






目录
1. 作业简介:淡水预测
1.1 问题描述
淡水是我们最重要和最稀缺的自然资源之一,仅占地球总水量的 3%。它几乎触及我们日常生活的方方面面,从饮用、游泳和沐浴到生产食物、电力和我们每天使用的产品。获得安全卫生的供水不仅对人类生活至关重要,而且对正在遭受干旱、污染和气温升高影响的周边生态系统的生存也至关重要。
在这个问题中,我们所需解决的是一个机器学习分类挑战——可非饮用水二分类问题。即,我们的任务是建立一个二分类模型,能够准确地判断采得样品是饮用水还是非饮用水。
1.2 预期解决方案
我们的目标是训练一个机器学习模型,使其在给定一组样品数据时能够准确地判断其是否为饮用水。该模型应该能够推广到从未见过的样品数据,并在测试数据上表现良好。我们期待该模型在模拟的生产环境中部署的结果——这里将推理时间和二分类准确度(F1分数)作为评分的主要依据。
1.3 使用到的Intel工具包
1. Intel-optimized Scikit-learn
使用“面向Scikit-learn的Intel扩展”,您可以加速您的Scikit-learn程序,又不影响先前有关Scikit-learn的API与算法。面向Scikit-learn的Intel扩展是一款免费的AI加速器,可在各种应用程序中提供超过10倍甚至100倍的加速。
2. Intel-optimized XGBoost
XGBoost是一个优化的分布式梯度提升库,设计为高效、灵活和便携。它在Gradient Boosting框架下实现了机器学习算法。XGBoost提供了一种并行的树提升(也称为GBDT、GBM),可以快速准确地解决许多数据科学问题。
1.4 数据集来源
这里提供一种方式下载数据集https://filerepo.idzcn.com/hack2023/datasetab75fb3.zip
2. 数据预处理
2.1 数据集结构
本项目数据集共有5956841组数据,23个特征和1个标签。
data = data.infer_objects()
data.info()
print()
# 划分各特征(离散量、连续量)
cols = data.columns
discrete_cols, continuous_cols = [], []
for col in cols: # 特征值数量统计
if data[col].value_counts().count() < 15: # 离散量
discrete_cols.append(col)
else: # 连续量
continuous_cols.append(col)
print("离散量:", discrete_cols)
print("连续量:", continuous_cols) https://filerepo.idzcn.com/hack2023/datasetab75fb3.zip
https://filerepo.idzcn.com/hack2023/datasetab75fb3.zip
2.2 数据集探索性分析
2.2.1 缺失值、重复值
对各特征的缺失值、重复值进行统计,并将结果输出。

