







文章目录
前言
map和set的底层是红黑树,希望大家看完前一篇文章后再来看本章内容。
1. 关联式容器
在初阶阶段,我们已经接触过STL中的部分容器,比如:vector、list、deque、forward_list(C++11)等,这些容器统称为序列式容器,因为其底层为线性序列的数据结构,里面存储的是元素本身。那什么是关联式容器?它与序列式容器有什么区别?
关联式容器也是用来存储数据的,与序列式容器不同的是,其里面存储的是<key, value>结构的键值对,在数据检索时比序列式容器效率更高。
2.键值对
用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量key和value,key代表键值,value表示与key对应的信息。比如:现在要建立一个英汉互译的字典,那该字典中必然有英文单词与其对应的中文含义,而且,英文单词与其中文含义是一一对应的关系,即通过该应该单词,在词典中就可以找到与其对应的中文含义。
SGI-STL中关于键值对的定义:
template <class T1, class T2>
struct pair
{
typedef T1 first_type;
typedef T2 second_type;
T1 first;
T2 second;
pair() : first(T1()), second(T2())
{}
pair(const T1& a, const T2& b) : first(a), second(b)
{}
};
3.树形结构的关联式容器
根据应用场景的不同,STL总共实现了两种不同结构的管理式容器:树型结构与哈希结构。树型结构的关联式容器主要有四种:map、set、multimap、multiset。这四种容器的共同点是:使用平衡搜索树(即红黑树)作为其底层结果,容器中的元素是一个有序的序列。
3.1 set的介绍
- set是按照一定次序存储元素的容器
- 在set中,元素的value也标识它(value就是key,类型为T),并且每个value必须是唯一的。set中的元素不能在容器中修改(元素总是const),但是可以从容器中插入或删除它们。
- 在内部,set中的元素总是按照其内部比较对象(类型比较)所指示的特定严格弱排序准则进行排序。
- set容器通过key访问单个元素的速度通常比unordered_set容器慢,但它们允许根据顺序对子集进行直接迭代。
- set在底层是用二叉搜索树(红黑树)实现的。
注意:
- 与map/multimap不同,map/multimap中存储的是真正的键值对<key, value>,set中只放value,但在底层实际存放的是由<value, value>构成的键值对。
- set中插入元素时,只需要插入value即可,不需要构造键值对。
- set中的元素不可以重复(因此可以使用set进行去重)。
- 使用set的迭代器遍历set中的元素,可以得到有序序列
- set中的元素默认按照小于来比较
- set中查找某个元素,时间复杂度为: l o g 2 n log_2 n log2n
- set中的元素不允许修改
- set中的底层使用二叉搜索树(红黑树)来实现
它的使用方式与平衡二叉树一样,只是优化了单支树的问题。
3.2 map的介绍
- map是关联容器,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元素。
- 在map中,键值key通常用于排序和惟一地标识元素,而值value中存储与此键值key关联的内容。键值key和值value的类型可能不同,并且在map的内部,key与value通过成员类型value_type绑定在一起,为其取别名称为pair:typedef pair<const key, T> value_type;
