







爬虫scrapy框架系列—入门
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
挑战两天看完一本书
提示:写完文章后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
前言
提示:这里可以添加本文要记录的大概内容:
爬虫框架的使用
提示:以下是本篇文章正文内容,下面案例可供参考
一、scrapy是什么?
Scrapy (/ˈskreɪpaɪ/) 是一个用于抓取网站和提取结构化数据的应用程序框架,可用于广泛的有用应用程序,如数据挖掘、信息处理或历史档案。
尽管 Scrapy 最初是为网络抓取而设计的,但它也可以用于使用 API(例如Amazon Associates Web Services)或作为通用网络爬虫来提取数据。
可以参考网站:https://docs.scrapy.org/en/latest/intro/overview.html
二、使用步骤
1.安装
代码如下(示例):
终端:pip install scrapy
2.如何创建一个爬虫项目
代码如下(示例):
scrapy startproject news
这样就创建了一个名为news的项目,cd news 后就可以进入项目文件里、
现在我们可以利用命令行创建一个spider专门爬取站点新闻
scrapy genspider xxx.xxx.com.cn
现在文件的格式变为
该处使用的url网络请求的数据。
3.入门之实际操练完成一遍流程
1.本节目标
1,,创建一个项目,熟系创建
2,编写一个spider用来抓取
3,了解item pipeline 把数据存取mongodb数据库
4,了解运行流程
使用网站xxxx.com
2.准备工作
安装scrapy框架,mongodb和pymongo库
3.创建项目
scrapy startproject scrapytutorial
4.创建spider
cd scrapytutorial
scrapy genspider quotes quotes.toscrape.com
```c
import scrapy
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['xxxx.com']
start_urls = ['http://xxx.xxx.com/']
def parse(self, response):
pass
5.创建item
import scrapy
class ScrapytutorialItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
pass
item是保存爬取数据的容器,定义爬取结果的数据结构,text,author,taggs就是我们要爬取的数据·
6.解析Response&&使用item
观察页面,找到每个项目都对应一个div,我们使用css选择器进行选取,使用for遍历没一个模块。代码如下
import scrapy
from scrapytutorial.scrapytutorial.items import QuoteItem
class QuotesSpider(scrapy.Spider):
name = 'quotes'
allowed_domains = ['xxxx.com']
start_urls = ['http:xxxx.com/']
def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
item = QuoteItem()
item['text'] = quote.css('.text::text').extract_first()
item['author'] = quote.css('.author::text').extract_first()
item['tags'] = quote.css('.tags .tag::text').extract()
yield item
item就是保存数据的容器,我们使用它可以把内容解析出来赋值成一个一个项目
8.后续Request
我们成功爬取了一个页面的数据可是我们还有好多页,我们观察后续页面的网站,发现是/page/2/,以此类推的,我们可以在源代码中找到并且构造拼接语句,这里我们构造一个框架的request,使我们可以一直循环抓取
next = response.css('.pager .next a::attr("href")').extract_first()
url = response.urljoin(next)
yield scrapy.Request(url=url,callback=self.parse)
下面运行即可。。。
9.运行
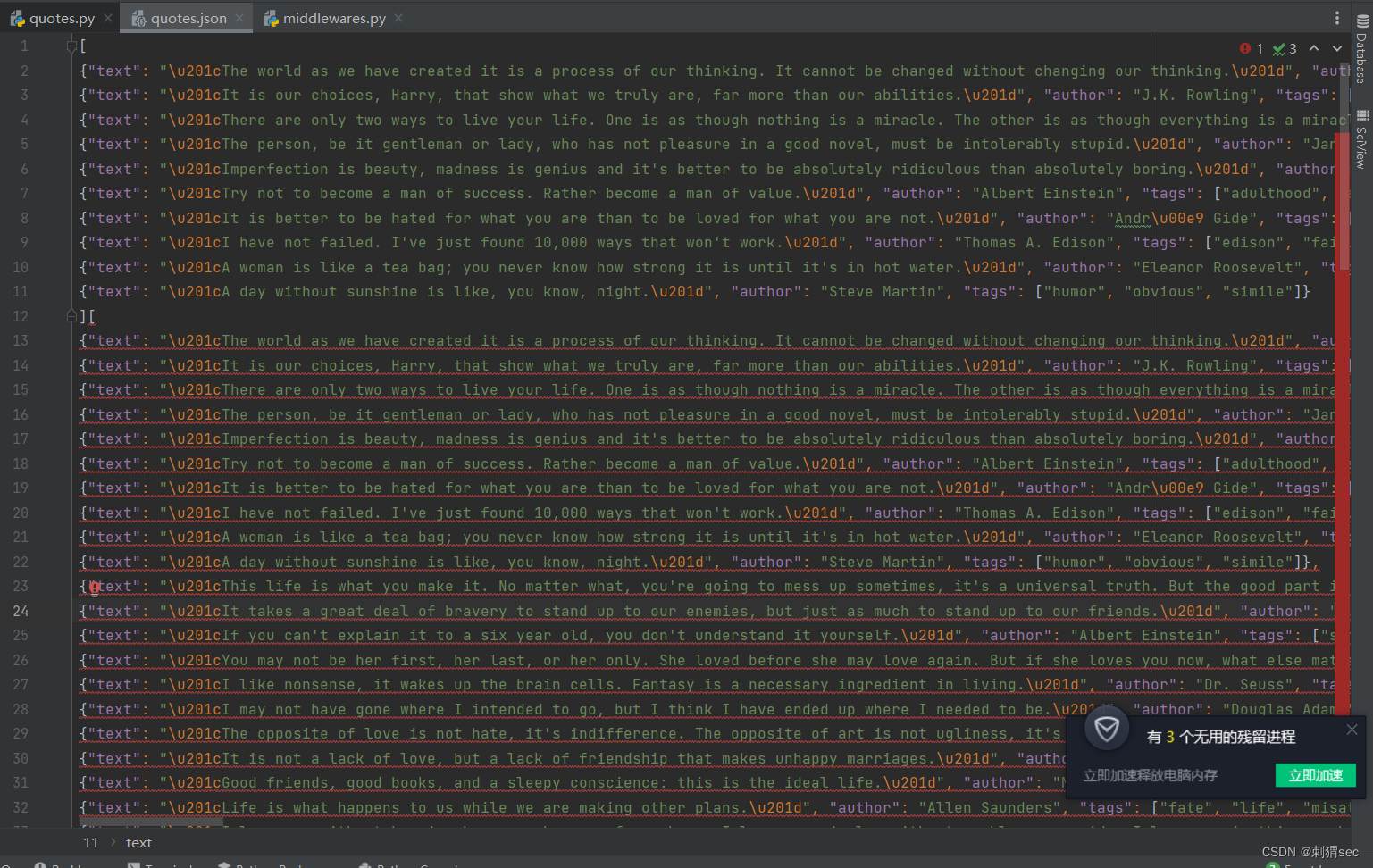
scrapy crawl quotes -o quotes.json
#存储为json格式
scrapy还有好多功能点,这只是入门,可以进一步导入到数据库,由于我花了2个小时没有安装成功数据库,于是放弃了,后期打算把数据库放到我的云服务器上进一步操作
总结
提示:这里对文章进行总结:
框架系列第一期之入门框架














 56万+
56万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









