







Uthread: switching between threads (moderate)
In this exercise you will design the context switch mechanism for a user-level threading system, and then implement it. To get you started, your xv6 has two files user/uthread.c and user/uthread_switch.S, and a rule in the Makefile to build a uthread program. uthread.c contains most of a user-level threading package, and code for three simple test threads. The threading package is missing some of the code to create a thread and to switch between threads.
在本练习中,您将为用户级线程系统设计上下文切换机制,然后实现它。为了让您开始,您的xv6有两个文件:user/uthread.c和user/uthread_switch.S,以及一个规则:运行在Makefile中以构建uthread程序。uthread.c包含大多数用户级线程包,以及三个简单测试线程的代码。线程包缺少一些用于创建线程和在线程之间切换的代码。
Your job is to come up with a plan to create threads and save/restore registers to switch between threads, and implement that plan. When you’re done, make grade should say that your solution passes the uthread test.
您的工作是提出一个创建线程和保存/恢复寄存器以在线程之间切换的计划,并实现该计划。完成后,make grade应该表明您的解决方案通过了uthread测试。
Once you’ve finished, you should see the following output when you run uthread on xv6 (the three threads might start in a different order):
完成后,在xv6上运行uthread时应该会看到以下输出(三个线程可能以不同的顺序启动):
$ make qemu
...
$ uthread
thread_a started
thread_b started
thread_c started
thread_c 0
thread_a 0
thread_b 0
thread_c 1
thread_a 1
thread_b 1
...
thread_c 99
thread_a 99
thread_b 99
thread_c: exit after 100
thread_a: exit after 100
thread_b: exit after 100
thread_schedule: no runnable threads
$
This output comes from the three test threads, each of which has a loop that prints a line and then yields the CPU to the other threads.
该输出来自三个测试线程,每个线程都有一个循环,该循环打印一行,然后将CPU让出给其他线程。
At this point, however, with no context switch code, you’ll see no output.
然而在此时还没有上下文切换的代码,您将看不到任何输出。
You will need to add code to thread_create() and thread_schedule() in user/uthread.c, and thread_switch in user/uthread_switch.S. One goal is ensure that when thread_schedule() runs a given thread for the first time, the thread executes the function passed to thread_create(), on its own stack. Another goal is to ensure that thread_switch saves the registers of the thread being switched away from, restores the registers of the thread being switched to, and returns to the point in the latter thread’s instructions where it last left off. You will have to decide where to save/restore registers; modifying struct thread to hold registers is a good plan. You’ll need to add a call to thread_switch in thread_schedule; you can pass whatever arguments you need to thread_switch, but the intent is to switch from thread t to next_thread.
您需要将代码添加到user/uthread.c中的thread_create()和thread_schedule(),以及user/uthread_switch.S中的thread_switch。一个目标是确保当thread_schedule()第一次运行给定线程时,该线程在自己的栈上执行传递给thread_create()的函数。另一个目标是确保thread_switch保存被切换线程的寄存器,恢复切换到线程的寄存器,并返回到后一个线程指令中最后停止的点。您必须决定保存/恢复寄存器的位置;修改struct thread以保存寄存器是一个很好的计划。您需要在thread_schedule中添加对thread_switch的调用;您可以将需要的任何参数传递给thread_switch,但目的是将线程从t切换到next_thread。
在线程中保存上下文信息,切换线程时将新线程的上下文写入寄存器中。
struct context {
uint64 ra;
uint64 sp;
// callee-saved
uint64 s0;
uint64 s1;
uint64 s2;
uint64 s3;
uint64 s4;
uint64 s5;
uint64 s6;
uint64 s7;
uint64 s8;
uint64 s9;
uint64 s10;
uint64 s11;
};
struct thread {
char stack[STACK_SIZE]; /* the thread's stack */
int state; /* FREE, RUNNING, RUNNABLE */
struct context context;
};
void
thread_create(void (*func)())
{
struct thread *t;
for (t = all_thread; t < all_thread + MAX_THREAD; t++) {
if (t->state == FREE) break;
}
t->state = RUNNABLE;
// YOUR CODE HERE
t->context.ra = (uint64)func;
t->context.sp = (uint64)t->stack + STACK_SIZE - 1;//栈底是高地址
}
void
thread_schedule(void)
{
struct thread *t, *next_thread;
/* Find another runnable thread. */
next_thread = 0;
t = current_thread + 1;
for(int i = 0; i < MAX_THREAD; i++){
if(t >= all_thread + MAX_THREAD)
t = all_thread;
if(t->state == RUNNABLE) {
next_thread = t;
break;
}
t = t + 1;
}
if (next_thread == 0) {
printf("thread_schedule: no runnable threads\n");
exit(-1);
}
if (current_thread != next_thread) { /* switch threads? */
next_thread->state = RUNNING;
t = current_thread;
current_thread = next_thread;
/* YOUR CODE HERE
* Invoke thread_switch to switch from t to next_thread:
* thread_switch(??, ??);
*/
thread_switch((uint64)&t->context, (uint64)&next_thread->context);
} else
next_thread = 0;
}
Some hints:
提示:
thread_switch needs to save/restore only the callee-save registers. Why?
