






一、pytest用例管理框架
pytest默认规则:
1.py文件必须以test_开头或以_test结尾
2.类名必须以Test开头(驼峰)
3.测试用例必须以test_开头
pytest用例管理框架的作用:
1.发现测试用例:从多个py文件中通过默认的规则去找测试用例
2.执行测试用例:顺序或条件
3.判断测试用例: 断言
4.生成测试报告:html,allure
二、pytest全局观
1.pytest可以和所有的自动化测试工具结合实现自动化测试
- 接口自动化:python+requests+pytest+yaml+allure+jenkins
- web自动化:python+selenium+pytest+pom+allure+jenkins
- app自动化:python+appium+pytest+pom+allure+jenkins
2.可以跳过用例或者失败用例重跑
3.结合alluer生成美观的测试报告
4.能和jenkins持续集成
5.有很多的强大插件
- pytest-html
- pytest-xdist
- pytest-ordering
- pytest-rerunfailures
- allure-html
在项目的根目录下创建 requirements.txt 文件保存插件名称
通过在Terminal控制台中输入:pip install -r requirements.txt 导入插件依赖包

三、运行方式
1. 主函数的方式(命令行的方式)
- -v 输出更加详细的运行信息 pytest.main(['-v'])
- -s 输出调试信息 pytest.main(['-vs'])
- -n 多线程运行 pytest.main(['-vs','-n'])
- --reruns 数字 失败用例重跑 pytest.main(['-vs','--reruns 2'])
- --html=报告路径 pytest.main(['-vs','--html=./report.html']) 生成到当前目录中
2.实际工作中使用 pytest.ini 配置文件来配置文件
[pytest]
addopts = -vs -n --reruns --html -m "smoke"
testpaths = ./testcases
python_files = test_*.py
python_classes = Test*
python_functions = test_*
markers =
smoke:maoyan
addopt = 后面跟需要的命令
markers 通过标记去执行冒烟用例,在用例前用装饰器mark标记 @pytest.mark.smoke

四、前后置夹具
1.def setup(self): print("在每个用例前执行一次")
2.def teardown(self): print("在每个用例后执行一次")

3.def setup_class(self): print("在每个类前执行一次")
4.def teardown_class(self): print("在每个类后执行一次")
5.@pytest.fixture(scope="作用域",params="数据驱动",autouse="自动执行",ids="自定义参数名",name="重命名")
部分用例执行通过装饰器fixture将方法名传入到用例中,通过yield实现用例后执行(yield返回多次以及多个数据,yield后可以接代码,而return只会返回一次,return之后不能接代码)
作用域:function,class,module,package/session 默认是function


6.@pytest.fixture()一般会和 conftest.py 文件一起使用,创建一个名为 conftest.py 的文件(名称是固定的)
1.conftest.py 文件是单独存放@pytest.fixture()的方法,可以在多个py文件之间共享前置配置
2.conftest.py 里面的方法在调用时不需要导入,可以直接使用。
3.conftest.py 可以有多个,可以有不同层级
五、接口自动化测试框架封装(接口关联的封装)
一般情况下通过一个关联的yaml文件来实现,在根目录下新建一个 extract.yml (什么也不需要写),还需要一个读写yaml文件的一个公共方法,创建一个公共的包common在里面新建一个yaml_util.py的工具类用来实现yaml文件的读写
class YamlUtil:
#读取extract.yml文件
def read_extract_yaml(self,key):
with open(os.getcwd()+"./extract.yml",mode='r',encoding='utf-8') as f:
value = yaml.load(stream=f,Loader=yaml.FullLoader)
return value[key];
#写入extract.yml文件
def write_extract_yaml(self,data):
with open(os.getcwd()+"./extract.yml",mode='w',encoding='utf-8') as f:
yaml.dump(data=data,stream=f,allow_unicode=True)
open打开os.getcwd系统路径,mode='r'为读取,编码为utf-8作为数据流传入f,通过yaml.load方法加载数据流为f,加载方式为yaml.FullLoader的全局加载,将读取结果赋于value,返回value。mode='w'为写入,将传入的数据data通过yaml.dump方法写入,允许unicode编码

