






使用gnome-extensions list 来启用桌面图标
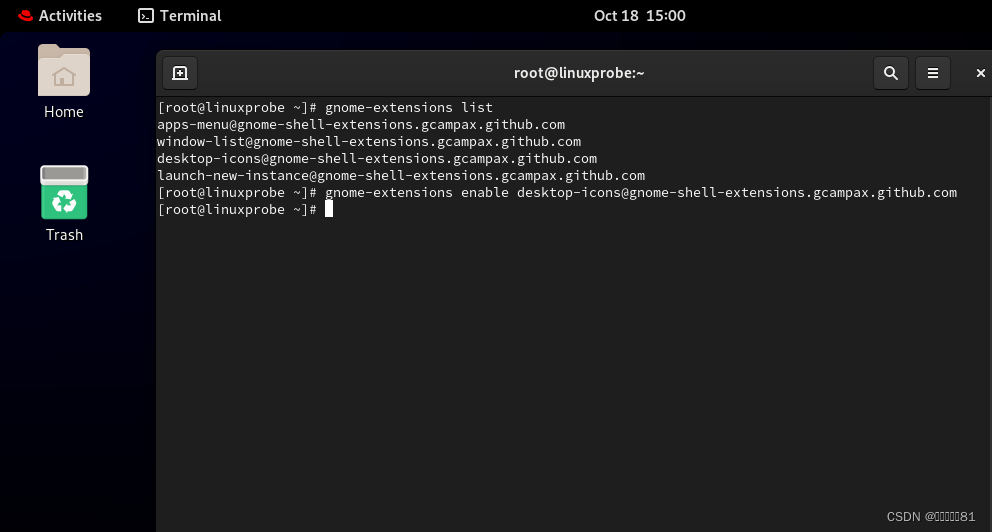
取消图标用disable
![]()
使用登录窗口的设置: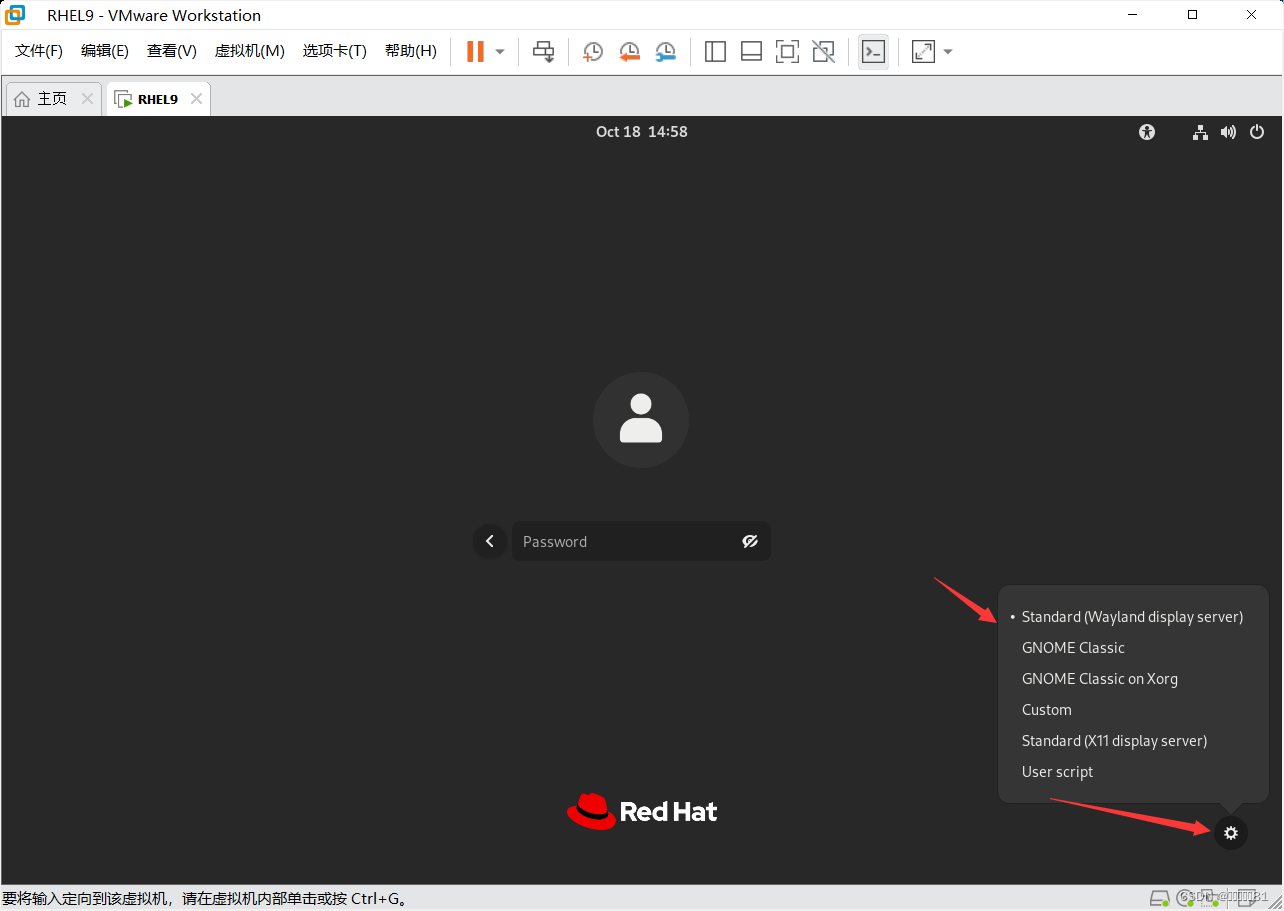
一、Linux基础命令
Linux命令格式: 命令名称 [命令参数] 命令对象;
注意:命令名称、命令参数与命令对象之间要用空格进行分隔,且字母严格区分大小写。
命令名称:表达想要做的事情
命令参数:可以用长格式(man --help)也可以用短格式 (man -help)
命令对象:一般指要处理的文件、命令、用户等资源名称
man 命令中常用按键及其作用
空格键 向下翻一页
PaGe down 向下翻一页
PaGe up 向上翻一页
home 直接前往首页
end 直接前往尾页
/ 从上至下搜索某个关键词,如“/linux”
? 从下至上搜索某个关键词,如“?linux”
n 定位到下一个搜索到的关键词
N 定位到上一个搜索到的关键词
q 退出帮助文档
使用Tab键 来让命令补全 如:re<Tab 键><Tab 键>;就会显示所有以re开头的命令
Ctrl+C:当同时按下键盘上的 Ctrl 和字母 C 的时候,意味着终止当前进程的运行。
Ctrl+D: 当同时按下键盘上的 Ctrl 和字母 D 的时候,表示键盘输入结束。
Ctrl+l:当同时按下键盘上行的 Ctrl 和字母 l 的时候,会清空当前终端中已有的内容(相当于清屏操作)
Ctrl+A:跳转到首行
Ctrl+E:跳转到行尾
常用系统工作命令
1.echo命令
echo
命令用于在终端设备上输出字符串或变量提取后的值,语法格式为“
echo [
字符串] [$
变量
]
”。
执行“
echo
字符串” 或“echo $
变量”都行,其中
$
符号的意思是提取变量的实际值,以便后续的输出操作。

使用“
$
变量”的方式提取出变量
SHELL
的值,并将其输出到屏幕上:
注意大小写
2.date命令
date
命令用于显示或设置系统的时间与日期,语法格式为“
date [+
指定的格式
]
”。
date 命令中的参数及其作用
%S 秒(00~
59
)
%M 分钟(00~
59
)
%H 小时(00~
23
)
%I 小时(00~
12
)
%m 月份(1
~
12
)
%p 显示出 AM
或
PM
%a 缩写的工作日名称(例如,Sun
)
%A 完整的工作日名称(例如,Sunday
)
%b 缩写的月份名称(例如,Jan
)
%B 完整的月份名称(例如,January
)
%q 季度(1
~
4
)
%y 简写年份(例如,20
)
新手必须掌握的 Linux 命令
%Y 完整年份(例如,2020
)
%d 本月中的第几天
%j 今年中的第几天
%n 换行符(相当于按下回车键)
%t 跳格(相当于按下 Tab
键)
按照默认格式查看当前系统时间的
date
命令如下所示:
按照“年
-
月
-
日 小时:
分钟
:
秒”的格式查看当前系统时间的
date
命令如下所示
按%F日期 %T时间
将系统的当前时间设置为
2021
年
11
月
1
日
8
点
30
分的
date
命令如下所示:

date
命令中的参数
%j
可用来查看今天是当年中的第几天。这个参数能够很好地区分备份
时间的早晚,即数字越大,越靠近当前时间。
![]()
3.timedatectl命令
timedatectl
命令用于设置系统的时间,英文全称为“
time date control”,语法格式为“
timedatectl [
参数
]
”。
发现电脑时间跟实际时间不符?如果只差几分钟的话,我们可以直接调整。但是,如果差几个小时,那么除了调整当前的时间,还有必要检查一下时区了。
timedatectl
命令中的参数以及作用
status 显示状态信息
list-timezones 列出已知时区
set-time 设置系统时间
set-timezone 设置生效时区
查看系统时间与时区:

如果查到的时区不是上海(
Asia/Shanghai
),可以手动进行设置:
![]()
如果时间还是不正确,可再手动修改系统日期

如果不能修改:
需要关闭NTP server:

而如果想修改时间的话,也很简单

4.reboot命令
reboot
命令用于重启系统,输入该命令后按回车键执行即可。
由于重启计算机这种操作会涉及硬件资源的管理权限,因此最好是以
root 管理员的身份来重启,普通用户在执行该命令时可能会被拒绝。
![]()
5.poweroff命令
poweroff
命令用于关闭系统,输入该命令后按回车键执行即可。
与上面相同,该命令也会涉及硬件资源的管理权限,因此最好还是以
root 管理员的身份来关闭电脑,其命令如下:
![]()
6.wget命令
wget
命令用于在终端命令行中下载网络文件,英文全称为“
web get
”,语法格式为“wget[
参数
]
网址”。
借助于
wget
命令,可以无须打开浏览器,直接在命令行界面中就能下载文件。
wget 命令中的参数以及作用
-b 后台下载模式
-P 下载到指定目录
-t 最大尝试次数
-c 断点续传
-p 下载页面内所有资源,包括图片、视频等
-r 递归下载
链接网络
通过nmtui编辑设置自动配置IP地址


激活一下

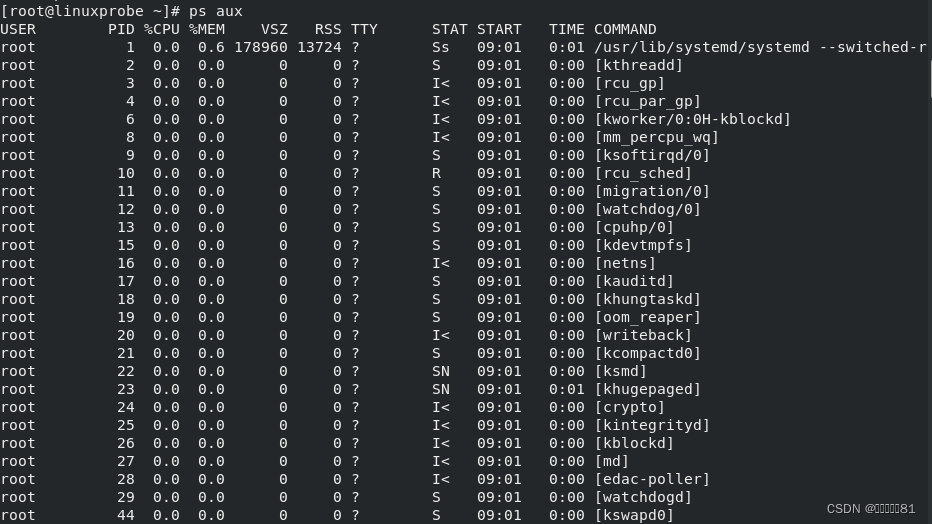
7.ps命令
ps
命令用于查看系统中的进程状态,英文全称为“
processes
”,语法格式为“
ps [参数
]
”。
ps 命令中的参数以及作用
-a 显示所有进程(包括其他用户的进程)
-u 用户以及其他详细信息
-x 显示没有控制终端的进程
在
Linux
系统中有
5
种常见的进程状态,分别为运行、中断、不可中断、僵死与停止,其各
自含义如下所示。
R(运行):进程正在运行或在运行队列中等待。
S(中断):进程处于休眠中,当某个条件形成后或者接收到信号时,则脱离该状态。
D(不可中断):进程不响应系统异步信号,即便用
kill 命令也不能将其中断。
Z(僵死):进程已经终止,但进程描述符依然存在
,
直到父进程调用
wait4()系统函数后将进程释放。
T(停止):进程收到停止信号后停止运行。
除了上面
5
种常见的进程状态,还有可能是高优先级(
<
)、低优先级(
N)、被锁进内存(
L)、包含子进程(s)以及多线程(l
)这
5
种补充形式。
8.pstree命令
pstree
命令用于以树状图的形式展示进程之间的关系,英文全称为“
process tree”,输入该命令后按回车键执行即可。-p显示进程ID号

9.top命令
top
命令用于动态地监视进程活动及系统负载等信息,输入该命令后按回车键执行即可。
前面介绍的命令都是静态地查看系统状态,不能实时滚动最新数据,而
top 命令能够动态地查看系统状态,因此完全可以将它看作是
Linux
中“强化版的
Windows
任务管理器”
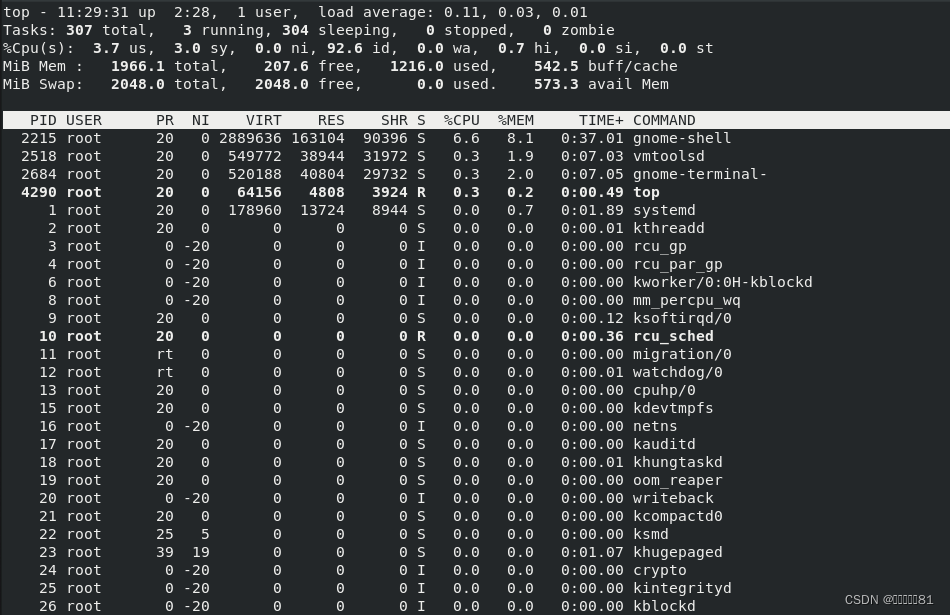
top
命令执行结果的前
5
行为系统整体的统计信息,其所代表的含义如下。
第
1
行:系统时间、运行时间、登录终端数、系统负载(
3
个数值分别为
1
分钟、5分钟、
15
分钟内的平均值,数值越小意味着负载越低)。
第
2 行:进程总数、运行中的进程数、睡眠中的进程数、停止的进程数、僵死的进程数。
第
3 行:用户占用资源百分比、系统内核占用资源百分比、改变过优先级的进程资源百分比、空闲的资源百分比等。其中数据均为
CPU 数据并以百分比格式显示,例如“
99.9 id
”意味着有
99.9%
的
CPU
处理器资源处于空闲。
第
4
行:物理内存总量、内存空闲量、内存使用量、作为内核缓存的内存量
第 5
行:虚拟内存总量、虚拟内存空闲量、虚拟内存使用量、已被提前加载的内存量。
注:按q退出
10.nice命令
nice
命令用于调整进程的优先级,语法格式为“
nice
优先级数字 服务名称”。
在
top
命令输出的结果中,
PR
和
NI 值代表的是进程的优先级,数字越低(取值范围是-20
~
19),优先级越高。在日常的生产工作中,可以将一些不重要进程的优先级调低,让紧迫的服务更多地利用
CPU
和内存资源,以达到合理分配系统资源的目的。例如将
bash 服务的优先级调整到最高:
11.pidof命令
pidof
命令用于查询某个指定服务进程的
PID
号码值,语法格式为“
pidof [
参数
]
服务名称”。
每个进程的进程号码值(
PID)是唯一的,可以用于区分不同的进程。例如,执行如下命令来查询本机上
sshd
服务程序的
PID
:

12.kill命令
kill
命令用于终止某个指定
PID
值的服务进程,语法格式为“
kill [
参数
]
进程的
PID
”
但有时系统会提示进程无法被终止,此时可以加参数
-9
,表示最高级别地强制杀死进程:
13.killall命令
killall
命令用于终止某个指定名称的服务所对应的全部进程,语法格式为“
killall [
参数
] 服务名称”。
通常来讲,复杂软件的服务程序会有多个进程协同为用户提供服务,如果用 kill 命令逐个去结束这些进程会比较麻烦,此时可以使用
killall
命令来批量结束某个服务程序带有的全部进程。
如果在系统终端中执行一个命令后想立即停止它,可以同时按下 Ctrl + C 组合键(生产环境中比较常用的一个组合键),这样将立即终止该命令的进程。或者,如果有些命令在执行时不断地在屏幕上输出信息,影响到后续命令的输入,则可以在执行命令时在末尾添加一个&
符号,这样命令将进入系统后台来执行。
14.help命令
用于提示命令需要的参数

系统状态检测命令
1.ifconfig命令
ifconfig
命令用于获取网卡配置与网络状态等信息,英文全称为“
interface config”,语法格式为“
ifconfig [
参数
] [
网络设备
]
”。
使用
ifconfig 命令来查看本机当前的网卡配置与网络状态等信息时,其实主要查看的就 是网卡名称、
inet
参数后面的
IP
地址、
ether
参数后面的网卡物理地址(又称为
MAC 地址), 以及
RX
、
TX
的接收数据包与发送数据包的个数及累计流量(即下面加粗的信息内容):

2.uname命令
uname
命令用于查看系统内核版本 -r与系统架构等信息,英文全称为“
unix name”,语法格式为“
uname [-a]
”。
在使用
uname
命令时,一般要固定搭配上-a 参数来完整地查看当前系统的内核名称、主机名、内核发行版本、节点名、压制时间、硬件名称、硬件平台、处理器类型以及操作系统名称等信息:

顺带一提,如果要查看当前系统版本的详细信息,则需要查看
redhat-release 文件,其命令以及相应的结果如下:

3.uptime命令
uptime
命令用于查看系统的负载信息,输入该命令后按回车键执行即可。
它可以显示当前系统时间、系统已运行时间、启用终端数量以及平均负载值等信息。平均负载值指的是系统在最近
1
分钟、
5
分钟、
15 分钟内的压力情况(下面加粗的信息部分),负载值越低越好:

4.free命令
free
命令用于显示当前系统中内存的使用量信息,语法格式为“
free [-h]
”。
在使用
free
命令时,可以结合使用
-h
参数以更人性化的方式输出当前内存的实时使用量信息。
第一个内存总量、已用量、空闲量、进程功效的内存量、缓存的内存量、可用量

如果不使用
-h
(易读模式)查看内存使用量情况,则默认以
KB
为单位。

5.who命令
who
命令用于查看当前登入主机的用户终端信息,输入该命令后按回车键执行即可。
登录用户名 终端设备 登录到系统的时间

6.last命令
last
命令用于调取主机的被访记录,输入该命令后按回车键执行即可。
Linux 系统会将每次的登录信息都记录到日志文件中,如果哪天想翻阅了,直接执行这条命令就行:

7.ping命令
ping
命令用于测试主机之间的网络连通性,语法格式为“
ping [
参数
]
主机地址”。
执行
ping 命令时,系统会使用
ICMP 向远端主机发出要求回应的信息,若连接远端主机的网络没有问题,远端主机会回应该信息。由此可见,
ping
命令可用于判断远端主机是否在线并且网络是否正常。
ping 命令中的参数以及作用
-c 总共发送次数
-l 指定网卡名称
-I 每次间隔时间(秒)
-W 最长等待时间(秒)
我们使用
ping
命令测试一台在线的主机(其
IP
地址为
192.168.122.10),得到的回应是这样的:


8.tracepath命令
tracepath 命令用于显示数据包到达目的主机时途中经过的所有路由信息,语法格式为“
tracepath [
参数
]
域名”。
9.netstat命令
netstat 命令用于显示如网络连接、路由表、接口状态等的网络相关信息,英文全称为“
network status
”,语法格式为“
netstat [
参数
]
”。
netstat 命令中的参数以及作用
-a 显示所有连接中的 Socket
-p 显示正在使用的 Socket 信息
-t 显示 TCP 协议的连接状态
-u 显示 UDP 协议的连接状态
-n 使用 IP 地址,不使用域名
-l 仅列出正在监听的服务状态
-i 现在网卡列表信息
-r 显示路由表信息
使用
netstat
命令显示详细的网络状况:
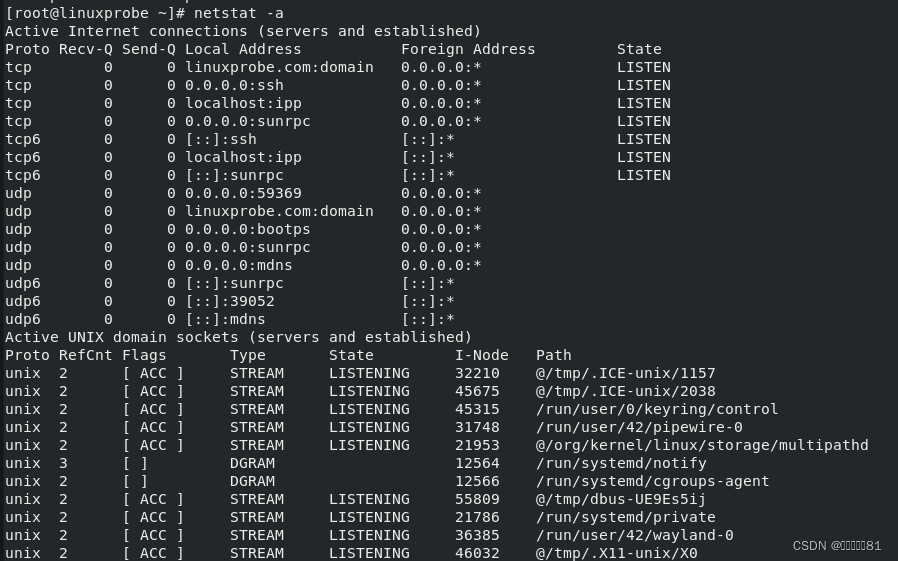
使用
netstat
命令显示网卡列表:

10.history命令
history
命令用于显示执行过的命令历史,语法格式为“
history [-c]
”。
执行
history 命令能显示出当前用户在本地计算机中执行过的最近
1000
条命令记录。如果觉得1
000
不够用,可以自定义
/etc/profile 文件中的
HISTSIZE
变量值。在使用
history
命令时,可以使用
-c
参数清空所有的命令历史记录。

可以使用“!
编码数字”的方式来重复执行某一次的命令:

历史命令会被保存到用户家目录中的
.bash
_
history
文件中。
Linux 系统中以点(.)开头的文件均代表隐藏文件,这些文件大多数为系统服务文件,可以用
cat
命令查看其文件内容:

要清空当前用户在本机上执行的
Linux
命令历史记录信息,可执行如下命令:

11.sosreport命令
sosreport
命令用于收集系统配置及架构信息并输出诊断文档,输入该命令后按回车键执行即可。
当 Linux 系统出现故障需要联系技术支持人员时,大多数时候都要先使用这个命令来简单收集系统的运行状态和服务配置信息,以便让技术支持人员能够远程解决一些小问题,抑或让他们能提前了解某些复杂问题。
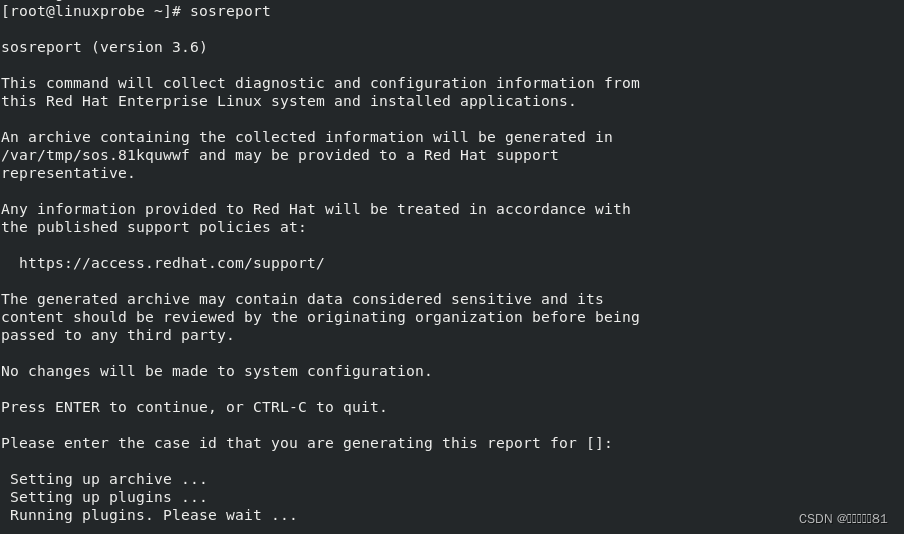
在下面的输出信息中,红框的部分是收集好的资料压缩文件以及校验码,将其发送给技术支持人员即可:

查找定位文件命令
工作目录指的是用户当前在系统中所处的位置。
1.pwd命令
pwd
命令用于显示用户当前所处的工作目录,英文全称为“
print working directory”,输入该命令后按回车键执行即可。
2.cd命令
cd
命令用于切换当前的工作路径,英文全称为“
change directory
”,语法格式为“
cd [参数
] [
目录
]
”。
可以通过
cd 命令迅速、灵活地切换到不同的工作目录。除了常见的切换目录方式,还可以使用“
cd -”命令返回到上一次所处的目录,使用“
cd..
”命令进入上级目录,以及使用“
cd~”命令切换到当前用户的家目录,抑或使用“
cd
~
username
”命令切换到其他用户的家目录
例如,使用下述的
cd
命令切换进
/etc
目录中:
使用下述命令切换到
/bin
目录中:
要返回到上一次的目录(即
/etc
目录),可执行如下命令:

可以通过下面的命令快速切换到用户的家目录:
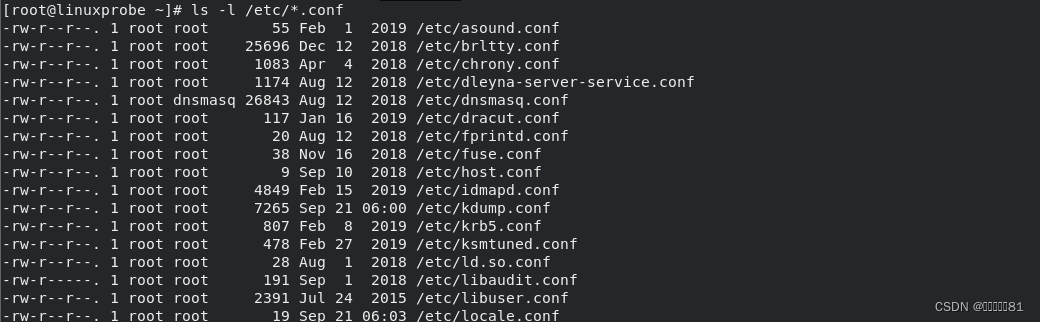
3.ls命令
ls
命令用于显示目录中的文件信息,英文全称为“
list
”,语法格式为“
ls [
参数
] [
文件名称
]
”。
使用
ls
命令的
-a 参数可以看到全部文件(包括隐藏文件),使用
-l 参数可以查看文件的属性、大小等详细信息。将这两个参数整合之后,再执行
ls 命令即可查看当前目录中的所有文件并输出这些文件的属性信息:

如果想要查看目录属性信息,则需要额外添加一个
-d 参数。例如,可使用如下命令查看/etc
目录的权限与属性信息:

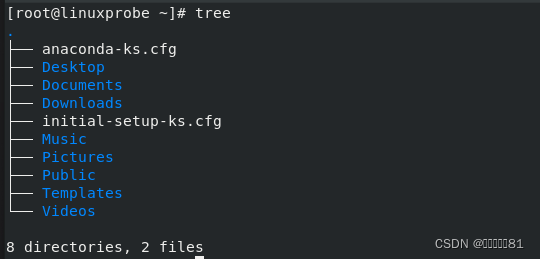
4.tree命令
tree
命令用于以树状图的形式列出目录内容及结构,输入该命令后按回车键执行即可。
虽然
ls 命令可以很便捷地查看目录内有哪些文件,但无法直观地获取到目录内文件的层次结构。比如,假如目录
A
中有个
B
,
B
中又有个
C
,那么
ls
命令就只能看到最外面的
A 目录,显然有些时候这不太够用。
tree
命令则能够以树状图的形式列出目录内所有文件的结构。
5.find命令
find
命令用于按照指定条件来查找文件所对应的位置,语法格式为“
find [
查找范围
] 寻找条件”。
在
Linux
系统中,搜索工作一般都是通过 find 命令来完成的,它可以使用不同的文件特性作为寻找条件(如文件名、大小、修改时间、权限等信息),一旦匹配成功则默认将信息显示到屏幕上。
find 命令中的参数以及作用
-name 匹配名称
-perm 匹配权限(mode 为完全匹配,
-mode
为包含即可)
-user 匹配所有者
-group 匹配所属组
-mtime -n +n 匹配修改内容的时间(-n 指
n
天以内,
+n
指
n
天以前)
-atime -n +n 匹配访问文件的时间(-n 指
n
天以内,
+n
指
n
天以前)
-ctime -n +n 匹配修改文件权限的时间(-n 指
n
天以内,
+n
指
n
天以前)
-nouser 匹配无所有者的文件
-nogroup 匹配无所属组的文件
-newer f1 !f2 匹配比文件 f1
新但比
f2
旧的文件
--type b/d/c/p/l/f 匹配文件类型(后面的字母依次表示块设备、目录、字符设备、管道、链接文件、文本文件)
-size 匹配文件的大小(+50KB为查找超过
50KB
的文件,而
-50KB
为查找小于50KB的文件)
-prune 忽略某个目录
-exec…… {}\; 后面可跟用于进一步处理搜索结果的命令(下文会有演示)
根据文件系统层次标准(
Filesystem Hierarchy Standard
)协议,
Linux 系统中的配置文件会保存到
/etc
目录中(详见第
6
章)。如果要想获取该目录中所有以
host 开头的文件列表,可以执行如下命令:

如果要在整个系统中搜索权限中包括
SUID
权限的所有文件(详见第
5 章),只需使用-4000
即可:

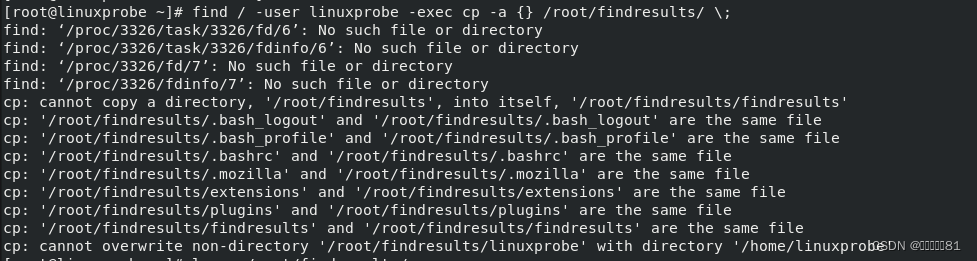
exec参数用于把
find 命令搜索到的结果交由紧随其后的命令作进一步处理。
该实验的重点是“-exec {} \;
”参数,其中的
{}
表示 find 命令搜索出的每一个文件,并且命令的结尾必须是“\;
”。完成该实验的具体命令如下:
6.locate命令
locate
命令用于按照名称快速搜索文件所对应的位置,语法格式为“
locate
文件名称”。
使用
find命令进行全盘搜索虽然更准确,但是效率有点低。如果仅仅是想找一些常见的且又知道大概名称的文件,不如试试
locate
命令。在使用
locate
命令时,先使用
updateddb命令生成一个索引库文件,这个库文件的名字是
/var/lib/mlocate/mlocate.db
,后续在使用locate命令搜索文件时就是在该库中进行查找操作,速度会快很多。
第一次使用
locate
命令之前,记得先执行
updatedb
命令来生成索引数据库,然后再进行查找:

使用
locate
命令搜索出所有包含“
whereis
”名称的文件所在的位置:

7.whereis命令
whereis命令用于按照名称快速搜索二进制程序(命令)、源代码以及帮助文件所对应的位置,语法格式为“
whereis
命令名称”。
简单来说,
whereis
命令也是基于
updatedb命令所生成的索引库文件进行搜索,它与locate命令的区别是不关心那些相同名称的文件,仅仅是快速找到对应的命令文件及其帮助文件所在的位置。
下面使用
whereis
命令分别查找出
ls
和
pwd
命令所在的位置:

8.which命令
which命令用于按照指定名称快速搜索二进制程序(命令)所对应的位置,语法格式为“
which
命令名称”。
which
命令是在
PATH变量所指定的路径中,按照指定条件搜索命令所在的路径。也就是说,如果我们既不关心同名文件(
find
与
locate),也不关心命令所对应的源代码和帮助文件(
whereis
),仅仅是想找到命令本身所在的路径,那么这个
which命令就太合适了。下面查找一下
locate
和
whereis
命令所对应的路径:

文本文件编辑命令
在Linux系统中,一切都是文件,对服务程序进行配置自然也就是编辑程序的配置文件。如果不能熟练地查阅系统或服务的配置文件,那以后工作时可就真的要尴尬了。
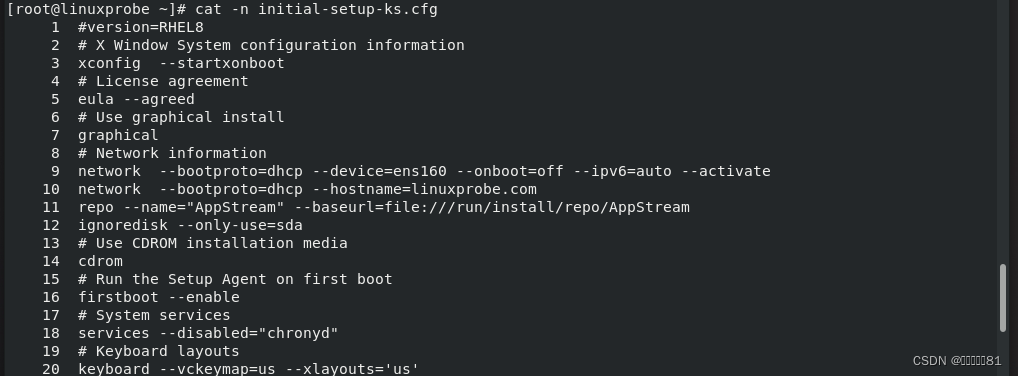
1.cat命令
cat
命令用于查看纯文本文件(内容较少的),英文全称为“
concatenate
”,语法格式为“cat [
参数
]
文件名称”。
果在查看文本内容时还想顺便显示行号的话,不妨在
cat
命令后面追加一个
-n
参数:
2.more命令
more
命令用于查看纯文本文件(内容较多的),语法格式为“
more [
参数
]
文件名称”。
more命令会在最下面使用百分比的形式来提示您已经阅读了多少内容;还可以使用空格键或回车
键向下翻页:
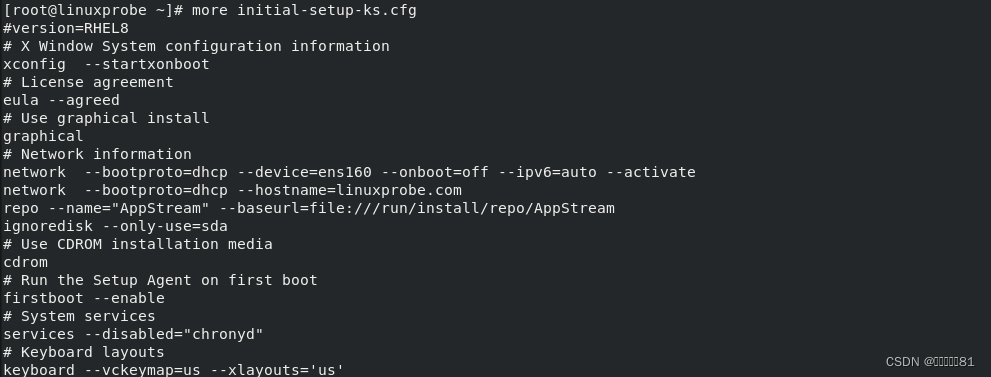

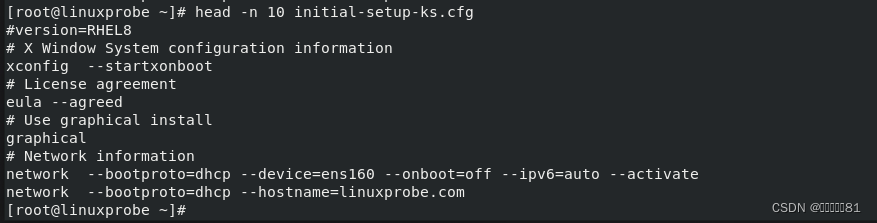
3.head命令
head
命令用于查看纯文本文件的前
N
行,语法格式为“
head [
参数
]
文件名称”。
在阅读文本内容时,谁也难以保证会按照从头到尾的顺序往下看完整个文件。如果只想查看文本中前
10
行的内容,该怎么办呢?
head
命令就能派上用场了:
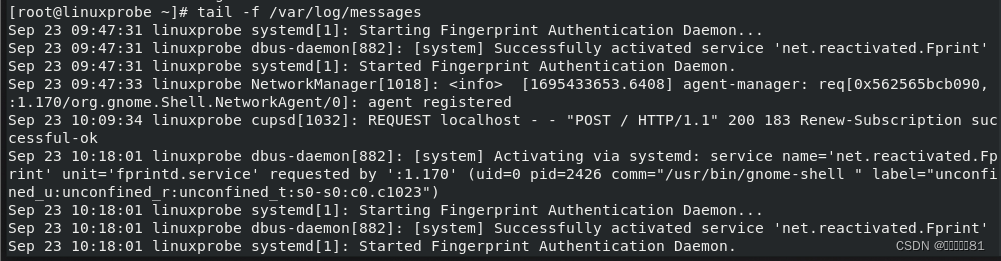
4.tail命令
tail
命令用于查看纯文本文件的后
N
行或持续刷新文件的最新内容,语法格式为“
tail [参数
]
文件名称”。

tail命令最强悍的功能是能够持续刷新一个文件的内容,当想要实时查看最新的日志文件时,这特别有用,此时的命令格式为“
tail -f
文件名称”:
5.tr命令
tr
命令用于替换文本内容中的字符,英文全称为“
translate
”,语法格式为“
tr [
原始字符] [
目标字符
]
”。
在很多时候,我们想要快速地替换文本中的一些词汇,又或者想把整个文本内容都进行替换。如果进行手工替换,难免工作量太大,尤其是需要处理大批量的内容时,进行手工替换更是不现实。这时,就可以先使用
cat
命令读取待处理的文本,然后通过管道符(详见第3章)把这些文本内容传递给
tr命令进行替换操作即可。例如,把某个文本内容中的英文全部替换为大写:修改前
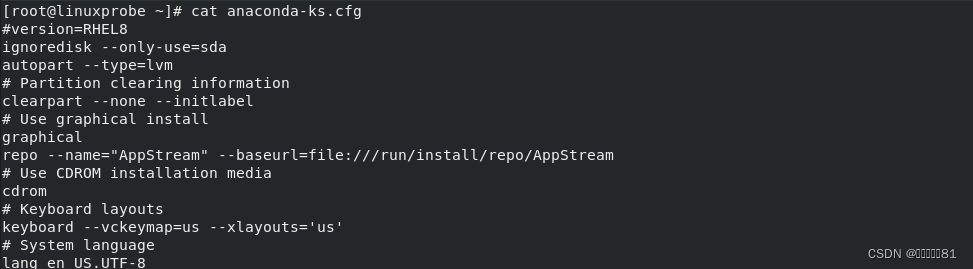
修改后:

6.wc命令
wc
命令用于统计指定文本文件的行数、字数或字节数,英文全称为“
word counts”,语法格式为“
wc [
参数
]
文件名称”。
wc 命令中的参数以及作用
-l 只显示行数
-w 只显示单词数
-c 只显示字节数
在
Linux
系统中,
/etc/passwd 是用于保存所有用户信息的文件,要统计当前系统中有多少个用户,可以使用下面的命令来进行查询,是不是很神奇:

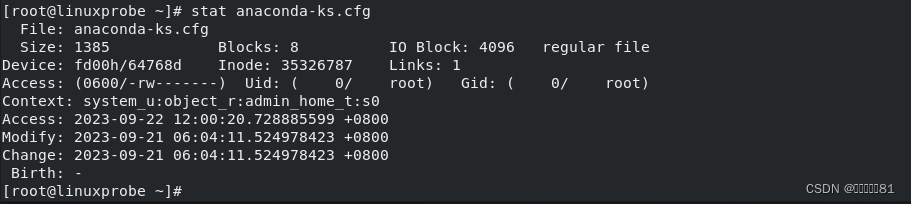
7.stat命令
stat
命令用于查看文件的具体存储细节和时间等信息,英文全称为“
status”,语法格式为“
stat
文件名称”。
Linux 系统中的文件包含
3
种时间状态,分别是
Access Time
(内容最后一次被访问的时间,简称为
Atime
),Modify Time
(内容最后一次被修改的时间,简称为
Mtime
)以及
Change Time(文件属性最后一次被修改的时间,简称为
Ctime
)。
下面使用
state
命令查看文件的这
3
种时间状态信息:
8.grep命令
grep
命令用于按行提取文本内容,语法格式为“
grep [
参数
]
文件名称”。
grep
命令两个最常用的参数:
-n 参数用来显示搜索到的信息的行号;
-v 参数用于反选信息(即没有包含关键词的所有信息行)。
grep 命令中的参数及其作用
-b 将可执行文件(binary
)当作文本文件(
text
)来搜索
-c 仅显示找到的行数
-i 忽略大小写
-n 显示行号
-v 反向选择—
仅列出没有“关键词”的行
在
Linux
系统中,
/etc/passwd 文件保存着所有的用户信息,而一旦用户的登录终端被设置成
/sbin/nologin
,则不再允许登录系统,因此可以使用
grep 命令查找出当前系统中不允许登录系统的所有用户的信息:


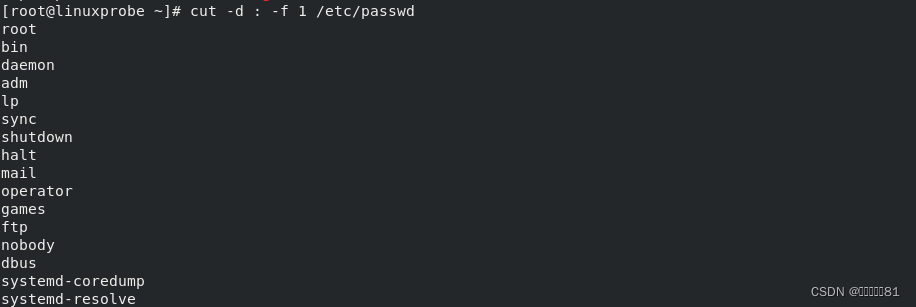
9.cut命令
cut
命令用于按“列”提取文本内容,语法格式为“
cut [
参数
]
文件名称”
一般而言,按基于“行”的方式来提取数据是比较简单的,只需要设置好要搜索的关键词即可。但是如果按“列”搜索,不仅要使用
-f
参数设置需要查看的列数,还需要使用
-d 参数来设置间隔符号。
接下来使用下述命令尝试提取出
passwd
文件中的用户名信息,即提取以冒号(:)为间
隔符号的第一列内容:
10.diff命令
diff
命令用于比较多个文件之间内容的差异,英文全称为“
different
”,语法格式为“
diff [参数
]
文件名称
A
文件名称
B
”。
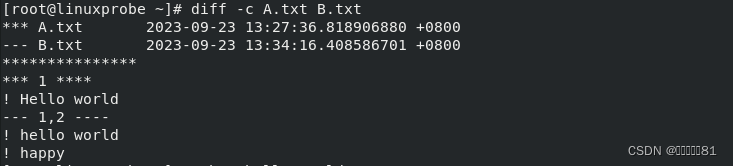
在使用
diff
命令时,不仅可以使用
--brief 参数来确认两个文件是否相同,还可以使用-c参数来详细比较出多个文件的差异之处。这绝对是判断文件是否被篡改的有力神器。例如,先使用
cat
命令分别查看
A.txt
和
B.txt
文件的内容,然后进行比较:

接下来使用
diff --brief
命令显示比较后的结果,判断文件是否相同:

最后使用带有
-c
参数的
diff
命令来描述文件内容具体的不同:
11.uniq命令
uniq
命令用于去除文本中连续的重复行,英文全称为“
unique
”,语法格式为“
uniq [
参数
] 文件名称”。
由
uniq
命令的英文全称
unique(独特的,唯一的)可知,该命令的作用是用来去除文本文件中连续的重复行,中间不能夹杂其他文本行(非相邻的默认不会去重)
—去除了重复的,保留的都是唯一的,自然也就是“独特的”“唯一的”了。
我们使用
uniq
命令对两个文本内容进行操作,区别一目了然:

12.sort命令
sort
命令用于对文本内容进行再排序,语法格式为“
sort [
参数
]
文件名称”
有时文本中的内容顺序不正确,一行行地手动修改实在太麻烦了。此时使用
sort 命令就再合适不过了,它能够对文本内容进行再次排序。
sort 命令中的参数及其作用
-f 忽略大小写
-b 忽略缩进与空格
-n 以数值型排序
-r 反向排序
-u 去除重复行
-t 指定间隔符
-k 设置字段范围
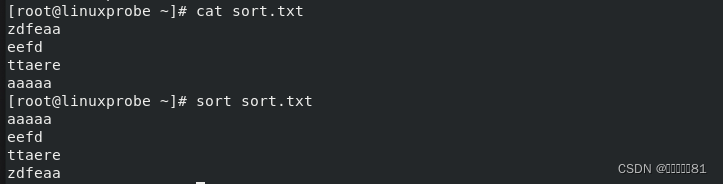
在执行
sort
命令后默认会按照字母顺序进行排序,非常方便:
此外,与
uniq
命令不同,
sort 命令是无论内容行之间是否夹杂有其他内容,只要有两个一模一样的内容行,立马就可以使用
-u
参数进行去重操作:

想对数字进行排序?一点问题都没有,而且完全不用担心出现
1
大于
20 这种问题(因为有些命令只比较数字的第一位,忽略了十、百、千的位):
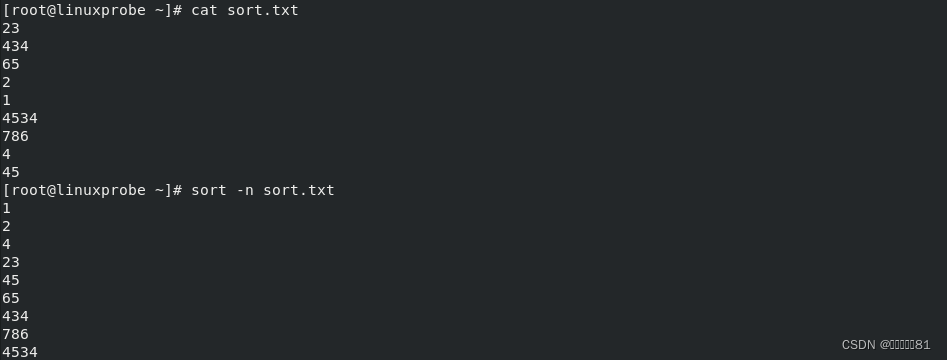
最后,我们挑战一个“高难度”的小实验。下面的内容节选自
/etc/passwd
文件中的前 5个字段,并且进行了混乱排序。(待续
文件目录管理器
有了上面的知识铺垫,我们将在本节介绍
Linux 系统日常运维工作中最常用的命令,实现对文件的创建、修改、复制、剪切、更名与删除等操作。
1.touch命令
touch
命令用于创建空白文件或设置文件的时间,语法格式为“
touch [
参数
]
文件名称”。
对
touch 命令来讲,有难度的操作主要是体现在设置文件内容的修改时间(
Mtime)、文件权限或属性的更改时间(
Ctime
)与文件的访问时间(
Atime
)上面。
touch 命令中的参数及其作用
-a 仅修改“访问时间”(Atime )
-m 仅修改“修改时间”(Mtime )
-d 同时修改 Atime 与 Mtime
先使用
ls 命令查看一个文件的修改时间,随后修改这个文件,最后再查看一下文件的修改时间,看是否发生了变化:

如果不想让别人知道我们修改了它,那么这时就可以用
touch 命令把修改后的文件时间设置成修改之前的时间:
 2.mkdir命令
2.mkdir命令
mkdir
命令用于创建空白的目录,英文全称为“
make directory
”,语法格式为“
mkdir [参数
]
目录名称”。
除了能创建单个空白目录外,
mkdir
命令还可以结合
-p 参数来递归创建出具有嵌套层叠关系的文件目录:

3.cp命令
cp
命令用于复制文件或目录,英文全称为“
copy
”,语法格式为“
cp [
参数
] 源文件名称 目标文件名称”。
在
Linux 系统中,复制操作具体分为
3
种情况:
如果目标文件是目录,则会把源文件复制到该目录中;
如果目标文件也是普通文件,则会询问是否要覆盖它;
如果目标文件不存在,则执行正常的复制操作。
复制命令基本不会出错,唯一需要记住的就是在复制目录时要加上
-r
参数。
cp 命令中的参数及其作用
-p 保留原始文件的属性
-d 若对象为“链接文件”,则保留该“链接文件”的属性
-r 递归持续复制(用于目录)
-i 若目标文件存在则询问是否覆盖
-a 相当于-pdr(p、
d
、
r
为上述参数)
接下来,使用
touch
命令创建一个名为
install.log 的普通空白文件,然后将其复制为一份名为
x.log
的备份文件,最后再使用
ls
命令查看目录中的文件:

4.mv命令
mv
命令用于剪切或重命名文件,英文全称为“
move
”,语法格式为“
mv [
参数
] 源文件名称 目标文件名称”。
剪切操作不同于复制操作,因为它默认会把源文件删除,只保留剪切后的文件。如果在同一个目录中将某个文件剪切后还粘贴到当前目录下,其实也就是对该文件进行了重命名操作:

5.rm命令
rm
命令用于删除文件或目录,英文全称为“
remove
”,语法格式为“
rm [
参数
] 文件名称”。
在
Linux 系统中删除文件时,系统会默认向您询问是否要执行删除操作,如果不想总是看到这种反复的确认信息,可在
rm
命令后跟上
-f 参数来强制删除。另外,要想删除一个目录,需要在
rm
命令后面加一个
-r
参数才可以,否则删除不掉。
rm 命令中的参数及其作用
-f 强制执行
-i 删除前询问
-r 删除目录
-v 显示过程
下面尝试删除前面创建的
install.log
和
linux.log
文件,大家感受一下加与不加
-f
参数的区别:

6.dd命令
dd
命令用于按照指定大小和个数的数据块来复制文件或转换文件,语法格式为“dd if=参数值
of=
参数值
count=
参数值
bs=
参数值”。
dd 命令是一个比较重要而且比较有特色的命令,它能够让用户按照指定大小和个数的数据块来复制文件的内容。当然,如果愿意的话,还可以在复制过程中转换其中的数据。Linux系统中有一个名为
/dev/zero 的设备文件,每次在课堂上解释它时都充满哲学理论的色彩。因为这个文件不会占用系统存储空间,但却可以提供无穷无尽的数据,因此常常使用它作为 dd命令的输入文件,来生成一个指定大小的文件。
dd 命令中的参数及其作用
if 输入的文件名称
of 输出的文件名称
bs 设置每个“块”的大小
count 设置要复制“块”的个数
conv 转换格式
bs
与
count
都是用来指定容量的大小。
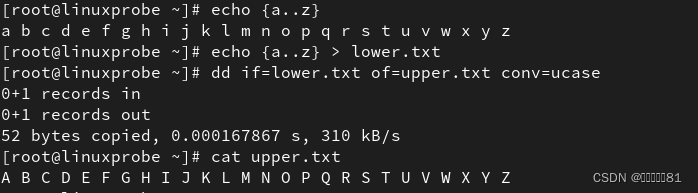
例如,用
dd
命令从
/dev/zero
设备文件中取出一个大小为
560MB 的数据块,然后保存成名为
560
_
file
的文件。在理解了这个命令后,以后就能随意创建任意大小的文件了:

dd
命令的功能也绝不仅限于复制文件这么简单。如果想把光驱设备中的光盘制作成 iso格式的镜像文件,在
Windows
系统中需要借助于第三方软件才能做到,但在
Linux 系统中可以直接使用
dd
命令来压制出光盘镜像文件,将它变成一个可立即使用的
iso
镜像:

7.file命令
file
命令用于查看文件的类型,语法格式为“
file
文件名称”。
在
Linux 系统中,由于文本、目录、设备等所有这些一切都统称为文件,但是它们又不像
Windows 系统那样都有后缀,因此很难通过文件名一眼判断出具体的文件类型,这时就需要使用
file
命令来查看文件类型了。

8.tar命令
tar
命令用于对文件进行打包压缩或解压,语法格式为“
tar
参数 文件名称”。
在
Linux
系统中,主要使用的是
.tar
、
.tar.gz
或.tar.bz2格式,这些格式大部分都是由
tar
命令生成的。
tar 命令中的参数及其作用
-c 创建压缩文件
-x 解开压缩文件
-t 查看压缩包内有哪些文件
-z 用 gzip 压缩或解压
-j 用 bzip2 压缩或解压
-J 用xzip压缩或解压
-v 显示压缩或解压的过程
-f 目标文件名
-p 保留原始的权限与属性
-P 使用绝对路径来压缩
-C 指定解压到的目录
首先,
-c
参数用于创建压缩文件,
-x 参数用于解压文件,因此这两个参数不能同时使用。其次,
-z
参数指定使用
gzip
格式来压缩或解压文件,
-j 参数指定使用 bzip2 格式来压缩或解压文件。用户使用时则是根据文件的后缀来决定应使用何种格式的参数进行解压。在执行某些压缩或解压操作时,可能需要花费数个小时,如果屏幕一直没有输出,您一方面不好判断打包的进度情况,另一方面也会怀疑电脑死机了,因此非常推荐使用
-v 参数向用户不断显示压缩或解压的过程。
-C
参数用于指定要解压到哪个指定的目录。
-f 参数特别重要,它必须放到参数的最后一位,代表要压缩或解压的软件包名称。”刘遄老师“一般使用“
tar -czvf 压缩包名称
.tar.gz
要打包的目录”命令把指定的文件进行打包压缩;相应的解压命令为“
tar -xzvf 压缩包名称
.tar.gz
”。
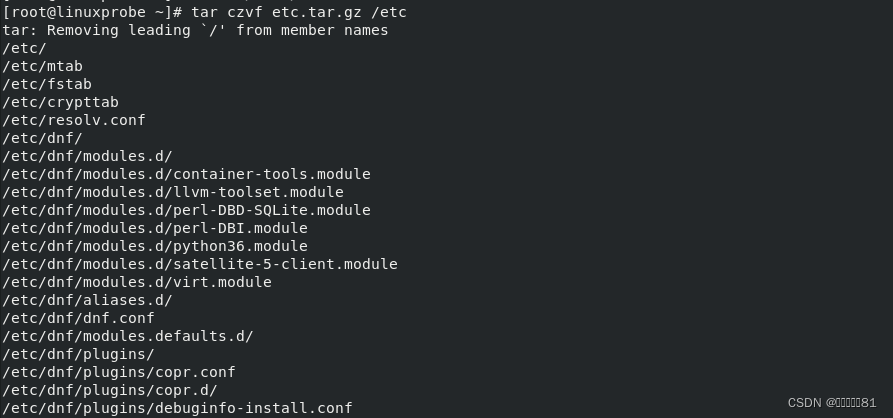
下面我们逐个演示打包压缩与解压的操作,先使用
tar
命令把
/etc
目录通过 gzip格式进行打包压缩,并把文件命名为
etc.tar.gz
:
接下来将打包后的压缩包文件指定解压到
/root/etc
目录中(先使用
mkdir
命令创建
/root/etc
目录):

其他
1.lscpu命令

2.echo颜色 \e[第一个参数(加粗);第二个参数(字体颜色);第三个参数(背景颜色);m
3.关机
init 0
init 0
shutdown -c
4.curl命令

5.nmtui
6.nmcli 重启网卡
7.route查看本地路由的相关信息

8.ip命令
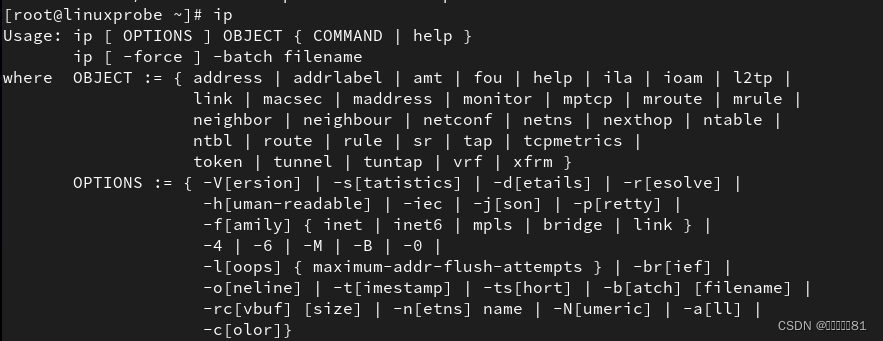
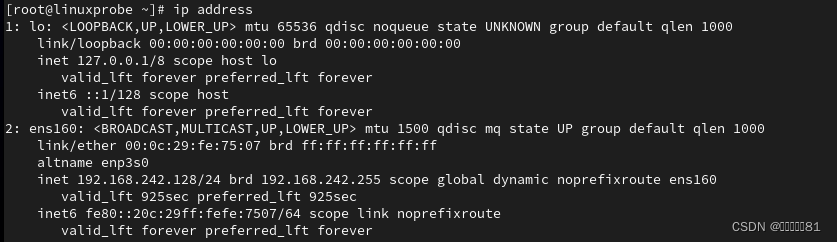
9.ss命令

10.fdisk命令
查看、修改系统的磁盘信息,
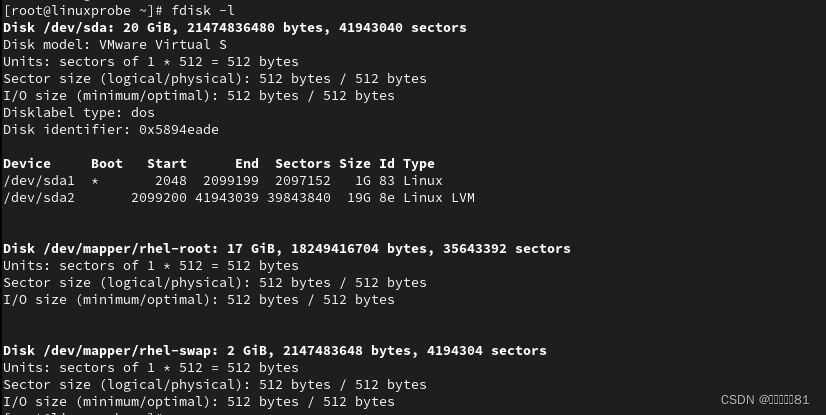
使用lsblk便捷显示磁盘信息:


11.w命令

12. .bashrc
给历史记录增加使用时间

编辑后使用source重新导入.bashrc到当前文件中

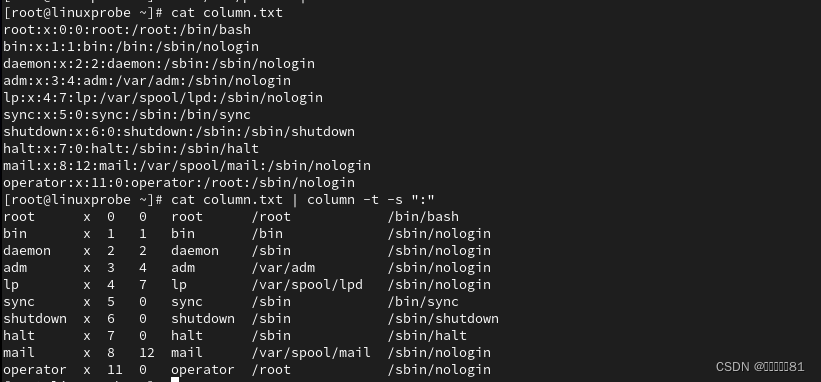
13.column格式化制表符
14.^符号
15.env命令,查看系统的环境变量
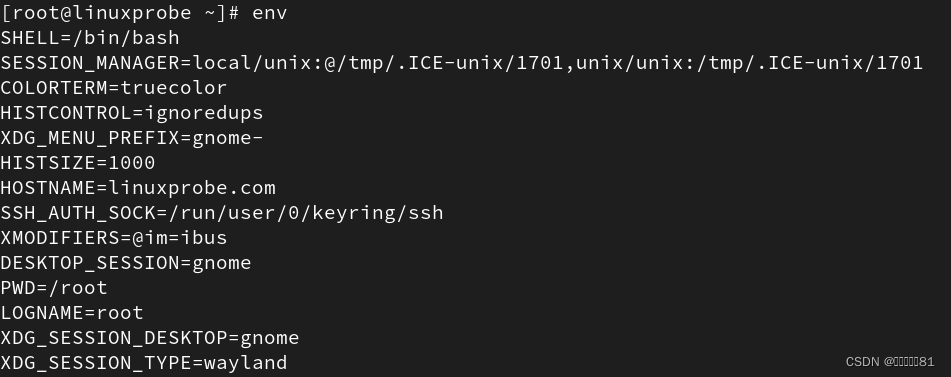
16.alias命令,起别名、查看系统别名

