







SlowFormer: Adversarial Attack on Compute and Energy Consumption of Efficient Vision Transformers

本文 “SlowFormer: Adversarial Attack on Compute and Energy Consumption of Efficient Vision Transformers” 指出,深度学习模型在推理时的计算优化有进展,自适应计算减少方法有潜力,但易受攻击。作者设计了针对 A-ViT、ATS 和 AdaViT 三种高效视觉 Transformer 方法的通用对抗图块攻击 SlowFormer,实验表明能大幅增加计算量,如在 A-ViT 上攻击成功率达 100% ,还提出对抗训练防御方法,虽能降低攻击效果但仍有提升空间,希望推动相关攻击和防御研究。
摘要-Abstract
Recently, there has been a lot of progress in reducing the computation of deep models at inference time. These methods can reduce both the computational needs and power usage of deep models. Some of these approaches adaptively scale the compute based on the input instance. We show that such models can be vulnerable to a universal adversarial patch attack, where the attacker optimizes for a patch that when pasted on any image, can increase the compute and power consumption of the model. We run experiments with three different efficient vision transformer methods showing that in some cases, the attacker can increase the computation to the maximum possible level by simply pasting a patch that occupies only 8% of the image area. We also show that a standard adversarial training defense method can reduce some of the attack’s success. We believe adaptive efficient methods will be necessary in the future to lower the power usage of expensive deep models, so we hope our paper encourages the community to study the robustness of these methods and develop better defense methods for the proposed attack.
