







来都来了点个赞再走呗🌹🌹🌹🌹🌹🌹🌹
前言
希望每一步都可以自己手敲尝试一下
一、导入依赖(有时候会爆红鼠标放上面会提示下载一下就好 了)
import urllib.error
import urllib.request二、发送请求
response = urllib.request.Request(url='https://www.bilibili.com/')
r=urllib.request.urlopen(response) #拿到爬取的数据
html=r.read() #读取拿到的数据
html=html.decode('utf-8') #设置编码
print(html)成功拿到数据

但是这种会有一个问题当你访问有反爬机制的网站的时候就会报错
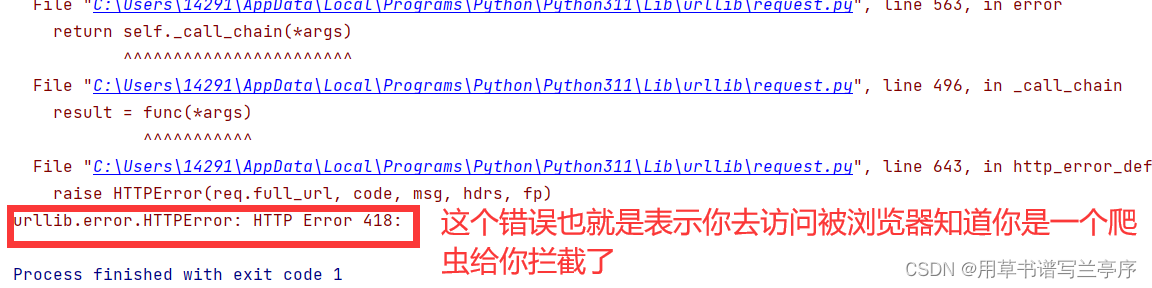
所以这个时候我们就要设置请求头
请求头是什么:


我们要做的就是设置这个user-Agent,因为爬虫不设置请求头的时候就会傻傻的告诉浏览器 我是一个爬虫你来拦截我呀!

设置请求头我们就只要现在本地访问一次在网络中找到这个参数
进到页面按F12进入网络,再次刷新网页就会出现很多请求,我们随便点击一个请求都可以,然后往下面拉找到User-Agent我们只要复制后面的字符串就好了。

拿到这个参数,但是在代码中要写成键值对的形式 key-value

请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.35"
}
response = urllib.request.Request(url='https://movie.douban.com/',headers=headers)
#在访问参数中加入headers参数对应的值就是你上面拿到的值再次运行就可以拿到网页的源代码了

