







一、混淆矩阵
1、混淆矩阵的概念
混淆矩阵(confusion matrix)是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。具体评价指标有总体精度、制图精度、用户精度等,这些精度指标从不同的侧面反映了图像分类的精度。在人工智能中,混淆矩阵是可视化工具,特别用于监督学习,在无监督学习一般叫做匹配矩阵。在图像精度评价中,主要用于比较分类结果和实际测得值,可以把分类结果的精度显示在一个混淆矩阵里面。
我们以分类模型中最简单的二分类为例,对于这种问题,我们的模型最终需要判断样本的结果是0还是1,或者说是positive还是negative。我们通过样本的采集,能够直接知道真实情况下,哪些数据结果是positive,哪些结果是negative。同时,我们通过用样本数据跑出分类型模型的结果,也能知道模型认为这些数据哪些是positive,哪些是negative。
这样就可以分成四个情况:真正例(True Positives, TP)、真负例(True Negatives, TN)、假正例(False Positives, FP)和假负例(False Negatives, FN)。
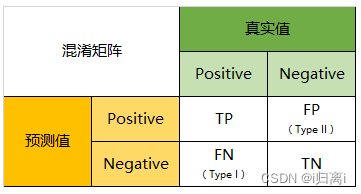
2、混淆矩阵的评价指标
预测分类模型时,我们希望预测结果越准越好,即希望TP与TN的数量大,而FP与FN的数量小。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









