







提要
白盒水印方案
白盒水印技术需要直接访问模型的内部结构和参数。它通常通过在模型的权重、结构或其他内部元素中嵌入特定的信息或模式来实现。由于白盒水印直接嵌入在模型内部,因此它可以提供更直接和可靠的版权证明。
针对水印方案的攻击
- 模糊攻击(Ambiguity Attacks):在这种攻击中,攻击者的目标是构造一个伪造的水印,当给定一个带有水印的DNN(深度神经网络)时,能够通过验证过程。这种攻击的目的是使验证过程产生误判,即错误地认为伪造的水印是原始水印。
- 移除攻击(Removal Attacks):与模糊攻击不同,移除攻击的目标更加直接,即试图通过从受保护的模型中移除秘密身份消息来使验证过程失效。由于这种攻击直接影响模型所有权的建立,因此您的研究专注于开发新的移除攻击,以破解当前最先进的白盒模型水印。
本文的攻击类型
背景
As a critical asset of AI corporations, well-trained DNNs are exposed under the risk of model stealing attacks, which makes the need for model copyright protection current and pressing
一个训练良好的模型是AI公司的重要财产,面临被盗窃的风险,需要版权保护来防止非法使用
To achieve the attack goal, the primary constraints for the attacker are (i) the obfuscation process should not cost more resources than training a DNN from scratch and (ii) the utility of the obfuscated model should have no clear decrease.
However, as summarized in Table 1, none of the existing approaches can balance well the cost on utility or computing resources for fully removing the embedded watermark.
On the one hand, removal attacks by parameter modification inevitably encounter degradation in the normal model utility
对于白盒水印攻击,有2个限制:
- 修改模型参数或结构所消耗的资源不能比重新训练一个模型更高
- 修改后的模型在预测能力上不能有明显的下降
而现有的方法都无法在完全移除嵌入的水印的同时,很好地平衡模型效用或计算资源的成本。
要解决的问题
-
现有方法不能在完全移除嵌入的水印的同时,很好地平衡模型效用或计算资源的成本。
-
现有的移除攻击的局限性:
- 剪枝(Pruning):
剪枝通过将DNN中一定比例的冗余参数设置为零来工作。然而,之前的白盒水印对剪枝具有很高的抵抗力。为了完全移除水印,剪枝需要去除大量的权重,这会导致不可接受的效用损失。也就是说,在移除水印的同时,模型的性能会大幅下降。 - 微调(Finetuning):
微调是在没有与水印相关的损失的情况下继续训练操作几个周期。这种移除攻击需要一定量的领域数据和计算资源,否则模型的效用会下降。这意味着,为了成功移除水印,攻击者需要投入大量的数据和计算资源,这可能会使攻击成本过高。 - 重写(Overwriting):
重写攻击是在知道水印过程的情况下,通过嵌入攻击者自己的识别信息来混淆验证。然而,在现实世界环境中,水印方案的细节通常不可用。此外,重写攻击通常无法按照更先进的方案在目标模型中编码新消息。这意味着,重写攻击的成功性受限于攻击者对水印方案的了解程度,以及水印方案本身的复杂性。 - 提取(Extraction):
提取攻击利用知识蒸馏技术在盗版模型上获得一个通常具有不同架构的混淆模型。然而,这种攻击不可避免地涉及大量的训练成本来提炼出一个训练良好的混淆模型。虽然最近的一些工作在知识蒸馏中消除了对数据集访问的假设,但大多数主流提取攻击仍然使用传统的知识蒸馏方法,并需要访问领域数据集以减少效用损失。这意味着,提取攻击不仅需要大量的计算资源,而且还需要访问与原始模型相同或相似的数据集,这可能会使攻击变得困难或不可能。
- 剪枝(Pruning):
创新点
提出了一种基于虚拟神经元(dummy neurons)的神经结构混淆攻击,这种攻击能够在不损失模型功能的情况下,有效地破坏水印的验证过程:
- 即一组可以添加到目标DNN模型中的神经元,用于在可证明地保持模型行为不变(即,在相同输入下模型输出保持不变)的同时,密集地干扰嵌入的水印。一个简单的例子是具有零输入和输出权重的神经元,如果添加到DNN模型中,对模型的输出没有贡献。作为一种初步但有效的攻击方式,攻击者通过向每个神经层注入一定数量的这些神经元来混淆受保护的模型,这已经可以抑制大多数最先进的白盒水印的执行,但在攻击隐蔽性方面存在明显的限制
提出一个更全面的框架用于自动生成并将虚拟神经元注入到受害模型中,该框架在检查混淆后的模型时实现了注入的虚拟神经元的固有隐蔽性。