原先是将中间值(token)设置为全局变量

将TestSendRequest.access_token = rep.json() ['access_token']换成下面这一句
YamlUtil.write_extract_yaml({'access_token':rep.json()['access_token']})用在yaml_util.py文件中写的write_extract_yaml()方法将access_token以键值对的形式写入extract.yml文件当中
 再用yaml_util.py文件中写的read_extract_yaml()方法读取access_token实现对access_token的调用
再用yaml_util.py文件中写的read_extract_yaml()方法读取access_token实现对access_token的调用
access_token = YamlUtil.read_extract_yaml('access_token')同样的将上面的全局变量csrf_token用yaml_util.py中的方法进行替换
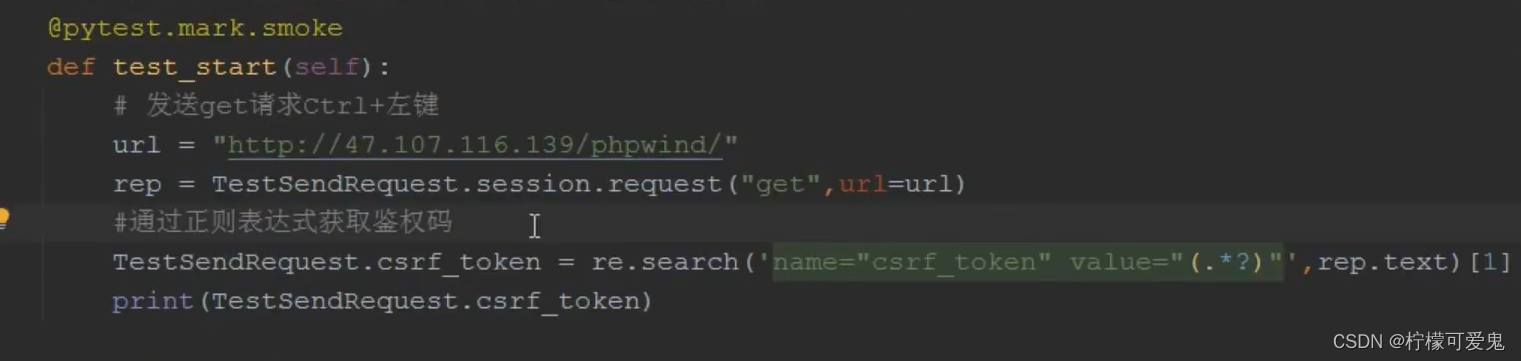
将TestSendRequest.csrd_token = re.search('name="csrf_token"value="(.*?)"',rep.text)[1]替换为下面这句
csrf_token = YamlUtil.write_extract_yaml({'csrf_token':re.search('name="csrf_token"value="(.*?)"',rep.text)[1]})用在yaml_util.py文件中写的write_extract_yaml()方法将csrf_token以键值对的形式写入extract.yml文件当中

再用yaml_util.py文件中写的read_extract_yaml()方法读取csrf_token实现对csrf_token的调用
csrf_token = read_extract_yaml('csrf_token')当在第二次调用write_extract_yaml()方法的时候extract.yml文件的第一次调用write_extract_yaml()方法所写的数据被覆盖掉了,因为在mode='w'是直接覆盖。

