







聚类的定义
聚类,在没有标签的情况下,按照某个特定标准(如距离)把一个数据集分割成不同的类或簇,使得同一个簇内的数据对象的相似性尽可能大,同时不在同一个簇中的数据对象的差异性也尽可能地大。也即聚类后同一类的数据尽可能聚集到一起,不同类数据尽量分离。
首先我们先在终端中下载必要的依赖库:
pip install scikit-learn常见的聚类算法
Kmeans算法
KMeans的核心目标是将给定的数据集划分成K个簇(K是超参),并给出每个样本数据对应的中心点。具体步骤非常简单,可以分为4步:
- 选择初始化的 k 个样本作为初始聚类中心:a = a1,a2,……,ak
- 针对数据集中每个样本
计算它到 k 个聚类中心的距离并将其分到距离最小的聚类中心所对应的类中;
- 针对每个类别
,重新计算它的聚类中心
(即属于该类的所有样本的质心)
- 重复上面 2 3 两步操作,直到达到某个中止条件(迭代次数、每一个聚类中的样本不发生改变等)。
而Kmeans++则是在Kmeans的第一步进行了改进,为了减少Kmeans对于初始点选择的敏感性,Kmeans++在选择初始点的时候使得初始点尽可能远。
示例代码
下面是一个示例代码:
from sklearn.cluster import KMeans
import numpy as np
# 创建示例数据
data = np.array([[1.0, 2.0], [1.5, 1.8], [5.0, 6.0], [6.0, 5.8], [1.0, 1.0], [9.0, 8.0]])
# 创建KMeans对象并指定聚类簇的数量,我们可以在进行初始点选择时使用Kmeans或者Kmeans++算法
kmeans = KMeans(n_clusters=2, init='k-means++')
# 拟合数据
kmeans.fit(data)
# 预测聚类标签
labels = kmeans.labels_
# 获取聚类中心
centers = kmeans.cluster_centers_
# 打印聚类标签和聚类中心
print("聚类标签:")
print(labels)
print("聚类中心:")
print(centers)在这里说一句,我们使用的大部分机器学习算法都是先建立模型,再使用.fit()和.predict()这两种方法进行模型训练和预测。
系统聚类
系统聚类的合并算法通过计算两类数据点间的距离,对最为接近的两类数据点进行组合,并反复迭代这一过程,直到将所有数据点合成一类,并生成聚类谱系图。此外,系统聚类可以解决簇数 K 的取值问题。
样本与样本之间的距离
在这里给出了常见的样本之间的距离计算公式:

类与类之间的距离
类与类之间的距离就是集合与集合之间的距离。
类与类之间的距离有如下两个属性:
- 由一个样品组成的类是最基本的类;如果每一类都由一个样品组成,那么样品间的距离就是类间距离。
- 如果某一类包含不止一个样品,那么就要确定类间距离,类间距离是基于样品间距离定义的。
