








目录
一、自定义类型种类
1、结构体
2、位段
3、枚举
4、联合体(共同体)
二、结构体
1、结构体的声明
定义一个表示学生信息的结构体如下
struct students
{
char name[10];
int age;
char sex[5];
};根据上述代码可得到结构体的第一种声明方式
struct 结构体名
{
成员变量列表;
}; //注意此处有分号除此之外还有匿名结构体,这种结构体只能使用一次,在声明的时候就定义了变量s,之后不可以再定义变量
struct
{
成员变量列表;
}s;2、结构体变量的定义与初始化
1.定义
1.在声明的时候定义变量
struct students
{
char name[10];
int age;
char sex[5];
}stu1;在声明的时候创建了结构体变量stu1,stu1此时是一个全局变量
2.在main函数内部定义变量
struct students
{
char name[10];
int age;
char sex[5];
}stu1;
int main()
{
struct students stu2;
}这种定义方式:struct 结构体名 变量名;
2.结构体变量的初始化
1.在声明的时候初始化
同2.1.1中的定义方式,在定义时初始化
struct students
{
char name[10];
int age;
char sex[5];
}stu1={"张三",15,"男"};定义方式:
struct students
{
成员变量列表;
}变量名={相对应成员列表的数据};
eg:定义一个表示坐标的结构体,p点在(2,4),定义变量表示p
struct point
{
int x;
int y;
}P={2,4};2.在main函数内部初始化
struct students
{
char name[10];
int age;
char sex[5];
}stu1={"张三",15,"男"};
int main()
{
struct students stu2={"李四",14,"男"};
}定义方式:struct 结构体名 变量名={与成员列表对应类型的数据};
3、结构体成员的访问
1.变量访问(.)
使用.这个操作符来访问
#include<stdio.h>
#pragma warning(disable:4996)
struct students
{
char name[10];
int age;
char sex[5];
}stu1={"张三",15,"男"};
int main()
{
struct students stu2={"李四",14,"男"};
printf("%s %d %s", stu2.name, stu2.age, stu2.sex);
}
控制台:
李四 14 男
访问时:变量名.要访问的结构体成员列表里的变量名
//给stu1变量赋值年龄如下:
stu1.age=90;2.指针访问(->)
使用前必须先定义一个结构体指针来指向要访问的结构体变量
struct students stu2={"李四",14,"男"};
struct students* p = &stu2;此时访问时可以通过:指针名->要访问的成员变量名
#include<stdio.h>
struct students
{
char name[10];
int age;
char sex[5];
}stu1={"张三",15,"男"};
int main()
{
struct students stu2={"李四",14,"男"};
struct students* p = &stu2;
printf("%s %d %s", p->name, p->age, p->sex);
return 0;
}
控制台:
李四 14男
使用:指针名->成员变量名
4、结构体重命名
1.结构体重命名
使用typedef重命名
typedef struct students
{
char name[10];
int age;
char sex[5];
}STU;
int main()
{
STU stu2={"李四",14,"男"};//重命名后使用重命名后的名字定义
return 0;
}2.结构体指针重命名
struct students
{
}* 重命名的名字;重命名后结构体指针可以这样使用
typedef struct students
{
char name[10];
int age;
char sex[5];
}STU,* stu;
int main()
{
STU stu2={"李四",14,"男"};
stu p = &stu2;
printf("%s %d %s", p->name, p->age, p->sex);
return 0;
}控制台:
李四 14 男
5、结构体传参
1.值传参
void print(struct students s)
{
printf("%s %d %s", s.name, s.age, s.sex);
}
int main()
{
struct students stu2={"李四",14,"男"};
print(stu2);//将结构体变量直接传入函数
return 0;
}这种传参方式不推荐使用,因为函数的每次调用都会在栈上开辟空间,开辟函数栈帧的时候,而形参又是实参的零时拷贝,会将结构体变量拷贝一份到函数的栈上,如果结构体所占内存过大,对空间的消耗会很大
2.址传参
void print(struct students* s)//由于传入的是一个地址,所以要用指针来接收
{
printf("%s %d %s", s->name, s->age, s->sex);
}
int main()
{
struct students stu2={"李四",14,"男"};
print(&stu2);//将该结构体变量的指针传入
return 0;
}推荐使用这种传参方式,传入地址,节省空间
6、结构体内存对齐
1.对齐数
在介绍内存对齐前必须先了解一个概念,就对齐数。对齐数就是,该编译器默认对齐数与该变量所占字节的小的较小值,如果没有默认对对齐数,就是后者,VS2022默认对齐数时8
默认对齐数的修改
#pragma pack(对齐数字)默认对齐数的改回
#pragma pack()2.内存对齐的规则
1.第一个结构体成员放在相对于起始地址偏移量为0的地方存放
2.其他结构体成员要对齐到对齐数的整数倍的位置上
3.结构体总的大小必须等于最大对齐数的整数倍
4.如果有结构体嵌套的情况,嵌套结构体对齐到他最大对齐数的整数倍,结构体整体大小必须对齐到整个结构体(包含嵌套结构体)的最大对齐数的整数倍处
3.计算结构体大小训练
1.
