









第二章 KNN算法
2.1 KNN算法概述
KNN(k-Nearest Neighbor,k-近邻)是一种分类和回归的统计方法,是监督学习。它通过测量新样本与已知样本之间的距离,找到距离最近的 k 个邻居,并根据这 k 个邻居的属性对新样本进行分类。KNN 算法的核心思想是“物以类聚,人以群分”,即通过观察样本周围的邻居来判断其所属的类别。
测试数据的预测结果取决于已知数据和测试数据的距离以及人为设置的k值。

如图所示,假设问号位置有一个图形
假设k设置为3,由于测试数据最相近的3个已知数据有2个正方形,1个圆形,则预测结果为正方形;
假设k设置为5,由于测试数据最相近的5个已知数据是3个正方形,2个圆形,则预测结果为正方形。
2.1.1 KNN算法 一般流程
1、收集数据:可以使用任何方法。
2、准备数据:距离计算所需要的数值,最好是结构化的数据格式。
3、分析数据:可以使用任何方法。
4、测试算法:计算错误率。
5、使用算法:
5.1. 计算预测数据与训练数据之间的距离
5.2. 将距离进行递增排序
5.3. 选择距离最小的前K个数据
5.4. 确定前K个数据的类别,及其出现频率
5.5. 返回前K个数据中频率最高的类别(预测结果)
2.1.2 KNN算法 关于距离计算
对于n维实数向量空间 R n R^{n} Rn上的两个点x=( x 1 x _{1} x1, x 2 x _{2} x2,…… x n x _{n} xn)和y=( y 1 y _{1} y1, y 2 y _{2} y2,…… y n y _{n} yn),我们可以定义两点之间一个较为泛化的 L p L _{p} Lp距离——闵可夫斯基距离(Minkowski distance)为:
L p L_ {p} Lp(x,y)=( ∑ i = 1 n \sum _ {i=1}^ {n} ∑i=1n ∣ x i |x_ {i} ∣xi- y i ∣ p y_ {i}|^{p} yi∣p) 1 p \frac {1}{p} p1
其中p≥1时满足数学上对距离的定义。当p=2时,即为我们最常见的欧式距离(Euclidean distance):
L
2
L_ {2}
L2 (x,y)=
∑
i
=
1
n
(
x
i
−
y
i
)
2
\sqrt {\sum _ {i=1}^ {n}(x_ {i}-y_ {i})^ {2}}
∑i=1n(xi−yi)2
也就是
L
2
L_ {2}
L2 (x,y) =
(
x
2
−
x
1
)
2
+
(
y
2
−
y
1
)
2
\sqrt {(x_ {2}-x_ {1})^ {2}+(y_ {2}-y_ {1})^ {2}}
(x2−x1)2+(y2−y1)2
当p=1时,可以称之为曼哈顿距离(Manhattan distance):
L
1
L_ {1}
L1 (x,y)=
∑
i
=
1
n
\sum _ {i=1}^ {n}
∑i=1n
∣
x
i
|x_ {i}
∣xi -
y
i
∣
y_ {i}|
yi∣
当p=∞时,可以称之为切比雪夫距离(Chebyshev distance):
L
∞
L_ {\infty }
L∞(x,y)=
max
i
\max _ {i}
maxi
∣
x
i
|x_ {i}
∣xi-
y
i
∣
y_ {i}|
yi∣
当然,老师上课也特别提到海明距离(Hamming distance)
其距离的值是等于维度不同的维度之和:
如(1,0,1)和(0,0,0)其距离为2
2.1.3 KNN算法 关于K值的选择
| K值 | 影响 |
|---|---|
| 过大 | 预测标签比较稳定,可能过平滑,容易欠拟合 |
| 过小 | 预测的标签比较容易受到样本的影响,容易过拟合 |
我们通常可以使用交叉验证的方法来确定k值的大小,从选取一个较小的K值开始,不断增加K的值,然后计算验证集合的方差,最终找到一个比较合适的K值。
def cross_validate(self, x, y, cv_folds=5):
knn = self
def evaluate_knn(x_test, y_test):
scores = knn.predict(x_test)
return scores
scores = cross_val_score(evaluate_knn, x, y, cv=cv_folds)
return scores
2.2 实现:利用sklearn实现KNN算法完成鸢尾花分类
Sklearn 已经成为最给力的Python机器学习库(library)了。scikit-learn支持的机器学习算法包括分类,回归,降维和聚类。还有一些特征提取(extracting features)、数据处理(processing data)和模型评估(evaluating models)的模块运用到了sklearn
2.2.1 数据集介绍
鸢尾花数据集记录了三个类别(山鸢尾/0,虹膜锦葵/1,变色鸢尾/2),
每个类别50个样本,每个样本四个特征值(萼片长度,萼片宽度,花瓣长度,花瓣宽度)
我们的目标是当输入一个测试数据时通过KNN算法获得预测结果。
2.2.2 代码
# -*- coding: utf-8 -*-
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
class KNN(object):
def get_iris_data(self):
iris = load_iris()
iris_data = iris.data
iris_target = iris.target
return iris_data, iris_target
