







🍎 博客主页:🌙@披星戴月的贾维斯
🍎 欢迎关注:👍点赞🍃收藏🔥留言
🍇系列专栏:🌙 C/C++专栏
🌙那些看似波澜不惊的日复一日,一定会在某一天让你看见坚持的意义!-- 算法导论🌙
🍉一起加油,去追寻、去成为更好的自己!

提示:以下是本篇文章正文内容,下面案例可供参考
前言
期末月来了,想必大家都在紧锣密鼓复习吧,希望所有人都能安全度过期末,科科过!最近博主在备考MPI,整理了一些复习资料,和大家来分享一下!希望对大家考MPI有所帮助。
🍎1、什么是MPI?
总的来说:Massage Passing Interface:是消息传递函数库的标准规范,由MPI论坛开发,支持Fortran和C
- 一种新的库描述,不是一种语言。共有上百个函数调用接口,在Fortran和C语言中可以直接对这些函数进行调用
- MPI是一种标准或规范的代表,而不是特指某一个对它的具体实现
- MPI是一种消息传递编程模型,并成为这种编程模型的代表和事实上的标准
为什么要用MPI?
- 高可移植性 MPI已在IBM PC机上、MS Windows上、所有主要的Unix工作站上和所有主流的并行机上得到实现。使用MPI作消息传递的C或Fortan并行程序可不加改变地运行在IBM PC、 MS Windows 、 Unix工作站以及各种并行机上。
🍇运行mpi程序的工具 — Docker
🍇MPI是MIMD系统,该系统有几种网络互连方式

🍎2、MPI程序的的编译与运行
🍇步骤1编译程序
mpicc 是C语言的包装脚本(wrapper script)。包装脚本的主要目的是运行某个程序。
示例:
mpicc hello.c –o hello
编译生成hello执行文件,没有-o默认生成a.out.
🍇步骤2运行程序
-
方法一:产生的进程都在同台机子上
mpirun –np 4 hello
4 指定np的实参,表示进程数,由用户指定.
hello 要运行的MPI并行程序. -
方法二:产生的进程在不同的机子上
创建一个文本文件(如new.txt),在该文件上每行写上一个机器别名,写几行该机器别名就会在该机器上产生几个进程。
该服务器上的机器别名:console(控制服务器,主节点),g0110~g0119
mpirun –np 进程数 –machinefile 文本文件名 可执行文件
🍇mpi运行的基本命令总结
执行docker
docker start openmpi
进入mpi
docker exec -it openmpi bash
编译成文件mpicc
mpirun –np 4 ./hello
mpirun --allow-run-as-root -np 4 ./hello
mpirun是MPI程序快速执行命令
mpirun –np 进程个数 ./可执行文件
🍎3、MPI函数讲解
🍇6个最基本的MPI函数
- MPI_Init(…)
- MPI_Comm_size(…)
- MPI_Comm_rank(…)
- MPI_Send(…)
- MPI_Recv(…)
- MPI_Finalize(…)
MPI初始化-MPI_Init
函数原型:
int MPI_Init(int *argc, char **argv)
- 函数清除MPI环境的所有状态, MPI_Finalize是MPI程序的最后一个调用,它结束MPI程序的运行,它是MPI程序的最后一条可执行语句,否则程序的运行结果是不可预知的。
- 标志并行代码的结束,结束除主进程外其它进程。
- 之后串行代码仍可在主进程(rank = 0)上运行(如果必须).
MPI结束-MPI_Finalize
函数原型:
int MPI_Finalize(void)
- 函数清除MPI环境的所有状态, MPI_Finalize是MPI程序的最后一个调用,它结束MPI程序的运行,它是MPI程序的最后一条可执行语句,否则程序的运行结果是不可预知的。
- 标志并行代码的结束,结束除主进程外其它进程。
- 之后串行代码仍可在主进程(rank = 0)上运行(如果必须).
