






一、KNN算法
(一)基本概念
KNN(K-NearestNeighbor)即K近邻算法,是数据挖掘分类技术中最简单的方法之一。所谓K近邻,就是K个最近的邻居的意思,说的是每个样本都可以用它最接近的K个邻近值来代表。
(二)KNN算法原理
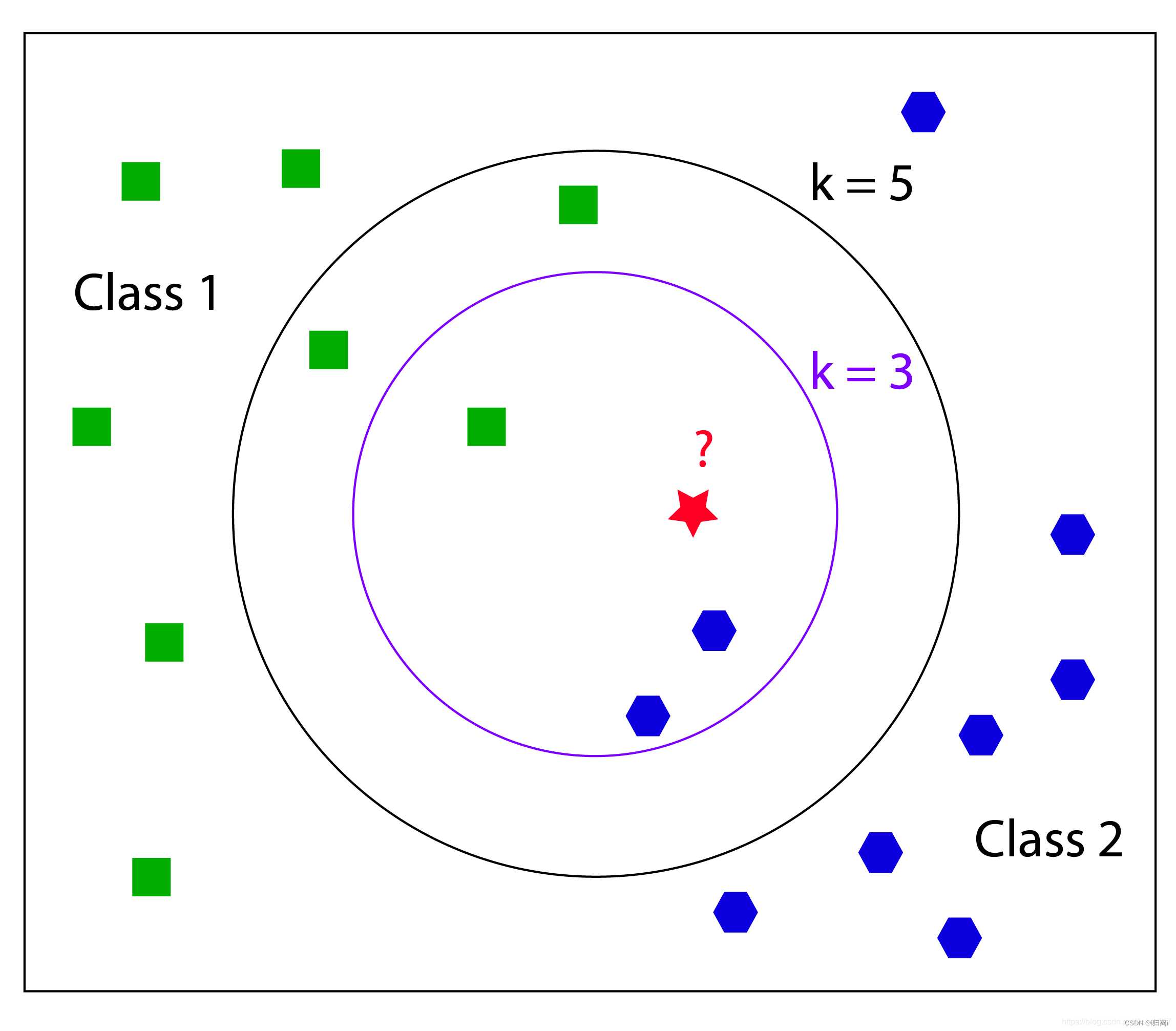
如下图所示:
当k设置为3,测试数据最相近的3个数据中有2个正六边形,1个正方形,则预测结果为正六边形;
当k设置为5,测试数据最相近的5个数据中是3个正方形,2个正六边形,此时预测结果为正方形。
(三)距离计算
闵可夫斯基距离 (Minkowski Distance),也被称为闵氏距离。它不仅仅是一种距离,而是将多个距离公式(曼哈顿距离、欧式距离、切比雪夫距离)总结成为的一个公式。
首先假设两个 n 维变量 A (x11, x12, . . . ,x1n) 与 B ( x21,x22, . . . ,x2n) 。
对于这两个 n 维变量,则有闵氏距离公式为: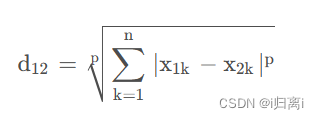
当p=1时,闵氏距离为曼哈顿距离
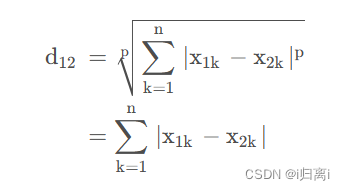
当p=2 时,闵氏距离为欧式距离

当p=∞时,闵氏距离为切比雪夫距离
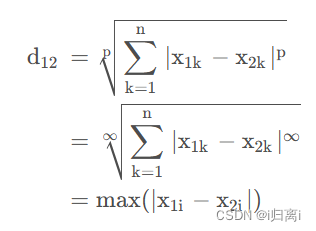
(四)K值选择
当k值较小时,是在较小的范围内进行预测,由于与输入的实例相近,算法的近似误差(训练集上的误差)会比较小,但是,如果近邻点是噪声点的话,预测就会出错,导致估计误差(测试集上的误差),即k值过小容易导致KNN算法的过拟合。
而当k值较大时,距离较远的训练样本也会对预测结果产生影响。这时,不会因为个别噪声点对最终预测结果产生影响。但是,由于与输入实例相差比较远,会使得预测结果产生较大偏差,此时模型容易发生欠拟合。
(五)实现方法
1.导入数据
def fileMatrix(filename):
file = open(filename) #打开文件
arrayOLines = file.readlines() #读取文件所有内容
numberOfLines = len(arrayOLines) #得到文件行数
returnMat = zeros((numberOfLines, 3)) #返回给定形状和类型的新数组,用0填充
classLabelVector = []#返回的分类标签向量
index = 0 #行的索引值
for line in arrayOLines:
line = line.strip()#用于移除字符串头尾指定的字符,默认删除空白符(包括'\n','\t','\r',' ')
listFromLine = line.split('\t')#通过指定分隔符对字符串进行切片,返回分割后的字符串列表
returnMat[index,:] = listFromLine[0:3]#将数据前三列提取出来,存放到returnMat的numpy矩阵中
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat,classLabelVector
fileMatrix('KNNdata1.txt') 
2.分析数据:使用Matplotlib创建散点图
def showdatas(datingDataMat, datingLabels):
#设置汉字格式
# sans-serif就是无衬线字体,是一种通用字体族。
mpl.rcParams['font.sans-serif'] = ['Songti SC'] # 用来正常显示中文标签
mpl.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
#将fig画布分隔成2行2列,不共享x轴和y轴,fig画布的大小为(13,8)
#当nrow=2,nclos=2时,代表fig画布被分为四个区域,axs[0][0]表示第一行第一个区域