17.PS1环境变量 大写W表示相对路径,小写表示相对路径

对所有用户修改
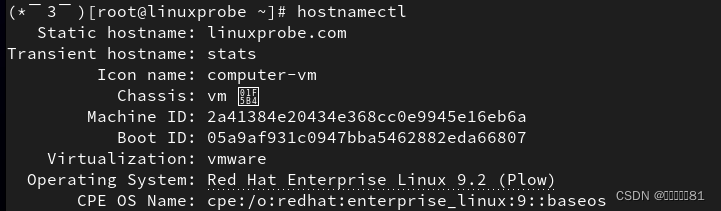
18.hostnamectl
二、管道符、重定向与环境变量
本章首先讲解与文件读写操作有关的重定向技术的
5
种模式—标准覆盖输出重定向、标准追加输出重定向、错误覆盖输出重定向、错误追加输出重定向以及输入重定向,通过实验切实理解每个重定向模式的作用,解决输出信息的保存问题。
1.输入输出重定向
简而言之,输入重定向是指把文件导入到命令中,而输出重定向则是指把原本要输出到屏幕的数据信息写入到指定文件中。在日常的学习和工作中,相较于输入重定向,我们使用输出重定向的频率更高,所以又将输出重定向分为了标准输出重定向和错误输出重定向两种不同的技术,以及覆盖写入与追加写入两种模式。
标准输入重定向(STDIN,文件描述符为0):默认从键盘输入,也可从其他文件或命令中输入。
标准输出重定向(STDOUT,文件描述符为1):
默认输出到屏幕。
错误输出重定向(STDERR,文件描述符为2):
默认输出到屏幕。
比如分别查看两个文件的属性信息,我们先创建出第一个文件,而第二个文件是不存在的。所以,虽然针对这两个文件的操作都分别会在屏幕上输出一些信息,但这两个操作的差异其实很大:

在上述命令中,名为
linuxprobe 的文件是真实存在的,输出信息是该文件的一些相关权限、所有者、所属组、文件大小及修改时间等信息,这也是该命令的标准输出信息。而名为
xxxxxx 的第二个文件是不存在的,因此在执行完
ls 命令之后显示的报错提示信息也是该命令的错误输出信息。那么,要想把原本输出到屏幕上的数据转而写入到文件当中,就要区别对待这两种输出信息。
对于输入重定向来讲,
输入重定向中用到的符号及其作用
命令 < 文件 将文件作为命令的标准输入
命令 << 分界符 从标准输入中读入,直到遇见分界符才停止
命令
<
文件
1 > 文件 2 将文件 1
作为命令的标准输入并将标准输出到文件
2
对于输出重定向来讲,
输出重定向中用到的符号及其作用
命令 > 文件 将标准输出重定向到一个文件中(清空原有文件的数据)
命令 2> 文件 将错误输出重定向到一个文件中(清空原有文件的数据)
命令 >> 文件 将标准输出重定向到一个文件中(追加到原有内容的后面)
命令 2>> 文件 将错误输出重定向到一个文件中(追加到原有内容的后面)
命令
>> 文件 2>&1 或 命令
&>> 文件 将标准输出与错误输出共同写入到文件中(追加到原有内容的后面)
对于重定向中的标准输出模式,可以省略文件描述符
1 不写,而错误输出模式的文件描述符
2
是必须要写的。
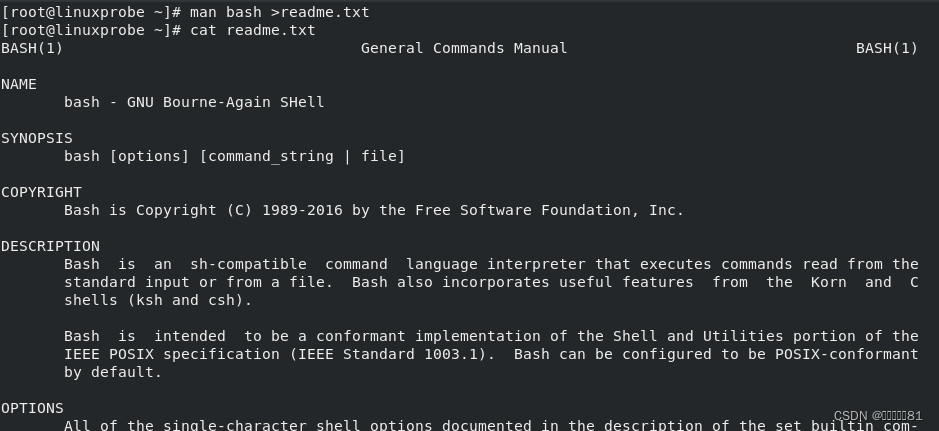
通过标准输出重定向将
man bash 命令原本要输出到屏幕的信息写入到文件
readme.txt
中,然后显示
readme.txt
文件中的内容。具体命令如下:
接下来尝试输出重定向技术中的覆盖写入与追加写入这两种不同模式带来的变化。首先通过覆盖写入模式向
readme.txt 文件写入多行数据(该文件中已包含上一个实验的
man 命令信息)。需要注意的是,在通过覆盖写入模式向文件中写入数据时,每一次都会覆盖掉上一次写入的内容,所以最终文件中只有最后一次的写入结果:

再通过追加写入模式向
readme.txt
文件写入一次数据,然后在执行
cat 命令之后,可以看到如下所示的文件内容:

虽然都是输出重定向技术,但是命令的标准输出和错误输出还是有区别的。例如查看当前目录中某个文件的信息,这里以 linuxprobe 文件为例。由于这个文件是真实存在的,因此使用标准输出即可将原本要输出到屏幕的信息写入到文件中,而错误的输出重定向则依然把信息输出到了屏幕上。

如果想把命令的报错信息写入到文件,需要用命令 2> 文件 ,将错误输出重定向到一个文件中,当用户在执行一个自动化的 Shell 脚本时,这个操作会特别有用,而且特别实用,因为它可以把整个脚本执行过程中的报错信 息都记录到文件中,便于安装后的排错工作。
接下来以一个不存在的文件进行实验演示:

还有一种常见情况,就是我们想不区分标准输出和错误输出,只要命令有输出信息则全部追加写入到文件中。这就要用到
&>>
操作符了:

输入重定向的作用是把文件直接导入到命令中。接下来使用输入重定向把
readme.txt
文件导入给
wc -l 命令,统计一下文件中的内容行数:

相对于 wc -l readme.txt 没有了文件名称,因为使用的“wc -l readme.txt ”是一种非常标准的“命令+参数+对象”的执行格式,而“wc -l < readme.txt”则是将 readme.txt 文件中的内容通过操作符导入到命令中,没有被当作命令对象进行执行,因此 wc 命令只能读到
信息流数据,而没有文件名称的信息。
2.管道命令符
同时 按下键盘上的
Shift+反斜杠(\
)键即可输入管道符,其执行格式为“命令
A |
命令
B
”。管道
命令符的作用也可以用一句话概括为“把前一个命令原本要输出到屏幕的信息当作后一个命令的标准输入”。
在
2.6
节讲解
grep
文本搜索命令时,我们通过匹配关键词
/sbin/nologin 找出了所有被限制登录系统的用户。在学完本节内容后,完全可以把下面这两条命令合并为一条:
找出被限制登录用户的命令是
grep /sbin/nologin /etc/passwd
;
统计文本行数的命令则是
wc–l
。
现在要做的就是把
grep
搜索命令的输出值传递给
wc 统计命令,即把原本要输出到屏幕的用户信息列表再交给
wc 命令作进一步的加工,因此只需要把管道符放到两条命令之间即可,具体如下:
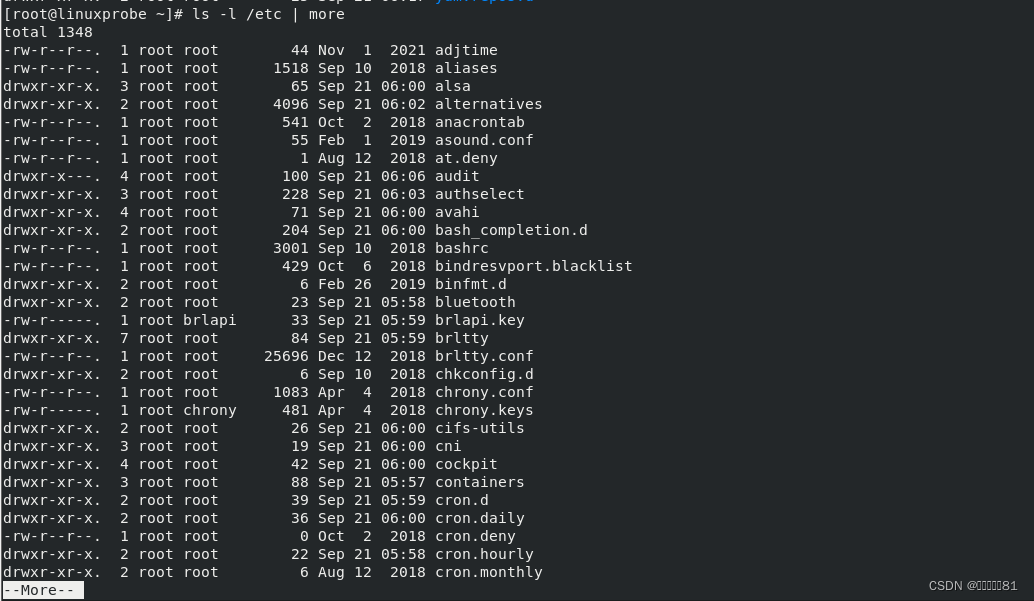
我们可以将它套用到其他不同的命令上,比如用翻页的形式查看
/etc 目录中的文件列表及属性信息(这些内容默认会一股脑儿地显示到屏幕上,根本看不清楚):
在修改用户密码时,通常都需要输入两次密码以进行确认,这在编写自动化脚本时将成为一个非常致命的缺陷。通过把管道符和
passwd
命令的
--stdin 参数相结合,可以用一条命令来完成密码重置操作:

学习
ps
命令的时候,输入
ps aux 命令后屏幕信息呼呼闪过,根本找不到有用的信息。现在也可以将
ps
、
grep
、管道符三者结合到一起使用了。下面搜索与
bash
有关的进程信息:

管道命令符并不是只能在一个命令组合中使用一次。我们完全可以这样使用:“命令
A |
命令
B |
命令
C
”。
如果需要将管道符处理后的结果既输出到屏幕,又同时写入到文件中,则可以与
tee
命令结合使用。

3.命令行的通配符
我们有时候也会遇到明明一个文件的名称就在嘴边但就是想不起来的情况。如果只记得一个文件的开头几个字母,想遍历查找出所有以这几个字母开头的文件,可以使用通配符来搞定。比如,假设我们想要批量查看所有硬盘文件的相关权限属性,有一种实现方式是下面这样的:

这些硬盘设备文件都是以
sda
开头并且存放到了
/dev 目录中,这样一来,即使不知道硬盘的分区编号和具体分区的个数,也可以使用通配符来搞定。

顾名思义,通配符就是通用的匹配信息的符号,比如星号(
*)代表匹配零个或多个字符,问号(
?
)代表匹配单个字符,中括号内加上数字
[0-9]
代表匹配
0
~
9 之间的单个数字的字符,而中括号内加上字母
[abc]
则是代表匹配
a
、
b
、
c
三个字符中的任意一个字符。
Linux 系统中的通配符及含义
* 任意字符
? 单个任意字符
[a-z] 单个小写字母
[A-Z] 单个大写字母
[a-Z] 单个字母
[0-9] 单个数字
[[:alpha:]] 任意字母
[[:upper:]] 任意大写字母
[[:lower:]] 任意小写字母
[[:digit:]] 所有数字
[[:alnum:]] 任意字母加数字
[[:punct:]] 标点符号
下面我们就来匹配所有在
/dev
目录中且以 sda开头的文件:
如果只想查看文件名以
sda 开头,但是后面还紧跟其他某一个字符的文件的相关信息,这时就需要用到问号来进行通配了:

除了使用
[0-9]
来匹配
0
~
9
之间的单个数字,也可以用
[135]
这样的方式仅匹配这
3 个指定数字中的一个;若没有匹配到数字
1
或
2
或
3
,则不会显示出来:

通配符不一定非要放到最后面,也可以放到前面。比如,可以使用下述命令来搜索/etc/目录中所有以
.conf
结尾的配置文件有哪些:
通配符不仅可用于搜索文件或代替被通配的字符,还可以与创建文件的命令相结合,一口气创建出好多个文件。不过在创建多个文件时,需要使用大括号,并且字段之间用逗号间隔:

使用通配符还可以输出一些指定的信息:
4.常用的转义字符
为了能够更好地理解用户的表达,
Shell 解释器还提供了特别丰富的转义字符来处理输入的特殊数据。
4
个最常用的转义字符如下所示。
反斜杠( \ ):使反斜杠后面的一个变量变为单纯的字符。
单引号(' '):转义其中所有的变量为单纯的字符串。
双引号(" "):保留其中的变量属性,不进行转义处理。
反引号(` `):把其中的命令执行后返回结果。
我们先定义一个名为
PRICE
的变量并赋值为
5,然后输出以双引号括起来的字符串与变量信息:

接下来,我们希望能够输出“
Price is $5
”,即“价格是
5 美元”的字符串内容,但碰巧美元符号与变量提取符号合并后的
$$
作用是显示当前程序的进程
ID
号码,于是命令执行后输出的内容并不是我们所预期的:
要想让第一个“
$”乖乖地作为美元符号,那么就需要使用反斜杠(\)来进行转义,将这个命令提取符转义成单纯的文本,去除其特殊功能:
而如果只需要某个命令的输出值,可以像
`
命令
`这样,将命令用反引号括起来,达到预期的效果。例如,将反引号与
uname -a
命令结合,然后使用
echo
命令来查看本机的
Linux 版本和内核信息:
反斜杠和反引号的功能比较有特点,但对于什么时候使用双引号却容易混淆,因为在大多数情况下好像加不加双引号,效果都一样:

两者的区别在于用户无法得知第一种执行方式中到底有几个参数。是的,不能确定!因为有可能把“
AA BB CC
”当作一个参数整体直接输出到屏幕,也有可能分别将
AA
、
BB 和CC
输出到屏幕。而且,就算摸清了
echo
命令处理参数的机制,在使用其他命令时依然存在
这种情况。
简单小技巧,虽然可能不够严谨,但绝对简单:如果参数中出现了空格,就加双引号;如果参数中没有空格,那就不用加双引号。
5.重要的环境变量
变量是计算机系统用于保存可变值的数据类型。在
Linux 系统中,变量名称一般都是大写的,命令则都是小写的,这是一种约定俗成的规范。
Linux 系统中的环境变量是用来定义系统运行环境的一些参数,比如每个用户不同的家目录、邮件存放位置等。可以直接通过变量名称来提取到对应的变量值。
前文中曾经讲到,在
Linux 系统中一切都是文件,
Linux
命令也不例外。那么,在用户执行了一条命令之后,
Linux 系统中 到底发生了什么事情呢?简单来说,命令在
Linux
中的执行分为
4
个步骤。
第一步:判断用户是否以绝对路径或相对路径的方式输入命令(如/bin/ls),如果是绝对路径则直接执行,否则进入第 2 步继续判断。
第二步:Linux 系统检查用户输入的命令是否为“别名命令”,即用一个自定义的命令名称来替换原本的命令名称。
之前在使用
rm
命令删除文件时,
Linux 系统都会要求用户确认是否执行删除操作,其实这就是
Linux
系统为了防止用户误删除文件而特意设置的
rm
别名命令
—
“
rm -i
”。
可以用
alias
命令来创建一个属于自己的命令别名,语法格式为“
alias
别名
=命令”。若要取消一个命令别名,则是用
unalias
命令,语法格式为“
unalias
别名”。
将当前
rm
命令所被设置的别名取消掉,再删除文件试试:

创建别名用双引号或者单引号都可以:

第三步:Bash 解释器判断用户输入的是内部命令还是外部命令。
内部命令是解释器内部的指令,会被直接执行;而用户在绝大部分时间输入的是外部命令,这些命令交由步骤 4 继续处理。可以使用“type 命令名称”来判断用户输入的命令是内部命令还是外部命令:

echo就是内部命令(builtin 安装在内部的),而uptime是外部命令。
第四步:系统在多个路径中查找用户输入的命令文件,而定义这些路径的变量叫作 PATH,可以简单地把它理解成是“解释器的小助手”,作用是告诉 Bash 解释器待执行的命令可能存放的位置,然后 Bash 解释器就会乖乖地在这些位置中逐个查找。PATH 是由多个路径值组成的变量,每个路径值之间用冒号间隔,对这些路径的增加和删除操作将影响到 Bash 解释器对Linux 命令的查找。
增加路径:

我们可以使用
env
命令来查看
Linux 系统中所有的环境变量
Linux 系统中最重要的 10
个环境变量
HOME 用户的主目录(即家目录)
SHELL 用户在使用的 Shell 解释器名称
HISTSIZE 输出的历史命令记录条数
HISTFILESIZE 保存的历史命令记录条数
MAIL 邮件保存路径
LANG 系统语言、语系名称
RANDOM 生成一个随机数字
PS1 Bash 解释器的提示符
PATH 定义解释器搜索用户执行命令的路径
EDITOR 用户默认的文本编辑器
inux 作为一个多用户、多任务的操作系统,能够为每个用户提供独立的、合适的工作运行环境。因此,一个相同的变量会因为用户身份的不同而具有不同的值。例如,使用下述命令来查看
HOME
变量在不同的用户身份下都有哪些值(
su 是用于切换用户身份的命令
):

其实变量是由固定的变量名与用户或系统设置的变量值两部分组成的,我们完全可以自行创建变量来满足工作需求。例如,设置一个名称为
WORKDIR 的变量,方便用户更轻松地进入一个层次较深的目录

但是,这样的变量不具有全局性,作用范围也有限,默认情况下不能被其他用户使用:

如果工作需要,可以使用
export 命令将其提升为全局变量,这样其他用户也就可以使用它了:

后续要是不使用这个变量了,则可执行
unset
命令把它取消掉:

注意:直接在终端设置的变量能够立即生效,但在重启服务器后就会失效,因此我们需要将变量和变量值写入到.bashrc 或者.bash_profile 文件中,以确保永久能使用它们。
三、Vim编辑器与Shell命令脚本
使用
Vim 编辑器来编写和修改文档,然后通过逐步配置主机名称、系统网卡以及软件仓库等文件,加深
Vim
编辑器中诸多命令、快捷键与模式的理解。
1.Vim文本编辑器
Vim
的发布最早可以追溯到
1991
年,英文全称为
Vi Improved
。它也是
Vi 编辑器的提升版本,其中最大的改进当属添加了代码着色功能,在某些编程场景下还能自动修正错误代码。
Vim
之所以能得到广大厂商与用户的认可,原因在于
Vim
编辑器中设置了 3 种模式—命令模式、末行模式和编辑模式,每种模式分别又支持多种不同的命令快捷键,这大大提高了工作效率,而且用户在习惯之后也会觉得相当顺手。要想高效地操作文本,就必须先搞清这
3
种模式的操作区别以及模式之间的切换方法。
命令模式:控制光标移动,可对文本进行复制、粘贴、删除和查找等工作。
输入模式:正常的文本录入。
末行模式:保存或退出文档,以及设置编译环境。
Vim
编辑器模式的切换方法
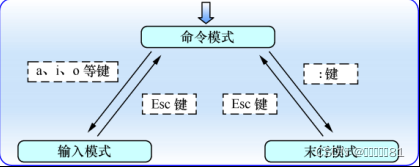
在每次运行 Vim 编辑器时,默认进入命令模式,此时需要先切换到输入模式后再进行文档编写工作。而每次在编写完文档后需要先返回命令模式,然后再进入末行模式,执行文档的保存或退出操作。在
Vim
中,无法直接从输入模式切换到末行模式。
Vim 编辑器中内置的命令有成百上千种用法,为了能够帮助读者更快地掌握
Vim
编辑器,
总结了在命令模式中最常用的一些命令:
dd 删除(剪切)光标所在整行
5dd 删除(剪切)从光标处开始的 5
行
yy 复制光标所在整行
5yy 复制从光标处开始的 5
行
n 显示搜索命令定位到的下一个字符串
N 显示搜索命令定位到的上一个字符串
u 撤销上一步的操作
p 将之前删除(dd)或复制(
yy
)过的数据粘贴到光标后面
末行模式主要用于保存或退出文件,以及设置
Vim 编辑器的工作环境,还可以让用户执行外部的
Linux 命令或跳转到所编写文档的特定行数。要想切换到末行模式,在命令模式中输入一个冒号就可以了。
末行模式中常用的一些命令
:w 保存
:q 退出
:q! 强制退出(放弃对文档的修改内容)
:wq! 强制保存退出
:set nu 显示行号
:set nonu 不显示行号
:命令 执行该命令
:整数 跳转到该行
:s/one/two 将当前光标所在行的第一个 one 替换成
two
:s/one/two/g 将当前光标所在行的所有 one 替换成
two
:%s/one/two/g 将全文中的所有 one 替换成 two
?字符串 在文本中从下至上搜索该字符串按n键wnag
/字符串 在文本中从上至下搜索该字符串
vim说明书
中文版
取消高亮
设置鼠标行 set cursorline