thread_switch只需要保存/还原被调用方保存的寄存器(callee-save register,参见LEC5使用的文档《Calling Convention》)。为什么?
内核调度器无论是通过时钟中断进入(usertrap),还是线程自己主动放弃 CPU(sleep、exit),最终都会调用到 yield 进一步调用 swtch。
由于上下文切换永远都发生在函数调用的边界(swtch 调用的边界),恢复执行相当于是 swtch 的返回过程,会从堆栈中恢复 caller-saved 的寄存器,
所以用于保存上下文的 context 结构体只需保存 callee-saved 寄存器,以及 返回地址 ra、栈指针 sp 即可。恢复后执行到哪里是通过 ra 寄存器来决定的(swtch 末尾的 ret 转跳到 ra)
而 trapframe 则不同,一个中断可能在任何地方发生,不仅仅是函数调用边界,也有可能在函数执行中途,所以恢复的时候需要靠 pc 寄存器来定位。
并且由于切换位置不一定是函数调用边界,所以几乎所有的寄存器都要保存(无论 caller-saved 还是 callee-saved),才能保证正确的恢复执行。
这也是内核代码中 struct trapframe 中保存的寄存器比 struct context 多得多的原因。
另外一个,无论是程序主动 sleep,还是时钟中断,都是通过 trampoline 跳转到内核态 usertrap(保存 trapframe),然后再到达 swtch 保存上下文的。
恢复上下文都是恢复到 swtch 返回前(依然是内核态),然后返回跳转回 usertrap,再继续运行直到 usertrapret 跳转到 trampoline 读取 trapframe,并返回用户态。
也就是上下文恢复并不是直接恢复到用户态,而是恢复到内核态 swtch 刚执行完的状态。负责恢复用户态执行流的其实是 trampoline 以及 trapframe。
作者:Miigon
链接:https://juejin.cn/post/7016228101717753886
来源:稀土掘金
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Using threads (moderate)
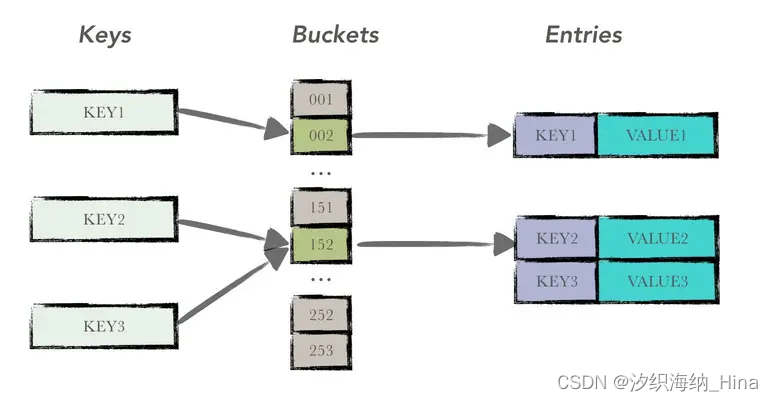
先聊一下ph.c中的NBUCKET,这里为解决哈希冲突问题使用的方法是哈希桶,NBUCKET=5,对应的哈希桶有五个key,每个key对应一个链表,即struct entry *table[NBUCKET];,往哈希桶中插入值时,先找到value对应的key,再添加到链表末端。
In this assignment you will explore parallel programming with threads and locks using a hash table. You should do this assignment on a real Linux or MacOS computer (not xv6, not qemu) that has multiple cores. Most recent laptops have multicore processors.
在本作业中,您将探索使用哈希表的线程和锁的并行编程。您应该在具有多个内核的真实Linux或MacOS计算机(不是xv6,不是qemu)上执行此任务。最新的笔记本电脑都有多核处理器。
This assignment uses the UNIX pthread threading library. You can find information about it from the manual page, with man pthreads, and you can look on the web, for example here, here, and here.
