






课程地址:05.用PyTorch实现线性回归_哔哩哔哩_bilibili
目录
编辑 1.准备数据(使用mini-batch目的是为了一次性求出y_hat)
理论
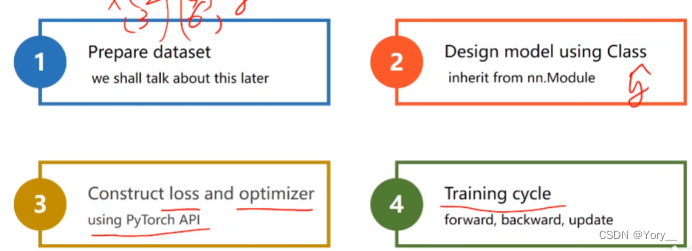 1.准备数据(使用mini-batch目的是为了一次性求出y_hat)
1.准备数据(使用mini-batch目的是为了一次性求出y_hat)
2.定义模型

构造函数的模板→扩展模型完成PyTorch中各式各样的任务
3.构造损失函数和优化器

4.训练过程

课程代码总结
代码:
import torch
x_data = torch.Tensor([[1.0], [2.0], [3.0]])
y_data = torch.Tensor([[2.0], [4.0], [6.0]])
# 定义线性模型
class LinearModel(torch.nn.Module):
def __init__(self):
super(LinearModel, self).__init__() # 在python3的版本可以直接写成super().__init__()
self.linear = torch.nn.Linear(1, 1)
def forward(self, x):
y_pred = self.linear(x) # 对象后面加括号实现一个可调用的对象
return y_pred
model = LinearModel()
# MSELoss继承自Module
criterion = torch.nn.MSELoss(size_average=False)
# parameters会检查module中所有成员 如果成员中有相应的权重将加到最后训练的权重之中
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
for epoch in range(100):
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
# loss是标量 打印时自动使用__str__()函数
print(epoch, loss.item())
# 将所有梯度都归零
optimizer.zero_grad()
loss.backward()
# step函数进行一次更新
optimizer.step()
print('w = ', model.linear.weight.item()) # 此处item()将矩阵转成数值
print('b = ', model.linear.bias.item())
x_test = torch.Tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data)

按照课上的代码运行出来的代码结果与我们预期的8有些许差距,原因是模型还没有完全拟合
解决方法:
1.根据老师的方法多迭代几次

2.适当调整学习率lr




上图的lr依次为0.02、0.03、0.04、0.06(0.04和0.05运行结果相差不大就没放入其中)
可以发现适当调整学习率也可以达到预测值,当学习率过大时就会出现过拟合的情况
作业

尝试用不同的优化器进行优化 结果在100次循环内效果最好的应该是Rprop
疑惑
部分优化器在运行多次后预测值偏差较大,不是很明白这是为什么














 205
205











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









