






一、基础语法
1.1 输出函数
1.1.1. set
含义:用来间隔多个值
格式:sep=" "
- 默认值是一个空格
print("1","2","3",sep="|")result:1|2|3
1.1.2. end
含义:用来设定以什么结尾
格式:end=" "
- 默认值是换行符\n
print('123',end=" ")
print("123")
result:123 123
1.2. 数值类型
1.2.1. 布尔型
- True相当于1,False相当于0
print(True + False)
print(True + 1)result:1
2
1.2.2. 复数型
格式:z = a + bj
- a是实部,b是虚部,j是虚数单位
a = 1 + 2j
b = 2 + 3j
print(a + b)result:3+5j
1.3. 字符串
1.3.1. 字符串编码转换
1.3.1.1. encode
含义:encode编码
格式:变量名.encode()
a='hello'
a1=a.encode()
print(a1,type(a1))
a='你好'
a1=a.encode("utf-8")
print(a1,type(a1))
result:b'hello' <class 'bytes'>
b'\xe4\xbd\xa0\xe5\xa5\xbd' <class 'bytes'>
1.3.1.2. decode
含义:decode解码
格式:变量名.decode()
a='hello'
a1=a.encode()
print(a1)
a2=a1.decode()
print(a2,type(a2))result:b'hello'
hello <class 'str'>
1.3.2. 字符串常见操作
1.3.2.1. 字符串拼接
a='1'
b='2'
print(a+b)result:12
1.3.2.2. 字符串多行输出
含义:三引号多行内容输出
格式:"""string"""
name = """Ni
ko
"""
print(name)result:Ni
ko
1.3.2.3. 字符串重复输出
含义:重复输出
格式:字符*数字
print('没'*3)result:没没没
1.3.2.4. 成员运算符
1.3.2.4.1. in
含义:如果包含的话,返回True,不包含返回False
格式:字符串 in 变量
name = 'bingbing'
print('bing' in name)
print('aing' in name)result:True
False
1.3.2.4.2. not in
含义:not in:如果不包含的话,返回True,包含返回False
格式:字符串 not in 变量
name = 'bingbing'
print('bing' not in name)
print('aing' not in name)result:False
True
1.3.2.5. 切片
格式:[开始位置:结束位置:步长]
- 包前不包后,步长默认1
st = 'abcdefghijk'
print(st[0:5])
print(st[0:5:2])
print(st[0:])
print(st[0::2])
print(st[:9])
print(st[:9:3])
print(st[-5:])
print(st[-5:-3])
print(st[2:-3])
print(st[:-1])
print(st[-1:])
print(st[-1:-5:-1])result:abcde
ace
abcdefghijk
acegik
abcdefghi
adg
ghijk
gh
cdefgh
abcdefghij
k
kjih
1.3.2.6. find
含义:检查某个字符串是否包含在字符串中
格式:find(子字符串,开始位置下标,结束位置下标)
- 如果在就返回这个字符串开始位置的下标,否则就返回-1
- 包前不包后,开始和结束位置下标可以省略
a="bingbing"
print(a.find("b"))
print(a.find("bing"))
print(a.find("b",3))
print(a.find("b",5))
print(a.find("b",3,5))
print(a.find("b",3,4))result:0
0
4
-1
4
-1
1.3.2.7. index
含义:检查某个子字符串是否包含在字符串中,如果在就返回这个字符串开始位置的下标
- 没找到会报错
a="bingbing"
print(a.index("bin"))result:0
1.3.2.8. count
含义:在子字符串中出现的次数
格式:count(子字符串,开始位置下标,结束位置下标)
- 包前不包后
a='bingbing'
print(a.count('b'))result:2
1.3.2.9. startswith
含义:是否以子字符串开头
格式:startswith(子字符串,开始位置下标,结束位置下标)
- 是的话就返回True,不是的话就返回False
a='bingbing'
print(a.startswith('bing'))result:True
1.3.2.10. endswith
含义:是否以子字符串结尾
格式:endswith(子字符串,开始位置下标,结束位置下标)
- 是的话就返回True,不是的话就返回False
a='bingbing'
print(a.endswith('bing'))result:True
1.3.2.11 . isupper
含义:检测字符串中所有的字符是否都为大写
格式:变量名.isupper()
- 是的话就返回True,不是就为False
a='bingBing'
print(a.isupper())result:False
1.3.2.12. replace
含义:替换内容
格式:replace(旧内容,新内容,替换次数)
- 默认全部替换
a='好好学习,天天向上'
print(a.replace('天','好'))
print(a.replace('天','好',1))result:好好学习,好好向上
好好学习,好天向上
1.3.2.13. split
含义:指定分隔符来切分字符串
格式:split(字符,次数)
- 可以指定次数
- 如果字符串中不包含分割内容,就不进行分割,会作为一个整体。
a='hello,python'
print(a.split(','))
print(a.split('o'))
print(a.split('o',1))
print(a.split('a'))result:['hello', 'python']
['hell', ',pyth', 'n']
['hell', ',python']
['hello,python']
1.3.2.14. capitalize
含义:第一个字符大写,其他全是小写
格式:变量名.capitalize()
a='sagapoHH'
print(a.capitalize())result:Sagapohh
1.3.2.15. lower
含义:lower 大写字母转小写
格式:变量名.lower()
a='SAGAPOHH'
print(a.lower())
result:sagapohh
1.3.2.16. upper
含义:upper 小写字母转大写
格式:变量名.upper()
a='sagapohh'
print(a.upper())result:SAGAPOHH
1.4. 格式化输出
1.4.1. 占位符
1.4.1.1. %s
含义:%s 字符串占位符
name = "Mico"
print("name = %s" % name)result:name = Mico
1.4.1.2. %d
含义:%d 整数占位符
age = 18
height = 180
print("height = %s,age = %d" % (height,age))
result:height = 180,age = 18
1.4.1.3. %4d
含义:%4d 整数占位符,数字设置位数
- 不足前面默认补空白
- 在数字前加0,不足用0补全
age = 1
print("age = %4d" % age)
print("age = %04d" % age)result:age = 1
age = 0001
1.4.1.4. %f
含义:%.f 浮点数占位符
- 默认六位小数
- 不足后面补0,遵循四舍五入原则
a = 1.23456
print("a = %f" % a)result:a = 1.234560
1.4.1.5. %.4f
含义:%.4f 数字设置小数位数
- 遵循四舍五入原则
a = 1.23456
print("a = %.4f" % a)result:a = 1.2346
1.4.1.6. %%
print("我是%%的%%" % ())result:我是%的%
1.4.2. f格式化
格式:f"{表达式}"
print(f"my name is {name},age is {age}")result:my name is Mico,age is 1
1.5. 算数运算符
1.5.1. /
含义:商
- 一定是浮点数,除数不为0
a = 4 / 2
print(a)result:2.0
1.5.2. //
- 取商的整数部分,向下取整(不管四舍五入的规则,只要后面有小数,就忽略小数)
a = 4 // 3
print(a)result:1
1.5.3. %
含义:取余数
a = 6 % 4
print(a)result:2
1.5.4. **
含义:幂次方
- m**n:m的n次方
a = 3
b = 2
print(b**a)result:8
1.6. 运算符优先级
- 幂(最高优先级) > 乘、除、取余、取整数 > 加减
print(3**2+5//2)result:11
1.7. 输入函数 input
含义:输入函数,默认是字符串类型
格式:input()
name = input("请输入:")
print(name)
result:请输入:mico
mico
1.8. 转义字符
1.8.1. \r
含义:\r 回车 表示将当前位置移到本行开头
- 前面的数据就没有了
print("dsfs\rads")result:ads
1.8.2. r'string'
含义:表示引号内部的字符默认不转义
print(r'abc\\\sda')result:abc\\\sda
1.9. if判断
1.9.1. if语句
age = 18
if age < 20:
print("不可以结婚")result:不可以结婚
1.9.2. not
含义:表示相反的结果
print(not 3>9)result:True
1.9.3. if else
a=3
b=5
print("a比b大")if a>b else print("a比b小")result:a比b小
1.9.4. if elif else
score = 80
if 85<=score<=100:
print('优秀')
elif 60<=score<85:
print("及格")
else:
print("不及格")
result:不及格
1.10. 循环语句 while
格式:while 条件 :
i =1
while i<5 :
print("hi")
i+=1result:hi
hi
hi
hi
1.11. 列表
1.11.1. 列表的基本格式
格式:列表名 = [元素1,元素2,元素3]
li=[1,2,'a',4]
print(li)
print(li[0:3])
for i in li:
print(i)result:[1, 2, 'a', 4]
[1, 2, 'a']
1
2
a
4
1.11.2. 列表的常见操作
1.11.2.1. 添加元素
1.11.2.1.1. append
含义:append列表元素整体添加
格式:列表名.append()
li=[1,2,'a',4]
li.append('five')
print(li)result:[1, 2, 'a', 4, 'five']
1.11.2.1.2. extend
含义:extend分散添加
格式:列表名.extend()
- extend只能添加可迭代对象(列表,字符串)
li=[1,2,'a',4]
li.extend('six')
print(li)result:[1, 2, 'a', 4, 's', 'i', 'x']
1.11.2.1.3. insert
含义:在指定位置插入元素
格式:列表名.insert()
- 指定位置如果有元素,原元素后移
li = [1,2,3]
li.insert(3,4)
print(li)
li.insert(0,-1)
print(li)result:[1, 2, 3, 4]
[-1, 1, 2, 3, 4]
1.11.2.2. 修改列表元素
方法:通过下标修改
格式:列表名[下标] = 值
a=[1,2,3]
a[2]='a'
print(a)result:[1, 2, 'a']
1.11.2.3. 查找列表元素
方法:通过in、not in 查找
a=[1,2,3]
print('1' in a)
print('1' not in a)result:False
True
1.11.2.4. 删除列表元素
1.11.2.4.1. del
含义:删除列表元素,根据下表删除
格式:del 列表名[下标]
li=['a','b','c','d']
del li[2]
print(li)result:['a', 'b', 'd']
1.11.2.4.2. pop
含义:默认删除最后一个元素
格式:pop 列表名[下标]
li=['a','b','c','d']
li.pop(2)
print(li)result:['a', 'b', 'd']
1.11.2.4.3. remove
含义:删除列表元素,根据元素删除
格式:列表名.remove()
li=['a','b','c','a']
li.remove('a')
print(li)result:['b', 'c', 'a']
1.11.2.5. 排序列表元素
1.11.2.5.1. sort
含义:从小到大排序
格式:列表名.sort()
li = ['78','23','61','6','35']
li.sort()
print(li)result:['23', '35', '6', '61', '78']
1.11.2.5.2. reverse
含义:倒序排序
格式:列表名.reverse()
li = ['78','23','61','6','35']
li.reverse()
print(li)result:['35', '6', '61', '23', '78']
先sort后reverse:从小到大
li = ['78','23','61','6','35']
li.sort()
li.reverse()
print(li)result:['78', '61', '6', '35', '23']
1.11.3. 列表推导式
1.11.3.1. [表达式 for 变量 in 列表]
格式:[表达式 for 变量 in 列表]
- in后面可以放列表,还可以放range()、可迭代对象
li = [1,2,3,4,5]
[print(i,end="") for i in li]
print('')
[print(i,end="") for i in range(1,6)]
print('')li=[]
[li.append(i) for i in range(1,6)]
print(li)result:12345
12345
[1, 2, 3, 4, 5]
1.11.3.2. [表达式 for 变量 in 列表 if条件]
格式:[表达式 for 变量 in 列表 if条件]
在1到11中找出奇数添加到 li 列表中
li=[]
[li.append(i) for i in range(1,11) if i % 2 == 1]
print(li)result:[1, 3, 5, 7, 9]
1.11.4. 列表嵌套
li=[1,2,3,[4,5,6]]
print(li[3])
print(li[3][2])result:[4, 5, 6]
6
1.12. 元组
1.12.1. 元组的基本格式
格式:元组名 = (元素1,元素2,元素3...)