此处的解决办法是将mode='w'改成mode='a',a意味着追加。但是如果执行多次会导致access_token和csrf_token出现多次值。
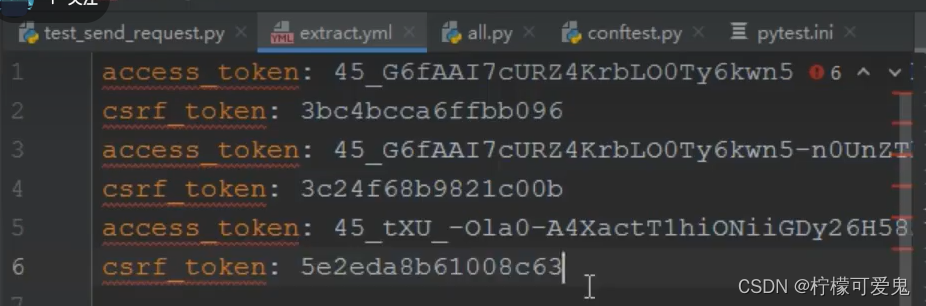
此时需要在每一次session会话结束后就进行一次对extract.yml文件数据的清除。
在yaml_utill.py文件中加入此代码,用来对extract.yml文件数据的清除。
def clear_extract_yaml(self):
with open(os.getcwd+"./extract.yml",mode='w',encoding='utf-8') as f:
f.truncate()在conftest.py文件中加入此代码,用来在每一次session结束后就进行clear_extract_yaml()方法。
@pytets.fixture(scope="session",autouse=True)
def clear_yaml():
YamlUtil.write_extract_yaml()六、pytest接口断言
判断access_token是否在结果里
assert 'access_token' in rep.json()判断url是否在结果里
assert 'url' in rep.json()判断简单json格式中的key是否等于值,此处展示errcode是否等于0
result = rep.json()
assert result['errcode'] == 0七、pytest结合allure_pytest生成allure测试报告
1.官网下载allure,下载zip包后解压到本地,将bin目录配置到环境变量path里面去。
2.在cmd或者控制台中输入allure --version查看版本
3.执行命令
- 生成临时的json文件:在 pytest.ini 文件中的addopts = -vs --allure ./temp(在当前目录的temp中生成json的临时文件)
- 用json的临时文件输出allure报告:在主函数中加入以下代码生成报告
if __name__ == '__main__':
pytest.main()
os.system("allure generate temp -o reports --clean")八、接口自动化测试框架YAML数据驱动的封装
为了让每个用例使用多组数据,将数据封装到了yaml文件,通过读取yaml文件的数据返回到用例上,以实现用例不臃肿。
@pytest.mark.parametrize(args_name,args_value)
agrs_name:参数名
args_value:参数值(使用list列表,tuple元祖,字典列表,字典元祖等)在数据中有多少接口用例就会执行多少次。

1.此处将列表中的三个值:百里、星瑶、依然分别赋给args,每次赋值后就执行一次,打印出三次结果。

2.当args_value为[['百里',13],['星瑶',10]]的时候,['百里',13]是一个值

3.当args_name为'name,age'的时候,['百里',13]是两个值,进行了解包操作。
4.yaml也是一种数据格式,他的主要作用:配置文件、测试用例。他的数据组成由两部分构成:
- map对象:键:(空格)值 例:name: 百里
- 列表: 用-开头(表示一个横杠-下为一个列表,一个列表下可以有多个数据组)
5.每个用例创建一个yaml文件,在此处创建一个get_token.yml获取token的yaml文件用来存放数据。
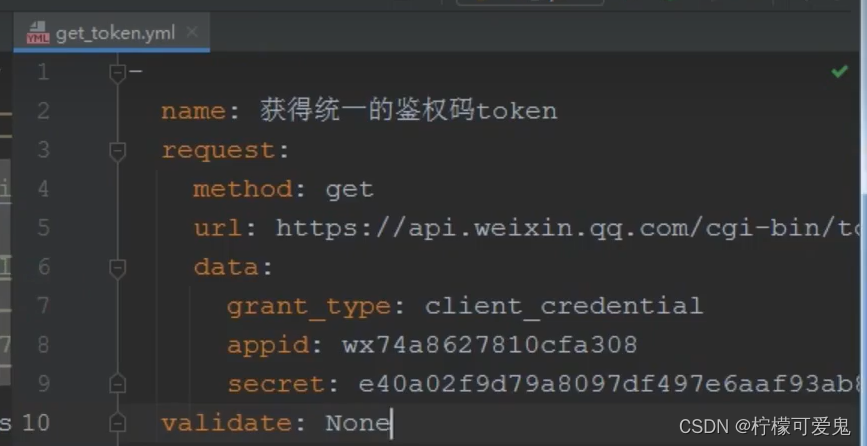
包含了name,request接口请求下的请求方式、请求路径、请求数据,以及请求数据下的各种参数,这边要注意的是data:下的参数是没有双引号的,以及validate断言机制。
接下来需在YamlUtil.py文件中写出读取get.token.yml文件的方法。
def read_testcase_yaml(self,yaml_name):
with open(os.getcwd+"/testcases/"+yaml_name,mode='r',encoding='utf-8') as f:
value = yaml.load(stream=f,Loader=yaml.FullLoader)
return value;
接下来就是去调用这个方法,在用例的前面用上这个@pytest.mark.parametrize(args_name,args_value)

