






对于该芯片,我们使用的神经网络为AOD_net,输入特征图为640*480大小,位宽为8,是一个8位二进制数,范围为0-255,但在实际设计过程中,由于芯片面积的限制,我们精修了部分网络,并通过软件验证与原模型得出的结果误差小于百分之1,以下是我们设计时所使用的最终网络模型
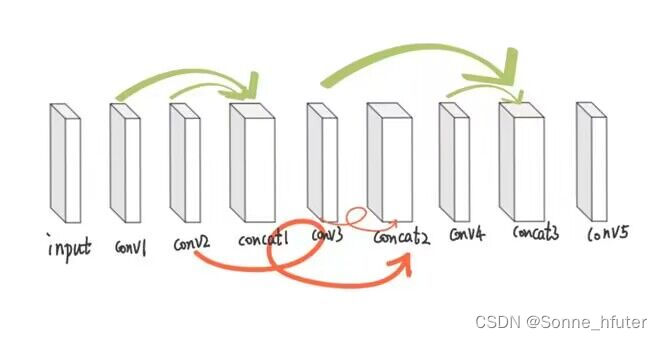
接下来我们介绍卷积层conv2的Verilog代码实现(已通过软件计算验证),第二层卷积层为3*3*3的kernel_size(3通道),对于整个卷积层,使用组内焦文博学长的卷积层设计思路和设计代码做一个详解,方便自己理解和学习,接下来是整个conv的模块连接思路(较为简洁)
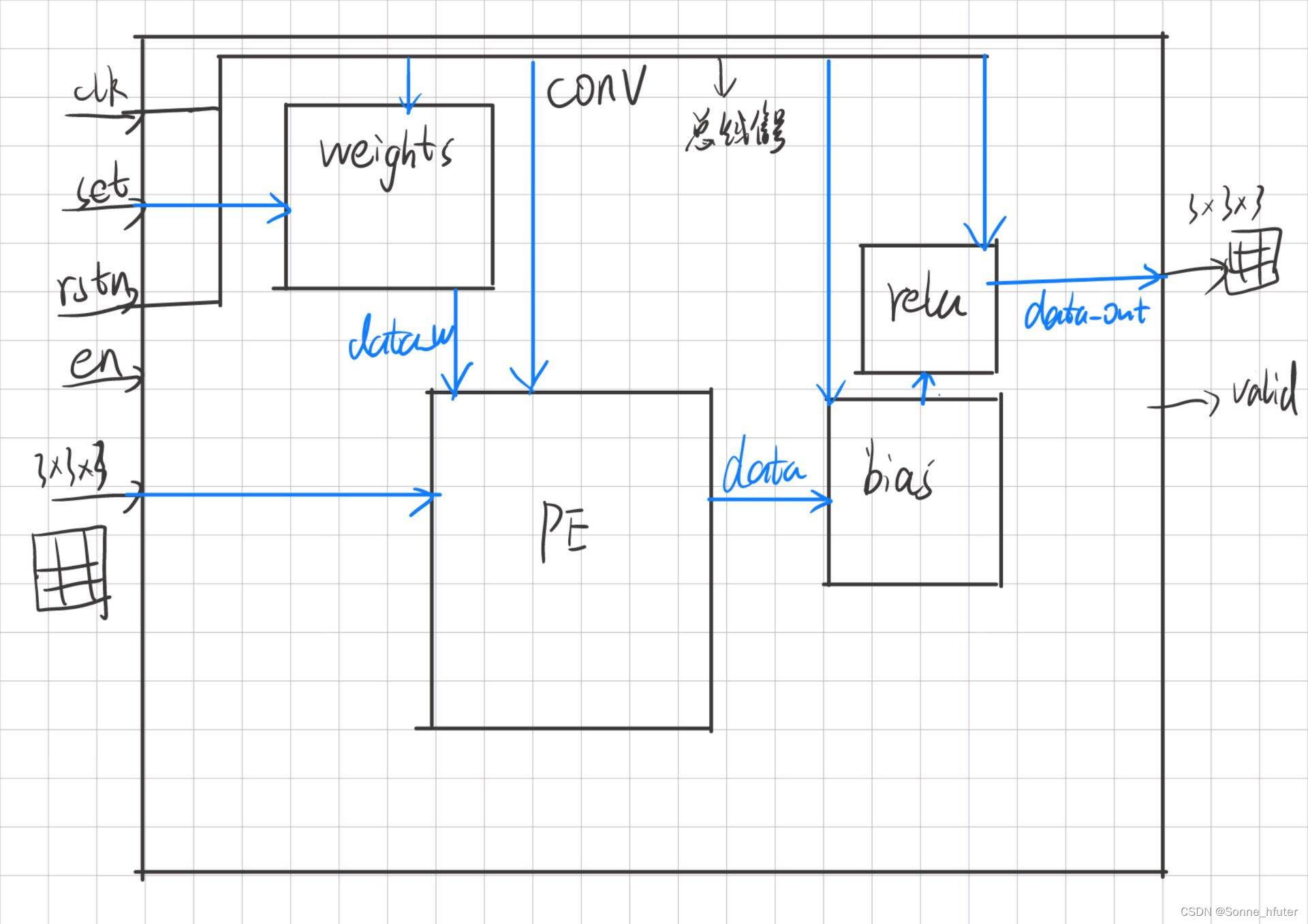
下方为conv的状态机思路
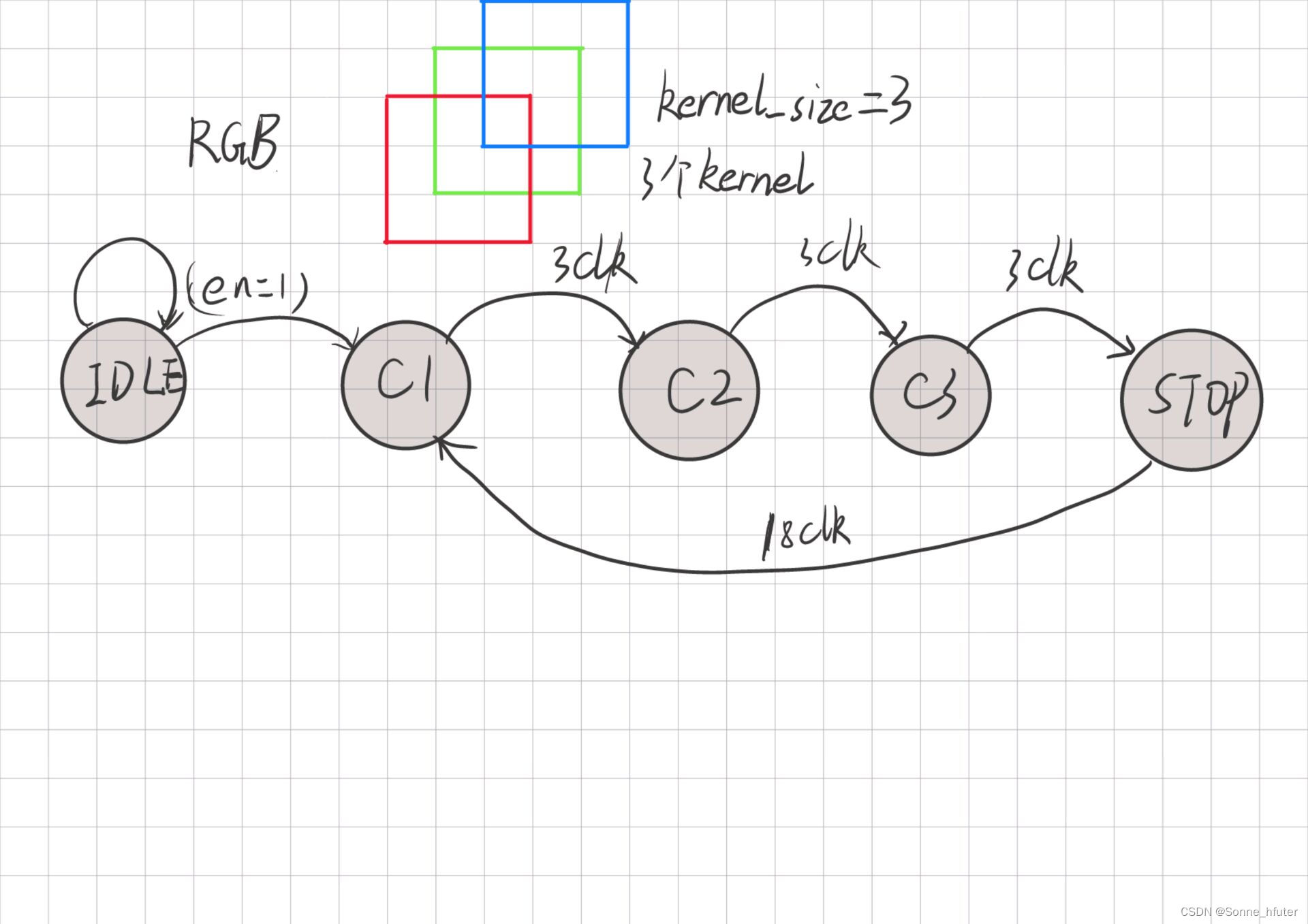
如上,状态由IDLE开始跳转,当输入的使能信号en为1是,IDLE跳转为C1状态,也就是channel1的计算状态,这个计算需要经过3个周期,每个channel都要3个周期计算,三通道计算完毕后停下,随后等待18个clk回到C1状态,至于为什么要等18个周期,这是因为我们最慢的一层计算需要27个周期(更改网络前,修改后实际上最慢需要18个周期,我日后会找时间精进修改),27-9=18,因此需要conv2闲置18个周期随后继续计算,
