






一、引言
自然语言处理(Natural Language Processing, NLP)是人工智能领域的一个重要分支,涉及使计算机能够理解、解释和生成人类语言的能力。它结合了计算机科学、人工智能、语言学和信息工程等多个学科的知识,旨在使计算机能够处理和理解人类语言的各种形式。
在自然语言处理领域中,姓氏分类是一个经典且实用的问题。通过姓氏分类,我们可以根据其语言特征将姓氏归类到不同的文化或地理群体中。本文将探讨如何利用前馈神经网络(Feedforward Neural Networks, FNN)来解决这一问题,以及其在实际应用中的意义和挑战。
二、多层感知机
2.1多层感知机简介
多层感知机(Multilayer Perceptron,简称MLP),是一种基于前馈神经网络(Feedforward Neural Network)的深度学习模型,由多个神经元层组成,其中每个神经元层与前一层全连接。多层感知机可以用于解决分类、回归和聚类等各种机器学习问题。
多层感知机的每个神经元层由许多神经元组成,其中输入层接收输入特征,输出层给出最终的预测结果,中间的隐藏层用于提取特征和进行非线性变换。每个神经元接收前一层的输出,进行加权和和激活函数运算,得到当前层的输出。通过不断迭代训练,多层感知机可以自动学习到输入特征之间的复杂关系,并对新的数据进行预测。
2.2示例图
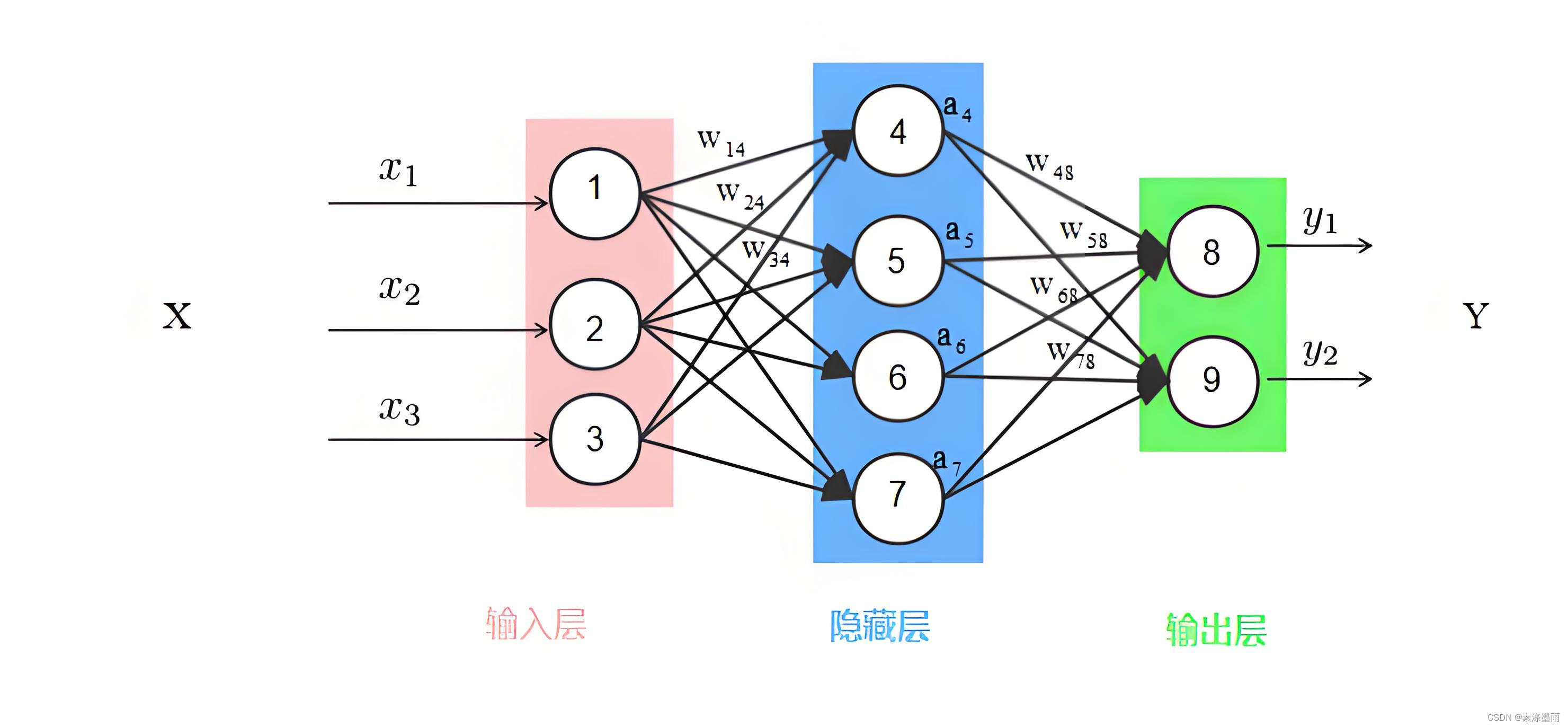
以上是一个比较简单的多层感觉及模型,它由输入层、隐藏层、输出层构成。
2.3代码示例
下面是由PyTorch实现多层感知机的代码示例
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
# 定义一个简单的MLP类
class MLP(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size) # 第一层隐藏层
self.relu = nn.ReLU() # 激活函数
self.fc2 = nn.Linear(hidden_size, output_size) # 输出层
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
# 使用MLP的示例
if __name__ == '__main__':
# 示例数据:随机输入和输出
np.random.seed(0)
input_data = np.random.rand(100, 10) # 100个样本,10个特征
output_data = np.random.randint(0, 2, size=100) # 二分类
# 将数据转换为PyTorch张量
inputs = torch.FloatTensor(input_data)
targets = torch.LongTensor(output_data)
# 定义超参数
input_size = input_data.shape[1]
hidden_size = 50
output_size = 2 # 二分类,所以输出大小为2
# 初始化MLP
model = MLP(input_size, hidden_size, output_size)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练循环
num_epochs = 100
for epoch in range(num_epochs):
# 前向传播上述代码定义了一个简单的MLP,包括一个隐藏层(hidden_size个神经元)和一个输出层(output_size个神经元)。
nn.Linear定义了全连接层。
nn.ReLU()用作第一个线性层后的激活函数。
前向传播方法:前向传播方法定义了网络的前向传播过程。它接受输入x,应用线性变换(fc1),应用ReLU激活,然后应用另一个线性变换(fc2)以生成输出。
在训练后,展示了如何使用训练好的模型对新数据(test_input)进行预测。
使用torch.max获取预测类别。
这个示例提供了如何使用PyTorch实现基本MLP进行分类任务的基础理解。可以根据特定要求和数据集调整模型架构、超参数和数据处理。
2.4XOR问题测试实例

以下是一个关于MLP解决上图XOR问题的测试实例
# 设置批量大小为2,表示一次输入的样本数量为2
batch_size = 2
# 设置输入维度为3,表示每个输入样本的特征数为3
input_dim = 3
# 设置隐藏层维度为100,表示隐藏层神经元的数量为100
hidden_dim = 100
# 设置输出维度为4,表示模型输出的结果数量为4
output_dim = 4
# 初始化多层感知机模型,输入维度为input_dim,隐藏层维度为hidden_dim,输出维度为output_dim
mlp = MultilayerPerceptron(input_dim, hidden_dim, output_dim)