最近,在降低深度模型推理时的计算量方面取得了许多进展。这些方法既能减少深度模型的计算需求,又能降低其功耗。其中一些方法会根据输入实例自适应地调整计算量。我们发现,这类模型可能容易受到通用对抗图块攻击,攻击者通过优化一个图块,将其粘贴到任何图像上时,都能增加模型的计算量和功耗。我们对三种不同的高效视觉 Transformer 方法进行了实验,结果表明,在某些情况下,攻击者只需粘贴一个仅占图像面积 8% 的图块,就能将计算量提升到最大可能水平。我们还证明了标准的对抗训练防御方法可以在一定程度上降低攻击的成功率。我们认为,未来自适应高效方法对于降低昂贵的深度模型的功耗是必要的,因此我们希望我们的论文能鼓励该领域研究这些方法的稳健性,并针对所提出的攻击开发更好的防御方法。
引言-Introduction
该部分主要介绍了研究背景、攻击思路、攻击特点和研究贡献,旨在揭示自适应计算的视觉 Transformer 模型存在的安全隐患,具体内容如下:
- 研究背景与动机:深度学习在降低模型推理计算量方面取得进展,分为不依赖输入(如权重剪枝、模型量化)和依赖输入(自适应计算)两类方法。自适应计算方法因能根据输入复杂度调整计算量,在实际应用中(如自动驾驶)具有重要价值,有望成为未来关键研究方向。计算量减少通常可降低功耗,这对电池供电的移动设备至关重要,如 iPhone 电池容量增长缓慢,而计算能力提升显著,同时,像 Starship 送货机器人,增加少量功耗就会大幅缩短电池续航。
- 攻击思路与目标:提出自适应计算模型易受攻击的观点,攻击者可通过修改输入增加模型计算量和功耗。研究旨在设计通用对抗图块,将其粘贴到任意图像上,使模型计算量和功耗上升。该攻击对依赖电池的安全关键型移动系统威胁极大。研究通过衡量推理时 FLOPs 的变化评估攻击效果(假设功耗与 FLOPs 正相关),并针对 A-ViT、ATS 和 Ada-VIT 三种高效视觉 Transformer 方法展开攻击实验。
- 攻击的独特性:与以往像素级扰动攻击不同,本文的通用图块攻击更具实用性。在实际应用中,修改真实机器人图像像素难以实现,而通用图块不依赖特定图像,可从训练数据泛化到测试数据。
- 研究贡献:证明高效视觉 Transformer 方法易受通用图块攻击,该攻击可显著增加计算量和功耗。通过对三种不同方法的实验,展示了攻击的有效性。此外,研究表明标准对抗训练防御方法能在一定程度上降低攻击成功率,为后续研究提供了方向 。
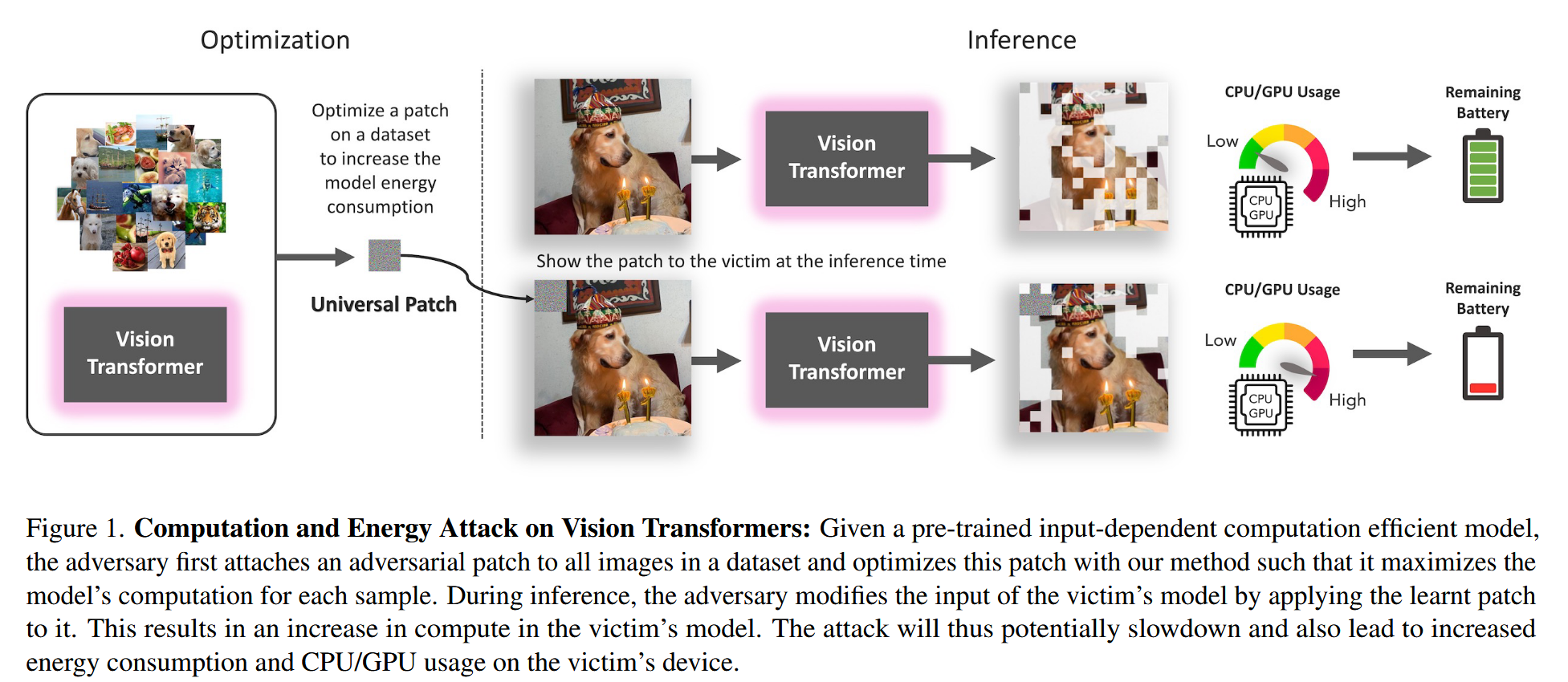
图1. 对视觉 Transformer 的计算和能量攻击:给定一个预先训练好的、依赖输入的高效计算模型,攻击者首先将一个对抗图块附加到数据集中的所有图像上,并使用我们的方法对这个图块进行优化,以便针对每个样本最大化模型的计算量。在推理过程中,攻击者通过将学习到的图块应用到受害者模型的输入上,对其进行修改。这会导致受害者模型的计算量增加。因此,这种攻击可能会使受害者设备的运行速度变慢,还会导致其能耗以及CPU/GPU使用率上升。