fig, axs = plt.subplots(nrows=2, ncols=2,sharex=False, sharey=False, figsize=(13,9))
LabelsColors = []
for i in datingLabels:
if i == 0:
LabelsColors.append('green')
if i == 1:
LabelsColors.append('red')
if i == 2:
LabelsColors.append('blue')
#画出散点图,以datingDataMat矩阵的第一(家庭人均年收入)、第二列(使用手机价格)数据画散点数据,散点大小为15,透明度为0.5
axs[0][0].scatter(x=datingDataMat[:,0], y=datingDataMat[:,1], color=LabelsColors,s=15, alpha=.5)
#设置标题,x轴label,y轴label
axs0_title_text = axs[0][0].set_title('家庭人均年收入与使用手机价格')
axs0_xlabel_text = axs[0][0].set_xlabel('家庭人均年收入')
axs0_ylabel_text = axs[0][0].set_ylabel('使用手机价格')
plt.setp(axs0_title_text, size=12, weight='bold', color='red')
plt.setp(axs0_xlabel_text, size=10, weight='bold', color='black')
plt.setp(axs0_ylabel_text, size=10, weight='bold', color='black')
#画出散点图,以datingDataMat矩阵的第一(家庭人均年收入)、第三列(每月外出吃饭次数)数据画散点数据,散点大小为15,透明度为0.5
axs[0][1].scatter(x=datingDataMat[:,0], y=datingDataMat[:,2], color=LabelsColors,s=15, alpha=.5)
#设置标题,x轴label,y轴label
axs1_title_text = axs[0][1].set_title('家庭人均年收入与每月外出吃饭次数',)
axs1_xlabel_text = axs[0][1].set_xlabel('家庭人均年收入')
axs1_ylabel_text = axs[0][1].set_ylabel('每月外出吃饭次数')
plt.setp(axs1_title_text, size=12, weight='bold', color='red')
plt.setp(axs1_xlabel_text, size=10, weight='bold', color='black')
plt.setp(axs1_ylabel_text, size=10, weight='bold', color='black')
#画出散点图,以datingDataMat矩阵的第二(使用手机价格)、第三列(每月外出吃饭次数)数据画散点数据,散点大小为15,透明度为0.5
axs[1][0].scatter(x=datingDataMat[:,1], y=datingDataMat[:,2], color=LabelsColors,s=15, alpha=.5)
#设置标题,x轴label,y轴label
axs2_title_text = axs[1][0].set_title('使用手机价格与每月外出吃饭次数')
axs2_xlabel_text = axs[1][0].set_xlabel('使用手机价格')
axs2_ylabel_text = axs[1][0].set_ylabel('每月外出吃饭次数')