# 打印多层感知机模型的信息
print(mlp)
print("Predicted class:", predicted_class.item())在这个例子中,MLP模型的输出是一个有两行四列的张量。这个张量中的行与批处理维数对应,批处理维数是小批处理中的数据点的数量。列是每个数据点的最终特征向量。在某些情况下,例如在分类设置中,特征向量是一个预测向量。名称为“预测向量”表示它对应于一个概率分布。预测向量会发生什么取决于我们当前是在进行训练还是在执行推理。在训练期间,输出按原样使用,带有一个损失函数和目标类标签的表示。
XOR问题是一个经典的非线性可分问题,MLP通过在隐藏层引入非线性激活函数(ReLU),使得模型能够学习到XOR操作所需的复杂特征映射。在训练完成后,模型能够准确地对新的输入进行分类,输出它们的异或结果。
三、卷积神经网络
3.1卷积神经网络简介
卷积神经网络(Convolutional Neural Network,CNN)是一种专门用于处理具有网格结构数据的深度学习神经网络。它的核心特征包括卷积层(Convolutional Layer)、池化层(Pooling Layer)和全连接层(Fully Connected Layer)。在卷积层中,网络通过一系列的滤波器(或称卷积核)在输入数据的局部区域上进行滑动操作,每个滤波器提取特定的特征,例如边缘、纹理等。通过这种局部感知的方式,CNN能够有效地捕捉图像中的空间结构信息。
3.2卷积核
卷积核(Convolutional Kernel)是卷积神经网络(CNN)中的重要组成部分,也称为滤波器(Filter)。它是一个小型的矩阵,用于在输入数据上进行卷积操作,从而提取特定的特征信息。
卷积核的大小通常是正方形,例如3x3、5x5等,其大小决定了每次卷积操作关注的局部区域大小。在卷积操作中,卷积核在输入数据的局部区域上进行滑动操作,并通过与输入数据对应位置的元素相乘再求和的方式,得到卷积输出。
卷积核的参数是需要学习的,在CNN的训练过程中通过反向传播算法更新参数,使得网络能够学习到不同特征所对应的卷积核。这样,不同的卷积核可以捕捉输入数据中不同层次的特征信息,例如边缘、纹理、形状等。
通过堆叠多个卷积核,CNN能够提取更加丰富和复杂的特征,从低级到高级逐渐抽象的特征表示,这是CNN在图像处理和其他领域取得优异性能的重要原因之一。
上图展示的是将核大小为3的卷积用于输入矩阵。结果是一个折中的结果,在每次将内核应用于矩阵时都会使用更多的局部信息,但输出的大小会更小。
3.3卷积步长
卷积步长(Convolutional Stride)是卷积神经网络中一个重要的概念,用于控制卷积核在输入数据上滑动的步长大小。具体来说,步长决定了每次卷积核在输入数据上移动的像素数目。
在常见的卷积操作中,卷积核通常以一定的步长在输入数据的宽度和高度方向上进行滑动。例如,若卷积核的步长设置为1,则卷积核每次在输入数据上移动一个像素;若步长设置为2,则每次移动两个像素,依此类推。
通过调整卷积核的步长,可以改变输出特征图的尺寸。一般情况下,较大的步长会导致输出特征图的空间尺寸减小,因为卷积核在输入上的滑动次数减少,而较小的步长则会产生更大的输出特征图。
在实际应用中,步长的选择需要考虑多个因素,如输入数据的尺寸、希望获得的输出特征图的尺寸以及计算效率等。通过调整步长,可以在保持有效感受野的同时,控制网络的计算负载和输出特征的空间分辨率。
Stride控制卷积之间的步长。如果步长与核相同,则内核计算不会重叠。另一方面,如果跨度为1,则内核重叠最大。输出张量可以通过增加步幅的方式被有意的压缩来总结信息。
3.4边界填充
边界填充(Padding)是卷积神经网络中的一个技术,用于在输入数据的边缘周围添加额外的像素值,以控制卷积操作后输出特征图的大小。
在卷积操作中,卷积核通常会在输入数据的每个位置进行滑动计算。当卷积核在接近输入数据边缘时,如果没有填充,这些边缘像素的信息可能不足以完整地参与卷积运算,从而导致输出特征图尺寸的缩小。为了解决这个问题,可以在输入数据周围添加额外的像素(通常是0值),即进行填充操作。
3.5膨胀
膨胀(Dilation)是一种用于增加感受野(Receptive Field)的技术。通常,卷积操作会使用卷积核在输入数据上进行局部滑动,每次滑动的步长由卷积步长决定,这样可以获得局部区域的特征信息。然而,有时候需要获得更大范围的上下文信息,这时就可以使用膨胀技术。
膨胀卷积与普通卷积的区别在于,膨胀卷积中卷积核内部的元素不再是连续的,而是通过在元素之间插入固定数量的零来实现间隔,这个间隔称为膨胀率(Dilation Rate)。膨胀率决定了卷积核内元素之间的距离,从而扩大了卷积核的感受野。
 3.6代码实现
3.6代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class SimpleCNN(nn.Module):