通信器、MPI_Comm_size
-
通信器(通信子):一组可以互相发送消息的进程集合
-
MPI 程序启动时自动建立两个通信器:
MPI_COMM_WORLD :包含程序中所有MPI进程
MPI_COMM_SELF:由单个进程独自构成,仅包含自己 -
进程号是在通信器被创建时赋予的,相对通信器而言;
同一进程在不同的通信器中可以有不同的进程号;
用MPI_Comm_size获得进程个数p
函数原型:
int MPI_Comm_size(
MPI_Comm comm /*in*/, //通信子
int* size /*out*/);//通信子的进程数
用MPI_Comm_rank 获得进程的一个叫rank的值
该rank值为0到p-1间的整数,相当于进程的ID
函数原型:
int MPI_Comm_rank(
MPI_Comm comm /*in*/,
int* my_rank_p /*out*/); //正在调用的进程在通信子中的进程号
🍇MPI_Send
MPI_Send 是MPI(Message Passing Interface)标准中用于发送消息的函数之一。它的主要作用是将数据从发送方进程发送到接收方进程。
MPI_Send 的函数原型如下:
int MPI_Send(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm)
MPI_Send 函数的工作原理是将数据从发送缓冲区复制到MPI库内部的缓冲区中,然后将消息发送到目标进程。MPI_Send 是一个阻塞函数,当它被调用时,发送方进程会阻塞,直到消息被成功发送到目标进程为止。
需要注意的是,MPI_Send 只是将消息发送到目标进程,接收方进程需要使用 MPI_Recv 或者其他接收消息的函数来接收消息。同时,MPI_Send 可能会产生死锁,因此需要注意正确使用 MPI_Send 和其他MPI函数来避免死锁问题的发生。
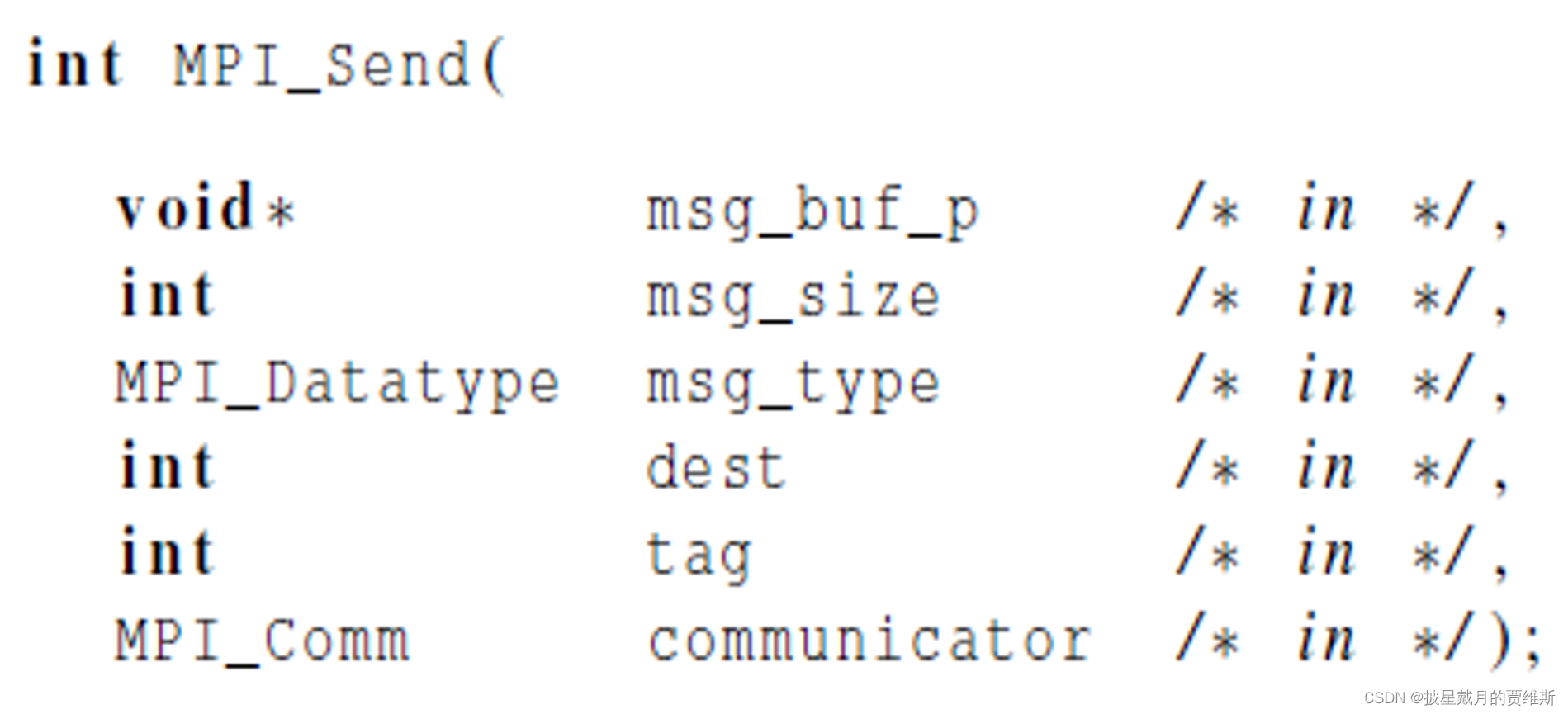
其中 void* msg_buf_p 是发送内容的地址(源)
int msg_size 是发送内容的大小
MPI_Datatype是消息的数据类型
int source 是发送进程的进程号
int tag 是消息标签
MPI_Comm communicator 是通信子
举例:
MPI_Send(send_buf_p, send_buf_sz, send_type, dest, send_tag, send_comm);
🍇MPI_Recv
MPI_Recv 是MPI(Message Passing Interface)标准中用于接收消息的函数之一。它的主要作用是从发送方进程接收数据。
MPI_Recv 的函数原型如下:
int MPI_Recv(void* buf, int count, MPI_Datatype datatype, int source, int tag, MPI_Comm comm, MPI_Status *status)
MPI_Recv 函数的工作原理是从MPI库内部的缓冲区中接收消息,然后将数据复制到接收缓冲区中。MPI_Recv 是一个阻塞函数,当它被调用时,接收方进程会阻塞,直到接收到消息为止。
需要注意的是,MPI_Recv 必须与 MPI_Send 或者其他发送消息的函数配合使用。同时,MPI_Recv 也可能会产生死锁,因此需要注意正确使用 MPI_Recv 和其他MPI函数来避免死锁问题的发生。