提出了NeuronClique和NeuronSplit两种新颖的结构混淆原语来构建虚拟神经元组,其中这些神经元具有非零权重,但不会对模型输出产生任何变化。具体来说,NeuronClique原语直接生成任意数量的神经元,并为它们分配权重,以抵消其他神经元的输出;而NeuronSplit则将受害模型中的一个神经元转换为两个替代神经元,这两个替代神经元保留了被替换神经元的功能
方案
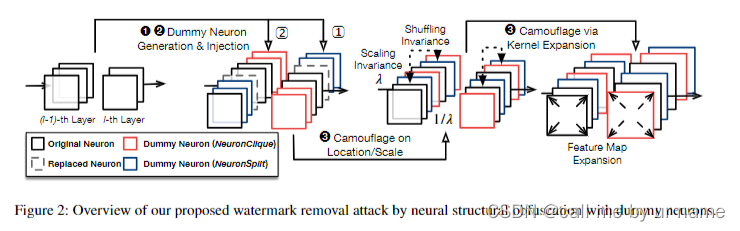
-
虚拟神经元生成(Dummy Neuron Generation):作者提出了两种非平凡的虚拟神经元生成原语,即 “NeuronClique” 和 “NeuronSplit”,用于构建具有非消失权重的虚拟神经元。这些虚拟神经元旨在防止基于消失权重的直接检测。
-
虚拟神经元注入(Dummy Neuron Injection):攻击者将使用这两种原语从模型的最后一个隐藏层开始,向前生成并注入虚拟神经元。这个过程考虑了注入的虚拟神经元的隐蔽性。
-
进一步伪装(Further Camouflage):最后一步是通过其他DNN上的不变变换来进一步伪装注入的虚拟神经元,包括在规模、位置和形状上,目的是将原始模型转换为与原始自身几乎没有结构相似性的混淆模型,同时保持模型的正常效用。
NeuronZero
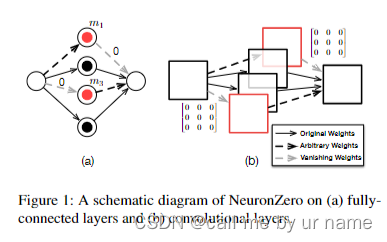
将神经元的输入或输出权重设置为全零向量,同时将可选的偏置也设置为0可选的偏置为z=wx+b中的b,但保持输入/输出权重可以任意分配。例如,在图1(a)中的虚拟神经元m1具有值为0的输出权重(即,对于所有的j,v1,j = 0)。因此,m1对后续层中任何神经元的贡献始终是0。另外,虚拟神经元m3的输入权重值为0,这意味着m3的激活值始终是0。这两种情况都证明了它们对下一层输出没有影响,并最终保持了模型的效用不变。
由于DNN中的全连接层是卷积层的一种简化形式,我们可以在卷积神经网络(CNN)中以同样的方式添加虚拟神经元(图1(b)),即将所有输入或输出卷积核的权重设置为0。
NeuronClique
它创建一组具有相同输入权重和任意输出权重的虚拟神经元。这些虚拟神经元的设计满足了它们相互之间的输出可以抵消掉,从而不会改变模型的输出。具体来说,对于生成的每个虚拟神经元,它们的输入权重是相同的,而输出权重是随机采样的,且它们的总和为零,这保证了虚拟神经元对模型行为的不影响。

U是输入权重,取样自前一层实数张量的空间
R:表示实数集,意味着张量中的每个元素都是一个实数; N l − 1 N_{l-1} Nl−1表示第 l − 1 l−1 l−1 层的神经元数量; w 和 h w和h w和h:分别表示卷积核的宽度和高度,也就是卷积核在输入特征图上的“视野”或“感受野”的大小。

其中,应为
V
k
,
o
u
t
l
V^l_{k,out}
Vk,outl
NeuronSplit
这是一种将一个普通神经元分裂成多个替代神经元的方法,这些替代神经元共同工作以保持对后续层的功能不变性。具体做法是,将选定的普通神经元的权重分配给一组新的替代神经元,这些替代神经元的输出权重之和等于原神经元的输出权重,从而保持了模型的原有功能。选定第 l l l 层的第一个神经元进行分裂

其中,应为
V
k
,
o
u
t
l
V^l_{k,out}
Vk,outl,
m
k
l
m^l_k
mkl,
W
1
,
i
n
l
W^l_{1,in}
W1,inl
虚拟神经元注入

伪装
-
利用洗牌不变性:为了随机化虚拟神经元的位置,攻击者利用了神经网络的洗牌不变性。通过随机排列每一扩展层中的神经元,注入的虚拟神经元被分散在原始神经元之间。这样做可以随机化虚拟神经元的位置,而不是将它们作为独立的模块注入,从而防止了位置信息被用于神经元检测。
-
利用缩放不变性:你可以将某一层的所有权重都乘以一个正数λ(即“缩放”),然后在下一层以相同的比例缩放权重,网络的输出仍然保持不变(在忽略激活函数非线性影响的前提下)
-
攻击者通过增加受保护模型中每个卷积层的核大小来修改模型架构。这实际上是通过在原始核矩阵周围填充零(即增加隐式填充量)来实现的,同时保持输入激活映射(activation maps)的隐式填充量相应增加。这样做会改变卷积层的权重形状,从而混淆虚拟神经元的权重分布。
与注入的虚拟神经元相结合,攻击者可以在同一层的核中填充非零值,而不仅仅是零。这样做不仅可以提高注入神经元的隐蔽性(因为它们的权重现在与真实神经元的权重更难区分),还可以给验证过程引入更多的扰动,使得检测攻击变得更加困难。
实验
论文中提到了9种水印方法
这里选用greedy-residuals
论文提到了虚拟神经元消除算法,但在这里,我只做攻击
评估指标
攻击有效性:使用位错误率(Bit Error Rate,BER),即提取出的水印中修改的位数与预定义签名的位数之比,来衡量我们的移除攻击对水印的破坏程度。
效用损失:水印模型在攻击前后的性能,包括图像生成任务的FID[56]得分、图像描述任务的BLEU-1[57]得分以及其他任务的分类准确率[16, 18]。这些指标用于衡量移除攻击对模型原始功能的影响。
代码
import torch
import torch.nn as nn
