






1 函数
1.1 常用的统计学函数
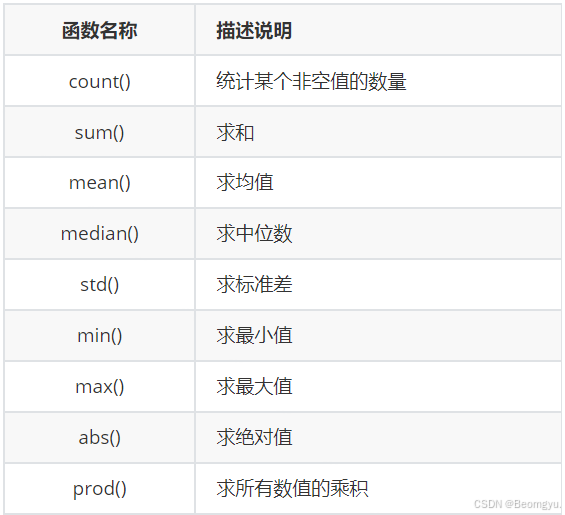
import pandas as pd
import numpy as np
def pd_df_cal():
data={
'A':[1,2,3,4,5],
'B':[10,20,30,40,50],
'C':[100,200,300,400,500]
}
df=pd.DataFrame(data)
print(f"df:\n{df}")
# 算术平均值
print(f"df.mean():\n{df.mean()}")
# 中位数
print(f"df.median():\n{df.median()}")
# 样本方差
print(f"df.var():\n{df.var()}")
# 标准差
print(f"df.std():\n{df.std()}")
# 最大值
print(f"df.max():\n{df.max()}")
# 最小值
print(f"df.min():\n{df.min()}")
# 求和
print(f"df.sum():\n{df.sum()}")
# 统计数量
print(f"df.count():\n{df.count()}")1.2 重置索引
1.2.1 DataFrame.reindex
DataFrame.reindex(labels=None, index=None, columns=None,axis=None, method=None, copy=True, level=None,fill_value=np.nan, limit=None, tolerance=None):
重置Dataframe索引,可变相添加行/列,若新行/列索引与原来不一致,则新行/列数据默认填充NaN,一致则直接填充。
参数:
1. labels:
- 类型:数组或列表,默认为 None。
- 描述:新的索引标签。
2. index:
- 类型:数组或列表,默认为 None。
- 描述:新的行索引标签。
3. columns:
- 类型:数组或列表,默认为 None。
- 描述:新的列索引标签。
4. axis:
- 类型:整数或字符串,默认为 None。
- 描述:指定重新索引的轴。0 或 'index' 表示行,1 或 'columns' 表示列。
5. method:
- 类型:字符串,默认为 None。
- 描述:用于填充缺失值的方法。
'ffill'(前向填充):用前一行/列的数据填充当前行/列
'bfill'(后向填充):用后一行/列的数据填充当前行/列
6. copy:
- 类型:布尔值,默认为 True。
- 描述:是否返回新的 DataFrame 或 Series。
7. level:
- 类型:整数或级别名称,默认为 None。
- 描述:用于多级索引(MultiIndex),指定要重新索引的级别。
8. fill_value:
- 类型:标量,默认为 np.nan。
- 描述:当新行/列有缺失值时,可用指定值填充
9. limit:
- 类型:整数,默认为 None。
- 描述:指定连续填充的最大数量。
10. tolerance:
- 类型:标量或字典,默认为 None。
- 描述:指定重新索引时的容差。
import pandas as pd
import numpy as np
def pd_df_reindex():
df=pd.DataFrame({'A':[1,2,3],'B':[4,5,6],'C':[7,8,9]},index=['a','b','c'])
print(f"df1:\n{df}")
# 重新索引行
new_index=['a','b','c','d']
df1=df.reindex(new_index)
print(f"df1:\n{df1}")
new_columns=['A','B','C','D']
df2=df.reindex(columns=new_columns,method='ffill')
print(f"df2:\n{df2}")
df3=df.reindex(new_index,fill_value=0)
print(f"df3:\n{df3}")1.2.2 DataFrame.reindex_like
DataFrame.reindex_like(other, method=None, copy=True, limit=None, tolerance=None):
用其他Dataframe中的索引来重置自己的索引,如果在新的索引与原始索引不完全匹配,那么不匹配的位置将会被填充为 NaN 值。
参数:
1. other:
- 类型:DataFrame 或 Series。
- 描述:用于对齐索引和列的参考对象。
2. method:
- 类型:字符串,默认为 None。
- 描述:用于填充缺失值的方法。可选值包括 'ffill'(前向填充)、'bfill'(后向填充)等。
3. copy:
- 类型:布尔值,默认为 True。
- 描述:是否返回新的 DataFrame 或 Series。
4. limit:
- 类型:整数,默认为 None。
- 描述:指定连续填充的最大数量。
5. tolerance:
- 类型:标量或字典,默认为 None。
- 描述:指定重新索引时的容差。
import pandas as pd
import numpy as np
def pd_df_row_reinedx_like():
