l}} σIl 分别是 I l I_{l} Il 的均值和标准差。此外,给定 token 嵌入张量 X X X,其 token 全局上下文属性 a a a 可定义为 a = [ a i = 1 d ∑ t = 1 d x i ( t ) ] N × 1 a=\left[a_{i}=\frac{1}{d} \sum_{t=1}^{d} x_{i}(t)\right]_{N × 1} a=[ai=d1∑t=1dxi(t)]N×1.
空间自相关 Token 分析-Spatial Autocorrelation Token Analysis
这部分主要介绍了空间自相关 Token 分析(SATA)方法,包括其整体架构以及具体的 token 处理步骤,具体内容如下:
- SATA 模块架构:SATA 模块位于标准 ViT 块中注意力和 FFN 单元之间。通过观察不同块中 ViT token 嵌入张量的空间自相关分数
s
s
s,发现从第 6 层开始,token 的
∣
s
^
∣
|\hat s|
∣s^∣ 值往往较低。基于此,SATA 方法分两个步骤处理 token,以提高 ViT 的鲁棒性和性能。
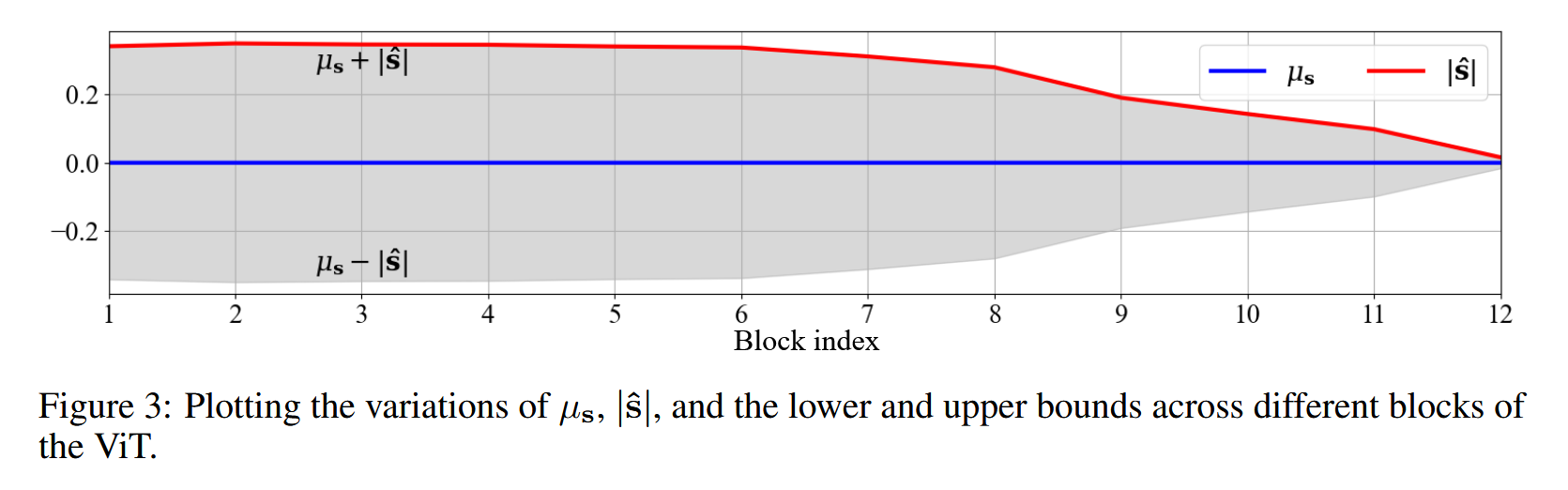
图3:绘制视觉 Transformer(ViT)不同模块中 μ s \mu_{s} μs、 ∣ s ^ ∣ |\hat s| ∣s^∣ 以及上下界的变化情况。 - Token Splitting(Token 分裂):SATA方法将 Transformer 中从 γ × B \gamma ×B γ×B( γ > 0 \gamma>0 γ>0, B B B 为 Transformer 的深度或块数)层往后的 token,依据空间自相关分数 s s s 划分为两组。其中, A = { x i ; s i < α ( μ s − ∣ s ^ ∣ ) 且 s i > α ( μ s + ∣ s ^ ∣ ) } \mathbb{A}=\left\{x_{i} ; s_{i}<\alpha\left(\mu_{s}-|\hat{s}|\right) 且 s_{i}>\alpha\left(\mu_{s}+|\hat{s}|\right)\right\} A={xi;si<α(μs−∣s^∣)且si>α(μs+∣s^∣)}, B = { x j ; α ( μ s − ∣ s ^ ∣ ) ≤ s j ≤ α ( μ s + ∣ s ^ ∣ ) } \mathbb{B}=\left\{x_{j} ; \alpha\left(\mu_{s}-|\hat{s}|\right)\leq s_{j}\leq \alpha\left(\mu_{s}+|\hat{s}|\right)\right\} B={xj;α(μs−∣s^∣)≤sj≤α(μs+∣s^∣)}。 α ( μ s − ∣ s ^ ∣ ) \alpha(\mu_{s}-|\hat{s}|) α(μs−∣s^∣) 和 α ( μ s + ∣ s ^ ∣ ) \alpha(\mu_{s}+|\hat{s}|) α(μs+∣s^∣) 分别为下限和上限, α α α 是控制因子,其具体取值和 γ \gamma γ 的选择在后续章节讨论。
