







文章目录
一、实验内容
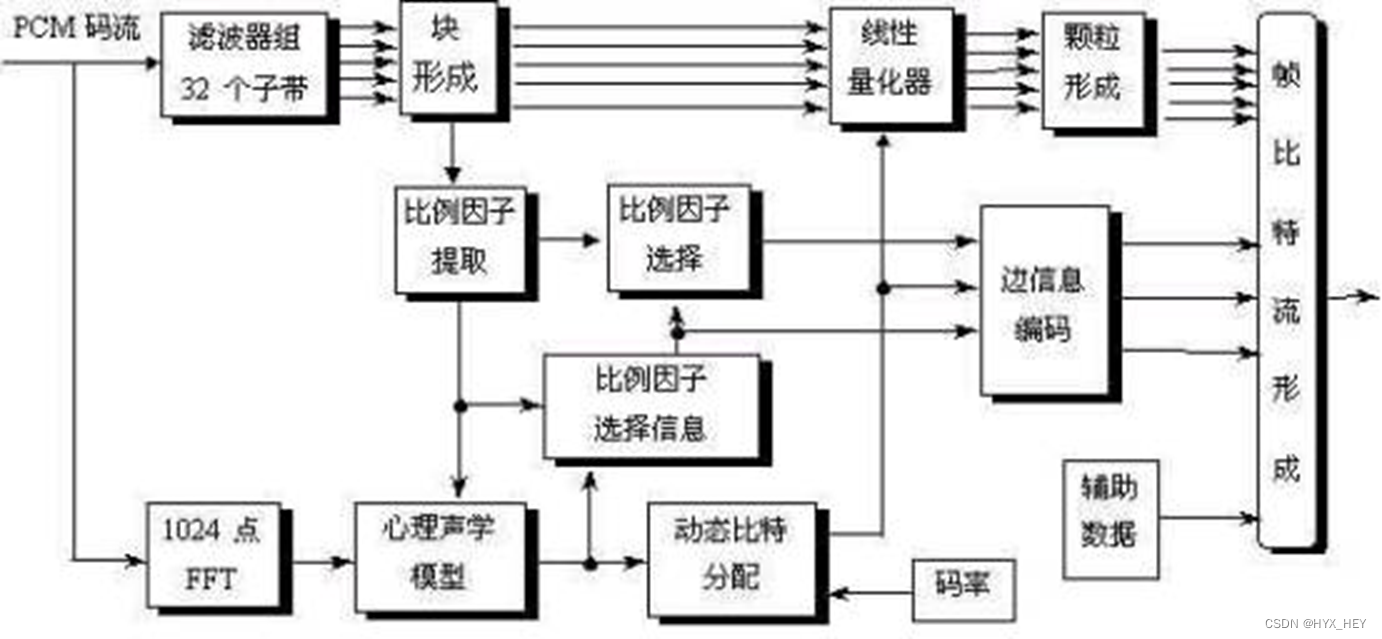
1 、MPEG-1音频编码器框架
- 多相滤波器组:将PCM样本变换到32个子带的频域信号
如果输入的采样频率为48kHz,那么子带的频率宽度为48/(2*32)=0.75kHz - 心理声学模型(Psychoacoustic Model):计算信号中不可听觉感知的部分
计算噪声遮蔽效应 - 比特分配器(Bit Allocator):根据心理声学模型的计算结果,为每个子带信号分配比特数
- 装帧(Frame Creation):产生MPEG-I兼容的比特流
2 、理解感知音频编码的设计思想
- 两条线
第1条线:输入的PCM码流经过多相滤波器组分解成32个子带信号,经过块形成后,对每个子带数据进行线性量化,对部分量化级别采用颗粒优化以增大压缩比,最后装帧输出。
第2条线:输入的PCM码流进行FFT变换,经过心理声学模型去除信号中被掩蔽的部分,确定动态比特分配和比例因子选择信息。最后相关信息进行边信息编码,一起封装成帧比特流进行传输。 - 时-频分析矛盾
时域分辨力和频域分辨力不可兼得,增大频域分辨力的同时时域分辨力便相应减小,反之亦然。
根据这一矛盾,MPEG-1音频编码采取了一些措施:通过子带分析滤波器组使信号具有高的时间分辨率,确保在短暂冲击信号情况下,编码的声音信号具有足够高的质量又可以使信号通过FFT运算具有高的频率分辨率,因为掩蔽阈值是从功率谱密度推出来的。
3 、理解心理声学模型的实现过程
MPEG-I 标准定义了两个模型
- 心理声学模型1: 计算复杂度低;但对假设用户听不到的部分压缩太严重
- 心理声学模型2 : 提供了适合Layer III编码的更多特征