struct point
{
int a;
int b;
char c;
};
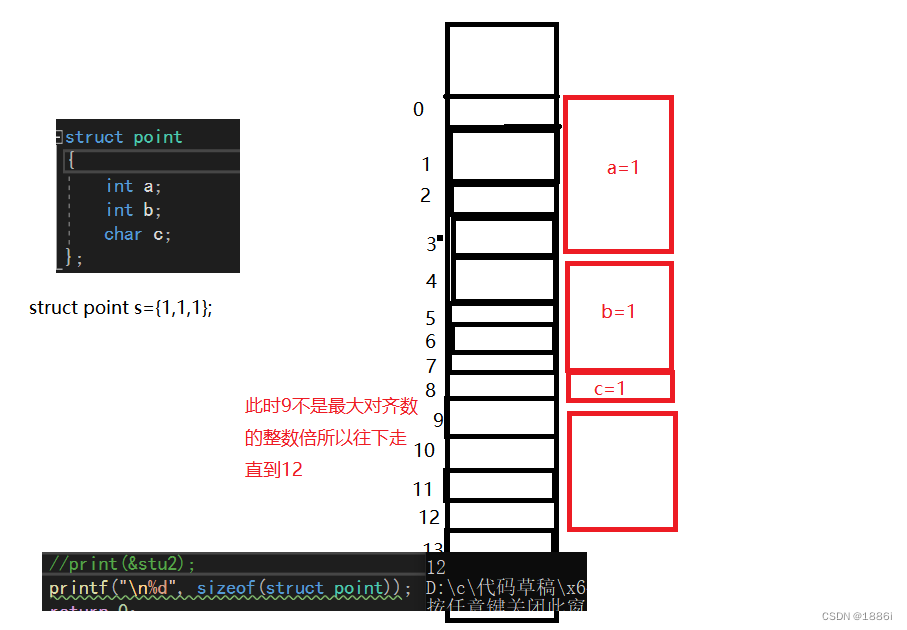
//计算该结构题大小根据上述规则一,第一个成员变量a从相对偏移量为0的位置开始存储他占4个字节,于是存到了0-3,第二个变量b根据规则2,他的对齐数是4,从对齐数的整数倍开存,接下来存储a之后偏移量来到了4是4的整数倍,开始存储占用4-7,最后是c他的对齐数是1,偏移量来的了8,于是存进去了c,接着相对偏移量到了9,但是最大对齐数是4,9不是4的整数倍,所以继续偏移,直到12,是最大偏移量的整数倍,所以这个结构体所占大小是12
2.
