







背景
本文背景聚焦于医学影像分析中深度学习模型适配的挑战,特别是数据稀缺和新疾病出现的情况下:
-
医学影像领域的特殊性:
- 专业标注数据的缺乏和高昂成本限制了大规模深度学习模型的开发。
- 在新疾病(如 COVID-19)刚出现时,通常只能获得少量样本,这对模型的泛化能力提出了很高要求。
-
预训练视觉-语言模型(Vision-Language Models, VLMs)的潜力和局限:
- VLMs 通过结合自然语言处理(NLP)和计算机视觉(CV),利用视觉和文本语义对齐的能力,在多种领域展现出强大的迁移学习能力。
- 然而,这些模型在训练数据集中对目标疾病的表示有限时(即稀有疾病)或完全没有相关数据时(即新疾病),适配效果往往不理想。
-
现有方法的局限性:
- 现有的模型适配方法包括适配器(adapter)和提示学习(prompting)技术:
- 适配器方法(如 CLIP-Adapter、Tip-Adapter)仅调整模型的最后几层参数,对新任务的适应性较弱。
实验结果表明,在 PanNuke 数据集上应用下游任务时,基于适配器的方法总体表现最差。这意味着仅仅调整最后一层可能无法有效地利用 VLM 在下游任务中的能力。在与其他方法(如基于提示的方法等)对比时,该类方法在各项指标上的表现均不突出,如在肾脏、结肠和胰腺等器官的分类任务中,其 F1 和 AUC 等指标相对较低,无法达到较好的分类效果 - 提示学习方法(如 CoOp、CoCoOp)优化可学习提示,能够提升性能,但未能有效融入特定领域知识,如医学中的疾病特性。
- 适配器方法(如 CLIP-Adapter、Tip-Adapter)仅调整模型的最后几层参数,对新任务的适应性较弱。
- 现有的模型适配方法包括适配器(adapter)和提示学习(prompting)技术:
-
实际临床需求:
- 在临床环境中,快速而高效地适配模型来识别新疾病(如 COVID-19 初期)或处理数据稀缺的任务尤为重要。
- 此外,能够基于有限的标注数据提升性能的模型对医学影像分析的广泛应用具有重要意义。
要解决的问题
1. 稀有疾病的适配
- 问题:在预训练数据集中,某些疾病的样本数量极少或类别表示不足,导致 VLMs 在这些疾病上的性能较差。
- 挑战:如何从有限的数据中提取出有效的疾病特征,提升模型在稀有疾病上的泛化能力。
2. 新疾病的适配
- 问题:当遇到预训练数据集中完全没有表示的新疾病(如 COVID-19),模型缺乏相关先验知识,无法有效识别。
- 挑战:如何通过引入领域知识和少量新样本,使模型能够快速适应新疾病的分类或诊断任务。
3. 小样本学习的效率问题
- 问题:医学影像分析领域标注数据稀缺且昂贵,模型需要在有限的标注样本下仍能展现出色的表现。
- 挑战:如何通过高效的训练机制,在大幅减少标注数据的情况下,仍能显著提升模型性能。
4. 模型几何表示的优化
- 问题:预训练 VLMs 的特征表示往往缺乏结构化的几何约束,可能导致模型在分类或检索任务中表现不佳。
- 挑战:如何对模型的潜在空间进行几何正则化,以提升特征的可分性和疾病的准确识别能力。
5. 结合医学知识进行模型优化
- 问题:现有方法通常未充分利用医学领域知识(如疾病的纹理、形状、位置等特征)来优化模型,导致表现有限。
- 挑战:如何将医学领域知识与视觉-语言模型结合,增强模型在医学影像分析中的表现。
详解框架、工作流程
本文提出了一种 疾病信息驱动的视觉-语言模型适配框架,由两个核心模块组成:疾病信息驱动的上下文提示 (Disease-informed Contextual Prompting, DiCoP) 和 疾病原型学习 (Disease Prototype Learning, DPL)。以下是该框架的详细结构和工作流程:
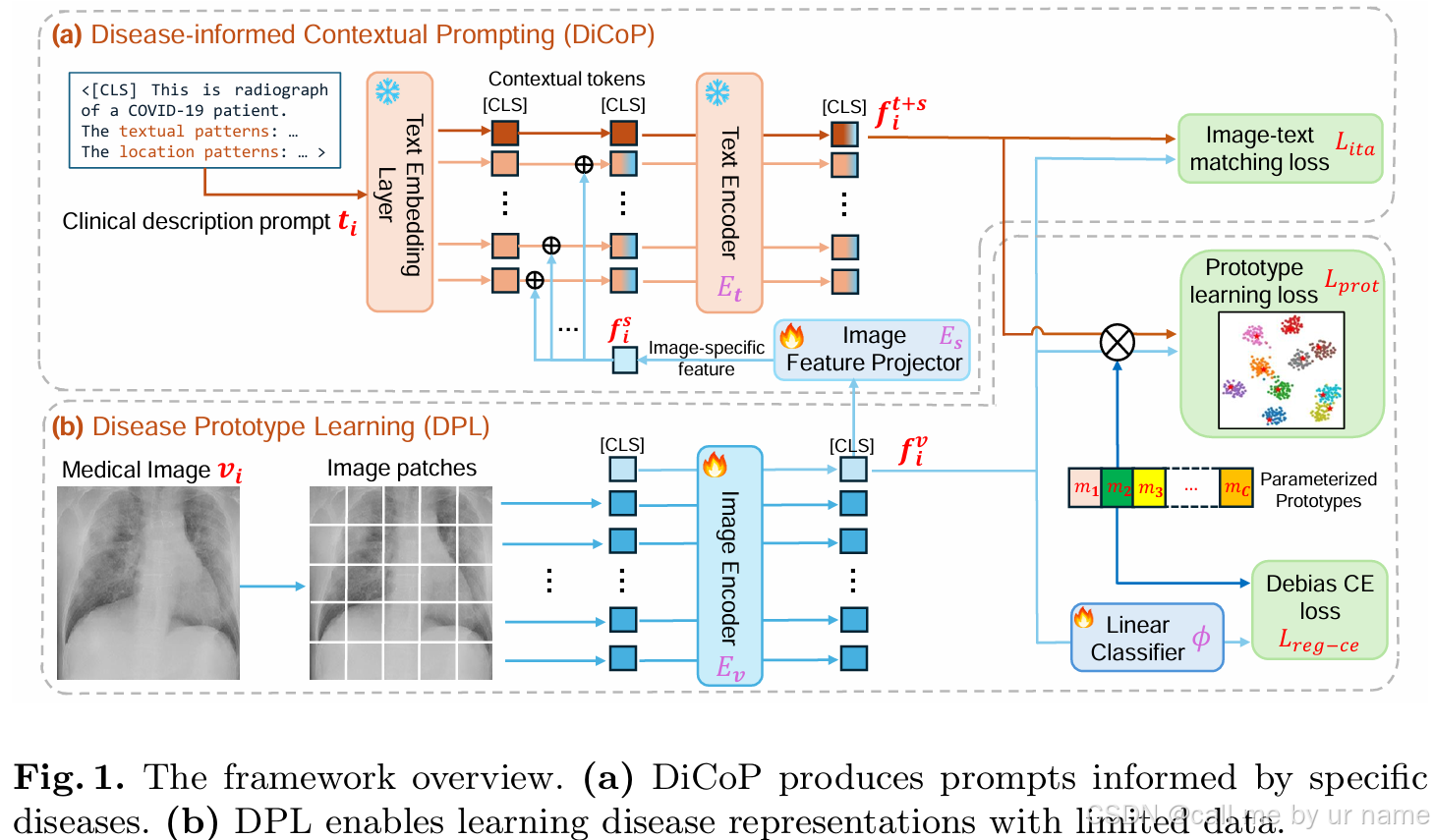
框架概述
模型主要由以下组件构成:
- 视觉编码器 ( E v \mathbf{E}_v Ev):用于提取医学影像的特征。
- 文本编码器 ( E t \mathbf{E}_t Et):用于处理由疾病相关文本生成的提示(prompts)。
- 图像特征投影器 ( E s \mathbf{E}_s Es):将视觉特征转换为适合文本上下文增强的形式。
- 疾病原型参数 ( { m k } k = 1 C \{\mathbf{m}_k\}_{k=1}^C {mk}k=1C):每个疾病类别的表示,用于正则化和优化潜在特征空间。
- 线性分类器 ( ϕ \phi ϕ):将视觉特征映射到最终分类任务。
输入输出
- 输入:图像 v i \mathbf{v}_i vi 和对应的手工设计提示 t i \mathbf{t}_i ti。
- 输出:分类结果,如疾病的类型或状态。
框架主要包含两个阶段:
- 疾病信息驱动的上下文提示 (DiCoP)
- 疾病原型学习 (DPL)
1. 疾病信息驱动的上下文提示 (DiCoP)
目标
通过结合医学知识生成上下文提示,将疾病的关键属性(纹理、形状、位置等)与图像特定的特征结合,以提升模型对稀有或新疾病的表示能力。
工作流程
- 构建疾病提示模板
- 基于临床知识,构建描述性模板
Prompt
k
\text{Prompt}_k
Promptk,包括疾病的 纹理(texture)、形状(shape) 和 位置(location):
Prompt k = Des k ( texture ) ⊕ Des k ( location ) ⊕ Des k ( shape ) , \text{Prompt}_k = \text{Des}_k(\text{texture}) \oplus \text{Des}_k(\text{location}) \oplus \text{Des}_k(\text{shape}), Promptk=Desk(texture)⊕Desk(location)⊕Desk(shape),
其中 ⊕ \oplus ⊕ 表示描述的拼接, Des k ( ⋅ ) \text{Des}_k(\cdot) Desk(⋅) 是针对疾病 k k k 的描述。
- 结合图像上下文特征
使用视觉编码器 E v \mathbf{E}_v Ev 提取图像特征 f i v = E v ( v i ) \mathbf{f}_i^v = \mathbf{E}_v(\mathbf{v}_i) fiv=Ev(vi),再通过图像特征投影器 ( E s \mathbf{E}_s Es) 映射到上下文空间:
f i s = E s ( f i v ) . \mathbf{f}_i^s = \mathbf{E}_s(\mathbf{f}_i^v). fis=Es(fiv).将投影后的图像特征添加到文本提示的嵌入向量中(除了 ([CLS]) 标记),生成增强提示: f i t + s = f i t + f i s . \mathbf{f}_i^{t+s} = \mathbf{f}_i^t + \mathbf{f}_i^s. fit+s=fit+fis. - 图像-文本对齐损失
通过优化图像和提示的对齐,增强模型对稀有疾病的表示能力。损失函数定义为:
L ita = 1 2 N ∑ i = 1 N [ log exp ( f i v ⋅ f i t + s / τ 1 ) ∑ j = 1 N exp ( f i v ⋅ f j t + s / τ 1 ) + log exp ( f i t + s ⋅ f i v / τ 1 ) ∑ j = 1 N exp ( f j t + s ⋅ f i v / τ 1 ) ] , \mathcal{L}_{\text{ita}} = \frac{1}{2N} \sum_{i=1}^N \left[ \log \frac{\exp(\mathbf{f}_i^v \cdot \mathbf{f}_i^{t+s} / \tau_1)}{\sum_{j=1}^N \exp(\mathbf{f}_i^v \cdot \mathbf{f}_j^{t+s} / \tau_1)} + \log \frac{\exp(\mathbf{f}_i^{t+s} \cdot \mathbf{f}_i^v / \tau_1)}{\sum_{j=1}^N \exp(\mathbf{f}_j^{t+s} \cdot \mathbf{f}_i^v / \tau_1)} \right], Lita=2N1i=1∑N[log∑j=1Nexp(fiv⋅fjt+s/τ1)exp(fiv⋅fit+s/τ1)+log∑j=1Nexp(fjt+s⋅fiv/τ1)exp(fit+s⋅fiv/τ1)],
其中 τ 1 \tau_1 τ1 是温度超参数。
2. 疾病原型学习 (DPL)
目标
通过为每个疾病类别构建原型 m k \mathbf{m}_k mk,对潜在特征空间进行几何正则化,从而提升分类任务中的表现。
工作流程
- 疾病原型初始化
每个疾病类别 (k) 的原型初始化为对应文本提示的表示:
m k = f k t . \mathbf{m}_k = \mathbf{f}_k^t. mk=fkt. - 原型优化
- 对每张图像的视觉特征 f i v \mathbf{f}_i^v fiv 和增强提示特征 f i t + s \mathbf{f}_i^{t+s} fit+s,优化它们与对应类别原型 m k \mathbf{m}_k mk 的余弦相似性。
- 损失函数定义为:
L prot = ∑ k = 1 C 1 ∣ S k ∣ ∑ i ∈ S k [ exp ( f i v ⋅ m k τ 2 ) + exp ( f i t + s ⋅ m k τ 2 ) ] − λ 1 ∑ k ≠ j exp ( m k ⋅ m j τ 2 ) , \mathcal{L}_{\text{prot}} = \sum_{k=1}^C \frac{1}{|S_k|} \sum_{i \in S_k} \left[ \exp \left( \frac{\mathbf{f}_i^v \cdot \mathbf{m}_k}{\tau_2} \right) + \exp \left( \frac{\mathbf{f}_i^{t+s} \cdot \mathbf{m}_k}{\tau_2} \right) \right] - \lambda_1 \sum_{k \neq j} \exp \left( \frac{\mathbf{m}_k \cdot \mathbf{m}_j}{\tau_2} \right), Lprot=k=1∑C∣Sk∣1i∈Sk∑[exp(τ2fiv⋅mk)+exp(τ2fit+s⋅mk)]−λ1k=j∑exp(τ2mk⋅mj),其中 τ 2 \tau_2 τ2是温度超参数, λ 1 \lambda_1 λ1 是权重因子。
- 正则化交叉熵损失
为避免过拟合,添加正则化项,使原型与对应文本提示嵌入保持较小的 (L_2) 距离:
L reg-ce = − 1 N ∑ i = 1 N log ( ϕ ( f i v ) ⋅ y i ) + λ 2 ∑ k = 1 C ∥ m k − f k t ∥ 2 2 , \mathcal{L}_{\text{reg-ce}} = - \frac{1}{N} \sum_{i=1}^N \log(\phi(\mathbf{f}_i^v) \cdot \mathbf{y}_i) + \lambda_2 \sum_{k=1}^C \|\mathbf{m}_k - \mathbf{f}_k^t\|_2^2, Lreg-ce=−N1i=1∑Nlog(ϕ(fiv)⋅yi)+λ2k=1∑C∥mk−fkt∥22,其中 λ 2 \lambda_2 λ2 是正则化权重。 - 总损失
模型的总损失为:
L total = L ita + L prot + L reg-ce . \mathcal{L}_{\text{total}} = \mathcal{L}_{\text{ita}} + \mathcal{L}_{\text{prot}} + \mathcal{L}_{\text{reg-ce}}. Ltotal=Lita+Lprot+Lreg-ce.
工作流程总结
- 提取图像和文本提示的特征,生成疾病相关的上下文提示。
- 优化图像-文本对齐损失,使模型能够更好地理解疾病的概念。
- 构建疾病原型并通过几何正则化优化潜在空间的表示。
- 综合优化上述损失,提升模型在稀有和新疾病上的分类表现。
实验
实验设计与结果
我们在两个数据集PanNuke和COVIDx上评估了所提出的方法。PanNuke[4]包含19个器官的7558张病理图像。任务是基于组织外观进行二分类(恶性或良性)。当应用于下游任务时,PLIP在某些器官(包括肾脏、结肠和胰腺)上表现出次优的零样本性能(F1 < 0.5),这是因为它们在预训练数据集中的代表性不足[11]。我们按照==PLIP[11]==将图像调整为224×224像素大小,并将数据按7:1:2的比例划分为训练/验证/测试集。COVID - x(v6)[23]包含从多个国家收集的胸部X光图像。任务是三分类(COVID - 19、非COVID肺炎或正常)。在MIMIC数据集[12]上预训练的BioViL[2]是在COVID大流行之前开发的。因此,COVID - 19对该模型来说是一种新疾病。由于我们无法获取测试集,我们将29634张图像的原始训练集按7:1的比例划分为训练子集和验证子集,并使用原始的400张图像的验证集进行测试。我们按照BioViL将所有图像调整为512×512像素大小。
实验数据集
-
PanNuke
- 任务:二分类(恶性或良性),针对19种器官的病理图像。
- 数据量:7,558张病理图像。
- 问题:某些器官(如肾脏、结肠和胰腺)在预训练数据集中样本稀少,导致模型对这些类别表现不佳。
- 数据预处理:图像统一调整为 (224 \times 224) 分辨率,训练集、验证集和测试集按照7:1:2划分。
-
COVID-x
- 任务:三分类(COVID-19、非COVID肺炎和正常)。
- 数据量:29,634张胸部X光片(训练集和验证集),测试集400张。
- 问题:COVID-19为新疾病,预训练数据集中完全没有样本。
- 数据预处理:图像统一调整为 (512 \times 512) 分辨率。
实验设置
-
基线方法
- 适配器方法:
- Linear Probing:仅调整模型最后一层。
- CLIP-Adapter:通过轻量化适配器对特征进行调整。
- Tip-Adapter:结合特征提取与分类头优化。
- 提示学习方法:
- CoOp:优化可学习提示。
- CoCoOp:在CoOp的基础上加入上下文特征。
- MaPLe:利用多模态提示进行领域适配(仅适用于Transformer)。
