






习题6-4 推导LSTM网络中参数的梯度, 并分析其避免梯度消失的效果
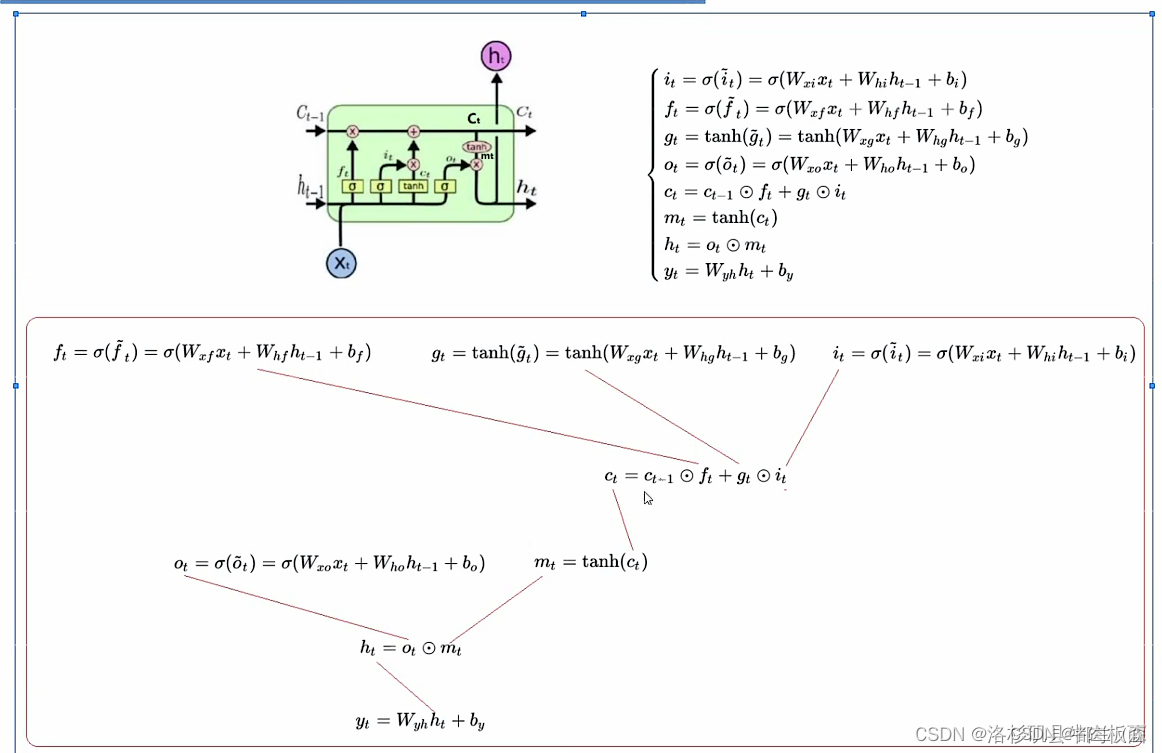
LSTM的更新公式

在推导时候,看了朋友给推荐的视频,感觉还是挺不错的。
视频up主结论图
其实这些参数几乎都是使用链式法则进行梯度更新的,以其中一个参数为例
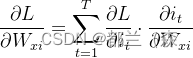
通过链式法则展开就是
![]()
其他的参数也是大差不差。然后在更新过程中,梯度会乘以一个常数,这样就可以避免梯度消失的问题。然后我也查阅了资料去认真看LSTM怎么避免梯度消失的。hhh也是看的朋友推荐的博客。在这篇博客里,他推出了梯度的路径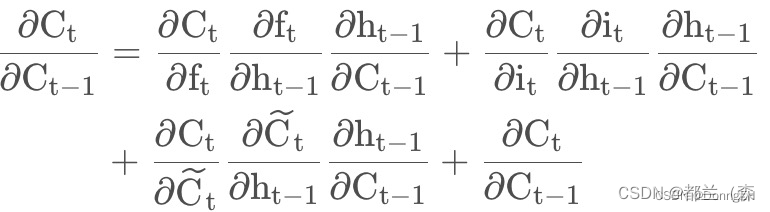
进一步推导得
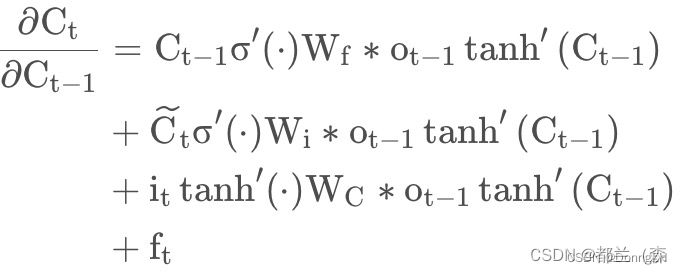
根据公式,如果要计算时刻k的,简单的利用上式进行乘t-k+1次即可。也就是遗忘门可以控制上述的偏导的值
,又因为上述偏导与ft前面三项值有关,所以他的值就不会局限于[0,1],所以他会大于1,所以缓解了梯度消失。所以总结来看避免梯度消失原因为:
1.cell状态的加法更新策略使得梯度传递更恰当,使得梯度更新有可能大于1。
2.门控单元可以决定遗忘多少梯度,他们可以在不同的时刻取不同的值。这些值都是通过隐层状态和输入的数据学习到的。
习题6-3P 编程实现下图LSTM运行过程
1. 使用Numpy实现LSTM算子
import numpy as np
x = np.array([[1, 0, 0, 1],
[3, 1, 0, 1],
[2, 0, 0, 1],
[4, 1, 0, 1],
[2, 0, 0, 1],
[1, 0, 1, 1],
[3, -1, 0, 1],
[6, 1, 0, 1],
[1, 0, 1, 1]])
# x = np.array([
# [3, 1, 0, 1],
#
# [4, 1, 0, 1],
# [2, 0, 0, 1],
# [1, 0, 1, 1],
# [3, -1, 0, 1]])
inputGate_W = np.array([0, 100, 0, -10])
outputGate_W = np.array([0, 0, 100, -10])
forgetGate_W = np.array([0, 100, 0, 10])
c_W = np.array([1, 0, 0, 0])
def sigmoid(x):
y = 1 / (1 + np.exp(-x))
if y >= 0.5:
return 1
else:
return 0
temp = 0
y = []
c = []
for input in x:
c.append(temp)
temp_c = np.sum(np.multiply(input, c_W))
temp_input = sigmoid(np.sum(np.multiply(input, inputGate_W)))
temp_forget = sigmoid(np.sum(np.multiply(input, forgetGate_W)))
temp_output = sigmoid(np.sum(np.multiply(input, outputGate_W)))
temp = temp_c * temp_input + temp_forget * temp
y.append(temp_output * temp)
print("memory:",c)
print("y :",y)![]()
2. 使用nn.LSTMCell实现
import torch
import torch.nn as nn
# 输入数据 x 维度需要变换,因为LSTMcell接收的是(time_steps,batch_size,input_size)
# time_steps = 9, batch_size = 1, input_size = 4
x = torch.tensor([[1, 0, 0, 1],
[3, 1, 0, 1],
[2, 0, 0, 1],
[4, 1, 0, 1],
[2, 0, 0, 1],
[1, 0, 1, 1],
[3, -1, 0, 1],
[6, 1, 0, 1],
[1, 0, 1, 1]], dtype=torch.float)
x = x.unsqueeze(1)
# LSTM的输入size和隐藏层size
input_size = 4
hidden_size = 1