- 不同元素也可以是不同数据类型
- 可以定义空元组
- 只有一个元素的时候,末尾必须加上逗号,否则返回唯一的值的数据类型
tup=(1,'a',1.3,[1,'a',1.3])
print(type(tup))
tup=()
print(type(tup))
tup=(1,)
print(type(tup))
tup=(1)
print(type(tup))result: <class 'tuple'>
<class 'tuple'>
<class 'tuple'>
<class 'int'>
1.12.2. 元组与列表的区别
- 元组只有一个元素末尾时必须加逗号,列表不需要
- 元祖只支持查询操作,不支持怎删改操作
- count、index、len、[] 跟列表的用法相同
li=[1]
print(type(li))
tup=(1,2,3,1)
print(tup[2])
print(tup.count(1))
print(tup.index(2))
print(len(tup))
print(tup[1:])result:<class 'list'>
3
2
1
4
(2, 3, 1)
1.12.3. 元组的应用场景
- 函数的参数和返回值
- 格式化输出后面的()本质上就是一个元组
- 数据不可被修改,保护数据的安全
name ='bingbing'
age = 18
print('%s的年龄是%d' % (name,age))
info = (name,age)
print(type(info))
print('%s的年龄是%d' % info)result:bingbing的年龄是18
<class 'tuple'>
bingbing的年龄是18
1.13. 字典
1.13.1. 字典的基本格式
格式:字典名 = {键1:值1,键2:值2...}
- 字典中的键具备唯一性,键名重复前面的值会被后面的值替代
- 字典中的值可以重复
dic = {'name':'bing','age':18}
print(type(dic))
dic1 = {'name':'bingbing','name':'susu'}
print(dic1)
dic2 = {'name1':'bingbing','name2':'bingbing'}
print(dic2)result:<class 'dict'>
{'name': 'susu'}
{'name1': 'bingbing', 'name2': 'bingbing'}
1.13.2. 字典的常见操作
1.13.2.1. 查看字典元素
1.13.2.1.1. 变量名[键名]
格式:变量名[键名]
- 不可根据下标查找元素,需要根据键名查找
dic = {'name':'bingbing','age':18}
print(dic['name'])
result:bingbing
1.13.2.1.2. 变量名.get(键名)
格式:变量名.get(键名)
- 键名不存在返回自己设置的值,默认是None
dic = {'name':'bingbing','age':18}
print(dic.get('name'))
print(dic.get('sex'))
print(dic.get('sex','性别不存在'))result:bingbing
None
性别不存在
1.13.2.2. 修改字典元素
格式:变量名[键名] = 值
dic = {'name':'bingbing','age':18}
dic['name'] = 'susu'
print(dic)result:{'name': 'susu', 'age': 18}
1.13.2.3. 添加字典元素
格式:变量名[键名] = 值
dic = {'name':'bingbing','age':18}
dic['sex'] = '男'
print(dic)result:{'name': 'bingbing', 'age': 18, 'sex': '男'}
1.13.2.4. 删除字典
格式:del 字典名
dic = {'name':'bingbing','age':18}
del dic1.13.2.5. 删除字典元素
格式:del 字典名[键名]
dic = {'name':'bingbing','age':18}
del dic['name']
print(dic)result:{'age': 18}
1.13.2.6. clear
含义:清空整个字典里面的东西,但保留了这个字典
格式:字典名.clear()
dic = {'name':'bingbing','age':18}
dic.clear()
print(dic)result:{}
1.13.2.7. pop
含义:删除指定键值对
格式:字典名.pop()
dic = {'name':'bingbing','age':18}
dic.pop('name')
print(dic)result:{'age': 18}
1.13.2.8. popitem
含义:删除键值对
格式:字典名.popitem()
- 3.7版本以前随机删除一个键值对,3.7版本之后删除最后一个元素
dic = {'name':'bingbing','age':18}
dic.popitem()
print(dic)result:{'name': 'bingbing'}
1.13.2.9. len
含义:求长度
格式:len(变量名)
dic = {'name':'bingbing','age':18}
tup = (1,2,'a')
li = [1,2,3,4]
str = 'hello'
print(len(dic),len(tup),len(li),len(str))result:2 3 4 5
1.13.2.10. keys
含义:返回字典里面包含的所有键名
格式:变量名.keys()
- 可以用for循环取出
dic = {'name':'bingbing','age':18}
a= dic.keys()
print(type(a))
print(dic.keys())
for i in a:
print(i,end=' ')result:<class 'dict_keys'>
dict_keys(['name', 'age'])
name age
1.13.2.11. values
含义:返回字典里面包含的所有值
格式:变量名.values()
- 可以用for循环取出
dic = {'name':'bingbing','age':18}
a= dic.values()
print(type(a))
print(dic.values())
for i in a:
print(i,end=' ')result:<class 'dict_values'>
dict_values(['bingbing', 18])
bingbing 18
1.13.2.12. item
含义:返回字典里包含的所有键值对,键值对以元组形式返回
格式:变量名.items()
- 可以用for循环取出
dic = {'name':'bingbing','age':18}
a= dic.items()
print(type(a))
print(dic.items())
for i in a:
print(i,end=' ')
print()
print(type(i))result:<class 'dict_items'>
dict_items([('name', 'bingbing'), ('age', 18)])
('name', 'bingbing') ('age', 18)
<class 'tuple'>
1.14. 集合
1.14.1. 集合的基本格式
格式:集合名 = {元素1,元素2.,元素3...}
s1 = {1,2,3}
print(type(s1))
print(s1)result:<class 'set'>
{1, 2, 3}
1.14.2. 空集合的定义
格式:变量名 = set()
s1 = {}
print(type(s1))
s1 = set()
print(type(s1))result:<class 'dict'>
<class 'set'>
1.14.3. 集合具有无序性
- 每次运行的结果都不一样
s1 = {'a','b','c','d','e'}
print(s1)
result:{'d', 'b', 'a', 'e', 'c'}
result:{'b', 'c', 'd', 'a', 'e'}
result:{'d', 'e', 'c', 'b', 'a'}
- 集合数字运行结果一样,并且从小到大排列
s1 = {2,4,9,1,6}
print(s1)result:{1, 2, 4, 6, 9}
result:{1, 2, 4, 6, 9}
result:{1, 2, 4, 6, 9}
1.14.4. 集合无序的实现方法涉及hash表(了解)
- 每次运行结果不同:python中string字符串型的hash值不同,那么在hash表中的位置也不同, 所以才有集合的无序性
注:因此不能查询、修改集合中的值(都不知道修改哪一个),只能添加、删除
print(hash('a'))result:6186969021618527376
result:1374242042952206087
result:6186969021618527376
- 每次运行结果相同:python中int整型的hash值相同,那么在hash表中的位置也相同,所以才 顺序不会发生改变
print(hash(1))result:1
result:1
result:1
1.14.5. 集合具有唯一性
含义:可以自动去除
s1 = {1,1,3,7,7,9,4}
print(s1)result:{1, 3, 4, 7, 9}
1.14.6. 集合的基本操作
1.14.6.1. add
含义:集合的添加
格式:集合名.add(元素)
- add添加的是一个整体,一次只能添加一个元素(元组可以作为一个元素)
s1 = {1,2,3,4}
s1.add(5)
s1.add((7,8))
print(s1)result:{1, 2, 3, 4, 5, (7, 8)}
1.14.6.2. update
含义:把传入的元素拆分,一个个放进集合当中
格式:集合名.update(元素)
- 元素必须是能够被for循环的可迭代对象
s1 = {1,2,3,4}
s1.update('56')
s1.update([7,8])
s1.update((9,10))
s1.update({11,12})
s1.update({'name':'mico'},{'age':'18'})
print(s1)result:{1, 2, 3, 4, '6', 'name', 7, 8, 9, 10, 11, 12, 'age', '5'}
1.14.6.3. remove
含义:删除集合元素,元素没有则会报错
格式:变量名.remove(元素)
s1 = {1,2,3,4}
s1.remove(1)
print(s1)result:{2, 3, 4}
1.14.6.4. pop
含义:集合删除
格式:变量名.pop()
s1 = {'a','b','c','d'}
print(s1)
s1.pop()
print(s1)result:{'c', 'b', 'a', 'd'}
{'b', 'a', 'd'}
1.14.6.5. discard
含义:选择要删除的元素,有的会删除,没有则不会发生任何改变
格式:变量名.discard(元素)
s1 = {1,2,3,4}
s1.discard(4)
print(s1)
s1.discard(5)
print(s1)result:{1, 2, 3}
{1, 2, 3}
1.14.7. 交集
格式:a & b
- 没有交集返回空集合
a = {1,2,3,4}
b = {3,4}
print(a & b)
a = {1,2,3,4}
b = {5,6}
print(a & b)result:{3, 4}
set()
1.14.8. 并集
格式:a | b
a = {1,2,3,4}
b = {3,4,5,6}
print(a | b)result:{1, 2, 3, 4, 5, 6}
1.15. 类型转换
1.15.1. int()
含义:转换为一个整型
格式:int()
- 浮点型强转整形会去掉小数点及后面的数值,只保留整数部分
- 只能转换由数字组成的字符串
a = 1.2
b = int(a)
print(b,type(b))
c = '123'
d = int(c)
print(d,type(d))result:1 <class 'int'>
123 <class 'int'>
1.15.2. float()
含义:转换为一个浮点型
格式:float()
- 整型转换为浮点型,会自动添加一位小数
- 只能转换由数字组成的字符串
a = 1
b = float(a)
print(b,type(b))
c = '123'
d = float(c)
print(d,type(d))result:1.0 <class 'float'>
123.0 <class 'float'>
1.15.3. str()
含义:转换为一个字符串型
格式:str()
- 任何类型都可以转换成字符串类型
- float转换成str会取出末位为0的小数部分
num = 123
str_num = str(num)
print(str_num,type(str_num))
li = [1,2,3]
str_li = str(li)
print(str_li,type(str_li))
fl = 1.80
str_fl = str(fl)
print(str_fl,type(str_fl))result:123 <class 'str'>
[1, 2, 3] <class 'str'>
1.8 <class 'str'>
1.15.4. eval
含义:执行一个字符串表达式,并返回表达式的值
格式:eval('表达式')
