






最近在神经网络的学习过程中,转战pytorch了,然后想把我们组的神经网络模型通过自己写代码给复现出来,因此这篇文章记录了从数据处理和加载到模型构建和训练模型,最后保存模型并利用netron查看,在这之中遇见了很多问题,我也会把其中最有价值的问题和解答进行解释,帮助更好的理解深度学习中的神经网络模型构建,下方是我们组的神经网络模型
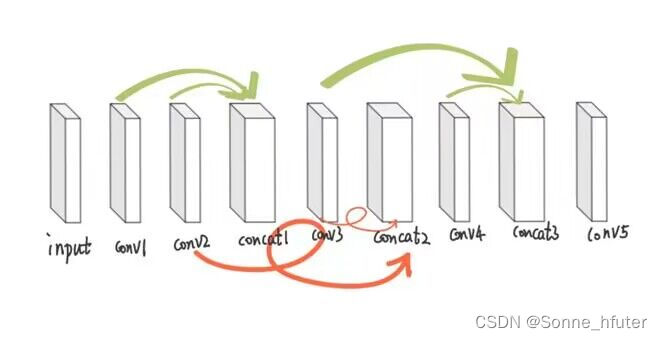
对于上述模型,我们输入是480*640*3的特征图,输出也是3*480*640的特征图,也就是说该模型的输入输出都是4D张量,之前我所学习的例子都是基于1D张量输出,来写的训练模型,4D张量的训练模型这次是首写,训练方法比较简单,方便小白理解。
下方是我单独写的model模块(model.py),为上方网络模型的基本复现
import torch.nn as nn
import torch
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Sequential(#创建了一个按顺序执行的层序列
nn.Conv2d(3,3,1,1,0),
nn.ReLU())#relu层
self.conv2 = nn.Sequential(#创建了一个按顺序执行的层序列
nn.Conv2d(3,3,3,1,1),
nn.ReLU())#relu层
self.conv3 = nn.Sequential(#创建了一个按顺序执行的层序列
nn.Conv2d(6,3,5,1,2),
nn.ReLU())#relu层
self.conv4 = nn.Sequential(#创建了一个按顺序执行的层序列
nn.Conv2d(6,3,7,1,3),
nn.ReLU())#relu层
self.conv5 = nn.Sequential(#创建了一个按顺序执行的层序列
nn.Conv2d(6,3,3,1,1),
nn.ReLU())#relu层
def forward(self,x):
conv1_out = self.conv1(x)
conv2_out = self.conv2(conv1_out)
concat1 = torch.cat((conv1_out,conv2_out),dim= 1)
conv3_out = self.conv3(concat1)
concat2 = torch.cat((conv2_out,conv3_out),dim=1)
conv4_out = self.conv4(concat2)
concat3 = torch.cat((conv3_out,conv4_out),dim=1)
conv5_out = self.conv5(concat3)
conv_out = nn.functional.relu((conv5_out*x) - conv5_out + 1)
return conv_out
上方定义了一个Net类,5个conv层,3个concat层,接下来我们通过torchsummary来观测我们构建的模型(类似于keras库中的model.summary())
import model