# 定义LSTM单元
lstm_cell = nn.LSTMCell(input_size=input_size, hidden_size=hidden_size, bias=False)
lstm_cell.weight_ih.data = torch.tensor([[0, 100, 0, 10], # forget gate
[0, 100, 0, -10], # input gate
[1, 0, 0, 0], # output gate
[0, 0, 100, -10]]).float() # cell gate
lstm_cell.weight_hh.data = torch.zeros([4 * hidden_size, hidden_size])
#https://runebook.dev/zh/docs/pytorch/generated/torch.nn.lstmcell
hx = torch.zeros(1, hidden_size)
cx = torch.zeros(1, hidden_size)
outputs = []
for i in range(len(x)):
hx, cx = lstm_cell(x[i], (hx, cx))
outputs.append(hx.detach().numpy()[0][0])
outputs_rounded = [round(x) for x in outputs]
print(outputs_rounded)![]()
其中的参数也是查阅其他资料以及同学的博客弄懂的
Parameters
input_size – 输入 x 中预期特征的数量
hidden_size – 隐藏状态下的特征数量 h
偏差 – 如果 False ,则该层不使用偏差权重 b_ih 和 b_hh 。默认值: True
输入:输入,(h_0, c_0)
形状 (batch, input_size) 的输入:包含输入特征的张量
h_0 形状为 (batch, hidden_size) :包含批次中每个元素的初始隐藏状态的张量。
c_0 形状为 (batch, hidden_size) :包含批次中每个元素的初始单元状态的张量。
如果未提供 (h_0, c_0) ,则 h_0 和 c_0 均默认为零。
输出:(h_1,c_1)
h_1 形状为 (batch, hidden_size) :包含批次中每个元素的下一个隐藏状态的张量
c_1 形状为 (batch, hidden_size) :包含批次中每个元素的下一个单元状态的张量
Variables:
~LSTMCell.weight_ih – 可学习的输入隐藏权重,形状为 (4*hidden_size, input_size)
~LSTMCell.weight_hh – 可学习的隐藏权重,形状为 (4*hidden_size, hidden_size)
~LSTMCell.bias_ih – 可学习的输入隐藏偏差,形状为 (4*hidden_size)
~LSTMCell.bias_hh – 可学习的隐藏-隐藏偏差,形状为 (4*hidden_size)
3. 使用nn.LSTM实现
import torch
import torch.nn as nn
# 输入数据 x 维度需要变换,因为 LSTM 接收的是 (sequence_length, batch_size, input_size)
# sequence_length = 9, batch_size = 1, input_size = 4
x = torch.tensor([[1, 0, 0, 1],
[3, 1, 0, 1],
[2, 0, 0, 1],
[4, 1, 0, 1],
[2, 0, 0, 1],
[1, 0, 1, 1],
[3, -1, 0, 1],
[6, 1, 0, 1],
[1, 0, 1, 1]], dtype=torch.float)
x = x.unsqueeze(1)
# LSTM 的输入 size 和隐藏层 size
input_size = 4
hidden_size = 1
# 定义 LSTM 模型
lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size, bias=False)
# 设置 LSTM 的权重矩阵
lstm.weight_ih_l0.data = torch.tensor([[0, 100, 0, 10], # forget gate
[0, 100, 0, -10], # input gate
[1, 0, 0, 0], # output gate
[0, 0, 100, -10]]).float() # cell gate