- 整型与字符串不可以相加
- 可以实现list、dict、tuple、str之间的转换
- 不够安全,容易被恶意修改数据,不建议使用
st = '10+10'
eval_st = eval(st)
print(eval_st,type(eval_st))
#实现字符串与列表转换
str_li = '[[1,2],[3,4],[5,6]]'
eval_li = eval(str_li)
print(eval_li,type(eval_li))
#实现字符串与元组转换
str_tup = "(1,2,'a')"
eval_tup = eval(str_tup)
print(eval_tup,type(eval_tup))
#实现字符串与字典转换
str_dict = "{'name':'bing','age':18}"
eval_dict = eval(str_dict)
print(eval_dict,type(eval_dict))result:20 <class 'int'>
[[1, 2], [3, 4], [5, 6]] <class 'list'>
(1, 2, 'a') <class 'tuple'>
{'name': 'bing', 'age': 18} <class 'dict'>
1.15.5. list
含义:将可迭代对象转换成列表
格式:list(变量名)
- 支持转换为list的类型:str、tuple、dict、set
- 字典转换成列表,会取键名作为列表的值
#字符串转列表
st = '123'
list_st = list(st)
print(list_st,type(list_st))
#元组转列表
tup = (1,2,'a')
list_tup = list(tup)
print(list_tup,type(list_tup))
#集合转列表
se = {'a','b','c','b'}
list_set = list(se)
print(list_set,type(list_set))
#字典转列表
dic = {'name':'bing','age':18}
list_dic = list(dic)
print(list_dic,type(list_dic))result:['1', '2', '3'] <class 'list'>
[1, 2, 'a'] <class 'list'>
['b', 'c', 'a'] <class 'list'>
['name', 'age'] <class 'list'>
1.16. 深浅拷贝
1.16.1. id
含义:查看内存地址
格式:id(变量名)
st = 'abc'
print(id(st))result:2342672860808
1.16.2. 赋值
- 等于完全共享资源,一个值改变会完全被另一个值共享
li1=[1,2,3]
li2 = li1
li2.append(4)
print(li1)
print(li2)
print('str1地址:',id(li1))
print('str2地址:',id(li2))result:[1, 2, 3, 4]
[1, 2, 3, 4]
str1地址: 1689620828104
str2地址: 1689620828104
1.16.3. 浅拷贝(可变对象)
含义:会创建新的对象,拷贝第一层的数据
格式:copy.copy(变量名)
- 嵌套层会指向原来的内存地址
#会创建新的对象,拷贝第一层的数据
li1=[1,2,3,[4,5]]
li2 = copy.copy(li1)
li2.append(4)
print(li1)
print(li2)
print('str1地址:',id(li1))
print('str2地址:',id(li2))
#嵌套层会指向原来的内存地址
li2[3].append(6)
print(li1)
print(li2)
print('str1[3]地址',id(li1[3]))
print('str1[3]地址',id(li2[3]))result:[1, 2, 3, [4, 5]]
[1, 2, 3, [4, 5], 4]
str1地址: 1689626021128
str2地址: 1689626090632
[1, 2, 3, [4, 5, 6]]
[1, 2, 3, [4, 5, 6], 4]
str1[3]地址 1689626090568
str1[3]地址 1689626090568
1.16.4. 深拷贝(可变对象)
含义:外层的对象和内部的元素都拷贝了一遍
格式:copy.deepcopy(变量名)
li1 = [1,2,3,[4,5,6]]
li2 = copy.deepcopy(li1)
li2[3].append(7)
li2.append(8)
print(li1,' ',id(li1),id(li1[3]))
print(li2,id(li2),id(li2[3]))result:[1, 2, 3, [4, 5, 6]] 1627738016776 1627736428296
[1, 2, 3, [4, 5, 6, 7], 8] 1627737951688 1627738016712
1.16.5. 可变类型
含义:变量对应的值可以修改,但是内存地址不会发生改变
- 常见的可变类型:list、dict、set
1.16.6. 不可变类型
含义:存储空间保存的数据不可以被修改,如果被修改就会生成一个新的值从而分配新的内存空间
- 常见的不可变类型:数值类型(int、bool、float、complex)、字符串、元组
1.17. 函数基础
1.17.1. 函数
定义:def 函数名():
函数体
调用:函数名():
1.17.2. 返回值
1.17.2.1. return
- 会给函数的执行者返回值
- 函数中遇到return,表示此函数结束,不继续执行
- return返回多个值,以元组的形式返回给调用者
- 没有返回值,默认None
def buy():
return '西瓜',2
return 20
print(buy())result:('西瓜', 2)
1.17.2.2. return和print的区别
- return表示此函数结束,print会一直执行
- return是返回计算值,print是打印结果
1.17.3. 函数参数
1.17.3.1. 参数的基本格式
定义:def 函数名(形参a,形参b):
函数体
...(如a = 1 b = 2)
调用:函数名(实参1,实参2)
1.17.3.2. 必备参数(位置参数)
含义:传递和定义参数的顺序及个数必须一致
1.17.3.3. 默认参数
含义:为参数提供默认值,调用函数时可不传该默认参数的值
- 所有的必备参数(位置参数)必须出现在默认参数前,包括函数定义和调用
def function(a = 1,b=2):
print(a,b)
function()
function(200)result:1 2
200 2
1.17.3.4. 可变参数
含义:传入的值的数量是可以改变的,可以传入多个,也可以不传
格式:def 函数名(*args)
- 以元组的形式接收
def func(*args):
print(args)
print(type(args))
func('niko','simple','monesy')result:('niko', 'simple', 'monesy')
<class 'tuple'>
1.17.3.5. 关键字参数
含义:可以扩展函数的功能
格式:def func(**kwargs)
def func(**kwargs):
print(kwargs)
print(type(kwargs))
func(name='niko',age=18)result:{'name': 'niko', 'age': 18}
<class 'dict'>
1.17.4. 函数嵌套
含义:在函数中调用函数
def study():
print('study')
def course():
study()
print('math')
study()
course()result:study
study
math
1.17.5. 嵌套定义
含义:在一个函数中定义另外一个函数
def course():
print('python')
def study():
print('English')
study()
course()result:python
English
1.17.6. global
含义:在函数内部修改为全局变量的值
格式:global 变量名,变量名,...
def study():
global name
name = 'python'
print(f"study:{name}")
study()
print(name)result:study:python
python
1.17.7. nonlocal
含义:用来声明外层的局部变量,只对上一级变量进行修改
格式:nonlocal 变量名,变量名,...
- 只能在嵌套函数中使用
def outer1():
a = 1
def inner1():
a = 2
def inner2():
nonlocal a
a = 3
print('inner2:',a)
inner2()
print('inner1:',a)
inner1()
print('outer1:',a)
outer1()result:inner2: 3
inner1: 3
outer1: 1
1.17.8. lambda
定义:函数名 = lambda 形参 :返回值(表达式)
调用:结果 = 函数名(实参)
add = lambda a,b : a + b
print(add(1,2))result:3
1.17.9. lambda的参数形式
- 无参数:返回的就是返回值
- 必备参数:返回传入参数
- 默认参数:默认参数必须放非默认值后面,多个参数返回值要用元组
- 可变参数:以元组的形式接收
- 关键字参数:以字典的形式接收
#无参
Wushen = lambda : "Wushen"
print(Wushen())
#必备参数
Essential_parameters = lambda name: name
print(Essential_parameters('Niko'))
#默认参数
Default_parameters = lambda name,age = 18 : (name,age)
print(Default_parameters('Niko'))
print(Default_parameters('Niko',20))
#可变参数
Variable_parameters = lambda *args : args
print(Variable_parameters('Niko','Simple'))
#关键字参数
Keyword_parameters = lambda **kwargs : kwargs
print(Keyword_parameters(name='Niko',age='18'))result:Wushen
Niko
('Niko', 18)
('Niko', 20)
('Niko', 'Simple')
{'name': 'Niko', 'age': '18'}
1.17.10. lambda结合if
- 只能实现简单的逻辑,如果逻辑复杂且代码量较大,不建议使用lambda,降低代码的可读性,为后期的代码维护增加成本
combine = lambda a,b:'a比b大' if a>b else 'a比b小'
print(combine(5,6))result:a比b小
1.17.11. 内置函数
1.17.11.1. 查看内置函数
格式:dir(builtins)
- 大写字母开头一般是内置常量名,小写字母开头一般是内置函数名
print(dir(builtins))result:['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning', 'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError', 'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning', 'EOFError', 'Ellipsis', 'EnvironmentError', 'Exception', 'False', 'FileExistsError', 'FileNotFoundError', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError', 'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'ModuleNotFoundError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError', 'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError', 'RecursionError', 'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning', 'StopAsyncIteration', 'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning', 'WindowsError', 'ZeroDivisionError', '__build_class__', '__debug__', '__doc__', '__import__', '__loader__', '__name__', '__package__', '__spec__', 'abs', 'all', 'any', 'ascii', 'bin', 'bool', 'breakpoint', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit', 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip']
