






3.高级神经网络结构
3.1什么是卷积神经网络CNN (Convolutional Neural Network)
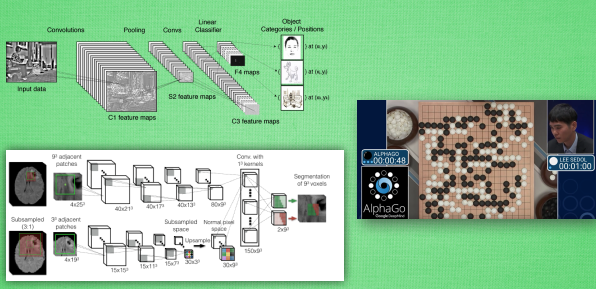
卷积神经网络是近些年逐步兴起的一种人工神经网络结构, 因为利用卷积神经网络在图像和语音识别方面能够给出更优预测结果, 这一种技术也被广泛的传播和应用. 卷积神经网络最常被应用的方面是计算机的图像识别, 不过因为不断地创新, 它也被应用在视频分析, 自然语言处理, 药物发现, 等等. 近期最火的 Alpha Go, 让计算机看懂围棋, 同样也是有运用到这门技术
卷积和神经网络

举一个识别图片的例子, 神经网络是由一连串的神经层组成,每一层神经层里面存在有很多的神经元. 这些神经元就是神经网络识别事物的关键. 每一种神经网络都会有输入输出值, 当输入值是图片的时候, 实际上输入神经网络的并不是那些色彩缤纷的图案,而是一堆堆的数字. 就比如说. 当神经网络需要处理这么多输入信息的时候, 也就是卷积神经网络就可以发挥它的优势的时候了.
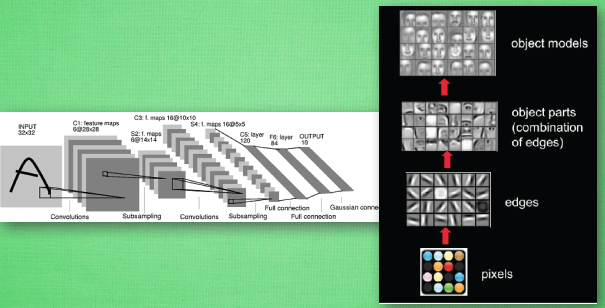
“卷积” 和 “神经网络”. 卷积也就是说神经网络不再是对每个像素的输入信息做处理了,而是图片上每一小块像素区域进行处理, 这种做法加强了图片信息的连续性. 使得神经网络能看到图形, 而非一个点. 这种做法同时也加深了神经网络对图片的理解. 具体来说, 卷积神经网络有一个批量过滤器, 持续不断的在图片上滚动收集图片里的信息,每一次收集的时候都只是收集一小块像素区域, 然后把收集来的信息进行整理, 这时候整理出来的信息有了一些实际上的呈现, 比如这时的神经网络能看到一些边缘的图片信息, 然后在以同样的步骤, 用类似的批量过滤器扫过产生的这些边缘信息, 神经网络从这些边缘信息里面总结出更高层的信息结构,比如说总结的边缘能够画出眼睛,鼻子等等. 再经过一次过滤, 脸部的信息也从这些眼睛鼻子的信息中被总结出来. 最后再把这些信息套入几层普通的全连接神经层进行分类, 这样就能得到输入的图片能被分为哪一类的结果了

上面是一张猫的图片, 图片有长, 宽, 高 三个参数. 对! 图片是有高度的! 这里的高指的是计算机用于产生颜色使用的信息. 如果是黑白照片的话, 高的单位就只有1, 如果是彩色照片, 就可能有红绿蓝三种颜色的信息, 这时的高度为3. 我们以彩色照片为例子. 过滤器就是影像中不断移动的东西, 他不断在图片收集小批小批的像素块, 收集完所有信息后, 输出的值, 可以理解成是一个高度更高,长和宽更小的”图片”. 这个图片里就能包含一些边缘信息. 然后以同样的步骤再进行多次卷积, 将图片的长宽再压缩, 高度再增加, 就有了对输入图片更深的理解. 将压缩,增高的信息嵌套在普通的分类神经层上,就能对这种图片进行分类了
池化(pooling)

研究发现, 在每一次卷积的时候, 神经层可能会无意地丢失一些信息. 这时, 池化 (pooling) 就可以很好地解决这一问题. 而且池化是一个筛选过滤的过程, 能将 layer 中有用的信息筛选出来, 给下一个层分析. 同时也减轻了神经网络的计算负担 (具体细节参考). 也就是说在卷积的时候, 不压缩长宽, 尽量地保留更多信息, 压缩的工作就交给池化了,这样的一项附加工作能够很有效的提高准确性. 有了这些技术,就可以搭建一个卷积神经网络了
流行的 CNN 结构