2.2.2 特征描述性统计
查看各特征的描述性统计,包括数量、均值、标准差、最小值、25%分位数等十个统计特征。

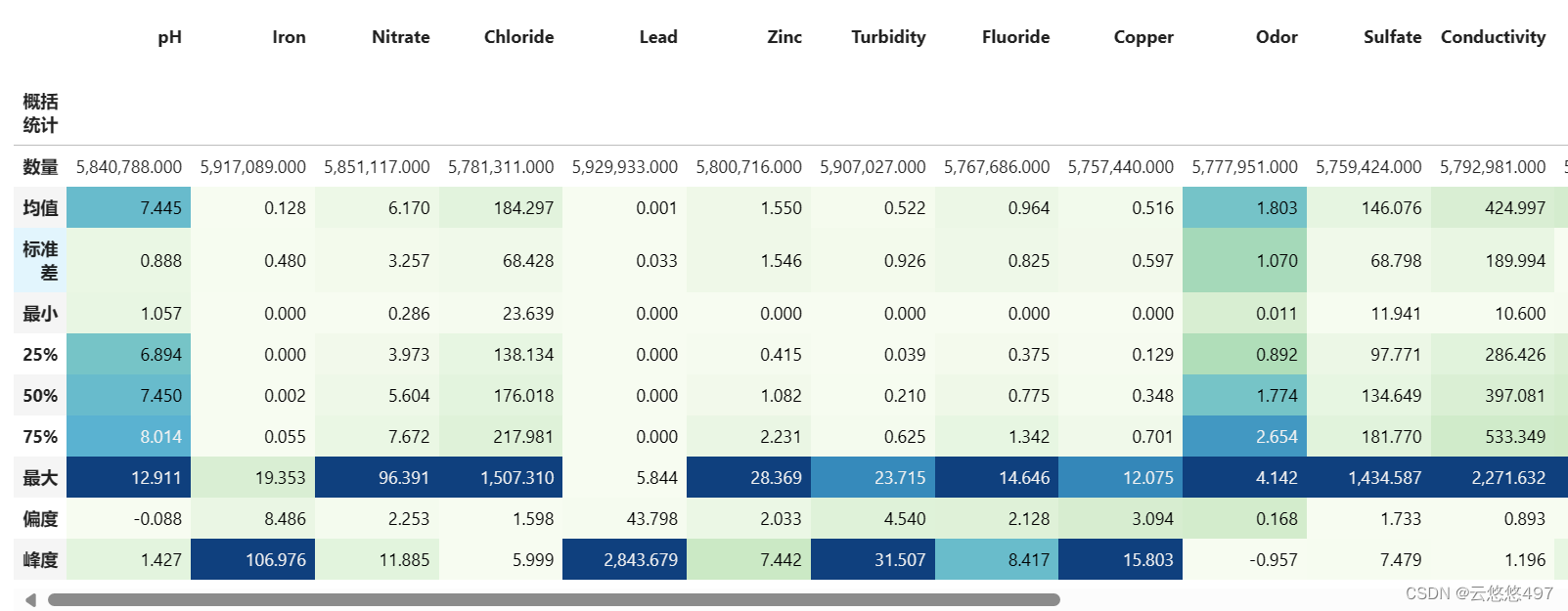
从上面可以看出,24个特征总体上都是呈现比较标准的正态分布的
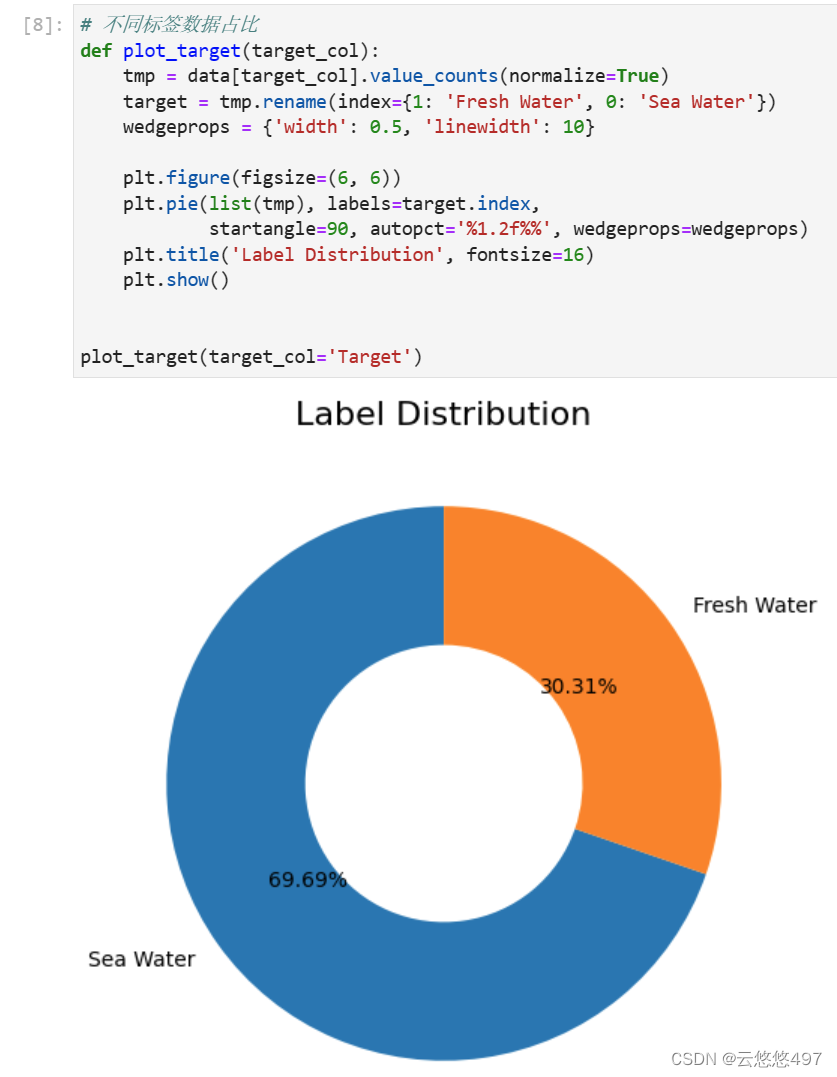