- Token Grouping(Token 分组):对于落在上下限范围之外(即 α ( μ s ± ∣ s ^ ∣ ) \alpha(\mu_{s} \pm|\hat{s}|) α(μs±∣s^∣))的 token,即集合 A 中的 token,采用二分匹配算法进行处理。具体步骤为:先将集合 A 大致等分为两个子集 A 1 A_{1} A1 和 A 2 A_{2} A2;接着从 A 1 A_{1} A1 中的每个 token 向 A 2 A_{2} A2 中与其最相似的 token 连一条边;然后将相连的 token 通过平均它们的特征进行合并;剩余未连接的 token 作为残余 token。最终,SATA 模块的输出 token 由集合 B 中的 token 和二分匹配算法得到的合并 token 连接而成,并输入到 FFN 模块。残余 token 则与 FFN 的输出连接,形成新 ViT 块的最终输出,以恢复原始 token 数量 N N N.
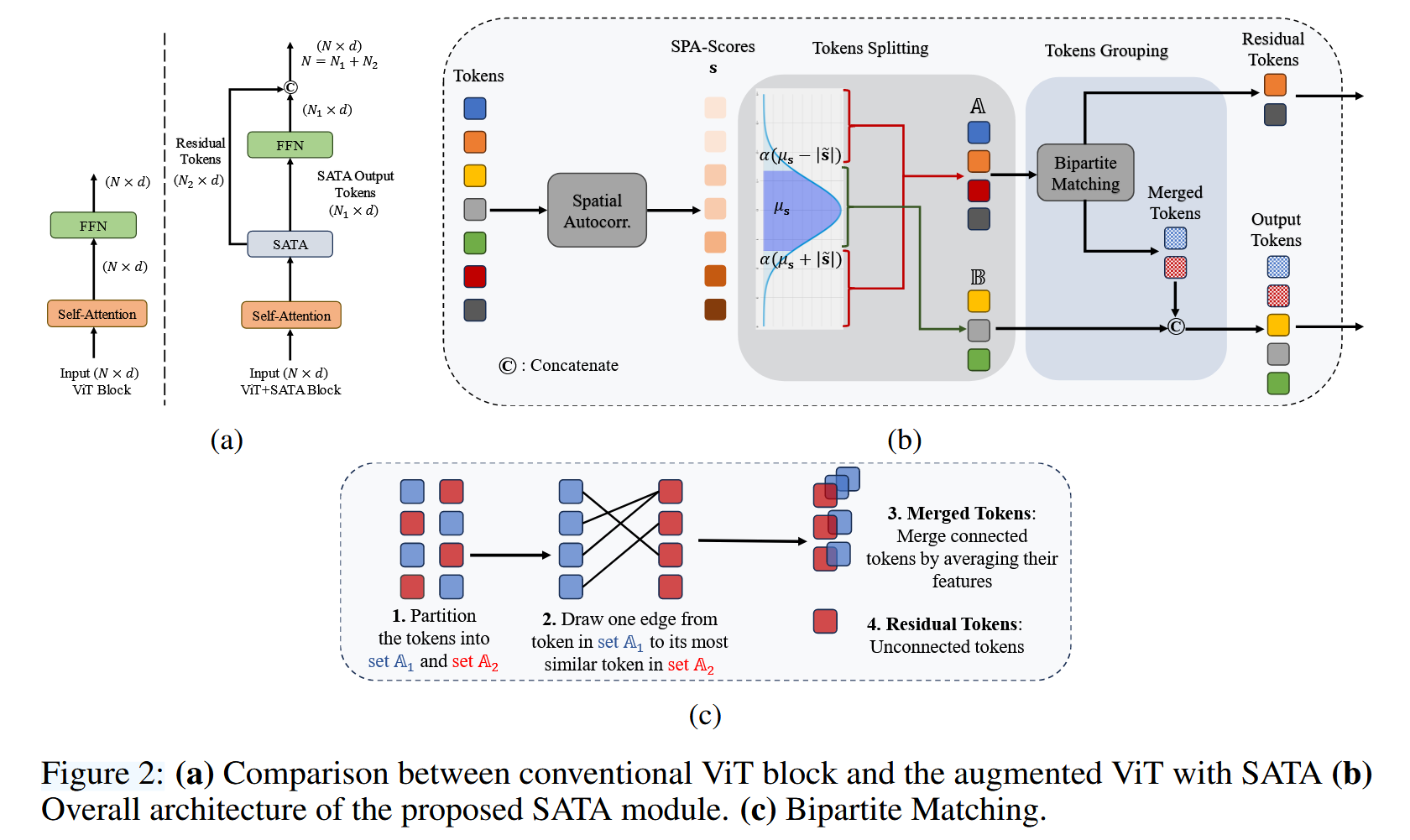
图2:(a) 传统 ViT 模块与添加了 SATA 的增强型 ViT 的对比;(b) 所提出的 SATA 模块的整体架构;(c) 二分匹配。
实验结果与分析-Experiment Results & Analysis
这部分主要介绍了 SATA 方法的实验设置、结果及分析,验证了 SATA 在提升模型性能和鲁棒性方面的有效性,具体内容如下:
- 实验设置