相关工作-Related Work
该部分主要梳理了与本文研究紧密相关的工作,包括视觉 Transformer、高效视觉Transformer、动态计算、对抗攻击以及能量攻击等方面的研究进展,为本文的研究提供了坚实的背景基础,具体内容如下:
- 视觉 Transformer:自首个视觉 Transformer 被提出后,其在视觉领域迅速走红,在众多计算机视觉任务中表现卓越,同时也是自监督学习和视觉语言模型的核心架构。本文聚焦于针对视觉 Transformer 计算和能源效率的攻击研究。
- 高效视觉 Transformer:鉴于视觉 Transformer 的重要性和广泛应用,诸多研究致力于提升其效率。相关工作涵盖了基于 token 剪枝去除无信息 token、合并相似 token、引入线性注意力机制改进自注意力模块的二次计算问题,以及设计限制 token 注意力跨度的高效架构等方面。本文主要针对基于 token 剪枝且计算量随输入样本变化的高效 Transformer 展开攻击。
- 动态计算:在降低视觉模型计算量的方法中,知识蒸馏、模型量化和模型修剪等传统方法在推理时计算量固定。与之不同,动态计算方法根据输入的复杂性,通过动态提前退出、跳过层、选择性激活神经元等方式改变计算量,还包括像素级和区域级的动态架构以及自适应调整图像分辨率等方法。近期,一些输入动态的 Transformer 架构也相继出现。
- 对抗攻击:对抗攻击旨在通过在推理时对图像样本施加针对性扰动或图块,使模型做出错误判断,同时也有相应的防御措施来应对此类攻击。Patch-Fool 研究了基于对抗图块对 Transformer 的攻击,部分工作还关注了对抗攻击在视觉 Transformer 上的可迁移性。然而,以往大多数对抗攻击主要针对模型准确性,忽视了模型效率。
- 能量攻击:近期出现了一些针对神经网络的能量对抗攻击研究,如 ILFO、DeepSloth、GradAuto 等分别对不同的动态神经网络进行攻击,但这些方法大多采用基于图像特定扰动的攻击方式。本文与这些研究相关,但重点在于设计针对视觉 Transformer 的通用对抗图块攻击,并提供了潜在的防御策略。
计算与能量攻击-Computation and Energy Attack
该部分详细介绍了针对高效视觉 Transformer 的计算和能量攻击方法,包括威胁模型的设定以及对三种不同高效视觉 Transformer 方法的具体攻击策略,具体内容如下:
- 威胁模型:攻击者能够获取受害者训练好的深度模型,并通过修改输入来增加模型的能量消耗和计算需求,且攻击与模型的准确率无关。为使攻击场景更具现实性,假设攻击者仅能通过在输入图像上粘贴一个通用的、与图像无关的图块来修改输入。在推理时,将预先训练好的图块粘贴到测试图像上,再输入到网络中进行处理。由于攻击者仅操作输入图像而不改变网络参数,因此被攻击的模型必须具有依赖于输入图像的动态计算特性。
- 攻击高效视觉 Transformer 的方法