类与类之间的距离有如下几种定义:
最短距离法:
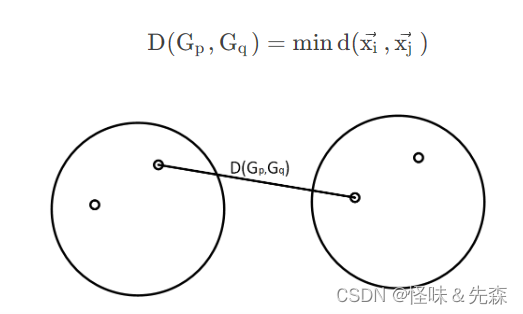
最长距离法:
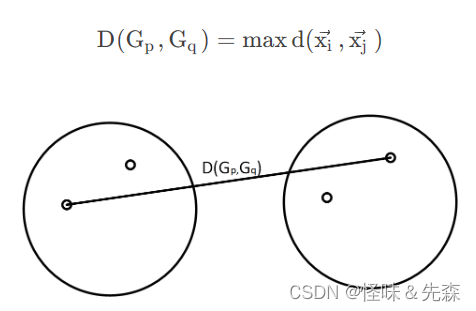
组间平均连线法:
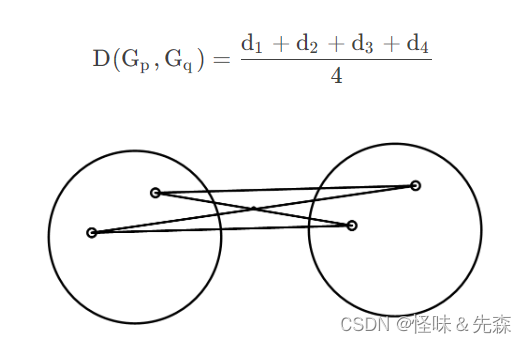
组内平均连接法:
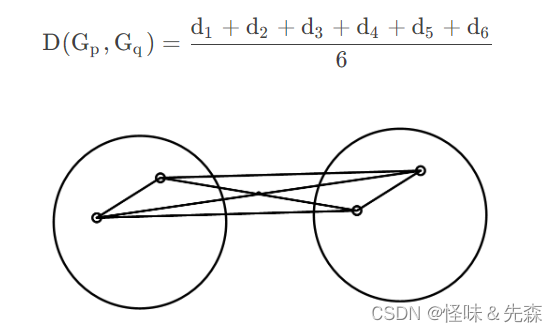
重心法:
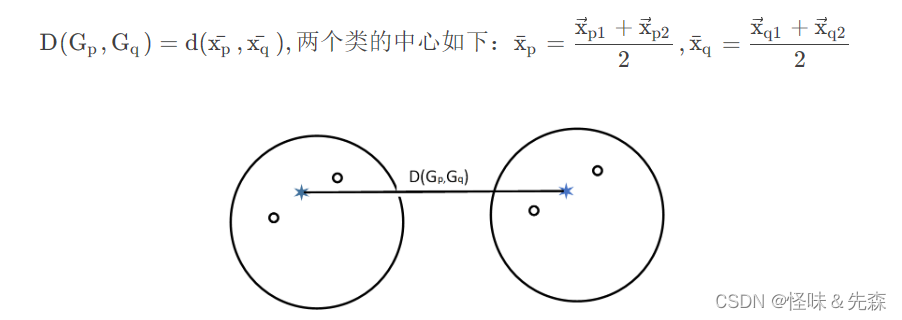
在上述类间的距离公式中,我最常使用的重心法,也叫做(ward法)。
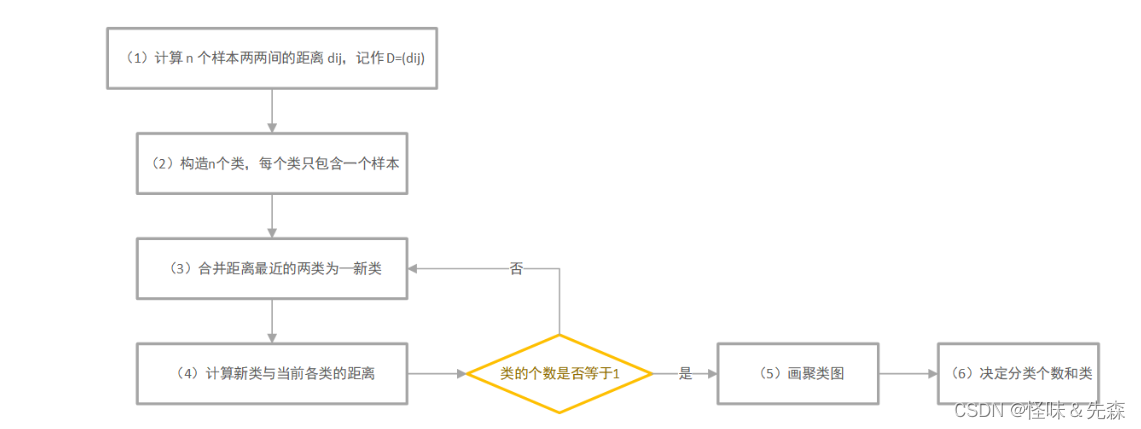
系统聚类的流程图
示例代码
接下来就是大家最关心的代码部分了:
import numpy as np
from scipy.cluster.hierarchy import linkage, dendrogram
import matplotlib.pyplot as plt
# 创建示例数据
data = np.array([[1, 2], [2, 1], [4, 2], [4, 3], [6, 5]])
# 使用linkage函数进行层次聚类,我们可以通过method参数来选择不同的类间距离
Z = linkage(data, method='ward')
# 绘制树状图
dendrogram(Z,leaf_font_size=10,leaf_rotation=90,color_threshold=4) # 可以通过调color_thrshold来控制从哪里开始变颜色其中类间距离参数参考博客:Python层次聚类sci.cluster.hierarchy.linkage函数详解-CSDN博客
DBSCAN
DBSCAN算法是一种基于密度的噪声应用空间聚类的无监督算法。在这里使用两张图来介绍Kmeans算法和DBSCAN算法之间的区别。
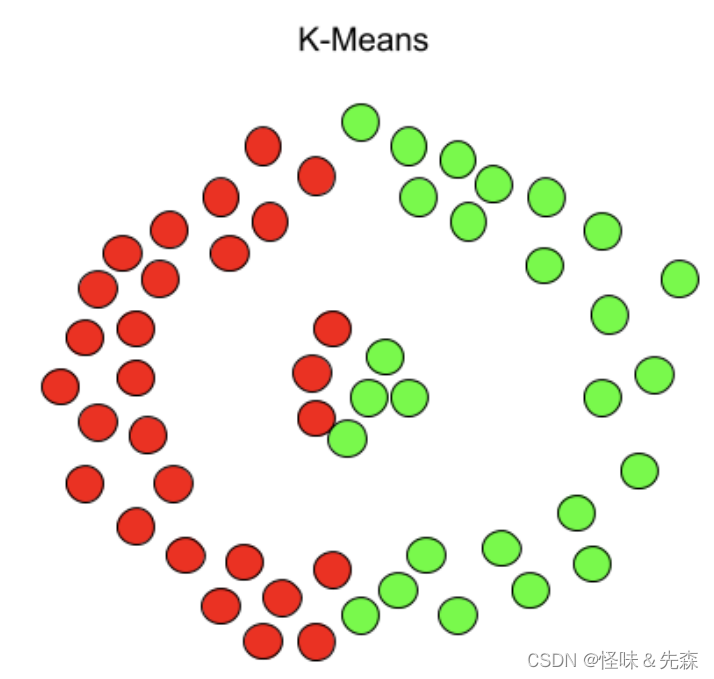
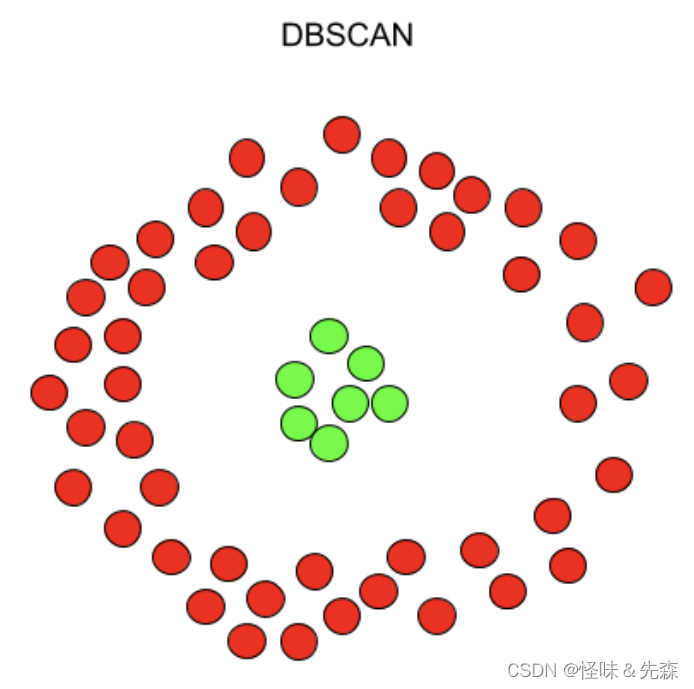
由上图可知,DBSCAN算法是基于密度进行聚类的算法。由于DBSCAN的理论部分牵涉到过多了理论基础,详见:详解DBSCAN聚类 - 知乎 (zhihu.com)
示例代码
from sklearn.cluster import DBSCAN
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
# 创建一个月亮形状的样本数据集
X, y = make_moons(n_samples=200, noise=0.05, random_state=0)
# 创建DBSCAN聚类模型
dbscan = DBSCAN(eps=0.3, min_samples=5)
# 拟合数据
dbscan.fit(X)
# 获取聚类标签
labels = dbscan.labels_