df1=pd.DataFrame({'A':[1,2,3],'B':[4,5,6]},index=['a','b','c'])
df2=pd.DataFrame({'A':[7,8,9],'B':[10,11,12]},index=['b','c','d'])
df3=df1.reindex_like(df2)
print(f"df3:\n{df3}")1.3 遍历
1.3.1 Series遍历
import pandas as pd
import numpy as np
def pd_df_series_iter():
# 遍历Series可以像一维数组一样操作
s=pd.Series([1,2,3,4,5,6])
for i in s:
print(i)
# 1.通过items遍历
for index,value in s.items():
print(f"index:{index},value:{value}")
# 2.通过Index遍历
for index in s.index:
print(f"index:{index},value:{s[index]}")
print("\n")
# 通过values遍历
for v in s.values:
print(f"value:{v}")1.3.2 DataFrame遍历
1.iterrows(): 遍历 DataFrame 的行,返回index和row两个变量,遍历返回的row为Series对象
2.itertuples(): 遍历 DataFrame 的行,返回row一个变量,遍历的返回值为一个元组对象
import pandas as pd
def pd_df_DataFrame_row_iter():
df=pd.DataFrame({'A':[1,2,3],'B':[4,5,6]})
# 遍历行
# 1.通过iterrows遍历行,返回index和row两个变量,遍历返回的row为Series对象
for index,row in df.iterrows():
print(f"index:{index}\nrow:\n{row}")
# 2.通过itertuples遍历行,返回row一个变量,遍历的返回值为一个元组对象
for row in df.itertuples():
print(f"row:{row}")1.4 排序
1.4.1 sort_index
DataFrame.sort_index(axis=0, ascending=True, inplace=False):
对 DataFrame 或 Series 的索引进行排序。
参数:
- axis:指定要排序的轴。默认为 0,表示按行索引排序。如果设置为 1,将按列索引排序。
- ascending:布尔值,指定是升序排序(True)还是降序排序(False)。
- inplace:布尔值,指定是否在原地修改数据。如果为 True,则会修改原始数据;如果为 False,则返回一个新的排序后的对象。
1.4.2 sort_values
DataFrame.sort_values(by, axis=0, ascending=True,inplace=False, kind='quicksort', na_position='last'):用于根据一个或多个列的值对 DataFrame 进行排序。
参数:
- by:列的标签或列的标签列表。指定要排序的列。
- axis:指定沿着哪个轴排序。默认axis=0:按行排序。axis=1:按列排序
- ascending:布尔值或布尔值列表,指定是升序排序(True)还是降序排序(False)。可以为每个列指定不同的排序方向。
- inplace:布尔值,指定是否在原地修改数据。=True:修改原始数据,=False:返回一个新的排序后的对象。
- kind:排序算法。默认为 'quicksort',也可以选择 'mergesort' 或 'heapsort'。
- na_position:指定缺失值(NaN)的位置。可以是 'first' 或 'last'。
import pandas as pd
import numpy as np
def pd_df_sort():
df=pd.DataFrame({'A':[1,2,3],'B':[4,5,6]},index=['b','c','a'])
print(f"df:\n{df}")
# sort_index:
df1=df.sort_index()
print(f"df1:\n{df1}")
df2=df.sort_index(ascending=False)
print(f"df2:\n{df2}")
df3=pd.DataFrame({'A':[1,2,3],'B':[4,5,6]},index=['b','c','a'])
df3.sort_index(ascending=False,inplace=True)
print(f"df3:\n{df3}")
# sort_values:
df4=df.sort_values('A',ascending=False)
print(f"df4:\n{df4}")
df5 = df.sort_values(['A','B'], ascending=False)
print(f"df5:\n{df5}")1.5 去重
1.5.1 drop_duplicates
drop_duplicates(by=None, subset=None, keep='first', inplace=False):
用于删除 DataFrame 或 Series 中的重复行或元素。