完整代码
import urllib.request
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.35"
}
response = urllib.request.Request(url='https://movie.douban.com/',headers=headers)
r=urllib.request.urlopen(response)
print(r.headers)
html=r.read()
html=html.decode('utf-8')
print(html)三、解析数据
1.引入依赖
from bs4 import BeautifulSoup2.使用
2.1为了方便观察我们把刚刚拿到的html代码写入html文件中
with open("./test.html", "w",encoding="utf-8") as f:
f.write(html)
f.close()2.2在开发者模式下找到对应的html元素
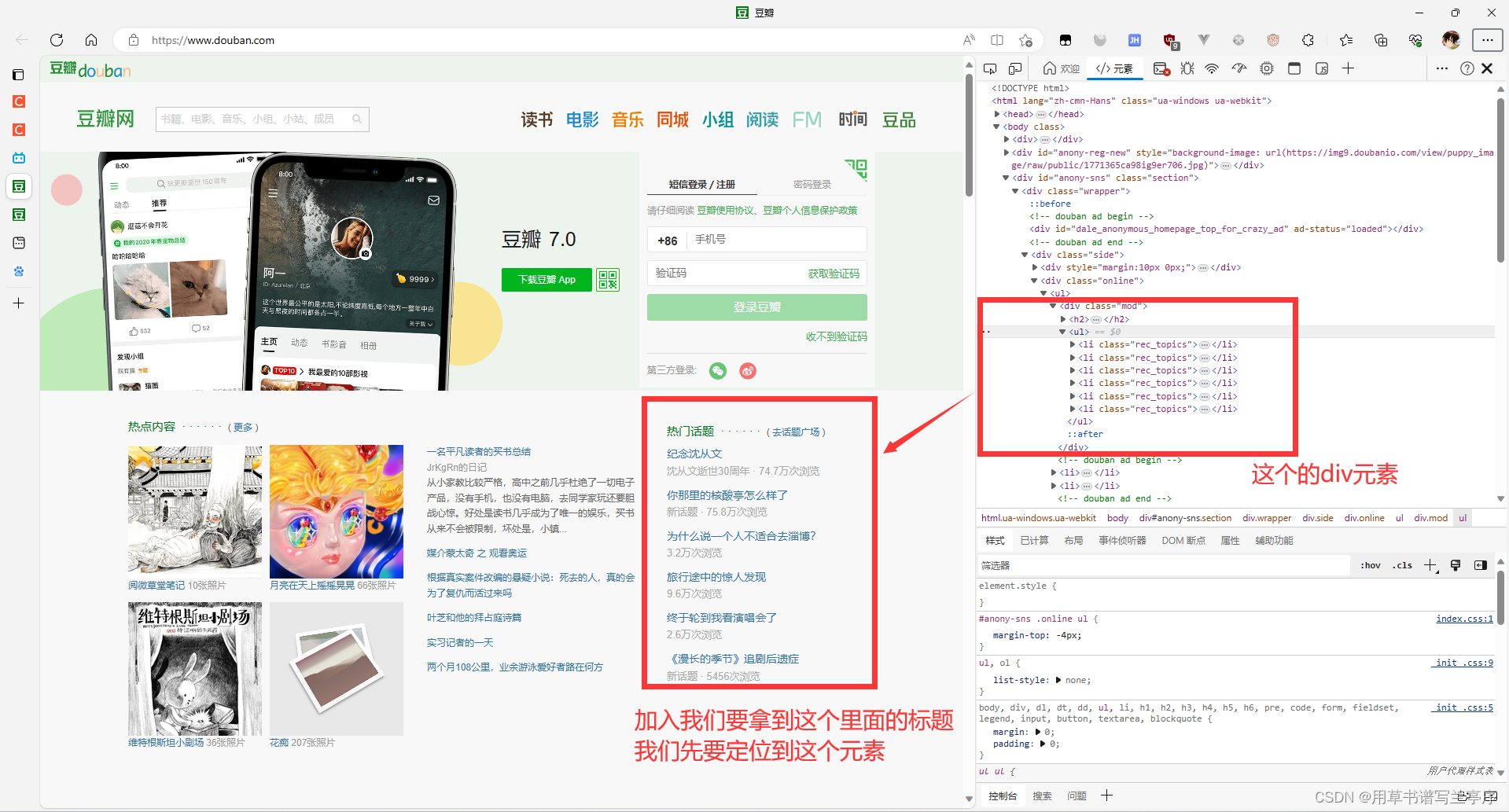
2.3获取从html元素中获取到对应我们需要的html元素
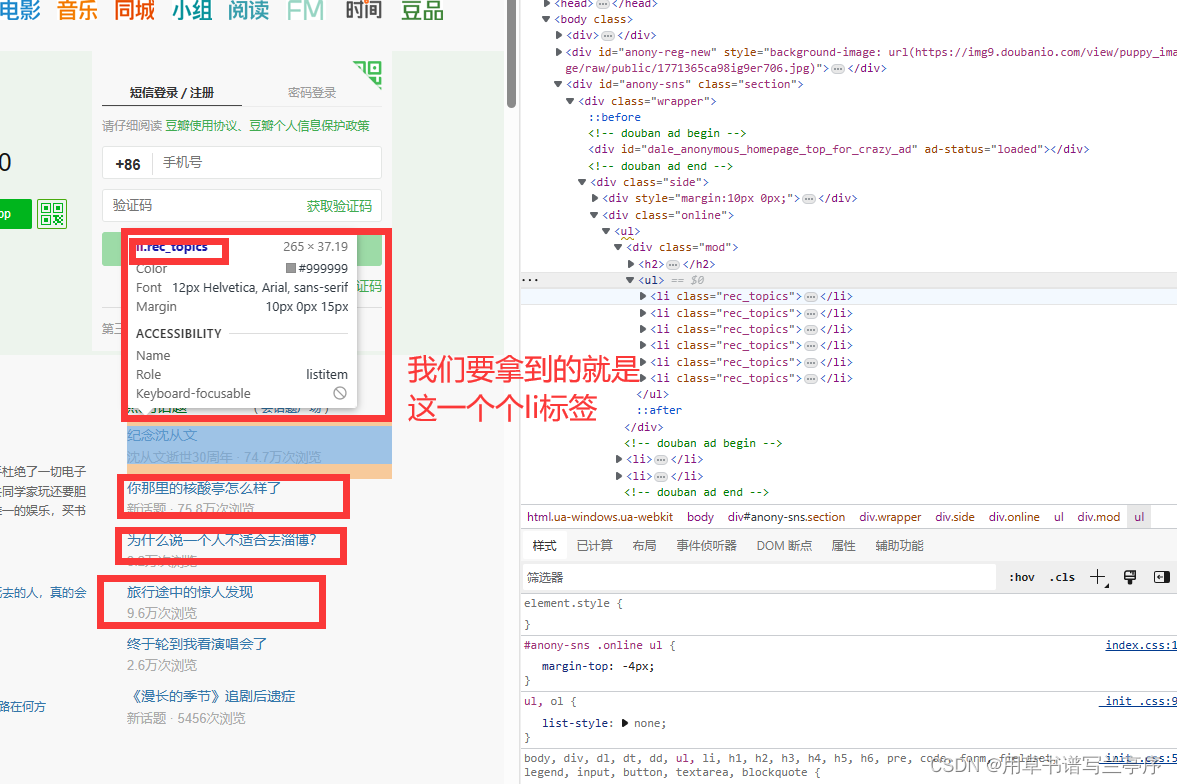
2.4使用Beausoup
soup = BeautifulSoup(html, "html.parser") #解析字符串,直接用就好了不要知道是什么意思
for item in soup.find_all("li", class_="rec_topics"): #find_all函数,第一个参数是这是什么标签,第二个参数是class参数的名字(可以直接在F12开发者模式下选中看到)
print(item)拿到了一个一个的li标签