设置鼠标列 set cursorcolumn

关闭鼠标列 set nocursorcolumn;
v 进入可视化模式 Ctrl+v进入可视化块模式能选择多行多列。
批量注释1

方法二。ctrl+v进入块模式,按shift+i对选中的行内容进行编辑,按esc退出即可

打开两个文件,按Ctrl+ww/ Ctrl+w+上下键切换文件,
退出按shift+: wqa一块退qzai出,在那个文件中安:号在那退出
1.编写简单文档
编写脚本文档的第
1
步就是给文档取个名字,这里将其命名为
practice.txt。如果存在该 文档,则是打开它。如果不存在,则是创建一个临时的输入文件,💤
打开 practice.txt
文档后,默认进入的是
Vim
编辑器的命令模式。此时只能执行该模式下的命令,而不能随意输入文本内容。我们需要切换到输入模式才可以编写文档。
可以分别使用 a
、
i
、
o
这
3
个键从命令模式切换到输入模式。其中,a 键与
i
键分别是在光标后面一位和光标当前位置切换到输入模式,而
o 键则是在光标的下面 再创建一个空行,此时可敲击
a
键进入编辑器的输入模式,
进入输入模式后,可以随意输入文本内容,
Vim 编辑器不会把您输入的文本内容当作命令而执行
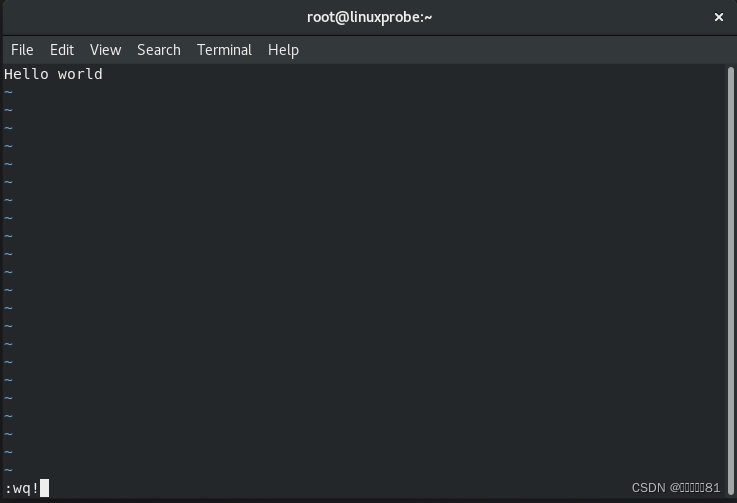
在编写完之后,要想保存并退出,必须先敲击键盘的
Esc 键从输入模式返回命令模式,然后再输入“
:wq!
”切换到末行模式才能完成保存退出操作,

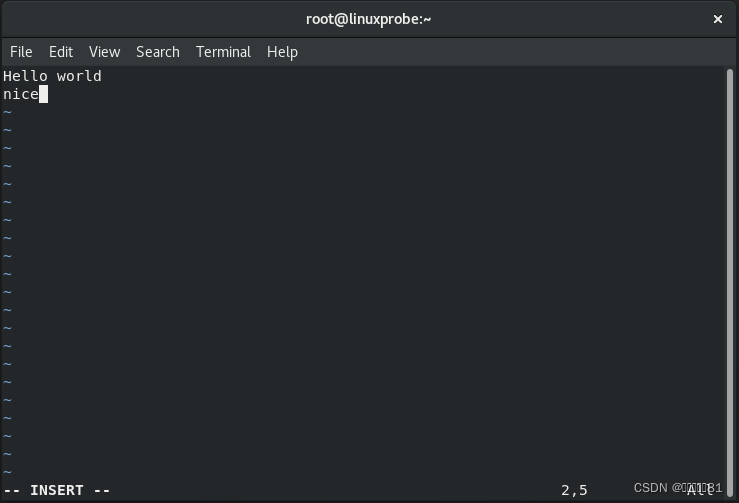
继续编辑这个文档。因为要在原有文本内容的下面追加内容,所以在命令模式中敲击
o
键进入输入模式更会高效,
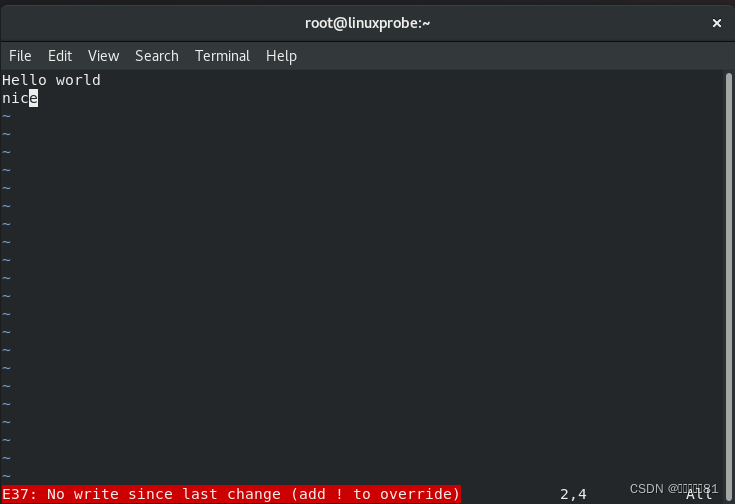
因为此时已经修改了文本内容,所以
Vim 编辑器在我们尝试直接退出文档而不保存的时候就会拒绝我们的操作了。此时只能强制退出才能结束本次输入操作,


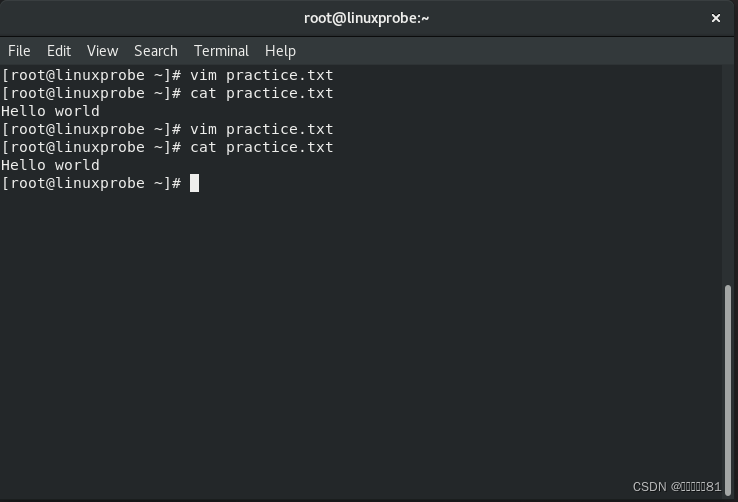
现在查看文本的内容,果然发现追加输入的内容并没有被保存下来
2.配置主机名称
为了便于在局域网中查找某台特定的主机,或者对主机进行区分,除了要有 IP 地址外,还要为主机配置一个主机名,主机之间可以通过这个类似于域名的名称来相互访问。在 Linux系统中,主机名大多保存在/etc/hostname 文件中,接下来将/etc/hostname 配置文件的内容修改为“linuxprobe.com
”,
第一步:使用Vim编辑器修改/etc/hostname主机名称文件。或者hostnamectl检测
第二步:把原始主机名称删除后追加
“
linuxprobe.com”。注意,使用 Vim 编辑器修改主机名称文件后,要在末行模式下执行“:wq!”命令才能保存并退出文档。
第三步:
保存并退出文档,然后使用
hostname
命令检查是否修改成功。

hostname 命令用于查看当前的主机名称,但有时主机名称的改变不会立即同步到系统中,所以如果发现修改完成后还显示原来的主机名称,可重启虚拟机后再行查看:

3.配置网卡信息
网卡
IP
地址配置的是否正确是两台服务器是否可以相互通信的前提。在
Linux 系统中,一切都是文件,因此配置网络服务的工作其实就是在编辑网卡配置文件。
在
RHEL 5
、
RHEL 6
中,网卡配置文件的前缀为
eth
,第
1 块网卡为eth0
,第
2
块网卡为
eth1
;以此类推。在
RHEL 7
中,网卡配置文件的前缀则以
ifcfg 开始,再加上网卡名称共同组成了网卡配置文件的名字,例如
ifcfg-eno16777736
。而在
RHEL 8 中,网卡配置文件的前缀依然为
ifcfg
,区别是网卡名称改成了类似于
ens160 的样子,不过好在除了文件名发生变化外,网卡参数没有其他大的区别。
现在有一个名称为
ifcfg-ens160
的网卡设备,将其配置为开机自启动,并且
IP 地址、子网、网关等信息由人工指定,其步骤如下所示。
第 1 步:首先切换到/etc/sysconfig/network-scripts 目录中(存放着网卡配置文件)
第 2 步:使用 Vim 编辑器修改网卡文件 ifcfg-ens160,逐项写入下面的配置参数并保存退出。由于每台设备的硬件及架构是不一样的,因此请读者使用 ifconfig 命令自行确认各自网卡的默认名称。
设备类型:TYPE=Ethernet
地址分配模式:BOOTPROTO=static
网卡名称:NAME=ens160
是否启动:ONBOOT=yes
IP地址:IPADDR=192.168.10.10
子网掩码:NETMASK=255.255.255.0
网关地址:GATEWAY=192.168.10.1
DNS地址:DNS1=192.168.10.1
第 3 步:
重启网络服务并测试网络是否连通。
进入到网卡配置文件所在的目录,然后编辑网卡配置文件,在其中填入下面的信息:
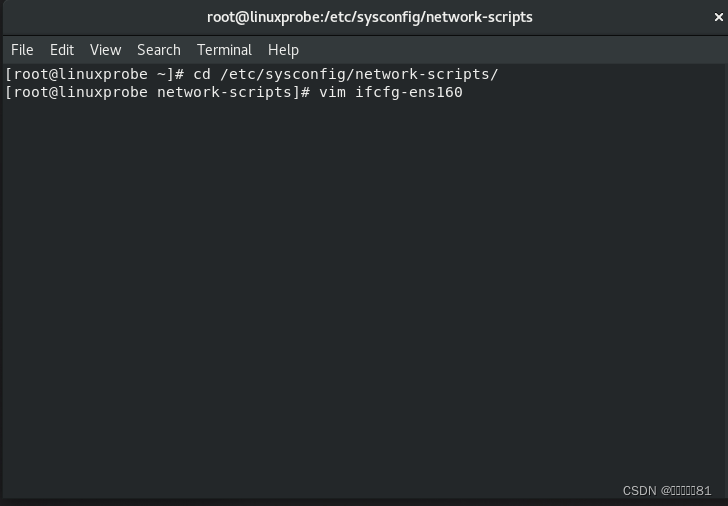
原有的内容:

编辑后:
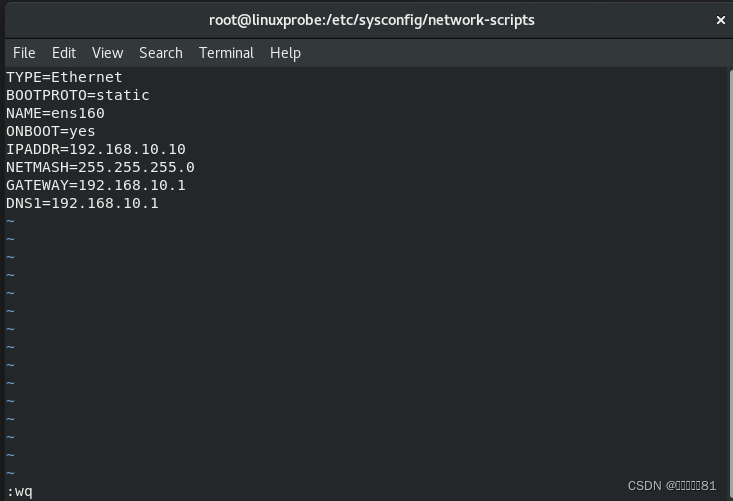
执行重启网卡设备的命令,然后通过
ping
命令测试网络能否连通。由于在
Linux 系统中ping
命令不会自动终止,因此需要手动按下
Ctrl+C
组合键来强行结束进程。
RHEL9配置网卡
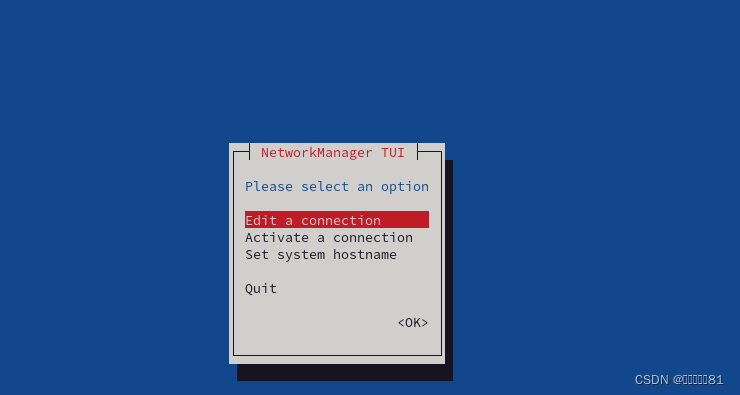
1.配置网卡地址到 /etc/NetworkManager/system-connection/ens160.nmconnection文件
或者使用nmtui进入图形化界面配置
2.使用老版本的配置,进入/etc/NetworkManager/NetworkManager.conf文件
将plugins取消注释让其等于ifcfg-rh

然后重启服务
删除现有的keyfile格式的配置文件
重新加载配置文件
重新启动网卡设备
然后再 /etc/sysconfig/network-scripts目录中就会重新出现ifcfig-ens160文件
4.配置软件仓库
本书前面讲到,软件仓库是一种能进一步简化
RPM 管理软件的难度以及自动分析所需软件包及其依赖关系的技术。可以把
Yum
或
DNF 想象成是一个硕大的软件仓库,里面保存有几乎所有常用的工具,而且只需要说出所需的软件包名称,系统就会自动为您搞定一切。
Yum
与
DNF 软件仓库的配置文件是通用的,也就是说填写好配置文件信息后,这两个软件仓库的命令都是可以正常使用。建议在
RHEL 8
中使用
dnf 作为软件的安装命令,因为它具备更高的效率,而且支持多线程同时安装软件。
搭建并配置软件仓库的大致步骤如下所示。
第 1 步:进入/etc/yum.repos.d/目录中
(因为该目录存放着软件仓库的配置文件)
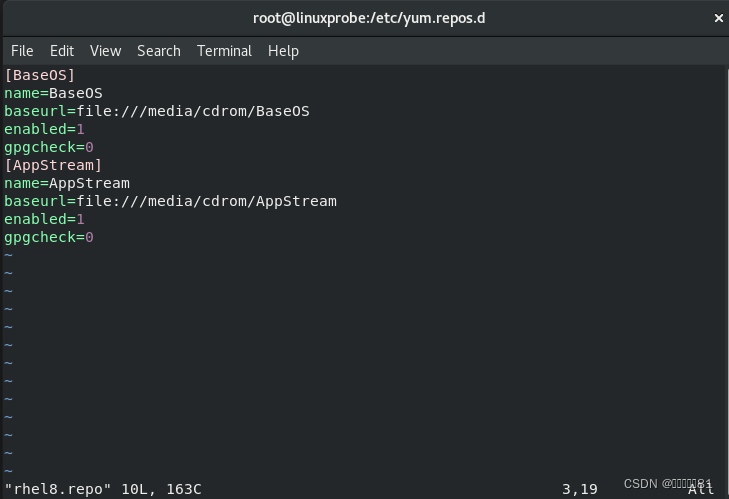
第 2 步:使用 Vim 编辑器创建一个名为 rhel8.repo 的新配置文件(文件名称可随意,但后缀必须为.repo),逐项写入下面的配置参数并保存退出。
仓库名称:
具有唯一性的标识名称,不应与其他软件仓库发生冲突。
描述信息:
可以是一些介绍性的词,易于识别软件仓库的用处。
仓库位置:软件包的获取方式,可以使用 FTP 或 HTTP 下载,也可以是本地的文件(需要在后面添加 file 参数)。
是否启用:
设置此源是否可用;
1
为可用,
0
为禁用。
是否校验:
设置此源是否校验文件;
1
为校验,
0 为不校验。
公钥位置:若上面的参数开启了校验功能,则此处为公钥文件位置。若没有开启,则省略不写。
公钥位置:若上面的参数开启了校验功能,则此处为公钥文件位置。若没有开启,则省略不写。
第 3 步:
按配置参数中所填写的仓库位置挂载光盘,并把光盘挂载信息写入
/etc/fstab
文件中。
第 4 步:
使用“
dnf install httpd -y
”命令检查软件仓库是否已经可用。
进入
/etc/yum.repos.d
目录后创建软件仓库的配置文件:

创建挂载点后进行挂载操作,并设置成开机自动挂载(详见第
6
章):

开机自动挂载

尝试使用软件仓库的
dnf
命令来安装
Web
服务,软件包名称为httpd,安装后出现“Complete! ”则代表配置正确:

2.编写Shell脚本
可以将
Shell
终端解释器当作人与计算机硬件之间的“翻译官”,它作为用户与 Linux 系统内部的通信媒介,除了能够支持各种变量与参数外,还提供了诸如循环、分支等高级编程语言才有的控制结构特性。要想正确使用
Shell 中的这些功能特性,准确下达命令尤为重要。
Shell
脚本命令的工作方式有下面两种。
交互式:
用户每输入一条命令就立即执行。
批处理:由用户事先编写好一个完整的 Shell 脚本,Shell 会一次性执行脚本中诸多的命令。
在
Shell
脚本中不仅会用到前面学习过的很多 Linux 命令以及正则表达式、管道符、数据流重定向等语法规则,还需要把内部功能模块化后通过逻辑语句进行处理,最终形成日常所见的
Shell
脚本。
通过查看
SHELL
变量可以发现,当前系统已经默认使用
Bash
作为命令行终端解释器了:
1.编写简单的脚本
上文指的是一个高级
Shell
脚本的编写原则,其实使用
Vim
编辑器把
Linux 命令按照顺序依次写入到一个文件中,就是一个简单的脚本了。
例如,如果想查看当前所在工作路径并列出当前目录下所有的文件及属性信息,实现这个功能的脚本应该类似于下面这样:
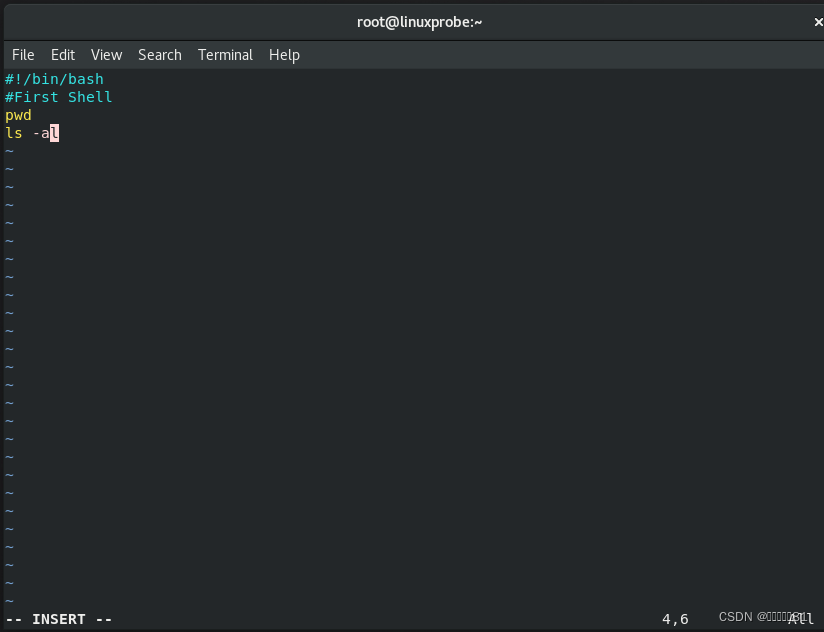
Shell
脚本文件的名称可以任意,但为了避免被误以为是普通文件,建议将
.sh 后缀加上,以表示是一个脚本文件。
在上面的这个
example.sh
脚本中实际上出现了
3
种不同的元素:第一行的脚本声明(
#!)用来告诉系统使用哪种
Shell
解释器来执行该脚本;第二行的注释信息(#)是对脚本功能和 某些命令的介绍信息,使得自己或他人在日后看到这个脚本内容时,可以快速知道该脚本的作用或一些警告信息;第三、四行的可执行语句也就是我们平时执行的
Linux 命令了。你们不相信这么简单就编写出来了一个脚本程序?!那我们来执行一下看看结果:

除了上面用
Bash
解释器命令直接运行 Shell 脚本文件外,第二种运行脚本程序的方法是通过输入完整路径的方式来执行。但默认会因为权限不足而提示报错信息,此时只需要为脚本文件增加执行权限即可
。

2.接受用户的参数
但是,像上面这样的脚本程序只能执行一些预先定义好的功能,未免太过死板。为了让Shell 脚本程序更好地满足用户的一些实时需求,以便灵活完成工作,必须要让脚本程序能够像之前执行命令时那样,接收用户输入的参数。
比如,当用户执行某一个命令时,加或不加参数的输出结果是不同的:

这意味着命令不仅要能接收用户输入的内容,还要有能力进行判断区别,根据不同的输入调用不同的功能。
其实,
Linux
系统中的
Shell 脚本语言早就考虑到了这些,已经内设了用于接收参数的变量,变量之间使用空格间隔。例如,
$0
对应的是当前
Shell
脚本程序的名称,
$#对应的是总共有几个参数,
$*
对应的是所有位置的参数值,
$?对应的是显示上一次命令的执行返回值,而
1
、
$2
、
$3
……则分别对应着第
N
个位置的参数值