plt.setp(axs2_title_text, size=12, weight='bold', color='red')
plt.setp(axs2_xlabel_text, size=10, weight='bold', color='black')
plt.setp(axs2_ylabel_text, size=10, weight='bold', color='black')
#设置图例
impoverished = mlines.Line2D([], [], color='green', marker='.', markersize=6, label='贫困')
ordinary = mlines.Line2D([], [], color='red', marker='.',markersize=6, label='普通')
affluent = mlines.Line2D([], [], color='blue', marker='.',markersize=6, label='富裕')
#添加图例
axs[0][0].legend(handles=[impoverished,ordinary,affluent])
axs[0][1].legend(handles=[impoverished,ordinary,affluent])
axs[1][0].legend(handles=[impoverished,ordinary,affluent])
#显示图片
plt.show()
datingDataMat, datingLabels = fileMatrix('KNNdata1.txt')
showdatas(datingDataMat,datingLabels)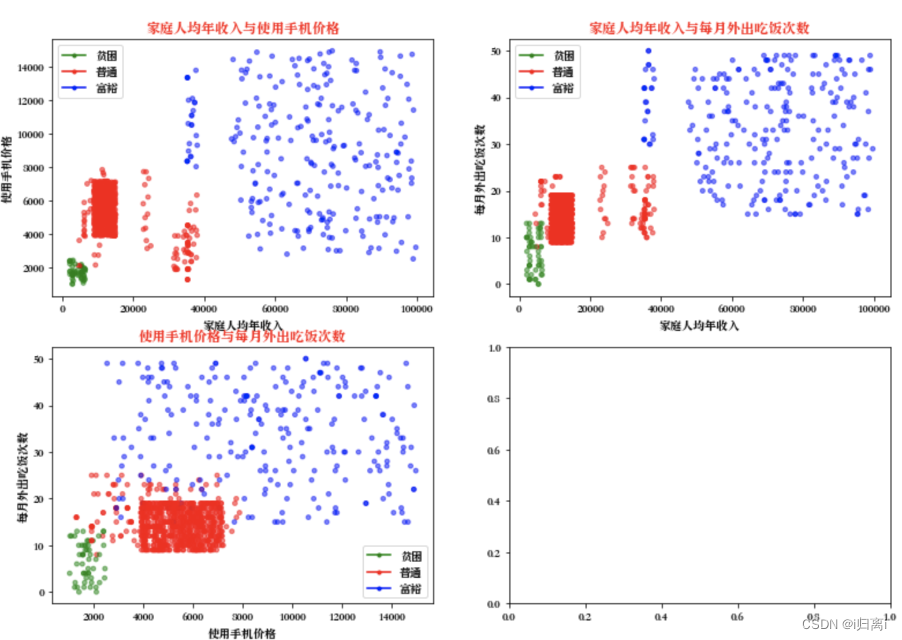
3.处理数据
def autoNorm(dataSet):
#获得每列数据的最小值和最大值
minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals #最大值和最小值范围
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0] #返回dataset的行数
normDataSet = dataSet - tile(minVals, (m, 1)) #原始值减去最小值
normDataSet = normDataSet/tile(ranges, (m, 1)) #除以最大和最小值的差,得到归一化数据
return normDataSet, ranges, minVals #返回归一化数据结果,数据范围,最小值
datingDatMat, datingLabels = fileMatrix('KNNdata1.txt')
normData, ranges, minVals = autoNorm(datingDatMat)
print('normData')
print(normData)
print('ranges')
print(ranges)
print('minVals')
print(minVals)
4. 分类器
def datingClassTest():
hoRatio = 0.2 #20%的测试数据
datingDatMat, datingLabels = fileMatrix('KNNdata1.txt') #从文件读数据
normMat, ranges, minVals = autoNorm(datingDatMat) #数据的归一化
m = normMat.shape[0]
numTestVecs = int(m*hoRatio) #测试数据数量
errorCount = 0.0 #错误数量统计
for i in range(numTestVecs):
classifierResult = classify(normMat[i, :], normMat[numTestVecs:m, :], datingLabels[numTestVecs:m], 1)