实际实现的模型复杂度取决所需要的压缩因子。
-
心理声学模型I的实现
1、将样本变换到频域
32个等分的子带信号并不能精确地反映人耳的听觉特性。引入FFT补偿频率分辨率不足的问题。
2、确定子带声压级别
3、考虑安静时阈值,即绝对阈值
在标准中有根据输入PCM信号的采样率编制的“频率、临界频带率和绝对阈值”表。
4、将音频信号分解成“乐音(tones)” 和“非乐音/噪声”部分
两种信号的掩蔽能力不同。根据音频频谱的局部功率最大值确定乐音成分局部峰值为乐音,然后将本临界频带内的剩余频谱合在一起,组成一个代表噪声频率(无调成份)
5、音调和非音调掩蔽成分的消除
利用标准中给出的绝对阈值消除被掩蔽成分;考虑在每个临界频带内,小于0.5Bark的距离中只保留最高功率的成分
6、单个掩蔽阈值的计算
音调成分和非音调成分单个掩蔽阈值根据标准中给出的算法求得。
7、全局掩蔽阈值的计算

还要考虑别的临界频带的影响。一个掩蔽信号会对其它频带上的信号产生掩蔽效应(掩蔽扩散)
8、每个子带的掩蔽阈值
选择出本子带中最小的阈值作为子带阈值
9、计算每个子带信号掩蔽比(SMR),并将SMR传递给编码单元
4 、理解码率分配的实现思路
- 在调整到固定的码率之前,先确定可用于样值编码的有效比特数,这个数值取决于比例因子、比例因子选择信息、比特分配信息以及辅助数据所需比特数。
- 算法:使整帧和每个子带的总噪声—掩蔽比最小
1、计算噪声-掩蔽比(noise-to-mask ratio, NMR):
N M R = S M R – S N R ( d B ) NMR = SMR – SNR (dB) NMR=SMR–SNR(dB)其中SNR 由MPEG-I标准给定 (为量化水平的函数),NMR:表示波形误差与感知测量之间的误差