- 适配器方法:
-
模型参数
- 使用 ( ViT-B/16 ) (\text{ViT-B/16}) (ViT-B/16) 作为视觉编码器, ( ResNet-50 ) (\text{ResNet-50}) (ResNet-50) 用于部分实验。
- 超参数:
- 学习率:0.0005。
- 优化器:AdamW。
- 批量大小:64。
- 损失函数中的温度参数: τ 1 = τ 2 = 0.07 \tau_1 = \tau_2 = 0.07 τ1=τ2=0.07。
- 正则化权重: λ 1 = λ 2 = 0.1 \lambda_1 = \lambda_2 = 0.1 λ1=λ2=0.1。
-
评价指标
- AUC:衡量分类器的综合性能。
- F1 Score:用于评估分类的精确性和平衡性。
- Precision 和 Recall:用于衡量分类细节。
实验结果
1. PanNuke:稀有疾病的分类性能
- 数据使用:仅使用训练集5%的样本。
- 结果:
- 提出的 DiCoP + DPL 方法 在所有指标上显著优于基线方法。
- 对关键器官(如肾脏、结肠、胰腺)的结果(10次运行均值)如下表所示:
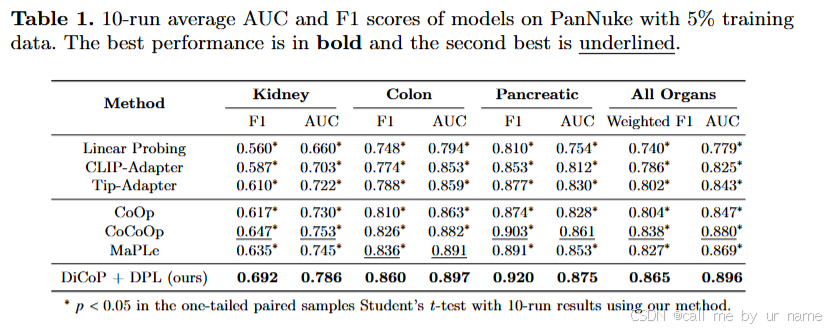
我们通过将我们的方法与基于适配器的方法(线性探测[19]、CLIP - 适配器[5]和提示适配器[29])以及基于提示的方法(CoOp[31]、CoCoOp[30]和MaPLe[13])进行对比,来证明我们方法的有效性。在PanNuke数据集方面,当应用于下游任务时,PLIP在某些器官(包括肾脏、结肠和胰腺)上呈现出次优的零样本性能(F1 < 0.5),正如作者[11]所提到的,这是由于它们在预训练数据集中的代表性不足。我们在每次运行中通过对5%的训练数据进行采样来微调PLIP,并计算测试集上的10次运行平均度量值以消除随机性。结果展示在表1中。基于适配器的方法在所有方法中通常表现最差。这表明仅仅调整最后一层可能无法在下游任务中有效地利用视觉语言模型(VLM)的能力。我们的方法在几乎所有情况下都显著(通过学生t检验,p < 0.05)优于其他基于提示的方法。这凸显了疾病知情上下文提示(DiCoP)相对于在无临床知识情况下优化提示的优势,也展示了疾病原型学习(DPL)在使视觉语言模型适应代表性不足器官方面的益处,从而避免了在稀缺数据上出现过拟合的情况。
在统计学中,“(通过学生t检验,p < 0.05)”具有特定的含义:
- 学生t检验:这是一种常用的假设检验方法,用于比较两组数据的均值是否有显著差异。它基于t分布理论,通过计算t值来判断两组数据之间的差异是否仅仅是由于随机因素造成的。在该研究中,主要用于比较本文所提出的方法与其他方法在性能上的差异。例如,比较使用疾病知情上下文提示(DiCoP)和疾病原型学习(DPL)的方法(即DiCoP + DPL,本文方法)与其他基于适配器或基于提示的方法(如线性探测、CLIP - Adapter、CoOp、CoCoOp等方法)在处理医学图像分析任务(如在PanNuke数据集上的器官组织分类任务,或在COVID - x数据集上的COVID - 19检测等任务)时的性能差异。
- p值:p值是在假设检验中用于衡量证据强度的指标。它表示在原假设(通常是两组数据没有差异或某种处理没有效果)成立的情况下,观察到当前数据或更极端数据的概率。在该研究中,原假设可以是本文方法与其他对比方法在性能上没有差异。如果p值小于预先设定的显著性水平(通常为0.05),则拒绝原假设,认为两组数据之间存在显著差异;如果p值大于0.05,则不能拒绝原假设,即没有足够的证据表明两组数据之间存在显著差异。例如,在比较本文方法与其他方法在PanNuke数据集上的性能时,计算得到的p值小于0.05,这意味着在该数据集上,本文方法与其他对比方法的性能差异不太可能是由于随机因素导致的,而是本文方法在统计上显著优于其他对比方法。同样,在COVID - x数据集上的比较中,p值小于0.05也表明本文方法在检测COVID - 19以及整体分类任务上的性能显著优于其他方法。