# 假设我们有一个已经存在的模型,我们想要在第l层添加虚拟神经元
# 为了示例,我们简单地使用一个具有线性层的假想模型
class VictimModel(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(VictimModel, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = self.fc2(x)
return x
# NeuronClique实现
def add_neuron_clique(model, layer_index, num_dummy_neurons, input_weights=None):
# 假设layer_index是我们要修改的层的索引(从0开始)
# 这里我们简单地假设我们要修改的是第一个全连接层fc1
assert 0 <= layer_index < len(list(model.modules())), "Layer index out of range"
# 找到要修改的层
layers = list(model.modules())
target_layer = layers[layer_index]
assert isinstance(target_layer, nn.Linear), "The target layer is not a linear layer"
# 获取原始权重
orig_weight = target_layer.weight.data
orig_bias = target_layer.bias.data if target_layer.bias is not None else None
# 如果未提供输入权重,则随机采样
if input_weights is None:
input_weights = torch.randn(num_dummy_neurons, orig_weight.size(1))
# 构造输出权重,使得它们的和为零(这里简化处理,仅设置为零)
output_weights = torch.zeros(num_dummy_neurons, orig_weight.size(0))
# 创建一个新的线性层来包含虚拟神经元
dummy_layer = nn.Linear(num_dummy_neurons, orig_weight.size(0), bias=False)
dummy_layer.weight.data = output_weights
# 这里我们只是简单地将虚拟神经元的输出设置为零,实际上你可能需要更复杂的策略
# 来确保它们的输出在下一层相互抵消
# 你可以将dummy_layer添加到模型中,但这里为了简单起见,我们只是展示了如何创建它
# 注意:在实际应用中,你可能需要修改模型结构来容纳这个新的层,并相应地调整前向传播逻辑
# 返回原始权重、虚拟神经元的输入权重和输出权重(以及偏置,如果有的话)
return orig_weight, orig_bias, input_weights, output_weights
# 示例用法
input_size = 10
hidden_size = 20
output_size = 3
victim_model = VictimModel(input_size, hidden_size, output_size)
# 假设我们要在第一个全连接层(索引为0)添加3个虚拟神经元
num_dummy_neurons = 3
orig_weight, orig_bias, input_weights, output_weights = add_neuron_clique(victim_model, 0, num_dummy_neurons)
# 打印原始权重和虚拟神经元的权重
print("Original weights shape:", orig_weight.shape)
print("Input weights for dummy neurons shape:", input_weights.shape)
print("Output weights for dummy neurons shape:", output_weights.shape)
import torch
import torch.nn as nn
class NeuronClique(nn.Module):
def __init__(self, in_features, out_features, num_dummy_neurons):
super(NeuronClique, self).__init__()
# 创建一组虚拟神经元
self.dummy_neurons = nn.ModuleList([nn.Linear(in_features, out_features) for _ in range(num_dummy_neurons)])
# 初始化输入权重为相同随机值
self.dummy_input_weights = nn.Parameter(torch.randn(num_dummy_neurons, in_features), requires_grad=False)
# 初始化输出权重,使得所有虚拟神经元的输出相互抵消
self.dummy_output_weights = nn.Parameter(torch.zeros(num_dummy_neurons, out_features), requires_grad=False)
# 计算并设置输出权重,使得它们的输出相互抵消
self.set_output_weights()