比较流行的一种搭建结构是这样, 从下到上的顺序,
- 首先是输入的图片(image),
- 经过一层卷积层 (convolution),
- 然后在用池化(pooling)方式处理卷积的信息, 这里使用的是 max pooling 的方式.
- 然后在经过一次同样的处理, 把得到的第二次处理的信息传入两层全连接的神经层 (fully connected),这也是一般的两层神经网络层,
- 最后在接上一个分类器(classifier)进行分类预测.
3.2CNN卷积神经网络
orch.manual_seed(1) # reproducible
# Hyper Parameters
EPOCH = 1 # 训练整批数据多少次, 为了节约时间, 我们只训练一次
BATCH_SIZE = 50
LR = 0.001 # 学习率
DOWNLOAD_MNIST = True # 如果你已经下载好了mnist数据就写上 False
# Mnist 手写数字
train_data = torchvision.datasets.MNIST(
root='./mnist/', # 保存或者提取位置
train=True, # this is training data
transform=torchvision.transforms.ToTensor(), # 转换 PIL.Image or numpy.ndarray 成
# torch.FloatTensor (C x H x W), 训练的时候 normalize 成 [0.0, 1.0] 区间
download=DOWNLOAD_MNIST, # 没下载就下载, 下载了就不用再下了
黑色的地方的值都是0, 白色的地方值大于0
CNN模型
用一个 class 来建立 CNN 模型. 这个 CNN 整体流程是 卷积层(Conv2d) (1个过滤器-> 激励函数(ReLU) -> 池化, 向下采样 (MaxPooling) -> 再来一遍 -> 展平多维的卷积成的特征图 -> 接入全连接层 (Linear) -> 输出
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential( # input shape (1, 28, 28)
nn.Conv2d(
in_channels=1, # input height,高度为1
out_channels=16, # n_filters
kernel_size=5, # filter size,长宽为5
stride=1, # filter movement/step
padding=2, # 如果想要 con2d 出来的图片长宽没有变化, padding=(kernel_size-1)/2 当 stride=1,周围一圈0,方便检测
), # output shape (16, 28, 28)
nn.ReLU(), # activation
nn.MaxPool2d(kernel_size=2), # 在 2x2 空间里向下采样, output shape (16, 14, 14),相当于第二次过滤
)
self.conv2 = nn.Sequential( # input shape (16, 14, 14)
nn.Conv2d(16, 32, 5, 1, 2), # output shape (32, 14, 14)
nn.ReLU(), # activation
nn.MaxPool2d(2), # output shape (32, 7, 7)
)
self.out = nn.Linear(32 * 7 * 7, 10) # fully connected layer, output 10 classes
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) # 展平多维的卷积图成 (batch_size, 32 * 7 * 7)
output = self.out(x)
return output
cnn = CNN()训练
下面我们开始训练, 将 x y 都用 Variable 包起来, 然后放入 cnn 中计算 output, 最后再计算误差. 下面代码省略了计算精确度 accuracy 的部分, 如果想细看 accuracy 代码的同学, 请去往我的 github 看全部代码
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
# training and testing
for epoch in range(EPOCH):
for step, (b_x, b_y) in enumerate(train_loader): # 分配 batch data, normalize x when iterate train_loader
output = cnn(b_x) # cnn output
loss = loss_func(output, b_y) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients3.3什么是循环神经网络RNN (Recurrent Neural Network)
序列数据

现在有一组序列数据 data 0,1,2,3. 在当预测 result0 的时候,我们基于的是 data0, 同样在预测其他数据的时候,也都只单单基于单个的数据. 每次使用的神经网络都是同一个 NN. 不过这些数据是有关联顺序的 , 就像在厨房做菜, 酱料 A要比酱料 B 早放, 不然就串味了. 所以普通的神经网络结构并不能让 NN 了解这些数据之间的关联
处理序列数据的神经网络
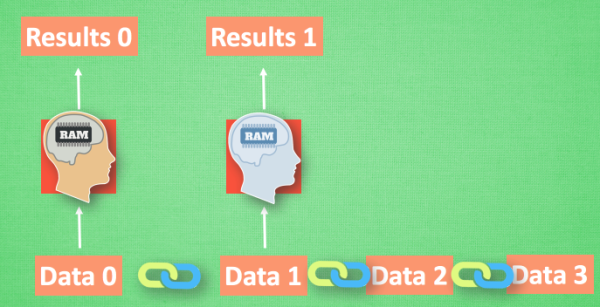
最基本的方式,就是记住之前发生的事情.让神经网络也具备这种记住之前发生的事的能力. 再分析 Data0 的时候, 我们把分析结果存入记忆. 然后当分析 data1的时候, NN会产生新的记忆, 但是新记忆和老记忆是没有联系的. 就简单的把老记忆调用过来, 一起分析. 如果继续分析更多的有序数据 , RNN就会把之前的记忆都累积起来, 一起分析

每次 RNN 运算完之后都会产生一个对于当前状态的描述 , state. 我们用简写 S( t) 代替, 然后这个 RNN开始分析 x(t+1) , 他会根据 x(t+1)产生s(t+1), 不过此时 y(t+1) 是由 s(t) 和 s(t+1) 共同创造的.
RNN 的应用
RNN 的形式不单单这有这样一种, 他的结构形式很自由. 如果用于分类问题, 比如说一个人说了一句话, 这句话带的感情色彩是积极的还是消极的. 那我们就可以用只有最后一个时间点输出判断结果的RNN.
又或者这是图片描述 RNN, 我们只需要一个 X 来代替输入的图片, 然后生成对图片描述的一段话.
或者是语言翻译的 RNN, 给出一段英文, 然后再翻译成中文.
3.4什么是 LSTM循环神经网络
为了记住这些数据, RNN 会像人一样产生对先前发生事件的记忆. 不过一般形式的 RNN 就像一个老爷爷, 有时候比较健忘.