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.Net().to(device)
sum.summary (model,(3,480,640))
上方的import model为引入我自定义的model.py,而前两行代码为判断用gpu还是cpu来查看模型,这里我们使用的是cpu,如果想使用gpu跑的话可以上网查看教程,只需要改几行代码即可,以下是我们打印出来的网络模型基本架构
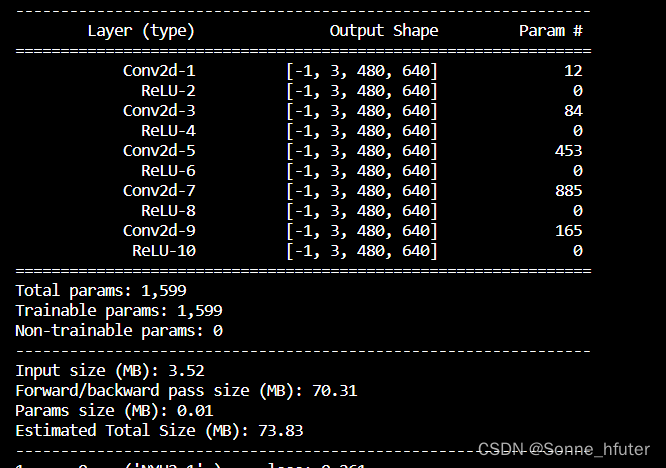
可以看到,网络模型构建基本没有什么问题,总参数为1599,与我使用keras和方洁鸿学姐使用的tensorflow构建的网络模型参数一致。
网络模型构建完成,接下来我们来预处理数据,下方是我们的图片数据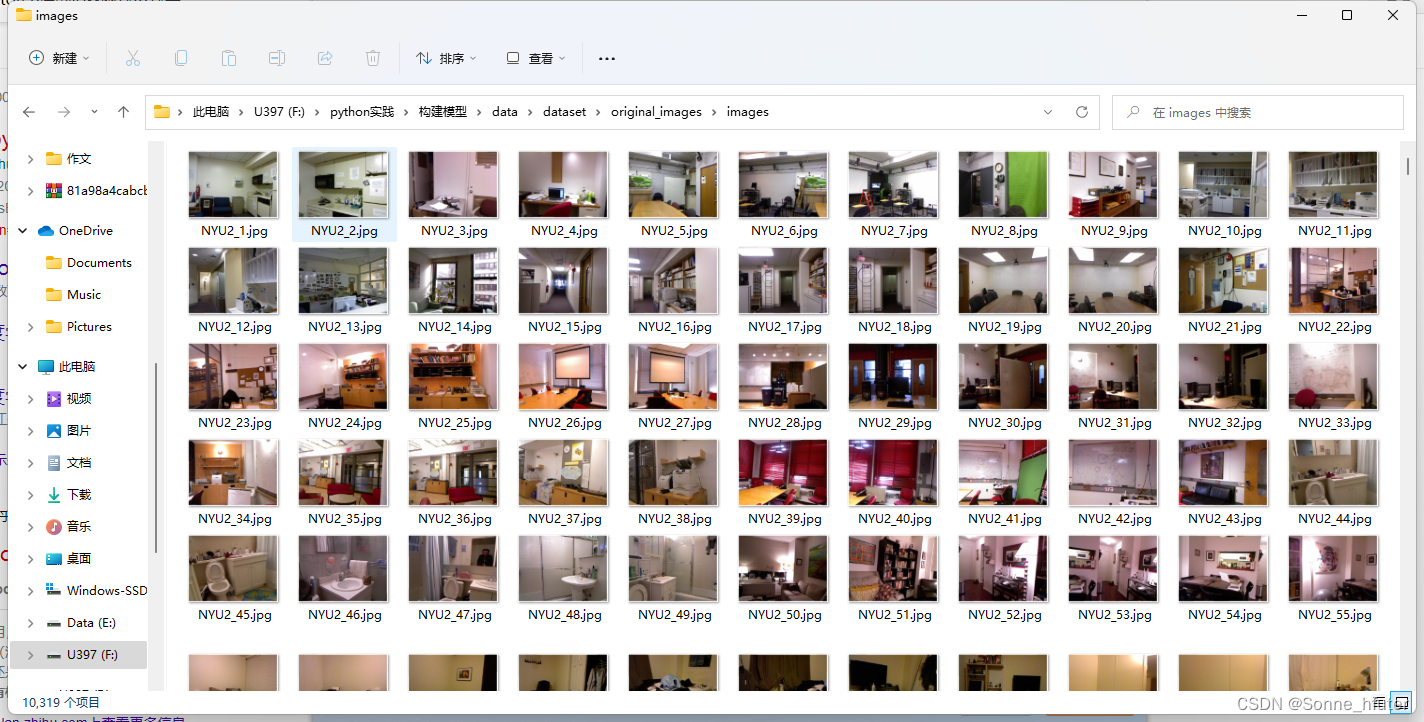
上方为validation集,下方为train集,也就是上方是无雾图片,下方是不同程度的有雾图片
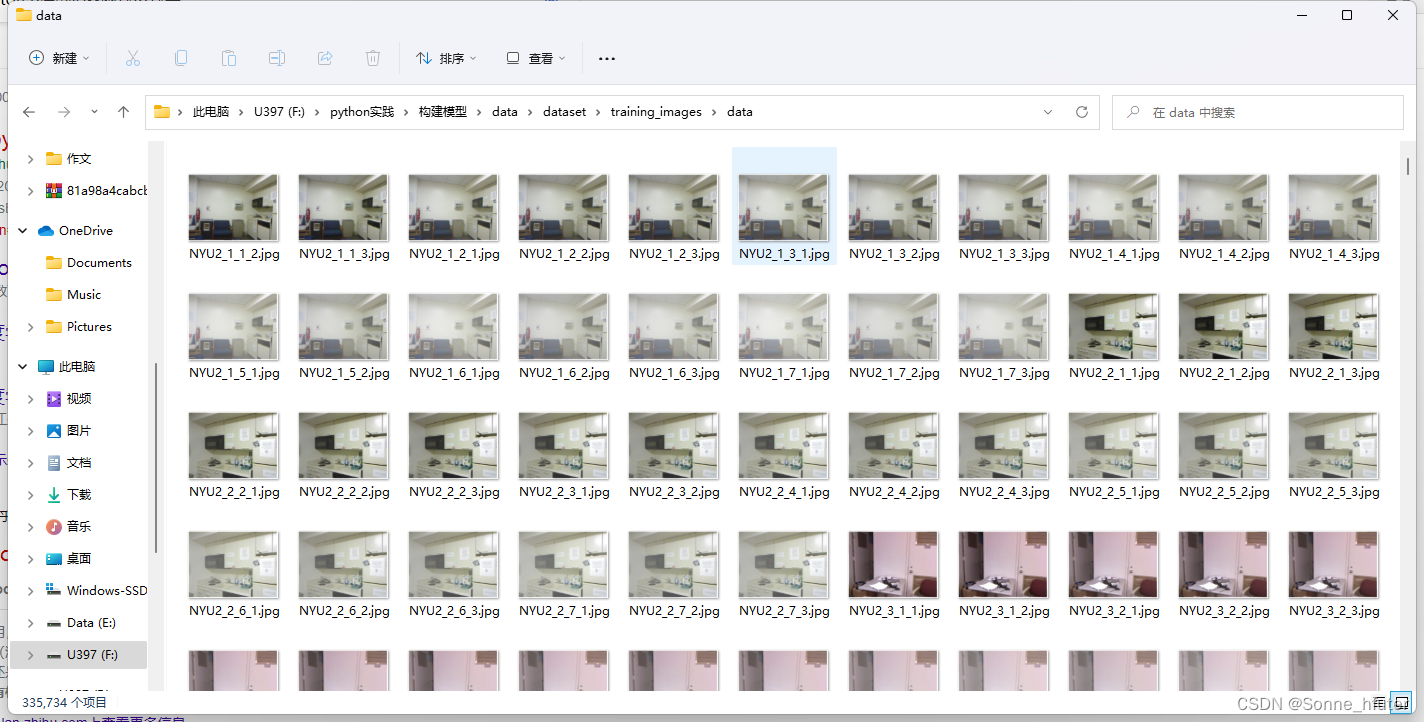
无雾图片有10319项,而有雾图片有335734项,其中我们可以观察,validation中的第一张图片名称是NYU2_1,而跟其属于同一类的有雾图片在此前缀下有许多不同的后缀,因此,我们在数据处理时可以考虑将验证集和训练集根据这一相同前缀来分别训练有雾图像经过网络模型后与无误雾图像的mse误差。
这里我们考虑将不同的图片集转化成具有标签和图片路径的txt文件,随后更方便我们后续处理,值得注意的是,我们这里最好将不同的txt文件,按顺序对应起来,这样能优化模型训练速度,我们这里选择使用自定义函数来做循环检阅,但生成txt速度较慢,足足花费我10分钟,代码如下
from torchvision import transforms # import io import glob #打开存放图片的文件夹,然后遍历文件名,把文件名字, label 还有 文件夹名写入data.txt文件中。 import os transforms = transforms.Compose([ transforms.ToTensor() #把图片进行归一化,并把数据转换成Tensor类型 ]) root = './data/dataset/' def convert_to_img(root): f=open(root +'train.txt','w') data_t_path = root +'training_images/data/' if(not os.path.exists(data_t_path)):#后面这段表示判断路径是否存在,存在则返回true os.makedirs(data_t_path) #新建一个路劲 hazy_data = glob.glob(data_t_path + "*.jpg") # 获取路径下所有模糊图像 f1 = open(root + 'validation.txt', 'w') data_path = root + 'original_images/images/' if(not