def set_output_weights(self):
# 假设我们创建了d个虚拟神经元
d = self.dummy_neurons[0].out_features
# 随机生成一组权重,然后对它们进行单位化处理
random_weights = torch.randn(d)
normalized_weights = random_weights / torch.norm(random_weights, dim=0)
# 将输出权重设置为这些单位化的权重,但符号相反,以相互抵消
self.dummy_output_weights.data = torch.diag(normalized_weights).repeat(len(self.dummy_neurons), 1)
def forward(self, x):
# 为每个虚拟神经元计算输出
dummy_outputs = [neuron(x) for neuron in self.dummy_neurons]
# 将所有虚拟神经元的输出相加,由于它们的输出权重设计为相互抵消,总和为零
return torch.stack(dummy_outputs).sum(dim=0)
# 示例:如何在一个全连接层后注入NeuronClique
class ModelWithNeuronClique(nn.Module):
def __init__(self, in_features, hidden_features, out_features, num_dummy_neurons):
super(ModelWithNeuronClique, self).__init__()
self.fc1 = nn.Linear(in_features, hidden_features)
self.neuron_clique = NeuronClique(hidden_features, out_features, num_dummy_neurons)
self.fc2 = nn.Linear(hidden_features, out_features)
def forward(self, x):
x = self.fc1(x)
x = self.neuron_clique(x)
x = self.fc2(x)
return x
# 创建模型
model = ModelWithNeuronClique(in_features=784, hidden_features=256, out_features=10, num_dummy_neurons=5)
# 展示模型结构
print(model)
import torch
import torch.nn as nn
class NeuronSplit(nn.Module):
def __init__(self, original_layer: nn.Linear, d: int):
super(NeuronSplit, self).__init__()
self.original_layer = original_layer
self.d = d
# 假设我们只分割第一个神经元,因此只复制第一个神经元的权重
# 获取原始神经元的权重和偏置
original_weights = original_layer.weight.data
original_bias = original_layer.bias.data if original_layer.bias is not None else None
# 初始化新的权重和偏置
# 假设我们仅修改输入层到第一神经元的权重
new_weights = torch.zeros(original_weights.size(0) + d, original_weights.size(1) , device=original_weights.device)
new_bias = torch.zeros(original_weights.size(0) + d, device=original_weights.device) if original_bias is not None else None
# 复制原始神经元的权重到新的权重矩阵的第一行
new_weights[0, :] = original_weights[0, :]
if original_bias is not None:
new_bias[0] = original_bias[0]
# 随机初始化剩余虚拟神经元的权重(这里简化为均匀分布)
for i in range(1, d + 1):
# 注意:这里应该根据具体需求来选择权重的初始化方式
new_weights[:, i] = torch.randn_like(original_weights[:, 0]) * 0.01 # 假设使用小权重初始化
if original_bias is not None:
new_bias[i] = torch.randn_like(original_bias[0]) * 0.01 # 假设使用小偏置初始化
# 构造新的线性层
self.new_layer = nn.Linear(original_layer.in_features + d, original_layer.out_features, bias=original_bias is not None)