在 MPI_Recv 函数返回后,可以通过 status 参数获取消息的状态,包括发送进程的排名、消息的标记、消息的大小等信息。
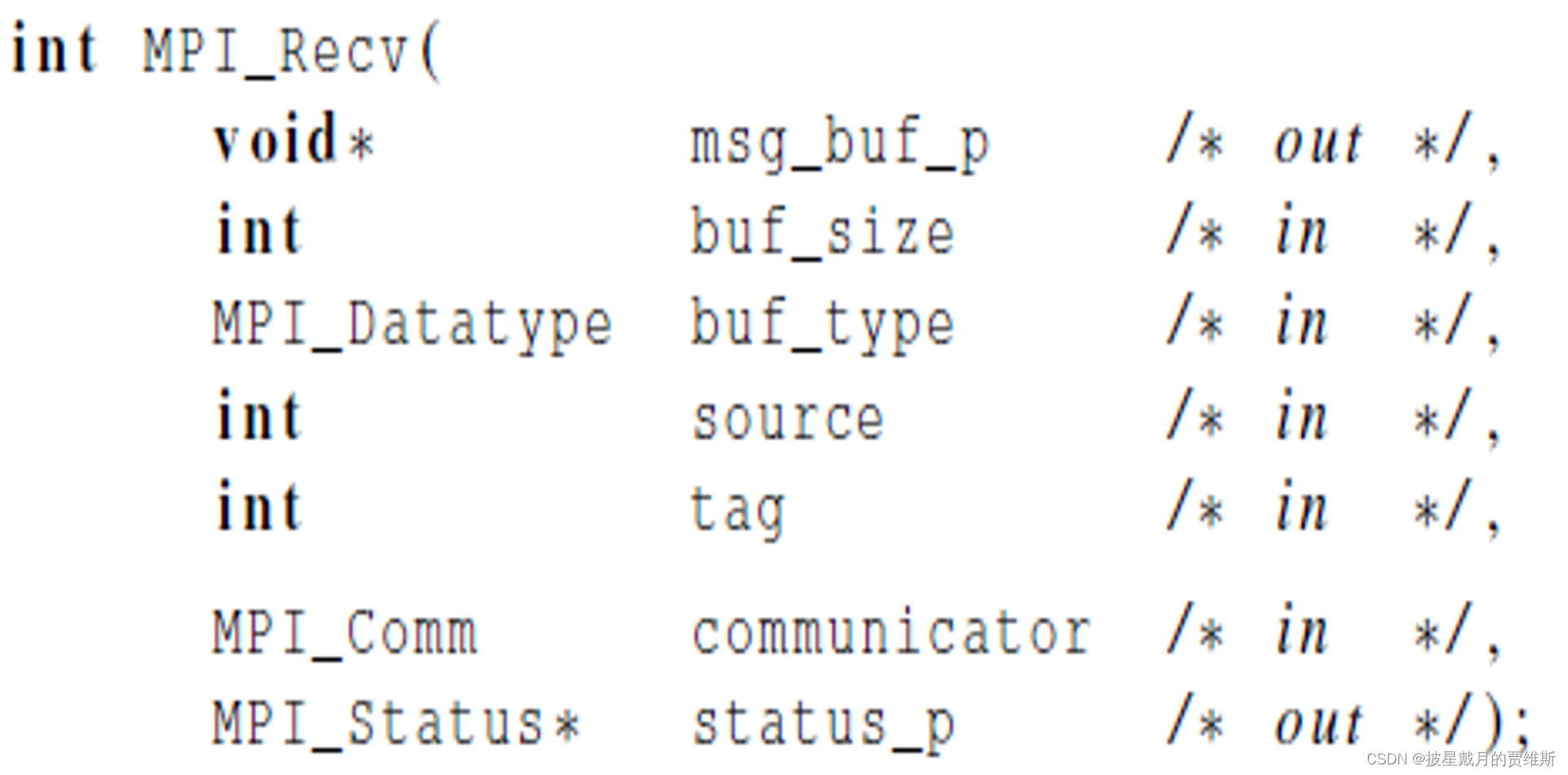
其中 void* msg_buf_p 是放消息的内存地址
int buf_size 是消息的大小
MPI_Datatype是接受消息的数据类型
int source 是接收进程的进程号
int tag 是消息标签
MPI_Comm communicator 是通信子
MPI_Status status_p 返回状态
集合通信函数讲解
集合通信是一个进程组中的所有进程都参加的全局通信操作。
集合通信主要实现功能:通信、聚集和同步。
通信功能主要完成组内数据的传输
聚集功能在通信的基础上对给定的数据完成一定的操作
同步功能实现组内所有进程在执行进度上取得一致
集合通信按照通信方向分为三种:一对多通信、多对一通信、多对多通信

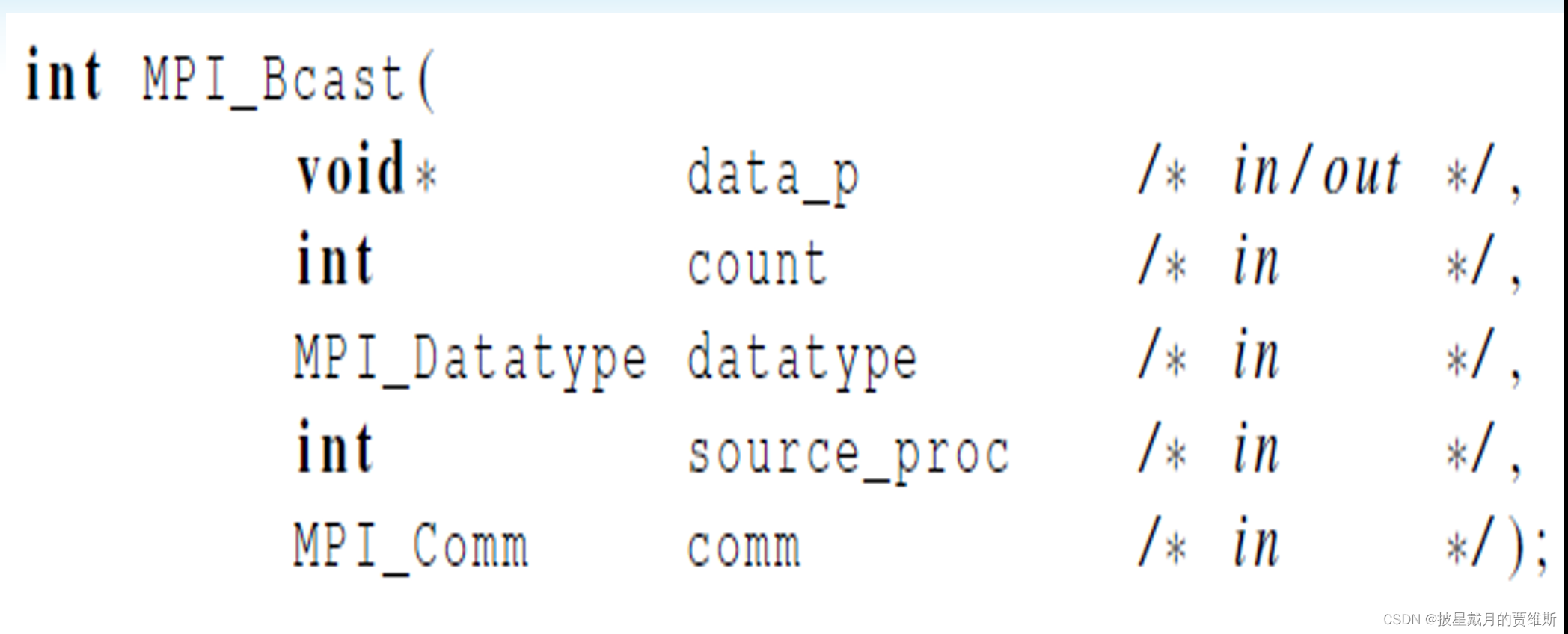
广播MPI_Bcast
是直接把全部数据发送到各个进程
广播函数 MPI_Bcast(),将某个进程的某个变量的值广播到该通信子中所有进程的同名变量中
函数原型:
MPI_BCAST(buffer,count,datatype,root,comm)
IN/OUT buffer 通信消息缓冲区的起始地址(可变)
IN count 通信消息缓冲区中的数据个数(整型)
IN datatype 通信消息缓冲区中的数据类型(句柄)
IN root 发送广播的根的序列号(整型)
IN comm 通信子(句柄)
int MPI_Bcast(void* buffer,int count,MPI_Datatype datatype,int root, MPI_Comm comm)
MPI_BCAST是从一个序列号为root的进程将一条消息广播发送到组内的所有进程,
包括它本身在内.调用时组内所有成员都使用同一个comm和root,
其结果是将根的通信消息缓冲区中的消息拷贝到其他所有进程中去.
MPI_Bcast(&n,1,MPI_INT,0,MPI_COMM_WORLD);//集合通信一定要放外面
MPI_Reduce
将通信子内各进程的同一个变量参与规约计算,并向指定的进程输出计算结果
全局规约函数MPI_Reduce:
将所有的发送信息进行同一个操作。
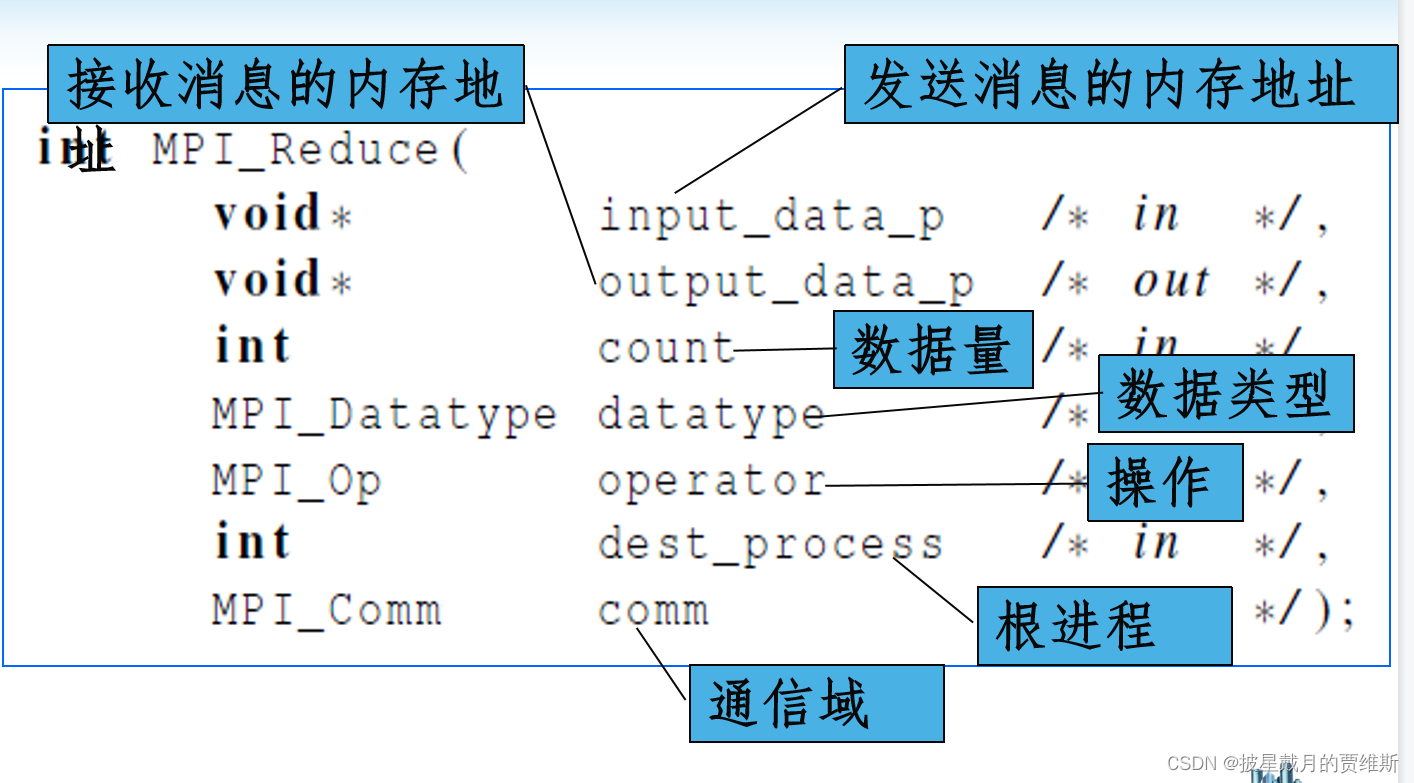
函数原型:
int MPI_Reduce(
void *input_data, /*指向发送消息的内存块的指针 */
void *output_data, /*指向接收(输出)消息的内存块的指针 */
int count,/*数据量*/
MPI_Datatype datatype,/*数据类型*/
MPI_Op operator,/*规约操作*/
int dest,/*要接收(输出)消息的进程的进程号*/
MPI_Comm comm);/*通信器,指定通信范围*/

散射函数 MPI_Scatter()
是平均分,把数据平均分到每一个进程
散射函数 MPI_Scatter(),将向量数据分段发送到各进程中
函数原型:
MPI_Scatter(
void* send_data,//存储在0号进程的数据,array
int send_count,//具体需要给每个进程发送的数据的个数
//如果send_count为1,那么每个进程接收1个数据;如果为2,那么每个进程接收2个数据
MPI_Datatype send_datatype,//发送数据的类型