2、对最高NMR的子带分配比特,使获益最大的子带的量化级别增加一级
3、重新计算分配了更多比特子带的NMR
4、循环重复2、3步骤,直到没有比特分配。
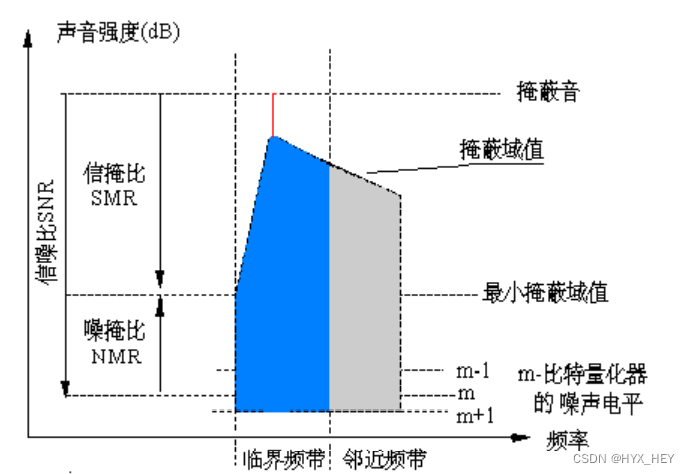
二、理解程序设计的整体框架
按照以下顺序一次处理多达2个通道的一个音频重叠帧
1.通过滤波器滑窗过滤出每个通道32个子带样本(window_subband,filter_subband)
2.如果是联合立体声模式,则组合左右声道 (combine_LR)
3.计算比例因子与比例因子选择信息(* _scale_factor_calc)
4.使用选定的心理声学模型计算心理声学掩蔽电平(psycho_i,psycho_ii)
5.使用步骤 4的掩蔽电平,对低掩噪比的子带执行迭代比特分配
6.如果错误保护标志活跃,则添加纠错 (* _CRC_calc)
7.将比特分配、比例因子和比例因子选择标头打包到比特流中(* _encode_bit_alloc,* _ encode_scale,transmission_pattern)
8.量化子带并将其打包进比特流(* _subband_quantization,* _ sample_encoding)
三、实验步骤与实验结果
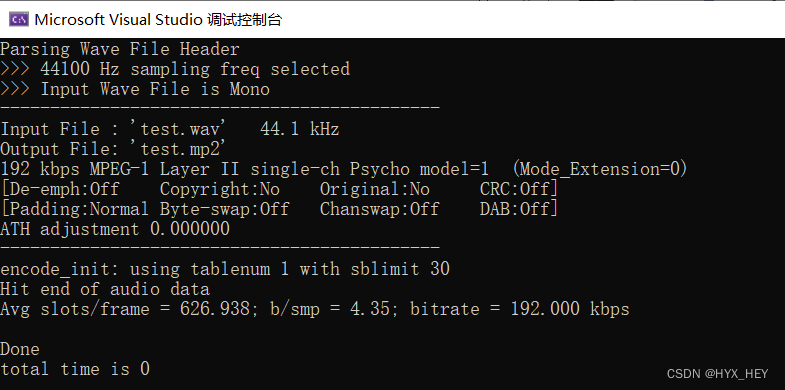
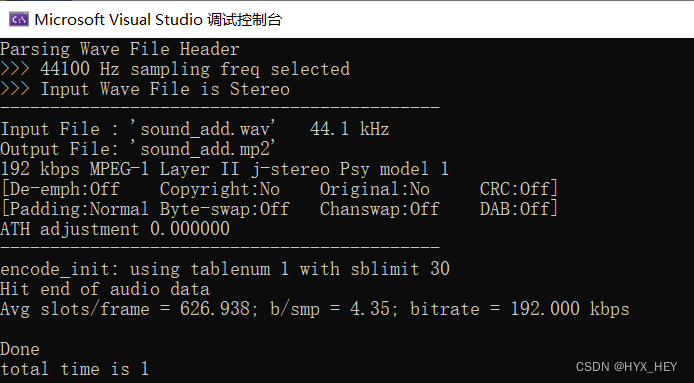
1.输出音频的采样率和目标码率
源代码已经有将音频采样率和目标码率输出到命令行的代码print_config() 。
void print_config (frame_info * frame, int *psy, char *inPath,char *outPath)