这个作业使用UNIX的pthread线程库。您可以使用man pthreads在手册页面上找到关于它的信息,您可以在web上查看,例如这里、这里和这里。
The file notxv6/ph.c contains a simple hash table that is correct if used from a single thread, but incorrect when used from multiple threads. In your main xv6 directory (perhaps ~/xv6-labs-2021), type this:
文件notxv6/ph.c包含一个简单的哈希表,如果单个线程使用,该哈希表是正确的,但是多个线程使用时,该哈希表是不正确的。在您的xv6主目录(可能是~/xv6-labs-2020)中,键入以下内容:
$ make ph
$ ./ph 1
Note that to build ph the Makefile uses your OS’s gcc, not the 6.S081 tools. The argument to ph specifies the number of threads that execute put and get operations on the the hash table. After running for a little while, ph 1 will produce output similar to this:
请注意,要构建ph,Makefile使用操作系统的gcc,而不是6.S081的工具。ph的参数指定在哈希表上执行put和get操作的线程数。运行一段时间后,ph 1将产生与以下类似的输出:
100000 puts, 3.991 seconds, 25056 puts/second
0: 0 keys missing
100000 gets, 3.981 seconds, 25118 gets/second
The numbers you see may differ from this sample output by a factor of two or more, depending on how fast your computer is, whether it has multiple cores, and whether it’s busy doing other things.
您看到的数字可能与此示例输出的数字相差两倍或更多,这取决于您计算机的速度、是否有多个核心以及是否正在忙于做其他事情。
ph runs two benchmarks. First it adds lots of keys to the hash table by calling put(), and prints the achieved rate in puts per second. The it fetches keys from the hash table with get(). It prints the number keys that should have been in the hash table as a result of the puts but are missing (zero in this case), and it prints the number of gets per second it achieved.
ph运行两个基准程序。首先,它通过调用put()将许多键添加到哈希表中,并以每秒为单位打印puts的接收速率。之后它使用get()从哈希表中获取键。它打印由于puts而应该在哈希表中但丢失的键的数量(在本例中为0),并以每秒为单位打印gets的接收数量。
You can tell ph to use its hash table from multiple threads at the same time by giving it an argument greater than one. Try ph 2:
通过给ph一个大于1的参数,可以告诉它同时从多个线程使用其哈希表。试试ph 2:
$ ./ph 2
100000 puts, 1.885 seconds, 53044 puts/second
1: 16579 keys missing
0: 16579 keys missing
200000 gets, 4.322 seconds, 46274 gets/second
The first line of this ph 2 output indicates that when two threads concurrently add entries to the hash table, they achieve a total rate of 53,044 inserts per second. That’s about twice the rate of the single thread from running ph 1. That’s an excellent “parallel speedup” of about 2x, as much as one could possibly hope for (i.e. twice as many cores yielding twice as much work per unit time).
这个ph 2输出的第一行表明,当两个线程同时向哈希表添加条目时,它们达到每秒53044次插入的总速率。这大约是运行ph 1的单线程速度的两倍。这是一个优秀的“并行加速”,大约达到了人们希望的2倍(即两倍数量的核心每单位时间产出两倍的工作)。
However, the two lines saying 16579 keys missing indicate that a large number of keys that should have been in the hash table are not there. That is, the puts were supposed to add those keys to the hash table, but something went wrong. Have a look at notxv6/ph.c, particularly at put() and insert().
然而,声明16579 keys missing的两行表示散列表中本应存在的大量键不存在。也就是说,puts应该将这些键添加到哈希表中,但出现了一些问题。请看一下notxv6/ph.c,特别是put()和insert()。
Why are there missing keys with 2 threads, but not with 1 thread? Identify a sequence of events with 2 threads that can lead to a key being missing. Submit your sequence with a short explanation in answers-thread.txt
为什么两个线程都丢失了键,而不是一个线程?确定可能导致键丢失的具有2个线程的事件序列。在answers-thread.txt中提交您的序列和简短解释。
To avoid this sequence of events, insert lock and unlock statements in put and get in notxv6/ph.c so that the number of keys missing is always 0 with two threads. The relevant pthread calls are:
为了避免这种事件序列,请在notxv6/ph.c中的put和get中插入lock和unlock语句,以便在两个线程中丢失的键数始终为0。相关的pthread调用包括:
pthread_mutex_t lock; // declare a lock
pthread_mutex_init(&lock, NULL); // initialize the lock
pthread_mutex_lock(&lock); // acquire lock
pthread_mutex_unlock(&lock); // release lock
参考之前对哈希桶的解释,int i = key % NBUCKET;,i即为桶的编号,之后将操作这个桶,故在操作之前给桶加锁即可,对桶(table)操作完成后即可释放锁。
pthread_mutex_t locks[NBUCKET];
static
void put(int key, int value)
{
int i = key % NBUCKET;
pthread_mutex_lock(&locks[i]);
// is the key already present?