# 绘制聚类结果
plt.scatter(X[:, 0], X[:, 1], c=labels)
plt.xlabel('X')
plt.ylabel('Y')
plt.title('DBSCAN Clustering')
plt.show()我们可以通过模型的属性来得到聚类之后的聚类中心和对未知样本进行预测。上述代码中我们需要根据具体问题来设置DBSCAN模型中的eps和min_samples参数,其中eps越小,聚类的半径越小,min_samples越小,聚类的个数可能越多。
OPTICS
optics针对于dbscan的问题进行了改进,optics可以对任意密度的簇进行聚类,避免了“dbscan直接根据人工指定的半径eplison和min_points,实际上直接定义了最小密度,则密度较小的簇最终会被忽略掉了”的问题;由于DBSCAN无法解决不同密度的聚类问题,因此optics应运而生。
OPTICS的理论在DBSCAN基础上由增加了几个概念,详见:OPTICS聚类最清晰解释 - 知乎 (zhihu.com)
示例代码
from sklearn.cluster import OPTICS
from sklearn.datasets import make_blobs
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
colors = ['red', 'green', 'blue',"yellow","grey"]
cmap = ListedColormap(colors)
# 创建一个随机样本数据集
X, y = make_blobs(n_samples=100, centers=3, random_state=0)
# 创建OPTICS聚类模型
optics = OPTICS(min_samples=5, xi=0.01, min_cluster_size=0.1) # 较小的xi值会产生更多的聚类
# 拟合数据
optics.fit(X)
# 获取聚类标签
labels = optics.labels_
# 获取核心样本的可达距离和聚类半径
reachability_distances = optics.reachability_
cluster_distances = optics.cluster_hierarchy_
# 绘制样本和聚类结果
plt.scatter(X[:, 0], X[:, 1], c=labels,cmap=cmap)
plt.xlabel('X')
plt.ylabel('Y')
plt.title('OPTICS Clustering')
plt.show()
print(set(labels))好啦,今天的聚类算法就到此为止了,希望大家可以为我的博客提一点建议,我也会继续加油的!















 6401
6401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