{
frame_header *header = frame->header;
if (glopts.verbosity == 0)
return;
fprintf (stderr, "--------------------------------------------\n");
fprintf (stderr, "Input File : '%s' %.1f kHz\n",(strcmp (inPath, "-") ? inPath : "stdin"),s_freq[header->version][header->sampling_frequency]);
fprintf (stderr, "Output File: '%s'\n",(strcmp (outPath, "-") ? outPath : "stdout"));
fprintf (stderr, "%d kbps ", bitrate[header->version][header->bitrate_index]);
fprintf (stderr, "%s ", version_names[header->version]);
if (header->mode != MPG_MD_JOINT_STEREO)
fprintf (stderr, "Layer II %s Psycho model=%d (Mode_Extension=%d)\n",mode_names[header->mode], *psy, header->mode_ext);
else
fprintf (stderr, "Layer II %s Psy model %d \n", mode_names[header->mode],*psy);
fprintf (stderr, "[De-emph:%s\tCopyright:%s\tOriginal:%s\tCRC:%s]\n",
((header->emphasis) ? "On" : "Off"),
((header->copyright) ? "Yes" : "No"),
((header->original) ? "Yes" : "No"),
((header->error_protection) ? "On" : "Off"));
fprintf (stderr, "[Padding:%s\tByte-swap:%s\tChanswap:%s\tDAB:%s]\n",
((glopts.usepadbit) ? "Normal" : "Off"),
((glopts.byteswap) ? "On" : "Off"),
((glopts.channelswap) ? "On" : "Off"),
((glopts.dab) ? "On" : "Off"));
if (glopts.vbr == TRUE)
fprintf (stderr, "VBR Enabled. Using MNR boost of %f\n", glopts.vbrlevel);
fprintf(stderr,"ATH adjustment %f\n",glopts.athlevel);
fprintf (stderr, "--------------------------------------------\n");
}
- 设置命令行参数

- 运行结果
音频的采样率为44.1kHz,目标码率为192kbps
2.输出数据帧信息
对于某个数据帧,输出该帧所分配的比特数、该帧的比例因子、该帧的比特分配结果。
在main()函数中添加代码