- 实验环境:在 NVIDIA V100 GPU 上,以 224×224 的图像分辨率开展实验,将 SATA 模块集成到多种预训练的通用视觉 Transformer(如 Deit-Tiny/16、Deit-Small/16 等)中,得到不同尺寸的模型(SATA-T、SATA-S等)。
- 评估基准:采用 ImageNet-1K 数据集评估标准性能;从三个维度评估鲁棒性,即利用 FGSM 和 PGD 攻击生成的对抗样本在 ImageNet-1K 验证集上测试对抗鲁棒性,使用包含15种算法生成的不同程度 corruption 的 ImageNet-C 评估常见腐败鲁棒性,通过 ImageNet-R 和 ImageNet-Sketch 评估分布外鲁棒性。
- 实验结果
- 标准性能评估:SATA 显著优于其他基于 Transformer 和 CNN 的分类模型。不同版本的 SATA 增强 ViT 模型在 ImageNet-1K 上取得了新的最先进的 top-1 准确率,且计算成本更低,提升了效率。
- 对抗鲁棒性评估:在白盒攻击(FGSM 和 PGD)测试中,SATA 模型表现优异,相比之前的 ViT 变体,在 FGSM 攻击下有超过20%的提升;在自然对抗鲁棒性方面, SATA-T 性能与部分先进方法相当,而 SATA 在相似尺寸模型中优势明显,超越其他模型约 50%。
- 常见腐败鲁棒性评估:在 ImageNet-C 上,SATA 方法大幅降低了模型的平均腐败误差(mCE)。如将 DeiT-Ti 的 mCE 从71.1%降至51.1%,在其他较大 ViT 组中,SATA 模型的 mCE 约为28%,相比其他方法有显著提升,确立了新的最优结果。
