






 文章介绍了使用Numpy实现简单的SRN模型,然后逐步引入PyTorch中的nn.RNNCell和nn.RNN,以及序列到序列模型和编码器-解码器结构的应用,展示了如何在这些框架下构建和训练循环神经网络。
文章介绍了使用Numpy实现简单的SRN模型,然后逐步引入PyTorch中的nn.RNNCell和nn.RNN,以及序列到序列模型和编码器-解码器结构的应用,展示了如何在这些框架下构建和训练循环神经网络。
1、实现SRN
(1)、使用Numpy
import numpy as np
inputs=np.array([[1,1],[1,1],[2,2]])
w1,w2,w3,w4,w5,w6,w7,w8=1,1,1,1,1,1,1,1
U1,U2,U3,U4=1,1,1,1
print("inputs is",inputs)
state_t=np.zeros(2,)
print("state_t is",state_t)
for input_t in inputs:
print("input_t is",input_t)
print("state_t is",state_t)
#全连接[tanh(输入*线性权重)]+延迟器+状态权重
h1=np.dot([w1,w3],input_t)+np.dot([U2,U4],state_t)
h2=np.dot([w2,w4],input_t)+np.dot([U1,U3],state_t)
#更新延迟器
state_t=(h1,h2)
#全连接
y1=np.dot([w5,w7],[h1,h2])
y2=np.dot([w6,w8],[h1,h2])
print("output_y is",y1,y2)其运行及结果:

(2)、在(1)的基础上增加激活函数tanh

import numpy as np
inputs=np.array([[1,1],[1,1],[2,2]])
w1,w2,w3,w4,w5,w6,w7,w8=1,1,1,1,1,1,1,1
U1,U2,U3,U4=1,1,1,1
print("inputs is",inputs)
state_t=np.zeros(2,)
print("state_t is",state_t)
for input_t in inputs:
print("input_t is",input_t)
print("state_t is",state_t)
#全连接[tanh(输入*线性权重)]+延迟器+状态权重
h1=np.tanh(np.dot([w1,w3],input_t))+np.dot([U2,U4],state_t)
h2=np.tanh(np.dot([w2,w4],input_t))+np.dot([U1,U3],state_t)
#更新延迟器
state_t=(h1,h2)
#全连接
y1=np.dot([w5,w7],[h1,h2])
y2=np.dot([w6,w8],[h1,h2])
print("output_y is",y1,y2)
print("------------")其运行结果为:

(3)、使用nn.RNNCell实现

import torch
batch_size=1#单次传递给程序用以训练的数据(样本)个数
input_size=2#输入层维度
seq_len=3#序列长度
hidden_size=2#隐藏层维度
output_size=2#输出层维度
#RNNCell
cell=torch.nn.RNNCell(input_size=input_size,hidden_size=hidden_size)
for name,params in cell.named_parameters():
if name.startswith("weight"):
torch.nn.init.ones_(params)
else:
torch.nn.init.zeros_(params)
#线形层
linear=torch.nn.Linear(hidden_size,output_size)
linear.weight.data=torch.tensor([[1.,1.],[1.,1.]])
linear.bias.data=torch.tensor([0.,0.])
#输入
seq=torch.tensor([[[1.,1.]],
[[1.,1.]],
[[2.,2.]]])
#隐藏层初始设置为0
hidden=torch.zeros(batch_size,hidden_size)
output=torch.zeros(batch_size,output_size)
#输出
for id,input_t in enumerate(seq):
print("--------",id,"---------")
print('input is:',input_t)
print("hidden is:",hidden)
#求解循环网络单元
hidden=cell(input_t,hidden)
#全连接
output=linear(hidden)
print("output is:",output)其运行结果为:

(4)、使用nn.RNN实现
import torch
# 定义参数
batch_size = 1
seq_len = 3
input_size = 2
hidden_size = 2
num_layers = 1
output_size = 2
# 创建RNN模型
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers)
# 初始化参数
for name, param in cell.named_parameters():
if name.startswith("weight"):
torch.nn.init.ones_(param)
else:
torch.nn.init.zeros_(param)
# 创建线性层
liner = torch.nn.Linear(hidden_size, output_size)
liner.weight.data = torch.Tensor([[1., 1.], [1., 1.]])
liner.bias.data = torch.Tensor([0.,0.])
# 创建输入张量和隐藏张量
inputs = torch.Tensor([[[1., 1.]], [[1., 1.]], [[2., 2.]]])
hidden = torch.zeros(num_layers, batch_size, hidden_size)
# 运行RNN模型
out, hidden = cell(inputs, hidden)
# 打印结果
print('Input :', inputs[0])
print('hidden:', 0, 0)
print('Output:', liner(out[0]))
print('--------------------------------------')
print('Input :', inputs[1])
print('hidden:', out[0])
print('Output:', liner(out[1]))
print('--------------------------------------')
print('Input :', inputs[2])
print('hidden:', out[1])
print('Output:', liner(out[2]))
其运行结果:

2. 实现“序列到序列”
观看视频,学习RNN原理,并实现视频P12中的教学案例

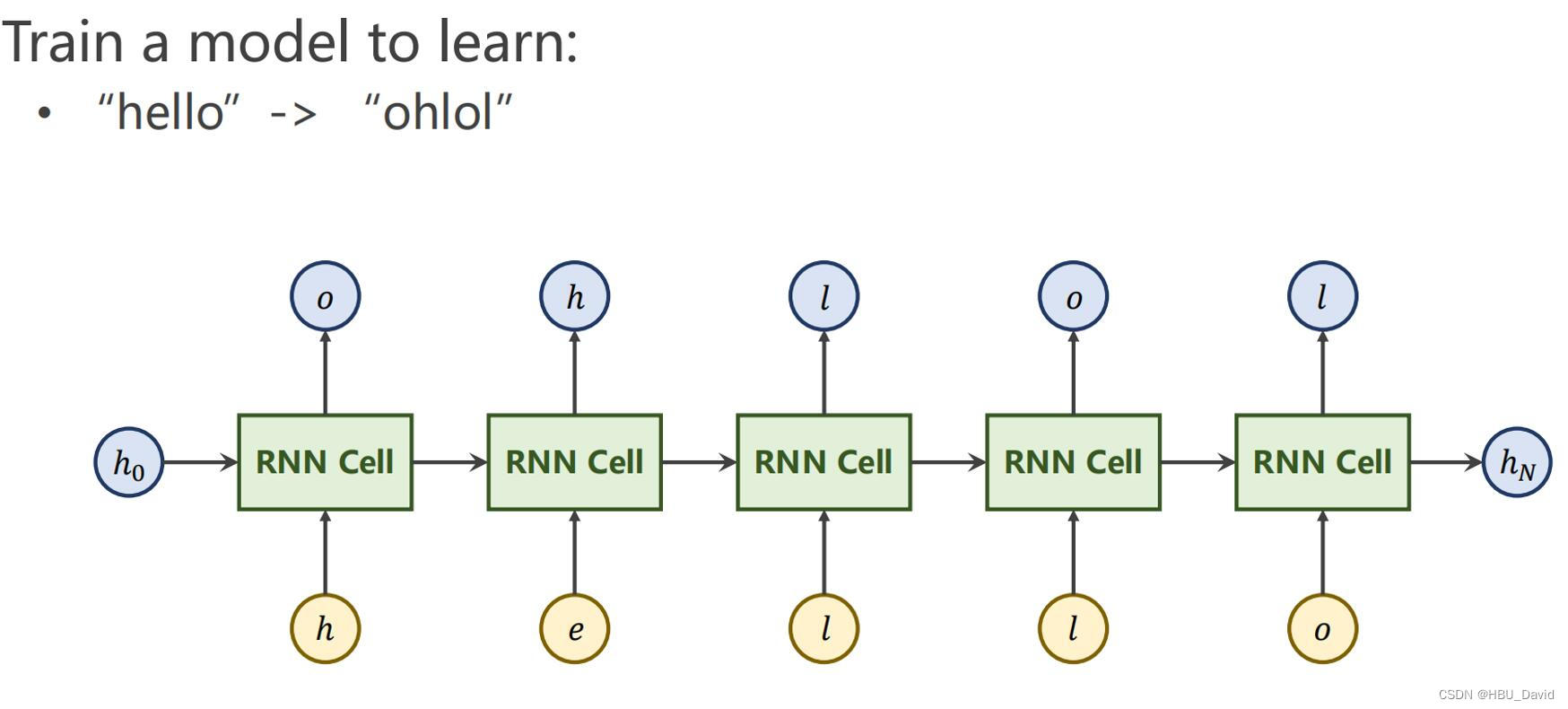

案例实现:
import torch
# 定义参数
batch_size = 1
seq_len = 3
input_size = 2
hidden_size = 2
num_layers = 1
output_size = 2
# 创建RNN模型
cell = torch.nn.RNN(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers,batch_first=True)
inputs=torch.randn(batch_size,seq_len,input_size)
hidden=torch.zeros(num_layers,batch_size,hidden_size)
out,hidden=cell(inputs,hidden)
print("Output size:",out.shape)
print("Output:",out)
print("Hidden size:",hidden.shape)
print("Hidden:",hidden)结果:

实现序列到序列
import torch
input_size = 4
hidden_size = 4
batch_size = 1
index2char = ['e', 'h', 'l', 'o']
x_data = [1, 0, 2, 2, 3]
y_data = [3, 1, 2, 3, 2]
one_hot_lookup = [[1, 0, 0, 0],[0, 1, 0, 0],[0, 0, 1, 0],[0, 0, 0, 1]]
x_one_hot = [one_hot_lookup[x] for x in x_data] # 转化为独热向量,维度(seq, batch, input)
dataset = torch.Tensor(x_one_hot).view(-1, batch_size,input_size)
labels = torch.LongTensor(y_data).view(-1, 1)
class Model(torch.nn.Module):
def __init__(self, input_size, hidden_size, batch_size):
super(Model, self).__init__()
self.batch_size = batch_size
self.input_size = input_size
self.hidden_size = hidden_size
self.rnncell = torch.nn.RNNCell(input_size=self.input_size, hidden_size=hidden_size)
def forward(self, input, hidden):
hidden = self.rnncell(input, hidden)
return hidden
def init_hidden(self):
return torch.zeros(self.batch_size, self.hidden_size)
net = Model(input_size, hidden_size, batch_size)
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=0.1)
for epoch in range(15):
loss = 0
optimizer.zero_grad()
hidden = net.init_hidden() # 初始化h0
print('Predicted string:', end='')
for input, label in zip(dataset, labels):
hidden = net(input, hidden)
loss += criterion(hidden, label) # loss是第一层的一个损失,需要相加求所有的loss
_, idx = hidden.max(dim=1) # 取出概率最大的索引
print(index2char[idx.item()], end='')
loss.backward()
optimizer.step()
print(',Epoch [%d / 15] loss:%.4f' % (epoch + 1, loss.item()))结果:

3. “编码器-解码器”的简单实现

import torch
import numpy as np
import torch.nn as nn
import torch.utils.data as Data
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# S: Symbol that shows starting of decoding input
# E: Symbol that shows starting of decoding output
# ?: Symbol that will fill in blank sequence if current batch data size is short than n_step
letter = [c for c in 'SE?abcdefghijklmnopqrstuvwxyz']
letter2idx = {n: i for i, n in enumerate(letter)}
seq_data = [['man', 'women'], ['black', 'white'], ['king', 'queen'], ['girl', 'boy'], ['up', 'down'], ['high', 'low']]
# Seq2Seq Parameter
n_step = max([max(len(i), len(j)) for i, j in seq_data]) # max_len(=5)
n_hidden = 128
n_class = len(letter2idx) # classfication problem
batch_size = 3
def make_data(seq_data):
enc_input_all, dec_input_all, dec_output_all = [], [], []
for seq in seq_data:
for i in range(2):
seq[i] = seq[i] + '?' * (n_step - len(seq[i])) # 'man??', 'women'
enc_input = [letter2idx[n] for n in (seq[0] + 'E')] # ['m', 'a', 'n', '?', '?', 'E']
dec_input = [letter2idx[n] for n in ('S' + seq[1])] # ['S', 'w', 'o', 'm', 'e', 'n']
dec_output = [letter2idx[n] for n in (seq[1] + 'E')] # ['w', 'o', 'm', 'e', 'n', 'E']
enc_input_all.append(np.eye(n_class)[enc_input])
dec_input_all.append(np.eye(n_class)[dec_input])
dec_output_all.append(dec_output) # not one-hot
# make tensor
return torch.Tensor(enc_input_all), torch.Tensor(dec_input_all), torch.LongTensor(dec_output_all)
'''
enc_input_all: [6, n_step+1 (because of 'E'), n_class]
dec_input_all: [6, n_step+1 (because of 'S'), n_class]
dec_output_all: [6, n_step+1 (because of 'E')]
'''
enc_input_all, dec_input_all, dec_output_all = make_data(seq_data)
class TranslateDataSet(Data.Dataset):
def __init__(self, enc_input_all, dec_input_all, dec_output_all):
self.enc_input_all = enc_input_all
self.dec_input_all = dec_input_all
self.dec_output_all = dec_output_all
def __len__(self): # return dataset size
return len(self.enc_input_all)
def __getitem__(self, idx):
return self.enc_input_all[idx], self.dec_input_all[idx], self.dec_output_all[idx]
loader = Data.DataLoader(TranslateDataSet(enc_input_all, dec_input_all, dec_output_all), batch_size, True)
# Model
class Seq2Seq(nn.Module):
def __init__(self):
super(Seq2Seq, self).__init__()
self.encoder = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5) # encoder
self.decoder = nn.RNN(input_size=n_class, hidden_size=n_hidden, dropout=0.5) # decoder
self.fc = nn.Linear(n_hidden, n_class)
def forward(self, enc_input, enc_hidden, dec_input):
# enc_input(=input_batch): [batch_size, n_step+1, n_class]
# dec_inpu(=output_batch): [batch_size, n_step+1, n_class]
enc_input = enc_input.transpose(0, 1) # enc_input: [n_step+1, batch_size, n_class]
dec_input = dec_input.transpose(0, 1) # dec_input: [n_step+1, batch_size, n_class]
# h_t : [num_layers(=1) * num_directions(=1), batch_size, n_hidden]
_, h_t = self.encoder(enc_input, enc_hidden)
# outputs : [n_step+1, batch_size, num_directions(=1) * n_hidden(=128)]
outputs, _ = self.decoder(dec_input, h_t)
model = self.fc(outputs) # model : [n_step+1, batch_size, n_class]
return model
model = Seq2Seq().to(device)
criterion = nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
for epoch in range(5000):
for enc_input_batch, dec_input_batch, dec_output_batch in loader:
# make hidden shape [num_layers * num_directions, batch_size, n_hidden]
h_0 = torch.zeros(1, batch_size, n_hidden).to(device)
(enc_input_batch, dec_intput_batch, dec_output_batch) = (
enc_input_batch.to(device), dec_input_batch.to(device), dec_output_batch.to(device))
# enc_input_batch : [batch_size, n_step+1, n_class]
# dec_intput_batch : [batch_size, n_step+1, n_class]
# dec_output_batch : [batch_size, n_step+1], not one-hot
pred = model(enc_input_batch, h_0, dec_intput_batch)
# pred : [n_step+1, batch_size, n_class]
pred = pred.transpose(0, 1) # [batch_size, n_step+1(=6), n_class]
loss = 0
for i in range(len(dec_output_batch)):
# pred[i] : [n_step+1, n_class]
# dec_output_batch[i] : [n_step+1]
loss += criterion(pred[i], dec_output_batch[i])
if (epoch + 1) % 1000 == 0:
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.6f}'.format(loss))
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Test
def translate(word):
enc_input, dec_input, _ = make_data([[word, '?' * n_step]])
enc_input, dec_input = enc_input.to(device), dec_input.to(device)
# make hidden shape [num_layers * num_directions, batch_size, n_hidden]
hidden = torch.zeros(1, 1, n_hidden).to(device)
output = model(enc_input, hidden, dec_input)
# output : [n_step+1, batch_size, n_class]
predict = output.data.max(2, keepdim=True)[1] # select n_class dimension
decoded = [letter[i] for i in predict]
translated = ''.join(decoded[:decoded.index('E')])
return translated.replace('?', '')
print('test')
print('man ->', translate('man'))
print('mans ->', translate('mans'))
print('king ->', translate('king'))
print('black ->', translate('black'))
print('up ->', translate('up'))结果:

4.简单总结nn.RNNCell、nn.RNN
nn.RNNCell会将序列上的每个时刻分开来处理,更加灵活,但计算比较麻烦,它是一个计算单元,不涉及层数的概念。
nn.RNN是循环神经网络层,RNN有了layers的概念,可以根据需要设置层数、隐藏状态的维度、激活函数等参数来构建不同规模和功能的RNN模型。
5.谈一谈对“序列”、“序列到序列”的理解
序列:是一系列具有连续关系的数据的高度抽象,序列数据大多有时序关系,每个数据点的意义往往依赖于其前面或后面的数据。
序列到序列:
循环神经网络可以用在同步的序列到序列和异步的序列到序列两种不同的模式。
同步的序列到序列模式主要用于序列标注任务,每一时刻都有输入和输出,并且输入序列和输出序列的长度相同。
异步的序列到序列模式,输入序列和输出序列不需要有严格的对应关系,也不需要保持相同的长度。















 968
968

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