os.path.exists(data_path)):#后面这段表示判断路径是否存在,存在则返回true os.makedirs(data_path) #新建一个路劲 hazy_data1 = glob.glob(data_path + "*.jpg") # 获取路径下所有模糊图像 for h_image1 in hazy_data1: h_image1 = h_image1.split("\\")[-1] img_path = data_path + h_image1 id_ = h_image1.split("_")[0] + '_' + h_image1.split("_")[1] # io.imsave(data_path) id_ = id_.rstrip('.jpg') f1.write(img_path + ' ' + id_ + '\n' ) for h_image in hazy_data: h_image = h_image.split("\\")[-1] img1_path = data_t_path + h_image id_1 = h_image.split("_")[0] + '_' + h_image.split("_")[1] if id_1 == id_ : # io.imsave(data_t_path) f.write(img1_path + ' ' + id_1 + '\n' ) if (id_1 != id_): break # else : continue f.close() f1.close() convert_to_img(root)
由于代码是自己写的,难免会有一些代码注释,大家观看的时候建议忽略掉一些代码注释,写完后得出如下txt文件
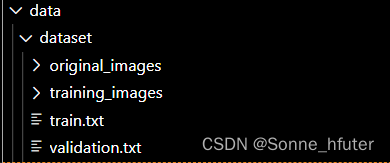
下面是train.txt
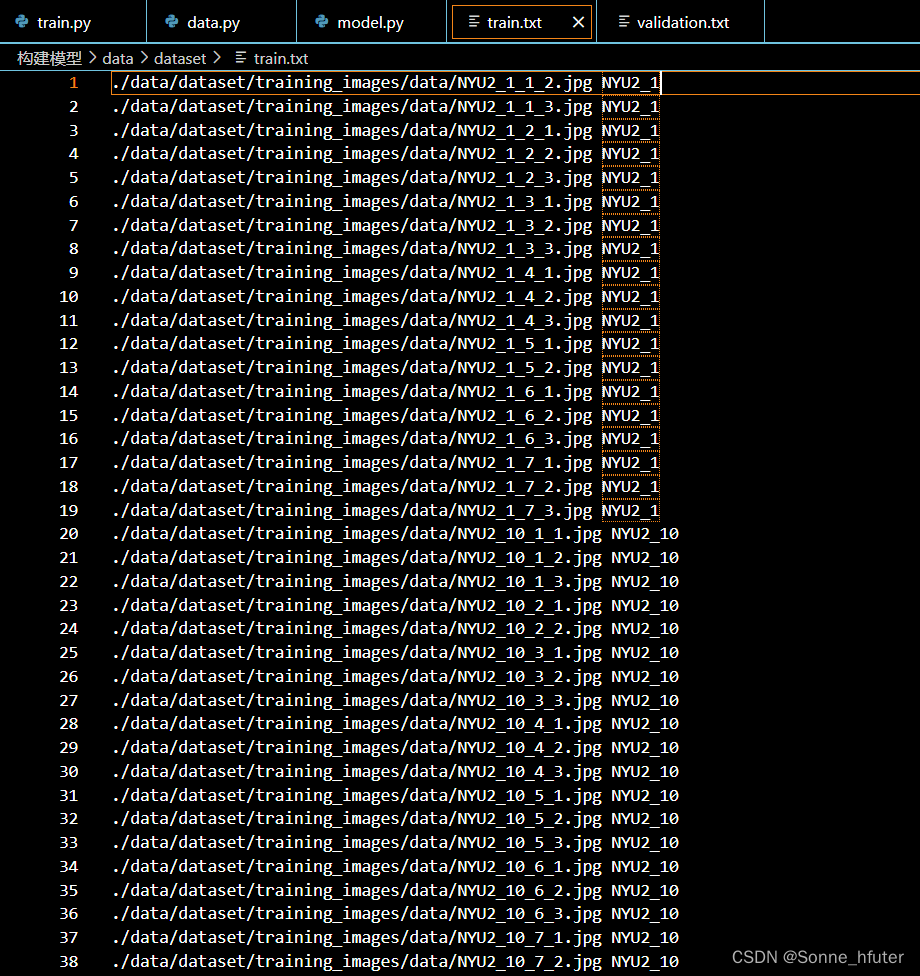
下面是validation.txt
两txt文件从上到下能对应下来
接下来我们看看两txt文件中的最大值是否满足原文件夹的最大值,即看是否便利文件夹中所有文件

分别满足要求
接下来便是加载txt文件,处理数据了,我这边使用自定义的dataset函数来处理txt文件中的数据,代码如下:
import torch
# import torchvision
from PIL import Image
# from matplotlib import pyplot as plt
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
import torchsummary as sum
transforms = transforms.Compose([
transforms.Resize((480,640)),
# transforms.CenterCrop(224), #将图片从中心切剪成3*224*224大小的图片
transforms.ToTensor() #把图片进行归一化,并把数据转换成Tensor类型
])
class MyDataset(Dataset):