- 分布外鲁棒性评估:在 ImageNet-R 和 ImageNet-Sketch 数据集上,SATA 增强的 ViT 模型的 top-1 准确率优于其他 ViT 模型,表明 SATA 能有效捕捉特征分布变化,提升模型的分布外泛化能力。
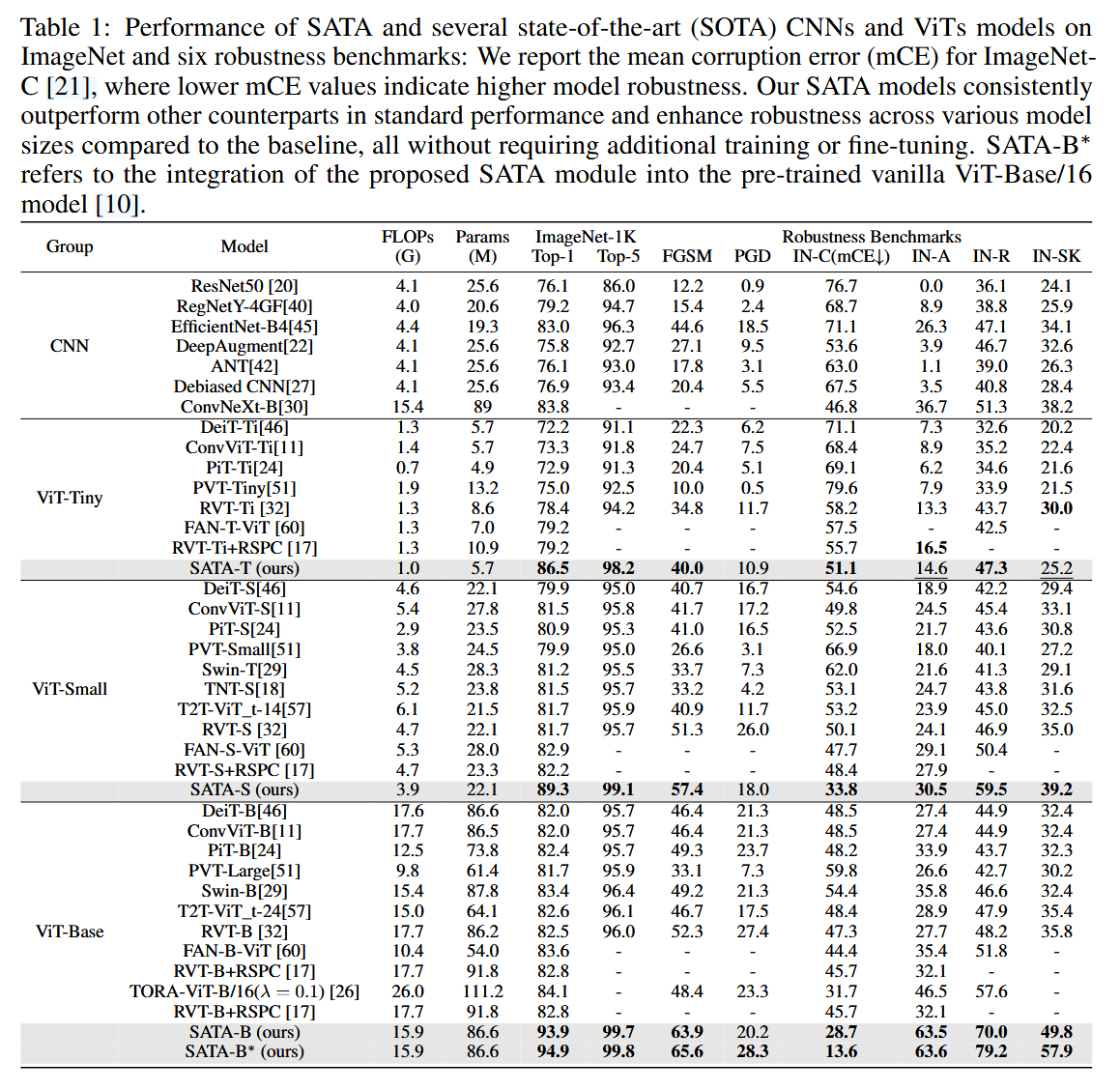
表1:SATA 与几种最先进的(SOTA)卷积神经网络(CNNs)和视觉 Transformer(ViTs)模型在 ImageNet 数据集以及六个鲁棒性基准测试中的性能表现:我们报告了 ImageNet-C 的平均损坏误差(mCE),mCE 值越低表明模型的鲁棒性越高。我们的 SATA 模型在标准性能方面始终优于其他同类模型,并且与基线模型相比,在各种模型规模下都增强了鲁棒性,且所有这些都无需额外的训练或微调。SATA-B ∗ ^∗ ∗ 指的是将本文提出的 SATA 模块集成到预训练的普通 ViT-Base/16 模型中。
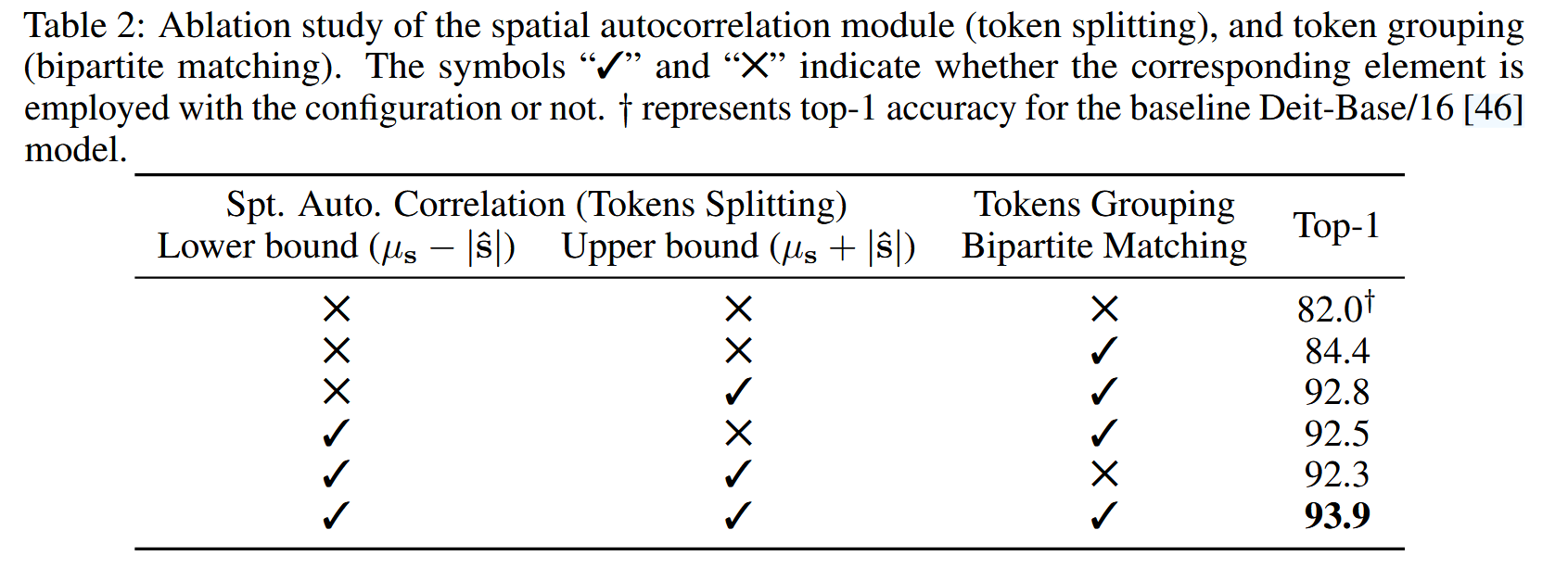
- 消融实验
- Token 分裂和分组:评估 token 分裂和分组模块的作用,结果表明基于空间自相关分数上下界的 token 分裂和二分匹配的 token 分组均有效,且两者结合能进一步提升模型性能。
表2:空间自相关模块(token 分裂)和 token 分组(二分匹配)的消融研究。符号“✓”和“✕”分别表示相应元素在配置中是否被采用。 † † † 代表基线 Deit-Base/16 模型的 top-1 准确率。