1.17.11.2. abs
含义:返回绝对值
格式:abs()
print(abs(-12))result:12
1.17.11.3. sum
含义:求和
格式:sum()
- sum要放可迭代对象,如列表、元组、集合
- 字符串不可以进行相加
print(sum([1,2,3]))
print(sum((1,2,3)))
print(sum({1,2,3}))result:6
6
6
1.17.11.4. min
含义:最小值
- 可以放可迭代对象
- 传入了绝对值函数,则参数就会先求绝对值再取结果
print(min(1,2,3))
print(min(-7,-8,-9,key=abs))result:1
-7
1.17.11.5. max
含义:最大值
- 可以放可迭代对象
- 传入了绝对值函数,则参数就会先求绝对值再取结果
print(max(1,2,3))
print(max(1,2,-4,key=abs))result:3
-4
1.17.11.6. zip
含义:将可迭代对象作为参数,将对象中对应的元素打包成一个个元组
格式:zip()
- 可以通过for循环取出
- 如果元素个数不一致,就按照长度最短的返回
- 可以转换成列表打印
li =[1,2,3]
tup = ('a','b')
print(type(zip(li,tup)))
print(zip(li,tup))
for i in zip(li,tup):
print(i)
print(list(zip(li,tup)))
result:<class 'zip'>
<zip object at 0x000002A634D87AC8>
(1, 'a')
(2, 'b')
[(1, 'a'), (2, 'b')]
1.17.11.7. map
含义:可以对可迭代对象中的每一个元素进行映射,分别去执行
格式:map(func,iter1)
- func--自己定义的函数,iter1--要放进去的可迭代对象
- 可以通过for循环取出
- 可以转换成列表打印
funa = lambda x : x + 5
li = [1,2,3]
mp = map(funa,li)
print(type(mp))
print(mp)
for i in mp:
print(i)
print(list(map(funa,li)))result:<class 'map'>
<map object at 0x000001E2D64F1860>
6
7
8
[6, 7, 8]
1.17.11.8. reduce
含义:先把对象中的两个元素取出,计算出一个值然后保存着,接下来把计算值跟第三个元素进 行计算
格式:reduce(function,sequence)
- function--函数:必须有两个参数的函数,sequence--序列:可迭代对象
li = [1,2,3,4]
funa = lambda x,y : x + 2 * y
re = reduce(funa,li) # 1+2*2=5,5+2*3=11,11+2*4=19
print(re)result:19
1.17.12. 拆包
含义:对于函数中的多个返回数据,去掉元组,列表或者字典直接获取里面的数据的过程
- 要求元组内的个数与接收的变量个数相同,对象内有多少个数据就需要定义多少个变量接收
- 先把单独的取完,其它剩下的全部交给带*的变量
tup = (1,2,3)
a,b,c = tup
print(a,b,c)
#方法二
a,*b = tup
print(a,b)result:1 2 3
1 [2, 3]
二、异常、模块和包
2.1. 异常
2.1.1. 常见异常种类
- NameError:使用一个还未被赋值的变量
- SyntaxError:代码不符合python语法规定
- IndexError:下标/索引超出范围
- ZeroDivisionError:除数为0
- keyError:字典里不存在这个键
- IOError:输入/输出操作失败,基本上是无法打开文件(比如你要读的文件不存在)
- AttributeError:对象没有这个属性
- ValueError:传入的值有错误
- TypeError:类型错误,传入的类型不匹配
- ImportError:无法引入模块或包;基本上是路径错误或名称错误
- IndentationError:缩进错误;代码没有正确对齐
2.1.2. 异常处理(捕获异常)
2.1.2.1. try except:
格式:try:
可能引发异常现象的代码(检测的代码块)
except 异常类型(可写可不写):
出现异常现象的处理代码
- 可以声明捕获异常类型,但是遇到其他异常类型依然会报错,无法捕获异常
- 当要捕获多个异常类型时,可把要捕获的异常类型的名字放到except后,并以元组的形式编写
- Exception万能异常,可以捕获任意异常类型
- as相当于取别名,可以打印出异常信息
try:
print(abc)
except (NameError,SyntaxError):
print('异常1')
try:
print(abc)
except Exception:
print('异常2')
try:
print(abc)
except Exception as e:
print('异常3')
print(e)result:异常1
异常2
异常3
name 'abc' is not defined
2.1.2.2. try except else:
格式:try:
可能引发异常现象的代码
except:
出现异常现象的处理代码
else:
没有捕获到异常执行的代码
try:
print('abc')
except Exception:
print('异常')
else:
print('这里是else')result:abc
这里是else
2.1.2.3. try except else finally:
格式:try:
可能引发异常现象的代码
except:
现异常现象的处理代码
else:
没有捕获到异常执行的代码
finally:
try代码块结束后运行的代码
- finally不管怎样都会被执行
- 可以单独使用try...finally...,也可以配合except等使用
2.1.3. raise
含义:自定义异常信息
格式:raise Exception('xxx'),xxx--异常信息
def funa():
pwd = input('输入密码:')
length = len(pwd)
if len(pwd) >= 6:
return '密码输入成功'
raise Exception('密码长度小于6位')
try:
print(funa())
except Exception as e:
print(e)
print(123)result:输入密码:123
密码长度小于6位
123
2.2. 模块
2.2.1. 模块的定义
含义:一个py文件就是一个模块,即导入一个模块本质上就是执行一个py文件
- 内置模块:random、time、os、logging,直接导入即可使用
- 第三方模块:cmd窗口pip install 模块名
- 自定义模块:自己在项目中定义的模块
注意:自定义模块命名要遵循标识符规定以及变量的命名规范,并且不要与内置模块起冲突,否则将导致模块功能无法使用
2.2.2. 导入模块
2.2.2.1. 导入指定模块
格式:import 模块名
调用:模块名.功能名
#创建test.py
print('这是test')
name = 'Niko'
def funa():
print('这是funa')#在主模块导入自定义的test模块,调用其中的功能
import test
print(test.name)
test.funa()result:这是test
Niko
这是funa
2.2.2.2. 从模块中导入指定的部分
格式:from 模块名 import 功能1,功能2...
调用:功能名
- 调用功能直接输入功能即可,不需要添加模块名
- 没有导入就会报错
from test import name,funa
funa()
print(name)
result:这是test
这是funa
Niko
2.2.2.3. 把模块中的所有内容全部导入
格式:from 模块名 import *
调用:功能名
from test import *
funa()
print(name)result:这是test
这是funa
Niko
2.2.2.4. 给模块起别名
格式:import 模块名 as 别名
调用:别名.功能名 , 功能名
import test as t
print(t.name)
t.funa()result:这是test
Niko
这是funa
2.2.2.5. 给功能起别名
格式:from 模块名 import 功能 as 别名
调用:功能名
from test import funa as f,name as n
f()
print(n)result:这是test
这是funa
Niko
2.2.3. 内置全局变量__name__
2.2.3.1. if __name__ == "__main__":
含义:用来控制py文件在不同的应用场景执行不同的逻辑
格式:if __name__ == "__main__":
- 文件在当前程序执行(即自己执行自己):__name__ == "__main__":
#在test.py文件中
print('这是test')
name = 'Niko'
def funa():
print('这是funa')
if __name__ == '__main__':
print('这是main')result:这是test
这是main
- 文件被当做模块被其他文件导入则不会执行main中的代码
#在all.py文件中
import test
test.funa()result:这是test
这是funa
2.2.3.2. if __name__ == '模块名':
格式:if __name__ == '模块名':
- 文件被当做模块被其他文件导入:__name__ == '模块名':
#在test.py文件中
print('这是test1')
name = 'Niko'
def funa():
print('这是funa')
if __name__ == 'test':
print('这是test2')result:这是test1
- 文件被当做模块被其他文件导入则会执行模块中的代码
#在all.py文件中
import test
test.funa()result:这是test1
这是test2
这是funa
2.3. 包
2.3.1. 包的定义
含义:就是项目结构中的文件夹/目录,将有联系的模块放到同一个文件夹下,并且在这个文件夹 中创建一个名字为__init__.py文件,那么这个文件夹就称之为包,有效避免模块名称冲突 问题,让结构更清晰
- 包的本质依然是模块,包又可以包含包
2.3.2. 导包
格式:import 包名
- 当导包时会自动执行__init__.py文件
- 不建议在__init__.py文件中写大量代码
#创建pack_01包,在包中创建register.py文件,在register.py文件中
def funa():
print('这是注册函数')#在__init__.py文件中
print('这是init')#在all.py文件中
import pack_01运行all.py文件
result:这是init
2.3.4. 导包中的模块
格式:from 包名 import 模块名
调用:模块名.功能名
#创建pack_01包,在包中创建register.py文件,在register.py文件中
def funa():
print('这是注册函数')#在__init__.py文件中
print('这是init')在all.py文件中
from pack_01 import register
register.funa()运行all.py文件
result:这是init
这是注册函数
- 将导入模块放入__init__.py文件中
#创建pack_01包,在包中创建register.py文件,在register.py文件中
def funa():
print('这是注册函数')#在__init__.py文件中
print('这是init')
from pack_01 import register
register.register()在all.py文件中
import pack_01result:这是init
这是注册函数
2.3.4. __all__
含义:本质上是一个列表,列表里的元素就代表要导入的模块,可以控制要引入的东西
格式:__all__ = ['模块名'](在__init__.py文件中)
from 包名 import * (在all.py文件中)
#创建pack_01包,在包中创建register.py文件,在register.py文件中
def funa():
print('这是注册函数')#在__init__.py文件中
print('这是init')
__all__ = ['register']在all.py文件中
from pack_01 import register
register.register()result:这是init
这是注册函数
三、闭包
3.1. 递归函数
条件:
- 必须有一个明确的结束条件
- 每进行更深一次的递归,问题规模相比上次递归都要有所减少
- 相邻两次重复之间有紧密的联系
#进行数值累加,1+2+3+...+n
def add(n):
if n == 1:
return 1
return n + add(n - 1)
print(add(10))
result:55
#斐波那契数列,1,1,2,3,5,8,13...