print("分类器返回的结果是:%d,真实结果是:%d"%(classifierResult, datingLabels[i]))
if(classifierResult != datingLabels[i]):
errorCount += 1.0
print('分类器处理约会数据集的错误率是:%f'%(errorCount/float(numTestVecs)))这里调用了分类器函数classify
def classify(inX, dataSet, labels, k):
#dataSetSize是训练样本集数量
dataSetSize = dataSet.shape[0]
#距离计算——欧式距离公式
#tile函数,把inX变成能与dataSet相减的二维数组
diffMat = tile(inX, (dataSetSize, 1)) - dataSet
sqDiffMat = diffMat ** 2
#axis=1是列相加求和,即得到(x1-x2)^2+(y1-y2)^2的值
sqDistances = sqDiffMat.sum(axis = 1)
distances = sqDistances ** 0.5
#按照距离递增次序排序,返回下标
sortedDistIndicies = distances.argsort()
#选择距离最小的k个点
classCount = {}
for i in range(k):
voteILabel = labels[sortedDistIndicies[i]]
classCount[voteILabel] = classCount.get(voteILabel,0) + 1
#按照字典里的关键字的值排序,reverse=True降序排序
sortedClassCount = sorted(classCount.items(), key = operator.itemgetter(1), reverse = True)
#返回类别最多的标签
return sortedClassCount[0][0] 
5.运行
def classifyPerson():
resultList = ['贫困', '普通', '富裕']
precentTats = float(input('家庭人均年收入:')) #用户输入三个特征
ffMiles = float(input('使用手机价格:'))
iceCream = float(input('每月外出吃饭次数:'))
datingDatMat, datingLabels = fileMatrix('KNNdata.txt') #文件数据读入
normMat, ranges, minVals = autoNorm(datingDatMat)
inArr = array([precentTats, ffMiles, iceCream]) #生成测试集
norminArr = (inArr-minVals)/ranges #数据归一化
classifierResult = classify(norminArr, normMat, datingLabels, 3) #分类器分类
print('这位学生的家庭情况可能是%s'%(resultList[classifierResult]))
![]()
(六)总结
优点:KNN算法的原理较为简单,易于理解和实现。无需进行显式的训练过程,可以直接进行预测。可以处理多类别分类问题,并且对于类别之间的边界没有假设。对于异常值的影响较小,因为它考虑的是最近邻的邻居。
缺点:KNN算法需要计算测试样本与所有训练样本之间的距离,因此在处理大规模数据时会变得非常耗时。很大程度上依赖于选择合适的K值,而确定K值没有固定的规则可循。对特征空间中的度量尺度敏感,不同的度量尺度可能导致不同的结果。















 1011
1011











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