- 通用对抗图块:使用一个通用的对抗图块来攻击 Transformer 的计算效率。这个图块在训练集上进行优化,训练完成后在所有测试图像上使用。图块的像素值初始化为服从 [0, 255] 均匀分布的独立同分布样本,在训练过程中,每次迭代时将图块粘贴到小批量样本上,并通过更新图块来增加被攻击网络的计算量,每次迭代后将图块值投影到 [0, 255] 并量化到 256 个均匀级别。在整个过程中,使用的是预训练网络,其参数在训练和评估攻击时均不更新。
- 针对不同模型的攻击
- 攻击 A-ViT:A-ViT 通过自适应修剪图像 token 来加快推理速度并尽量减少精度损失。在攻击 A-ViT 时,由于关注的是计算量而非特定任务性能,因此使用 − ( α d L d i s t . + α p L p o n d e r ) -(\alpha_{d} L_{dist. }+\alpha_{p} L_{ponder }) −(αdLdist.+αpLponder) 作为损失函数来训练图块以增加推理计算量。也可通过在损失函数中加入或减去任务损失 L t a s k L_{task } Ltask 来保持或损害任务性能。
- 攻击 AdaViT:AdaViT 通过在每个 Transformer 块前插入并训练决策网络,来动态决定保留或激活哪些图块、自注意力头和 Transformer 块。攻击时,通过将计算目标r值设为 0 并取负计算损失 L u s a g e L_{usage } Lusage 来训练图块,以最大化保留相应部分的概率。同时,也可选择包含或排除任务损失 L c e L_{ce } Lce 来攻击预测性能。
- 攻击 ATS:ATS根据分类 token 对其他 token 的关注程度为每个 token 分配重要性分数,并据此采样 token。为了在 ATS 中最大化计算量,通过优化图块使分类 token 对其他 token 的注意力为均匀分布,使用均方误差(MSE)损失 L = ∑ i = 2 N ∥ A 1 , i − 1 N ∥ 2 2 \mathcal{L}=\sum_{i=2}^{N}\left\| \mathcal{A}_{1, i}-\frac{1}{N}\right\| _{2}^{2} L=∑i=2N A1,i−N1 22 进行优化。对于多头注意力层,计算每个头的损失并求和,且在模型的所有 ATS 层应用该损失并进行加权求和优化。
防御-Defense
该部分主要介绍了针对文中攻击方法的两种防御策略,分析了其优劣,具体内容如下:
- 使用非动态高效方法防御:一种较为直接但效果欠佳的防御方式是仅采用非动态高效方法,如权重剪枝。这类方法的计算量减少是确定性的,不依赖于输入,因此不受输入变化的影响,也就不存在被文中攻击方式利用的风险。然而,由于它们无法利用图像的简单性来进一步优化计算,往往难以实现较高的计算效率,在实际应用场景中存在一定的局限性。
- 采用标准对抗训练防御:作者采用标准对抗训练作为更有效的防御手段。在常规的对抗训练中,每次训练模型时会加载一张图像,对其进行攻击,然后使用正确标签参与模型训练。但由于本文攻击的通用图块具有跨图像的特性,不能直接应用常规方式。因此,作者维护了一组对抗图块,在训练模型的每次迭代中,从这组图块中随机(均匀)采样一个,并将其用于输入,同时优化高效模型的原始损失来训练一个更具鲁棒性的模型。