2.5拿到标签中的文字
第一步:我们首先要观察我们需要的东西在元素的什么地方,就好比我们现在要拿到的是纪念沈从文,我们可以很明显的看到纪念沈从文是在a标签中的文字
第二步:所以我们就可以直接使用方法了
item.find("a", class_="rec_topics_name").text #find方法找到class名为rec_topics_name的a标签,就和上面的find_all一个道理这样子我们就可以拿到名字了

这是一种简单的方法,但是还是有一些情况是不可以这样直接拿到的我们就必须要用正则表达式的方法,正则表达式我会用最简单的方式告诉你怎么用
3.正则表达式的使用
3.1引入依赖
import re3.2创建正则表达式
先分析这个里面所有的都是有一个统一的格式
<span class="rec_topics_subtitle">*******</span>
我们要做的就是拿到*******这个里面的内容我们就是要匹配这个里面的内容我们就可以直接把内容替换为(.*?)就可以匹配到里面的文字了

#创建正则表达式对象(规则,字符串模式)
find = re.compile(r'<span class="rec_topics_subtitle">(.*?)</span>')3.3使用正则表达式
re.findall(find,str(item)) #传入的参数第一个是正则表带是,第二个是你刚刚通过beausoup获取到的然后遍历拿到的单一html代码段也就可以拿到了里面的数据,但是要注意拿到的是一个数组噢

