






一、要求
根据用户上网的搜索记录对每天的热点搜索词进行统计,以了解用户所关心的热点话题。
要求完成:统计每天搜索数量前3名的搜索词(同一天中同一用户多次搜索同一个搜索词视为1次)。
二、数据
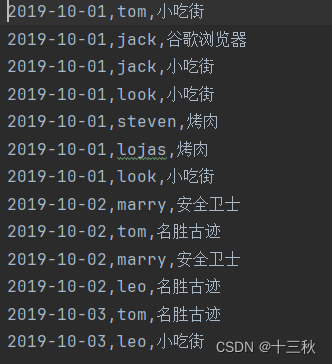
三、配置scala环境
1.下载scala插件
Scala插件的安装有两种方式:在线与离线。我们学习在线安装方式。
启动IDEA,在欢迎界面中选择Configure→Plugins命令,搜索scala进行下载
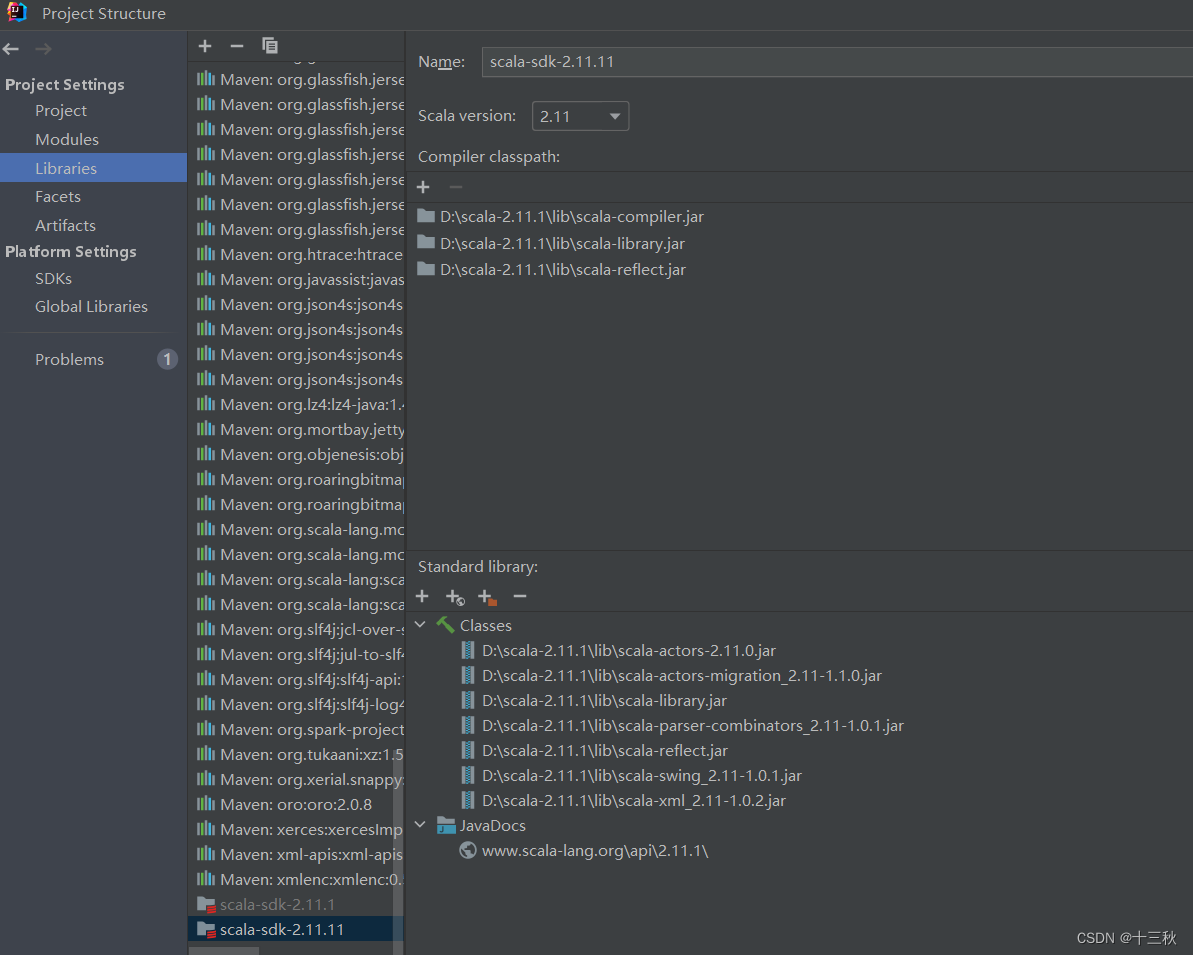
2.配置scala环境
下载后的scala进行环境配置
在Project Settings->Libraries中添加下载好的Scala
3.创建scala class
4.编写scala代码
package org.example
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.types._
import scala.collection.mutable.ListBuffer
object keywords {
def main(args: Array[String]): Unit = {
//构建SparkSession
// 构建SparkSession
val spark = SparkSession.builder()
.appName("YourAppName") // 设置应用程序的名称,显示在Spark UI中
.master("local[*]") // 设置Spark应用程序运行的主节点和资源
.getOrCreate() // 创建或获取已存在的SparkSession对象
//读取数据
val linesRDD: RDD[String] = spark.sparkContext.textFile("data/keywords.txt")
// 使用map算子操作转换RDD中的每个元素
val transformedRDD = linesRDD.map(line => {
val fields = line.split(",") // 按逗号分割每行数据
val date = fields(0) // 日期
val user = fields(1) // 用户
val keyword = fields(2) // 搜索词
((date, keyword), user) // 结果创建一个新的元组,其中包含键和值
})
//根据关键词进行分组
val groupedBy = transformedRDD.groupByKey() //将时间和搜索词相等的(键相等)划分为一组
