






 本文介绍了使用selenium爬取裁判文书网的过程,包括如何模拟登录、定位元素和处理iframe等难点,同时列举了爬虫需要完善的多个方面,如翻页、高级搜索、效率提升和异常处理。
本文介绍了使用selenium爬取裁判文书网的过程,包括如何模拟登录、定位元素和处理iframe等难点,同时列举了爬虫需要完善的多个方面,如翻页、高级搜索、效率提升和异常处理。
今天在CSDN上看了不少帖子,发现裁判文书网的爬取难度很高,据说是由国内顶尖的瑞数信息提供的防护措施,在请求参数中加入了三个加密参数,什么DES3加密直接把我看懵了。对于初学者,我们只好另找一种笨办法——selenium。
如果说requests是将我们伪装成浏览器发送请求,那么selenium就是将浏览器当做我们的提线木偶。相比requests,selenium既有优点也有缺点。优点在于selenium是直接模拟人来操作网页,不用去后台再寻找js代码,因此非常简单,而且不容易被识别;缺点是浏览器本身需要加载时间,因此网络延迟或电脑卡顿都会降低效率。


准备阶段,首先导入selenium和time模块
创建一个谷歌浏览器,作为我们的“提线木偶”
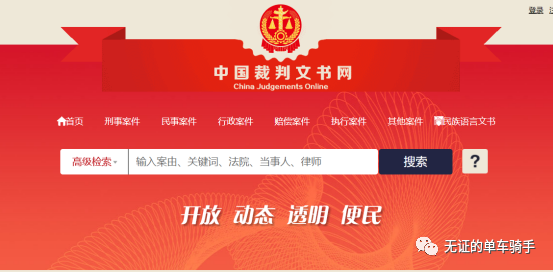
来到主页,我们首先要做的就是点击右上角的登录,否则是无法搜索的
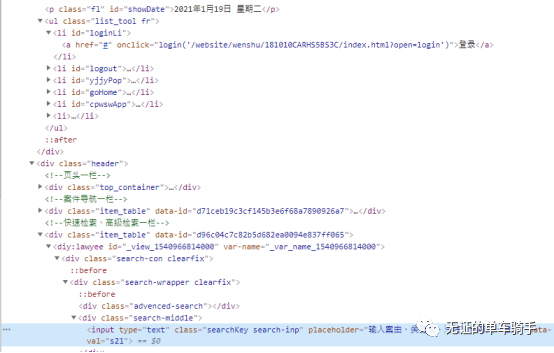
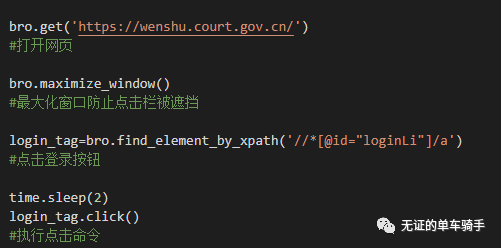
开启检查,获取登录图标所对应的XPath路径,并设定点击该按钮。
接下来来到登录页面,这时候我们需要输入用户名和密码
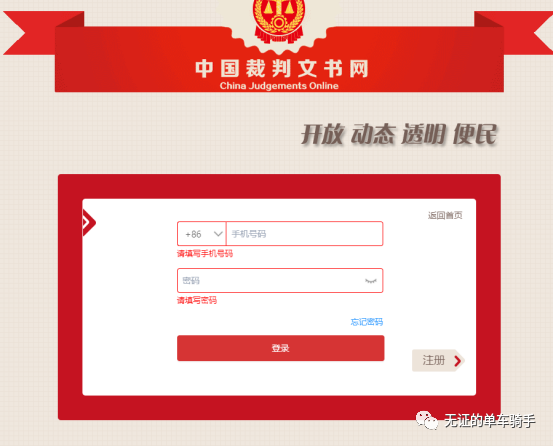
但我在这里报错了很久,面向百度编程后终于发现了问题,这里的输入窗口是iframe结构,也就是网页中的网页,不能直接利用XPath定位到,需要进行位置的切换
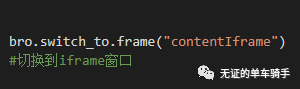
接下来便是利用XPath定位手机号码、密码、登录三个图标的位置,再将我们的手机号、密码输入,点击登录按钮。
登陆成功回到主页,接下来定位搜索栏,输入我们想搜索的内容,点击搜索。
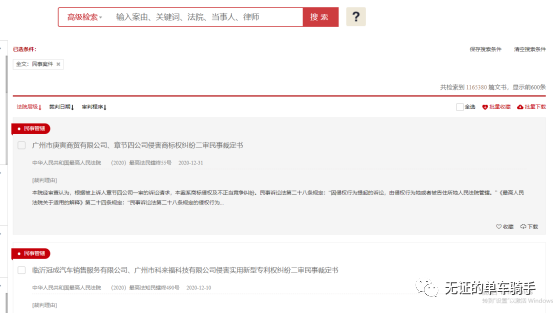
搜索成功,接下我们只需要定位并点击右面的全选和批量下载,即可获取当前页码的全部文书。
这样一来,一个简单的文书网爬虫就完成了
尚需完善的地方:
1. 添加翻页功能,获取更多文书
2. 添加高级搜索功能,将搜索结果限定在600以内,方便全部爬取
3. 对下载的文件进行解压整理,方便使用
4. 尚未进行浏览器伪装,可能会被检测
5. selenium的效率太低,需要进行异步多线程的设计
6. 进行IP代理,防止操作频繁被封
7. 没有设定异常处理,可能因为卡顿或网络延迟而中断

















 1103
1103

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