def __init__(self):
super(SimpleCNN, self).__init__()
# 定义卷积层和池化层
self.conv1 = nn.Conv2d(in_channels=3, out_channels=16, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
# 定义全连接层
self.fc1 = nn.Linear(32 * 56 * 56, 512) # 假设输入图像大小为224x224
self.fc2 = nn.Linear(512, 10) # 假设输出类别数为10
def forward(self, x):
# 前向传播过程
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
x = x.view(-1, 32 * 56 * 56) # 将特征张量展平
x = F.relu(self.fc1(x))
x = self.fc2(x)
return x
# 创建一个网络实例
net = SimpleCNN()
# 在此处可以添加数据加载和训练代码,使用net进行训练和评估这个示例中,SimpleCNN类定义了一个简单的卷积神经网络结构,包括两个卷积层(每层后接ReLU激活函数和最大池化层),以及两个全连接层用于分类。在forward方法中,定义了数据从输入到输出的传播路径。
四、姓氏分类问题
4.1姓氏数据集简介
姓氏数据集(SurnameDataset)是一个用于研究人类姓氏的起源、分布和特征的数据集。它收集了来自18个不同国家的10,000个姓氏,包含了不同姓氏的频率、来源地区、历史背景等信息,有助于研究者了解姓氏在不同文化和地理背景下的变化和演变。
4.2载入数据集
class SurnameDataset(Dataset):
# ... existing implementation from Section 4.2
def __getitem__(self, index):
# 获取指定索引的行数据
row = self._target_df.iloc[index]
# 将姓氏转换为向量矩阵,长度为_max_seq_length
surname_matrix = \n self._vectorizer.vectorize(row.surname, self._max_seq_length)
# 查找国籍对应的索引值
nationality_index = \n self._vectorizer.nationality_vocab.lookup_token(row.nationality)
# 返回包含姓氏向量矩阵和国籍索引的字典
return {'x_surname': surname_matrix,
'y_nationality': nationality_index}4.3实现姓氏矢量器
class SurnameVectorizer(object):
"""协调词汇表并将其用于向量化的向量器"""
def vectorize(self, surname):
"""
将姓氏转换为独热矩阵表示
Args:
surname (str): 姓氏字符串
Returns:
one_hot_matrix (np.ndarray): 一个独热向量矩阵
"""
one_hot_matrix_size = (len(self.character_vocab), self.max_surname_length)
one_hot_matrix = np.zeros(one_hot_matrix_size, dtype=np.float32)
for position_index, character in enumerate(surname):
character_index = self.character_vocab.lookup_token(character)
one_hot_matrix[character_index][position_index] = 1
return one_hot_matrix
@classmethod
def from_dataframe(cls, surname_df):
"""从数据集中实例化向量器
Args:
surname_df (pandas.DataFrame): 姓氏数据集
Returns:
an instance of the SurnameVectorizer
"""
character_vocab = Vocabulary(unk_token="@") # 初始化字符词汇表,使用@作为未知字符标记
nationality_vocab = Vocabulary(add_unk=False) # 初始化国籍词汇表,不添加未知标记
max_surname_length = 0 # 初始化最大姓氏长度为0
# 遍历数据集中的每一行
for index, row in surname_df.iterrows():