struct point
{
int a;
char b;
int c;
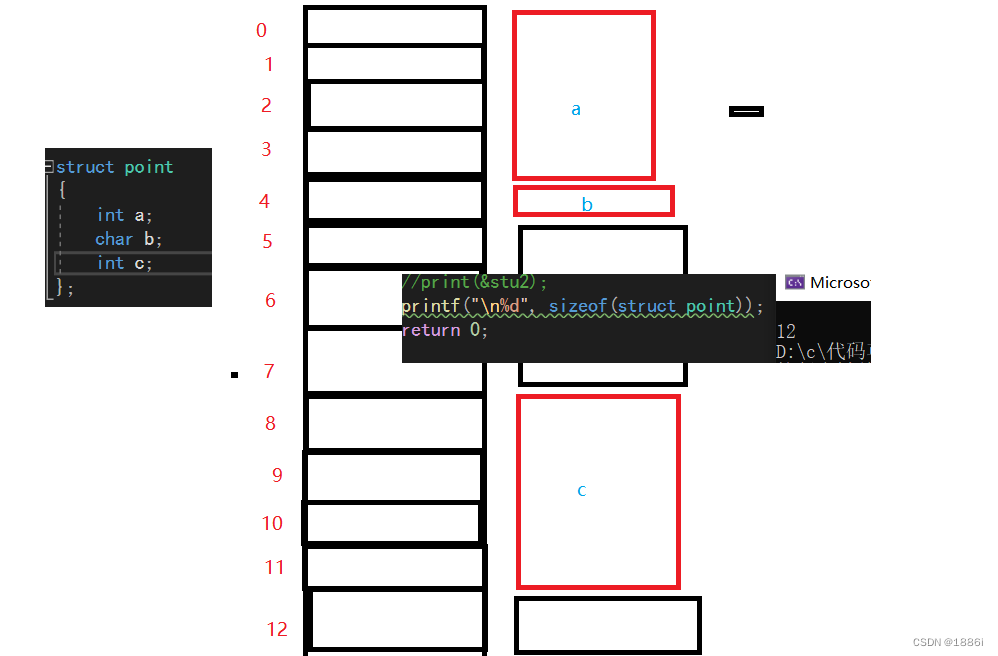
};a是第一个成员变量,存储在相对偏移量为0的位置,所以0-3存储a,接下来是b对齐数是1,于是存放到相对偏移量为4,接着c的对齐数是4,但是相对偏移量是5,不是4的整数倍,直到相对偏移量为8的时候开始存储8-11,存放c,接下来偏移量是12,是最大对齐数4的倍数,所以这个结构体大小也是12
4.内存对齐的意义
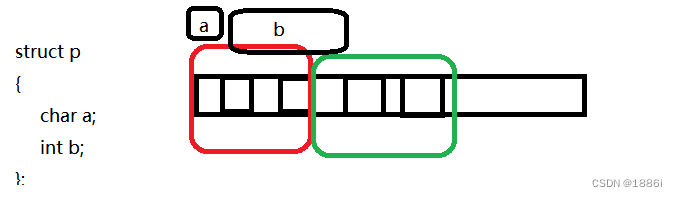
未对齐的数据访问时需要访问两次才能拿到,内存对齐相当于拿空间来换时间
对于32位的机器,如果没有对齐,再下图拿数据时,需要访问2次才能拿到b的值
三、位段
1、位段的成员要求及声明
1.位段成员变量
必须是int unsigned int ,char ,signed int,int这些
2.位段的声明
struct point
{
int a : 32;
int b : 12;
int c : 19;
};每个成员变量后跟:数字,后面数其实是所占比特位大小
2、位段的内存分配
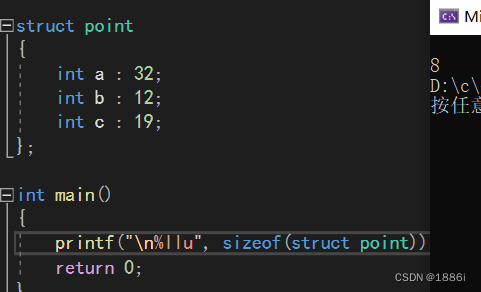
位段的跨平台性差,不同的编译器对他的内存分配不同,可移植性的代码应该避免位段的使用,在VS里,他的内存分配如下:
先给他开辟4个字节空间来放第一个成员变量,放入后,接着存放第二个数据,如果在存放第二个数据的时候之前开辟的空间不够用,就会接着再开辟4个字节,将第二个数据放在新开辟的空间里,以此类推直到存放完
在三.1.2声明里的代码所占大小是8个字节,先开辟4个字节空间存放a,接着不够了再开辟4字节存放b,之后空间足够放c,所以占8个字节
四、联合体
1、联合体的概念与声明
1.概念
变量公用一块空间
2.声明
union point
{
int a;
char i;
};
union 联合体名
{
成员变量;
};
2、联合体的内存分配
如上述代码
变量a与i公用一块空间,他也存在内存对齐
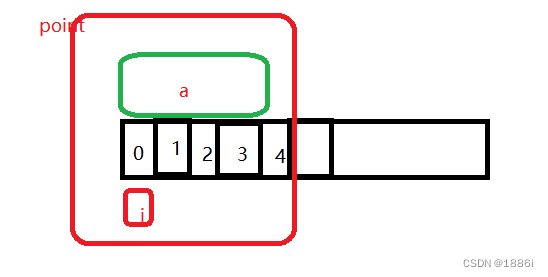
3.联合体的应用——判断大小端(面试题)

大端字节序:在存储数据时,数字的低位存储在内存的高地址,数字的高位存储在低地址
小端字节序:在存储数据时,数字的低位存储在内存的低地址,数字的高位存储在高地址
union point
{
int a;
char i;
};
int main()
{
union point s;
s.a = 1;
s.i = 0;
if (s.a==0)
{
printf("小端");
}
else
{
printf("大端");
}
return 0;