2.2.3 正负标签占比
通过将淡海水样本数量绘制成饼状图,可以直观地反映出正负样本的比例关系。
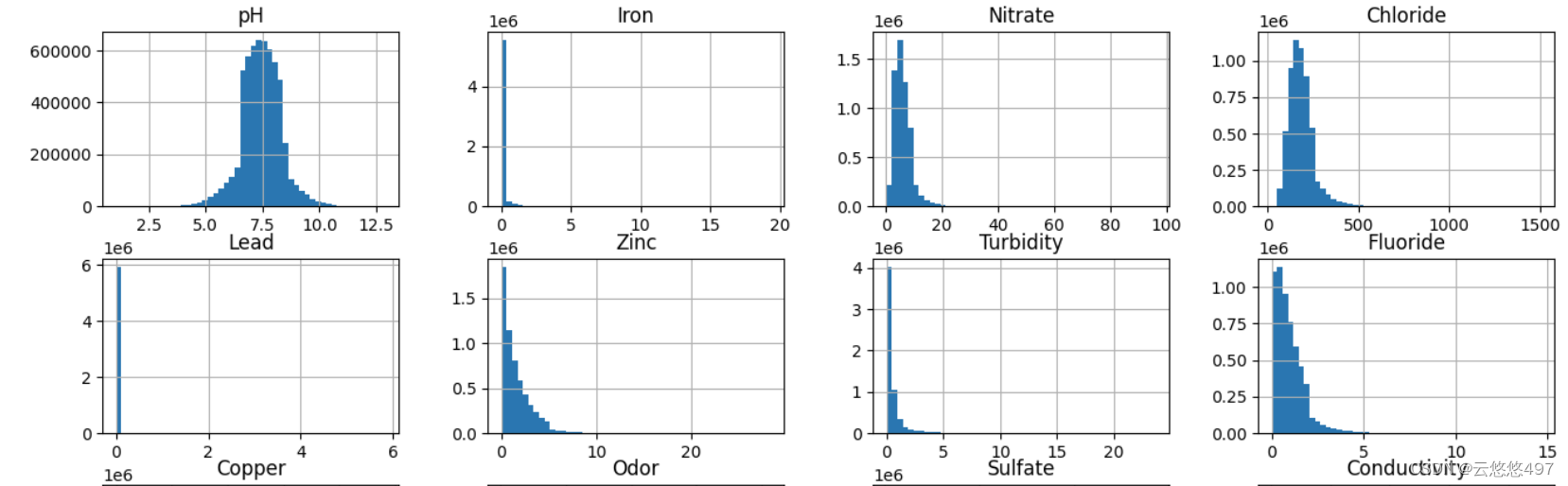
2.2.4 特征数据分布
通过绘制柱状图,可以看出各特征值在正坐标轴上的分布情况。此外,在这里排除了Index列和Target列。
2.2.5 相关系数柱状图