想像现在有这样一个 RNN, 他的输入值是一句话: ‘我今天要做红烧排骨, 首先要准备排骨, 然后…., 最后美味的一道菜就出锅了’, 现在请 RNN 来分析, 我今天做的到底是什么菜呢. RNN可能会给出“辣子鸡”这个答案. 由于判断失误, RNN就要开始学习 这个长序列 X 和 ‘红烧排骨’ 的关系 , 而RNN需要的关键信息 ”红烧排骨”却出现在句子开头
红烧排骨这个信息原的记忆要进过长途跋涉才能抵达最后一个时间点. 然后得到误差, 而且在 反向传递 得到的误差的时候, 他在每一步都会 乘以一个自己的参数 W. 如果这个 W 是一个小于1 的数, 比如0.9. 这个0.9 不断乘以误差, 误差传到初始时间点也会是一个接近于零的数, 所以对于初始时刻, 误差相当于就消失了. 我们把这个问题叫做梯度消失或者梯度弥散 Gradient vanishing. 反之如果 W 是一个大于1 的数, 比如1.1 不断累乘, 则到最后变成了无穷大的数, RNN被这无穷大的数撑死了, 这种情况我们叫做梯度爆炸, Gradient exploding. 这就是普通 RNN 没有办法回忆起久远记忆的原因
LSTM
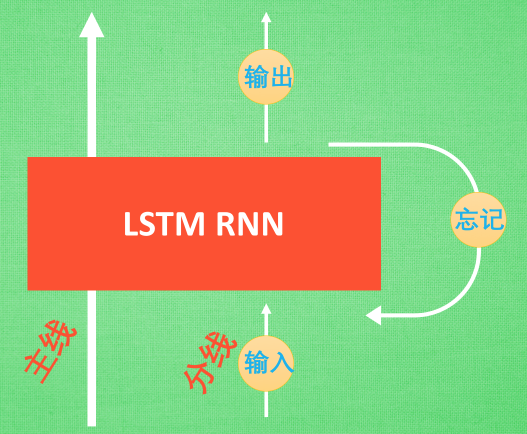
LSTM 就是为了解决这个问题而诞生的. LSTM 和普通 RNN 相比, 多出了三个控制器. (输入控制, 输出控制, 忘记控制).
他多了一个 控制全局的记忆, 我们用粗线代替. 把粗线想象成电影或游戏当中的 主线剧情. 而原本的 RNN 体系就是分线剧情. 三个控制器都是在原始的 RNN 体系上, 先看 输入方面 , 如果此时的分线剧情对于剧终结果十分重要, 输入控制就会将这个分线剧情按重要程度 写入主线剧情 进行分析. 再看 忘记方面, 如果此时的分线剧情更改了对之前剧情的想法, 那么忘记控制就会将之前的某些主线剧情忘记, 按比例替换成现在的新剧情. 所以主线剧情的更新就取决于输入和忘记 控制. 最后的输出方面, 输出控制会基于目前的主线剧情和分线剧情判断要输出的到底是什么.基于这些控制机制, LSTM 就像延缓记忆衰退的良药, 可以带来更好的结果
3.5RNN循环神经网络(分类)
MNIST手写数据
torch.manual_seed(1) # reproducible
# Hyper Parameters
EPOCH = 1 # 训练整批数据多少次, 为了节约时间, 我们只训练一次
BATCH_SIZE = 64
TIME_STEP = 28 # rnn 时间步数 / 图片高度
INPUT_SIZE = 28 # rnn 每步输入值 / 图片每行像素
LR = 0.01 # learning rate
DOWNLOAD_MNIST = True # 如果你已经下载好了mnist数据就写上 Fasle
# Mnist 手写数字
train_data = torchvision.datasets.MNIST(
root='./mnist/', # 保存或者提取位置
train=True, # this is training data
transform=torchvision.transforms.ToTensor(), # 转换 PIL.Image or numpy.ndarray 成
# torch.FloatTensor (C x H x W), 训练的时候 normalize 成 [0.0, 1.0] 区间
download=DOWNLOAD_MNIST, # 没下载就下载, 下载了就不用再下了
)
黑色的地方的值都是0, 白色的地方值大于0
RNN模型
用一个 class 来建立 RNN 模型. 这个 RNN 整体流程是
(input0, state0)->LSTM->(output0, state1);(input1, state1)->LSTM->(output1, state2);- ...
(inputN, stateN)->LSTM->(outputN, stateN+1);outputN->Linear->prediction. 通过LSTM分析每一时刻的值, 并且将这一时刻和前面时刻的理解合并在一起, 生成当前时刻对前面数据的理解或记忆. 传递这种理解给下一时刻分析
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.LSTM( # LSTM 效果要比 nn.RNN() 好多了
input_size=28, # 图片每行的数据像素点
hidden_size=64, # rnn hidden unit
num_layers=1, # 有几层 RNN layers
batch_first=True, # input & output 会是以 batch size 为第一维度的特征集 e.g. (batch, time_step, input_size)
)
self.out = nn.Linear(64, 10) # 输出层
def forward(self, x):
# x shape (batch, time_step, input_size)
# r_out shape (batch, time_step, output_size)
# h_n shape (n_layers, batch, hidden_size) LSTM 有两个 hidden states, h_n 是分线, h_c 是主线
# h_c shape (n_layers, batch, hidden_size)
r_out, (h_n, h_c) = self.rnn(x, None) # None 表示 hidden state 会用全0的 state
# 选取最后一个时间点的 r_out 输出
# 这里 r_out[:, -1, :] 的值也是 h_n 的值
out = self.out(r_out[:, -1, :])
return out
rnn = RNN()训练
将图片数据看成一个时间上的连续数据, 每一行的像素点都是这个时刻的输入, 读完整张图片就是从上而下的读完了每行的像素点. 然后拿出 RNN 在最后一步的分析值判断图片是哪一类了.
optimizer = torch.optim.Adam(rnn.parameters(), lr=LR) # optimize all parameters
loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
# training and testing
for epoch in range(EPOCH):
for step, (x, b_y) in enumerate(train_loader): # gives batch data
b_x = x.view(-1, 28, 28) # reshape x to (batch, time_step, input_size)
output = rnn(b_x) # rnn output
loss = loss_func(output, b_y) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients3.6 RNN循环神经网络(回归)
训练数据
我们要用到的数据就是这样的一些数据, 我们想要用 sin 的曲线预测出 cos 的曲线