self.new_layer.weight.data = new_weights
if original_bias is not None:
self.new_layer.bias.data = new_bias
def forward(self, x, dummy_input=None):
# 如果没有提供虚拟神经元的输入,则使用0填充
if dummy_input is None:
dummy_input = torch.zeros(x.size(0), self.d, device=x.device)
# 拼接原始输入和虚拟神经元的输入
combined_input = torch.cat([x, dummy_input], dim=1)
# 通过新的线性层进行前向传播
output = self.new_layer(combined_input)
return output
# 示例用法
original_layer = nn.Linear(10, 20) # 假设的原始层
d = 3 # 虚拟神经元的数量
# 创建NeuronSplit层
neuron_split_layer = NeuronSplit(original_layer, d)
# 模拟输入数据
input_data = torch.randn(5, 10) # 原始输入
dummy_input_data = torch.randn(5, d) # 虚拟神经元的输入
# 前向传播
output = neuron_split_layer(input_data, dummy_input_data)
print(output.shape) # 应该是(5, 20),与原始层的输出形状相同
# 实现权重缩放和洗牌的函数
def scale_and_shuffle_weights(model):
for name, module in model.named_children():
if isinstance(module, nn.Linear):
# 获取权重和偏置
weights = module.weight.data
bias = module.bias.data if module.bias is not None else None
# 随机缩放权重
scale_factor = torch.rand(weights.size(0)) + 0.5 # 缩放因子在0.5到1.5之间
weights *= scale_factor[:, None]
# 如果有偏置,也缩放偏置
if bias is not None:
bias *= scale_factor
# 随机洗牌权重
torch.randperm(weights.size(0))[:, None]
# 更新模块的权重和偏置
module.weight.data = weights
if bias is not None:
module.bias.data = bias
elif isinstance(module, nn.Conv2d):
# 对于卷积层,我们可以通过增加核大小和填充来扩展核
# 这里我们简单地将核大小增加1,并在输入上添加相应的填充
new_kernel_size = module.kernel_size[0] + 1
new_padding = (new_kernel_size - module.kernel_size[0]) // 2
module.conv2d = nn.Conv2d(module.in_channels, module.out_channels, kernel_size=new_kernel_size, padding=new_padding)
# 利用缩放不变性来伪装权重
def camouflage_scaling(layer, scale_factor):
layer.weight.data *= scale_factor
layer.bias.data *= scale_factor
# 利用洗牌不变性来随机化权重的位置
def camouflage_shuffling(layer):
indices = torch.randperm(layer.weight.size(0))
layer.weight.data = layer.weight.data[indices]
layer.bias.data = layer.bias.data[indices]
# 核扩展技术(这里仅提供一个概念性的示例)
def kernel_expansion(layer, expansion_factor):
# 假设我们有一个卷积层,我们扩展它的核大小
# 这个例子不完整,因为实际的核扩展技术会更复杂
# 并且需要根据卷积层的具体实现来设计
pass
# 应用伪装技术到模型的某个层
def apply_camouflage(layer, scale_factor=None, shuffle=True):
if scale_factor is not None:
camouflage_scaling(layer, scale_factor)
if shuffle:
camouflage_shuffling(layer)
某校老师夏令营考核















 961
961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