- 在内部,map中的元素总是按照键值key进行比较排序的。
- map中通过键值访问单个元素的速度通常比unordered_map容器慢,但map允许根据顺序对元素进行直接迭代(即对map中的元素进行迭代时,可以得到一个有序的序列)。
- map支持下标访问符,即在[]中放入key,就可以找到与key对应的value。
- map通常被实现为二叉搜索树(更准确的说:平衡二叉搜索树(红黑树))。
总结:
- map中的的元素是键值对
- map中的key是唯一的,并且不能修改
- 默认按照小于的方式对key进行比较
- map中的元素如果用迭代器去遍历,可以得到一个有序的序列
- map的底层为平衡搜索树(红黑树),查找效率比较高 O ( l o g 2 N ) O(log_2 N) O(log2N)
- 支持[]操作符,operator[]中实际进行插入查找
3.3 multiset的介绍
- multiset是按照特定顺序存储元素的容器,其中元素是可以重复的。
- 在multiset中,元素的value也会识别它(因为multiset中本身存储的就是<value, value>组成的键值对,因此value本身就是key,key就是value,类型为T). multiset元素的值不能在容器中进行修改(因为元素总是const的),但可以从容器中插入或删除。
- 在内部,multiset中的元素总是按照其内部比较规则(类型比较)所指示的特定严格弱排序准则进行排序。
- multiset容器通过key访问单个元素的速度通常比unordered_multiset容器慢,但当使用迭代器遍历时会得到一个有序序列。
- multiset底层结构为二叉搜索树(红黑树)。
注意:
- multiset中再底层中存储的是<value, value>的键值对
- mtltiset的插入接口中只需要插入即可
- 与set的区别是,multiset中的元素可以重复,set是中value是唯一的
- 使用迭代器对multiset中的元素进行遍历,可以得到有序的序列
- multiset中的元素不能修改
- 在multiset中找某个元素,时间复杂度为 O ( l o g 2 N ) O(log_2 N) O(log2N)
- multiset的作用:可以对元素进行排序
3.4 multimap的介绍
- Multimaps是关联式容器,它按照特定的顺序,存储由key和value映射成的键值对<key, value>,其中多个键值对之间的key是可以重复的。
- 在multimap中,通常按照key排序和惟一地标识元素,而映射的value存储与key关联的内容。key和value的类型可能不同,通过multimap内部的成员类型value_type组合在一起,value_type是组合key和value的键值对:typedef pair<const Key, T> value_type;
- 在内部,multimap中的元素总是通过其内部比较对象,按照指定的特定严格弱排序标准对key进行排序的。
- multimap通过key访问单个元素的速度通常比unordered_multimap容器慢,但是使用迭代器直接遍历multimap中的元素可以得到关于key有序的序列。
- multimap在底层用二叉搜索树(红黑树)来实现。
注意:multimap和map的唯一不同就是:map中的key是唯一的,而multimap中key是可以重复的。
set实际上就是排序+去重,map则是通过K值找V值。而它们的另一种multi都是将它们的去重功能给去掉了。
4.封装