为了使对抗图块集更好地适应正在训练的模型,作者在每个训练周期(epoch)的20%进度点中断训练,优化生成一个新的图块并添加到图块集中。为控制训练的计算成本,在生成新图块时仅使用 500 次迭代进行优化。实验结果表明,这种防御方法能够在一定程度上减少攻击的成功率,但防御后的模型计算量仍高于未受攻击时的模型,说明仍有进一步改进的空间。
实验-Experiments
该部分通过多组实验评估了 SlowFormer 攻击的效果、进行了消融实验,并测试了对抗训练防御的有效性,具体内容如下:
-
攻击高效视觉 Transformer 的实验
- 实验设置:选用 ImageNet-1K 和 CIFAR-10 数据集。使用 Top-1 准确率和以 GFLOPs 为单位的平均计算量衡量模型性能,定义攻击成功率(Attack Success)评估攻击效果,公式为 ( F L O P s s t a c k − F L O P s m i n ) ( F L O P s m a x − F L O P s m i n ) \frac{( FLOPs _{stack }-FLOPs_{min })}{(FLOPs_{max }-FLOPs_{min })} (FLOPsmax−FLOPsmin)(FLOPsstack−FLOPsmin). 设置随机图块(Random Patch)、非目标性通用对抗图块(NTAP)、目标性通用对抗图块(TAP)作为基线方法。实验基于 PyTorch 框架,使用特定大小的图块,在指定图像尺寸下训练和测试,利用 AdamW 优化器和多块 NVIDIA RTX 3090 GPU 进行计算。
- 实验结果:在 A-ViT 上,SlowFormer 攻击能完全抵消其计算量减少的效果,攻击成功率达100%;在 ATS 和 AdaViT 上也有较高攻击成功率,分别为 60% 和 40%(ViT-Small 模型)。随机图块攻击对模型准确率和计算量影响甚微,NTAP 和 TAP 这两种标准对抗攻击基线不仅使模型准确率近乎降至 0%,还进一步降低了被攻击的高效模型的计算量。在 CIFAR-10 数据集上,SlowFormer 对 A-ViT 和 ATS 的攻击同样有效,攻击成功率分别为 40% 和 34%。通过可视化展示,攻击前高效模型在网络后层仅保留高度相关的 token,攻击后几乎整个图像都在模型各层传递,增加了计算量和功耗。
表1. 对高效视觉 Transformer 的计算和能量攻击:将我们的攻击效果与基线方法进行比较,基线方法包括无攻击、随机图块、目标性(TAP)和非目标性(NTAP)对抗图块,这些方法应用于三种不同架构的输入动态计算高效预训练模型。给定架构的最大可能计算量以粗体显示。在 A-ViT 上,我们通过攻击完全抵消了高效方法所获得的效率提升,攻击成功率达到100%。我们在所有方法上都实现了较高的攻击成功率,而基线方法如预期的那样,对增加计算量没有帮助。
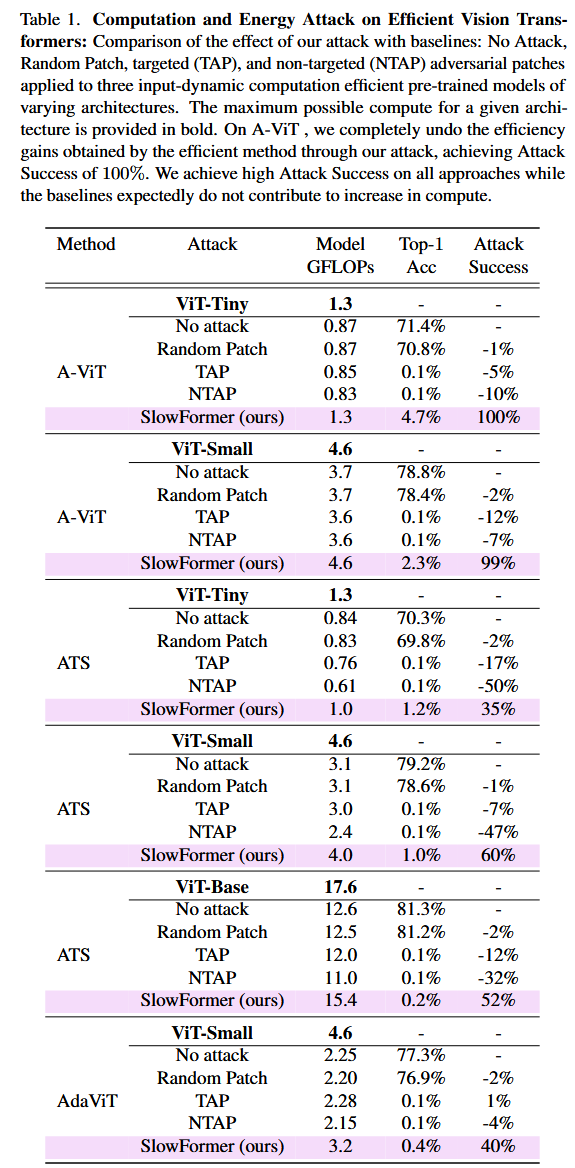
表2. CIFAR10 数据集上的结果。我们报告在 CIFAR10 数据集上的结果,以表明我们的攻击并非仅针对 ImageNet 数据集。与 ImageNet 相比,CIFAR-10 是一个小数据集,因此会产生一个计算效率极高的 A-ViT 模型。我们的攻击将浮点运算次数(FLOPs)从 0.11 增加到 0.58,几乎恢复了原始 FLOPs 减少量的41%.
