







 本文详细探讨了聚类分析的基本概念、常用算法及其在数据结构中的应用。通过实例解析,阐述了如何使用C语言实现聚类过程,包括K-means、层次聚类等方法,并讨论了它们的优缺点及适用场景。
本文详细探讨了聚类分析的基本概念、常用算法及其在数据结构中的应用。通过实例解析,阐述了如何使用C语言实现聚类过程,包括K-means、层次聚类等方法,并讨论了它们的优缺点及适用场景。
聚类分析(Cluster Analysis)
一、聚类分析与判别分析
• 判别分析:已知分类情况,将未知个体归入正确类别
• 聚类分析:分类情况未知,对数据结构进行分类
二、Q型和R型 聚类
Q型是对样本进行分类处理,其作用在于:
1.能利用多个变量对样本进行分类
2.分类结果直观,聚类谱系图能明确、清楚地表达其数值分类结果
3.所得结果比传统的定性分类方法更细致、全面、合理
R型是对变量进行分类处理,其作用在于:
1.可以了解变量间及变量组合间的亲疏关系
2.可以根据变量的聚类结果及它们之间的关系,选择主要变量进行回归分析或Q型聚类分析
三、聚类过程
1.数据预处理(标准化)
2.构造关系矩阵(亲疏关系的描述)
3.聚类(根据不同方法进行分类)
4.确定最佳分类(类别数)
3.1
标准化:
3.1.1为什么要做标准化: 指标变量的量纲不同或数量级相差很大,为了使这些数据能放到一起加以比较,常需做变换。
3.1.2相关说明:假设有N个样本1,2,…n,每个样本有m项指标x
1,
x
2,…,x
m,用
x
ij表示第i个样品第j个指标的值,则可得到样品数据矩阵。
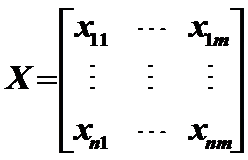
均值表示为,标准差为
,极差为
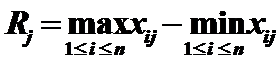
3.1.3 常用方法
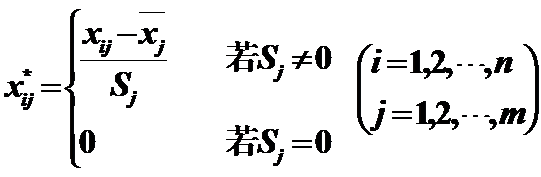
1)Z Scores:标准化变换
作用:变换后的数据均值为0,标准差为1,消去了量纲的影响;当抽样样本改变时,它仍能保持相对稳定性。
2)Range –1 to 1:极差标准化变换
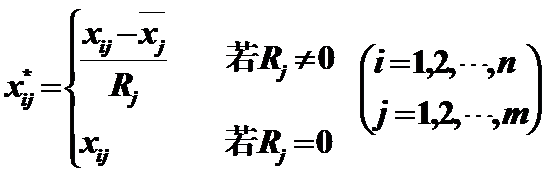
作用:变换后的数据均值为0,极差为1,且|
xij*|<1,消去了量纲的影响;在以后的分析计算中可以减少误差的产生。
3)Maximum magnitude of 1
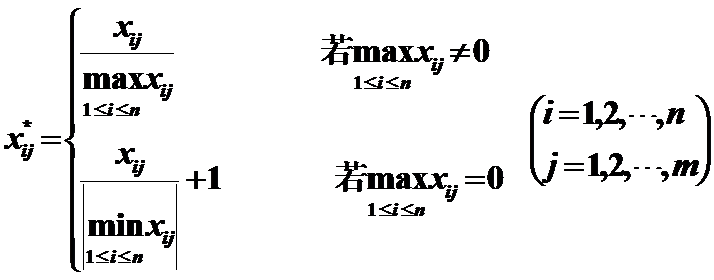
作用:变换后的数据最大值为1。
4)Range 0 to 1(极差正规化变换 / 规格化变换)

作用:变换后的数据最小为0,最大为1,其余在区间[0,1]内,极差为1,无量纲。
5)Mean of 1
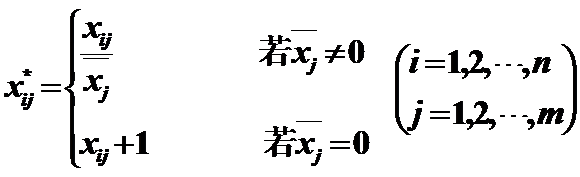
作用:变换后的数据均值为1。
6)Standard deviation of 1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1100
1100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









