






代码
import math
import numpy as np
import pandas as pd
from sklearn.model_selection import KFold
spambase=pd.read_csv(r"C:\Users\hina\Desktop\spambase\spambase.data",header=None)#读取文件,没有表头要加header=None
spambasedata = np.array(spambase)
np.random.shuffle(spambasedata)#打乱顺序,数据集前半部分label全为1,后半部分全为0,如果不打乱顺序的话,会导致测试集全为0
indexs=np.arange(spambasedata.shape[0])
#划分五折交叉验证
kf=KFold(n_splits=5,shuffle=False)
data=[]
for train_index , test_index in kf.split(indexs): # 调用split方法切分数据
data.append((spambasedata[train_index], spambasedata[test_index]))
n=0
for train, test in data:#[feature1,feature2,...,label]*length
n+=1
print(f"第{n}折交叉验证")
#按照标签将训练集分类
tarin_lable0=train[train[:,-1]==0]
p0=tarin_lable0.shape[0]/train.shape[0]#P(lable=0)
tarin_lable1=train[train[:,-1]==1]
p1=tarin_lable1.shape[0]/train.shape[0]#P(lable=1)
print("训练集中01分别占的比例(概率)为",p0,p1)
#计算每一列的均值和方差
mean0=np.mean(tarin_lable0[:,:-1],axis=0)
std0=np.std(tarin_lable0[:,:-1],axis=0)+1e-10
mean1=np.mean(tarin_lable1[:,:-1],axis=0)
std1=np.std(tarin_lable1[:,:-1],axis=0)+1e-10#加上一个很小平滑值,防止方差为0
#计算每一列的概率密度函数
def gaussian_probability(x, mean, stdev):
exponent = math.exp(-(math.pow(x - mean, 2) / (2 * math.pow(stdev, 2))))
return (1 / (math.sqrt(2 * math.pi) * stdev)) * exponent
#计算测试集的预测值
pred=[]
for data in test:#[feature1,feature2,...,label]
p0_x=1
p1_x=1
for i in range(len(data)-1):
p0_x*=gaussian_probability(data[i],mean0[i],std0[i])
p1_x*=gaussian_probability(data[i],mean1[i],std1[i])
if p0_x*p0>p1_x*p1:
pred.append(0)
else:
pred.append(1)
print("前20个预测结果与真实值比较:","\n",pred[:20],"\n",test[:,-1][:20])
print("准确率:",(pred==test[:,-1]).sum()/test.shape[0])
理论
https://blog.csdn.net/u013066730/article/details/125821190
单个特征对应概率
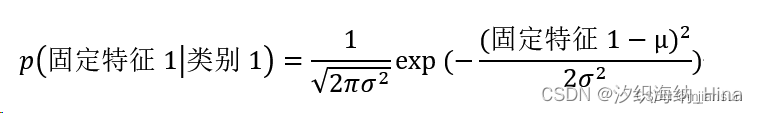
对应代码
def gaussian_probability(x, mean, stdev):
exponent = math.exp(-(math.pow(x - mean, 2) / (2 * math.pow(stdev, 2))))
return (1 / (math.sqrt(2 * math.pi) * stdev)) * exponent
将所有特征的概率相乘,除以相应类别的概率,即为预测的分为该类别的概率

p0_x=1
p1_x=1
for i in range(len(data)-1):
p0_x*=gaussian_probability(data[i],mean0[i],std0[i])
p1_x*=gaussian_probability(data[i],mean1[i],std1[i])
取所有类别概率最大值即为预测结果
求方差时注意要给一个平滑值,否则方差为0会出现除0错误
#计算每一列的均值和方差
mean0=np.mean(tarin_lable0[:,:-1],axis=0)
std0=np.std(tarin_lable0[:,:-1],axis=0)+1e-10
mean1=np.mean(tarin_lable1[:,:-1],axis=0)
std1=np.std(tarin_lable1[:,:-1],axis=0)+1e-10#加上一个很小平滑值,防止方差为0
代码输出
第1折交叉验证
训练集中01分别占的比例(概率)为 0.6021739130434782 0.3978260869565217
前20个预测结果与真实值比较:
[0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 1, 1, 0, 1, 0, 0, 0, 1, 1, 1]
[0. 0. 0. 1. 1. 1. 1. 0. 1. 0. 1. 1. 0. 0. 0. 0. 0. 1. 1. 1.]
准确率: 0.8241042345276873
第2折交叉验证
训练集中01分别占的比例(概率)为 0.6085302906818799 0.3914697093181201
前20个预测结果与真实值比较:
[1, 1, 1, 0, 0, 1, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 0]
[1. 0. 1. 0. 0. 1. 0. 0. 1. 1. 0. 0. 0. 0. 0. 0. 1. 1. 1. 0.]
准确率: 0.8130434782608695
第3折交叉验证
训练集中01分别占的比例(概率)为 0.6047269763651182 0.3952730236348818
前20个预测结果与真实值比较:
[1, 1, 1, 1, 1, 1, 0, 1, 0, 1, 0, 1, 1, 1, 1, 1, 0, 1, 0, 0]
[1. 1. 1. 1. 0. 1. 0. 0. 0. 1. 0. 1. 1. 1. 0. 0. 0. 0. 0. 0.]
准确率: 0.8108695652173913
第4折交叉验证
训练集中01分别占的比例(概率)为 0.6052703069817984 0.3947296930182016
前20个预测结果与真实值比较:
[1, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 1, 1, 1, 0]
[0. 0. 0. 0. 0. 0. 0. 0. 1. 0. 1. 0. 0. 0. 1. 0. 1. 1. 1. 0.]
准确率: 0.8141304347826087
第5折交叉验证
训练集中01分别占的比例(概率)为 0.6090736212985601 0.3909263787014398
前20个预测结果与真实值比较:
[1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 1, 0, 0, 0, 1, 1]
[1. 0. 1. 0. 0. 0. 1. 1. 1. 1. 0. 0. 0. 0. 1. 0. 0. 0. 1. 1.]
准确率: 0.8076086956521739
(全部预测1准确率也有0.6,贝叶斯预测准确率只有0.8,还是得用深度学习)














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