def run(self):
iris_data, iris_target = self.get_iris_data()
x_train, x_test, y_train, y_test = train_test_split(iris_data, iris_target, test_size=0.25)
std = StandardScaler()
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test)
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(x_train, y_train)
y_predict = knn.predict(x_test)
labels = ["山鸢尾","虹膜锦葵","变色鸢尾"]
for i in range(len(y_predict)):
print("第%d次测试:真实值:%s\t预测值:%s"%((i+1),labels[y_test[i]],labels[y_predict[i]]))
print("准确率:",knn.score(x_test, y_test))
if __name__ == '__main__':
knn = KNN()
knn.run()
2.2.3 运行结果
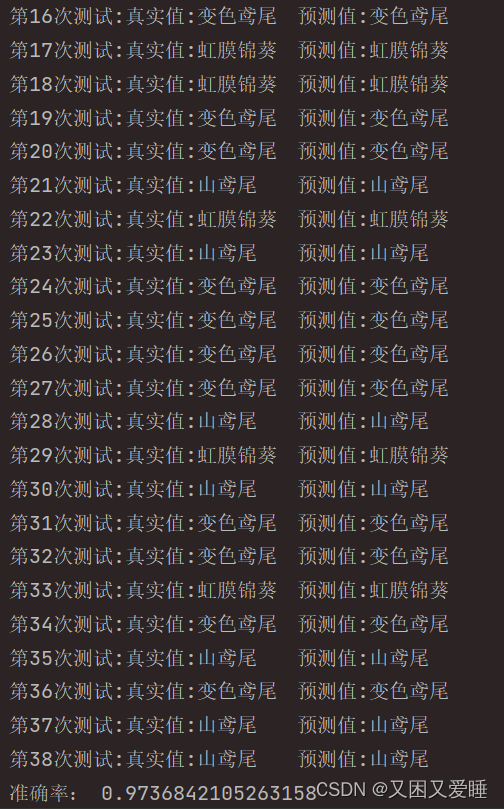
2.3 实现:利用KNN算法分类语音信号中的数字
2.3.1数据集介绍
数据集包括 0 到 5 的数字语音信号。
数据集包含了多种说话者和语音特性,适用于多种语音识别任务。以下是关于简要介绍:
数据集来源:包括网络、电话、广播等。
数据量:数据集包含了大约 100 个说话者,每个说话者录制了1 个数字(1-5),总数据量约为 30000 个语音信号。
数据格式:数据集的语音信号采样率为 8000Hz,16 位采样精度,单语音信号时长不一,每个句子的录音时间约为 1-2 秒。
数据标注:为每个语音信号训练集提供了精确的标注,标注文件包含了每个信号的数字信息。
测试集:选取了249个无标注的随机数字(1-5)语音信号
2.3.2代码
2.3.2.1 KNN类实现及MFCC特征提取
导入所需的库:numpy、glob、librosa 和 scipy。这些库用于处理音频数据、文件操作、MFCC 特征提取和计算统计量。
euclidean_distance():计算欧几里得距离。
get_most_common():获取出现次数最多的元素。
string_to_int():将字符串标签转换为整数。
get_features():使用 librosa 从给定路径加载音频文件,提取 MFCC 特征并计算其 z-score。
KNN 类:
init():初始化 KNN 分类器,接收 k(最近邻数量)和训练数据。
predict():预测新的测试数据,计算其与训练数据的距离,找到 k 个最近邻并返回最常见的标签。
predict_all():预测新的给定测试数据集,对数据集中的每个数据进行预测。
import numpy as np
import glob
import librosa
from scipy import stats
from sklearn.model_selection import cross_val_score
def euclidean_distance(x1, x2):
return np.sqrt(np.sum((x1 - x2) ** 2))
def get_most_common(arr):
unique, pos = np.unique(arr, return_inverse=True) # 获取所有独特元素及其位置
counts = np.bincount(pos) # 计算每个唯一元素的数量
max_count_pos = counts.argmax() # 获取最大计数的位置
# 返回具有最大计数的元素
return unique[max_count_pos]
# 将字符串标签转换为整数
def string_to_int(s):
nums = {"one": 1, "two": 2, "three": 3, "four": 4, "five": 5}
if s in nums:
return str(nums[s])
# 使用 librosa 从给定路径(训练数据)加载音频文件
# 对于每个示例,获取MFCC音频特征并计算其z-score
# 返回一个 3D 数组,其中包含每个文件的z-score数组
def get_features(x_path_list):
x = np.empty(0)
for num_examples in range(len(x_path_list)):
y, sr = librosa.load(x_path_list[num_examples], sr=None)
xi = librosa.feature.mfcc(y=y, sr=sr)
xi = stats.zscore(xi, axis=1)
x = np.append(x.reshape(num_examples, xi.shape[0], xi.shape[1]), [xi], axis=0)
return x
class KNN:
def __init__(self, k, x, y):
self.k = k
# 拟合训练数据和标签
self.x_train = x
self.y_train = y
# 预测新的测试数据
def predict(self, x):
