







本次实验将实现一棵具备完整功能且正常运行的B树,并用dot脚本语言实现B树的可视化,能够根据操作实时进行B树的结构变换。
参考教材:殷人昆老师版 数据结构
代码链接:BTree Visualize
数据结构:B树
此处仅做简介,详细请见教材。B树是一种常用的多路平衡搜索树(也称为多叉树),可以看作平衡二叉树的更为平常的版本,但是拥有m路的B树更加复杂。B树被广泛应用于数据库和文件系统等存储结构中,以支持高效的数据插入、删除和查找操作。B树的特点是每个节点可以存储多个关键码(即key值),并且节点之间的高度尽量保持一致,从根节点到每一个叶子节点的路径长度基本相等,且失败节点均在同一层上,保证了数据的均衡性和快速访问。

B树有如下特性:
- 每个节点最多有M个子节点(M>=2),即最多有M-1个关键码。通常情况下,M的值很大,可以存储大量的关键字,从而减少树的高度,提高数据访问效率;
- 根节点至少有两个子节点;
- 非根节点至少有ceil(M/2)个子节点,即至少有(M-1)/2个关键码;
- 所有叶子节点位于同一层,即它们具有相同的深度;
- B树的插入和删除操作都需要进行树的平衡调整,以保持B树的特性。
在插入操作中,如果插入后导致节点的关键字数超过了M-1个,需要进行节点的分裂,将一部分关键字移到一个新节点中,然后将新节点插入到父节点中。
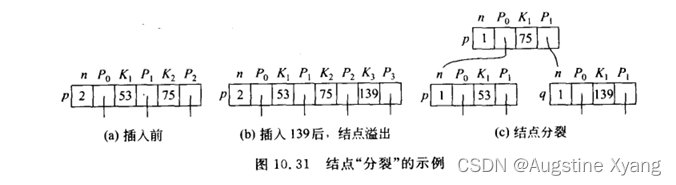
在删除操作中,如果删除导致节点的关键字数少于(M-1)/2个,需要进行节点的合并,将相邻的两个节点合并为一个节点,然后将父节点中的关键字删除。
B树的平衡调整过程比较复杂,但它保证了B树各路的高度平衡,从而保证了高效的数据访问速度。B树的应用广泛,特别是在数据库索引和文件系统中,它能够高效地支持大规模数据的存储和查询。
B树代码实现
查找
这是B树的基本功能,search方法会根据关键码在树中搜寻其位置,如果搜寻不到,则会返回该关键码的插入位置
struct ans
{
Bnode* r; //地址
int i; //关键码
bool tag; // 0成功,1失败
};
ans BTree::search(const int& x)
{
ans result;
Bnode* p = root, * q = NULL;//p为扫描指针,q为p的父结点指针
int i = 0;
while (p != NULL)
{
i = 0;
p->key[(p->num) + 1] = maxValue;
while (p->key[i + 1] < x)i++;
if (p->key[i + 1] == x)
{
result.r = p;
result.i = i + 1;
result.tag = 0;
return result;
}
q = p;
p = p->child[i]; //下移到相应子树
}
result.r = q;
result.i = i; //记录位置i
result.tag = 1;
return result;
}
插入
插入操作会先调用search方法,即可找到该关键码在树中应当插入的位置
bool BTree::insertKey(Bnode* p, const int& x, Bnode* rp) //用于在p节点中插入一项x
{
int i = p->num;
while (i > 0 && x < p->key[i])
{
p->key[i + 1] = p->key[i];//向后移位
p->child[i + 1] = p->child[i];
i--;
}
p->key[i + 1] = x; //插入x
p->child[i + 1] = rp;
p->num++;
return true;
}
bool BTree::insert(const int& x)
{
ans pos = search(x);
if (!pos.tag)
return false;//x已经存在
Bnode* p = pos.r; //p为要插入的地址
Bnode* q, * t, * rp = NULL;
int k = x;
int j = pos.i;
while (true)
{
if (p->num < m - 1) //关键码个数未超出
{
insertKey(p, k, rp);
return true;
}
int s = (m + 1) / 2; //溢出则分裂结点,s为中间项
insertKey(p, k, rp); //先插入x
q = new Bnode(m); //分裂结点,先建立新结点
move(p, q, s, m); //将p的key[s+1...m]和child[s...m]移动到q的key[1...m-s]和child[0...m-s],p.n变为s-1,q.n变为m-s
k = p->key[s]; //新要插入的结点,p中只剩下s-1个关键码,p中有m-s个关键码
p->key[s] = maxValue;
rp = q; //形成新的插入二元组(k,rp)
if (p->parent != NULL)
{
t = p->parent;
t->key[(t->num) + 1] = maxValue;
q->parent = p->parent;
p = t;
}
else
{
root = new Bnode(m);
root->num = 1;
root->parent = NULL;
root->key[1] = k;
root->child[0] = p;
root->child[1] = rp;
q->parent = p->parent = root;
return true;
}
}
}
当结点关键码超出限制时,会进行结点的分裂,此时用到了move()函数,用于将p的key[s+1…m]和child[s…m]移动到q的key[1…m-s]和child[0…m-s],p.n变为s-1,q.n变为m-s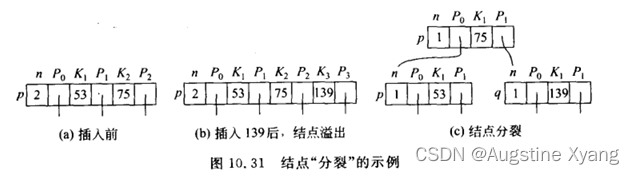
void BTree::move(Bnode* p, Bnode* q, int s, int m)//将p的key[s+1...m]和child[s...m]移动到q的key[1...m-s]和child[0...m-s],p.n变为s-1,q.n变为m-s
{
int i;
for (i = 1; i <= m - s; i++)
{
q->key[i] = p->key[i + s];
q->child[i - 1] = p->child[i + s - 1];
if (q->child[i - 1] != NULL)q->child[i - 1]->parent = q;
p->child[i + s - 1] = NULL;
}
q->child[m - s] = p->child[m];
if (q->child[m - s] != NULL)q->child[m - s]->parent = q;
p->child[m] = NULL;
p->num = s - 1;
q->num = m - s;
}
删除
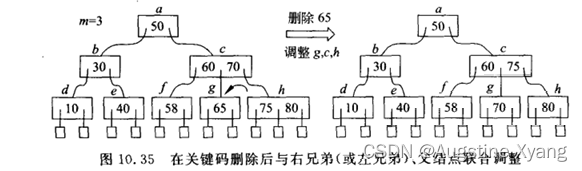
个人认为删除是B树中最为复杂的操作,会涉及结点关键码的左右调整等。
删除时,会先进行search找到想要删除的关键码的位置,如果位于非叶结点,那么先删去该关键码K,再将该结点的子树的最小关键码x来代替K的位置即可,这样可以做到保证B树的性质不变。紧接着,需要在x所在的叶结点中删去x。
综上,B树的删除操作都可以归结为在叶结点中删去关键码的操作,此时有4种情况:
-
该叶结点也是根节点,且关键码数num>=2 ,直接删去即可;