以下是状态机具体代码
always @(posedge clk or negedge rstn) begin
if (!rstn) begin
state<=0;
cnt<=0;
end
else begin
case (state)
IDLE: begin
cnt<=cnt;
if (en) begin
state<=C1;
end
else begin
state<=IDLE;
end
end
C1:begin
if (cnt==2) begin
state<=C2;
cnt<=0;
end
else begin
state<=C1;
cnt<=cnt+1;
end
end
C2:begin
if (cnt==2) begin
state<=C3;
cnt<=0;
end
else begin
state<=C2;
cnt<=cnt+1;
end
end
C3:begin
if (cnt==2) begin
state<=STOP;
cnt<=0;
end
else begin
state<=C3;
cnt<=cnt+1;
end
end
STOP:begin
if (cnt==17) begin
state<=C1;
cnt<=0;
end
else begin
state<=STOP;
cnt<=cnt+1;
end
end
default: begin
cnt<=cnt;
state<=IDLE;
end
endcase
end
end下方为为什么一个通道计算需要3个周期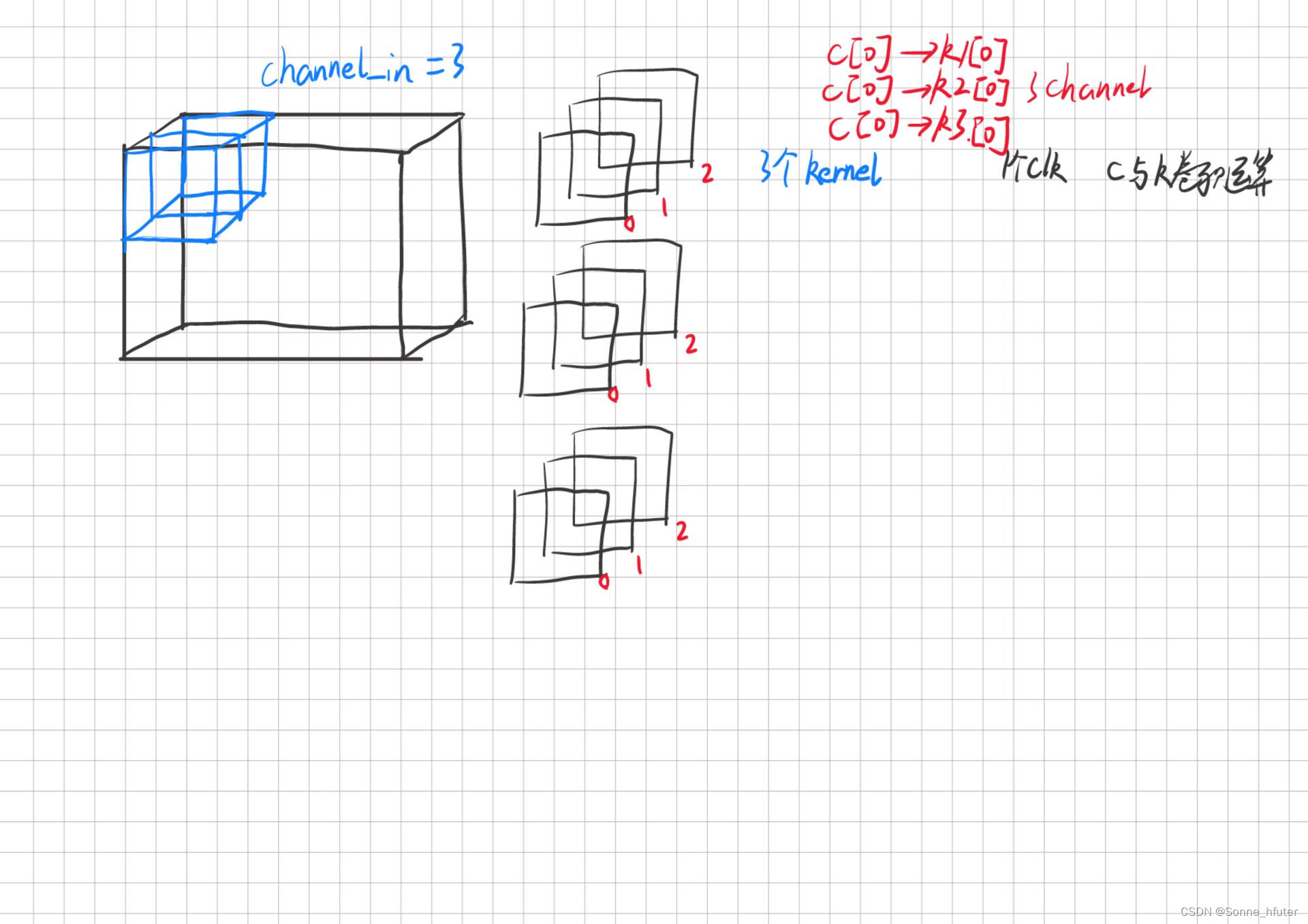
如上,对于三通道的输入图片,首先我们设定一个通道的卷积计算耗时一个周期,而第一个通道分别与三个卷积核的第一个通道分别卷积得到输出特征图的第一个通道的第一个像素点的值,而这个计算我们设定在三个周期内完成,而总共有三个通道,因此总共需要计算九个周期。
而我们也设置了一个data2pe,来实现,在不同通道的计算状态下,存取不同通道的数据来实现计算,下方为部分代码,channel_RF为输入三通道的不同通道的数据,为寄存器组类型
always @(*) begin
case (state)
IDLE: data2pe<=0;
C1: data2pe<=channel_RF[0];
C2: data2pe<=channel_RF[1];
C3: data2pe<=channel_RF[2];
STOP:data2pe<=0;
default: data2pe<=0;
endcase
end 我们定义一个子模块实现计算功能,为PE,同时在实现PE功能前,我们还需要放入我们所训练出来的权重数据来帮助计算,为weights模块,我们在权重模块定义寄存器组来存放weights数据,而weights模块方面的状态机如下图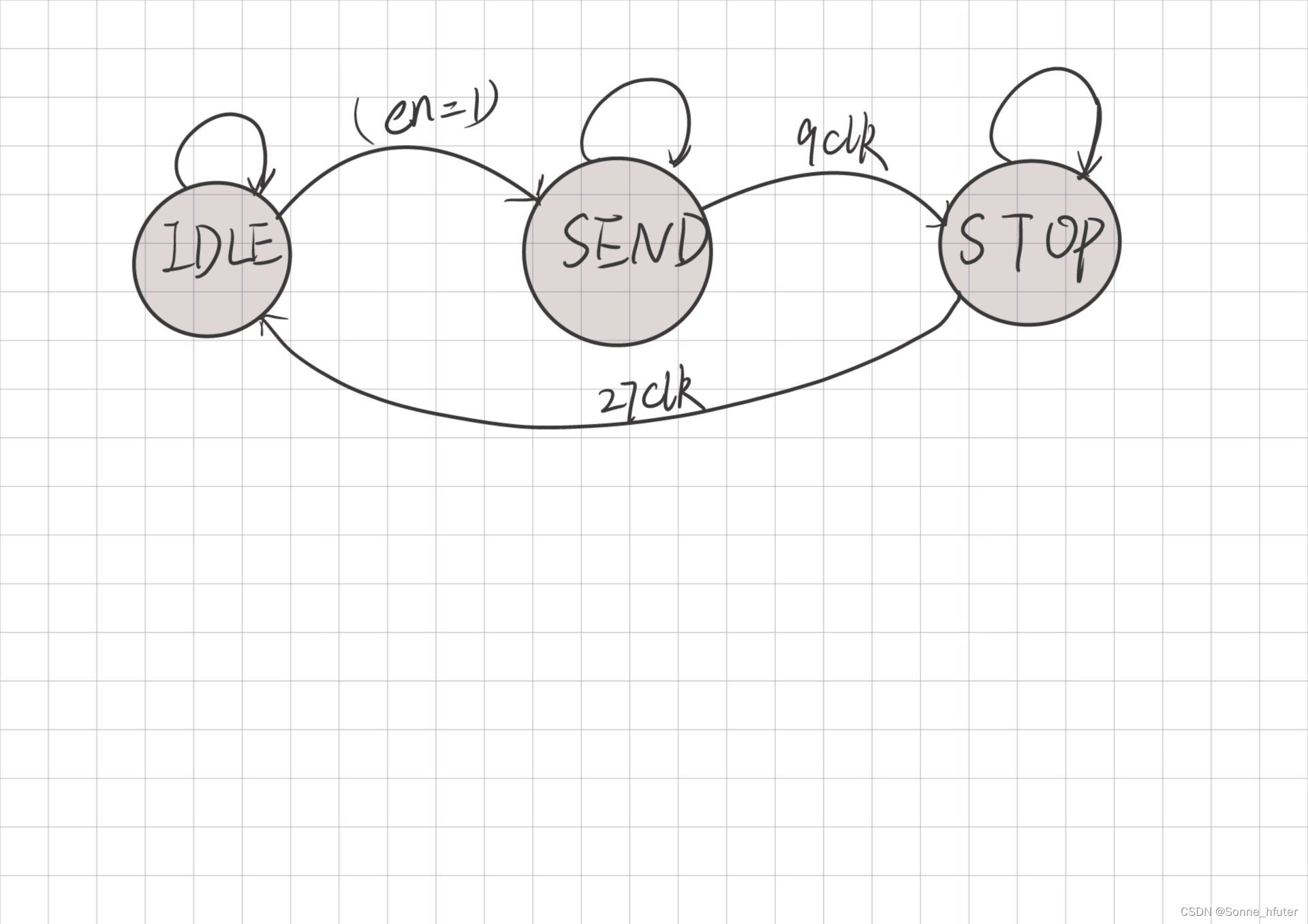