# 计算所有距离
distances = [euclidean_distance(x, x_train) for x_train in
self.x_train] # 列表理解 - 从新样本 X 到 X 中每个样本的所有距离
# 获取 k 最近邻
k_indices = np.argsort(distances)[:self.k] # 对距离进行排序并获取 k 个最接近距离的索引
k_nearest_labels = [self.y_train[i] for i in k_indices] # 获取通过索引找到的最近邻居的标签
# 多数票 - 返回最常见的标签
return get_most_common(k_nearest_labels)
# 预测新的给定测试数据集
def predict_all(self, x):
return [self.predict(xi) for xi in x] # 预测给定数据集 X 中的每个数据
# 交叉验证
def cross_validate(self, x, y, cv_folds=5):
knn = self
def evaluate_knn(x_test, y_test):
scores = knn.predict(x_test)
return scores
scores = cross_val_score(evaluate_knn, x, y, cv=cv_folds)
return scores
2.3.2.2 数据集处理
两个路径变量x_train_path和x_test_path,分别用于存储训练数据和测试数据的文件路径。
代码创建了一个空数组y_train,用于存储训练数据的标签。然后,遍历x_train_path中的每个文件,将其文件夹位置的名称作为标签,并存储在y_train数组中。
使用get_features函数对训练数据和测试数据的音频文件进行特征提取,分别存储在x_train和x_test变量中。
定义一个 KNN 类,并传入训练数据x_train和标签y_train进行训练。训练完成后,使用predict_all方法对测试数据x_test进行预测,并将预测结果存储在predictions变量中。
对预测结果进行处理,并将预测结果保存到名为predictions.txt的文件中。
if __name__ == '__main__':
x_train_path = glob.glob('train_data/*/*.wav') # 获取训练数据文件路径
x_test_path = glob.glob('test_files/*.wav') # 获取测试数据文件路径
# 为训练数据中样本数大小的标签创建空数组
y_train = np.empty(len(x_train_path), dtype=list)
# 获取列表数据标签
for label in range(len(y_train)):
y_train[label] = x_train_path[label][11:-22] # 文件夹位置的名称 - 文件夹的名称是标签
x_train = get_features(x_train_path)
x_test = get_features(x_test_path)
# get k=1 nearest neighbors and predict given data set-x_test
# 获取 k=1 个最近邻并预测给定的数据集x_test
one_nn = KNN(1, x_train, y_train)
predictions = one_nn.predict_all(x_test)
# 输入预测测试文件名(按位置)和预测数量(非标签)
for label in range(len(predictions)):
predictions[label] = x_test_path[label][11:] + " - " + string_to_int(predictions[label])
# 将预测保存到文件
np.savetxt('predictions.txt', [predictions], fmt="%s", delimiter='\n')
2.3.3结果
经人工检验前25/249个,预测准确率约为48%

2.4 总结
2.4.1 优点
简单易用,相比其他算法,KNN算是比较简洁明了。即使没有很高的数学基础也能搞清楚它的原理。
预测效果好。
对异常值不敏感
2.4.2 缺点
对内存要求较高,因为该算法存储了所有训练数据
对训练数据依赖度特别大
预测阶段可能很慢
向量的维度越高,欧式距离的区分能力就越弱
2.4.3 思考
2.4.3.1 KNN适用于语音分类吗,是否可以用在情感识别分类
KNN 分类算法适用于语音情感识别分类。在情感识别中,首先需要提取MFCC语音特征,例如音调、音高、语音强度等,然后将这些特征作为输入变量,使用 KNN 算法对语音进行分类。需要注意的是,KNN 分类算法在处理大量数据时可能存在过拟合的风险,并且在选择邻居时存在一定的主观性。因此,在使用 KNN 算法进行情感识别时,需要选择合适的参数,并进行交叉验证等方法以提高分类的准确性。
2.4.3.2 KNN算法和K-means聚类的区别
KNN 算法是一种基于实例的学习方法,适合于分类和回归任务,而 K-means 聚类算法是一种基于划分的学习方法,适合于聚类任务。















 373
373











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