理论过后再来练习一下。尝试编写一个脚本程序示例,通过引用上面的变量参数来看一下真实效果:
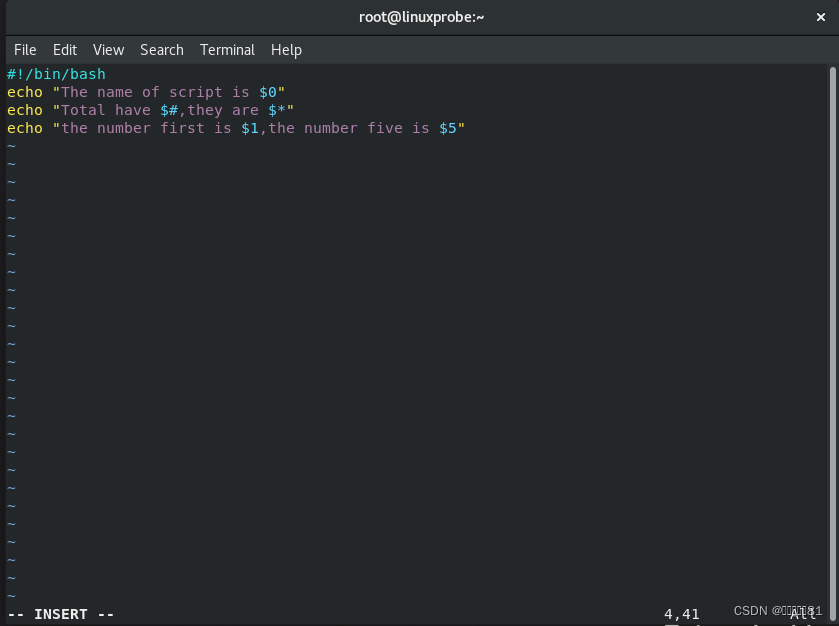

3.判断用户的参数
在学习完
Linux
命令,掌握
Shell 脚本语法变量和接收用户输入的信息之后,就要踏上新的高度
—
能够进一步处理接收到的用户参数。
系统在执行
mkdir 命令时会判断用户输入的信息,即判断用户指定的文件夹名称是否已经存在,如果存在则提示报错;反之则自动创建。
Shell 脚本中的条件测试语法可以判断表达式是否成立,若条件成立则返回数字
0,否则便返回非零值。
切记,条件表达式两边均应有一个空格。

按照测试对象来划分,条件测试语句可以分为
4
种:
文件测试语句;
逻辑测试语句;
整数值比较语句;
字符串比较语句。
文件测试即使用指定条件来判断文件是否存在或权限是否满足等情况的运算符,具体的参数:
文件测试所用的参数
-d 测试文件是否为目录类型
-e 测试文件是否存在
-f 判断是否为一般文件
-r 测试当前用户是否有权限读取
-w 测试当前用户是否有权限写入
-x 测试当前用户是否有权限执行
下面使用文件测试语句来判断
/etc/fstab
是否为一个目录类型的文件,然后通过
Shell 解释器的内设
$?
变量显示上一条命令执行后的返回值。如果返回值为
0,则目录存在;如果返回值为非零的值,则意味着它不是目录,或这个目录不存在:

再使用文件测试语句来判断
/etc/fstab
是否为一般文件,如果返回值为
0,则代表文件存在,且为一般文件:

判断与查询其实可以一次搞定。
逻辑语句用于对测试结果进行逻辑分析,根据测试结果可实现不同的效果。例如在 Shell终端中逻辑“与”的运算符号是
&&,它表示当前面的命令执行成功后才会执行它后面的命令,因此可以用来判断
/dev/cdrom
文件是否存在,若存在则输出
Exist
字样。
除了逻辑“与”外,还有逻辑“或”,它在
Linux
系统中的运算符号为
||,表示当前面的命令执行失败后才会执行它后面的命令,因此可以用来结合系统环境变量
USER 来判断当前登录的用户是否为非管理员身份:

第三种逻辑语句是“非”,在 Linux 系统中的运算符号是一个叹号(!),它表示把条件测试中的判断结果取相反值。也就是说,如果原本测试的结果是正确的,则将其变成错误的;原本测试错误的结果,则将其变成正确的。
我们现在切换回到
root 管理员身份,再判断当前用户是否为一个非管理员的用户。由于判断结果因为两次否定而变成正确,因此会正常地输出预设信息:

叹号应该放到判断语句的前面,代表对整个的测试语句进行取反值操作,而不应该写成“
$USER != root”,因为“!=
”代表的是不等于符号(
≠),尽管执行效果一样,但缺少了逻辑关系,
整数比较运算符仅是对数字的操作,不能将数字与字符串、文件等内容一起操作,而且不能想当然地使用日常生活中的等号、大于号、小于号等来判断。因为等号与赋值命令符冲突,大于号和小于号分别与输出重定向命令符和输入重定向命令符冲突。因此一定要使用规范的整数比较运算符来进行操作。
可用的整数比较运算符
-eq 是否等于
-ne 是否不等于
-gt 是否大于
-lt 是否小于
-le 是否等于或小于
-ge 是否大于或等于
先测试一下
10
是否大于
10
以及
10
是否等于
10(通过输出的返回值内容来判断):

在
2.4
节曾经讲过
free 命令,它能够用来获取当前系统正在使用及可用的内存量信息。接下来先使用
free -m
命令查看内存使用量情况(单位为
MB
),然后通过“
grep Mem:”命令过滤出剩余内存量的行,再用
awk '{print $4}'
命令只保留第 4 列。

如果想把这个命令写入到
Shell 脚本中,那么建议把输出结果赋值给一个变量,以方便其他命令进行调用:

。我们使用整数运算符来判断内存可用量的值是否小于
1024,若小于则会提示“
Insufficient Memory
”(内存不足)的字样:
字符串比较语句用于判断测试字符串是否为空值,或两个字符串是否相同。它经常用来判断某个变量是否未被定义(即内容为空值),理解起来也比较简单。
常见的字符串比较运算符
= 比较字符串内容是否相同
!= 比较字符串内容是否不同
-z 判断字符串内容是否为空
接下来通过判断
String
变量是否为空值,进而判断是否定义了这个变量:

再次尝试引入逻辑运算符来试一下。当用于保存当前语系的环境变量值
LANG 不是英语(
en.US
)时,则会满足逻辑测试条件并输出“
Not en.US
”(非英语)的字样:

3.流程控制语句
尽管此时可以通过使用 Linux 命令、管道符、重定向以及条件测试语句来编写最基本的 Shell脚本,但是这种脚本并不适用于生产环境。原因是它不能根据真实的工作需求来调整具体的执行命令,也不能根据某些条件实现自动循环执行。通俗来讲,就是不能根据实际情况做出调整。
通常脚本都是从上到下一股脑儿地执行,效率是很高,但一旦某条命令执行失败了,则后面的功能全都会受到影响。
接下来我们通过
if
、
for
、
while
、
case
这
4 种流程控制语句来学习编写难度更大、功能更强的
Shell
脚本。
1.if条件测试语句
if
条件测试语句可以让脚本根据实际情况自动执行相应的命令。从技术角度来讲,
if 语句分为单分支结构、双分支结构、多分支结构;其复杂度随吗 着灵活度一起逐级上升。
if
条件语句的单分支结构由
if
、
then
、
fi 关键词组成,而且只在条件成立后才执行预设的命令,相当于口语的“如果……那么……”。单分支的
if
语句属于最简单的一种条件判断结构,

下面使用单分支的
if
条件语句来判断
/media/cdrom 目录是否存在,若不存在就创建这个目录,反之则结束条件判断和整个
Shell
脚本的执行。

这里继续用“
bash 脚本名称”的方式来执行脚本。在正常情况下,顺利执行完脚本文件后没有任何输出信息,但是可以使用
ls 命令验证/media/cdrom
目录是否已经成功创建:

if
条件语句的双分支结构由
if
、
then
、
else
、fi 关键词组成,它进行一次条件匹配判断,如果与条件匹配,则去执行相应的预设命令;反之则去执行不匹配时的预设命令,相当于口语的“如果……那么……或者……那么……”。
if 条件语句的双分支结构也是一种很简单的判断结构,

下面使用双分支的
if 条件语句来验证某台主机是否在线,然后根据返回值的结果,要么显示主机在线信息,要么显示主机不在线信息。这里的脚本主要使用
ping 命令来测试与对方主机的网络连通性,而
Linux
系统中的
ping
命令不像
Windows
一样尝试
4 次就结束,因此为了避免用户等待时间过长,需要通过
-c
参数来规定尝试的次数,并使用
-i 参数定义每个数据包的发送间隔,以及使用
-W
参数定义等待超时时间。

我们在
4.2.3
节中用过
$?变量,作用是显示上一次命令的执行返回值。若前面的那条语句成功执行,则
$?
变量会显示数字
0
,反之则显示一个非零的数字(可能为
1
,也可能为
2,取决于系统版本)。因此可以使用整数比较运算符来判断
$?
变量是否为
0,从而获知那条语句的最终判断情况。这里的服务器
IP
地址为
192.168.10.10
,我们来验证一下脚本的效果:

if
条件语句的多分支结构由
if
、
then
、
else
、
elif
、fi 关键词组成,它进行多次条件匹配判断,这多次判断中的任何一项在匹配成功后都会执行相应的预设命令,相当于口语的“如果……那么……如果……那么……”。
if 条件语句的多分支结构是工作中最常使用的一种条件判断结构,尽管相对复杂但是更加灵活,
下面使用多分支的
if 条件语句来判断用户输入的分数在哪个成绩区间内,然后输出如Excellent
、
Pass
、
Fail
等提示信息。在
Linux
系统中,read 是用来读取用户输入信息的命令,能够把接收到的用户输入信息赋值给后面的指定变量,-p
参数用于向用户显示一些提示信息。

在下面的脚本示例中,只有当用户输入的分数大于等于
85
分且小于等于
100 分时,才输出
Excellent
字样;若分数不满足该条件(即匹配不成功),则继续判断分数是否大于等于 70分且小于等于
84
分,如果是,则输出
Pass 字样;若两次都落空(即两次的匹配操作都失败了),则输出
Fail
字样:
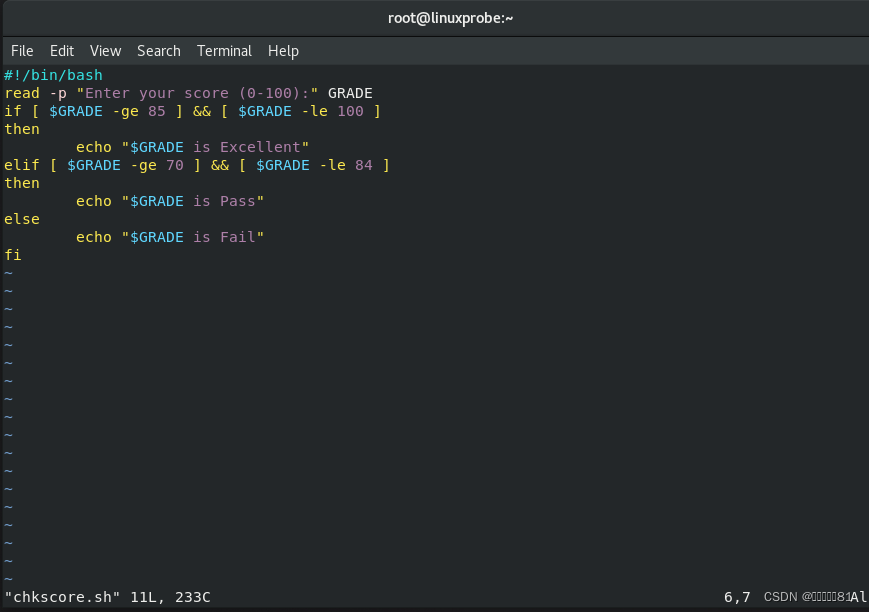

下面执行该脚本。当用户输入的分数为
200
时,其结果如下:

输入的分数为
200 时,没有成功匹配脚本中的两个条件判断语句,因此自动执行了最终的兜底策略。完善这个脚本,使得用户在输入大于
100
或小于
0
的分数时报错:
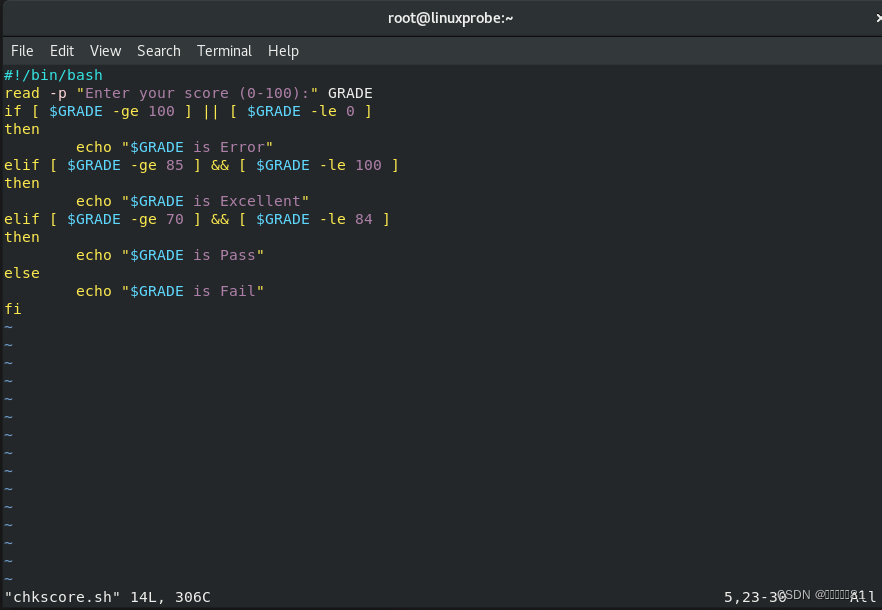

2.for条件循环语句
for 循环语句允许脚本一次性读取多个信息,然后逐一对信息进行操作处理。当要处理的数据有范围时,使用
for
循环语句就再适合不过了。

下面使用
for 循环语句从列表文件中读取多个用户名,然后为其逐一创建用户账户并设置密码。首先创建用户名称的列表文件
users.txt
,每个用户名称单独一行。
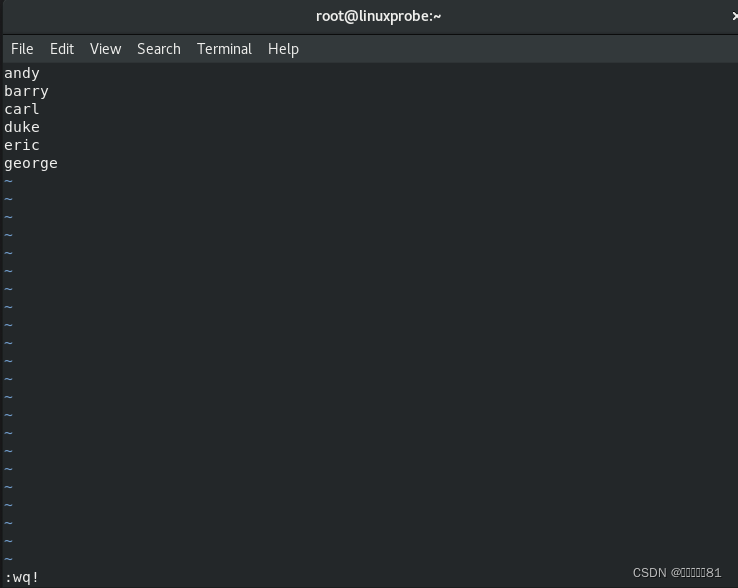
接下来编写
Shell
脚本
addusers.sh
。在脚本中使用
read 命令读取用户输入的密码值,然后赋值给
PASSWD
变量,并通过
-p 参数向用户显示一段提示信息,告诉用户正在输入的内容即将作为账户密码。在执行该脚本后,会自动使用从列表文件
users.txt
中获取到所有的用户
名称,然后逐一使用“
id
用户名”命令查看用户的信息,并使用
$?判断这条命令是否执行成功,也就是判断该用户是否已经存在。
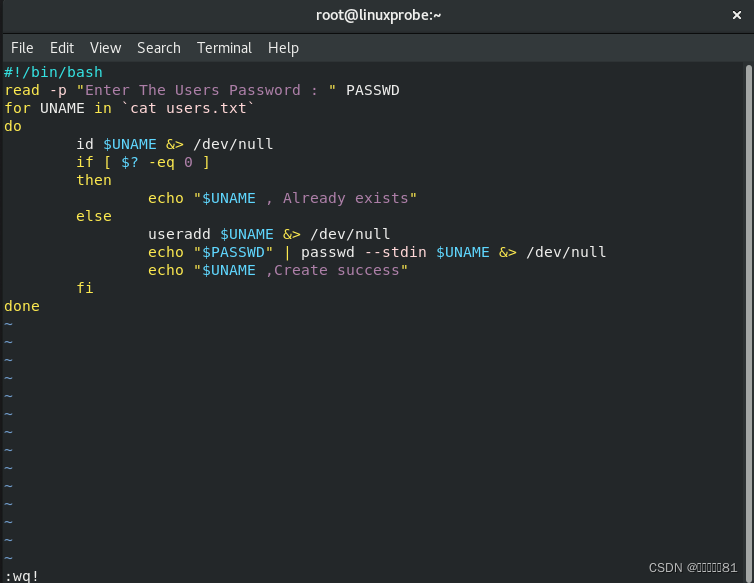
useradd 用户名;用来增加用户
/dev/null 是一个被称作 Linux 黑洞的文件,把输出信息重定向到这个文件等同于删 数据(类似于没有回收功能的垃圾箱),可以让用户的屏幕窗口保持简洁。

尝试让脚本从文本中自动读取主机列表,然后自动逐个测试这些主机是否在线。
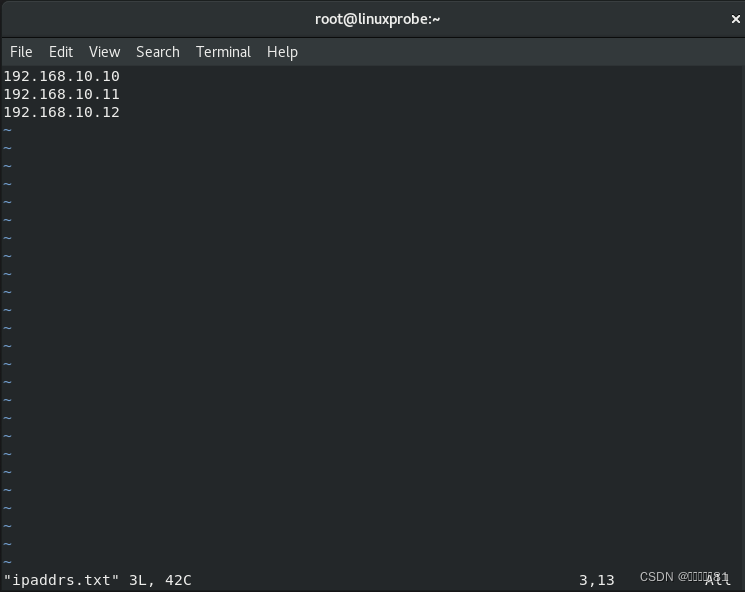
首先创建一个主机列表文件
ipaddrs.txt
:
然后将前面的双分支
if
条件语句与
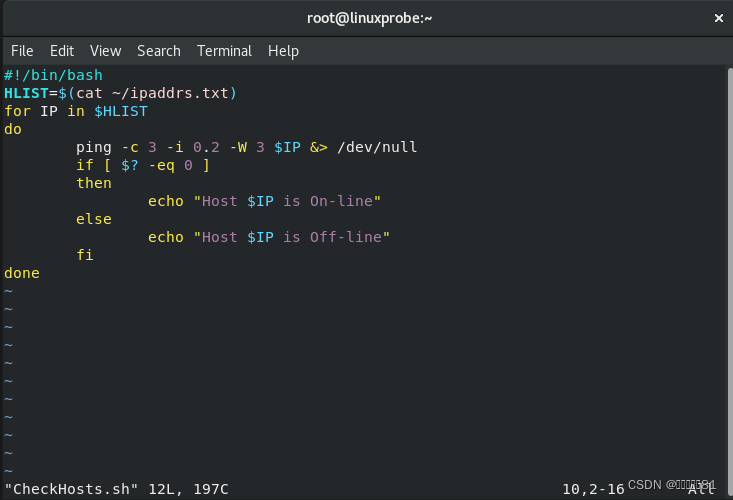
for 循环语句相结合,让脚本从主机列表文件ipaddrs.txt
中自动读取
IP
地址(用来表示主机)并将其赋值给
HLIST
变量,从而通过判断 ping命令执行后的返回值来逐个测试主机是否在线。脚本中出现的“
$(命令)”是一种完全类似于第
3
章的转义字符中反引号
`
命令
`
的
Shell 操作符,效果同样是执行括号或双引号括起来的字符串中的命令。大家在编写脚本时,多学习几种类似的新方法,可在工作中大显身手:

$(cat ~/ipaddrs.txt) 相当于`cat ~/ipaddrs.txt`
3.while条件循环语句
while 条件循环语句是一种让脚本根据某些条件来重复执行命令的语句,它的循环结构往往在执行前并不确定最终执行的次数,完全不同于
for 循环语句中有目标、有范围的使用场景。while 循环语句通过判断条件测试的真假来决定是否继续执行命令,若条件为真就继续执行,为假就结束循环。