接下来要做的就是将红黑树封装成map和set。
不过在此之前先来介绍一个结构体:pair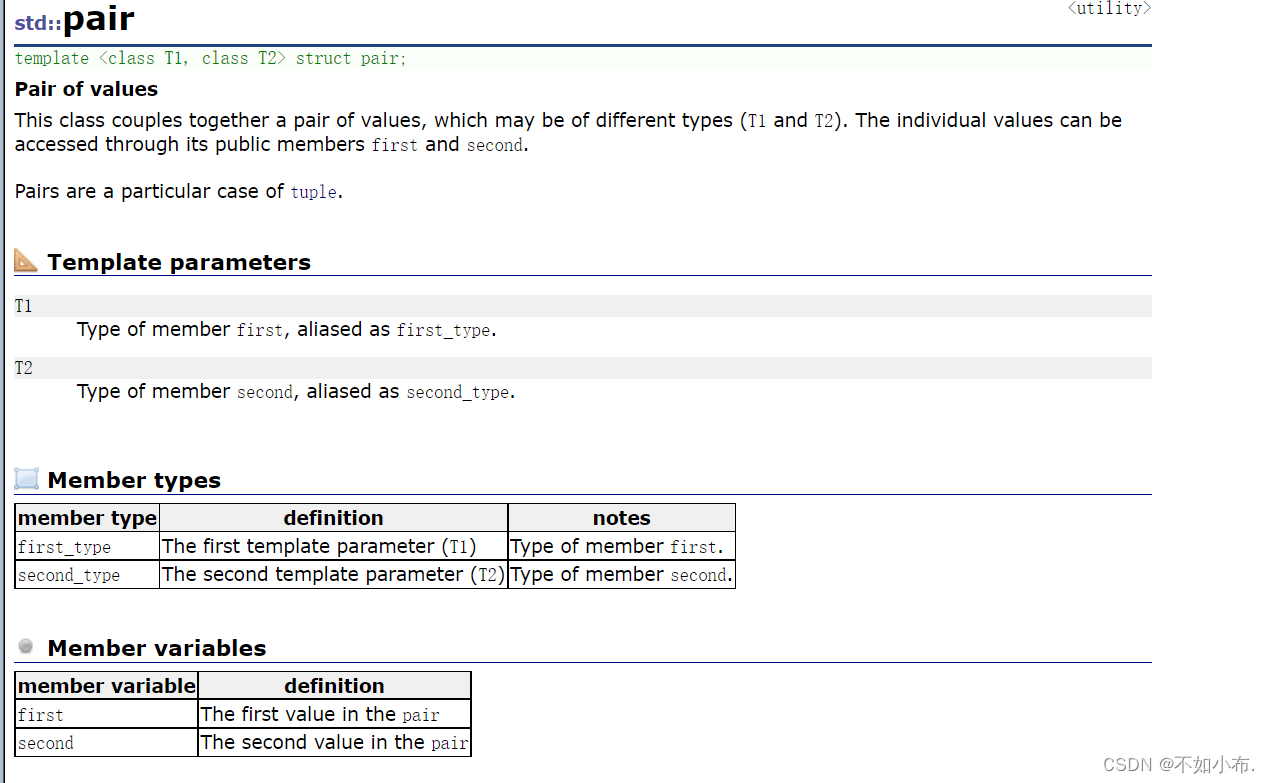
pair的文档介绍
它就是一个结构体,里面有两个成员变量。
接下来我们就来看红黑树的封装。那么第一个问题就来了,我们实现的红黑树是<K,V>结构,而set是< K >结构,map是<K,V>结构,这要如何进行区分呢?这是从底层上看的,在外层看就是你是传< K >,还是传<K,V>,也就是传一个参数还是传两个参数。
而此时对于<K,V>我们就可以用一个pair来存放,如此封装一下它就变成了传一个模板参数了。一个是< K >,另一个是pair<K,V>。(此时这里的pair<K,V>是一个整体噢,参数是一个pair类型)
而现在就将问题转化成了:给模板参数传的都是一个,只是类型不同。而此时我们的红黑树还是<K,V>结构,所以我们就要修改一下我们的模板参数。
template<class T>
struct RBTreeNode
{
RBTreeNode<T>* _left;
RBTreeNode<T>* _right;
RBTreeNode<T>* _parent;
T _data;
Colour _col;
RBTreeNode(const T& data)
:_left(nullptr)
,_right(nullptr)
,_parent(nullptr)
,_data(data)
,_col(RED)
{}
};
将原来的<K,V>改成< T >,因为我们已经将问题转化成了都是传一个模板参数的问题,所以可以用类模型让编译器自己推到传的是< K >,还是pair<K,V>。
但是问题又来了,我们之前在比较大小的时候是已经知道它是< K >,还是<K,V>结构了,因此可以直接比较大小,但是现在的类型可能是< K >,也可能是pair<K,V>,它们两个的比较方式是不同的(虽然pair中也是实现了比较功能,但是与这个地方的比较逻辑不太符合)。因此我们还需要处理内部比较数据大小的问题。那就需要再介绍一个知识点了——仿函数。
4.1 仿函数
仿函数的作用是用来在特定场合处理数据用的,它是一个类,类中只实现了()的重载,其功能可以根据不同的问题来书写代码(其实在C++模板进阶中示例代码中的比较函数,就是一种仿函数,它的功能是用来处理数据的比较)。比如拿上面的问题来说,我们现在是因为同一份代码中由于传入的数据类型不一样,而导致了在与数据比较时无法正常进行。比如传入的K是int,比较多数据是int,这没问你,而如果类型是pair呢?它怎么跟int,类型比较?
因此我们可以实现一个仿函数,让它可以返回自己的内部数据,K的话就返回K就好了,如果是pair的话就返回pair中的第一个成员变量。
namespace WY
{
template<class K>
class set
{
public:
struct SetKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
private:
RBTree<K, K, SetKeyOfT> _t;
};
}
namespace WY
{
template<class K, class V>
class map
{
public:
struct MapKeyOfT
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
private:
RBTree<K, pair<const K, V>, MapKeyOfT> _t;
};
}
有人可能会疑惑为什么在传模板参数的时候还要再传一个K,明明传一个它们本身的类型,再传一个它们的仿函数不就可以了吗?为什么还要传一个K呢?
