






课程地址:03.梯度下降算法_哔哩哔哩_bilibili 04.反向传播_哔哩哔哩_bilibili
目录
梯度下降算法
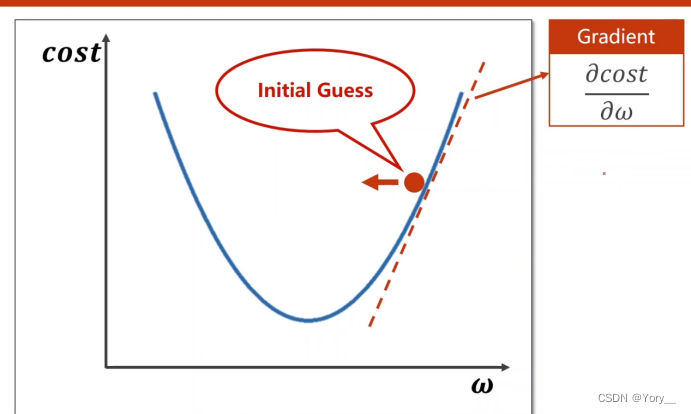
要进行梯度下降算法首要要求出梯度→算出上升方向
梯度算法推导:
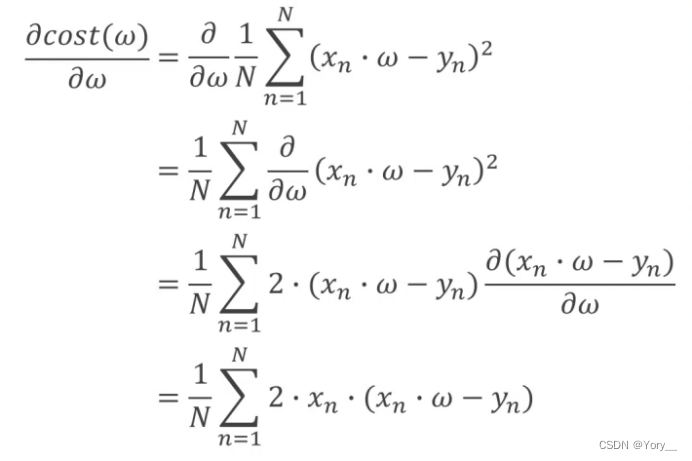
训练问题

当出现以上图形表明训练发散 可采取调小学习率来进行改正
课程中的代码就不放了 总而言之,随机梯度下降(mini-batch)时间久但性能好
反向传播
添加激活函数(非线性函数)
深度加深是为了把线性函数 变化成非线性的形式,从而准确地去拟合一些非线性函数。
Tensor
PyTorch中保存数据的都存在Tensor之中,可以保存标量、向量、矩阵、高维数集
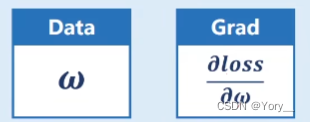
Data保存权重本身这个值 Grad保存损失函数对权重求偏导的值
张量就是多维数组 比如卷积完的那个大方块
PyTorch构建模型本质是构建如下计算图
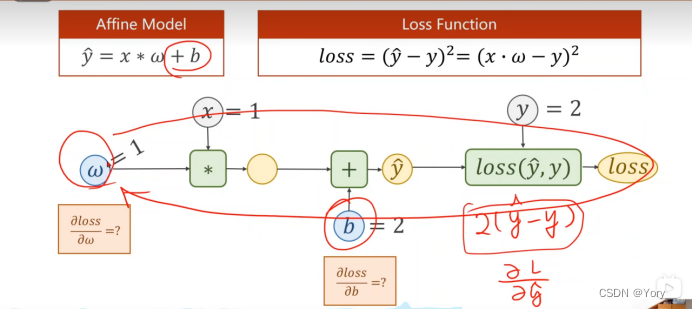
作业
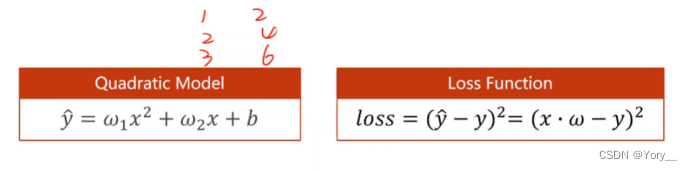
用代码实现以上推导
代码
import torch
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w1 = torch.Tensor([1.0])
w1.requires_grad = True # Tensor中requires_grad必须设置成True 计算梯度
w2 = torch.Tensor([1.0])
w2.requires_grad = True
b = torch.Tensor([1.0])
b.requires_grad = True
def forward(x):
return w1 * x ** 2 + w2 * x + b
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
print('Predict (before training)', 4, forward(4).item())
for epoch in range(100):
for x, y in zip(x_data, y_data):
l = loss(x, y)
l.backward() # 将计算图前面中的每一处需要梯度的地方求出后存入到变量中
print('\tgrad:', x, y, w1.grad.item(), w2.grad.item(), b.grad.item())
w1.data = w1.data - 0.01 * w1.grad.data # grad也是Tensor
w2.data = w2.data - 0.01 * w2.grad.data # 使用.data方便后期不需再刻意去算梯度
b.data = b.data - 0.01 * b.grad.data
# 权重中梯度里的数据全部清零
w1.grad.data.zero_()
w2.grad.data.zero_()
b.grad.data.zero_()
# .item() 将其中的损失值取出
print("progress:", epoch, l.item())
print('Predict (after training)', 4, forward(4).item())结果与总结
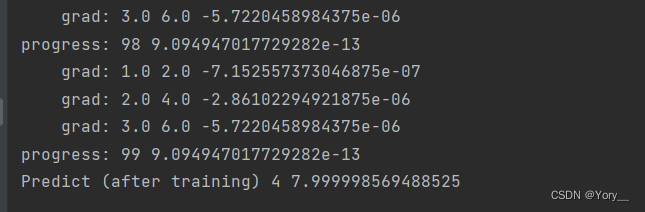
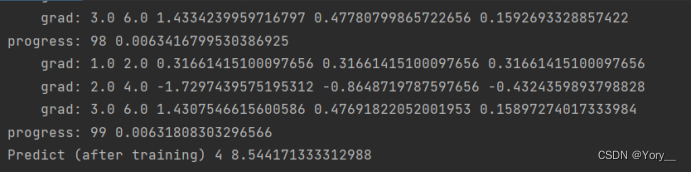
最后结果为4 8.5与原来线性模型有区别 个人认为是因为模型选得是二次函数难以和原数据拟合















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