接下来结合使用多分支的
if
条件测试语句与
while 条件循环语句,编写一个用来猜测数值大小的脚本
Guess.sh
。该脚本使用
$RANDOM
变量来调取出一个随机的数值(范围为
0~32767
),然后将这个随机数对
1000
进行取余操作,并使用
expr 命令取得其结果,再用这个数值与用户通过
read
命令输入的数值进行比较判断。
。这个判断语句分为
3 种情况,分别是判断用户输入的数值是等于、大于还是小于使用
expr 命令取得的数值。当前,现在这些内 容不是重点,我们要关注的是
while
条件循环语句中的条件测试始终为
true,因此判断语句会无限执行下去,直到用户输入的数值等于
expr
命令取得的数值后,才运行
exit 0 命令,终止脚本的执行。


当条件为
true
(真)的时候,
while
语句会一直循环下去,只有碰到
exit 才会结束,所以同学们一定要记得加上
exit
哦。
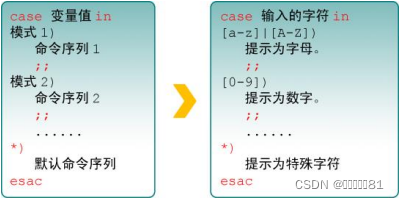
4.case条件测试语句
case 语句是在多个范围内匹配数据,若匹配成功则执行相关命令并结束整个条件测试;如果数据不在所列出的范围内,则会去执行星号(
*
)中所定义的默认命令。
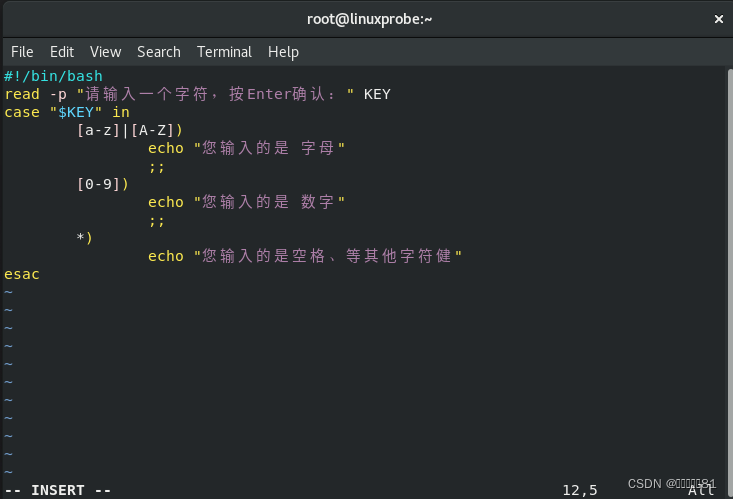
通过在脚本中组合使用
case
条件测试语句和通配符
,完全可以满足这里的需求。接下来我们编写脚本
Checkkeys.sh
,提示用户输入一个字符并将其赋值给变量
KEY,然后根据变量
KEY 的值向用户显示其值是字母、数字还是其他字符。
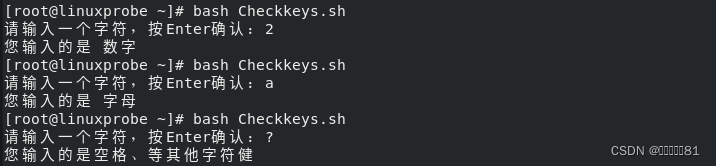
4.计划任务服务程序
设置服务器的计划任务服务,把周期性、规律性的工作交给系统自动完成。
计划任务分为一次性计划任务与长期性计划任务
一次性任务:今晚23:00重启网站服务
长期性计划任务:每周一凌晨
3:00
把
/home/wwwroot
目录打包备份为
backup.tar.gz
。
顾名思义,一次性计划任务只执行一次,一般用于临时的工作需求。可以用
at 命令实现这种功能,只需要写成“
at 时间”的形式就行。如果想要查看已设置好但还未执行的一次性计划任务,可以使用
at -l
命令;要想将其删除,可以使用“
atrm
任务序号”。
at 命令中的参数及其作用
-f 指定包含命令的任务文件
-q 指定新任务名称
-l 显示待执行任务的列表
-d 删除指定的待执行任务
-m 任务执行后向用户发邮件
在使用
at 命令来设置一次性计划任务时,默认采用的是交互式方法。例如,使用下述命令将系统设置为在今晚
23:00
自动重启网站服务。

看到
warning
提醒信息不要慌,
at
命令只是在告诉我们接下来的任务将由
sh 解释器负责执行。这与此前学习的
Bash
解释器基本一致,不需要有额外的操作。
让
at
命令接收前面
echo 命令的输出信息,以达到通过非交互式的方式创建计划一次性任务的目的。

上面设置了两条一样的计划任务,可以使用
atrm
命令轻松删除其中一条:

这里还有一种特殊场景
—
把计划任务写入
Shell 脚本中,当用户激活该脚本后再开始倒计时执行,而不是像上面那样在固定的时间(“
at 23:30”命令)进行。这该怎么办呢?
一般我们会使用“
at now +2 MINUTE
”的方式进行操作,这表示
2
分钟(
MINUTE)后执行这个任务,也可以将其替代成小时(
HOUR
)、日(
DAY
)、月(
MONTH
)等词汇:

还有些时候,我们希望
Linux 系统能够周期性地、有规律地执行某些具体的任务,那么Linux
系统中默认启用的
crond
服务简直再适合不过了。创建、编辑计划任务的命令为 crontab-e
,查看当前计划任务的命令为
crontab -l
,删除某条计划任务的命令为
crontab -r。另外,如果您是以管理员的身份登录的系统,还可以在
crontab
命令中加上
-u 参数来编辑他人的计划任务。
crontab 命令中的参数及其作用
-e 编辑计划任务
-u 指定用户名称
-l 列出任务列表
-r 删除计划任务
“分、时、日、月、星期 命令”。
这是使用 crond
服务设置任务的参数格式。需要注意的是,如果有些字段 没有被设置,则需要使用星号(*)占位,如图
4-24
所示。

使用
crond
设置任务的参数字段说明
Vim 编辑器与 Shell 命令脚本
字段 说明
分钟 取值为 0~
59
的整数
小时 取值为 0~
23
的任意整数
日期 取值为 1~
31
的任意整数
月份 取值为 1~
12
的任意整数
星期 取值为 0~
7
的任意整数,其中
0
与
7
均为星期日
命令 要执行的命令或程序脚本
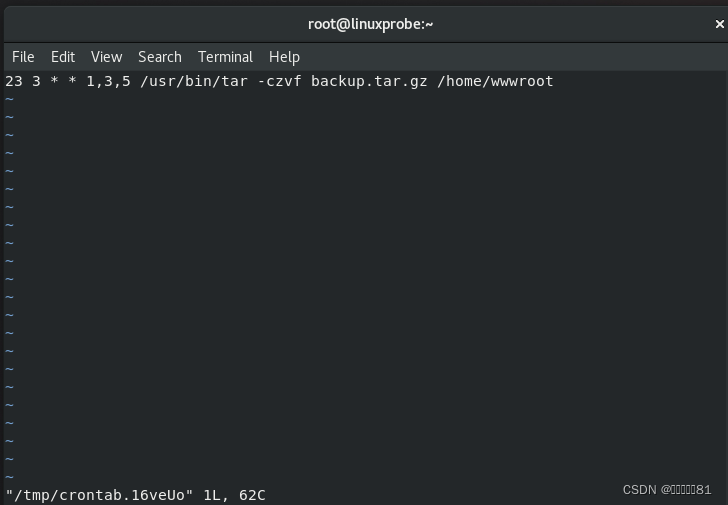
假设在每周一、三、五的凌晨
3:25
,都需要使用
tar 命令把某个网站的数据目录进行打包处理,使其作为一个备份文件。我们可以使用
crontab -e 命令来创建计划任务,为自己创建计划任务时无须使用
-u
参数。
crontab –e
命令的具体实现效果和
crontab -l
命令的结果如下所示:

需要说明的是,除了用逗号(,
)来分别表示多个时间段,例如“
8,9,12
”表示
8
月、
9 月和
12 月。还可以用减号(-
)来表示一段连续的时间周期(例如字段“日”的取值为“
12-15”,则表示每月的
12
~
15 日)。还可以用除号(/
)表示执行任务的间隔时间(例如“
*/2”表示每隔
2
分钟执行一次任务)。
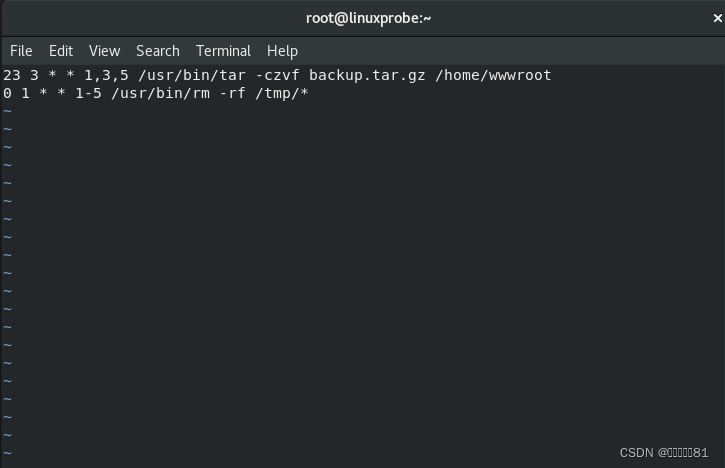
如果在
crond 服务中需要同时包含多条计划任务的命令语句,应每行仅写一条。例如我们再添加一条计划任务,它的功能是每周一至周五的凌晨
1
点自动清空
/tmp 目录内的所有文件。尤其需要注意的是,在
crond 服务的计划任务参数中,所有命令一定要用绝对路径的方式来写,如果不知道绝对路径,请用
whereis
命令进行查询。

总结一下使用计划服务的注意事项。
➢
在
crond
服务的配置参数中,一般会像
Shell
脚本那样以
#号开头写上注释信息,这样在日后回顾这段命令代码时可以快速了解其功能、需求以及编写人员等重要信息。
➢
计划任务中的“分”字段必须有数值,绝对不能为空或是
*号,而“日”和“星期”字段不能同时使用,否则就会发生冲突。
删除
crond
计划任务则非常简单,直接使用
crontab -e 命令进入编辑界面,删除里面的文本信息即可。也可以使用
crontab -r
命令直接进行删除:

四、用户身份与文件权限
Linux 是一个多用户、多任务的操作系统,具有很好的稳定性与安全性,在幕后保障 Linux系统的安全则是一系列复杂的配置工作。本章将详细讲解文件的所有者、所属组以及其他人可对文件进行的读(r
)、写(
w
)、执行(
x
)等操作,还将介绍如何在
Linux 系统中添加、删除、修改用户账户信息。
我们还可以使用
SUID
、
SGID
与 SBIT 特殊权限更加灵活地设置系统权限,来弥补对文件设置一般操作权限时所带来的不足。隐藏权限能够给系统增加一层隐形的防护层,让黑客最多只能查看关键日志信息,而不能篡改或删除。而文件访问控制列表(
Access Control List,ACL)可以进一步让单一用户、用户组对单一文件或目录进行特殊的权限设置,让文件具有能满足工作需求的最小权限。
1.用户身份与能力
Linux 系统的设计初衷之一就是为了满足多个用户同时工作的需求,因此必须具备很好的安全性,尤其是不能因为一两个服务出错而影响到整台服务器。在
安装
Linux
操作系统时,特别要求设置
root
管理员的密码,这个
root 管理员就是存在于所有类
UNIX 系统中的超级用户。它拥有最高的系统所有权,能够管理系统的各项功能,如添加
/
删除用户、启动
/
关闭服务进程、开启
/
禁用硬件设备等。虽然以
root 管理员的身份工作时不会受到系统的限制,但俗话讲“能力越大,责任就越大”,因此一旦使用这个高能的 root管理员权限执行了错误的命令,可能会直接毁掉整个系统。
Linux
系统的管理员之所以是
root
,并不是因为它的名字叫
root,而是因为该用户的身份号码即
UID
(
User IDentification
)的数值为
0
。在
Linux
系统中,
UID 就像我们的身份证号码一样具有唯一性,因此可通过用户的
UID
值来判断用户身份。在
RHEL 8 系统中,用户身份有下面这些。
管理员UID为0:
系统的管理员用户。
系统用户UID为1~999:Linux 系统为了避免因某个服务程序出现漏洞而被黑客提权至整台服务器,默认服务程序会由独立的系统用户负责运行,进而有效控制被破坏范围。
普通用户UID从1000开始:
是由管理员创建的用于日常工作的用户。
需要注意的是,
UID
是不能冲突的,而且管理员创建的普通用户的
UID
默认是从 1000开始的(即使前面有闲置的号码)
为了方便管理属于同一组的用户,
Linux
系统中还引入了用户组的概念。通过使用用户
组号码(
GID
,
Group IDentification
),可以把多个用户加入到同一个组中,从而方便为组中的
用户统一规划权限或指定任务。假设一个公司中有多个部门,每个部门中又有很多员工,如
果只想让员工访问本部门内的资源,则可以针对部门而非具体的员工来设置权限。
另外,在 Linux 系统中创建每个用户时,将自动创建一个与其同名的基本用户组,而且这个基本用户组只有该用户一个人。如果该用户以后被归纳到其他用户组,则这个其他用户组称之为扩展用户组。一个用户只有一个基本用户组,但是可以有多个扩展用户组,从而满 足日常的工作需要。
1.id命令
id
命令用于显示用户的详细信息,语法格式为“
id
用户名”。
这个
id 命令是一个在创建用户前需要仔细学习的命令,它能够简单轻松地查看用户的基本信息,例如用户
ID
、基本组与扩展组
GID,以便于我们判别某个用户是否已经存在,以及查看相关信息。
下面使用
id
命令查看一个名称为
linuxprobe
的用户信息:
2.useradd命令
useradd
命令用于创建新的用户账户,语法格式为“
useradd [
参数
]
用户名”
可以使用
useradd 命令创建用户账户。使用该命令创建用户账户时,默认的用户家目录会被存放在
/home
目录中,默认的
Shell
解释器为
/bin/bash,而且默认会创建一个与该用户同名的基本用户组。这些默认设置可以根据
useradd
命令参数自行修改。
useradd 命令中的参数以及作用
-d 指定用户的家目录(默认为/home/username)
-e 账户的到期时间,格式为 YYYY-MM-DD.
-u 指定该用户的默认 UID
-g 指定一个初始的用户基本组(必须已存在)
-G 指定一个或多个扩展用户组
-N 不创建与用户同名的基本用户组
-s 指定该用户的默认 Shell 解释器

下面我们提高难度,创建一个普通用户并指定家目录的路径、用户的
UID
以及
Shell 解释器。在下面的命令中,请注意
/sbin/nologin
,它是终端解释器中的一员,与
Bash 解释器有着天壤之别。一旦用户的解释器被设置为
nologin
,则代表该用户不能登录到系统中:

3.groupadd命令
groupadd
命令用于创建新的用户组,语法格式为“
groupadd [
参数
]
群组名”。
为了能够更加高效地指派系统中各个用户的权限,在工作中常常会把几个用户加入到同一个组里面,这样便可以针对一类用户统一安排权限。例如在工作中成立一个部门组,当有用户身份与文件权限新的同事加入时就把他的账号添加到这个部门组中,这样新同事的权限就自动跟其他同事一
模一样了,从而省去了一系列烦琐的操作。
创建用户组的步骤非常简单,例如使用如下命令创建一个用户组
ronny
:
4.usermod命令
usermod
命令用于修改用户的属性,英文全称为“
user modify
”,语法格式为“
usermod [参数
]
用户名”。
Linux 系统中的一切都是文件,因此在系统中创建用户也就是修改配置文件的过程。用户的信息保存在
/etc/passwd 文件中,可以直接用文本编辑器来修改其中的用户参数项目,也可以用
usermod
命令修改已经创建的用户信息,比如用户的
UID
、基本
/扩展用户组、默认终端等。
usermod 命令中的参数以及作用
-c 填写用户账户的备注信息
-d -m 参数-m 与参数-d 连用,可重新指定用户的家目录并自动把旧的数据转移过去
-e 账户的到期时间,格式为 YYYY-MM-DD
-g 变更所属用户组
-G 变更扩展用户组
-L 锁定用户禁止其登录系统
-U 解锁用户,允许其登录系统
-s 变更默认终端
-u 修改用户的 UID
我们先来看一下账户
linuxprobe
的默认信息:
然后将用户
linuxprobe
加入到
root
用户组中,这样扩展组列表中则会出现
root 用户组的字样,而基本组不会受到影响:

再来试试用
-u
参数修改
linuxprobe
用户的
UID
号码值:

除此之外,如果把用户的解释器终端由默认的
/bin/bash 修改为/sbin/nologin
后会有什么样的效果呢?我们来试试吧:

将用户的终端设置成/sbin/nologin 后用户马上就不能登录了(切换身份也不行),但这个用户依然可以被某个服务所调用,管理某个具体的服务。这样的好处是当黑客通过这个服务入侵成功后,破坏的范围也仅仅局限于这个特定的服务,而不能使用这个用户身份登录到整台服务器上,从而尽可能地把损失降至最小化。
5.passwd命令
passwd
命令用于修改用户的密码、过期时间等信息,英文全称为“
password”,语法格式为“
passwd [
参数
]
用户名”。
普通用户只能使用
passwd
命令修改自己的系统密码,而
root 管理员则有权限修改其他所有人的密码。更酷的是,
root
管理员在
Linux 系统中修改自己或他人的密码时不需要验证旧密码,这一点特别方便。既然
root 管理员能够修改其他用户的密码,就2表示其完全拥有该用户的管理权限。
passwd 命令中的参数以及作用
-l 锁定用户,禁止其登录
-u 解除锁定,允许用户登录
--stdin 通过标准输入修改用户密码,如 echo "NewPassWord" | passwd --stdin Username
-d 使该用户可用空密码登录系统
-e 强制用户在下次登录时修改密码
-S 显示用户的密码是否被锁定,以及密码所采用的加密算法名称
要修改自己的密码,只需要输入命令后敲击回车键即可:

要修改其他人的密码,则需要先检查当前是否为
root 管理员权限,然后在命令后指定要修改密码的那位用户的名称:

假设您有位同事正在度假,而且假期很长,那么可以使用
passwd 命令禁止该用户登录系统,等假期结束回归工作岗位时,再使用该命令允许用户登录系统,而不是将其删除。这样用既保证了这段时间内系统的安全,也避免了频繁添加、删除用户带来的麻烦:

在解锁时,记得也要使用管理员的身份;否则,如果普通用户也有锁定权限,系统肯定会乱成一锅粥:

6.userdel命令
userdel
命令用于删除已有的用户账户,英文全称为“
user delete
”,语法格式为“
userdel [参数
]
用户名”。
如果确认某位用户后续不会再登录到系统中,则可以通过
userdel 命令删除该用户的所有信息。在执行删除操作时,该用户的家目录默认会保留下来,此时可以使用
-r
参数将其删除。
userdel 命令中的参数以及作用
-f 强制删除用户
-r 同时删除用户及用户家目录
在删除一个用户时,一般会建议保留他的家目录数据,以免有重要的数据被误删除。所以在使用
userdel
命令时可以不加参数,写清要删除的用户名称就行:

虽然此时该用户已被删除,但家目录数据会继续存放在
/home 目录中,等确认未来不再使用时将其手动删除即可:

7.chage修改密码的过期时间
/etc/login.defs文件修改默认设置密码的使用时间
从用户组中移除某个用户
从用户组中移除某个用户

2.文件权限与归属
在 Linux 系统中,每个文件都有归属的所有者和所属组,并且规定了文件的所有者、所用户身份与文件权限属组以及其他人对文件所拥有的可读(r
)、可写(
w
)、可执行(
x)等权限。对于一般文件来说,权限比较容易理解:“可读”表示能够读取文件的实际内容;“可写”表示能够编辑、新
增、修改、删除文件的实际内容;“可执行”则表示能够运行一个脚本程序。但是,对于目录文件来说,理解其权限设置就不那么容易了。很多资深 Linux 用户其实也没有真正搞明白。对于目录文件来说,“可读”表示能够读取目录内的文件列表;“可写”表示能够在目录内新增、删除、重命名文件;而“可执行”则表示能够进入该目录。
可读、可写、可执行权限对应的命令在文件和目录上的区别
文件 目录
可读(r) cat ls
可写(w) vim touch、rm
可执行(x) ./script cd
文件的可读、可写、可执行权限的英文全称分别是
read
、
write
、
execute
,可以简写为
r、w
、
x
,亦可分别用数字
4
、
2
、
1 来表示,文件所有者、文件所属组及其他用户权限之间无关联,
文件权限的字符与数字表示
权限项: 可读 可写 可执行 可读 可写 可执行 可读 可写 可执行
字符表示:r w x r w x r w x
数字表示:4 2 1 4 2 1 4 2 1
权限分配: 文件所有者 文件所属组 其他用户
文件权限的数字表示法基于字符(
rwx)的权限计算而来,其目的是简化权限的表示方式。例如,若某个文件的权限为
7
,则代表可读、可写、可执行(
4+2+1
);若权限为
6,则代表可读、可写(4+2)。我们来看一个例子。现在有这样一个文件,其所有者拥有可读、可写、可执行的权限,其文件所属组拥有可读、可写的权限;其他人只有可读的权限。那么,这个文件的权限就是
rwxrw-r--
,数字法表示即为
764
。不过大家千万别再将这
3 个数字相加,计算出
7+6+4=17
的结果,这是小学的数学加减法,不是
Linux 系统的权限数字表示法,三者之间没有互通关系。
这里以
rw-r-x-w-权限为例来介绍如何将字符表示的权限转换为数字表示的权限。首先,要将各个位上的字符替换为数字,
减号是占位符,代表这里没有权限,在数字表示法中用
0
表示。也就是说,
rw-转换后是420
,
r-x
转换后是
401
,
-w-
转换后是
020
。然后,将这
3 组数字之间的每组数字进行相加,得出
652
,这便是转换后的数字表示权限。
将数字表示权限转换回字母表示权限的难度相对来说就大一些了,这里以
652 权限为例进行讲解。首先,数字
6
是由
4+2
得到的,不可能是
4+1+1(因为每个权限只会出现一次,不可能同时有两个
x
执行权限);数字
5
则是
4+1
得到的;数字
2 是本身,没有权限即是空值0
。接下来按照表
5-6
所示的格式进行书写,得到
420401020 这样一串数字。有了这些信息就好办了,就可以把这串数字转换成字母了,
文件的所有者、所属组和其他用户的权限之间无关联。一定不要写成
rrwwx----
的样子,一定要把
rwx
权限位对应到正确的位置,写成
rw-r-x-w-
。