在该文档中,“(通过学生t检验,p < 0.05)”多次出现,用于表明在不同数据集(如PanNuke和COVID - x)和不同任务(如器官组织分类、疾病检测)下,本文提出的方法与其他对比方法相比,在各项评估指标(如AUC、F1分数等)上具有显著的优势,这种优势是经过严格的统计检验得到的,不是偶然因素造成的,从而有力地证明了本文方法的有效性和优越性。
2. COVID-x:新疾病的分类性能
- 数据使用:仅使用训练集1%的样本。
- 结果:
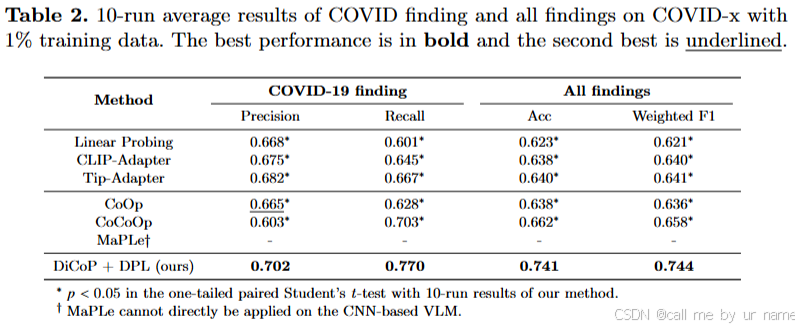
3. 数据效率
测试在不同训练数据比例(1%、5%、10%、50%、100%)下的模型性能:
- 结果:
- DiCoP + DPL 在小样本(1%或5%)时比其他方法表现出更高的 F1 和 Recall。
- 当训练数据量增加时,本方法仍能保持领先,证明了其数据效率。
4. 消融实验
通过逐步移除框架中的关键模块,验证各模块的贡献:
实验设计:
- w/o L prot \mathcal{L}_{\text{prot}} Lprot:移除原型学习损失。
- L reg-ce → L ce \mathcal{L}_{\text{reg-ce}} \to \mathcal{L}_{\text{ce}} Lreg-ce→Lce:用普通交叉熵替代正则化交叉熵。
- w/o L ita \mathcal{L}_{\text{ita}} Lita:移除图像-文本对齐损失。
- no E s \mathbf{E}_s Es:不加入图像特定特征。
- no attributes:移除疾病特征描述(纹理、形状、位置)。
结果:
- 各组件对性能都有显著贡献,尤其是 L prot \mathcal{L}_{\text{prot}} Lprot 和图像特定特征模块 E s \mathbf{E}_s Es。
实验结论
本文的 DiCoP + DPL 方法 在稀有和新疾病适配任务中均表现出色。通过结合医学知识和几何正则化,框架在数据高效性和小样本学习能力上表现卓越,证明其在医学影像分析领域的应用潜力。
引用
J. Zhang, G. Wang, M. K. Kalra and P. Yan, “Disease-informed Adaptation of Vision-Language Models,” in IEEE Transactions on Medical Imaging, doi: 10.1109/TMI.2024.3484294. keywords: {Diseases;Medical diagnostic imaging;Adaptation models;Visualization;Prototypes;Transfer learning;Image analysis;Tuning;COVID-19;Shape;Vision-Language Model;Foundation Model;Transfer Learning;Model Adaptation;New Disease;COVID-19},



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