我们通过传参后发现最后通过这个方法读取出来的yaml文件就是字典格式,所以我们取值的时候也需要通过key来获取他的值。
print(caseinfo['name'])
print(caseinfo['request'][method])
print(caseinfo['request'][url])
print(caseinfo['request'][data])
print(caseinfo['validate'])通过打印是我们想要的值,现在给他赋值
method = caseinfo['request']['method']
url = caseinfo['request']['url']
data = caseinfo['request']['data']6.做一个断言判断
rep = TestSendRequest.session.request(method,url=url,params=data)
result = rep.json
print(result)
if 'accsee_token' in result:
YamlUtil().write_extract_yaml({'access_token':rep.json()['access_token']})
access 'access_token' in result
else:
access result['errcode'] == 400027.统一接口请求封装
因为rep = TestSendRequest.session.request(method,url=url,params=data)这段接口请求代码把每个用例都会有,包括session = requests.session当我们有一百个用例就需要初始化100次导致了后面的session不是我原来的那个了,需要把它放在一个文件中统一session,我们需要对所有的请求做分析处理,日志监控。
首先创建在common工具包中创建一个request_util.py文件用来统一接口、session的请求,以及对请求做分析处理,日志监控。
class RequestUtil:
session = requests.session()
def send_request(method,url,data,**kwargs):
rep = RequestUtil.request.session(method,url,data,**kwargs)
return rep.textrep.json()获得返回的字典格式数据,rep.text获得返回字符串格式数据,rep.content获得返回bytes字节类型数据。此处用rep.text可以有更好的扩展性。
result = RequestUtil.send_request(method,url,data)
result = json.loads(result)在用例中直接调用,将text转化成json格式(将字符串转化成json格式)
我们要注意get请求不是用data来传参的,而是用params来传参的,如果是post有可能是通过json(复杂json)或者data(纯键值对)来传参的,这里因为有可能是json也有可能是data,所以我们使用data来兼容,不管你传的什么值都将他转换成一个字符串传参(将json格式字符串),所以在send_request()方法中我们需要进行判断。
class RequestUtil
session = requests.session()
der send_request(method,url,data,**kwargs):
method = str(method).lower()
rep = None
if method == 'get':
rep = RequestUtil.send(method,url=url,params=data,**kwargs):
else
data=json.dumps(data)
rep = RequestUtil.send(method,url=url,data=data,**kwargs):
return rep.textmethod = str(method).lower()方法是将method小写,因为在yaml文件中method有些人会写成大写,将其统一成小写。
8.在yaml用例中调用csv数据,正则表达,文件上传,动态参数,断言。
首先调用csv数据,创建一个data包, 创建一个get_token_data.csv文件

然后去调用文件
- name: $csv{name}
parameters:
name-appid-secret-grant_type-assert_str: data/get_token_data.csv
request:
method: GET
url: /cgi-bin/token
data:
appid: $csv{appid}
secret: $csv{secret}
grant_type: $csv{grant_type}
extract:
#正则表达式
#access_token: '"access_token":"(.*?)",'
#JSON提取器
access_token: access_token
validate:
- equalis: {status_code: 200}
- contains: $csv{assert_str}对文件的调用,以及正则和断言的封装。
data: {"tag":{"id":1890,"name":"abc${get_random_number()}"}}调用外部的一个随机数方法get_random_number()
def get_random_number(self):
return random.randint(88888888,99999999)这是在外部创建的随机数的.py文件的方法。
file:
media: "E:\1.png"这是文件上传。















 5214
5214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