void* recv_data,//接收缓存,缓存 recv_count个数据
int recv_count,
MPI_Datatype recv_datatype,
int root,//root进程的编号
MPI_Comm communicator)
聚集函数 MPI_Gather()
MPI_Gather和MPI_scatter刚好相反,他的作用是从所有的进程中将每个进程的数据集中到根进程中,同样根据进程的编号对array元素排序,如图所示:
![\AppData\Roaming\Typora\typora-user-images\image-20230612122847395.png)]](https://img-blog.csdnimg.cn/89e80ba9bd9d4547b9016abd630de106.png)
聚集函数 MPI_Gather(),将各进程中的向量数据分段聚集到一个进程的大向量中

还有些组合MPI函数就不过多介绍了。
🍎4、MPI常考编程题
MPI 编程惯例
- MPI 的所有常量与函数均以 MPI_ 开头
- 在C程序中,所有常数的定义除下划线外一律由大写字母组成,在函数和数据类型定义中, 接MPI_ 之后的第一个字母大写,其余全部为小写字母,即MPI_Xxx_xx
- MPI 程序的开始和结束必须是 MPI_Init和 MPI_Finalize
- 除MPI_Wtime 和 MPI_Wtick 外,所有 C 函数调用之后都将返回一个错误信息码
- 由于 C 语言的函数调用机制是值传递,所以 MPI 的所有 C 函数中的输出参数用的都是指针
最最简单的mpi程序 hello.c
输出hello world!
代码示例
#include <stdio.h>
#include "mpi.h"
int main (int argc, char* argv[])
{
int myid, num;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD,&myid); //获取进程的ID值
MPI_Comm_size(MPI_COMM_WORLD,&num);//获取进程个数p
printf("I am %d of %d:", myid, num);
printf(“Hello, world!\n”)
MPI_Finalize();
}
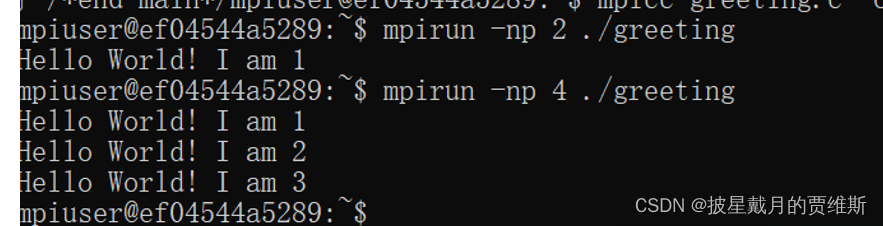
有消息传递greetings.c
for循环打印进程号
#include<stdio.h>
#include"mpi.h"
int main(int argc, char* argv[])
{
int numprocs, myid, source;//myid是当前进程的id,num是当前的进程数量
MPI_Init(&argc, &argv);
mPI_Status status;
char message[100];
MPI_Comm_rank(MPI_COMM_WORLD, &myid);//获取进程id值
MPI_Comm_size(MPI_COMM_WORLD, &numprocs);//获取进程个数
if (myid != 0)//如果不是0号进程
{
sprintf(message, "Hello World! I am %d ", myid);
MPI_Send(message, strlen(message) + 1, MPI_CHAR, 0, 99, MPI_COMM_WORLD);