struct entry *e = 0;
for (e = table[i]; e != 0; e = e->next) {
if (e->key == key)
break;
}
if(e){
// update the existing key.
e->value = value;
} else {
// the new is new.
insert(key, value, &table[i], table[i]);
}
pthread_mutex_unlock(&locks[i]);
}
static struct entry*
get(int key)
{
int i = key % NBUCKET;
pthread_mutex_lock(&locks[i]);
struct entry *e = 0;
for (e = table[i]; e != 0; e = e->next) {
if (e->key == key) break;
}
pthread_mutex_unlock(&locks[i]);
return e;
}
int
main(int argc, char *argv[])
{
...
for(int i = 0; i < NBUCKET; i++)
pthread_mutex_init(locks+i, NULL) == 0;
...
}
You’re done when make grade says that your code passes the ph_safe test, which requires zero missing keys with two threads. It’s OK at this point to fail the ph_fast test.
当make grade说您的代码通过ph_safe测试时,您就完成了,该测试需要两个线程的键缺失数为0。在此时,ph_fast测试失败是正常的。
Don’t forget to call pthread_mutex_init(). Test your code first with 1 thread, then test it with 2 threads. Is it correct (i.e. have you eliminated missing keys?)? Does the two-threaded version achieve parallel speedup (i.e. more total work per unit time) relative to the single-threaded version?
不要忘记调用pthread_mutex_init()。首先用1个线程测试代码,然后用2个线程测试代码。您主要需要测试:程序运行是否正确呢(即,您是否消除了丢失的键?)?与单线程版本相比,双线程版本是否实现了并行加速(即单位时间内的工作量更多)?
但是不写init好像也不会出问题(
There are situations where concurrent put()s have no overlap in the memory they read or write in the hash table, and thus don’t need a lock to protect against each other. Can you change ph.c to take advantage of such situations to obtain parallel speedup for some put()s? Hint: how about a lock per hash bucket?
在某些情况下,并发put()在哈希表中读取或写入的内存中没有重叠,因此不需要锁来相互保护。您能否更改ph.c以利用这种情况为某些put()获得并行加速?提示:每个散列桶加一个锁怎么样?
Modify your code so that some put operations run in parallel while maintaining correctness. You’re done when make grade says your code passes both the ph_safe and ph_fast tests. The ph_fast test requires that two threads yield at least 1.25 times as many puts/second as one thread.
修改代码,使某些put操作在保持正确性的同时并行运行。当make grade说你的代码通过了ph_safe和ph_fast测试时,你就完成了。ph_fast测试要求两个线程每秒产生的put数至少是一个线程的1.25倍。
Barrier(moderate)
In this assignment you’ll implement a barrier: a point in an application at which all participating threads must wait until all other participating threads reach that point too. You’ll use pthread condition variables, which are a sequence coordination technique similar to xv6’s sleep and wakeup.
在本作业中,您将实现一个屏障)(Barrier):应用程序中的一个点,所有参与的线程在此点上必须等待,直到所有其他参与线程也达到该点。您将使用pthread条件变量,这是一种序列协调技术,类似于xv6的sleep和wakeup。
屏障是什么?
来自维基百科,自由的百科全书
In parallel computing, a barrier is a type of synchronization method. A barrier for a group of threads or processes in the source code means any thread/process must stop at this point and cannot proceed until all other threads/processes reach this barrier.
在并行计算中,屏障是一种同步方法。源代码中一组线程或进程的障碍意味着任何线程/进程都必须在此时停止,并且在所有其他线程/进程达到此障碍之前无法继续。
Implementation 实现
The basic barrier has mainly two variables, one of which records the pass/stop state of the barrier, the other of which keeps the total number of threads that have entered in the barrier. The barrier state was initialized to be “stop” by the first threads coming into the barrier. Whenever a thread enters, based on the number of threads already in the barrier, only if it is the last one, the thread sets the barrier state to be “pass” so that all the threads can get out of the barrier. On the other hand, when the incoming thread is not the last one, it is trapped in the barrier and keeps testing if the barrier state has changed from “stop” to “pass”, and it gets out only when the barrier state changes to “pass”. The following C++ code demonstrates this procedure.[1][2]
基本屏障主要有两个变量,一个变量记录屏障的通过/停止状态,另一个变量保留已进入屏障的线程总数。屏障状态被第一个进入屏障的线程初始化为“停止”。每当线程进入时,根据屏障中已有的线程数,只有当它是最后一个线程时,线程才会将屏障状态设置为“通过”,以便所有线程都可以离开屏障。另一方面,当传入的线程不是最后一个线程时,它被困在屏障中,并不断测试屏障状态是否从“停止”变为“通过”,只有当屏障状态变为“通过”时才会脱落。
You should do this assignment on a real computer (not xv6, not qemu).