这是因为对于map中,如果想要查找一个数据,一般都是通过K,来查找V的,因此它的查找函数的形参就是K类型的,所以在这里还需要将pair中的第一个成员变量的类型再传一次。而set中也传仅仅是为了与map保持形式上的一致罢了。
// set->RBTree<K, K, SetKeyOfT> _t;
// map->RBTree<K, pair<const K, T>, MapKeyOfT> _t;
template<class K, class T, class KeyOfT>
class RBTree
{
Node* cur = _root;
Node* parent = nullptr;
//仿函数的对象
KeyOfT kot;
while (cur)
{
//这里通过仿函数就可以很好的处理数据类型不同无法比较的问题了
if (kot(cur->_data) < kot(data))
{
parent = cur;
cur = cur->_right;
}
else if (kot(cur->_data) > kot(data))
{
parent = cur;
cur = cur->_left;
}
else
{
return make_pair(cur, false);
}
}
}
因为重载的是(),在使用时就像是调用函数一样,所以叫做仿函数。
4.2 迭代器封装
主要是需要说一下迭代器++的实现,其他部分与list迭代器封装相差无几。
++实际上也就是要模拟一下中序的过程,我们来分析几种过程。
- 当前节点右孩子为空,并且它是它父亲节点的左孩子,那么++之后就是它的父亲节点。
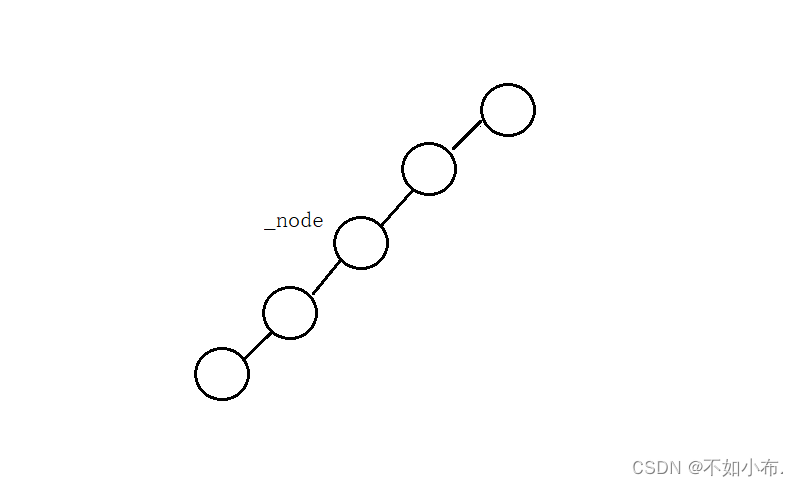
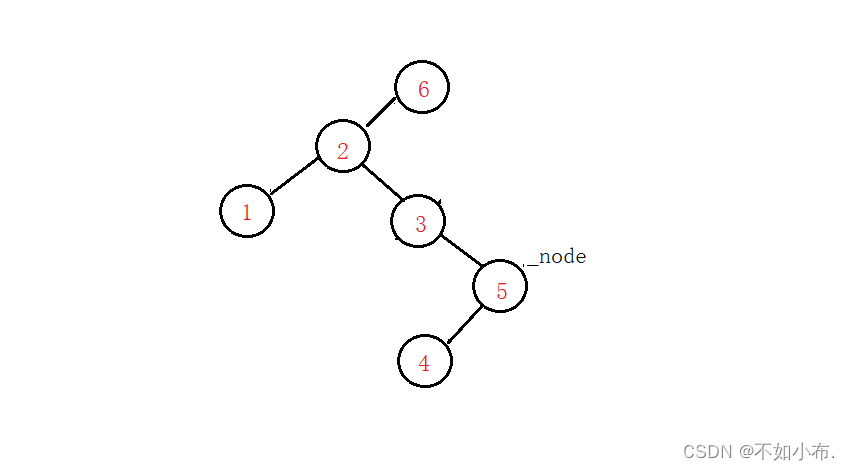
- 当前节点的右孩子为空,并且它是它父亲节点的右孩子,那么++之后应该是…看图吧,文字描述太费劲…,图中的数字就是中序遍历它们的顺序,从小到大。当前节点是5,它++之后应该就是节点6,也就是不断往上走,直到当前节点是它父亲节点的左孩子。
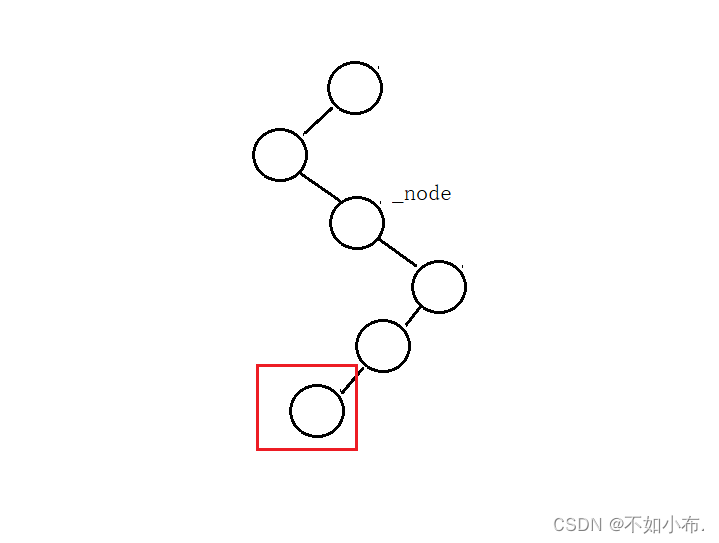
- 当前节点的右孩子不为空,直接找到右子树中的最左节点就好了。
代码:
Self& operator++()
{
if (_node->_right == nullptr)
{
Node* cur = _node;
Node* parent = cur->_parent;
while (parent && parent->_right == cur)
{
cur = parent;
parent = parent->_parent;
}
_node = parent;
}
else
{
// 下一个就是右子树的最左节点
Node* cur = _node->_right;
while (cur->_left)
{
cur = cur->_left;
}
_node = cur;
}
return *this;
}
4.3 map的operator[ ]
V& operator[](const K& key)
{
pair<iterator, bool> ret = insert(make_pair(key, V()));
return ret.first->second;
}
如果当前值不存在,那么就插入当前值;如果存在就返回当前值(K)所对应的(V)的引用。
5.代码实现
这里我只张贴经过修改后的部分,其他没改过的代码就不在这里呈现了。
5.1 MySet.h
#pragma once
#include"RBTree.h"
namespace WY
{
template<class K>
class set
{
public:
struct SetKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
typedef typename RBTree<K, K, SetKeyOfT>::const_iterator iterator;
typedef typename RBTree<K, K, SetKeyOfT>::const_iterator const_iterator;
iterator begin() const
{
return _t.begin();
}
iterator end() const
{
return _t.end();
}
pair<iterator, bool> insert(const K& key)
{
return _t.insert(key);
}
private:
RBTree<K, K, SetKeyOfT> _t;
};