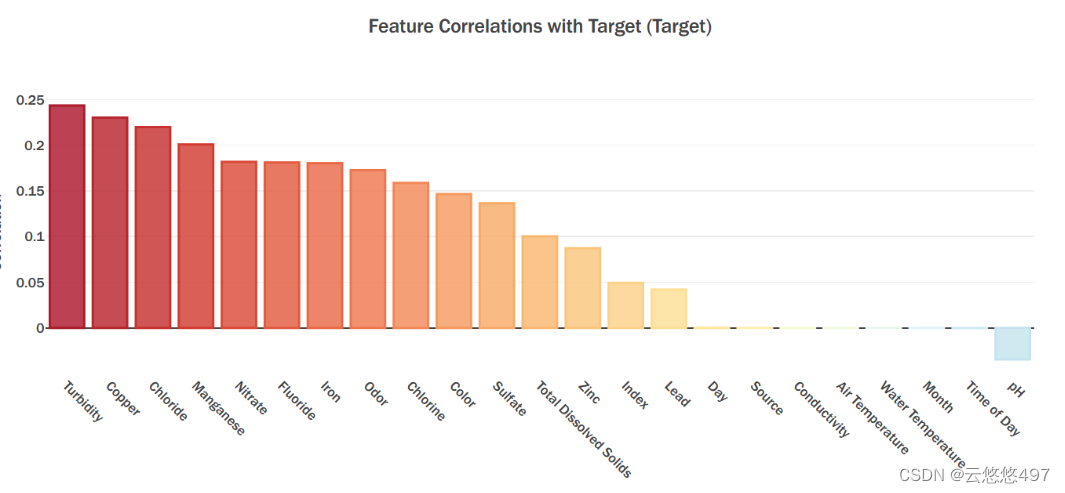
根据上图可以看出,浑浊度(Turbidity)、铜含量(Copper)、氯化物含量(Chloride)与标签有着比较强的线性关系,而采样日期(Day)、来源(Source)、导电率(Conductivity)等十个特征与标签线性关系较差甚至不存在线性关系。
2.3 数据预处理
由于存在离散量以及缺失值,我们需要进行数据预处理。此次采用的方法是,对于离散量,将其因子化,而缺失值则是用方法默认的-1将其填充;对于连续量的缺失值,则是用对应特征的中位数将其填充。实现代码如下。