我们采用三段式来描述这个FSM,其优点为优点:A、FSM做到了同步寄存器输出;B、消除了组合逻辑输出的不稳定与毛刺的隐患;C、更利于时序路径分组;D、在FPGA/CPLD等可编程逻辑器件上的综合与布局布线效果更佳,但是资源相对于两段式状态机消耗更多代码如下
//FSM1:状态转移时序逻辑
always @(posedge clk or negedge rstn) begin
if(!rstn)begin
cstate <= IDLE;
end
else begin
cstate <= nstate;
end
end
//FSM2:产生下一个状态组合逻辑
always @(*) begin
if(!rstn)begin
nstate = IDLE;
end
else begin
case(cstate)
IDLE:begin
if(weigth_en) nstate = SEND;
else nstate = IDLE;
end
SEND:begin
if(cnt_9_flag) nstate = STOP;
else nstate = SEND;
end
STOP:begin
if(cnt_26_flag) nstate = IDLE;
else nstate = STOP;
end
default: nstate = IDLE;
endcase
end
end
//FSM3:产生输出时序逻辑
always @(posedge clk or negedge rstn) begin
if(!rstn)begin
kernel_weights <= IDLE;
end
else begin
case(nstate)
SEND:kernel_weights <= W_RF[cnt];
default:kernel_weights <= 72'd0;
endcase
end
end如上,利用cnt来分周期将权重数据赋值到kernel_weights中,接下来我们考虑PE模块的设计,即卷积计算的设计,对于这个计算我们使用三级流水,具体流程如下图
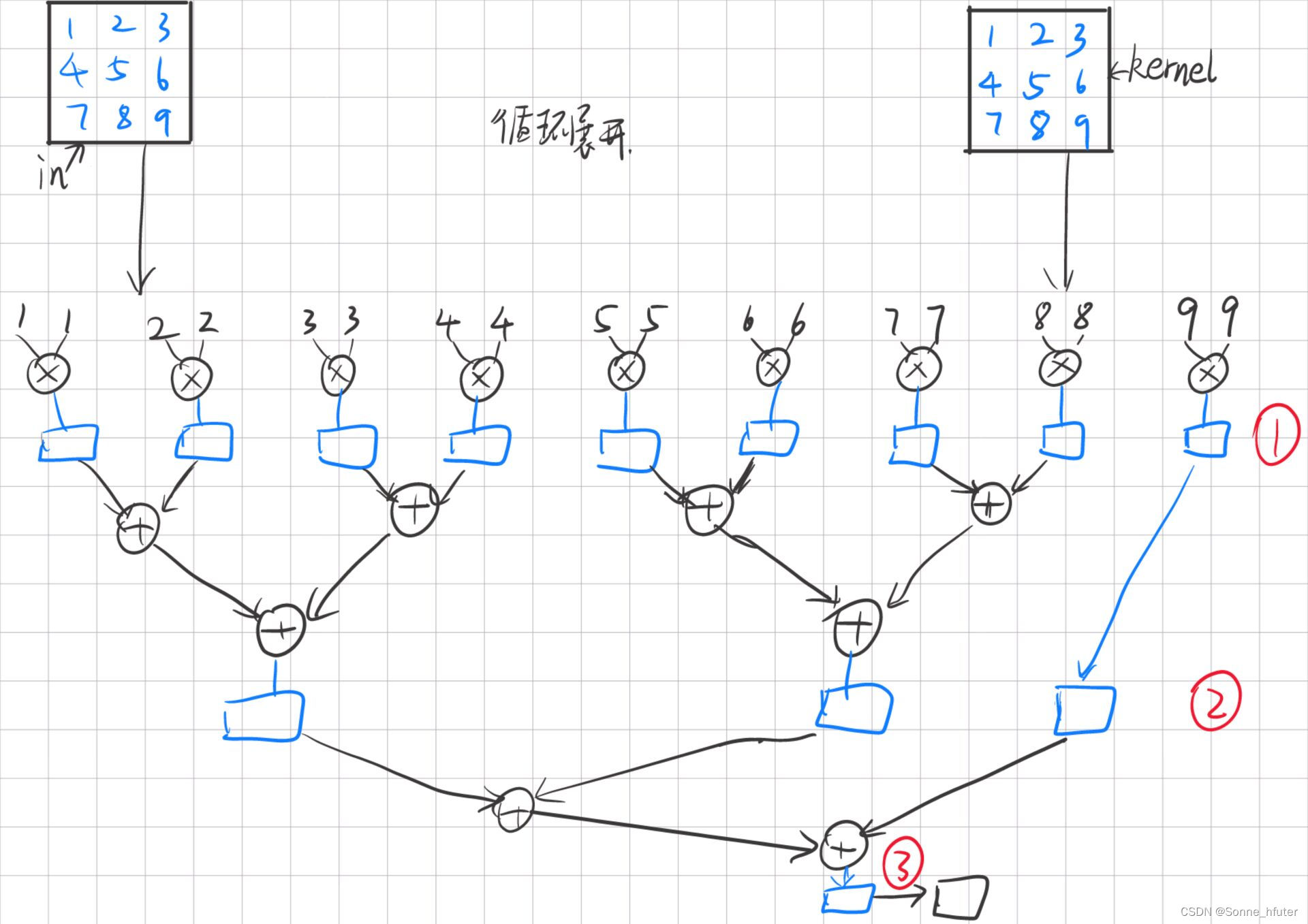
完成上述传输计算后对于完整的卷积层计算还差添加偏置和激活函数(relu函数),因此我们随后给出bias模块和relu模块的设计思路和部分代码
对于bias模块,我们考虑引入一个flag来控制剩余的conv计算,当flag有效时,计数器正常+1,从而控制三个周期完成计算,我们在bias模块中利用一个always块引入一个小型的一级流水线,加快计算速度,3个周期内完成计算,具体代码如下
//cnt 控制信号
always @(*) begin
if (!rstn) begin
flag=0;
end