-
非根节点,并且关键码数>=ceil(M/2),也可直接删除
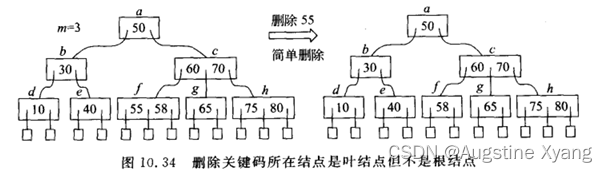
-
删除前关键码数=ceil(M/2)-1,且其(左/右)兄弟结点关键码数>=ceil(M/2),则联合父节点进行关键码的调整,从其兄弟结点中“偷取”关键码来满足B树的结构
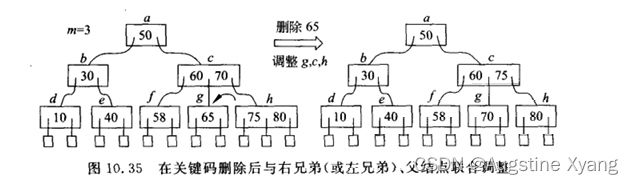
-
删除前关键码数=ceil(M/2)-1,且其(左/右)兄弟结点关键码数=ceil(M/2)-1,此时需要merge两个结点,形成一个新的结点
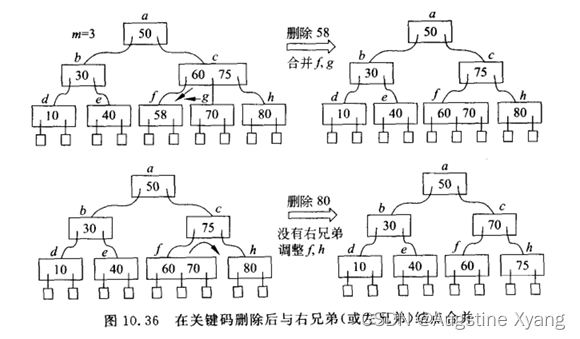
代码实现为:
bool BTree::remove(const int& x)
{
ans pos = search(x);
if (pos.tag == 1)return false;
Bnode* p = pos.r;
Bnode* q, * s;
int j = pos.i;
if (p->child[j] != NULL) //非叶节点
{
s = p->child[j];
q = p;
while (s != NULL) //寻找叶节点
{
q = s;
s = s->child[0];
}
p->key[j] = q->key[1]; //从叶节点找到替补
compress(q, 1); //删去叶结点中最小元
p = q; //转换为叶结点的删除
}
else compress(p, j);
int d = (m + 1) / 2;
while (true)
{
if (p->num < d - 1) //关键码数过少
{
j = 0;
q = p->parent; //开始从父节点中调整
while (j <= q->num && q->child[j] != p)
{
j++; //
}
if (j == q->num) //p是q的最后个子树,p与q与p的左兄弟进行调整
rightAdjust(p, q, d, j);
else //一般情况下,与q和p的右兄弟进行调整
leftAdjust(p, q, d, j);
p = q; //向上调整
if (p == root)break;
}
else
break; //关键码数量足够支持删除
}
if (root->num == 0) //调整后根为0
{
p = root->child[0];
delete root;
root = p;
root->parent = NULL;
}
return true;
}
其中compress用于删去某结点中第i个关键码:
void BTree::compress(Bnode* p, int pos)
{
for (int i = pos; i < p->num; i++)
{
p->key[i] = p->key[i + 1];
p->child[i] = p->child[i + 1];
}
p->key[p->num] = maxValue;
p->child[p->num] = NULL;
p->num--;
}
leftAdjust和rightAdjust用于进行结点关键码的调整:
void BTree::rightAdjust(Bnode* p, Bnode* q, int d, int j)//与左子树调整
{
Bnode* p1 = q->child[j - 1]; //p的左兄弟
if (p1->num > d - 1) //第三种情况,左兄弟关键码足够分给p
{
p->num++;
for (int i = 2; i <= p->num; i++)
{
p->key[i] = p->key[i - 1];
p->child[i] = p->child[i - 1];
}
p->key[1] = q->key[j - 1]; //父节点相应关键码下沉
q->key[j - 1] = p1->key[p1->num]; //左兄弟最大关键码上移
p->child[0] = p1->child[p1->num];
p1->child[p1->num] = NULL;
p1->key[p1->num] = maxValue;
