






目录
前言
Python是一种强大的编程语言,广泛应用于数据科学和数据分析领域。在数据分析中,数据的合并和清理是非常重要的步骤,初学者在学习数据分析和可视化的过程中可能经常听到或看到,在编写代码前要保证数据的准确性、完整性和一致性。这就要进行我们的数据合并和数据清理。在本文中,我将介绍Python中的数据合并和数据清理的方法。
1.数据合并
1.1 什么是数据合并
首先,数据合并是将来自不同源头的数据整合到一个统一的数据集中。这些源头可能包括来自不同部门、不同系统或不同时间段的数据。数据合并的目的是为了更好地进行数据分析和决策支持。通过将数据整合到一个统一的数据集中,可以消除数据分散导致的冗余和重复,提高数据利用率和效率。
1.2 怎样进行数据合并
数据合并是将两个或多个数据集合并成一个数据集的过程。在Python中,我们可以使用pandas库中的merge()函数来实现数据合并。merge()函数将两个数据集按照一定的条件进行合并,并返回一个新的数据集。我们通过例子更直接的了解:
例如,我们有两个数据集A和B,它们分别包含了学生的姓名、学号和成绩信息,我们想要将它们合并成一个数据集C。我们可以使用如下代码:
import pandas as pd #导入pandas库
# 创建数据集A
data_a = {'Name': ['Tom', 'Jerry', 'Mike', 'John'],
'ID': [101, 102, 103, 104],
'Score': [80, 90, 85, 95]
}
df_a = pd.DataFrame(data_a)
# 创建数据集B
data_b = {'Name': ['Tom', 'Jerry', 'Mike', 'John'],
'ID': [101, 102, 103, 104],
'Grade': ['A', 'A', 'B', 'A']
}
df_b = pd.DataFrame(data_b)
#打印出来
print(df_a)
print(df_b)
代码运行结果:
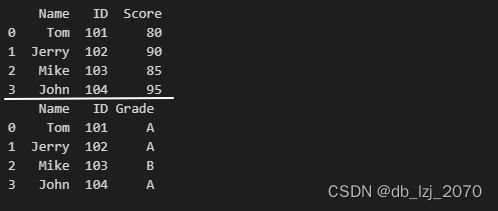
合并这两个数据集:
# 合并数据集A和B为C
df_c = pd.merge(df_a, df_b, on=['Name', 'ID'])
print(df_c)运行结果:
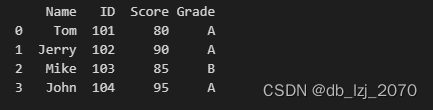
1.3 合并方法
数据合并也分合并方法,分别有:
-
内连接(Inner Join):内连接是指只保留两个数据集中共有的记录,即只有在两个数据集中都存在的记录才会被保留。
-
左连接(Left Join):左连接是指保留左侧数据集中所有的记录,而右侧数据集中没有匹配到的记录将被填充为缺失值。
-
右连接(Right Join):右连接是指保留右侧数据集中所有的记录,而左侧数据集中没有匹配到的记录将被填充为缺失值。
-
外连接(Full Outer Join):外连接是指保留两个数据集中所有的记录,并用缺失值填充那些在另一个数据集中没有匹配到的记录。
-
交叉连接(Cross Join):交叉连接是指将两个数据集中所有的记录进行组合,生成一个新的数据集。交叉连接不需要匹配条件,因此可能会生成非常大的数据集。
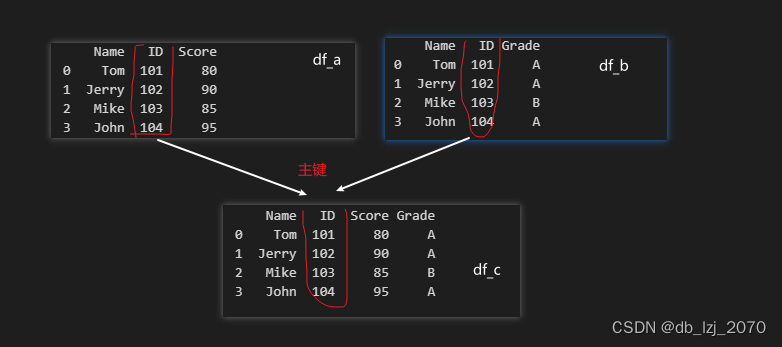
上面我们使用的是merge()函数的主键链接,没有设定它是左还是右。主键合并的概念是基于两个表共有的主键(即某列数据)将两个表的数据根据主键相同原则进行拼接(匹配)。
merge函数的格式:
merged_data = pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False)这里是一些参数的含义:
left和right是要合并的两个数据框。how指定合并的方式,包括'left'、'right'、'outer'和'inner'等。on指定用于合并的列名,若两个数据框的列名不同,可以使用left_on和right_on分别指定左右数据框的列名。left_index和right_index表示是否使用索引进行合并。
在上面的代码中,我们首先创建了两个数据集df_a和df_b,然后使用merge()函数将它们合并成一个新的数据集df_c。merge()函数的参数on指定了合并的条件,即按照姓名和学号进行合并。
2.数据清理
2.1 数据清理的概念
数据清理是指对数据进行检查、修复和删除,以消除数据集中的错误、不一致和缺失值。数据清理的过程包括识别异常值、处理重复数据、填充缺失值、纠正错误数据等操作。数据清理的目的是确保数据的准确性和可靠性,以便后续的数据分析和建模工作能够基于高质量的数据进行。
2.2 处理缺失值
缺失值是指数据集中的某些值为空或未定义。在Python中,我们可以使用fillna()函数来处理缺失值。fillna()函数将缺失值替换为指定的值或根据一定的规则进行填充。
处理缺失值的方法主要有以下几种:
-
删除缺失值:一种简单的处理方法是直接删除包含缺失值的记录或字段。这种方法适用于缺失值较少的情况,且确保删除缺失值不会导致数据偏差。
-