4.进阶使用
4.1观察url
有的时候很多数据都是分页查询的我们不可能写多个去拿到每一个的参数,要是两页三页的还好但是你要拿到一百页的数据,不仅耦合度很高,而且写下来也很麻烦,我们就用豆瓣网的电影排行做例子吧
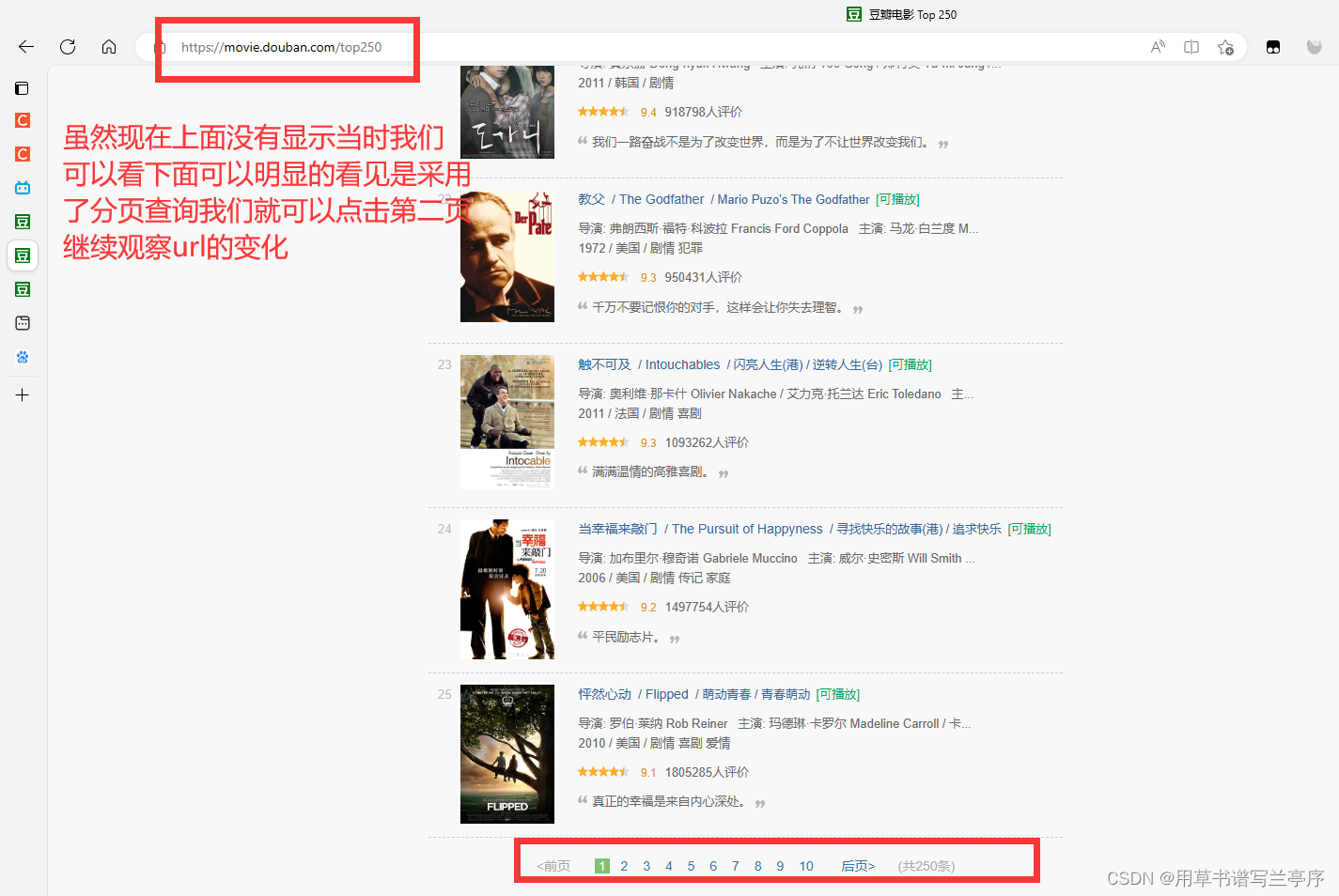
点击第二页
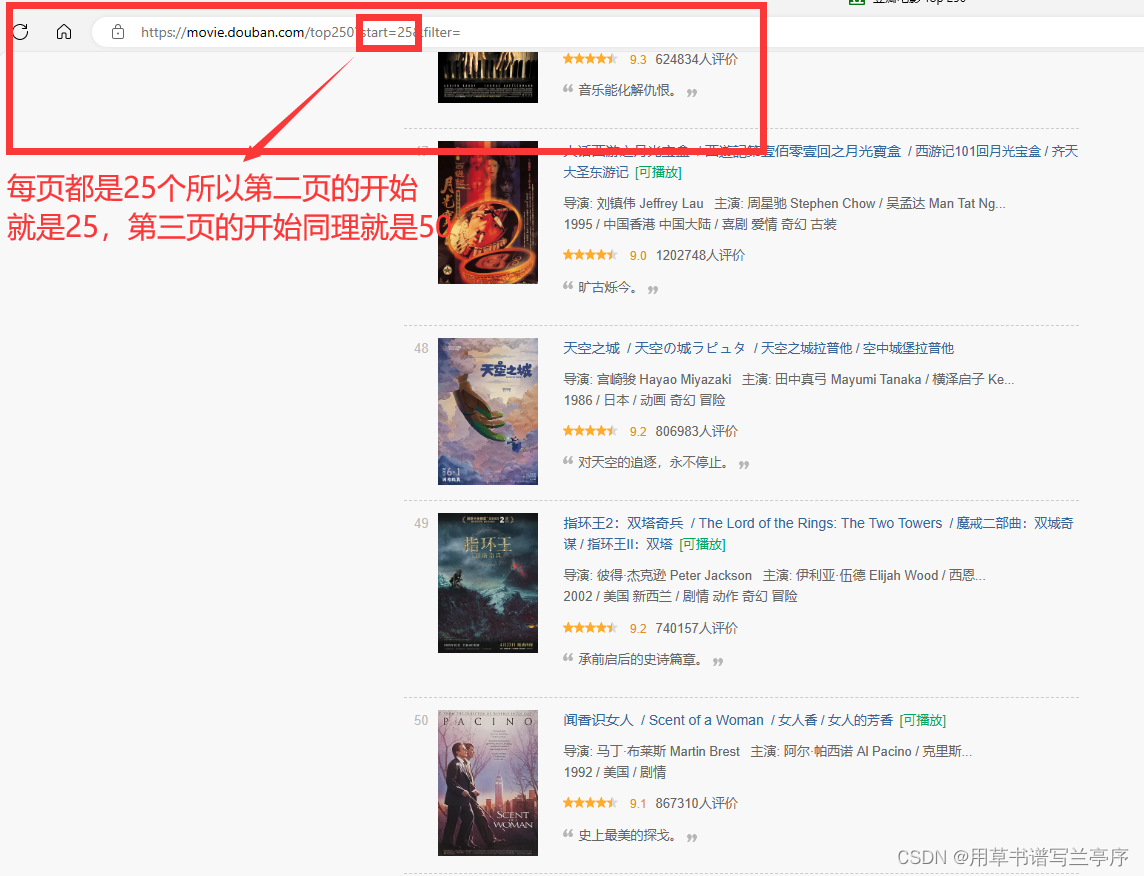
4.2动态url
baseurl = "https://movie.douban.com/top250?start=" # 基础的你要爬取的网页
for i in range(0,10):
url =baseurl + str(i*25) #str(i*25)也就是其实的数字但是我们要转化为syring类型的才可以使用+添加到字符串之后之后的步骤就和前面的一样啦
5.步骤总结
提前步骤(引入依赖库)常见使用的
import re
import urllib.request
from bs4 import BeautifulSoup第一步:设置url并且观察是不是分页查询分页查询的要用动态url噢
第二步:设置请求头,并且使用urllib.request访问并且拿到参数
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.35"
}
response = urllib.request.Request(url='https://www.douban.com/',headers=headers)
r=urllib.request.urlopen(response)
html=r.read()
html=html.decode('utf-8')第三步:把从浏览器拿到的源代码解析成beautifulsoup
soup = BeautifulSoup(html, "html.parser")第四步:soup找到总结需要的div片段,因为我们需要爬取的数据很大的概率上来说是有很大的重复性的,所以就有div片段相似的情况我们就可以直接的使用到find_all方法找到我们需要数据的重复的div或者li标签的片段,而且这种一般都是有class属性的,所以我们就可以使用到find_all方法
soup.find_all("li", class_="rec_topics")第五步:我们可以使用for循环遍历上面一步拿到的数组,然后就对其中的一个元素进行操作,这个地方一个还可以记起来有两种方法吧第一种是直接用元素的find方法,第二种是用正则表达式的方法,这个地方有点忘记的话可以去看前面的
第六步:把拿到的数据存入数组或者对应的数据类型中
最后就是自己尝试一下获取到豆瓣图书的前100条评论的内容(做完了可以问我对不对,不会也可以问我)

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