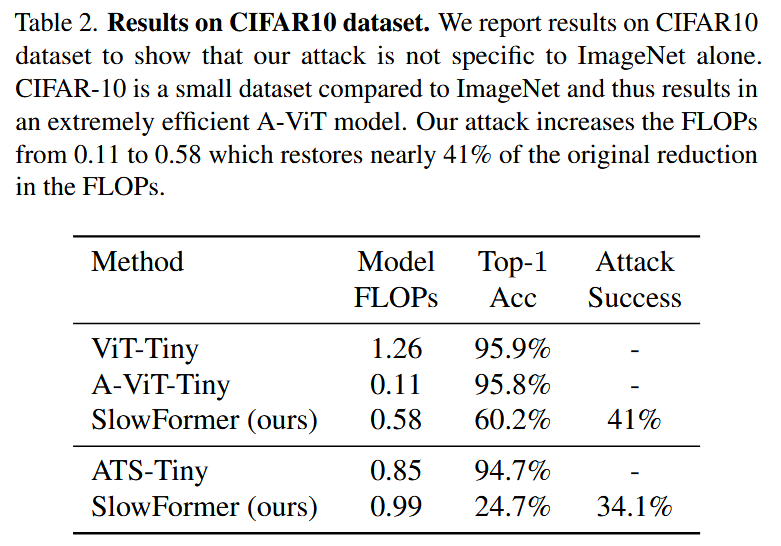
图2. 对视觉 Transformer 的能量攻击可视化。我们在攻击时使用大小为 32 的图块(位于左上角)。图中展示了 A-ViT-Small 第8层被修剪的 token。我们的攻击能够恢复大部分被修剪的 token,从而导致计算量和功耗增加。值得注意的是,尽管图块尺寸相当小且位于视野角落,但它却能影响网络的整个计算流程。这可能是由于 Transformer 中的全局注意力机制。我们对有、无我们攻击的 A-ViT-Small 进行了可视化展示。


图3. 优化图块的可视化:我们展示了针对三种高效方法各自学习到的通用图块。
-
消融实验
-
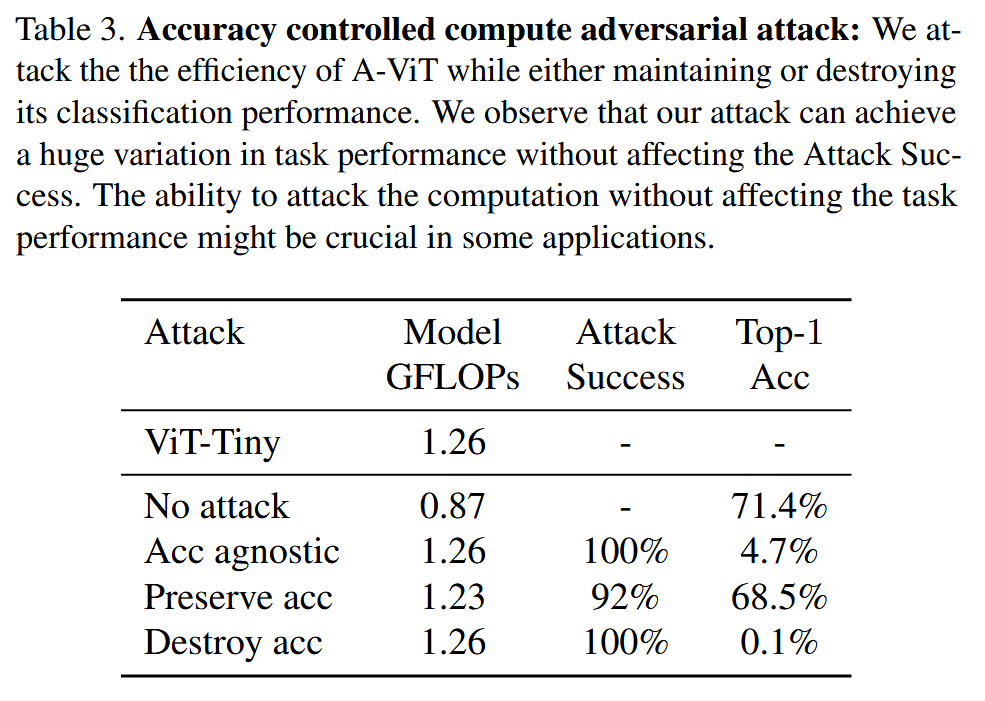
准确率可控的计算对抗攻击:在 A-ViT 的 ViT-Tiny 模型上实验发现,通过在图块优化中加入任务损失,能在攻击模型计算量的同时,灵活调整任务性能,在保持高攻击成功率的情况下,大幅改变模型准确率。
表3. 精度可控的计算对抗攻击:我们在攻击 A-ViT 效率的同时,要么维持要么破坏其分类性能。我们观察到,我们的攻击可以在不影响攻击成功率的情况下,使任务性能产生巨大变化。在某些应用中,在不影响任务性能的前提下攻击计算量的能力可能至关重要。
-
图块大小的影响:在 A-ViT 的 ViT-Small 模型上,研究不同图块大小对攻击成功率的影响。发现即使使用仅占输入图像面积2%的32×32大小的图块,攻击成功率仍可达73%,表明较小的图块也能有效影响模型计算量。