#if FRAME_TRACE
FILE* output;
output = fopen("output.txt", "a");
if (frameNum == 900) {
fprintf(output, "声道数:%d\n", nch);
fprintf(output, "目前观测第 %d 帧\n", frameNum);
fprintf(output, "本帧比特预算:%d bits\n", adb);
fprintf(output, "\n");
/* 比例因子 */
fprintf(output, "========== 比例因子 ==========\n");
for (ch = 0; ch < nch; ch++) // 每个声道单独输出
{
fprintf(output, "------ 声道%2d ------\n", ch + 1);
for (sb = 0; sb < frame.sblimit; sb++) // 每个子带
{
fprintf(output, "子带[%2d]:\t", sb + 1);
for (int gr = 0; gr < 3; gr++) {
fprintf(output, "%2d\t", scalar[ch][gr][sb]);
}
fprintf(output, "\n");
}
}
fprintf(output, "\n");
/* 比特分配表 */
fprintf(output, "========== 比特分配表 ==========\n"); //输出比特分配结果
for (ch = 0; ch < nch; ch++) {
fprintf(output, "------ 声道%2d ------\n", ch + 1); //按声道分配
for (sb = 0; sb < frame.sblimit; sb++) {
fprintf(output, "子带[%2d]:\t%2d\n", sb + 1, bit_alloc[ch][sb]);
}
fprintf(output, "\n");
}
}
fclose(output);
#endif // FRAME_TRACE
————————————————
-
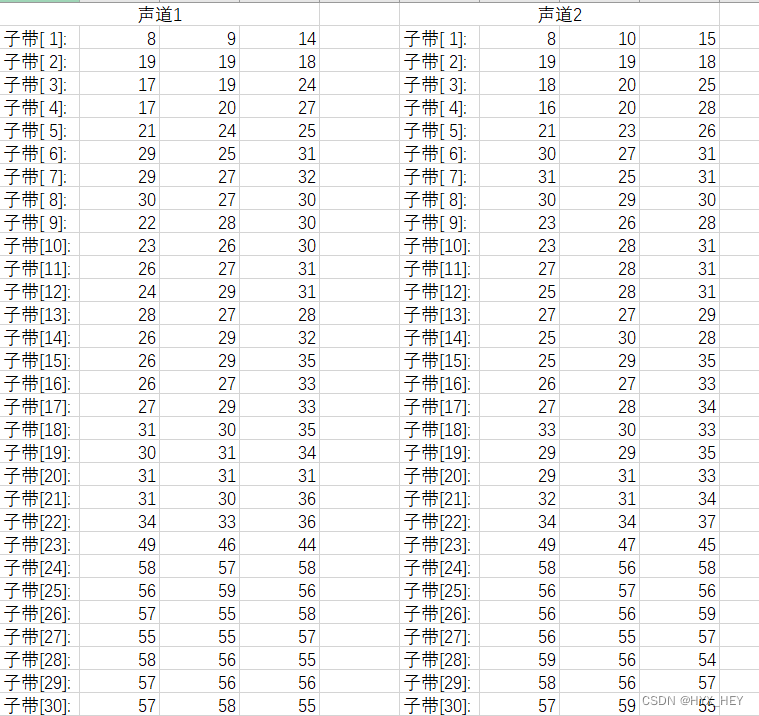
音乐文件
选择第900帧,该帧的bit预算为5016

比例因子
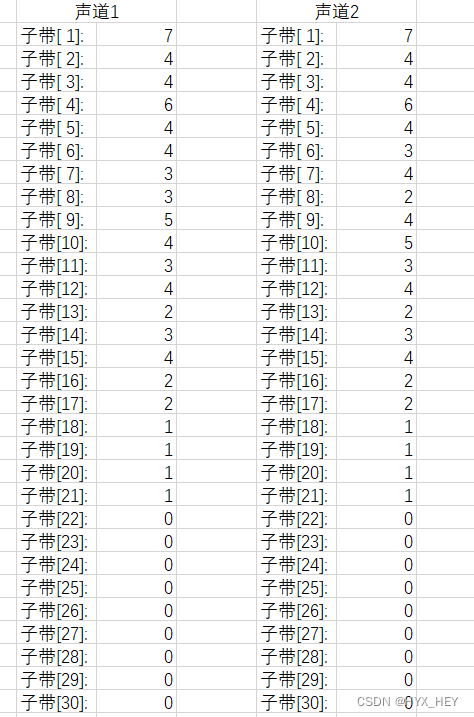
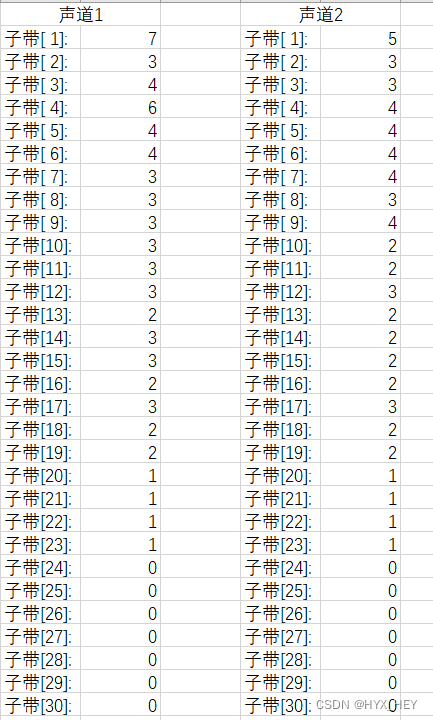
比特分配表
-
噪声文件(持续噪声)
选择第900帧,该帧的bit预算为5016
比例因子
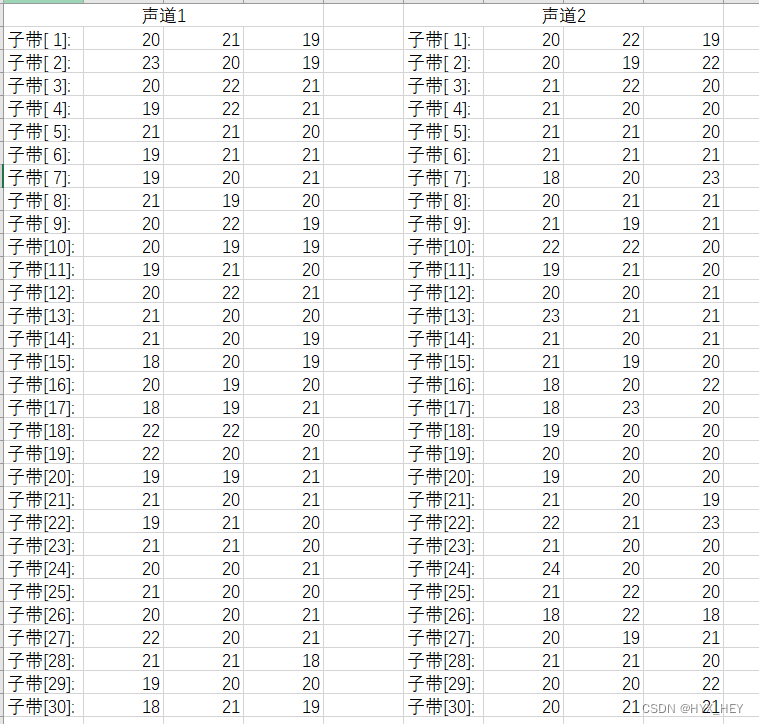
比特分配表
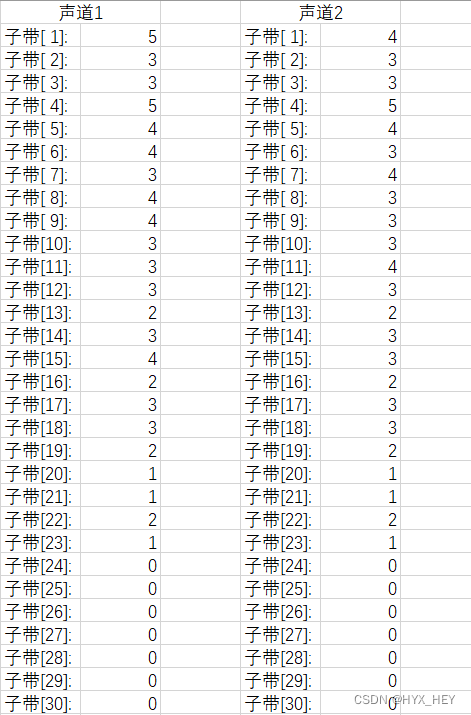
-
混合
选择第900帧,该帧的bit预算为5016
比例因子
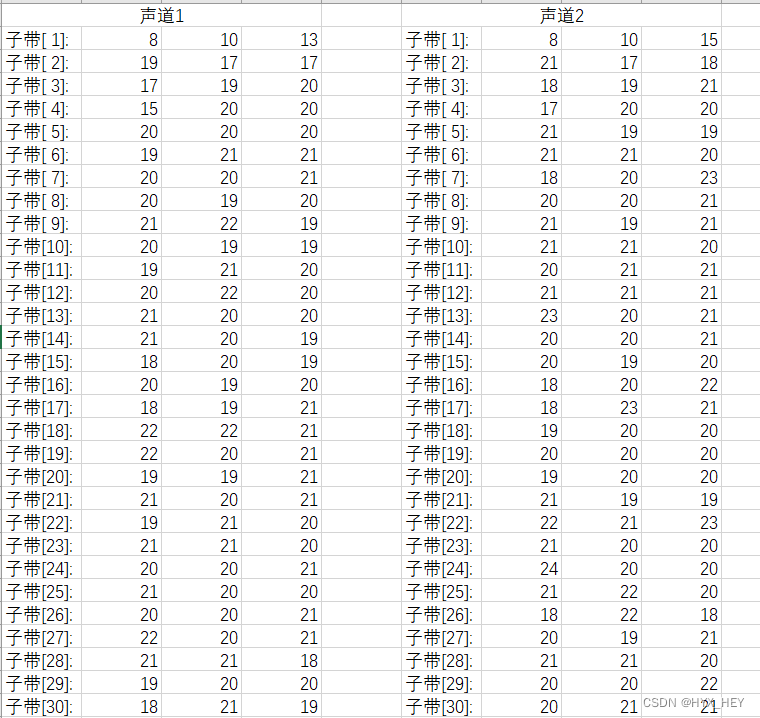
比特分配表
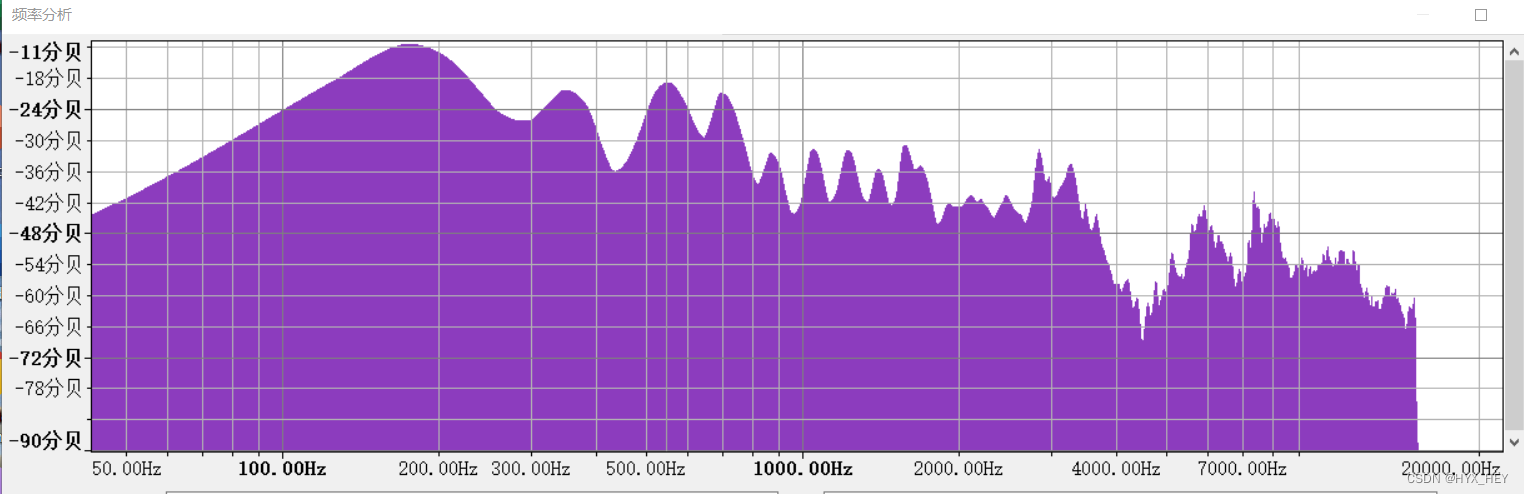
音频文件的频谱:能量集中在低频段
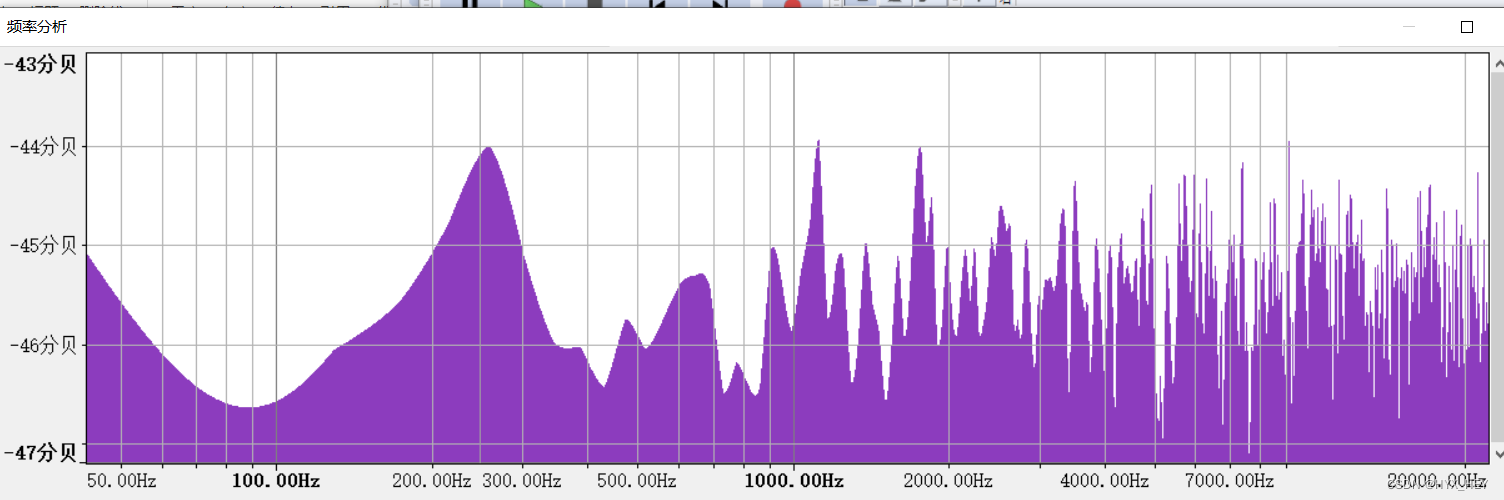
噪声文件:能量集中在高频段















 264
264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