else if(bais_en) begin
flag=1;
end
else if(cnt==2) begin
flag=0;
end
else flag=flag;
end
//cnt++
always @(posedge clk or negedge rstn) begin
if (!rstn) begin
cnt<=0;
end
else if(cnt==2) begin
cnt<=0;
end
else if(flag)begin
cnt<=cnt+1;
end
else begin
cnt<=cnt;
end
end
//
always @(posedge clk or negedge rstn) begin
if (!rstn) begin
data_m<=0;
Bais<=0;
bais2relu<=0;
end
else begin
data_m<=pe2bias*M_RF[cnt];
Bais<=B_RF[cnt];
bais2relu<=(data_m>>>16)+Bais;
end
end
always @(posedge clk or negedge rstn) begin
if (!rstn) begin
bais_valid<=0;
end
else if(cnt==1) begin
bais_valid<=1;
end
else bais_valid<=0;
end最后生成的valid有效信号是为了给下一个relu模块计算使用的使能信号 ,而我们编写的relu模块就很简单了,只需要实现小于-128的赋-128,大于127的赋值127,其余不变
module conv2_ReLU#(
parameter WIDTH = 8
)(
input clk,
input rstn,
input signed [20:0]qy,//输入数据
output reg signed [WIDTH-1:0]q_relu //输出数据
);
always @(posedge clk or negedge rstn) begin
if(!rstn) begin
q_relu <= 0;
end
else begin
if (qy>127) begin
q_relu<=127;
end
else if(qy<-128) begin
q_relu<=-128;
end
else q_relu<=qy;
end
end
endmodule
接下来便是通过总conv2模块来将weights,pe,bias,relu连接起来,最终输出data_out,为一个3*3*3的输出特征图,以上不为完整代码,只为部分重要处进行讲解,详细代码请私信
















 2672
2672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