def Fibonacci(n):
if n == 1:
return 1
if n == 2:
return 1
return Fibonacci(n-2) + Fibonacci(n-1)
print(Fibonacci(7))result:13
3.2. 闭包
含义:在嵌套函数的前提下,内部函数使用了外部函数的变量,而且外部函数返回了内部函数, 我们就把使用了外部函数变量的内部函数称为闭包。
调用:函数名()()
def outer():
n = 10
def inner():
print(n)
return inner
print(outer())#返回的是内部函数的内存地址
print(type(outer()))
outer()()result:<function outer.<locals>.inner at 0x0000020218D03BF8>
<class 'function'>
10
def outer(m):
n = 10
def inner(o):
print(n+m+o)
return inner
outer(20)(20)result:50
3.3. 函数引用
- test也只不过是一个函数名,里面存了这个函数所在位置的引用
def test():
print(123)
print(id(test))
te = test
print(id(te))result:2201195582736
2201195582736
四. 装饰器
4.1. 装饰器
含义:本质是一个闭包函数,它可以让其他函数在不需要做任何代码变动的前提下增加额外功 能,装饰器的返回值也是一个函数对象
#被装饰函数1
def send1():
print('发送消息1')
#被装饰函数2
def send2():
print('发送消息2')
#装饰器函数
def all(fn):
def login():
print('登录')
fn()
return login
all(send1)()
all(send2)()result:登录
发送消息1
登录
发送消息2
4.2. 语法糖
格式:@装饰器名称
- 在被装饰函数前加
- 装饰器名称后面不要加上(),前者是引用,后者是调用函数,返回该函数要返回的值
def outer(fn):
def inner():
print('登录')
fn()
return inner
#被装饰函数
@outer
def send():
print('发送消息')
send()result:登录
发送消息
4.3. 多个装饰器
- 多个装饰器的装饰过程,离函数最近的装饰器先装饰,然后外面的装饰器再进行装饰,由内到外的装饰过程
def deco1(fn):
def inner():
return '开头1'+fn()+'结尾1'
return inner
def deco2(fn):
def inner():
return '开头2'+fn()+'结尾2'
return inner
@deco1
@deco2
def test():
return '多拉贡'
print(test())result:开头1开头2多拉贡结尾2结尾1
五、面向对象基础
5.1. 面相对象与面相过程
面相过程:先分析出解决问题的步骤,再把步骤拆成一个个方法,是没有对象去调用的,通过一 个个方法的执行解决问题
面向对象:将编程当成是一个事物(对象),对外界来说,事物是直接使用的,不用去管内部的情 况,而编程就是设置事物能做什么事情
面相对象的三大特征:封装、继承、多态
5.2. 类
5.2.1. 类的定义
类:一系列具有相同属性和行为的事物的统称,不是真是存在的事物
对象:类的具体实现,是类创建出来的真实纯在的事物,面相对象思想的核心
5.2.2. 类的三要素
1.类名
2.属性:对象的特征描述,用来说明是什么样子的
3.方法:对象具有的功能(行为),用来说明能够做什么
5.2.3. 定义类
格式:class 类名:
代码块
class Washer:
height = 100
print(Washer.height)
Washer.weight = 50
print(Washer.weight)result:100
50
5.3. 对象
5.3.1. 创建对象
格式:对象名 = 类名()
- 创建对象的过程也叫实例化对象
- 可以实例化多个对象
class Washer:
height = 500 #类属性
wa1 = Washer()
wa2 = Washer()
print(type(wa1))
print(wa1)
print(wa2)result:<class '__main__.Washer'>
<__main__.Washer object at 0x00000243CFF12908>
<__main__.Washer object at 0x00000243CFF1A160>
5.3.2. 实例方法
含义:由对象调用,至少有一个self参数,执行实例方法的时候,自动将调用该方法的对象赋值给 self
- self参数是类中的实例方法必须具备的
- self表示当前调用该方法的对象,当对象调用实例方法时,python会自动将对象本身的引用作为参数,传递到实例方法的第一个参数self里面
class Washer:
height = 500 #类属性
def wash(self): #类方法,self参数是类中的实例方法必须具备的
print('洗衣服')
print(self) #self表示当前调用该方法的对象
wa = Washer()
print(wa)
wa.wash() #对象调用类方法result:<__main__.Washer object at 0x0000023F2A7F1978>
洗衣服
<__main__.Washer object at 0x0000023F2A7F1978>
5.3.3. 实例属性
格式:self.属性名
- 类属性属于类,是公共的,大家都可以访问,实例属性属于对象的,是私有的
- 只能由对象名访问,不能由类名访问
- 一个对象新增的实例属性,其他对象依然是没有这个属性的
class Person:
name = 'Niko' #类属性
def introduce(self): #类方法,self参数是类中的实例方法必须具备的
print('实例方法')
print(f"{Person.name}的年龄是{self.age}")
pe = Person()
pe.age = 18 #实例属性
pe.introduce()result:实例方法
Niko的年龄是18
5.4. 构造函数
含义:通常用来做属性初始化或者赋值操作
格式:__init__()
- 在类实例化对象的时候,会自动调用__init()__的方法
class Person:
def __init__(self):
print('__init__')
pe = Person()result:__init__
- 在实例化对象的时候传参
class Person:
def __init__(self,name,age,height):
self.name = name
self.age = age
self.height = height
def play(self):
print(f"{self.name}在打王者荣耀")
def introduce(self):
print(f"{self.name}的年龄是{self.age},身高是{self.height}cm")
pe1 = Person('Niko',18,180)
pe1.play()
pe1.introduce()
pe2 = Person('Simple',28,170)
pe2.play()
pe2.introduce()result:Niko在打王者荣耀
Niko的年龄是18,身高是180cm
Simple在打王者荣耀
Simple的年龄是28,身高是170cm
5.5. 析构函数
含义:删除对象的时候,解释器会默认调用__del__()方法
格式:__del__()
- 正常运行时,不会调用__del__(),对象执行结束之后,系统会自动调用__del__()
class Person:
def __init__(self):
print("init")
def __del__(self):
print("del")
pe = Person()
print('最后一行代码')result:init
最后一行代码
del
- del p语句执行时,内存会被立即回收,会调用对象本身的__del__()方法
class Person:
def __init__(self):
print("init")
def __del__(self):
print("del")
pe = Person()
del pe
print('最后一行代码')result:init
del
最后一行代码
六、封装
6.1. 隐藏属性、方法
6.1.1. 隐藏属性
含义:隐藏对象中一些不希望被外部所访问到的属性或者方法
格式:在属性名前面加上两个__
- 隐藏属性(私有权限):只允许在类的内部使用,无法通过对象访问
class Person:
name = 'Nike'
__age = 18
def introcuce(self):
self.__age = 28
print(f"{self.name}的年龄是{self.__age}")
pe = Person()
pe.introcuce()result:Nike的年龄是28
- 隐藏属性实际上是将名字修改为:_类名__属性名
class Person:
name = 'Nike'
__age = 18
def introcuce(self):
print(f"{self.name}的年龄是{self.__age}")
pe = Person()
pe._Person__age = 38
pe.introcuce()result:38
6.1.2. 隐藏方法
格式:在方法名前面加上两个__
- 隐藏方法(私有权限):只允许在类的内部使用,无法通过对象访问
class Person:
def __play(self):
print("玩手机")
def funa(self):
print('Niko')
Person.__play(self) #在实例方法中调用私有方法 不推荐
self.__play() # 推荐使用,更简便
pe = Person()
pe.funa()result:Niko
玩手机
玩手机
- 隐藏方法实际上是将名字修改为:_类名__方法名
class Person:
def __play(self):
print("玩手机")
def funa(self):
print('Niko')
pe = Person()
pe._Person__play()
result:玩手机
6.2. 私有属性、方法
6.2.1. 私有属性
格式:在属性名前面加上一个_
class Person:
name = 'Niko'
_age = 18
__sex = '男'
pe = Person()
print(pe._age)result:18
6.2.1. 私有方法
格式:在方法名前面加上一个_
class Girl:
def _buy(self):
print("shopping")
girl = Girl()
girl._buy()result:shopping
6.3. 普通、私有、隐藏属性\方法的区别
普通属性/方法:xxx
- 如果是类中定义的,则类可以在任意地方使用
私有属性/方法:_xxx
- 单下划线开头,如果定义在类中,外部可以使用,子类也可以继承,但是在另一个py文件中通过from xxx import * 导入时,无法导入,一般是为了避免与Python关键字冲突而采用的命名方法
隐藏属性方法:__xxx
- 双下划线开头,如果定义在类中,无法在外部直接访问,子类不会继承,要访问只能通过间接的方式,另一个py文件中通过from xxx import *导入的时候,也无法导入,这种命名一般是Python的魔术方法或属性,都是有特殊含义或者功能的,自己不要轻易定义
七、继承
7.1. 继承的定义
含义:就是让类和类之间转变为父子关系,子类默认继承父类的属性和方法
格式:class 类名(父类名)
代码块
7.2. 单继承
7.2.1. 单继承的定义
含义:子类可以继承父类的属性和方法,就算子类自己没有,也可以使用父类
- pass是占位符,类下面不写任何东西,会自动跳过
class Person():
def eat(self):
print('吃饭')
def sleep(self):
print('睡觉')
class Girl(Person):
pass #pass是站位符,可以直接跳过
class Boy(Person):
pass
girl = Girl()
girl.eat()
girl.sleep()
boy = Boy()
boy.eat()
boy.sleep()result:吃饭
睡觉
吃饭
睡觉
7.2.2. 继承的传递(多重继承)
含义:C类继承与B类,B类继承与A类,C类具有A、B类的属性和方法
class Father():
def eat(self):
print('吃饭')
class Son(Father):
def sleep(self):
print('睡觉')
class Grandson(Son):
pass
son = Son()
son.sleep()
son.eat()result:睡觉
吃饭
7.2.3. 方法的重写
含义:如果从父类继承的方法不能满足子类的需求,可以在子类中重写父类的方法,这个过程称 为方法的覆盖,也称方法的重写
7.2.3.1. 方法一
格式:父类名.方法名(self)
class Father():
def money(self):
print('继承100万')
class Son(Father):
def money(self):
Father.money(self)
print('赚100万')
son = Son()
son.money()result:继承100万
赚100万
7.2.3.2. 方法二(推荐)
格式:super().方法名()
- super在python里面是一个特殊的类,super()是使用super类创建出来的对象,可以调用父类中的方法
class Father():
def money(self):
print('继承100万')
class Son(Father):
def money(self):
super().money()
print('赚100万')
son = Son()
son.money()result:继承100万
赚100万
7.2.3.3. 方法三
格式:super(子类名,self).方法名
class Father():
def money(self):
print('继承100万')
class Son(Father):
def money(self):
super(Son,self).money()
print('赚100万')
son = Son()
son.money()
result:继承100万
赚100万
7.3. 新式类写法
7.3.1. 第一种(经典类)
格式:class A:
- 经典类:不由任意内置类型派生出来的类
- 派生类:子类有不同于父类的属性或者方法
7.3.2. 第二种(经典类)
格式:class A():
7.3.3. 第三种(新式类)
格式:class A(object):
- 新式类:继承了object类或者该类的子类都是新式类
- object——对象,python为所有对象提供的基类(顶级父类),提供了内置属性与方法,dir()查看
- python3中如果一个类没有继承任何类,则默认继承object类,因为python3都是新式类
print(dir(object))result:['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__le__', '__lt__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__']
7.4. 多继承
7.4.1. 多继承的定义
含义:子类可以拥有多个父类,并且具有所有父类的属性和方法
class Father(object):
def eat(self):
print('eat')
class Mother(object):
def drink(self):
print('drink')
class Son(Father,Mother):
pass
son = Son()
son.eat()
son.drink()result:eat
drink
7.4.2. 不同的父类存在同名的方法
- 有多个父类的属性和方法,如果多个父类具有同名方法的时候,调用就近原则,括号内哪一个最近,优先调用哪一个类的方法
class Father(object):
def eat(self):
print('apple')
class Mother(object):
def eat(self):
print('banana')
class Son(Father,Mother):
pass
son = Son()
son.eat()result:apple
7.4.3. 方法的搜索顺序
含义:用来查看方法的搜索顺序
格式:类名().__mro_
print(Son.__mro__)result:(<class '__main__.Son'>, <class '__main__.Father'>, <class '__main__.Mother'>, <class 'object'>)
