






logistic回归
前面几次实验学习了几种解决分类问题的算法:一、k-近邻算法,使用距离计算来实现分类;二、决策树,通过构建直观易懂的树来实现分类;三、朴素贝叶斯,使用概率论构建分类器。
此次实验内容是Logistic回归,其也是一种很常见的用来解决二元分类问题的回归方法,它主要是通过寻找最优参数来正确地分类原始数据。
一、线性回归
逻辑回归和线性回归同属于广义线性模型,逻辑回归就是用线性回归模型的预测值去拟合真实标签的的对数概率(此概率是指事件发生的概率与不发生的概率之比)。
逻辑回归和线性回归本质上都是得到一条直线,不同的是,线性回归的直线是尽可能去拟合输入变量X 的分布,使得训练集中所有样本点到直线的距离最短;而逻辑回归的直线是尽可能去拟合决策边界,使得训练集样本中的样本点尽可能分离开。
回归方程: (y是标签,x是特征)
两者的区别:逻辑回归是分类模型,线性回归是回归模型
二、sigmoid函数
sigmoid函数是一种跃迁函数。在二分类的情况下,函数能输出0或1。拥有这类性质的函数称为海维赛德阶跃函数,又称之为单位阶跃函数。
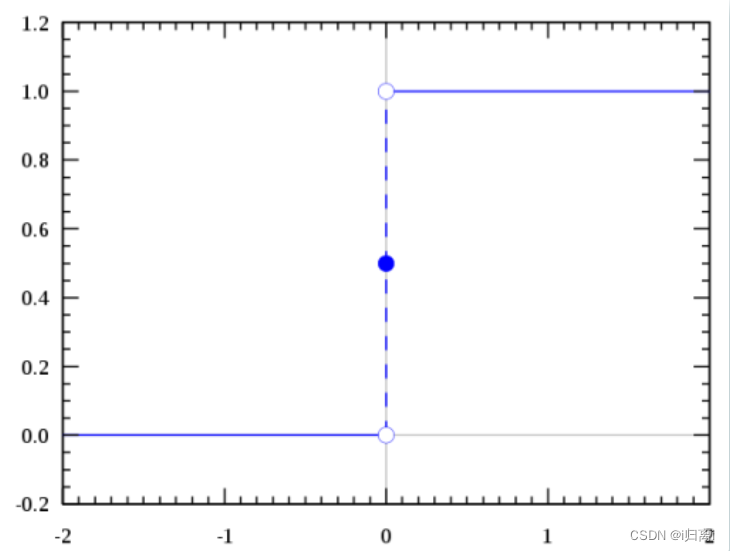
sigmoid函数公式:
当x为0时,Sigmoid函数值为0.5。随着x的增 大,对应的函数值将逼近于1;而随着x的减小,函数值逼近于0。
将线性模型和Sigmoid函数结合,我们可以得到逻辑回归的公式:
三、优化算法
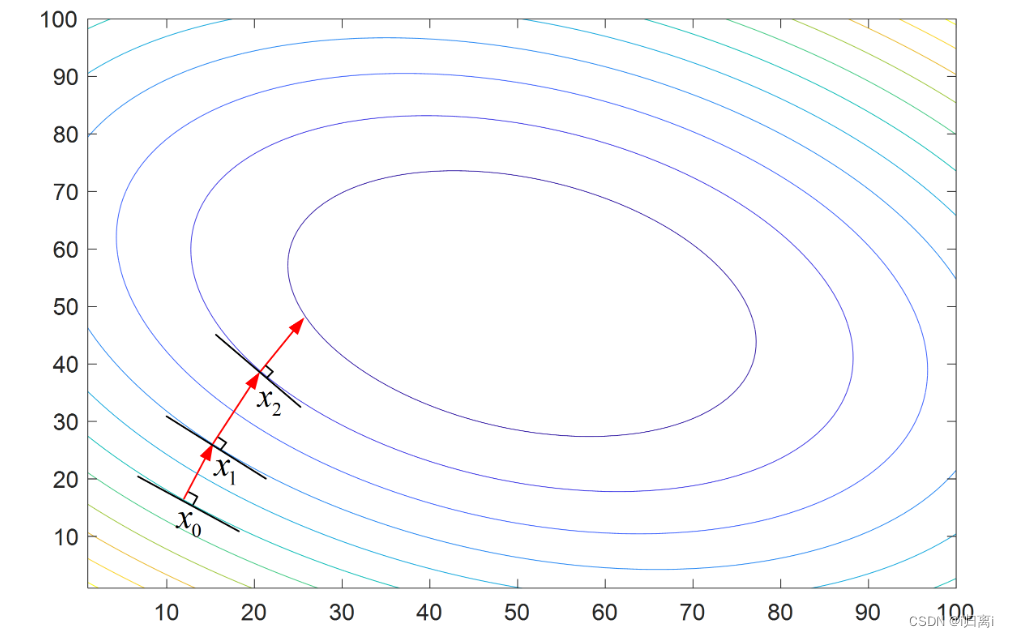
梯度上升法。要找到某个函数的最大值,最好的方法是沿着该函数的梯度方向探寻,探寻到每个点都会重新计算移动方向,只到满足条件。
四、 logistic回归实现
//读取训练数据集,将数据集分为特征矩阵dataMat和标签矩阵labelMat
def loadDataSet(dataFileName):
dataMat = []
labelMat = []
fr = open(dataFileName)
for line in fr:
lineArr = line.strip().split()
dataMat.append([1.0, float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat, labelMat
//计算sigmoid函数的值,激活函数
def sigmoid(x):
return 1.0 / (1+math.exp(-x))
//梯度上升法,优化权重向量 θ,接收数据矩阵、标签矩阵和学习率alpha作为输入参数
def gradientAscent(dataMat, labelMat, alpha):
m = len(dataMat) #训练集个数
n = len(dataMat[0]) #数据特征纬度
theta = [0] * n
iter = 1000
while(iter):
for i in range(m):
hypothesis = sigmoid(computeDotProduct(dataMat[i], theta))
error = labelMat[i] - hypothesis