插值填充:插值填充是指根据已知的数据信息,推断并填充缺失值。常见的插值方法包括均值填充、中位数填充、众数填充和线性插值等。选择合适的插值方法取决于数据类型和分布的特点。
-
使用特殊值替代:对于某些特定的字段,可以使用特殊值(如"Unknown"、"N/A")来代替缺失值。这种方法适用于数据集中缺失值没有实际意义的情况。
-
多重插补:多重插补是一种更复杂的填充方法,它基于变量之间的关系,在多个迭代中进行缺失值的估计和填充。这种方法可以提高填充结果的准确性和稳定性。
2.2.1 替换法
例如,我们有一个包含学生姓名、学号和成绩的数据集,其中有一些成绩缺失,我们可以使用如下代码来处理缺失值:
import pandas as pd
import numpy as np
# 创建数据集
data = {'Name': ['Tom', 'Jerry', 'Mike', 'John'],
'ID': [101, 102, 103, 104],
'Score': [80, np.nan, 85, 95]}
df = pd.DataFrame(data)
# 处理缺失值
df['Score'].fillna(0, inplace=True)
print(df)处理前:
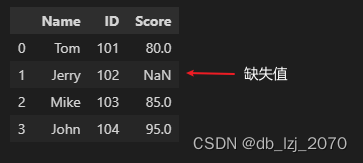
处理后:
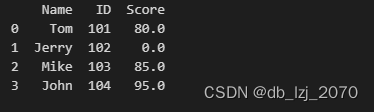
这里我们将缺失值替换成了0
2.2.2 删除法
dropna()是pandas库中用于删除缺失值的方法,它可以通过删除DataFrame或Series对象中包含缺失值的行或列来返回新的DataFrame或Series对象。它的一般语法如下:
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
参数:
| axis | 表示删除缺失值的方向,默认值为0,表示按行删除 |
| how | 表示删除行或列的条件,可以取值为'any'、'all',默认值为'any',表示只要有一个缺失值就删除相应的行或列 |
| thresh | 表示每行(列)至少需要具有非缺失值的数量,小于该数量的行(列)将被删除 |
| subset | 表示要考虑的列,默认值为None,即所有列都参与删除 |
| inplace | 表示是否在原对象上进行修改,默认值为False,表示不在原对象上进行修改 |
2.3 去除重复值
2.3.1 概念
去除重复值是数据处理中常用的操作,它用于从数据集中删除重复出现的值,以保证数据的唯一性和准确性。重复值可能是由于数据输入错误、数据合并或其他原因导致的。
去除重复值的目的是消除数据中的重复项,使得每个值在数据集中只出现一次。这样可以避免在分析和建模过程中对重复数据造成误解或扭曲结果,并提高数据的质量和可靠性。
在数据处理中,通常使用去重函数或方法来实现去除重复值的操作。常见的去重函数有drop_duplicates()函数。drop_duplicates()函数可以根据指定的列或整个数据集进行去重,并提供不同的参数设置来控制去重的行为,如保留第一次出现的值或最后一次出现的值等。
2.3.2 drop_duplicates()函数
drop_duplicates()是pandas库中用于去重的函数,它可以通过删除DataFrame或Series对象中的重复行来返回新的DataFrame或Series对象。它的一般语法如下:
DataFrame.drop_duplicates(subset=None, keep='first', inplace=False)
参数:
| subset | 表示要针对哪些列进行去重,默认值为None,即所有列都参与去重 |
| keep | 表示保留哪一个重复的值,可以取值为'first'、'last'、False,默认值为'first',表示保留第一次出现的值 |
| inplace | 表示是否在原对象上进行修改,可以取值为True、False,默认值为False,表示不在原对象上进行修改 |
例如,下面的代码将对DataFrame对象df中的姓名列进行去重,只保留第一次出现的重复值,并将结果保存在新的对象df2中:
df = pd.DataFrame(
[['甲',80],['甲',85],['乙',90]],
columns=['姓名','分数']
)
df
处理重复值并保存:
# 保存去重后的表
df2 = df.drop_duplicates(subset=['姓名']).reset_index(drop=True)
df2
到这里本文关于数据合并和数据清理的简单学习就结束了。
结语
本文介绍了Python中的数据合并和数据清理的方法,包括使用pandas库中的merge()、fillna()、drop_duplicates()和dropna()函数。数据合并和数据清理是数据分析中非常重要的步骤,它们可以帮助我们更好地理解和分析数据。















 7652
7652











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