// 去除每个分组中的重复用户名称
val distinctUsersPerGroup = groupedBy.map {
case ((date, keyword), users) => ((date, keyword), users.toSeq.distinct)
}
// 使用map操作来转换RDD中的每个元素,计数
val userCountsRDD = distinctUsersPerGroup.map {
case ((date, keyword), users) => ((date, keyword), users.size)
}
val result = userCountsRDD.collect()
println(result.mkString("\n"))
val rowRDD: RDD[Row] = userCountsRDD.map(line => {
Row(
line._1._1, //日期
line._1._2, //关键词
line._2.toInt //搜索次数
)
})
//构建DataFrame元数据
val structType = StructType(Array(
StructField("date", StringType, true),
StructField("keyword", StringType, true),
StructField("times", IntegerType, true)
))
//将RDD[Row]转为DataFrame
val df = spark.createDataFrame(rowRDD, structType)
//使用开窗函数取每一天的搜索前3名
df.createTempView("hot_times") //创建临时视图
//执行SQL查询
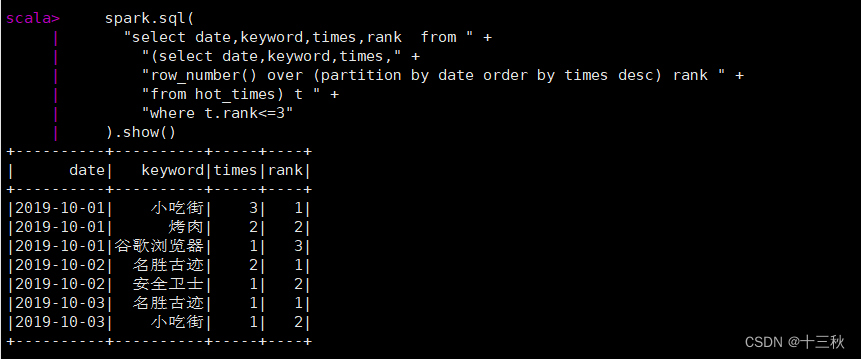
spark.sql(
"select date,keyword,times,rank from " +
"(select date,keyword,times," +
"row_number() over (partition by date order by times desc) rank " +
"from hot_times) t " +
"where t.rank<=3"
).show()
}
}
5.运行结果
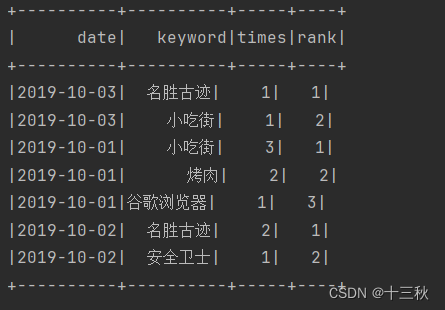
二、在Xshell中运行
总体流程
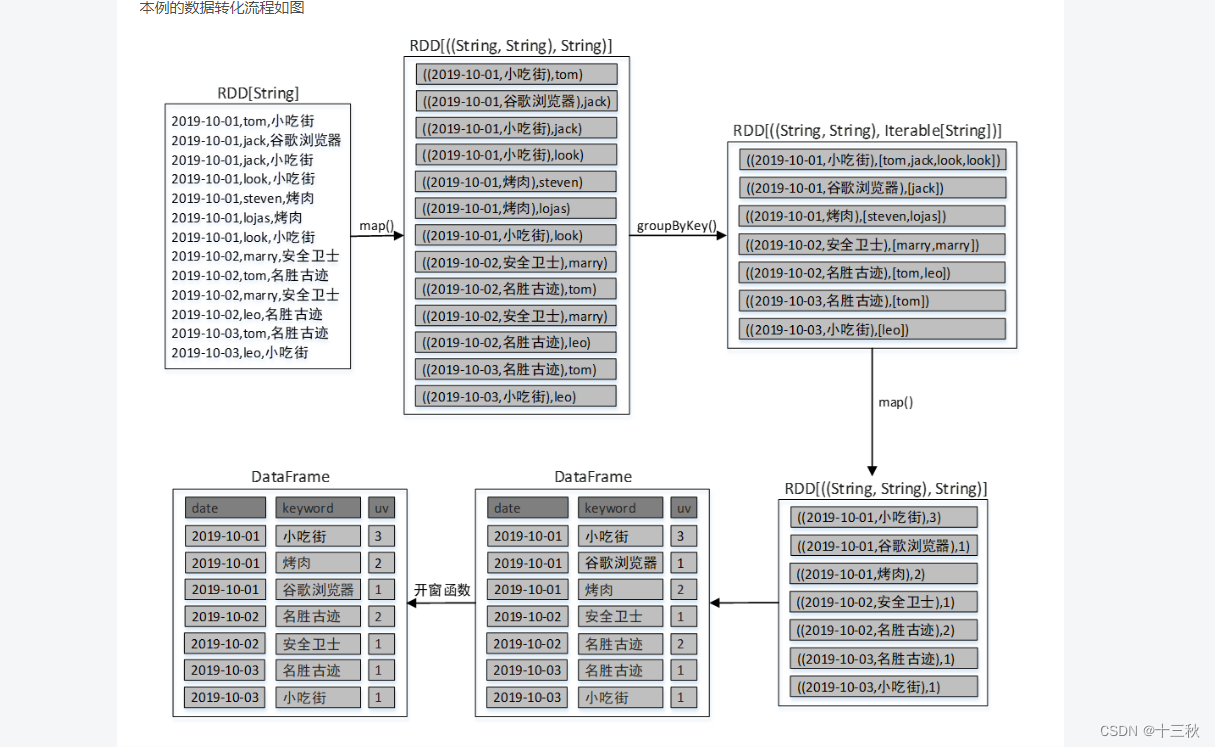
1.读取文件
val rdd = sc.textFile("file:///root/data/keywords.txt")