您应该在真正的计算机(不是xv6,不是qemu)上完成此任务。
The file notxv6/barrier.c contains a broken barrier.
文件notxv6/barrier.c包含一个残缺的屏障实现。
$ make barrier
$ ./barrier 2
barrier: notxv6/barrier.c:42: thread: Assertion `i == t' failed.
The 2 specifies the number of threads that synchronize on the barrier ( nthread in barrier.c). Each thread executes a loop. In each loop iteration a thread calls barrier() and then sleeps for a random number of microseconds. The assert triggers, because one thread leaves the barrier before the other thread has reached the barrier. The desired behavior is that each thread blocks in barrier() until all nthreads of them have called barrier().
2指定在屏障上同步的线程数(barrier.c中的nthread)。每个线程执行一个循环。在每次循环迭代中,线程都会调用barrier(),然后以随机微秒数休眠。如果一个线程在另一个线程到达屏障之前离开屏障将触发断言(assert)。期望的行为是每个线程在barrier()中阻塞,直到nthreads的所有线程都调用了barrier()。
Your goal is to achieve the desired barrier behavior. In addition to the lock primitives that you have seen in the ph assignment, you will need the following new pthread primitives; look here and here for details.
您的目标是实现期望的屏障行为。除了在ph作业中看到的lock原语外,还需要以下新的pthread原语;详情请看这里和这里。
pthread_cond_wait(&cond, &mutex); // go to sleep on cond, releasing lock mutex, acquiring upon wake up在cond上进入睡眠,释放锁mutex,在醒来时重新获取
pthread_cond_broadcast(&cond); // wake up every thread sleeping on cond唤醒睡在cond的所有线程
static void
barrier()
{
// YOUR CODE HERE
// 线程进入同步屏障 barrier 时,将已进入屏障的线程数量增加 1,然后再判断是否已经达到总线程数。如果未达到,则进入睡眠,等待其他线程。
// Block until all threads have called barrier() and
// then increment bstate.round.
//
pthread_mutex_lock(&bstate.barrier_mutex);
if(++bstate.nthread < nthread) {
pthread_cond_wait(&bstate.barrier_cond, &bstate.barrier_mutex);
} else {
bstate.nthread = 0;
bstate.round++;
pthread_cond_broadcast(&bstate.barrier_cond);
}
pthread_mutex_unlock(&bstate.barrier_mutex);
}
Make sure your solution passes make grade’s barrier test.
确保您的方案通过make grade的barrier测试。
pthread_cond_wait releases the mutex when called, and re-acquires the mutex before returning.
pthread_cond_wait在调用时释放mutex,并在返回前重新获取mutex。
We have given you barrier_init(). Your job is to implement barrier() so that the panic doesn’t occur. We’ve defined struct barrier for you; its fields are for your use.我们已经为您提供了barrier_init()。
您的工作是实现barrier(),这样panic就不会发生。我们为您定义了struct barrier;它的字段供您使用。
There are two issues that complicate your task:
有两个问题使您的任务变得复杂:
You have to deal with a succession of barrier calls, each of which we’ll call a round. bstate.round records the current round. You should increment bstate.round each time all threads have reached the barrier.
你必须处理一系列的barrier调用,我们称每一连串的调用为一轮(round)。bstate.round记录当前轮数。每次当所有线程都到达屏障时,都应增加bstate.round。
You have to handle the case in which one thread races around the loop before the others have exited the barrier. In particular, you are re-using the bstate.nthread variable from one round to the next. Make sure that a thread that leaves the barrier and races around the loop doesn’t increase bstate.nthread while a previous round is still using it.
您必须处理这样的情况:一个线程在其他线程退出barrier之前进入了下一轮循环。特别是,您在前后两轮中重复使用bstate.nthread变量。确保在前一轮仍在使用bstate.nthread时,离开barrier并循环运行的线程不会增加bstate.nthread。
Test your code with one, two, and more than two threads.
使用一个、两个和两个以上的线程测试代码。















 2753
2753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