def __init__(self, img_path, train = True, transform=None):
super(MyDataset, self).__init__()
self.root = img_path
if(train) :
self.txt_root = self.root + 'train.txt'
else :
self.txt_root = self.root + 'validation.txt'
f = open(self.txt_root, 'r')
data = f.readlines()
imgs = []
labels = []
for line in data:
line = line.rstrip()
word = line.split()
# print(word[0], word[1])
#word[0]是图片路径.jpg word[1]是label
labels.append(word[1])
imgs.append(word[0])
# print ('imgs:' , imgs, 'label: ', labels)
# print (labels)
self.img = imgs
self.label = labels
self.transform = transform
def __len__(self):
return len(self.label)
def __getitem__(self, item):
img = self.img[item]
label = self.label[item]
img = Image.open(img).convert('RGB')
# img = np.pad(img, (0, 582-img.shape[1]), 'constant', constant_values=(0, -1))
# 此时img是PIL.Image类型 label是str类型
if self.transform is not None:
img = self.transform(img)
# label = np.array(label).astype(np.int64)
# label = torch.from_numpy(label)
# print("new label: ", label)
return img, label
path = './data/dataset/'
dataset_train = MyDataset(path, train= True,transform=transforms)
dataset_validtion = MyDataset(path ,train= False,transform= transforms)
data_loader_train = DataLoader(dataset=dataset_train, batch_size=1, shuffle=False)
data_loader_validation = DataLoader(dataset=dataset_validtion, batch_size=1)这样上方便载入数据了,接下来我们定义优化器和损失函数分别为adam和mse