7.4.4. 多继承的弊端
- 容易引发冲突
- 会导致代码设计的复杂度增加
八、多态
8.1. 多态的定义
含义:指同一种行为具有不同的表现形式
- 不关注对象的类型,关注对象具有的行为,也就是对象的实例方法是否同名
- 多态的好处可以增加代码的外部调用灵活度,让代码更加通用,兼容性比较强
- 不同的子类对象,调用相同的父类方法,会产生不同的执行结果
class Animal(object):
"""父类:动物类"""
def shout(self):
print('动物叫')
class Cat(Animal):
"""子类一:猫类"""
def shout(self):
print("猫叫")
class Dog(Animal):
"""子类二:狗类"""
def shout(self):
print('狗叫')
dog = Dog()
dog.shout()
cat = Cat()
cat.shout()result:狗叫
猫叫
8.2. 多态性
含义:定义一个统一的接口,一个接口多种实现
class Animal(object):
def eat(self):
print('进食')
class Pig(Animal):
def eat(self):
print("吃饲料")
class Dog(Animal):
def eat(self):
print('吃狗粮')
def test(obj):
obj.eat()
animal = Animal()
pig = Pig()
dog = Dog()
test(animal)
test(pig)
test(dog)result:进食
吃饲料
吃狗粮
九、静态方法
格式:class 类名:
@staticmethod
def 方法名(形参):
方法体
调用:类名.方法名(实参)
对象名.方法名(实参)
- 使用@staticmethod来进行修饰,静态方法没有self,cls参数的限制
- 静态方法与类无关,可以被转化成函数使用
- 静态方法既可以使用对象访问,也可以使用类访问
- 取消不必要的参数传递,有利于减少不必要的内存占用和性能消耗
class Person(object):
@staticmethod
def study(name):
print(f"{name}学习")
Person.study('Niko')
person = Person()
person.study('Niko')result:Niko学习
Niko学习
十、类方法
含义:使用装饰器@classmethod来标识为类方法,对于类方法,第一个参数必须是类对象,一般 是以cls作为第一个参数
格式:class 类名:
@classmethod
def 方法名(cls):
方法体
- cls代表类对象本身,类本质上就是一个对象
- 当方法中需要使用到类对象(如访问私有类属性等),定义类方法
- 类方法一般是配合类属性使用
- 在调用时不需要传递cls
class Person(object):
name = "Niko"
@classmethod
def sleep(cls):
print(cls)
print(cls.name)
print(Person)
Person.sleep()result:<class '__main__.Person'>
<class '__main__.Person'>
Niko
十一、三大方法总结
在类中定义方法有三种:
- 实例方法:里面有个self参数,代表对象本身,方法内部可以访问实例属性,通过self.实例属性名来访问实例属性,也可以通过类名.类属性名来访问类属性。
- 静态方法:@staticmethod,没有形参的限制,不需要访问实例属性和类属性,如果要访问类属性,通过类名.类属性名访问,不能访问实例属性。
- 类方法:@classmethod,只能访问类属性,通过cls.类属性名来访问类属性
十二、单例模式
12.1. __new__()
含义:在内存中为对象分配空间,返回对象的引用
- 一个对象的实例化过程:首先执行__new__(),如果没有写__new__(),默认调用object里面的__new__(),返回一个实例对象,这个实例对象的引用作为第一个参数也就是self参数,self代表对象本身,再去调用__init__(),对、对象进行一个初始化
- object基类提供的内置的静态方法
- 重写__new__()一定要return,super().__new__(cls),否则python解释器得不到分配空间的对象引用,就不会调用__init__()
class Test(object):
def __init__(self):
print('self:',self) #self代表对象本身,跟te是一个东西
#new方法是object里面默认的方法,他是有自己的作用的,现在重写了一个print
#相当于是改变了他的功能
def __new__(cls, *args, **kwargs): #cls代表类本身
print('cls: ',cls)
# 对父类进行扩展 super().方法名()
res = super().__new__(cls)
print('res:',res)
#方法重写,res里面保存的是实例对象的引用
#__new__()是静态方法,形参里面有cls,实参就必须传cls
return res
te = Test()
print('te: ',te)
print('Test:',Test)result:cls: <class '__main__.Test'>
res: <__main__.Test object at 0x0000014DB3275F60>
self: <__main__.Test object at 0x0000014DB3275F60>
te: <__main__.Test object at 0x0000014DB3275F60>
Test: <class '__main__.Test'>
12.2. __new__()与__init__()区别
- __new__()是创建对象,__init__()是初始化对象
- __new__()是返回对象引用,__init__()定义实例属性
- __new__()是类级别的方法,__init__()是实例级别的方法
12.3. 单例模式的定义
含义:一种常用的软件设计模式,该模式的主要目的是确保某一个类只有一个实例存在。当你希 望在整个系统中,某个类只能出现一个实例时,单例模式就能派上用场。
- 优点:可以节省内存空间,减少了不必要的资源浪费
- 缺点:多线程访问的时候容易引发线程安全问题
12.4. 单例模式的实现
含义:对象的内存地址都是一样的,只有一个对象
- 通过@classmethod
- 通过装饰器实现
- 通过重写__new__()
- 通过导入模块实现
12.4.1. 通过重写__new__()实现单例模式
设计流程
- 定义一个类属性,初始值为None,用来记录单例对象的引用
- 重写__new__()方法
- 进行判断,如果类属性是None,把__new__()返回的对象引用保存进去
- 返回类属性中记录的对象引用
class Singleton(object):
obj = None
def __new__(cls, *args, **kwargs):
pass
if cls.obj == None:
cls.obj = super().__new__(cls)
return cls.obj
def __init__(self):
pass
s1 = Singleton()
print("s1:",s1)
s2 = Singleton()
print("s2:",s2)result:s1: <__main__.Singleton object at 0x000001EDC9FD8A90>
s2: <__main__.Singleton object at 0x000001EDC9FD8A90>
12.4.2. 通过导入模块实现
模块就是天然的单例模式
# 创建test.py文件,在test.py文件中
class Test(object):
def test(self):
pass
te = Test()
#在主文件中
from test import te as te01
from test import te as te02
print(te01,id(te01))
print(te02,id(te02))result:<test.Test object at 0x0000024D14D840F0> 2530085454064
<test.Test object at 0x0000024D14D840F0> 2530085454064
12.5. 单例模式的应用场景
- 回收站(只能打开一个回收站)
- 音乐播放器(一个音乐播放软件负责音乐播放的对象只有一个
- 开发游戏软件(场景管理器)
- 数据库配置、数据库连接池的设计
十三、魔法方法&魔法属性
含义:在Python中,__xx__()的函数叫做魔法方法,指的是具有特殊功能的函数
- __new__():在内存中为对象分配空间并返回对象的引用
- __init__():初始化对象或给属性赋值(构造函数)
- __doc__:类的描述信息
- __module__:表示当前操作对象所在模块
- __class__:表示当前操作对象所在的类
- __str__():对象的描述信息
- __del__():删除对象(析构函数)
- __call__():使一个实例对象成为一个可调用对象
- __dict__:返回对象具有的属性和方法
13.1. __doc__
含义:类的描述信息,属于魔法属性
- 只能使用多行注释,单行注释无效
class Person(object):
"""人类---类的描述信息""" #只能使用多行注释,单行注释无效
pass
print(Person.__doc__)result:人类---类的描述信息
13.2. __module__
含义:表示当前操作对象所在模块
#在main.py文件中
class Person(object):
"""人类---类的描述信息""" #只能使用多行注释,单行注释无效
pass
pe = Person()
print(pe.__module__)result:__main__
13.3. __class__
含义:表示当前操作对象所在的类
class Person(object):
"""人类---类的描述信息""" #只能使用多行注释,单行注释无效
pass
pe = Person()
print(pe.__class__)result:<class '__main__.Person'>
13.4. __str__()
含义:如果类中定义了此方法,那么在打印对象时,默认输出该方法的返回值,也就是打印方法 中return的数据
- __str__()必须返回一个字符串
class Person(object):
def __str__(self):
return 'str'
pe = Person()
print(pe)result:str
13.5. __call__()
含义:使一个实例对象成为一个可调用对象,就像函数那样可以调用
- 可调用对象:函数、内置函数和类都是可调用对象,凡是可以把一对()应用到某个对象身上都可以称为可调用对象
- callable():判断一个对象是否是可调用对象
- 调用一个可调用的实例对象,其实就是在调用它的__call__()方法
class Person(object):
pass
pe = Person()
print(callable(pe))
def test():
print('test')
print(callable(test))result:False
True
class Person(object):
def __call__(self, *args, **kwargs):
print('call')
def test(self):
print('test')
pe = Person()
pe() #调用一个可调用的实例对象,其实就是在调用它的__call__()方法
print(callable(pe))result:call
True
13.6. __dict__
含义:返回对象具有的属性和方法
class Person(object):
obj1 = None
def test(self):
print('test')
pe = Person
print(pe.__dict__)result:{'__module__': '__main__', 'obj1': None, 'test': <function Person.test at 0x0000019F5163E510>, '__dict__': <attribute '__dict__' of 'Person' objects>, '__weakref__': <attribute '__weakref__' of 'Person' objects>, '__doc__': None}
十四、文件
14.1. 文件对象的方法
- open():创建一个file对象,默认是以只读模式打开的
- read(n):读取文件内容
- write():将指定内容写入文件
- close():关闭软件
14.2. 文件属性
- 文件名.name:返回要打开的文件的文件名,可以包含文件的具体路径
- 文件名.mode:返回文件的访问模式
- 文件名.closed:检测文件是否关闭,关闭就返回True
f = open('test.txt')
print(f.name)
print(f.mode)
print(f.closed)
f.close() #文件不关闭,会一直占用系统资源
print(f.closed)result:test.txt
r
False
True
14.3. 文件读写
14.3.1. read()
含义:读取文件内容
- n表示从文件中读取的数据的长度,没有传n值或负值就默认一次性读取文件的所有内容
#在test.txt文件中写入Hello World!!
f = open('test.txt')
print(f.read(2))
print(f.read())
f.close()result:He
llo World!!
打开桌面的test.txt文件
#在桌面的text.txt文件中内容是:HelloWorld!!!
f = open(r'C:\Users\Sagapohh\Desktop\test.txt',encoding='utf-8')
print(f.read(2))
print(f.read())
print(f.name)
f.close()result:He
llo World!!!
C:\Users\Sagapohh\Desktop\test.txt
14.3.2. readline()
含义:一次读取一行内容,方法执行完,会把文件指针移到下一行,准备再次读取
# 在text.txt文件中的内容
# Hello World 1
# Hello World 2
# Hello World 3
f = open('test.txt')
while True:
text = f.readline()
if not text:
break
print(text)
f.close()result:Hello World 1
Hello World 2
Hello World 3
14.3.3. readlines()
含义:按照行的方式一次性读取全部内容
- 返回的是一个列表,每一行的数据就是列表中的一个元素
f = open('test.txt')
text = f.readlines()
print(text)
for i in text:
print(i)
f.close()result:['Hello Word 1\n', 'Hello Word 2\n', 'Hello Word 3\n']
Hello World 1
Hello World 2
Hello World 3
14.4. 访问模式
- r:只读模式,文件必须存在,不存在就会报错
- w:只写模式,文件存在就会先清空文件内容,再写入添加内容,不存在就创建新文件
- +:表示可以同时读写某个文件(会影响文件的读写效率,开发过程中多数是只读、只写)
- r+:可读写文件,文件不存在就会报错
- w+:先写再读,文件存在就重新编辑文件,不存在就创建新文件
- a:追加是,不存在就创建新文件进行写入,存在则在原有的内容的基础上追加新的内容
14.5. 文件定位
tell():显示文件内当前位置,即文件指针当前位置
seek(offset,where):移动文件读取指针到指定位置
offset:偏移量,表示要移动的字节数
where:起始位置,表示移动字节的参考位置,默认是0,0代表文件开头,1代表当前位置,2代 表文件结尾
- 文件内容写入后指针在结尾,文件读取从指针后开始读取
- 文件指针:标记从哪个位置开始读取数据
f = open('test.txt','w+')
f.write('Hello World!')
pos1 = f.tell()
print('pos:',pos1)
f.seek(0,0)
pos2 = f.tell()
print('pos:',pos2)
print(f.read())
f.close()result:pos: 12
pos: 0
Hello World!