表4. 图块大小的影响:分析对抗图块大小对 A-ViT 攻击成功率的影响。即使使用尺寸较小(32×32)、仅占图像面积 2% 的图块,我们的攻击也相当成功。有趣的是,位于视野角落的小图块会影响整个 Transformer 模型的计算流程。这可能是由于 Transformer 中的全局注意力机制。

-
图块位置的影响:对 A-ViT 的 ViT-Tiny 模型,随机改变图块在图像上的粘贴位置进行实验,发现所有位置的攻击成功率均为 100%,说明图块位置对攻击效果影响不大。
-
扰动攻击:除基于图块的攻击,高效 Transformer 也易受基于扰动的攻击。实验表明,随着扰动强度增加,模型计算量和攻击成功率上升,同时准确率下降。
表5. 在 ImageNet 上的对抗扰动攻击。这些高效方法也容易受到基于通用扰动的攻击。我们对扰动设置了 ℓ ∞ \ell_{\infty} ℓ∞ 范数约束。

-
-
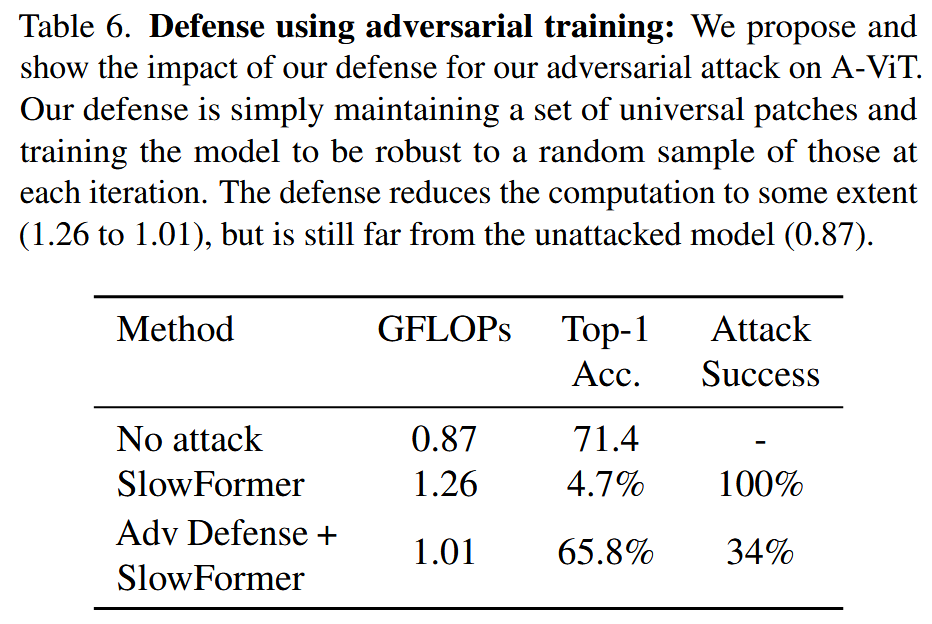
基于对抗训练的防御实验:采用维护一组通用图块并在训练中随机采样的对抗训练防御方法。以 A-ViT 为对象进行实验,结果显示,原 A-ViT 模型降低了计算量,SlowFormer 攻击使其计算量回升且攻击成功率为100%,而对抗训练防御能将计算量降低到一定程度(从1.26降至1.01),攻击成功率降至34%,但仍高于未受攻击的模型,说明该防御方法有一定效果,但仍需改进。
表6. 基于对抗训练的防御:我们提出并展示了针对 A-ViT 对抗攻击的防御方法及其效果。我们的防御方法很简单,即维护一组通用图块,并在每次迭代时,通过使用这些图块中的随机样本训练模型,使其具备更强的鲁棒性。该防御在一定程度上降低了计算量(从1.26降至1.01),但与未受攻击的模型(0.87)相比,仍有较大差距。