torch.manual_seed(1) # reproducible
# Hyper Parameters
TIME_STEP = 10 # rnn time step / image height
INPUT_SIZE = 1 # rnn input size / image width
LR = 0.02 # learning rate
DOWNLOAD_MNIST = False # set to True if haven't download the dataRNN模型
这一次的 RNN, 我们对每一个 r_out 都得放到 Linear 中去计算出预测的 output, 所以能用一个 for loop 来循环计算
class RNN(nn.Module):
def __init__(self):
super(RNN, self).__init__()
self.rnn = nn.RNN( # 这回一个普通的 RNN 就能胜任
input_size=1,
hidden_size=32, # rnn hidden unit
num_layers=1, # 有几层 RNN layers
batch_first=True, # input & output 会是以 batch size 为第一维度的特征集 e.g. (batch, time_step, input_size)
)
self.out = nn.Linear(32, 1)
def forward(self, x, h_state): # 因为 hidden state 是连续的, 所以我们要一直传递这一个 state
# x (batch, time_step, input_size)
# h_state (n_layers, batch, hidden_size)
# r_out (batch, time_step, output_size)
r_out, h_state = self.rnn(x, h_state) # h_state 也要作为 RNN 的一个输入
outs = [] # 保存所有时间点的预测值
for time_step in range(r_out.size(1)): # 对每一个时间点计算 output
outs.append(self.out(r_out[:, time_step, :]))
return torch.stack(outs, dim=1), h_state forward 过程中的对每个时间点求输出还有一招使得计算量比较小的. 上面的内容主要是为了呈现 PyTorch 在动态构图上的优势, 所以用了一个 for loop 来搭建那套输出系统. 下面介绍一个替换方式. 使用 reshape 的方式整批计算
def forward(self, x, h_state):
r_out, h_state = self.rnn(x, h_state)
r_out = r_out.view(-1, 32)
outs = self.out(r_out)
return outs.view(-1, 32, TIME_STEP), h_state3.7什么是自编码(Autoencoder)
压缩与解压

有一个神经网络, 它在做的事情是 接收一张图片, 然后 给它打码, 最后 再从打码后的图片中还原.