3. 模型训练
为了提升模型在整个数据集上的准确率,我们采取迭代的方式,不断划分训练集与测试集,并对模型参数进行逐步优化。以下是详细的训练步骤:
- 数据集的划分:将数据集按照7:3的比例划分为训练集和测试集,确保训练数据充足且测试数据具有代表性。
- 初始化过程:为所选模型设置基本参数,并确定参数优化的范围,为后续的参数调优提供基础。
- 超参数调优:通过采用超参数调优方法,寻找能够使模型性能达到最优的一组参数组合。
- 模型评估:在每次迭代训练后,记录评估所花费的时间,并根据预测结果与实际结果计算F1分数,以评估模型的性能。
通过这一系列的迭代训练与评估过程,我们期望模型能够逐渐提升预测准确率,并在未知数据上表现出更好的泛化能力。
3.1 训练集与测试集划分
由于只有一组数据集,因此需要将该数据集拆分为训练集与测试集供模型训练。这里以7:3的比例将数据集分别拆分为训练集与测试集。

3.2 模型训练
在这里我使用了以下几个部分来提高训练的精度:
(1):网格搜索 (GridSearchCV)。在指定的参数空间内,依次尝试每一组参数,从而在参数空间中找到效果最好的一组参数。由于是一次遍历每一组参数,网格搜索得到的参数效果能得到保障。
(2):随机搜索 (RandomizedSearchCV)。与网格搜索相类似,而随机搜索在搜索时参数间隔是随机的,而非网格搜索的等间距,因而随机搜索的搜索时间更短,搜索速度更快。
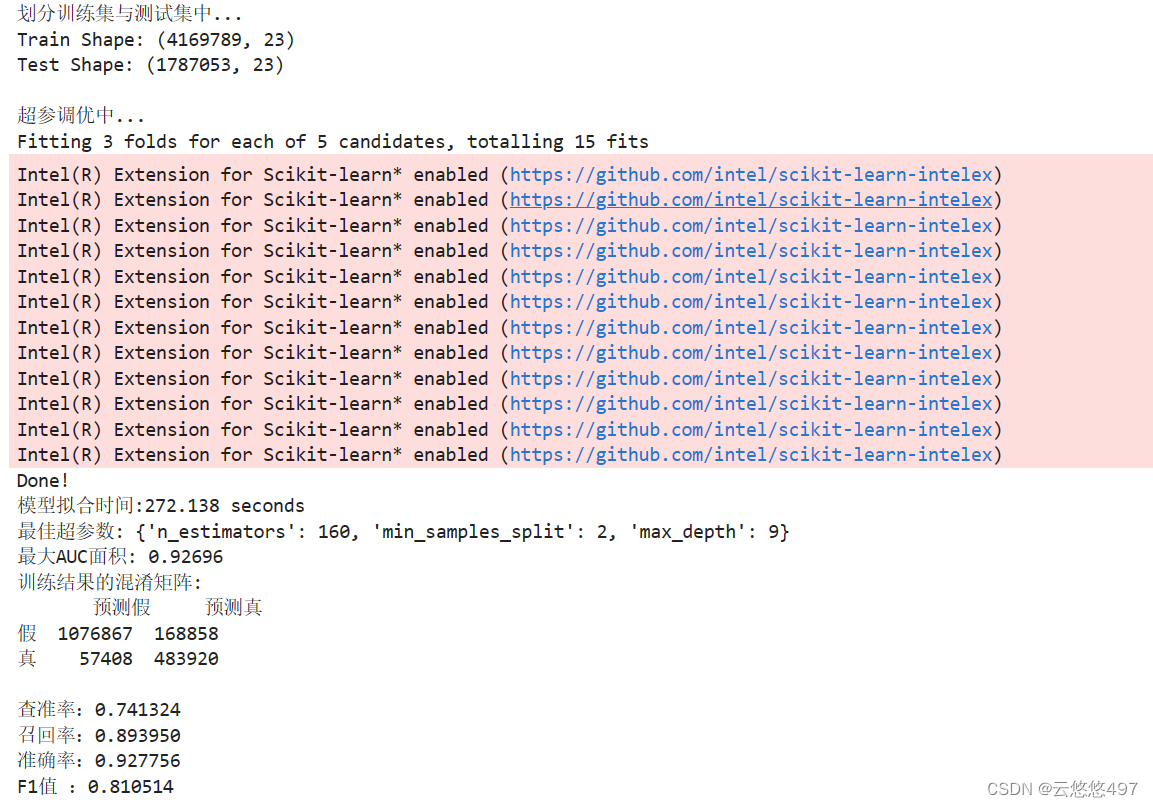
3.2.1 随机森林算法

3.2.2 XGBoost算法


3.3 小结
从训练算法上看,XGBoost算法对该数据集的训练效果更好,但模型拟合时间也更长。
4. 推理测试
4.1 随机森林算法


4.2 XGBoost算法


4.3 小结
从训练算法上看,XGBoost算法对测试集的推理速度更快,并且查准率等评估指标有更好。
5. 总结
在这次实验中,我深刻领悟到了Intel对于机器学习、深度学习以及数据分析等核心领域的库进行了精细化的优化。通过亲身实践与学习,我感受到了Intel AI Analytics Toolkit在解决理论与实践问题上的显著助力。oneAPI不仅为人工智能领域注入了新的活力,而且在机器学习和深度学习方面也表现出色,极大地简化了开发者和应用者的工作流程。















 1111
1111

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









