






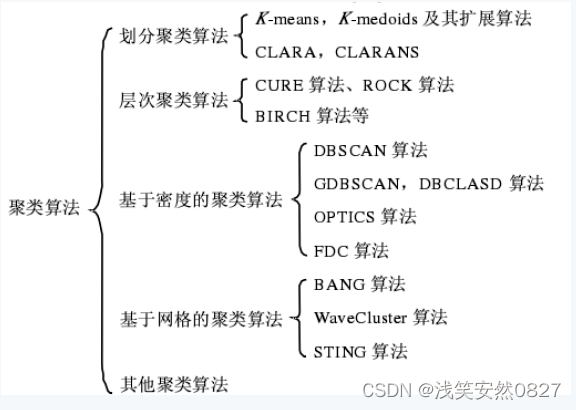
大量数据中具有"相似"特征的数据点或样本划分为一个类别。聚类分析提供了样本集在非监督模式下的类别划分。聚类的基本思想是"物以类聚、人以群分",将大量数据集中相似的数据样本区分出来,并发现不同类的特征。
从统计学的观点看,聚类分析是通过数据建模简化数据的一种方法。传统的统计聚类分析方法包括系统聚类法、分解法、加入法、动态聚类法、有序样品聚类、有重叠聚类和模糊聚类等。采用k-均值、k-中心点等算法的聚类分析工具已被加入到许多著名的统计分析软件包中,如SPSS、SAS等。
从机器学习的角度讲,簇相当于隐藏模式。聚类是搜索簇的无监督学习过程。与分类不同,无监督学习不依赖预先定义的类或带类标记的训练实例,需要由聚类学习算法自动确定标记,而分类学习的实例或数据对象有类别标记。聚类是观察式学习,而不是示例式的学习。
k均值聚类算法(k-means clustering algorithm)是一种迭代求解的聚类分析算法,其步骤是,预将数据分为K组,则随机选取K个对象作为初始的聚类中心,然后计算每个对象与各个种子聚类中心之间的距离,把每个对象分配给距离它最近的聚类中心。聚类中心以及分配给它们的对象就代表一个聚类。每分配一个样本,聚类的聚类中心会根据聚类中现有的对象被重新计算。这个过程将不断重复直到满足某个终止条件。终止条件可以是没有(或最小数目)对象被重新分配给不同的聚类,没有(或最小数目)聚类中心再发生变化,误差平方和局部最小。
(2)算法过程如下
1.计算欧氏距离
2.随机选k个初始聚类中心点
3.更新簇的中心点
4.迭代,直到收敛
import numpy as np
class KMeans:
def __init__(self,data,num_clusters):
self.data = data
self.num_clusters = num_clusters
def train(self,max_iterations):
#先随机选择k个中心点
centroids = KMeans.centroids_init(self.data,self.num_clusters)
num_examples = self.data.shape[0]
closest_centroids_ids = np.empty((num_examples,1))
for _ in range(max_iterations):
#得到当前每一样本到k个中心点的距离,找到最近的
closest_centroids_ids = KMeans.centroids_find_closest(self.data,centroids)
centroids = KMeans.centroids_compute(self.data,closest_centroids_ids,self.num_clusters)
return centroids,closest_centroids_ids
@staticmethod
def centroids_init(data,num_clusters):
num_examples = data.shape[0]
random_ids = np.random.permutation(num_examples)
centroids = data[random_ids[:num_clusters],:]
return centroids
@staticmethod
def centroids_find_closest(data,centroids):
num_examples = data.shape[0]
num_centroids = centroids.shape[0]
closest_centroids_ids = np.zeros((num_examples,1))
for example_index in range(num_examples):
distance = np.zeros((num_centroids,1))
for centroids_index in range(num_centroids):
distance_diff = data[example_index,:] - centroids[centroids_index,:]
distance[centroids_index] = np.sum(distance_diff**2) #马氏距离
closest_centroids_ids[example_index] = np.argmin(distance)
return closest_centroids_ids
@staticmethod
def centroids_compute(data,closest_centroids_ids,num_clusters):
num_features = data.shape[1]
centroids = np.zeros((num_clusters,num_features))
for centroid_id in range (num_clusters):
closest_ids = closest_centroids_ids == centroid_id
centroids[centroid_id] = np.mean(data[closest_ids.flatten(),:],axis=0)
return centroids
对于无监督聚类(如kmeans)的特征选择:
-
可以结合实际情况,选择相近的特征。
-
另一方面,可以结合缺失率、相似度、PCA等常用的特征选择降维方法去除噪音、减少计算量,结合特征进行重要性排序。
-
最后,也可以通过神经网络的特征表示,将高维的以低维的分布式向量表示。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