}
5.2 MyMap.h
#pragma once
#include"RBTree.h"
namespace WY
{
template<class K, class V>
class map
{
public:
struct MapKeyOfT
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
typedef typename RBTree<K, pair<const K, V>, MapKeyOfT>::iterator iterator;
typedef typename RBTree<K, pair<const K, V>, MapKeyOfT>::const_iterator const_iterator;
iterator begin()
{
return _t.begin();
}
iterator end()
{
return _t.end();
}
V& operator[](const K& key)
{
pair<iterator, bool> ret = insert(make_pair(key, V()));
return ret.first->second;
}
pair<iterator, bool> insert(const pair<K, V>& kv)
{
return _t.insert(kv);
}
private:
RBTree<K, pair<const K, V>, MapKeyOfT> _t;
};
}
5.3 RBTree.c
template<class T>
struct RBTreeNode
{
RBTreeNode<T>* _left;
RBTreeNode<T>* _right;
RBTreeNode<T>* _parent;
T _data;
Colour _col;
RBTreeNode(const T& data)
:_left(nullptr)
,_right(nullptr)
,_parent(nullptr)
,_data(data)
,_col(RED)
{}
};
template<class T,class Ref,class Ptr>
struct __Treeiterator
{
typedef RBTreeNode<T> Node;
typedef __Treeiterator<T, Ref, Ptr> Self;
Node* _node;
__Treeiterator(Node* node)
:_node(node)
{}
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &_node->_data;
}
Self& operator++()
{
if (_node->_right == nullptr)
{
Node* cur = _node;
Node* parent = cur->_parent;
while (parent && parent->_right == cur)
{
cur = parent;
parent = parent->_parent;
}
_node = parent;
}
else
{
// 下一个就是右子树的最左节点
Node* cur = _node->_right;
while (cur->_left)
{
cur = cur->_left;
}
_node = cur;
}
return *this;
}
bool operator!=(const Self& s)
{
return _node != s._node;
}
bool operator==(const Self& s)
{
return _node == s._node;
}
};
// set->RBTree<K, K, SetKeyOfT> _t;
// map->RBTree<K, pair<const K, T>, MapKeyOfT> _t;
template<class K, class T, class KeyOfT>
class RBTree
{
typedef RBTreeNode<T> Node;
public:
typedef __Treeiterator<T, T&, T*> iterator;
typedef __Treeiterator<T, const T&, const T*> const_iterator;
iterator begin()
{
Node* cur = _root;
while (cur->_left)
{
cur = cur->_left;
}
return cur;
}
iterator end()
{