参数:
- by:用于标识重复项的列名或列名列表。如果未指定,则使用所有列。
- subset:与 by 类似,但用于指定列的子集。
- keep:指定如何处理重复项。可以是:
- 'first':保留第一个出现的重复项(默认值)。
- 'last':保留最后一个出现的重复项。
- False:删除所有重复项。
- inplace:布尔值,指定是否在原地修改数据。
- True:会修改原始数据;
- Fals:返回一个新的删除重复项后的对象。
import pandas as pd
def pd_df_drop():
df=pd.DataFrame({
'A':[1,2,2,3],
'B':[4,5,5,6],
'C':[7,8,8,9]
})
print(f"df:\n{df}")
# 默认保留第一次重复的数据
df1=df.drop_duplicates()
print(f"df1:\n{df1}")
# keep='last':保留重复最后一条数据
df2=df.drop_duplicates(keep='last')
print(f"df2:\n{df2}")
df3=df.drop_duplicates(keep='False')
print(f"df3:\n{df3}")1.6 分组
1.6.1 groupby
DataFrame.groupby(by, axis=0, level=None,as_index=True, sort=True, group_keys=True,squeeze=False, observed=False, **kwargs):
对数据进行分组操作
参数:
- by:用于分组的列名或列名列表。
- axis:指定沿着哪个轴进行分组。默认为 0,表示按行分组。
- level:用于分组的 MultiIndex 的级别。
- as_index:布尔值,指定分组后索引是否保留。如果为 True,则分组列将成为结果的索引;如果为 False,则返回一个列包含分组信息的 DataFrame。
- sort:布尔值,指定在分组操作中是否对数据进行排序。默认为 True。
- group_keys:布尔值,指定是否在结果中添加组键。
- squeeze:布尔值,如果为 True,并且分组结果返回一个元素,则返回该元素而不是单列 DataFrame。
- observed:布尔值,如果为 True,则只考虑数据中出现的标签。
import pandas as pd
def pd_df_groupby():
data = {
'A': ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],
'B': ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],
'C': [1, 2, 3, 4, 5, 6, 7, 8],
'D': [10, 20, 30, 40, 50, 60, 70, 80]
}
df = pd.DataFrame(data)
print(f"df:\n{df}")
grouped=df.groupby('A')
for name,group in grouped:
print(f"name:{name},group:\n{group}")
# transform:数据计算和转换,返回的数据是保持的原df的数据结构
mean=df.groupby('A')['C'].transform('mean')
print(f"mean:\n{mean}")
# 把mean列添加到原df中
df['mean']=mean1.6.2 filter
import pandas as pd
def pd_df_filter():
data = {
'A': ['foo', 'bar', 'foo', 'bar', 'foo', 'bar', 'foo', 'foo'],
'B': ['one', 'one', 'two', 'three', 'two', 'two', 'one', 'three'],
'C': [1, 2, 3, 4, 5, 6, 7, 8],
'D': [10, 20, 30, 40, 50, 60, 70, 80]
}
df = pd.DataFrame(data)
print(f"df:\n{df}")
# 按列 'A' 分组,并过滤掉列 'C' 的平均值小于 4 的组
df1=df.groupby('A').filter(lambda x:x['C'].mean()>4)
print(f"df1:\n{df1}")1.7 合并
1.7.1 merge
pandas.merge(left,right,how='inner',on=None,left_on=None,right_on=None,left_index=False,right_index=False,sort=False, suffixes=('_x', '_y'), copy=True,indicator=False, validate=None):
两个Dataframe按照公共列进行合并
参数:
- left:左侧的 DataFrame 对象。
- right:右侧的 DataFrame 对象。
- how:合并方式,可以是 'inner'、'outer'、'left' 或 'right'。默认为 'inner'。
- 'inner':内连接,交集:返回两个DataFrame共有的键。
- 'outer':外连接,并集:返回两个DataFrame的所有键。
