







提示:本文主要讲解分类问题的概念、二分类和多分类、类别不平衡问题。
1.4 分类问题
一、分类问题是什么?
模型想要预测的结果是离散值,如”好瓜“和”坏瓜“,此类学习任务称为”分类“(classification)
二、二分类学习
- 对只涉及两个类别的”二分类“(binary classification)任务,其中一个类别为正类(positive class),另一个类为反类(negative class)。涉及多个类别时,则称为”多分类“(multi-class classification)任务。
- 二分类问题的常见模型:对数几率回归、决策树、朴素贝叶斯等。
三、多分类学习的基本思路和策略
有些二分类学习方法可以直接推广到多分类,但更多情况下是基于一些策略,利用二分类学习器来解决多分类问题。
不失一般性,考虑N个类别C1、C2、…、CN,多分类学习的基本思路是”拆解法“:将多分类任务拆为若干个二分类任务求解,即先对问题进行拆分,然后为拆出的每个二分类任务训练一个分类器,在测试时,先对这些分类器的预测结果进行集成以获得最终的多分类结果。
常见的拆分策略有三种:
- 一对一(OvO,One vs. One)
- 一对其余(OvR,One vs. Rest)
- 多对多(MvM,Many vs. Many)
给定数据集D={(x1,y1),(x2,y2),…(xm,ym)},yi属于{C1,C2,…,CN}:
3.1 一对一(OvO)
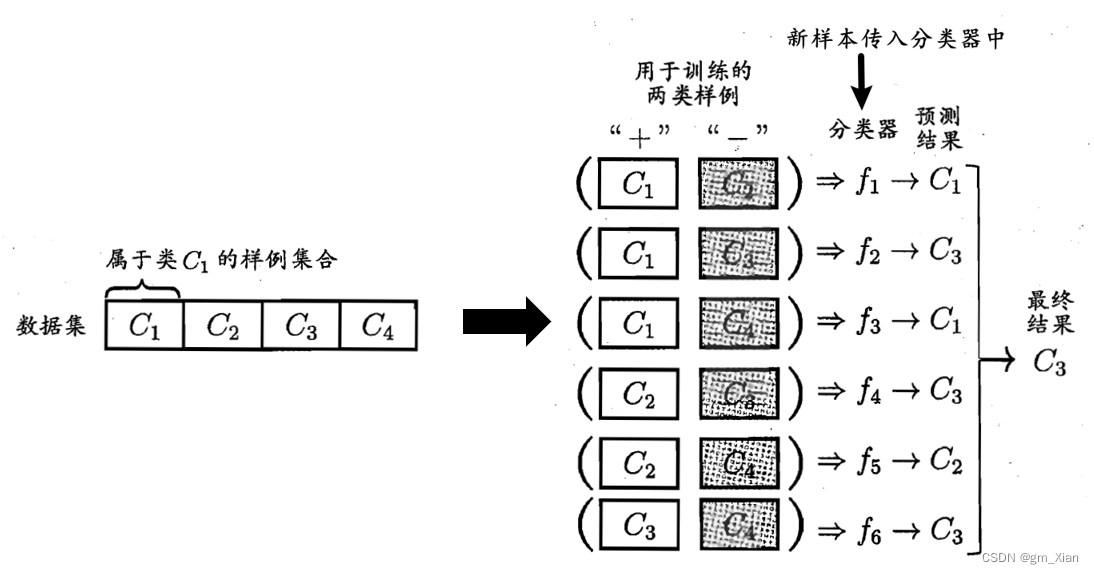
- 在训练阶段:OvO将这N个类别两两配对,从而产生N(N-1)/2个二分类任务,例如OvO为Ci、Cj训练一个分类器,该分类器将Ci类样例作为正例,Cj类样例作为反例。
- 在测试阶段:新样本将同时提交给所有分类器,于是得到N(N-1)/2个预测结果,最终可通过投票产生。
- 示意图如下:
3.2 一对其余(OvR)
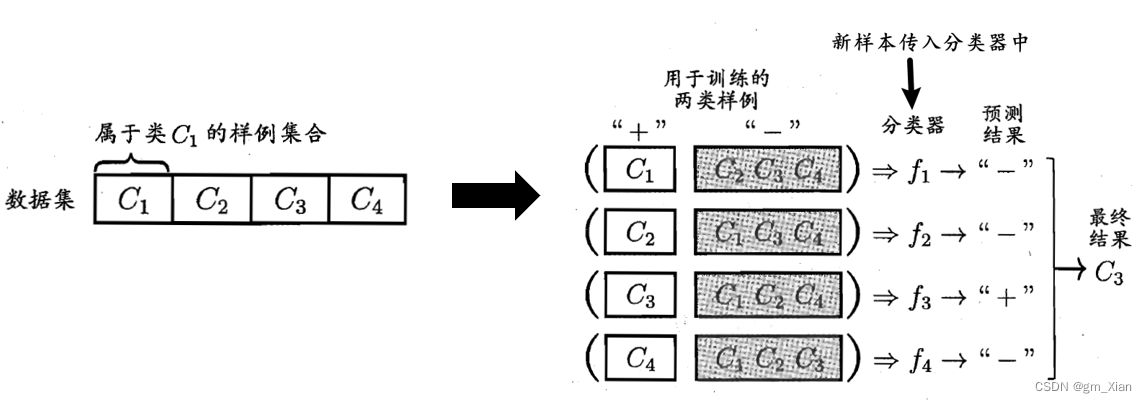
- 在训练阶段:每次将一个类的样例作为正例、所有其他类的样例作为反例来训练N 个分类器。
- 在测试阶段:若仅有一个分类器预测为正类,则对应的类别标记作为最终分类结果。若有多个分类器预测为正类,则通常考虑各分类器的预测置信度,选择置信度最大的类别标记作为分类结果。
- 示意图如下:
3.3 多对多(MvM)
- MvM是绛次将若干个类作为正类,若干个其他类作为反类.显然,OvO和OvR是MvM的特例.
- MvM的正、反类构造必须有特殊的设计,不能随意选取。下面介绍一种常用的MvM技术”纠错输出码“"(Error Correcting Output Codes,简称 ECOC).
3.3.1 纠错输出码(ECOC)
ECOC是将编码的思想引入类别拆分,并尽可能在解码过程中具有容错性.ECOC工作过程主要分为两步:
- 编码:对N个类别做M次划分,每次划分将一部分类别划为正类,一部分划为反类,从而形成一个二分类训练集;这样一共产生M个训练集,可训练出M个分类器。