//这里是由0号进程发送,99是通信子
}
else {
for (source = 1; source < numprocs; source++)
{
//message是接受数组, source是进程号,比MPI_Init函数多一个&status
MPI_Recv(message, 100, MPI_CHAR, source, 99, MPI_COMM_WORLD, &status);
printf("%s\n", message);
}
}
MPI_Finalize();
return 0;
}
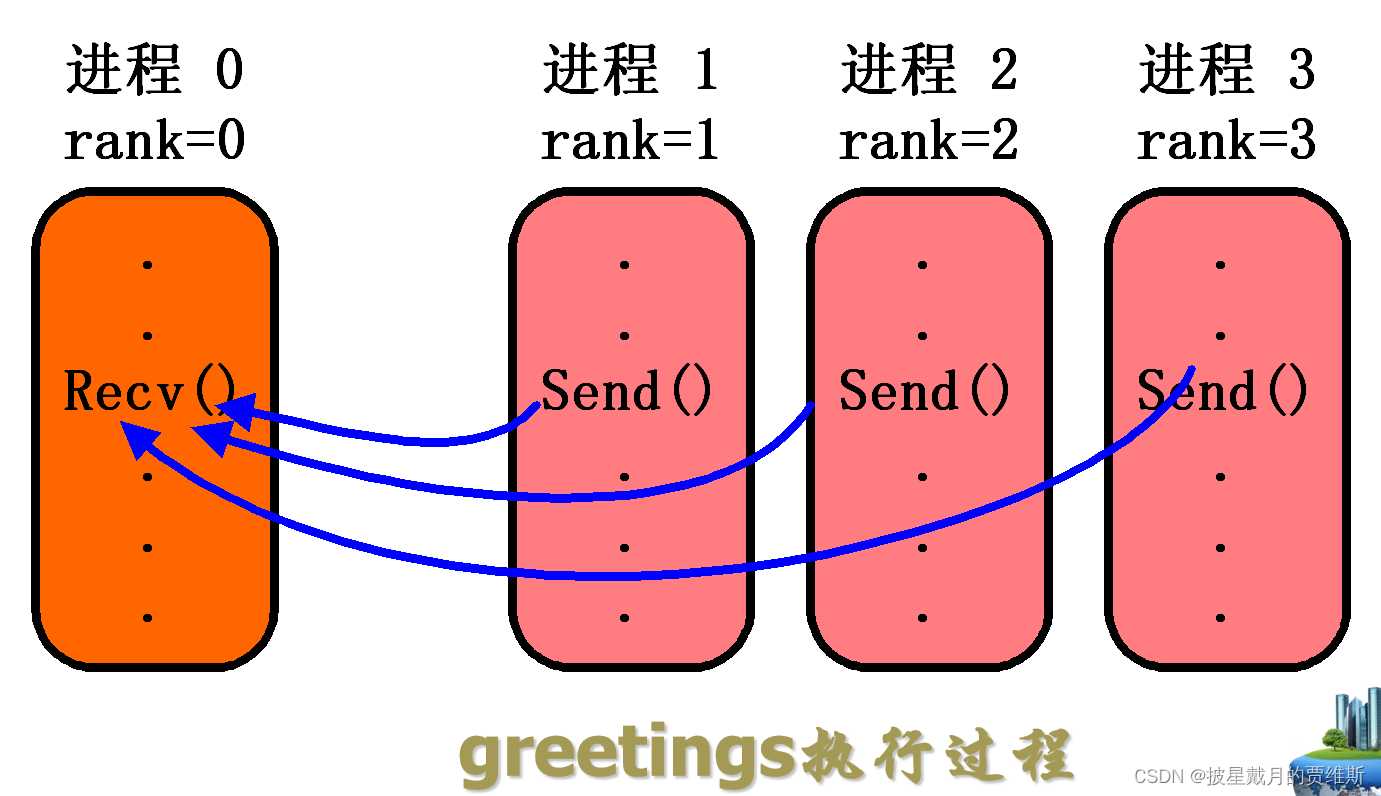
如图可以得出 0号进程负责接受,进程号从0开始,所以接受的进程=输入的进程-1

代码示例:
#include<stdio.h>
#include"mpi.h"
#include"string.h"
int main (int argc, char* argv[])
{
int myid, num;
MPI_Init(&argc, &argv);
MPI_Status status;
int tag = 999;
char a[100];
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
MPI_Comm_size(MPI_COMM_WORLD, &num);
if(myid != 0)
{
sprintf(a, "I am the process %d:", myid);
for(int i = 0; i < myid; i++)
{
sprintf(a, "%s%d", a, i + 1);
}
MPI_Send(a, strlen(a) + 1, MPI_CHAR, 0, tag, MPI_COMM_WORLD);
}
else{
for(int i = 1; i < num; i++){
MPI_Recv(a, 100, MPI_CHAR, i, tag, MPI_COMM_WORLD, &status);
printf("%s\n", a);
}
}
MPI_Finalize();
}

用MPI来实现梯形积分法
梯形积分法是一种数值积分方法,可以用于计算函数在区间上的积分值。将MPI和梯形积分法结合起来,可以实现在分布式系统上并行计算函数在区间上的积分值,提高计算效率。
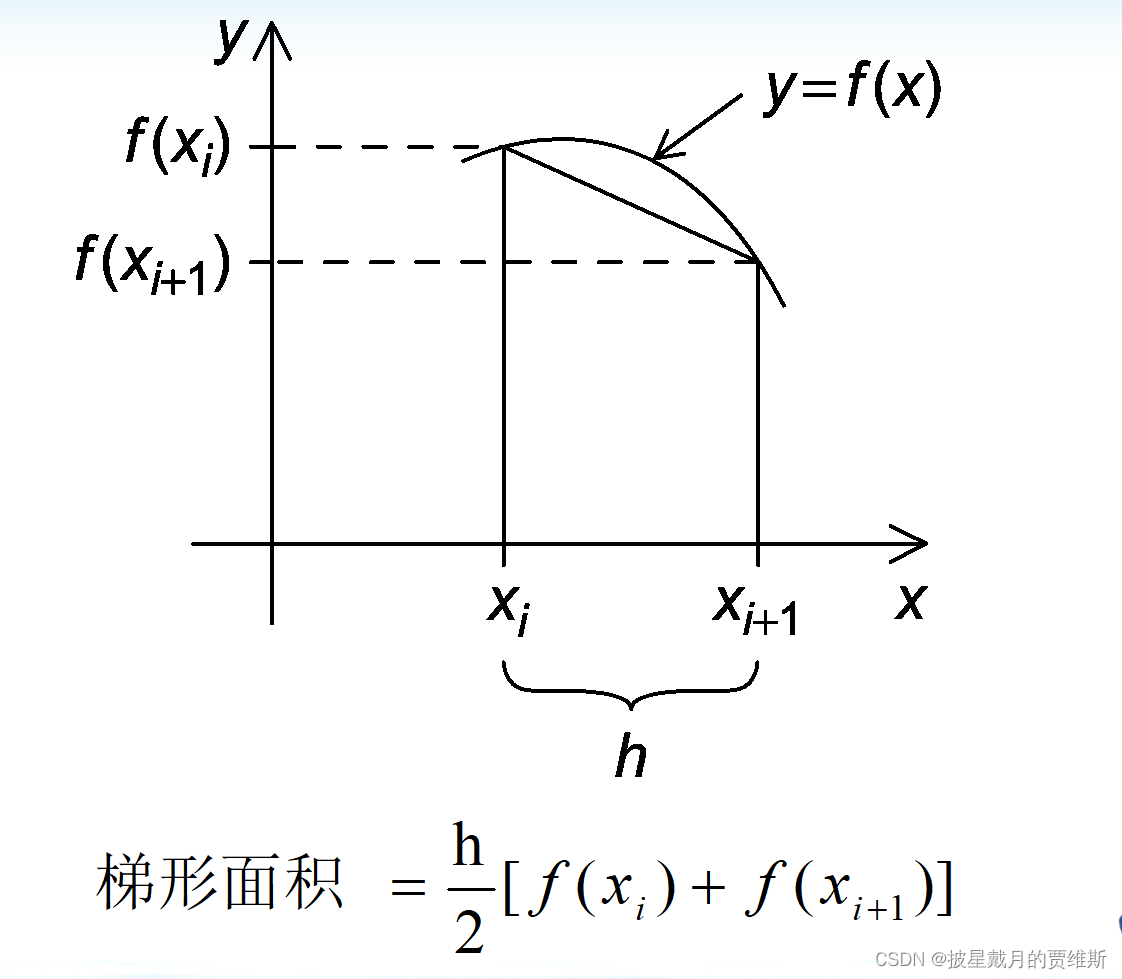
实现梯形积分法的MPI程序的基本步骤如下:
- 初始化MPI环境:调用MPI_Init函数初始化MPI环境,获取进程数和进程ID等信息。
- 分配任务:将整个区间分成若干个小区间,每个进程负责计算其中的一部分区间的积分值。
- 计算积分:对于每个小区间,使用梯形积分法计算积分值。
- 合并结果:使用MPI_Reduce函数将每个进程计算得到的积分值合并起来,得到最终的积分值。
- 结束MPI环境:调用MPI_Finalize函数结束MPI环境。
简单的mpi实现梯形积分法代码(有默认值):
#include<stdio.h>
#include"mpi.h"
double f(double x)
{
return x * x;
}
double Trap(double le, double re, int n, double h)
{
double ans, x;
ans = (f(le) + f(re) )/ 2.0;
for(int i = 1; i <= n - 1; i++)