max_surname_length = max(max_surname_length, len(row.surname)) # 更新最大姓氏长度
# 遍历每个姓氏中的每个字符
for letter in row.surname:
character_vocab.add_token(letter) # 将字符添加到字符词汇表中
nationality_vocab.add_token(row.nationality) # 将国籍添加到国籍词汇表中
return cls(character_vocab, nationality_vocab, max_surname_length)上述代码展示了一个用于处理姓氏数据的向量化器。它通过独热编码将姓氏字符串转换为可用于机器学习模型的输入格式。通过从数据集中构建词汇表并计算最大姓氏长度,它能够有效地准备输入数据。
4.4模型构建
import torch.nn as nn
import torch.nn.functional as F
class SurnameClassifier(nn.Module):
def __init__(self, initial_num_channels, num_classes, num_channels):
"""
初始化函数,定义网络结构
Args:
initial_num_channels (int): 输入特征向量的大小
num_classes (int): 输出预测向量的大小
num_channels (int): 在整个网络中要使用的常量通道大小
"""
super(SurnameClassifier, self).__init__()
# 定义卷积神经网络层
self.convnet = nn.Sequential(
nn.Conv1d(in_channels=initial_num_channels,
out_channels=num_channels, kernel_size=3),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3, stride=2),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3, stride=2),
nn.ELU(),
nn.Conv1d(in_channels=num_channels, out_channels=num_channels,
kernel_size=3),
nn.ELU()
)
# 定义全连接层
self.fc = nn.Linear(num_channels, num_classes)
def forward(self, x_surname, apply_softmax=False):
"""分类器的前向传播过程
Args:
x_surname (torch.Tensor): 输入数据张量。
x_surname.shape应该是(batch, initial_num_channels, max_surname_length)
apply_softmax (bool): softmax激活的标记
如果与交叉熵损失一起使用,应为false
Returns:
返回结果张量。tensor.shape应该是(batch, num_classes)
"""
# 通过卷积神经网络提取特征
features = self.convnet(x_surname).squeeze(dim=2)
# 通过全连接层得到预测向量
prediction_vector = self.fc(features)
# 如果需要应用softmax激活函数
if apply_softmax:
prediction_vector = F.softmax(prediction_vector, dim=1)
return prediction_vector代码构建了一个模型,这个模型适用于将输入的姓氏序列转换为预测该姓氏所属类别的概率分布。卷积神经网络部分负责从姓氏的字符级表示中提取特征,全连接层则将这些特征映射到类别空间。整体结构简洁明了,适用于处理文本分类任务,特别是在姓氏分类的情境下。
4.5配置训练
args = Namespace(
# 数据路径信息
surname_csv="data/surnames/surnames_with_splits.csv", # 姓氏数据文件路径
vectorizer_file="vectorizer.json", # 向量化器文件路径
model_state_file="model.pth", # 模型状态文件路径
save_dir="model_storage/ch4/cnn", # 保存模型的目录
# 模型超参数
hidden_dim=100, # 隐藏层维度
num_channels=256, # 通道数量
# 训练超参数
seed=1337, # 随机数种子
