






一.KNN(K-Nearest Neighbors)算法
基本介绍:K近邻是一种最经典和最简单的有监督学习方法之一。K-近邻算法是最简单的分类器,没有显式的学习过程或训练过程,是懒惰学习(Lazy Learning)。K近邻算法既能够用来解决分类问题,也能够用来解决回归问题。该方法有着非常简单的原理:当对测试样本进行分类时,首先通过扫描训练样本集,找到与该测试样本最相似的个训练样本,根据这个样本的类别进行投票确定测试样本的类别。也可以通过个样本与测试样本的相似程度进行加权投票。
基本要素:
KNN算法包含三个基本要素:K值选择,距离度量,分类决策规则
距离度量:特征空间中两个实例点之间的距离(反应了二者之间的相似程度)
Lp距离:

当 p = 2时为欧氏距离
当 p = 1时为曼哈顿距离
当 p=∞ 为各个坐标距离的最大值(切比雪夫距离)
k值选择:一般而言,从k = 1开始,随着的逐渐增大,K近邻算法的分类效果会逐渐提升;在增大到某个值后,随着的进一步增大,K近邻算法的分类效果会逐渐下降。一般通过交叉验证选取k值
交叉验证:交叉验证是在机器学习建立模型和验证模型参数时常用的办法,一般被用于评估一个机器学习模型的表现,一般将数据集拆分为:训练集+验证集+测试集
验证方法:
1.简单交叉验证
随机地将已给数据分为两部分:训练集和测试集 (例如,70% 训练集,30% 测试集);
然后用训练集在各种条件下 (比如,不同的参数个数) 训练模型,从而得到不同的模型;
在测试集上评价各个模型的测试误差,选出测试误差最小的模型。
2.k折交叉验证
随机地将数据集切分为 k 个互不相交的大小相同的子集;
然后将 k-1 个子集当成训练集训练模型,剩下的 一个子集当测试集测试模型;
对 k 种选择重复进行 (每次挑一个不同的子集做测试集);
这样就训练了 k 个模型,每个模型都在相应的测试集上计算测试误差,得到了 k 个测试误差,对这 k 次的测试误差取平均便得到一个交叉验证误差。这便是交叉验证的过程。
3.留一交叉验证
k折交叉验证的特殊情况,k=N,N 是数据集的样本数量
优点:所有的样本皆用于训练模型,因此最接近原始样本的分布,这样评估所得的结果比较可靠。
缺点:计算成本高
二.逻辑回归(Logistic回归)
定义:逻辑回归也称作logistic回归分析,是一种广义的线性回归分析模型,属于机器学习中的监督学习。其推导过程与计算方式类似于回归的过程,但实际上主要是用来解决二分类问题(也可以解决多分类问题)。通过给定的n组数据(训练集)来训练模型,并在训练结束后对给定的一组或多组数据(测试集)进行分类。
原理:
处理二分类问题:对于输入的每一组数据,都能映射到sigmoid函数上,成为0~1之间的数。并且如果函数值大于0.5,就判定属于1,否则属于0。
sigmoid函数图像:

sigmoid函数形式:
这里可设函数为:
三.朴素贝叶斯
朴素贝叶斯是经典的机器学习算法之一,也是为数不多的基于概率论(贝叶斯决策理论)的分类算法
贝叶斯定理:
先验概率:即基于统计的概率,是基于以往历史经验和分析得到的结果,不需要依赖当前发生的条件。
后验概率:则是从条件概率而来,由因推果,是基于当下发生了事件之后计算的概率,依赖于当前发生的条件。
条件概率:记事件A发生的概率为P(A),事件B发生的概率为P(B),则在B事件发生的前提下,A事件发生的概率即为条件概率,记为P(A|B)。
贝叶斯公式:
对于给定的新样本,判断其属于哪个标记的类别,根据贝叶斯定理,可以得到
属于
类别的概率
:
特征条件假设:假设每个特征之间没有联系,给定训练数据集
朴素贝叶斯算法对条件概率分布作出了独立性的假设,通俗地讲就是说假设各个维度的特征互相独立,在这个假设的前提上,条件概率可以转化为:
则朴素贝叶斯可以转化为:
模型:
- 高斯模型:处理特征是连续型变量的情况。
- 多项式模型:最常见,要求特征是离散数据。
- 伯努利模型:要求特征是离散的,且为布尔类型,即true和false,或者1和0。
四.支持向量机
概念解释:
支持向量:与分离超平面距离最近的两个样本点(一正一负)
间隔边界:两个支持向量所在的平行的两个超平面
分离超平面:平行且位于两个间隔边界中央的超平面
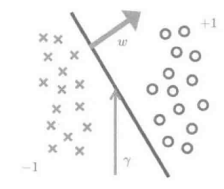
目的:
实现支持向量机分类算法步骤:















 1105
1105











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