文件的类型、访问权限、所有者(属主)、所属组(属组)、占用的磁盘大小、最后修改时间和文件名称等信息。通过分析可知,该文件的类型为普通文件,所有者权限为可读、可写(
rw-),所属组权限为可读(r--),除此以外的其他人也只有可读权限(r--),文件的磁盘占用大小是
34298
字节,最近一次的修改时间为
4
月
2
日的
0:23
,文件的名称为
install.log。
排在权限前面的减号(-)是文件类型(减号表示普通文件),新手经常会把它跟“无权限”混淆。尽管在
Linux 系统中一切都是文件,但是不同的文件由于作用不同,因此类型也不尽相同(有一点像
Windows 系统的后缀名)。常见的文件类型包括普通文件(-)、目录文件(
d)、链接文件(l)、管道文件(p)、块设备文件(b)以及字符设备文件(c
)。
普通文件的范围特别广泛,比如纯文本信息、服务配置信息、日志信息以及 Shell 脚本等,都属于普通文件。几乎在每个目录下都能看到普通文件(-
)和目录文件(
d)的身影。块设备文件(
b)和字符设备文件(c
)一般是指硬件设备,比如鼠标、键盘、光驱、硬盘等,在/dev/目录中最为常见。
3.文件的特殊权限
在复杂多变的生产环境中,单纯设置文件的
rwx 权限无法满足我们对安全和灵活性的需求,因此便有了
SUID
、
SGID
与
SBIT 的特殊权限位。这是一种对文件权限进行设置的特殊功能,可以与一般权限同时使用,以弥补一般权限不能实现的功能。
1.SUID
SUID 是一种对二进制程序进行设置的特殊权限,能够让二进制程序的执行者临时拥有所有者的权限(仅对拥有执行权限的二进制程序有效)。例如,所有用户都可以执行passwd
命令来修改自己的用户密码,而用户密码保存在
/etc/shadow 文件中。仔细查看这个文件就会发现它的默认权限是
000
,也就是说除了
root 管理员以外,所有用户都没有查看或编辑该文件的权限。但是,在使用
passwd
命令时如果加上
SUID 特殊权限位,就可让普通用户临时获得程序所有者的身份,把变更的密码信息写入到
shadow 文件中。因此这只是一种有条件的、临时的特殊权限授权方法。
查看
passwd
命令属性时发现所有者的权限由
rwx
变成了
rws
,其中
x
改变成
s 就意味着该文件被赋予了
SUID
权限。那么如果原本的权限是
rw-,原先权限位上没有
x
执行权限,那么被赋予特殊权限后将变成大写的
S
。

2.SGID
SGID 特殊权限有两种应用场景:当对二进制程序进行设置时,能够让执行者临时获取文件所属组的权限;当对目录进行设置时,则是让目录内新创建的文件自动继承该目录原有用户组的名称。
SGID
的第一种功能是参考
SUID 而设计的,不同点在于执行程序的用户获取的不再是文件所有者的临时权限,而是获取到文件所属组的权限。举例来说,在早期的
Linux 系统中,/dev/kmem
是一个字符设备文件,用于存储内核程序要访问的数据,权限为:
大家看出问题了吗?除了
root
管理员或属于 system 组的成员外,所有用户都没有读取该文件的权限。由于在平时需要查看系统的进程状态,为了能够获取进程的状态信息,可在用于查看系统进程状态的
ps
命令文件上增加
SGID
特殊权限位。下面查看
ps 命令文件的属性信息:
这样一来,由于
ps
命令被增加了
SGID 特殊权限位,所以当用户执行该命令时,也就临时获取到了
system
用户组的权限,从而顺利地读取到了设备文件。
每个文件都有其归属的所有者和所属组,当创建或传送一个文件后,这个文件就会自动归属于执行这个操作的用户(即该用户是文件的所有者)。如果现在需要在一个部门内设置共享目录,让部门内的所有人员都能够读取目录中的内容,那么就可以在创建部门共享目录后,在该目录上设置 SGID 特殊权限位。这样,部门内的任何人员在里面创建的任何文件都会归属于该目录的所属组,而不再是自己的基本用户组。此时,用到的就是SGID 的第二个功能,即在某个目录中创建的文件自动继承该目录的用户组(只可以对目录进行设置)。

在使用上述命令设置好目录的
777 权限(确保普通用户可以向其中写入文件),并为该目录设置了
SGID 特殊权限位后,就可以切换至一个普通用户,然后尝试在该目录中创建文件,并查看新创建的文件是否会继承新创建的文件所在的目录的所属组名称:

除了上面提到的
SGID
的这两个功能,再介绍两个与本节内容相关的命令:
chmod 和chown
。
chmod
命令用于设置文件的一般权限及特殊权限,英文全称为“
change mode”,语法格式为“
chmod [参数] 文件名”。
这是一个与文件权限的日常设置强相关的命令。例如,要把一个文件的权限设置成其所有者可读可写可执行、所属组可读可写、其他人没有任何权限,则相应的字符法表示为rwxrw----
,其对应的数字法表示为
760
。

chown
命令用于设置文件的所有者和所有组,英文全称为
change own
,语法格式为“chown所有者
:所有组 文件名”。/chgrp 单独修改用户组
chmod
和
chown 命令是用于修改文件属性和权限的最常用命令,它们还有一个特别的共性,就是针对目录进行操作时需要加上大写参数
-R 来表示递归操作,即对目录内所有的文件进行整体操作。
下面使用“所有者
:所有组”的格式把前面那个文件的所属信息轻松修改一下,变更后的效果如下:

3.SBIT
SBIT 特殊权限位可确保用户只能删除自己的文件,而不能删除其他用户的文件。换句话说,当对某个目录设置了
SBIT 粘滞位权限后,那么该目录中的文件就只能被其所有者执行删除操作了
RHEL 8
系统中的
/tmp 作为一个共享文件的目录,默认已经设置了
SBIT 特殊权限位,因此除非是该目录的所有者,否则无法删除这里面的文件。
与
SUID
和
SGID
权限显示方法不同,当目录被设置
SBIT 特殊权限位后,文件的其他用户权限部分的
x
执行权限就会被替换成
t
或者
T
—
原本有
x
执行权限则会写成
t,原本没有
x
执行权限则会被写成
T
。
由下可知,
/tmp
目录上的
SBIT 权限默认已经存在,这体现为“其他用户”权限字段的权限变为
rwt
:
其实,文件能否被删除并不取决于自身的权限,而是看其所在目录是否有写入权限。为了避免现在很多读者不放心,所以下面的命令还是赋予了这个 test文件最大的
777
权限(
rwxrwxrwx
):

随后,切换到一个普通用户身份下,尝试删除这个由其他人创建的文件,这时就会发现,即便读、写、执行权限全开,但是由于
SBIT 特殊权限位的缘故,依然无法删除该文件:

SUID
、
SGID
、
SBIT
特殊权限的设置参数
u+s 设置 SUID 权限
u-s 取消 SUID 权限
g+s 设置 SGID 权限
g-s 取消 SGID 权限
o+t 设置 SBIT 权限
o-t 取消 SBIT 权限
切换回
root
管理员的身份下,在家目录中创建一个名为
linux 的新目录,随后为其设置SBIT
权限:

SUID
、
SGID
与
SBIT
也有对应的数字表示法,分别为
4
、
2
、
1
。也就是说
777 还不是最大权限,最大权限应该是
7777
,其中第
1 个数字代表的是特殊权限位。数字表示法是由“特殊权限
+一般权限”构成的,在
rwxr-xr-t
权限中,最后一位是
t
,这说明该文件的一般权限为 rwxr-xr-x,并带有 SBIT 特殊权限。—
rwxr-xr-x
即
755
,而
SBIT
特殊权限位是
1
,则合并后的结果为
1755
。
再增加点难度,如果权限是“
rwsrwSr--
”,大写
S 表示原先没有执行权限,因此一般权限为
rwxrw-r--
,将其转换为数字表示法后结果是
764
。带有的
SUID
和 SGID 特殊权限的数字法表示是
4
和
2
,心算得出结果是
6
,合并后的结果为
6764
。

4.文件的隐藏属性
Linux 系统中的文件除了具备一般权限和特殊权限之外,还有一种隐藏权限,即被隐藏起来的权限,默认情况下不能直接被用户发觉。有用户曾经在生产环境和 RHCE 考试题目中碰到过明明权限充足但却无法删除某个文件的情况,或者仅能在日志文件中追加内容而不能修改或删除内容的情况,这在一定程度上阻止了黑客篡改系统日志的图谋,因此这种“奇怪”的文件权限也保障了
Linux
系统的安全性。
既然叫隐藏权限,那么使用常规的
ls 命令肯定不能看到它的真面目。隐藏权限的专用设置命令是
chattr
,专用查看命令是
lsattr
。
1.chattr命令
chattr
命令用于设置文件的隐藏权限,英文全称为
change attributes
,语法格式为“
chattr [
参
数
]
文件名称”。
如果想要把某个隐藏功能添加到文件上,则需要在命令后面追加“+参数”,如果想要把某个隐藏功能移出文件,则需要追加“-
参数”。
chattr 命令中可供选择的隐藏权限参数非常丰富
chattr
命令中的参数及其作用
i 无法对文件进行修改;若对目录设置了该参数,则仅能修改其中的子文件内容而不能新建或删除文件
a 仅允许补充(追加)内容,无法覆盖
/
删除内容(
Append Only
)
S 文件内容在变更后立即同步到硬盘(
sync
)
s 彻底从硬盘中删除,不可恢复(用零块填充原文件所在的硬盘区域)
A 不再修改这个文件或目录的最后访问时间(
Atime
)
b 不再修改文件或目录的存取时间
D 检查压缩文件中的错误
d 使用
dump
命令备份时忽略本文件
/
目录
c 默认将文件或目录进行压缩
u 当删除该文件后依然保留其在硬盘中的数据,方便日后恢复
t 让文件系统支持尾部合并(
tail-merging
)
x 可以直接访问压缩文件中的内容
我们先来创建一个普通文件,然后立即尝试删除(这个操作肯定会成功):

接下来再次新建一个普通文件,并为其设置“不允许删除与覆盖”(
+a
参数)权限,然后再尝试将这个文件删除:

2.lsattr命令
lsattr
命令用于查看文件的隐藏权限,英文全称为“
list attributes
”,语法格式为“
lsattr [参数
]
文件名称”。
在
Linux
系统中,文件的隐藏权限必须使用
lsattr
命令来查看,平时使用的
ls 之类的命令则看不出端倪:

此时按照显示的隐藏权限的类型(字母),使用
chattr
命令将其去掉:

查看目录

我们一般会将
-a
参数设置到日志文件(/var/log/messages)上,这样可在不影响系统正常写入日志的前提下,防止黑客擦除自己的作案证据。如果希望彻底地保护某个文件,不允许任何人修改和删除它的话,不妨加上
-i
参数试试,效果特别好。
5.文件访问控制列表
不知道大家是否发现,前文讲解的一般权限、特殊权限、隐藏权限其实有一个共性—权限是针对某一类用户设置的,能够对很多人同时生效。如果希望对某个指定的用户进行单独的权限控制,就需要用到文件的访问控制列表(
ACL)了。通俗来讲,基于普通文件或目录设置 ACL 其实就是针对指定的用户或用户组设置文件或目录的操作权限,更加精准地派发权限。另外,如果针对某个目录设置了 ACL,则目录中的文件会继承其 ACL 权限;若针对文件设置了 ACL,则文件不再继承其所在目录的 ACL 权限
在没有针对普通用户为
root
管理员的家目录设置
ACL 之前,其执行结果如下所示:

1.setfacl命令
setfacl
命令用于管理文件的
ACL
权限规则,英文全称为“
set files ACL”,语法格式为“
setfacl [
参数
] 文件名称”。ACL 权限提供的是在所有、所属组、其他人的读/写/执行权限之外的特殊权限控制。
使用
setfacl
命令可以针对单一用户或用户组、单一文件或目录来进行读
/
写
/执行权限的控制。其中,针对目录文件需要使用
-R
递归参数;针对普通文件则使用
-m 参数;如果想要删除某个文件的
ACL
,则可以使用
-b
参数。
setfacl
命令中的参数以及作用
-m 修改权限
-M 从文件中读取权限
-x 删除某个权限
-b 删除全部权限
-R 递归子目录
例如,我们原本是无法进入
/root
目录中的,现在为普通用户单独设置一下权限:
随后再切换到这位普通用户的身份下,现在能正常进入了:

常用的
ls
命令是看不到
ACL 信息的,但是却可以看到文件权限的最后一个点( . )变成了加号(+ ),这就意味着该文件已经设置了
ACL
。
2.getfacl命令
getfacl
命令用于查看文件的
ACL
权限规则,英文全称为“
get files ACL”,语法格式为“
getfacl [
参数
]
文件名称”。
想要设置
ACL
,用的是
setfacl 命令;要想查看
ACL
,则用的是
getfacl
命令。下面使用
getfacl
命令显示在
root 管理员家目录上设置的所有
ACL
信息:
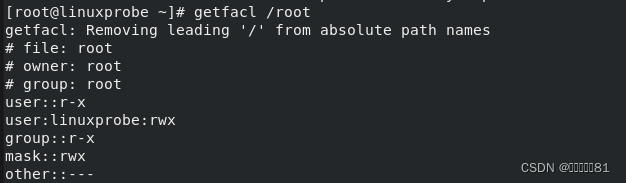
ACL
权限还可以针对某个用户组进行设置。例如,允许某个组的用户都可以读写/etc/fstab文件:

要清空所有
ACL
权限,请用
-b 参数;要删除某一条指定的权限,就用
-x
参数:
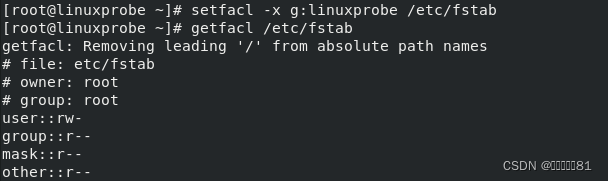
ACL 权限的设置都是立即且永久生效的,不需要再编辑什么配置文件,这一点特别方便。但是,这也带来了一个安全隐患。如果我们不小心设置错了权限,就会覆盖掉文件原始的权限信息,并且永远都找不回来了。
例如,在备份
/home
目录上的
ACL
权限时,可使用
-R 递归参数,这样不仅能够把目录本身的权限进行备份,还能将里面的文件权限也自动备份。另外,再加上第
3 章学习过的输出重定向操作,可以轻松实现权限的备份。需要注意,
getfacl 在备份目录权限时不能使用绝对路径的形式,因此我们需要先切换到最上层根目录,然后再进行操作。

ACL
权限的恢复也很简单,使用的是
--restore
参数。由于在备份时已经指定是对/home目录进行操作,所以不需要写对应的目录名称,它能够自动找到要恢复的对象:
6.su命令与sudo服务
su 命令可以解决切换用户身份的需求,使得当前用户在不退出登录的情况下,顺畅地切换到其他用户,比如从
root
管理员切换至普通用户:

的 su 命令与用户名之间有一个减号(-),这意味着完全切换到新的用户,即把环境变量信息也变更为新用户的相应信息,而不是保留原始的信息。强烈建议在切换用户身份时添加这个减号(-
)
另外,当从
root
管理员切换到普通用户时是不需要密码验证的,而从普通用户切换成 root管理员就需要进行密码验证了;这也是一个必要的安全检查:

尽管像上面这样使用
su
命令后,普通用户可以完全切换到
root 管理员的身份来完成相应工作,但这将暴露
root
管理员的密码,从而增大了系统密码被黑客获取的概率;这并不是最安全的方案。
接下来将介绍如何使用
sudo 命令把特定命令的执行权限赋予指定用户,这样既可保证普通用户能够完成特定的工作,也可以避免泄露
root 管理员密码。我们要做的就是合理配置
sudo
服务,以便兼顾系统的安全性和用户的便捷性。
sudo
命令用于给普通用户提供额外的权限,语法格式为“
sudo [
参数
]
用户名”。
使用
sudo
命令可以给普通用户提供额外的权限来完成原本只有 root管理员才能完成的任务,可以限制用户执行指定的命令,记录用户执行过的每一条命令,集中管理用户与权限(
/etc/sudoers),以及可以在验证密码后的一段时间无须让用户再次验证密码。
sudo
命令中的可用参数以及作用
-h 列出帮助信息
-l 列出当前用户可执行的命令
-u
用户名或
UID 值 以指定的用户身份执行命令
-k 清空密码的有效时间,下次执行
sudo
时需要再次进行密码验证
-b 在后台执行指定的命令
-p 更改询问密码的提示语
如果担心直接修改配置文件会出现问题,则可以使用
sudo
命令提供的
visudo 命令来配置用户权限
visudo
命令用于编辑、配置用户
sudo
的权限文件,语法格式为“
visudo [
参数
]
”。
这是一条会自动调用
vi
编辑器来配置
/etc/sudoers 权限文件的命令,能够解决多个用户同时修改权限而导致的冲突问题。不仅如此,
visudo 命令还可以对配置文件内的参数进行语法检查,并在发现参数错误时进行报错提醒。这要比用户直接修改文件更友好、安全、方便
使用
visudo
命令配置权限文件时,其操作方法与
Vim 编辑器中用到的方法完全一致,因此在编写完成后记得在末行模式下保存并退出。在配置权限文件时,按照下面的格式在第 101行(大约)填写上指定的信息。
谁可以使用 允许使用的主机 = (以谁的身份)可执行命令的列表
谁可以使用:
稍后要为哪位用户进行命令授权。
允许使用的主机:可以填写 ALL 表示不限制来源的主机,亦可填写如 192.168.10.0/24这样的网段限制来源地址,使得只有从允许网段登录时才能使用 sudo 命令。
以谁的身份:
可以填写
ALL
表示系统最高权限,也可以是另外一位用户的名字。
可执行命令的列表:可以填写 ALL 表示不限制命令,亦可填写如/usr/bin/cat 这样的文件名称来限制命令列表,多个命令文件之间用逗号(,)间隔。
在 Linux 系统中配置服务文件时,虽然没有硬性规定,但从经验来讲新增参数的位置不建议太靠上,以免我们新填写的参数在执行时失败,导致一些必要的服务功能没有成功加载。一般建议在配置文件中找一下相似的参数,然后在相邻位置进行新的修改,或者在文件的中下部位置进行添加后修改。

写完毕后记得要先保存再退出,然后切换至指定的普通用户身份,此时就可以用 sudo -l
命令查看所有可执行的命令了(在下面的命令中,验证的是普通用户的密码,而不是 root管理员的密码,请读者不要搞混了):

!作为一名普通用户,是肯定不能看到
root 管理员的家目录(
/root
)中的文件信息的,但是,只需要在想执行的命令前面加上
sudo
命令就行了:

是考虑到生产环境中不允许某个普通用户拥有整个系统中所有命令的最高执行权(这也不符合前文提到的权限赋予原则,即尽可能少地赋予权限),ALL 参数就有些不合适了。因此只能赋予普通用户具体的命令以满足工作需求,这也受到了必要的权限约束。如果需要让某个用户只能使用
root 管理员的身份执行指定的命令,切记一定要给出该命令的绝对路径,否则系统会识别不出来。这时,可以先使用
whereis
命令找出命令所对应的保存路径:

然后使用
visudo
命令继续编辑权限文件,将原先第 101 行所新增的参数作如下修改,且多个命令之间用逗号(,
)间隔:

在编辑好后依然是先保存再退出。再次切换到指定的普通用户,然后尝试正常查看某个系统文件的内容,此时系统提示没有权限(
Permission denied
)。这时再使用
sudo 命令就能顺利地查看文件内容了:

在每次执行
sudo 命令后都会要求验证一下密码。虽然这个密码就是当前登录用户的密码,但是每次执行
sudo
命令都要输入一次密码其实也挺麻烦的,这时可以添加
NOPASSWD 参数,使得用户下次再执行
sudo
命令时就不用密码验证

这样,当切换到普通用户后再执行命令时,就不用再频繁地验证密码了,我们在日常工作中也就痛快至极了。

visudo
命令只有
root 管理员才可以执行,普通用户在使用时会提示权限不足。















 603
603











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