learning_rate=0.001, # 学习率
batch_size=128, # 批量大小
num_epochs=100, # 训练轮数
early_stopping_criteria=5, # 早停标准
dropout_p=0.1, # Dropout概率
)上述代码提供了一个名为 `args` 的命名空间,其中包含了一些重要的超参数和文件路径信息,用于配置和训练神经网络模型。包括 数据路径信息、模型超参数以及训练超参数。这些超参数和路径信息为训练和保存深度学习模型提供了必要的配置。在实际应用中,可以根据具体任务和数据集的特点进行调整和优化。
4.6模型改进
我们对`predict_nationality()`函数的一部分发生了更改,如下列代码所示,我们没有使用视图方法重塑新创建的数据张量以添加批处理维度,而是使用PyTorch的`unsqueeze()`函数在批处理应该在的位置添加大小为1的维度。相同的更改反映在`predict_topk_nationality()`函数中。
def predict_nationality(surname, classifier, vectorizer):
"""预测姓氏所属国籍
参数:
surname (str): 需要分类的姓氏
classifier (SurnameClassifer): 分类器的实例
vectorizer (SurnameVectorizer): 对应的向量化器
返回:
一个字典,包含最可能的国籍及其概率
"""
# 将姓氏向量化
vectorized_surname = vectorizer.vectorize(surname)
# 将向量转换为张量并增加一个维度
vectorized_surname = torch.tensor(vectorized_surname).unsqueeze(0)
# 使用分类器对向量进行分类,并应用softmax函数
result = classifier(vectorized_surname, apply_softmax=True)
# 获取最大概率值和对应的索引
probability_values, indices = result.max(dim=1)
index = indices.item()
# 根据索引查找对应的国籍
predicted_nationality = vectorizer.nationality_vocab.lookup_index(index)
# 获取最大概率值
probability_value = probability_values.item()
# 返回预测结果
return {'nationality': predicted_nationality, 'probability': probability_value}这个函数结合了模型预测和结果后处理的步骤,可以方便地用于给定姓氏的国籍预测。在实际应用中,需要确保 classifier 和 vectorizer 对象已经正确初始化和训练,并且国籍词汇表的设置与模型训练时一致,以保证预测的正确性和准确性。
五、实验总结
上述实验结果深刻展示了卷积神经网络(CNN)在处理基于字符的文本分类任务中的显著优势。CNN能够有效地捕捉姓氏中的空间和序列特征,这对于区分具有强烈文化标识的姓氏尤为重要。此外,研究还探讨了特征表示方法对模型性能的影响,强调了使用嵌入向量和Transformer架构等先进方法可能带来的进一步性能提升。
探讨:
1. 特征表示的进一步优化:
- 嵌入向量与Transformer架构:相比传统的one-hot编码,嵌入向量能够更好地表达单词之间的语义关系,有助于提升模型对于文本特征的理解能力。未来的研究可以探索使用预训练的词嵌入模型(如Word2Vec、GloVe或BERT)以及基于Transformer的预训练语言模型(如BERT、GPT等),进一步增强模型在姓氏分类任务中的表现。
2. 模型架构的进化:
- 集成学习与模型融合:结合多个CNN模型的预测结果或与递归神经网络(RNN)结合,可能会带来更好的性能。例如,可以使用CNN提取空间特征,再通过RNN捕捉序列信息,以进一步提高分类精度
3. 文本数据增强:
- 生成对抗网络(GAN):利用GAN生成具有文化特征的姓氏样本,以增加数据多样性,提升模型的泛化能力和鲁棒性。
4. 模型评估与解释性:
- 解释性机器学习方法:使用SHAP(SHapley Additive exPlanations)等工具来解释模型预测的决策过程,帮助理解模型在姓氏分类中的运作方式,并发现模型可能的偏差或误差来源。
5. 跨语言和跨文化的应用:
- 多语言数据集和模型迁移:扩展研究到不同语言和文化背景下的姓氏分类,验证模型的泛化能力和适用性。
六、致谢
感谢阅读博客的读者,并鼓励提问和讨论。















 1145
1145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