# 定义损失函数和优化器
criterion = torch.nn.MSELoss() #mse
optimizer = torch.optim.Adam(model.parameters(), lr=0.001) # Adam优化器
然后接下来我们便可以开始训练循环了,由于图片数据过大,这里只指定了两轮回训练,但是还是没跑完,但是是能正确的跑模型和显示损失函数的
# 训练循环
epochs = 2
for epoch in range(epochs):
running_loss = 0.0
l = 0.0
for j ,data_validation in enumerate(data_loader_validation):
img_validation , lable_validation = data_validation
# i = j * 19 - 1
for i, data_train in enumerate(data_loader_train):
# print (i)
if(i>=19*j-1):
img_train , label_train = data_train
if label_train == lable_validation:
out = model(img_train)
# print(out.shape)
# print(label.shape)
loss = criterion(out,img_validation)
# print (loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item()
l += 1
if( j %10 == 0):
print('%d %5d %s = loss: %.3f' %(epoch+1, j , label_train,running_loss/ l))
# running_loss = 0.0
if((i>=20*j)&(label_train != lable_validation)): break
print('finished train')
显示如下: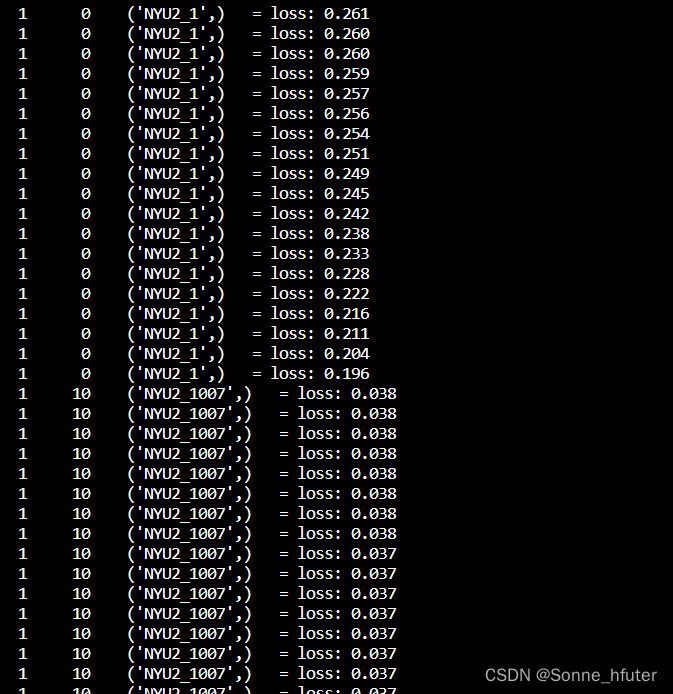
在这段代码中,我已经尽可能去优化加快循环速度了,包括检查完后直接break循环进入下一循环,但是由于validation验证集有1万多张图片,还是很难跑完,因此我等没事的时候再跑,后面跑完了,能正确显示模型可视化,再回来补完这篇博客。
为了使用netron正确可视化模型,pytorch中可以利用下方代码来打印模型以实现跟tflite相同功能的模型:
model_net = torch.jit.script(model)
torch.jit.save(model_net,'./model_net_new.pth')模型跑完后保存模型,会在当前文件夹下生成如下pth模型,打开后会跟tflite显示差不多,方面模型理解。

















 629
629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