假设刚刚那个神经网络是这样, 对应上刚刚的图片, 可以看出图片其实是经过了压缩,再解压的这一道工序. 当压缩的时候, 原有的图片质量被缩减, 解压时用信息量小却包含了所有关键信息的文件恢复出原本的图片
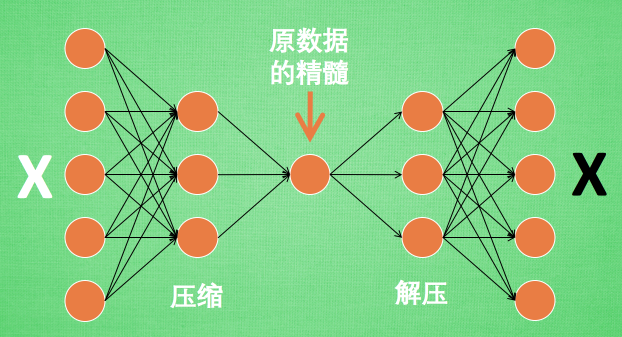
神经网络要接受大量的输入信息, 比如输入信息是高清图片时, 输入信息量可能达到上千万, 让神经网络直接从上千万个信息源中学习是一件很吃力的工作. 压缩一下, 提取出原图片中的最具代表性的信息, 缩减输入信息量, 再把缩减过后的信息放进神经网络学习. 这样学习起来就简单轻松了. 所以, 自编码就能在这时发挥作用. 通过将原数据白色的X 压缩, 解压 成黑色的X, 然后通过对比黑白 X ,求出预测误差, 进行反向传递, 逐步提升自编码的准确性. 训练好的自编码中间这一部分就是能总结原数据的精髓. 可以看出, 从头到尾, 只用到了输入数据 X, 并没有用到 X 对应的数据标签, 所以也可以说自编码是一种非监督学习. 到了真正使用自编码的时候. 通常只会用到自编码前半部分
编码器 Encoder
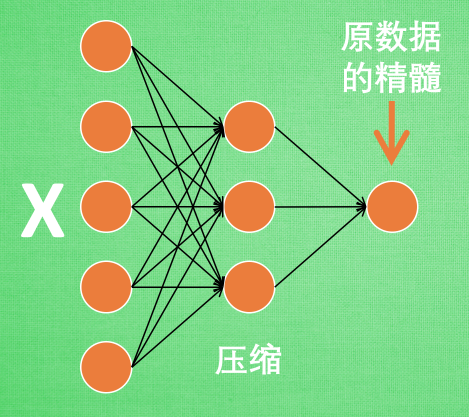
这 部分也叫作 encoder 编码器. 编码器能得到原数据的精髓, 然后只需要再创建一个小的神经网络学习这个精髓的数据,不仅减少了神经网络的负担, 而且同样能达到很好的效果
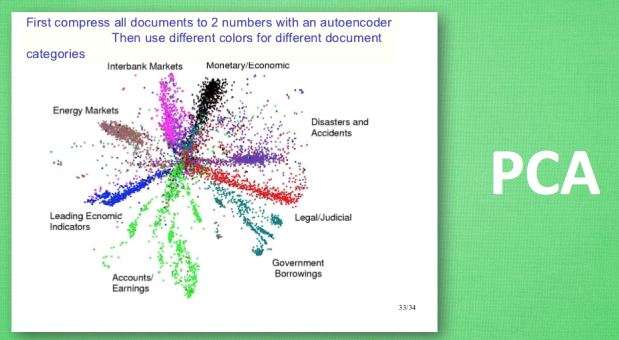
这是一个通过自编码整理出来的数据, 他能从原数据中总结出每种类型数据的特征, 如果把这些特征类型都放在一张二维的图片上, 每种类型都已经被很好的用原数据的精髓区分开来. 了解 PCA 主成分分析, 再提取主要特征时, 自编码和它一样,甚至超越了 PCA. 换句话说, 自编码 可以像 PCA 一样 给特征属性降维
3.8 AutoEncoder (自编码/非监督学习)
神经网络也能进行非监督学习, 只需要训练数据, 不需要标签数据. 自编码就是这样一种形式. 自编码能自动分类数据, 而且也能嵌套在半监督学习的上面, 用少量的有标签样本和大量的无标签样本学习
训练数据
# 超参数
EPOCH = 10
BATCH_SIZE = 64
LR = 0.005
DOWNLOAD_MNIST = True # 下过数据的话, 就可以设置成 False
N_TEST_IMG = 5 # 到时候显示 5张图片看效果, 如上图一
# Mnist digits dataset
train_data = torchvision.datasets.MNIST(
root='./mnist/',
train=True, # this is training data
transform=torchvision.transforms.ToTensor(), # Converts a PIL.Image or numpy.ndarray to
# torch.FloatTensor of shape (C x H x W) and normalize in the range [0.0, 1.0]
download=DOWNLOAD_MNIST, # download it if you don't have it
)
AutoEncoder
AutoEncoder 形式很简单, 分别是 encoder 和 decoder, 压缩和解压, 压缩后得到压缩的特征值, 再从压缩的特征值解压成原图片
class AutoEncoder(nn.Module):
def __init__(self):
super(AutoEncoder, self).__init__()
# 压缩
self.encoder = nn.Sequential(
nn.Linear(28*28, 128),
nn.Tanh(),
nn.Linear(128, 64),
nn.Tanh(),
nn.Linear(64, 12),
nn.Tanh(),
nn.Linear(12, 3), # 压缩成3个特征, 进行 3D 图像可视化
)
# 解压
self.decoder = nn.Sequential(
nn.Linear(3, 12),
nn.Tanh(),
nn.Linear(12, 64),
nn.Tanh(),
nn.Linear(64, 128),
nn.Tanh(),
nn.Linear(128, 28*28),
nn.Sigmoid(), # 激励函数让输出值在 (0, 1)
)
def forward(self, x):
encoded = self.encoder(x)
decoded = self.decoder(encoded)
return encoded, decoded
autoencoder = AutoEncoder()训练
训练, 并可视化训练的过程. 可以有效的利用 encoder 和 decoder 来做很多事, 比如这里用 decoder 的信息输出看和原图片的对比, 还能用 encoder 来看经过压缩后, 神经网络对原图片的理解. encoder 能将不同图片数据大概的分离开来. 这样就是一个无监督学习的过程
optimizer = torch.optim.Adam(autoencoder.parameters(), lr=LR)
loss_func = nn.MSELoss()
for epoch in range(EPOCH):
for step, (x, b_label) in enumerate(train_loader):
b_x = x.view(-1, 28*28) # batch x, shape (batch, 28*28)
b_y = x.view(-1, 28*28) # batch y, shape (batch, 28*28)
encoded, decoded = autoencoder(b_x)
loss = loss_func(decoded, b_y) # mean square error
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients3.9什么是 DQN
强化学习与神经网络