gradient = computeTimesVect(dataMat[i], error)
theta = computeVectPlus(theta, computeTimesVect(gradient, alpha))
iter -= 1
return theta
//牛顿法,优化权重向量 θ,接收数据矩阵、标签矩阵和迭代次数iterNum作为输入参数
def newtonMethod(dataMat, labelMat, iterNum=10):
m = len(dataMat) #训练集个数
n = len(dataMat[0]) #数据特征纬度
theta = [0.0] * n
while(iterNum):
gradientSum = [0.0] * n
hessianMatSum = [[0.0] * n]*n
for i in range(m):
try:
hypothesis = sigmoid(computeDotProduct(dataMat[i], theta))
except:
continue
error = labelMat[i] - hypothesis
gradient = computeTimesVect(dataMat[i], error/m)
gradientSum = computeVectPlus(gradientSum, gradient)
hessian = computeHessianMatrix(dataMat[i], hypothesis/m)
for j in range(n):
hessianMatSum[j] = computeVectPlus(hessianMatSum[j], hessian[j])
#计算hessian矩阵的逆矩阵有可能异常,如果捕获异常则忽略此轮迭代
try:
hessianMatInv = mat(hessianMatSum).I.tolist()
except:
continue
for k in range(n):
theta[k] -= computeDotProduct(hessianMatInv[k], gradientSum)
iterNum -= 1
return thet
//计算 Hessian 矩阵,用于牛顿法优化
def computeHessianMatrix(data, hypothesis):
hessianMatrix = []
n = len(data)
for i in range(n):
row = []
for j in range(n):
row.append(-data[i]*data[j]*(1-hypothesis)*hypothesis)
hessianMatrix.append(row)
return hessianMatrix
//计算两个向量的点积
def computeDotProduct(a, b):
if len(a) != len(b):
return False
n = len(a)
dotProduct = 0
for i in range(n):
dotProduct += a[i] * b[i]
return dotProduct
//计算两个向量的和
def computeVectPlus(a, b):
