






机器学习实验七——SVM
1.SVM
支持向量机(support vector machines)是一种二分类模型,它将实例的特征向量映射为空间中的一些点,SVM 的目的就是想要画出一条线,以 “最好地” 区分这两类点,以至如果以后有了新的点,这条线也能做出很好的分类。
SVM 适合中小型数据样本、非线性、高维的分类问题。
2.SVM的原理
SVM的基本原理是通过在特征空间中找到一个超平面,将不同类别的样本分开,并且使得离超平面最近的样本点到超平面的距离最大化。
以一个二维平面为例,判定边界是一个超平面(在本图中其实是一条线),它是由支持向量所确定的(支持向量是离判定边界最近的样本点,它们决定了判定边界的位置)。间隔的正中就是判定边界,间隔距离体现了两类数据的差异大小。 若严格地规定所有的样本点都不在“缓冲区”,都正确的在两边,称为硬间隔分类; 但是在一般情况下,不易实现。
这里有两个问题:一,这只对线性可分的数据起作用。二,可能会有异常值的干扰。
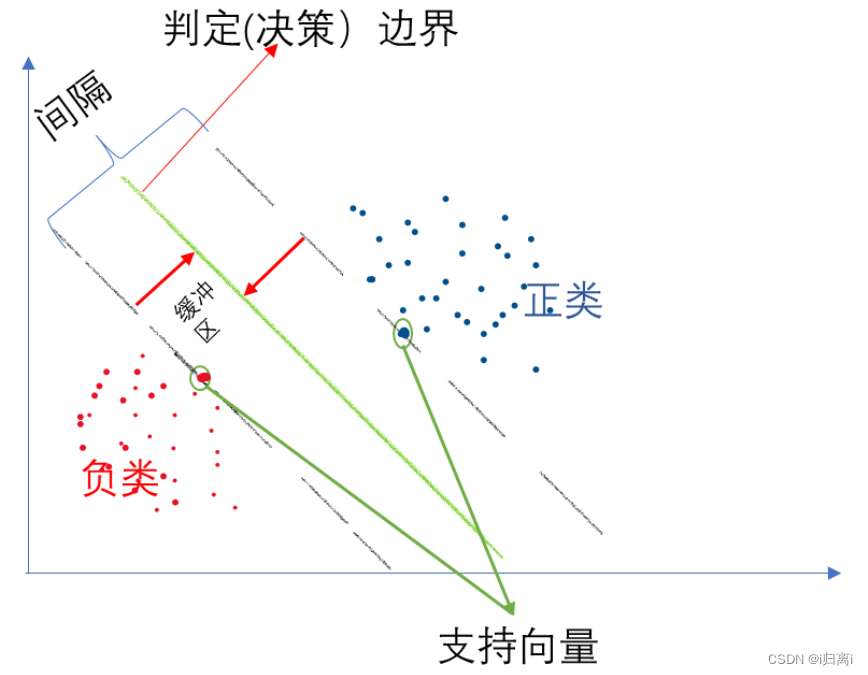
为了避免上述问题,可使用软间隔分类:
在保持“缓冲区”尽可能大和避免间隔违规之间找到一个良好的平衡,在sklearn中的SVM类,可以使用超参数 C(惩罚系数),控制了模型的复杂度和容错能力。较小的C值会导致容错能力较高(即更宽的缓冲区),可能会产生更多的错误分类(即间隔违规);较大的C值会导致容错能力较低,可能会产生更少的错误分类。

3.最大间隔
对于任意一个超平面,其两侧数据点都距离它有一个最小距离(垂直距离),这两个最小距离的和就是间隔。间隔越大越接近我们的目标。
超平面方程为 ,如图,最大间隔可转化为求
最大。

4.核函数
首先,为什么要引入核函数呢? 因为在SVM中,有时候很难找出一条线或一个超平面来分割数据集,这时候我们就需要升维,把无法线性分割的样本映射到高纬度空间,在高维空间实现分割。 核函数是特征转换函数,它可以将数据映射到高维特征空间中,从而更好地处理非线性关系。
选择核函数这一步是非常重要,它决定了模型能够学习的函数空间。常见的核函数包括:线性核函数,多项式核函数,高斯核函数,sigmoid核函数
假设特征数为N,训练数据集的样本个数为W,可按如下规则选择算法: 若N相对W较大,使用逻辑回归或线性核函数的SVM算法。 若N较小,W中等大小(W为N的十倍左右),可使用高斯核函数的SVM算法。 若N较小,W较大(W为N的五十倍以上),可以使用多项式核函数、高斯核函数的SVM算法
5.代码实现
# 导入相关的包
import numpy as np
import pylab as pl # 绘图功能
from sklearn import svm
# 创建 40 个点
np.random.seed(0) # 让每次运行程序生成的随机样本点不变
# 生成训练实例并保证是线性可分的
# np._r表示将矩阵在行方向上进行相连
# random.randn(a,b)表示生成 a 行 b 列的矩阵,且随机数服从标准正态分布
# array(20,2) - [2,2] 相当于给每一行的两个数都减去 2
X = np.r_[np.random.randn(20, 2) - [2, 2], np.random.randn(20, 2) + [2, 2]]
# 两个类别 每类有 20 个点,Y 为 40 行 1 列的列向量
Y = [0] * 20 + [1] * 20
# 建立 svm 模型
clf = svm.SVC(kernel='linear')
clf.fit(X, Y)
# 获得划分超平面
# 划分超平面原方程:w0x0 + w1x1 + b = 0
# 将其转化为点斜式方程,并把 x0 看作 x,x1 看作 y,b 看作 w2
# 点斜式:y = -(w0/w1)x - (w2/w1)
w = clf.coef_[0] # w 是一个二维数据,coef 就是 w = [w0,w1]
a = -w[0] / w[1] # 斜率
xx = np.linspace(-5, 5) # 从 -5 到 5 产生一些连续的值(随机的)
# .intercept[0] 获得 bias,即 b 的值,b / w[1] 是截距
yy = a * xx - (clf.intercept_[0]) / w[1] # 带入 x 的值,获得直线方程
# 画出和划分超平面平行且经过支持向量的两条线(斜率相同,截距不同)
b = clf.support_vectors_[0] # 取出第一个支持向量点
yy_down = a * xx + (b[1] - a * b[0])
b = clf.support_vectors_[-1] # 取出最后一个支持向量点
yy_up = a * xx + (b[1] - a * b[0])
# 查看相关的参数值
print("w: ", w)
print("a: ", a)
print("support_vectors_: ", clf.support_vectors_)
print("clf.coef_: ", clf.coef_)
# 在 scikit-learin 中,coef_ 保存了线性模型中划分超平面的参数向量。形式为(n_classes, n_features)。若 n_classes > 1,则为多分类问题,(1,n_features) 为二分类问题。
# 绘制划分超平面,边际平面和样本点
pl.plot(xx, yy, 'k-')
pl.plot(xx, yy_down, 'k--')
pl.plot(xx, yy_up, 'k--')
# 圈出支持向量
pl.scatter(clf.support_vectors_[:, 0], clf.support_vectors_[:, 1],
s=80, facecolors='none')
pl.scatter(X[:, 0], X[:, 1], c=Y, cmap=pl.cm.Paired)
pl.axis('tight')
pl.show()
输出结果:
Automatically created module for IPython interactive environment
w: [0.90230696 0.64821811]
a: -1.391980476255765
support_vectors_: [[-1.02126202 0.2408932 ]
[-0.46722079 -0.53064123]
[ 0.95144703 0.57998206]]
clf.coef_: [[0.90230696 0.64821811]]















 3696
3696











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