14.6. 编码格式
14.6.1. with open
含义:代码执行完,系统会自动调用f.close(),可以省略文件关闭步骤
with open('test.txt','w') as f:
f.write('aaa')
print(f.closed)result:True
14.6.2. encoding
- file对象的encoding参数的默认值与平台有关,比如windows上默认字符编码为GBK
- encoding表示编码集,根据文件的实际保存编码进行获取获取数据,对于我们而言,使用更多的是utf-8
with open('test.txt','w+',encoding='utf-8') as f:
f.write('我是Niko')
f.seek(0,0)
print(f.read())result:我是Niko
14.7. 读取图片
- rb:以字节来读取图片
- wb:以字节写入图片
with open(r'G:\图片\1.jpg','rb') as f1:
img = f1.read()
with open(r'E:\python-projects\1.jpg','wb') as f2:
f2.write(img)result:在我们的项目中就会出现我们添加进来的照片
14.8. 目录操作
条件:需要导入模块--import os
14.8.1. os.rename()
含义:文件重命名
os.rename('test.txt','123.txt')14.8.2. os.remove()
含义:删除文件
os.remove('123.txt')14.8.3. os.mkdir()
含义:创建文件夹
os.mkdir('test')14.8.4. os.rmdir()
含义:删除文件夹
os.rmdir('test')14.8.5. os.getcwd()
含义:获取当前目录
print(os.getcwd())result:E:\python-projects
14.8.6. os.listdir()
含义:获取目录列表
- os.listdir('../')--返回上一级列表
print(os.listdir())result:['.idea', '1.jpg', 'bbs_login.feature', 'emails', 'main.py', 'test.py', '__pycache__']
十五、可迭代对象、迭代器、生成器
15.1. 可迭代对象
15.1.1. 可迭代对象的定义
含义:可迭代对象Iterable--能被for循环依次从对象中把一个个元素取出来的过程
数据类型:str、list、tuple、dict、set等
15.1.2. 可迭代对象的条件
- 对象实现了__iter__()方法
- __iter__()方法返回了迭代器对象
15.1.3. for循环工作原理
- 通过__iter__()获取可迭代对象的迭代器
- 对获取到的迭代器不断调用__next__()方法来获取下一个值并将其赋值给临时变量i
15.1.4. isinstance():
含义:判断一个对象是否是可迭代对象或者是一个已知的数据类型
格式:isinstance(o,t)
- o:对象,t:类型,可以是直接或间接类名、基本类型或元组
from collections.abc import Iterable
st = '123'
print(isinstance(123,Iterable))
print(isinstance(st,(int,str)))result:False
True
15.2. 迭代器
15.2.1. 迭代器的定义
含义:是一个可以记住遍历位置的对象,在上次停留的位置继续做一些事情
15.2.1. iter()、next()
迭代器中有两个函数一个是iter(),一个是next()
iter():获取可迭代对象的迭代器
next():一个个去取元素,取完元素后会引发一个异常
- iter()调用对象的__iter__(),并把__iter__()方法的返回结果作为自己的返回值
- next()调用对象的__next__(),一个个取元素
- 所有元素都取完了,__next__()将引发StopIteration异常
li = [1,2,3]
li2 = iter(li) #创建迭代器对象
print(li2)
print(next(li2))#获取下一条数据
print(next(li2))
print(next(li2))
print(next(li2))#取完元素后,再使用next()会引发StopIteration异常result:<list_iterator object at 0x000001C67D358AC8>
1
2
3
Traceback (most recent call last):
File "E:\python-projects\main.py", line 12, in <module>
print(next(li2))#取完元素后,再使用next()会引发StopIteration异常
StopIteration
- dir():查看对象的属性和方法
- 通过dir()可以发现li1中有'__iter__',没有'__next__',而li2有'__next__'
li = [1,2,3]
print('li1:',dir(li))#li中没有__next__()方法
li2 = li.__iter__()
print('li2:',dir(li2))#li2中有__next__()方法
print(li2)
print(li2.__next__())
print(li2.__next__())
print(li2.__next__())
print(li2.__next__())result:li1: ['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
li2: ['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__length_hint__', '__lt__', '__ne__', '__new__', '__next__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__']
<list_iterator object at 0x000002A026CD5908>
1
2
3
Traceback (most recent call last):
File "E:\python-projects\main.py", line 9, in <module>
print(li2.__next__())
StopIteration
15.2.2. 可迭代对象iterable和迭代器iterator
- 凡是可以作用于for循环的都属于可迭代对象
- 凡是可以作用于next()的都是迭代器
from collections.abc import Iterable, Iterator
name = 'Niko'
print(isinstance(name,Iterable))
print(isinstance(name,Iterator))
name2 = iter(name)#将name转换成迭代器对象
print(isinstance(name2,Iterable))
print(isinstance(name2,Iterator))
#迭代器对象一定是可迭代对象result:True
False
True
True
15.2.3. 迭代器协议
对象必须提供一个next方法,执行该方法要么就返回迭代中的下一项,要么就引发StopIteration异常,来终止迭代
15.2.4. 自定义迭代器类
- 满足两个条件:iter()、next()
class Person(object):
def __init__(self):
self.num = 0
def __iter__(self):
return self #返回的是当前迭代器类的实例对象
def __next__(self):
if self.num == 10:
raise StopIteration('终止迭代,数据已经被取完')
self.num += 1
return self.num
pe = Person()
for i in pe:
print(i)result:1
2
3
4
5
6
7
8
9
10
15.3. 生成器
15.3.1. 生成器的定义
含义:Python中一边循环一边计算的机制,叫做生成器
格式:(表达式 for 变量 in 列表)
li = (i*5 for i in range(5))
print(li)
for i in li:
print(i)
print(next(li))result:<generator object <genexpr> at 0x00000174BB6D90C0>
0
5
10
15
20
Traceback (most recent call last):
File "E:\python-projects\main.py", line 10, in <module>
print(next(li))
StopIteration
15.3.2. 生成器函数
含义:pyhton中,使用了yield关键字的函数就称之为生成器函数
yield的作用:
- 类似于return,将指定值或者多个值返回给调用者
- yield语句一次返回一个结果,在每个结果中间,挂起函数,执行next(),再重新从挂起点继续往下执行
def gen():
yield 'a'#返回一个'a',并暂停函数,在此处挂起,下一次再从此处恢复运行
yield 'b'
yield 'c'
gen_01 = gen()
print(gen_01)
for i in gen_01:
print(i)
result:<generator object gen at 0x00000240928D90C0>
a
b
c
def gen(n):
li = []
a = 0
while a < n:
li.append(a)
yield a
a += 1
print('li:',li)
print(gen(5))
for i in gen(5):
print(i)
result:<generator object gen at 0x00000263F76090C0>
0
1
2
3
4
li: [0, 1, 2, 3, 4]
def test():
yield 'a'
yield 'b'
yield 'c'
print(test())
print(next(test()))
print(next(test()))
te = test()
print(next(te))
print(next(te))
print(next(te))result:<generator object test at 0x0000023CF6F890C0>
a
a
a
b
c
15.3.3. 三者关系
可迭代对象:指实现了python迭代协议,可以通过for...in...循环遍历的对象,比如list、dict、str...、迭代器、生成器
迭代器:可以记住自己遍历位置的对象,直观体现就是可以使用next()函数返回值,迭代器只能往前,不能往后,当遍历完毕之后,next()会抛出异常
生成器:是特殊的迭代器,需要注意的是迭代器并不一定是生成器,他是python提供的通过简便的方法写出迭代器的一种手段
包含关系:可迭代对象 > 迭代器 > 生成器
十六、线程
16.1. 线程的定义
含义:是cpu调度的基本单位
- 每一个进程至少都会有一个线程,这个线程通常就是我们所说的主线程
- 线程之间执行是无序的
- 线程执行由cpu调度决定的
- 线程同时进行,存在资源竞争
16.2. 线程语法结构
- threading模块提供了Thread类代表进程对象
16.2.1. Thread参数
target:执行的目标任务名,即子进程要执行的任务
args:以元组的形式传参
kwagrs:以字典的形式传参
16.2.2. 常用的方法
1. start():开启子进程
2. join():主进程等待子进程执行结束
3. getName():获取线程名
4. setName():修改线程名
16.3. 线程之间共享资源(全局变量)
import time
from threading import Thread
li = []
def wdata():
for i in range(5):
li.append(i)
time.sleep(0.2)
print('写入的数据:',li)
def rdata():
print('读取的数据:',li)
if __name__ == '__main__':
#创建子线程
t1 = Thread(target=wdata)
t2 = Thread(target=rdata)
t1.start()
t2.start()
result:读取的数据: [0]
写入的数据: [0, 1, 2, 3, 4]
16.4. 防止线程同步
防止线程同步两种方式:join和互斥锁
16.4.1. join()
含义:阻塞线程,等待任务结束
import time
from threading import Thread
li = []
def wdata():
for i in range(5):
li.append(i)
time.sleep(1)
print('写入的数据:',li)
def rdata():
print('读取的数据:',li)
if __name__ == '__main__':
#创建子线程
t1 = Thread(target=wdata)
t2 = Thread(target=rdata)