if len(a) != len(b):
return False
n = len(a)
sum = []
for i in range(n):
sum.append(a[i]+b[i])
return sum
//计算某个向量的n倍
def computeTimesVect(vect, n):
nTimesVect = []
for i in range(len(vect)):
nTimesVect.append(n * vect[i])
return nTimesVect
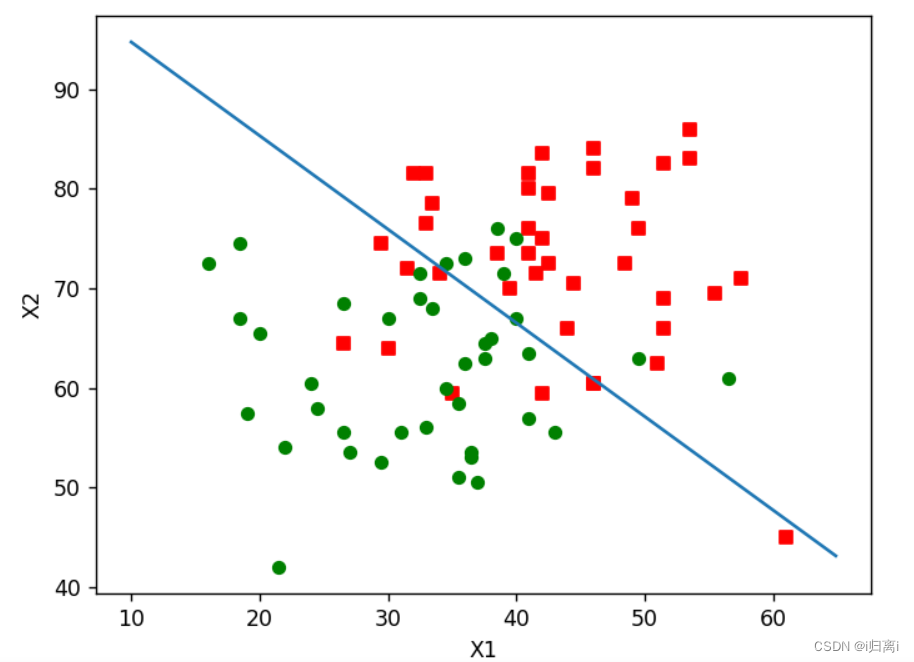
//绘制最优拟合直线,展示分类结果
def plotBestFit(dataMat, labelMat, weights):
import matplotlib.pyplot as plt
dataArr = array(dataMat)
n = shape(dataArr)[0]
xcord1 = []; ycord1 = []
xcord2 = []; ycord2 = []
for i in range(n):
if int(labelMat[i])== 1:
xcord1.append(dataArr[i,1]); ycord1.append(dataArr[i,2])
else:
xcord2.append(dataArr[i,1]); ycord2.append(dataArr[i,2])
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(xcord1, ycord1, s=30, c='red', marker='s')
ax.scatter(xcord2, ycord2, s=30, c='green')
x = arange(10.0, 65.0, 0.1)
y = (-weights[0]-weights[1]*x)/weights[2]
ax.plot(x, y)
plt.xlabel('X1'); plt.ylabel('X2');
plt.show()
//对输入向量进行分类,判断其属于正类还是负类
def classifyVector(inX, weights):
prob = sigmoid(sum(inX*weights))
if prob > 0.5: return 1.0
else: return 0.0
运行结果:
五、实验总结
Logistic回归的优点包括:
- 模型相对简单,易于理解和实现。
- 可解释性强,从特征的权重可以看到不同的特征对最后结果的影响。
- 训练速度较快。
Logistic回归的缺点包括:
- 容易发生欠拟合现象,分类的精度不高,不适合处理非线性关系的数据。
- 对数据和参数的敏感性较高,需要仔细调整和优化模型参数,在大规模数据集上训练时间可能会较长。
- 对于某些特殊的数据分布和特征类型,可能会出现一些问题,例如类别不平衡问题、特征相关性和多重共线性等。
- 对于一些复杂的分类问题,Logistic回归可能无法提供最佳的解决方案。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