- 起始块阈值( γ \gamma γ):研究 γ \gamma γ 对模型的影响,发现从 0.4 × B 0.4×B 0.4×B 往后应用 SATA 可提升效率并超越基线准确率,为平衡准确率和效率,实验中 γ \gamma γ 取 0.7。
- 上下界控制因子(
α
\alpha
α):探讨
α
\alpha
α 的影响,结果显示
α
=
1
\alpha = 1
α=1 时 SATA-B 在 ImageNet-1K 上性能最优。
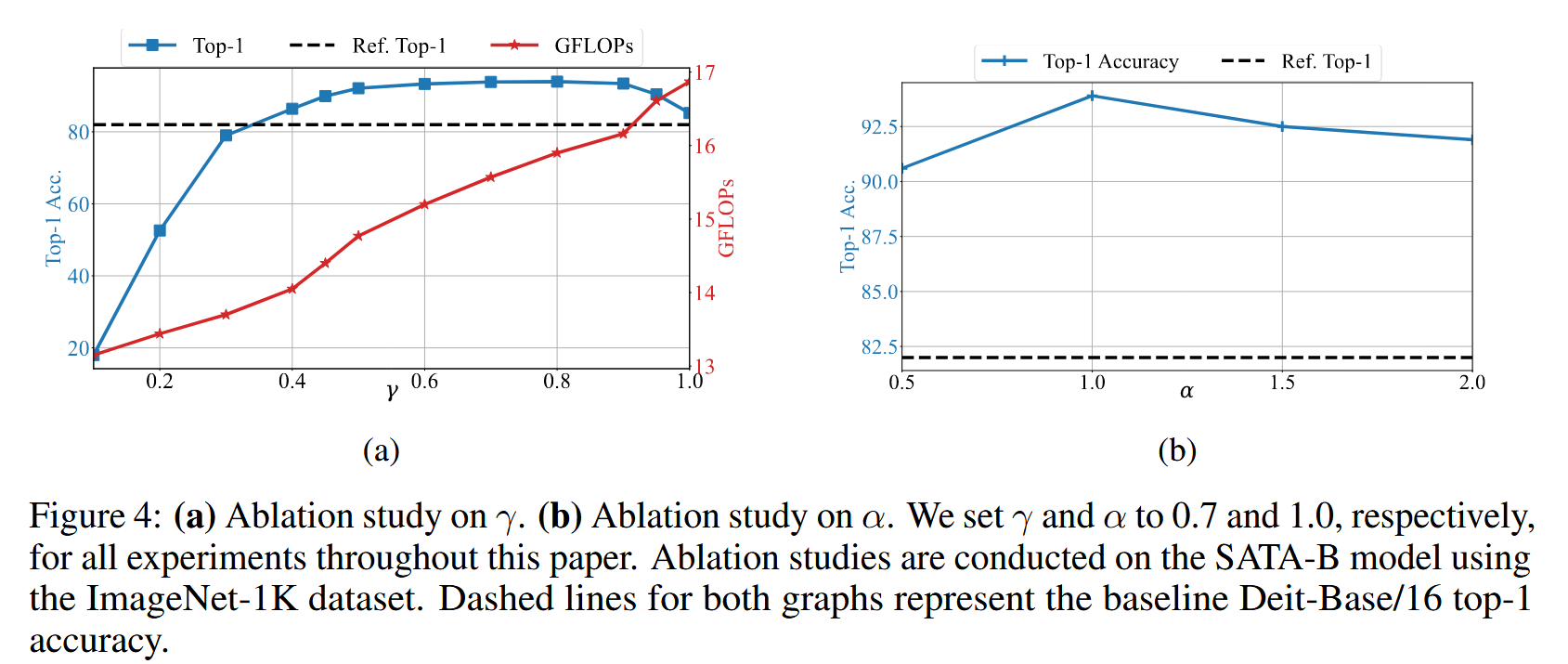
图4:(a) 对参数 γ γ γ 的消融研究;(b) 对参数 α α α 的消融研究。在本文的所有实验中,我们分别将 γ γ γ 和 α α α 设置为 0.7 和 1.0。消融研究是在使用 ImageNet-1K 数据集的 SATA-B 模型上进行的。两张图中的虚线均表示基线 Deit-Base/16 的 top-1 准确率。
- Token 分裂和分组:评估 token 分裂和分组模块的作用,结果表明基于空间自相关分数上下界的 token 分裂和二分匹配的 token 分组均有效,且两者结合能进一步提升模型性能。
- 可视化与讨论:计算干净和损坏图像对的类 token 注意力图与空间自相关分数的余弦相似度,发现空间自相关分数的相似度在早期提升且始终较高,表明 SATA 能提供更稳定可靠的特征表示,增强模型对各种损坏的鲁棒性。同时,可视化 token 分裂过程发现,干净和噪声输入下相应集合中的 token 相似,进一步证明了 SATA 的鲁棒性。
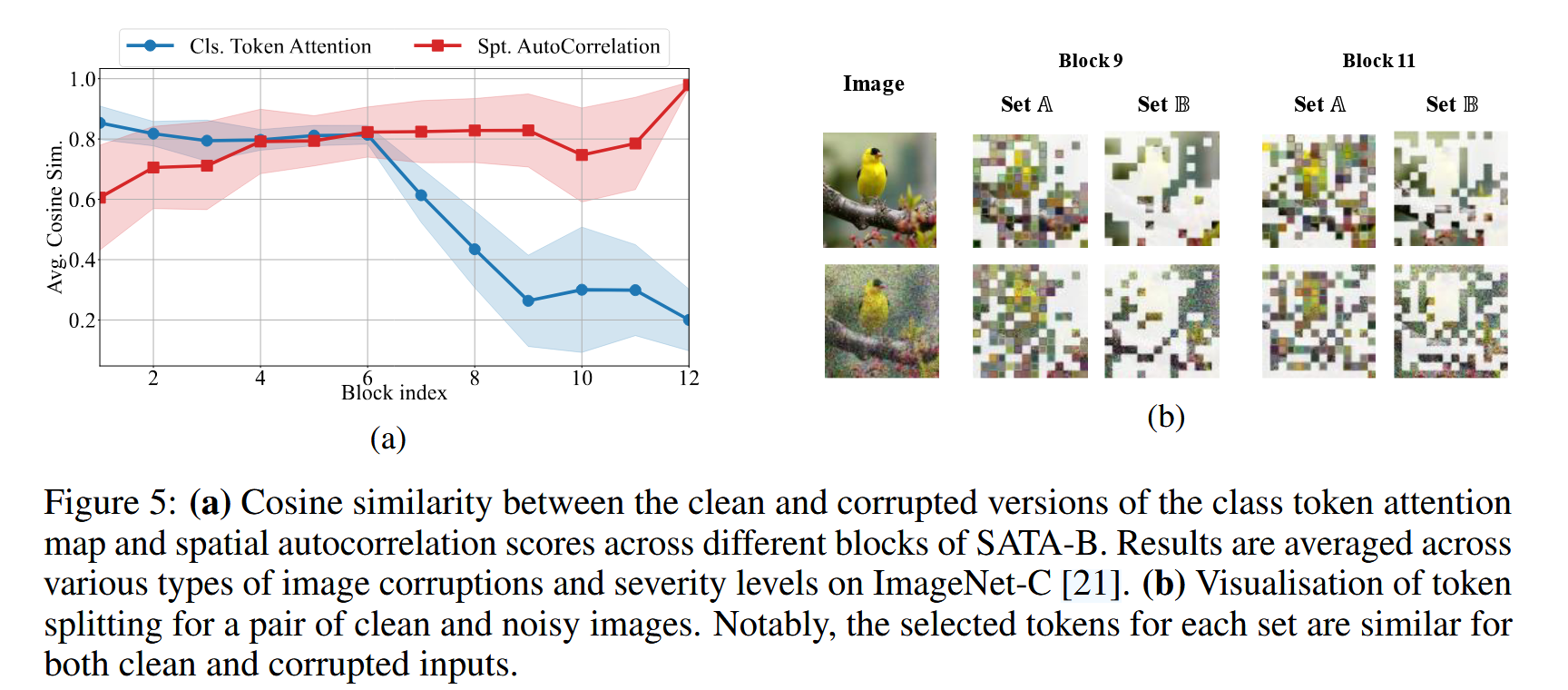