}
先给变量a赋值1,他的大小端存储方式如下图,任何给联合体里面的i赋值为0,由于他们同用一块空间,所以改变i的值时不同的存储方式,对a的值变化不同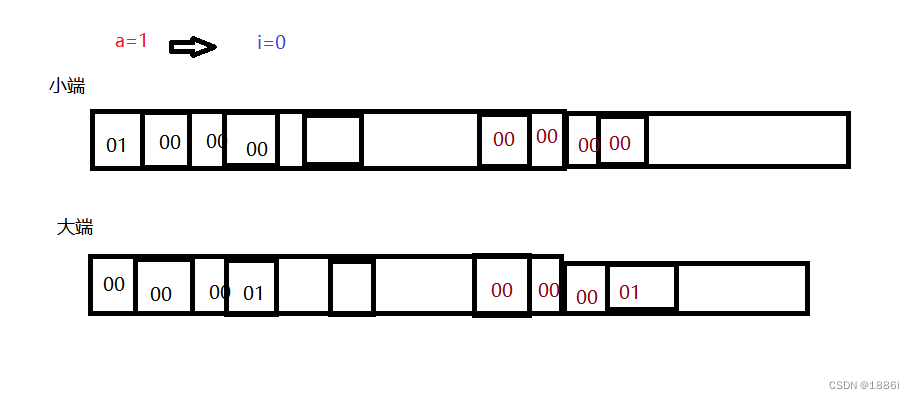
给i赋值0后可以看到小端存储方式把a的值改变成立0,而大端存储在这里没有改变,根据这一特点,我们可以通过上述代码来判断编译器的大小端
五、枚举
1、枚举的声明
enum sex
{
male,
female,
shemale
};2、枚举的使用
1.我们使用define来处理时,如果是连续的数字时我们可以使用枚举来增加程序的可读性
#define red 0
#define yellow 1
#define black 2
#define green 3
enum color
{
red,
yellow,
black,
green
};
2.switch语句时也可以使用枚举增加程序可读性
enum Function
{
Eixt,
Scoreb,
Scorex,
Scoreq,
Scoresort
};
do
{
system("cls");
printf("\t\t\t ___________________________________________________________\n");
printf("\t\t\t| |\n");
printf("\t\t\t| 0.退出 |\n");
printf("\t\t\t| 1.操作 |\n");
printf("\t\t\t| 2.操作 |\n");
printf("\t\t\t| 3.操作 |\n");
printf("\t\t\t| 4.操作 |\n");
printf("\t\t\t|___________________________________________________________|\n");
printf("\t\t请选择成绩操作:");
scanf("%d", &n);
switch (n)
{
case Scoreb:
scoreb(&class);
break;
case Scorex:
scorex(&class);
break;
case Scoreq:
scoreq(&class);
break;
case Scoresort:
scoresort(&class);
break;
case Eixt:
Eixtscore(&class);
break;
default:
_getch();
break;
}
} while (n);

















 2339
2339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