如今, 随着机器学习在日常生活中的各种应用, 各种机器学习方法也在融汇, 合并, 升级. 而今天所要探讨的强化学习则是这么一种融合了神经网络和 Q learning 的方法, 名字叫做 Deep Q Network.
神经网络的作用
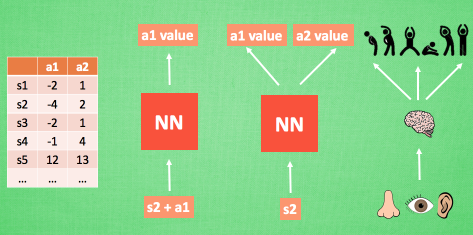
我们使用表格来存储每一个状态 state, 和在这个 state 每个行为 action 所拥有的 Q 值. 而当今问题是在太复杂, 状态可以多到比天上的星星还多(比如下围棋). 在机器学习中, 有一种方法对这种事情很在行, 那就是神经网络. 可以将状态和动作当成神经网络的输入, 然后经过神经网络分析后得到动作的 Q 值, 这样我们就没必要在表格中记录 Q 值, 而是直接使用神经网络生成 Q 值. 还有一种形式的是这样, 也能只输入状态值, 输出所有的动作值, 然后按照 Q learning 的原则, 直接选择拥有最大值的动作当做下一步要做的动作.
更新神经网络

接下来基于第二种神经网络来分析, 神经网络是要被训练才能预测出准确的值.
- 首先, 我们需要 a1, a2 正确的Q值, 这个 Q 值我们就用之前在 Q learning 中的 Q 现实来代替.
- 同样我们还需要一个 Q 估计 来实现神经网络的更新.
- 所以神经网络的的参数就是老的 NN 参数 加学习率 alpha 乘以 Q 现实 和 Q 估计 的差距. 我们整理一下

通过 NN 预测出Q(s2, a1) 和 Q(s2,a2) 的值, 这就是 Q 估计. 然后选取 Q 估计中最大值的动作来换取环境中的奖励 reward. 而 Q 现实中也包含从神经网络分析出来的两个 Q 估计值, 不过这个 Q 估计是针对于下一步在 s' 的估计. 最后再通过刚刚所说的算法更新神经网络中的参数. 但是这并不是 DQN 会玩电动的根本原因. 还有两大因素支撑着 DQN 使得它变得无比强大. 这两大因素就是 Experience replay 和 Fixed Q-targets
DQN 两大利器