图5:(a) SATA-B 不同模块中,干净图像和受损图像的类别 token 注意力图以及空间自相关分数之间的余弦相似度。结果是在ImageNet-C中各种类型的图像损坏和严重程度上取平均值得到的。(b) 一对干净图像和含噪图像的 token 分割可视化。值得注意的是,对于干净输入和受损输入,每个集合中选择的 token 都很相似。
结论-Conclusion
这部分内容总结了 SATA 方法的研究成果,阐述了其优势和应用潜力,并提出了未来的研究方向,具体如下:
- 研究成果总结:本文提出 SATA 方法,旨在提升视觉 Transformer(ViT)对各类损坏的性能和鲁棒性。SATA 利用简单而有效的空间自相关方案,挖掘 token 特征间的空间依赖关系,在提高模型表征能力、鲁棒性的同时,降低计算成本,提升了效率。
- 实验效果概述:实验结果表明,SATA 增强的 ViT 能提供稳定可靠的特征表示。在 ImageNet-1K 分类任务中达到了最先进的性能,在多个鲁棒性评估基准上也树立了新的标杆,且这些成果的取得都无需对基线模型进行额外训练或微调。
- 未来研究方向:一是适配基于窗口的和混合 ViT 架构,探索 SATA 在目标检测和分割等任务中的应用,以进一步提升其在不同视觉任务中的性能;二是探索 SATA 在其他基于 Transformer 的领域,如大语言模型(LLMs)中的应用,拓展其应用范围和影响力。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