- 解码:M个分类器分别对测试样本进行预测,这些预测标记组成一个编码。将这个预测编码与每个类别各自的编码进行比较,返回其中距离最小的类别作为最终预测结果。
类别划分通过编码矩阵指定。编码矩阵有很多种形式,如二元码(正类和反类)、三元码(正类、反类、停用类(即不使用该类))。
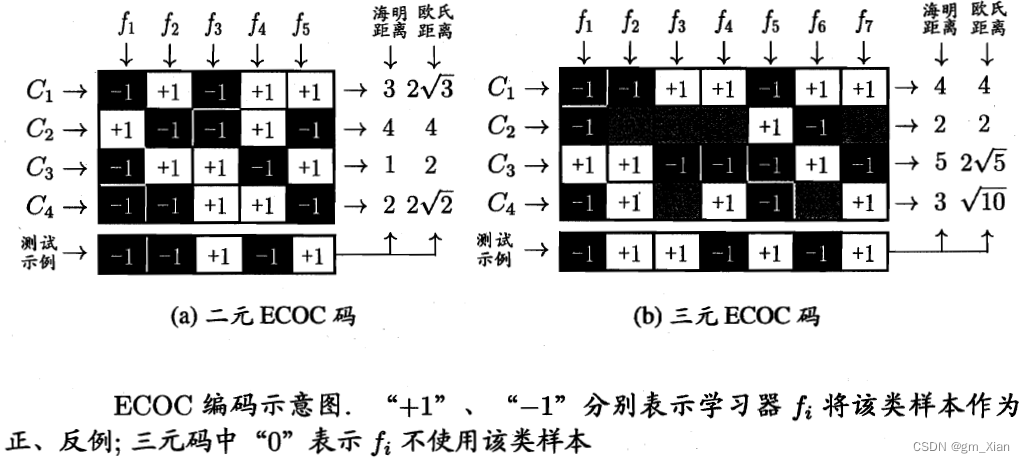
- 在图(a)中,分类器f1将C2类作为正例(+1),将C1、C3、C4作为反例(-1),预测新样本为反例(-1);其余分类器也对新样本进行预测。
- 在图(b)中,分类器f2将C3、C4类作为正例(+1),将C1作为反例(-1),将C2作为停用类(0)。
- 在解码阶段,各分类器的预测结果联合起来形成了测试示例的编码,该编码与各类所对应的编码进行比较,将距离最小的编码所对应的类别作为预测结果.例如在图3 .5 (a)中,若基于欧氏距离,预测结果将是C3.
纠错输出码的纠错能力:
- 同一个学习任务,ECOC编码越长,纠错能力越强。然而,编码越长,意味着所需训练的分类器越多,计算、存储开销都会增大;另一方面,对有限类别数,可能的组合数目是有限的,码长超过一定范围后就失去了意义。
- 对同等长度的编码,理论上来说,任意两个类别之间的编码距离越远,则纠错能力越强。因此,在码长较小时可根据这个原则计算出理论最优编码.然而,码长稍大一些就难以有效地确定最优编码,事实上这是NP难问题。
四、类别不平衡问题
4.1 类别不平衡比
定义多数类集合为m-,少数类集合为m+,则不平衡比:IR=m-/m+
IR越大,数据集越不平衡。
主要方法有:过采样、欠采样、阈值移动。
4.2 分类器的决策策略
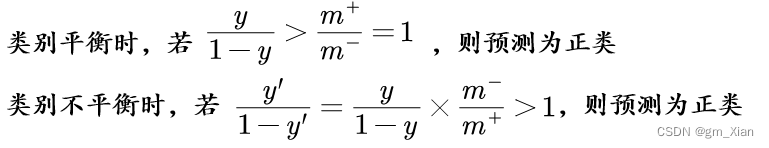
4.3 欠采样
对反例样本进行欠采样:
- 原理:去除一些反例(多数类的样本),使得正反例数目接近,然后再进行学习。
- 注意:欠采样法若随机丢弃反例,可能丢失一些重要信息。
- 代表算法1:EasyEnsemble(利用集成学习机制,将反例划分为若干个集合供不同学习器使用)
4.4 过采样
对正例样本进行过采样:
- 原理:增加一些正例(少数类的样本),使得正反例数目接近,然后再进行学习。
- 注意:过采样法不能简单地对初始正例样本进行重复采样,否则会招致严重的过拟合。
- 代表算法1:SMOTE算法(通过对训练集里的正例进行插值来产生额外的正例)
from imblearn.over_sampling import SMOTE
train_data_x,train_data_y = SMOTE().fit_resample(train_data_x,train_data_y)
4.5 阈值移动
- 原理:直接基于原始训练集进行学习,但在用训练好的分类器进行预测时,将上述4.2部分的第2个公式嵌入到其决策过程中。
[1]周志华.机器学习 [M].清华大学出版社, 2016.















 7178
7178











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