结论-Conclusion
该部分总结了高效视觉 Transformer 模型的研究现状、本文的研究发现、防御措施及未来展望,强调了研究对抗攻击和防御方法的重要性,具体如下:
- 研究现状与重要性:当前出现了根据输入自适应调整计算的高效视觉 Transformer 模型,这种自适应计算的方式是重要研究方向,未来有望取得更多进展。它能根据输入动态调整计算量,提升效率,在实际应用中具有显著优势。
- 研究发现:本文研究表明,现有自适应计算的高效视觉 Transformer 模型易受到通用对抗图块攻击。在推理时,这种攻击会增加模型计算量,进而提升功耗。实验针对三种先进的高效 Transformer 模型展开,结果显示,在部分设置下,基于训练数据优化的小图块能在测试数据中将模型计算量提升至最大可能水平。这揭示了自适应计算模型在安全性方面存在的问题,对依赖此类模型的应用构成潜在威胁。
- 防御措施:提出采用标准对抗训练的防御方法,虽能降低攻击的有效性,但防御效果还有提升空间。实验结果显示,该防御方法使攻击后的计算量有所降低,攻击成功率下降,但仍未恢复到未受攻击时的模型计算量水平。这表明当前防御手段虽有一定作用,但不足以完全抵御攻击,需要进一步研究更有效的防御策略。
- 未来展望:希望本文能促使研究人员深入探索此类攻击,开发出更有效的防御方法,应用于包括生成模型在内的各种自适应计算的机器学习方法,以增强模型安全性和稳定性。未来研究可从优化现有防御策略、探索新的防御机制以及深入分析攻击原理等方向展开,从而提高机器学习模型在复杂环境下的可靠性。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