简单来说, DQN 有一个记忆库用于学习之前的经历. Q learning 是一种 off-policy 离线学习法, 它能学习当前经历着的, 也能学习过去经历过的, 甚至是学习别人的经历. 所以每次 DQN 更新的时候, 都可以随机抽取一些之前的经历进行学习. 随机抽取这种做法打乱了经历之间的相关性, 也使得神经网络更新更有效率. Fixed Q-targets 也是一种打乱相关性的机理, 如果使用 fixed Q-targets, 就会在 DQN 中使用到两个结构相同但参数不同的神经网络, 预测 Q 估计 的神经网络具备最新的参数,
3.10 DQN强化学习
模块导入和参数设置
这次除了 Torch 自家模块, 还要导入 Gym 环境库模块
# 超参数
BATCH_SIZE = 32
LR = 0.01 # learning rate
EPSILON = 0.9 # 最优选择动作百分比
GAMMA = 0.9 # 奖励递减参数
TARGET_REPLACE_ITER = 100 # Q 现实网络的更新频率
MEMORY_CAPACITY = 2000 # 记忆库大小
env = gym.make('CartPole-v0') # 立杆子游戏
env = env.unwrapped
N_ACTIONS = env.action_space.n # 杆子能做的动作
N_STATES = env.observation_space.shape[0] # 杆子能获取的环境信息数神经网络
DQN 当中的神经网络模式, 将依据这个模式建立两个神经网络, 一个是现实网络 (Target Net), 一个是估计网络 (Eval Net).
class Net(nn.Module):
def __init__(self, ):
super(Net, self).__init__()
self.fc1 = nn.Linear(N_STATES, 10)
self.fc1.weight.data.normal_(0, 0.1) # initialization
self.out = nn.Linear(10, N_ACTIONS)
self.out.weight.data.normal_(0, 0.1) # initialization
def forward(self, x):
x = self.fc1(x)
x = F.relu(x)
actions_value = self.out(x)
return actions_valueDQN体系
简化的 DQN 体系是这样, 有两个 net, 有选动作机制, 有存经历机制, 有学习机制
class DQN(object):
def __init__(self):
# 建立 target net 和 eval net 还有 memory
def choose_action(self, x):
# 根据环境观测值选择动作的机制
return action
def store_transition(self, s, a, r, s_):
# 存储记忆
def learn(self):
# target 网络更新
# 学习记忆库中的记忆3.11什么是生成对抗网络(GAN)
常见神经网络形式
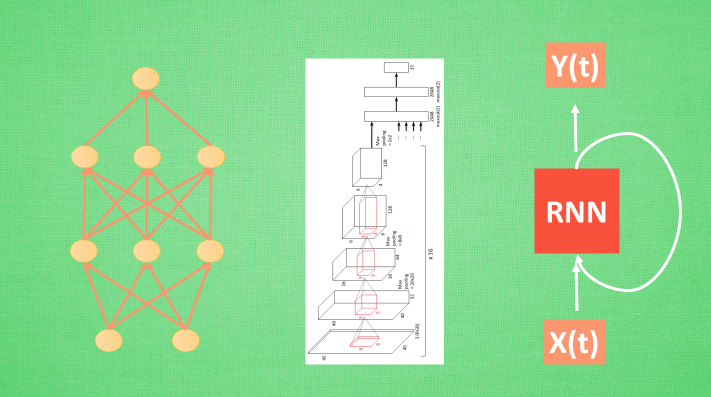
神经网络分很多种, 有普通的前向传播神经网络 , 有分析图片的 CNN 卷积神经网络 , 有分析序列化数据, 比如语音的 RNN 循环神经网络 , 这些神经网络都是用来输入数据, 得到想要的结果, 看中的是这些神经网络能很好的将数据与结果通过某种关系联系起来
生成网络

但是还有另外一种形式的神经网络, 他不是用来把数据对应上结果的, 而是用来”凭空”捏造结果, 这就是我们要说的生成网络啦. GAN 就是其中的一种形式. 当然这里的”凭空”并不是什么都没有的空盒子, 而是一些随机数

用没有意义的随机数来生成有有意义的作品, 比如著名画作. 当然, 这还不是全部, 这只是一个 GAN 的一部分而已, 这一部分的神经网络我们可以想象成是一个新手画家
新手画家

画家作画都需要点灵感 , 他们都是依照自己的灵感来完成作品. 有了灵感不一定有用, 因为他的作画技术并没有我们想象得好, 画出来有可能是一团糟. 聪明的新手画家找到了自己的一个正在学鉴赏的好朋友 – 新手鉴赏家
新手鉴赏家

可是新手鉴赏家也没什么能耐, 他也不知道如何鉴赏著名画作 , 所以坐在电脑旁边的你实在看不下去了, 拿起几个标签往屏幕上一甩 , 然后新手鉴赏家就被你这样一次次的甩来甩去着甩乖了, 慢慢也学会了怎么样区分著名画家的画了. 重要的是, 新手鉴赏家和新手画家是好朋友, 他们总爱分享学习到的东西
新手鉴赏家和新手画家

所以新手鉴赏家告诉新手画家, “你的画实在太丑了, 你看看人家达芬奇, 你也学学它呀, 比如这里要多加一点, 这里要画淡一点.” 就这样, 新手鉴赏家将他从你这里所学到的知识都分享给了新手画家, 让好朋友新手画家也能越画越像达芬奇. 这就是 GAN 的整套流程, 我们在来理一下.