p1->num--;
}
else
merge(p1, q, p, j); //第四种情况,需要进行合并
}
void BTree::merge(Bnode* p, Bnode* q, Bnode* p1, int j) //结点合并
{
p->key[(p->num) + 1] = q->key[j];
p->child[(p->num) + 1] = p1->child[0];
for (int i = 1; i <= p1->num; i++)
{
p->key[p->num + 1 + i] = p1->key[i];
p->child[p->num + 1 + i] = p1->child[i];
}
compress(q, j); //将父节点进行压缩,j后的key和child左移
p->num = p->num + p1->num + 1;
delete p1;
}
leftAdjust与此类似
void BTree::leftAdjust(Bnode* p, Bnode* q, int d, int j)//结点p与父节点q一起调整,d是最少阶数,j是父节点调整位置
{
Bnode* p1 = q->child[j + 1]; //p的右兄弟
if (p1->num > d - 1) //右兄弟关键码足够分给p
{
p->num++;
p->key[p->num] = q->key[j + 1]; //父节点相应关键码下沉
q->key[j + 1] = p1->key[1]; //p1的最小关键码上移
p->child[p->num] = p1->child[0];
p1->child[0] = p1->child[1];
compress(p1, 1);
}
else
merge(p, q, p1, j + 1);
}
B树可视化
为了实现B树的可视化,一开始想要运用MFC或QT实现,但是这样太过于复杂,为了实现一棵树的可视化需要花费大量实践。之后在VS Code上发现一个专为数据结构可视化而生的脚本语言dot,语言逻辑简单,且安装也十分简便
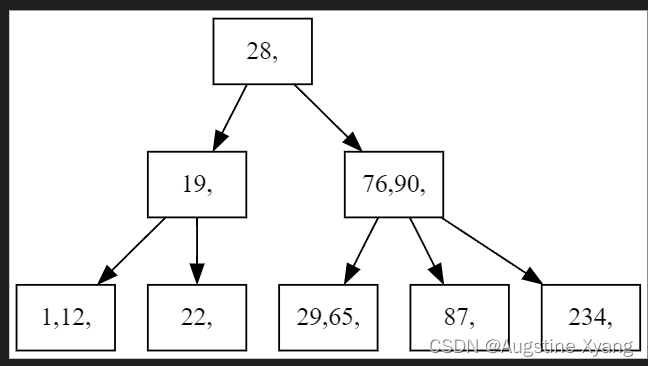
实际效果如图:
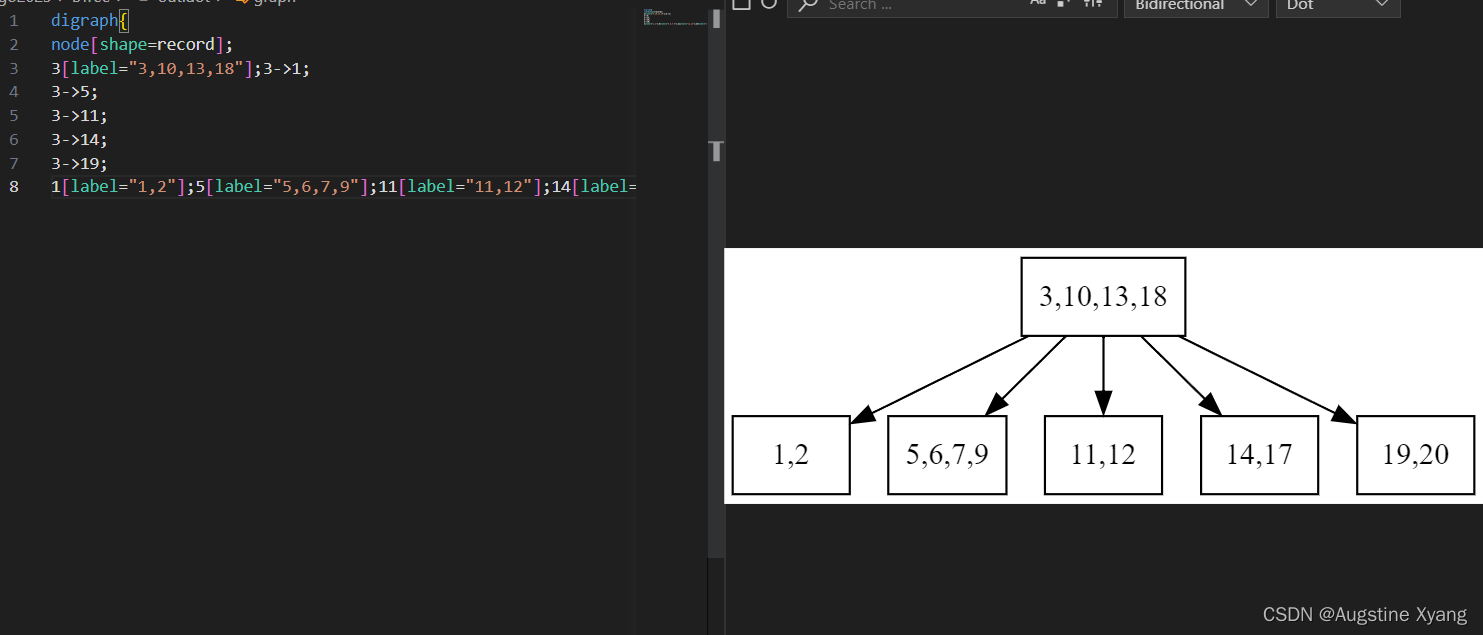
此处做简单说明:
· dot语言中3->1,3->14语句表示结点3指向结点1,结点3指向结点14。3、1、14即是结点的名字,而每个结点的[label=“…”]的label中则是每个结点的关键码内容。此处我简单使每个结点的名称是其第一个关键码,这样既可以保证不会重复,也会使写入dot文件时的流程更加简单。
代码方面:
void BTree::treePrint()
{
ofstream out("out.dot", ios::out | ios::trunc);
out << "digraph{" << endl << "node[shape=record];" << endl;
root->printNode(out);
out << "}";
}
void printNode(ofstream& out) {
//cout << setw(space);
//cout << "(";
string name = to_string(key[1]); //第一个关键码做名称
string str = name + "[label=\"";
for (int i = 1; i <= num; i++)
{
str += to_string(key[i]);
str += ",";
}
str += "\"];";
out << str;
for (int i = 0; i <= num; i++) //实现该结点指向其子结点
{
if (child[i] != NULL) {
out << name << "->" << child[i]->key[1] << ";" << endl;
}
}
int i = 0;
while (child[i] != NULL)
{
child[i]->printNode(out); //递归调用
i++;
}
}
使用说明
初始化
初始时,会需要输入初始的关键码个数和阶数,用于初始化B树:

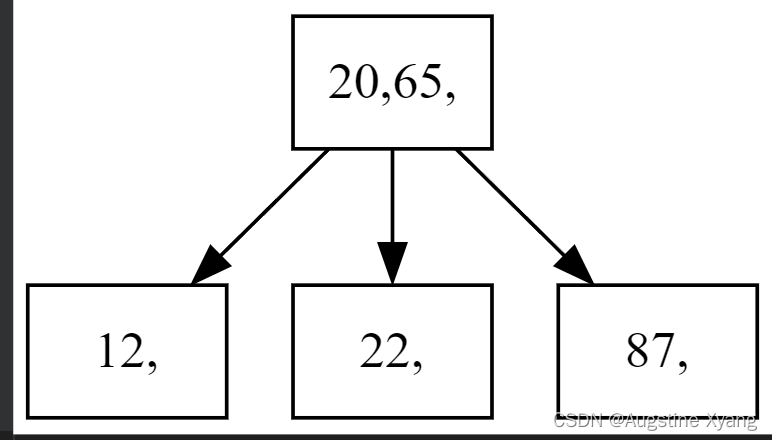
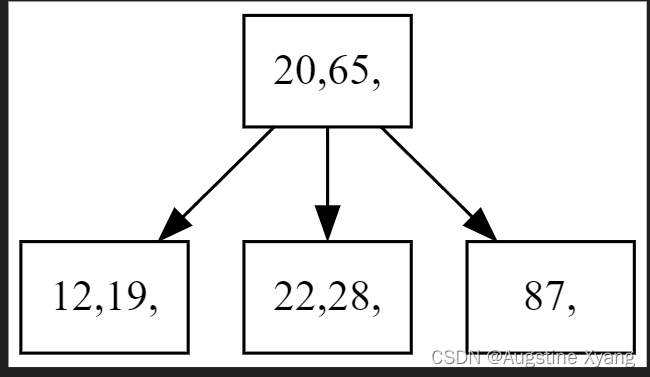
单次插入
输入I时,会执行insert插入关键码:

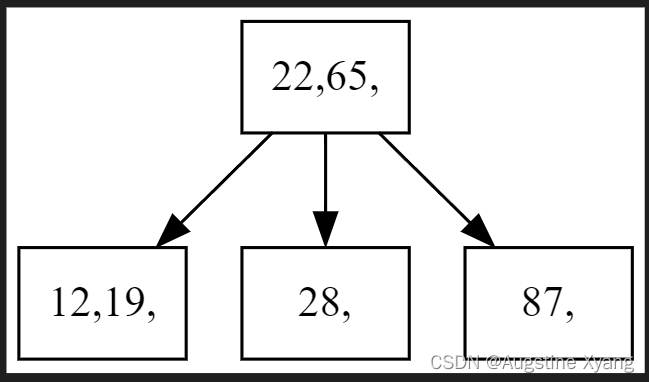
单次删除
输入D时,执行Delete删除操作

多插入
输入MI,执行multiInsert,一次性插入多个关键码,以以下格式输入:num,num,num……,num#:

会检测是否重复插入
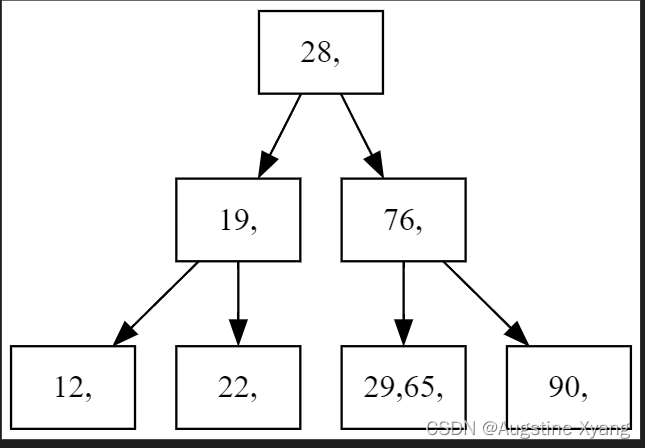
多删除
输入MD,执行多个关键码的删除
















 747
747











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