t1.start()
t1.join()#阻塞线程,等待t1任务执行结束
t2.start()
t2.join()result:写入的数据: [0, 1, 2, 3, 4]
读取的数据: [0, 1, 2, 3, 4]
16.4.2. 互斥锁
含义:对共享数据进行锁定,保证多个线程访问共享数据不会出现数据错误问题,保证同一时刻只能有一个线程去操作。
创建互斥锁:变量名 = Lock()
格式:变量名.acquire() 上锁
变量名.release() 释放锁
- 互斥锁是多个线程一起去抢,抢到锁的线程先执行
from threading import Thread, Lock
a = 0
b = 1000000
lock = Lock()
def add():
lock.acquire()
for i in range(b):
global a
a += 1
print('第一次:',a)
lock.release()
def add2():
lock.acquire()
for i in range(b):
global a
a += 1
print('第二次:',a)
lock.release()
if __name__ == '__main__':
first = Thread(target=add)
secon = Thread(target=add2)
first.start()
secon.start()result:第一次: 1000000
第二次: 2000000
16.5. 多线程
含义:同时运行多个线程
格式:threading.Thread
- 多线程可以完成多任务
- 一个进程默认有一个线程,进程里面可以创建多个线程,线程是依附在进程里面的,没有进程就没有线程
import threading
import time
def sing():
print('唱歌start')
time.sleep(2)
print('唱歌end')
def dance():
print('跳舞start')
time.sleep(2)
print('跳舞end')
if __name__ == '__main__':
t1 = threading.Thread(target=sing)
print(t1)
t2 = threading.Thread(target=dance)
t1.start()
t2.start()result:<Thread(Thread-1, initial)>
唱歌start
跳舞start
跳舞end
唱歌end
16.6. 守护线程
含义:主线程执行结束,子线程也会跟着结束
格式:setDaemon(True)
- 放在start()前面
import threading
import time
def sing():
print('唱歌start')
time.sleep(2)
print('唱歌end')
def dance():
print('跳舞start')
time.sleep(2)
print('跳舞end')
if __name__ == '__main__':
t1 = threading.Thread(target=sing)
print(t1)
t2 = threading.Thread(target=dance)
#守护进程,必须放在start()前面:主线程执行结束,子线程也会跟着结束
t1.setDaemon(True)
t2.setDaemon(True)
t1.start()
t2.start()
#阻塞主线程join():暂停的作用,等子线程执行结束后,主线程才会继续执行,必须放在start()后面
t1.join()#
t2.join()
print('完美谢幕,本次表演结束')result:<Thread(Thread-1, initial)>
唱歌start
跳舞start
跳舞end
唱歌end
完美谢幕,本次表演结束
16.7. getName()、setName
import threading
import time
def sing(name):
print(f'{name}唱歌start')
time.sleep(2)
print(f'{name}唱歌end')
def dance(name):
print(f'{name}跳舞start')
time.sleep(2)
print(f'{name}跳舞end')
if __name__ == '__main__':
t1 = threading.Thread(target=sing,args=('Niko',))
print(t1)
t2 = threading.Thread(target=dance,args=('Simple',))
#守护进程,必须放在start()前面:主线程执行结束,子线程也会跟着结束
t1.setDaemon(True)
t2.setDaemon(True)
t1.start()
t2.start()
#阻塞主线程join():暂停的作用,等子线程执行结束后,主线程才会继续执行,必须放在start()后面
t1.join()#
t2.join()
print(t1.getName())
print(t2.getName())
t1.setName('线程1')
t2.setName('线程2')
print(t1.getName())
print(t2.getName())
print('完美谢幕,本次表演结束')result:<Thread(Thread-1, initial)>
Niko唱歌start
Simple跳舞start
Niko唱歌end
Simple跳舞end
Thread-1
Thread-2
线程1
线程2
完美谢幕,本次表演结束
十七、进程
17.1. 进程的定义
含义:是操作系统进行资源分配和调度的基本单位,是操作系统结构的基础
- 一个正在运行的程序或者软件就是一个进程
- 进程里面可以创建多个线程,多线程也可以完成多任务
17.2. 进程的状态
- 就绪状态:运行的条件都已满足,正在等待cpu运行
- 执行状态:cpu正在执行其功能
- 等待(阻塞)状态:等某些条件满足,如一个程序sleep了,此时就处于等待状态
17.3. 进程语法结构
- multiprocessing模块提供了Process类代表进程对象
17.3.1. Process参数
target:执行的目标任务名,即子进程要执行的任务
args:以元组的形式传参
kwagrs:以字典的形式传参
17.3.2. 常用的方法
1. start():开启子进程
2. is alive():判断子进程是否还存活着,存活着返回True,死亡返回False
3. join():主进程等待子进程执行结束
17.3.3. 常用的属性
name:当前进程的别名,默认Process-N
pid:当前进程的进程编号
17.3.4. start()、target、name、pid
- 程序默认执行主进程,自己创建的才是子进程
- 父进程id相同,因为他们都是处于同一个py文件下面,这个py文件有一个主进程,所以父进程的id就是py文件的主进程的id
import os
from multiprocessing import Process
def sing():
print(f'sing父进程编号:{os.getppid()}')#os.getppid():获取当前父进程编号
print(f'sing子进程编号:{os.getpid()}')#os.getpid():获取当前进程编号
print('唱歌')
def dance():
print(f'dance父进程编号:{os.getppid()}') # os.getppid():获取当前父进程编号
print(f'dance子进程编号:{os.getpid()}') # os.getpid():获取当前进程编号
print('跳舞')
if __name__ == '__main__':
s1 = Process(target=sing,name='进程1')
d1 = Process(target=dance,name='进程2')
s1.start()
d1.start()
s1.name='进程一'
d1.name='进程二'
print('sing子进程名:',s1.name)
print('dance子进程名:',d1.name)
print('sing子进程编号:',s1.pid)
print('dance子进程编号:',d1.pid)
print('主进程pid:',os.getpid())
print('主进程的父进程pid:',os.getppid())result:sing子进程名: 进程一
dance子进程名: 进程二
sing子进程编号: 8508
dance子进程编号: 4296
主进程pid: 16240
主进程的父进程pid: 12836
sing父进程编号:16240
sing子进程编号:8508
唱歌
dance父进程编号:16240
dance子进程编号:4296
跳舞
- 主进程的父进程就是pycharm软件的进程号,在cmd中输入命令:tasklist,找pycharm看到进程号
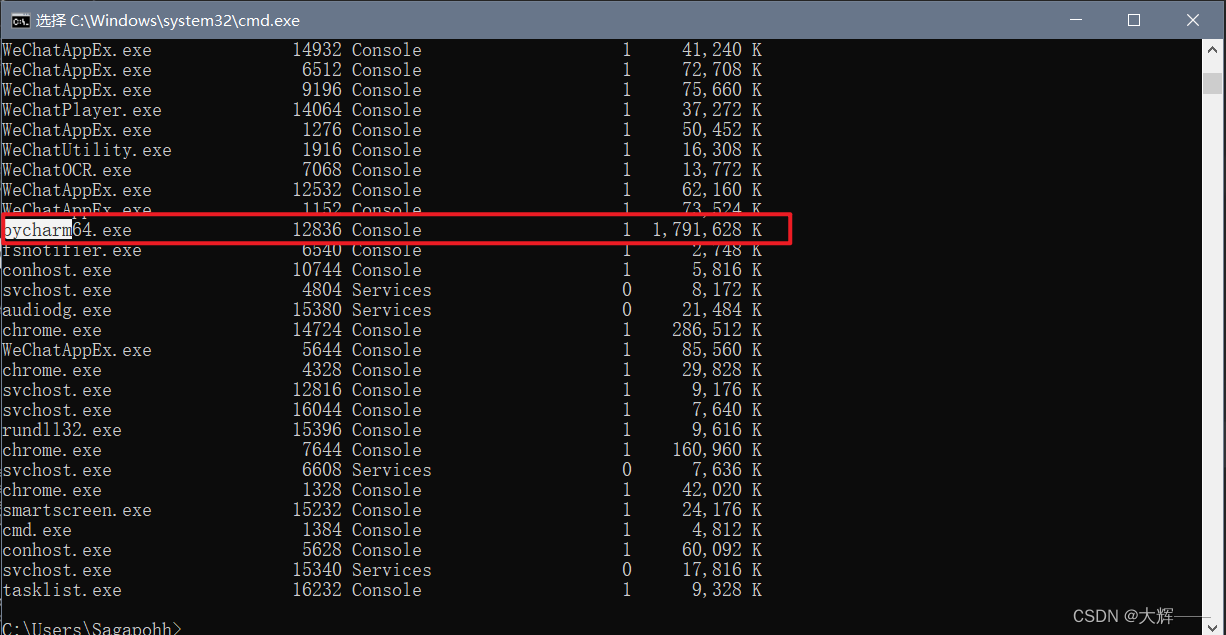
17.3.5. is_alive()、join()、args
- 写在主进程中判断存活状态的时候需要加入join阻塞一下
- 元组的形式传一个参数时需要加逗号
from multiprocessing import Process
def eat(name):
print(f'{name}吃饭')
def sleep(name):
print(f'{name}睡觉')
if __name__ == '__main__':
p1 = Process(target=eat,args=('Niko',))
p2 = Process(target=sleep,args=('Simple',))
p1.start()
p1.join()
p2.start()
p2.join()
print(p1.is_alive())
print(p2.is_alive())result:Niko吃饭
Simple睡觉
False
False
17.4. 进程间不共享全局变量
17.4.1. if __name__ == "__main__"
- 防止别人导入文件的时候执行main里面的方法
- 防止windows系统递归创建子进程
17.4.2. 进程间不共享全局变量
from multiprocessing import Process
li = []
def wdata():
for i in range(5):
li.append(i)
print('写入的数据:',li)
def rdata():
print('读取的数据:',li)
if __name__ == '__main__':
p1 = Process(target=wdata)
p2 = Process(target=rdata)
p1.start()
p1.join()
p2.start()result:写入的数据: [0, 1, 2, 3, 4]
读取的数据: []
17.5. 进程之间的通信
Queue(队列)
- q.put():放入数据
- q.get():取出数据
- q.empty():判断队列是否为空
- q.qsize():返回当前队列包含的消息数量
- q.full():判断队列是否满了
初始化一个队列对象
from queue import Queue
q = Queue(3)#最多可以接收三条消息,没写或者是负值就代表没有上限,直到内存的尽头
q.put('Niko')
q.put('Simple')
print('判断队列是否满了:',q.full())
q.put('monesy')
print('判断队列是否满了:',q.full())
print(q.get())#获取队列的一条消息,然后将其从队列中移除
print(q.get())
print('判断队列是否为空:',q.empty())
print('返回当前队列包含的消息数量:',q.qsize())
print('判断队列是否满了:',q.full())
print(q.get())
print('判断队列是否为空:',q.empty())
print('返回当前队列包含的消息数量:',q.qsize())
result:判断队列是否满了: False
判断队列是否满了: True
Niko
Simple
判断队列是否为空: False
返回当前队列包含的消息数量: 1
判断队列是否满了: False
monesy
判断队列是否为空: True
返回当前队列包含的消息数量: 0
from multiprocessing import Process,Queue
def wdata(q1):
for i in range(5):
q1.put(i)
print(f'{i}已经被放入')
def rdata(q2):
while True:
if q2.empty():
break
else:
print('取出数据:',q2.get())
if __name__ == '__main__':
q = Queue()
p1 = Process(target=wdata,args=(q,))
p2 = Process(target=rdata,args=(q,))
p1.start()
p1.join()
p2.start()result:0已经被放入
1已经被放入
2已经被放入
3已经被放入
4已经被放入
取出数据: 0
取出数据: 1
取出数据: 2
取出数据: 3
取出数据: 4

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