{
x = le + h * i;
ans += f(x);
}
ans = ans* h;
return ans;
}
int main (int argc, char ** argv)
{
int myid, size, n = 1000, lc_n;
double a = 0.0, b = 3.0, lc_a, lc_b, h;
double lc_int;
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Status status;
h = (b - a) / n;
lc_n = n / size;
lc_a = a + myid * lc_n * h;
lc_b = lc_a + lc_n * h;
lc_int = Trap(lc_a, lc_b, lc_n, h);
if(myid != 0)
{
MPI_Send(&lc_int, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
}
else{
double sum = lc_int;
for(int i = 1; i < size; i++)
{
MPI_Recv(&lc_int, 1, MPI_DOUBLE, i, 0, MPI_COMM_WORLD, &status);
sum += lc_int;
}
printf("With n =%d ans \n", n);
printf("Intergral from %f to %f = %.15e\n", a, b, sum);
}
MPI_Finalize();
}
有输入输出的梯形积分法
#include"mpi.h"
#include<stdio.h>
double func(double x)
{
return x * x;
}
//依据梯形积分法公式:S = h/2 * [f(xi) + f(xi + 1)]
double Trap(double le, double re, int n, double h)
{
double ans=0, x;
int i;
ans = (func(le) + func(re)) / 2.0; //计算第一段和最后一段的面积
for(i = 1; i <= n - 1; i++){//for循环计算第一段和最后一段之间的值
x = le + i * h;
ans += func(x);
}
ans = ans * h;
return ans;
}
void Get_input(int myid, int size, double *a_p, double *b_p, int* n_p)
{
if(myid == 0){
printf("please input a, b, n\n");
scanf("%lf %lf %d", a_p, b_p, n_p);
for(int i = 1; i < size; ++i){
MPI_Send(a_p, 1, MPI_DOUBLE, i, 0, MPI_COMM_WORLD);//通信子是0
MPI_Send(b_p, 1, MPI_DOUBLE, i, 0, MPI_COMM_WORLD);//通信子是0
MPI_Send(n_p, 1, MPI_INT, i, 0, MPI_COMM_WORLD);//通信子是0
}
}else{
MPI_Recv(a_p, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD,MPI_STATUS_IGNORE);