新手画家用随机灵感画画 , 新手鉴赏家会接收一些画作, 但是他不知道这是新手画家画的还是著名画家画的, 他说出他的判断, 你来纠正他的判断, 新手鉴赏家一边学如何判断, 一边告诉新手画家要怎么画才能画得更像著名画家, 新手画家就能学习到如何从自己的灵感画出更像著名画家的画了. GAN 也就这么回事
3.12GAN (Generative Adversarial Nets生成对抗网络)
超参数设置
新手画家 (Generator) 在作画的时候需要有一些灵感 (random noise), 我们这些灵感的个数定义为 N_IDEAS. 而一幅画需要有一些规格, 我们将这幅画的画笔数定义一下, N_COMPONENTS 就是一条一元二次曲线(这幅画画)上的点个数. 为了进行批训练, 我们将一整批话的点都规定一下(PAINT_POINTS)
torch.manual_seed(1) # reproducible
np.random.seed(1)
# 超参数
BATCH_SIZE = 64
LR_G = 0.0001 # learning rate for generator
LR_D = 0.0001 # learning rate for discriminator
N_IDEAS = 5 # think of this as number of ideas for generating an art work (Generator)
ART_COMPONENTS = 15 # it could be total point G can draw in the canvas
PAINT_POINTS = np.vstack([np.linspace(-1, 1, ART_COMPONENTS) for _ in range(BATCH_SIZE)])
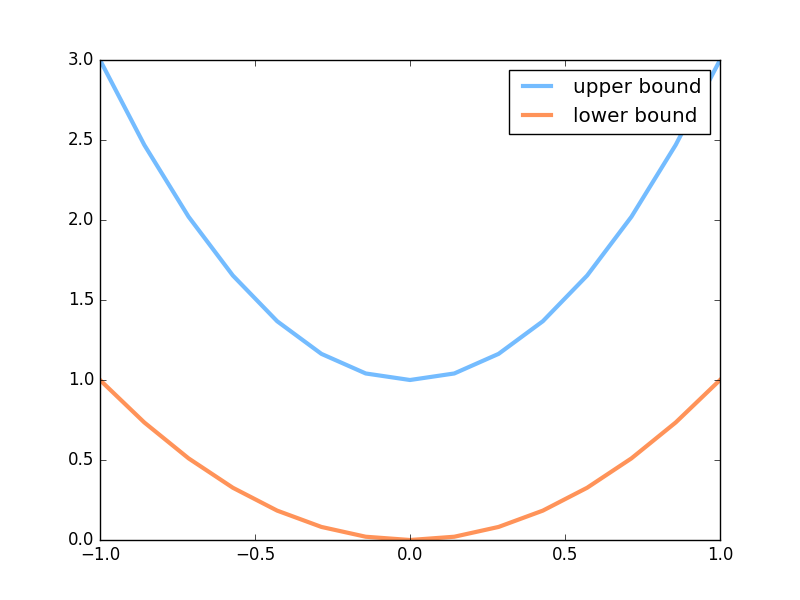
著名画家的画
我们需要有很多画是来自著名画家的(real data), 将这些著名画家的画, 和新手画家的画都传给新手鉴赏家, 让鉴赏家来区分哪些是著名画家, 哪些是新手画家的画. 如何区分我们在后面呈现. 这里我们生成一些著名画家的画 (batch 条不同的一元二次方程曲线).
def artist_works(): # painting from the famous artist (real target)
a = np.random.uniform(1, 2, size=BATCH_SIZE)[:, np.newaxis]
paintings = a * np.power(PAINT_POINTS, 2) + (a-1)
paintings = torch.from_numpy(paintings).float()
return paintings
下面就是会产生曲线的一个上限和下限.
神经网络
这里会创建两个神经网络, 分别是 Generator (新手画家), Discriminator(新手鉴赏家). G 会拿着自己的一些灵感当做输入, 输出一元二次曲线上的点 (G 的画).
D 会接收一幅画作 (一元二次曲线), 输出这幅画作到底是不是著名画家的画(是著名画家的画的概率).
G = nn.Sequential( # Generator
nn.Linear(N_IDEAS, 128), # random ideas (could from normal distribution)
nn.ReLU(),
nn.Linear(128, ART_COMPONENTS), # making a painting from these random ideas
)
D = nn.Sequential( # Discriminator
nn.Linear(ART_COMPONENTS, 128), # receive art work either from the famous artist or a newbie like G
nn.ReLU(),
nn.Linear(128, 1),
nn.Sigmoid(), # tell the probability that the art work is made by artist
)
训练
接着我们来同时训练 D 和 G. 训练之前, 我们来看看G作画的原理. G 首先会有些灵感, G_ideas 就会拿到这些随机灵感 (可以是正态分布的随机数), 然后 G 会根据这些灵感画画. 接着我们拿着著名画家的画和 G 的画, 让 D 来判定这两批画作是著名画家画的概率
for step in range(10000):
artist_paintings = artist_works() # real painting from artist
G_ideas = torch.randn(BATCH_SIZE, N_IDEAS) # random ideas
G_paintings = G(G_ideas()) # fake painting from G (random ideas)
prob_artist0 = D(artist_paintings) # D try to increase this prob
prob_artist1 = D(G_paintings) # D try to reduce this prob然后计算有多少来之画家的画猜对了, 有多少来自 G 的画猜对了, 我们想最大化这些猜对的次数. 这也就是 log(D(x)) + log(1-D(G(z)) 在论文中的形式. 而因为 torch 中提升参数的形式是最小化误差, 那我们把最大化 score 转换成最小化 loss, 在两个 score 的合的地方加一个符号就好. 而 G 的提升就是要减小 D 猜测 G 生成数据的正确率, 也就是减小 D_score1
D_loss = - torch.mean(torch.log(prob_artist0) + torch.log(1. - prob_artist1))
G_loss = torch.mean(torch.log(1. - prob_artist1))最后我们在根据 loss 提升神经网络就好了
opt_D.zero_grad()
D_loss.backward(retain_graph=True) # retain_graph 这个参数是为了再次使用计算图纸
opt_D.step()
opt_G.zero_grad()
G_loss.backward()
opt_G.step()















 978
978

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