2.使用map算子,转换RDD中的每个元素
val rdd2 = rdd.map(line => {
val fields = line.split(",") // 按逗号分割每行数据
val date = fields(0) // 日期
val user = fields(1) // 用户
val keyword = fields(2) // 搜索词
((date, keyword), user) // 创建一个新的元组,其中包含键和值
})

3.根据关键词进行分组
将时间和搜索词相等的(键相等)划分为一组
val rdd3GBy= rdd2.groupByKey()

4.去除重复的值
val rdd4 =rdd3GBy.map { case ((date, keyword), users) => ((date, keyword), users.toSeq.distinct) }

5.使用map操作来转换RDD中的每个元素,计数
val rdd5 = rdd4.map {
case ((date, keyword), users) => ((date, keyword), users.size)
}
6.导入必要的包
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types._
import org.apache.spark.sql.{Row, SparkSession}
7.在Apache Spark中,SparkSession 是一个核心对象,用于与Spark交互。它是执行Spark应用程序的入口点,负责创建DataFrame和Dataset,以及读写数据。
val rowRDD: RDD[Row] = rdd5.map(line => {
Row(
line._1._1, //日期
line._1._2, //关键词
line._2.toInt //搜索次数
)
})
8.这段Scala代码是在使用Apache Spark的RDD(弹性分布式数据集)API来处理文本数据。
val structType = StructType(Array(
StructField("date", StringType, true),
StructField("keyword", StringType, true),
StructField("times", IntegerType, true)
))
9.将RDD[Row]转为DataFrame
val df = spark.createDataFrame(rowRDD, structType)
10.使用开窗函数取每一天的搜索前3名
df.createTempView("hot_times") //创建临时视图
//执行SQL查询
spark.sql(
"select date,keyword,times,rank from " +
"(select date,keyword,times," +
"row_number() over (partition by date order by times desc) rank " +
"from hot_times) t " +
"where t.rank<=3"
).show()
结果展示
小结
我们本次学习了使用spark sql来编写一个代码完成统计。在本次学习中,我们探索了如何利用Apache Spark SQL的强大功能来编写代码,以完成数据统计任务。通过Spark SQL,我们能够以一种声明式的方式处理数据集,使得数据分析变得更加直观和高效。我们学习了如何创建SparkSession,执行SQL查询,以及使用DataFrame API进行数据转换和分析。这些技能对于处理大规模数据集至关重要,能够帮助我们快速得到所需的统计结果。通过实践,我们发现Spark SQL不仅简化了代码编写,还提高了数据处理的性能。















 2038
2038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