MPI_Recv(b_p, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD,MPI_STATUS_IGNORE);
MPI_Recv(n_p, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD,MPI_STATUS_IGNORE);
}
}
int main()
{
int myid, size, lc_n, n=1000;
double a=0, b=3, h,lc_a, lc_b;
double lc_int, total_int;
MPI_Init(NULL, NULL);
MPI_Status status;
MPI_Comm_rank(MPI_COMM_WORLD, &myid);
MPI_Comm_size(MPI_COMM_WORLD, &size);
Get_input(myid, size, &a, &b, &n);
h = (b - a) / n;
lc_n = n / size;
lc_a = a + myid * lc_n *h;
lc_b = lc_a + lc_n *h;//一段的长度
lc_int = Trap(lc_a, lc_b, lc_n, h);
if(myid != 0)
{
MPI_Send(&lc_int, 1, MPI_DOUBLE, 0, 0, MPI_COMM_WORLD);
}else{
double sum= lc_int;
//printf("0 %lf\n",lc_int);
for(int i = 1; i < size; i++)
{
MPI_Recv(&lc_int, 1, MPI_DOUBLE, i, 0, MPI_COMM_WORLD, &status);
printf("%d %lf\n",myid,lc_int);
sum +=lc_int;
}
printf("With n =%d ans \n", n);
printf("Intergral from %f to %f = %.15e\n", a, b, sum);
}
MPI_Finalize();
}
判断素数 利用MPI_Scatter函数
#include<stdio.h>
#include"mpi.h"
int isPrime(int n)
{
if(n<=1) return 0;
for(int i = 2; i <= n / i; i++)
if(n % i == 0)
{
return 0;
}
return 1;
}
int main(int argc,char **argv)
{
int myid, size, n, lc_n = 2;
int a[100], _a[100];
MPI_Init(&argc, &argv);
MPI_Comm w = MPI_COMM_WORLD;
MPI_Comm_size(w, &size);
MPI_Comm_rank(w, &myid);
n = lc_n * size;
if(myid == 0)
{
printf("please input data\n");
for(int i = 0; i < n; i++) scanf("%d", &a[i]);
MPI_Scatter(a, lc_n, MPI_INT, _a, lc_n,MPI_INT, 0, w);
}else{
MPI_Scatter(a, lc_n, MPI_INT, _a, lc_n,MPI_INT, 0, w);