lstm.weight_hh_l0.data = torch.zeros([4 * hidden_size, hidden_size])
# 初始化隐藏状态和记忆状态
hx = torch.zeros(1, 1, hidden_size)
cx = torch.zeros(1, 1, hidden_size)
# 前向传播
outputs, (hx, cx) = lstm(x, (hx, cx))
outputs = outputs.squeeze().tolist()
# print(outputs)
outputs_rounded = [round(x) for x in outputs]
print(outputs_rounded)![]()
Parameters
input_size – 输入 x 中预期特征的数量
hidden_size – 隐藏状态下的特征数量 h
num_layers – 循环层数。例如,设置 num_layers=2 意味着将两个 LSTM 堆叠在一起形成 stacked LSTM ,第二个 LSTM 接收第一个 LSTM 的输出并计算最终结果。默认值:1
偏差 – 如果 False ,则该层不使用偏差权重 b_ih 和 b_hh 。默认值: True
batch_first – 如果是 True ,则输入和输出张量提供为(batch、seq、feature)。默认: False
dropout – 如果非零,则在除最后一层之外的每个 LSTM 层的输出上引入 Dropout 层,dropout 概率等于 dropout 。默认值:0
双向 – 如果是 True ,则成为双向 LSTM。默认: False
proj_size – 如果是 > 0 ,将使用具有相应大小投影的 LSTM。默认值:0
输入:输入,(h_0, c_0)
形状 (seq_len, batch, input_size) 的输入:包含输入序列特征的张量。输入也可以是打包的可变长度序列。有关详细信息,请参阅 torch.nn.utils.rnn.pack_padded_sequence() 或 torch.nn.utils.rnn.pack_sequence() 。
h_0 形状为 (num_layers * num_directions, batch, hidden_size) :包含批次中每个元素的初始隐藏状态的张量。如果 LSTM 是双向的,则 num_directions 应为 2,否则应为 1。如果指定了 proj_size > 0 ,则形状必须为 (num_layers * num_directions, batch, proj_size) 。
c_0 形状为 (num_layers * num_directions, batch, hidden_size) :包含批次中每个元素的初始单元状态的张量。
如果未提供 (h_0, c_0) ,则 h_0 和 c_0 均默认为零。
输出:输出,(h_n, c_n)
形状 (seq_len, batch, num_directions * hidden_size) 的输出:对于每个 t ,包含来自 LSTM 最后一层的输出特征 (h_t) 的张量。如果 torch.nn.utils.rnn.PackedSequence 作为输入,输出也将是压缩序列。如果指定 proj_size > 0 ,输出形状将为 (seq_len, batch, num_directions * proj_size) 。
对于未包装的情况,可以使用 output.view(seq_len, batch, num_directions, hidden_size) 来区分方向,向前和向后分别是方向 0 和 1 。同样,在包装盒中,方向可以分开。
h_n 形状为 (num_layers * num_directions, batch, hidden_size) :包含 t = seq_len 隐藏状态的张量。如果指定了 proj_size > 0 ,则 h_n 形状将为 (num_layers * num_directions, batch, proj_size) 。
与输出一样,可以使用 h_n.view(num_layers, num_directions, batch, hidden_size) 来分离层,对于 c_n 也类似。
c_n 形状为 (num_layers * num_directions, batch, hidden_size) :包含 t = seq_len 细胞状态的张量。















 903
903











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