return nullptr;
}
const_iterator begin() const
{
Node* cur = _root;
while (cur->_left)
{
cur = cur->_left;
}
return cur;
}
const_iterator end() const
{
return nullptr;
}
pair<Node*, bool> insert(const T& data)
{
if (_root == nullptr)
{
_root = new Node(data);
_root->_col = BLACK;
return make_pair(_root,true);
}
Node* cur = _root;
Node* parent = nullptr;
KeyOfT kot;
while (cur)
{
if (kot(cur->_data) < kot(data))
{
parent = cur;
cur = cur->_right;
}
else if (kot(cur->_data) > kot(data))
{
parent = cur;
cur = cur->_left;
}
else
{
return make_pair(cur, false);
}
}
cur = new Node(data);
Node* newnode = cur;
if (kot(parent->_data) > kot(data))
{
parent->_left = cur;
cur->_parent = parent;
}
else
{
parent->_right = cur;
cur->_parent = parent;
}
while (parent && parent->_col == RED)
{
Node* uncle = nullptr;
Node* grandparent = parent->_parent;
if (parent == grandparent->_left)
{
uncle = grandparent->_right;
}
else
{
uncle = grandparent->_left;
}
//叔叔存在且为红
if (uncle && uncle->_col == RED)
{
parent->_col = uncle->_col = BLACK;
grandparent->_col = RED;
cur = grandparent;
parent = cur->_parent;
}
//叔叔不存在或者存在且为黑
else
{
if (parent == grandparent->_left && cur == parent->_left)
{
//右旋
RotateR(grandparent);
parent->_col = BLACK;
grandparent->_col = RED;
}
else if (parent == grandparent->_left && cur == parent->_right)
{
//先左旋,再右旋
RotateL(parent);
RotateR(grandparent);
cur->_col = BLACK;
grandparent->_col = RED;
}
else if (parent == grandparent->_right && cur == parent->_right)
{
//左旋
RotateL(grandparent);
parent->_col = BLACK;
grandparent->_col = RED;
}
else
{
//先右旋,再左旋
RotateR(parent);
RotateL(grandparent);
cur->_col = BLACK;
grandparent->_col = RED;
}
break;
}
}
_root->_col = BLACK;
return make_pair(newnode,true);
}
}
总结
关于红黑树的封装,比较复杂,它是一层又套了一层,所以看起来比较混乱,但是仔细了解其中的过程之后就会发现其实也不过如此,对于封装的部分,在后面的哈希封装时还会再梳理一次。希望本章内容能对大家有所帮助。
如果大家发现有什么错误的地方或者有什么问题,可以私信或者评论区指出喔。我会继续深入学习C++,希望能与大家共同进步,那么本期就到此结束,让我们下期再见!!觉得不错可以点个赞以示鼓励!!















 3564
3564











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