}
for(int i = 0; i < lc_n; i++)
{
if(isPrime(_a[i])) printf("%d ", _a[i]);
}
MPI_Finalize();
return 0;
}
判断素数:利用Bcast函数
#include<stdio.h>
#include"mpi.h"
int isPrime(int n)
{
if(n<=1) return 0;
for(int i = 2; i <= n / i; i++)
if(n % i == 0)
{
return 0;
}
return 1;
}
int main(int argc,char **argv)
{
int rank, size, n;
MPI_Init(&argc, &argv);
MPI_Comm_size(MPI_COMM_WORLD, &size);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if(rank == 0)
{
printf("Please input n\n");
scanf("%d", &n);
}
MPI_Bcast(&n,1,MPI_INT,0,MPI_COMM_WORLD);//集合通信一定要放外面
for(int i=rank;i<n;i+=size)
if(isPrime(i+1)) printf("%d ",i+1);
MPI_Finalize();
return 0;
}
水仙花数:利用MPI_Scatter函数
#include <stdio.h>
#include "mpi.h"
#include "stdlib.h"
int jv(int x)
{
int a,b,c;
c=x%10,b=x/10%10,a=x/100;
if(x==c*c*c+a*a*a+b*b*b) return 1;
else return 0;
}
int main(int argc,char* argv[])
{
int rank,size,n=999-100+1;
int a[1000],b[1000];
MPI_Status status;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&size);
MPI_Comm_rank(MPI_COMM_WORLD,&rank);
if(rank==0)
{
scanf("%d",&n);
for(int i=0;i<n;i++) a[i]=100+i;
MPI_Scatter(a,n/size,MPI_INT,b,n,MPI_INT,0,MPI_COMM_WORLD);
}
MPI_Bcast(&n,1,MPI_INT,0,MPI_COMM_WORLD);
if(rank) MPI_Scatter(a,n/size,MPI_INT,b,n,MPI_INT,0,MPI_COMM_WORLD);
for(int i=0;i<n/size;i++) if(jv(b[i])) printf("%d ",b[i]);
MPI_Finalize();
return 0;
}
🍎总结

本文总共写了1.2万字吗,也是有点震惊我,如果有需要mpi复习资料的也可以私信我要pdf版本之类的,希望大家读后能够有所收获!
















 855
855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