- 'left':左连接,返回左侧 DataFrame 的所有键,以及右侧 DataFrame 匹配的键。
- 'right':右连接,返回右侧 DataFrame 的所有键,以及左侧 DataFrame 匹配的键。
- on:指定两个Dataframe的公共列
- 如果未指定,则使用两个DataFrame中相同的列名。
- left_on 和 right_on:分别指定左侧和右侧 DataFrame 的连接列名。
- left_index 和 right_index:布尔值,指定是否使用索引作为连接键。
- sort:布尔值,指定是否在合并后对结果进行排序。
- suffixes:一个元组,指定当列名冲突时,右侧和左侧 DataFrame 的后缀。
- copy:布尔值,指定是否返回一个新的 DataFrame。如果为 False,则可能修改原始 DataFrame。
- indicator:布尔值,如果为 True,则在结果中添加一个名为 __merge 的列,指示每行是如何合并的。
- validate:验证合并是否符合特定的模式。
import pandas as pd
def pd_df_merge():
left=pd.DataFrame({
'key':[1,2,3,4,5],
'A':['A1','A2','A3','A4','A5'],
'B':['B1','B2','B3','B4','B5']
})
right=pd.DataFrame({
'key':[1,9,3,4,7],
'c':['c1','c2','c3','c4','c5'],
'D':['D1','D2','D3','D4','D5']
})
df=pd.merge(left,right,how='left')
print(df)
df1= pd.merge(left,right,how='right')
print(df1)
df2= pd.merge(left,right,how='outer')
print(df2)1.8 时间
1.8.1 datetime
import datetime as dt
def pd_df_datetime():
datetime=dt.datetime(2024,10,25,16,3,30)
print(datetime)
date=dt.date(2024,10,25)
print(date)
time=dt.time(16,3,30)
print(time)1.8.2 Timestamp
Timestamp 是一个特殊的 datetime 类型,用于表示单个时间点。
import pandas as pd
# 从日期字符串创建
ts = pd.Timestamp('2024-05-19 16:45:00')
print(ts)
# 从时间戳创建
ts = pd.Timestamp(1652937700) # Unix 时间戳
print(ts)1.8.3 to_datetime
pd.to_datetime():用于将字符串或其他格式的日期转换为 Pandas 的 Datetime 对象。
import pandas as pd
def pd_df_to_datetime():
s='2024-10-25 16:15:00'
d2=pd.to_datetime(s)
print(d2,"\n",type(d2))1.8.4 date_range
pandas.date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False, name=None, closed=None, **kwargs):
用于生成一个固定频率的日期时间索引(DatetimeIndex)
参数:
1. start:
- 类型:字符串或日期时间对象,默认为 None。
- 描述:起始日期时间。
2. end:
- 类型:字符串或日期时间对象,默认为 None。
- 描述:结束日期时间。
3. periods:
- 类型:整数,默认为 None。
- 描述:生成的日期时间索引的数量。
4. freq:
- 类型:字符串或日期偏移对象,默认为 None。
- 描述:时间频率。常见的频率包括 'D'(天)、'H'(小时)、'T' 或 'min'(分钟)、'S'(秒)
5. tz:
- 类型:字符串或时区对象,默认为 None。
- 描述:指定时区。
6. normalize:
- 类型:布尔值,默认为 False。
- 描述:是否将时间归一化到午夜。
7. name:
- 类型:字符串,默认为 None。
- 描述:生成的日期时间索引的名称。
8. closed:
- 类型:字符串,默认为 None。
- 描述:指定区间是否包含起始或结束日期时间。可选值为 'left'、'right' 或 None。
import pandas as pd
# 生成从 2023-01-01 到 2023-01-10 的每日日期时间索引
date_index = pd.date_range(start='2023-01-01', end='2023-01-10', freq='D')
print(date_index)
# 生成从 2023-01-01 00:00:00 到 2023-01-01 23:00:00 的每小时日期时间索引
date_index = pd.date_range(start='2023-01-01', periods=24, freq='H')
print(date_index)1.8.5 时间差
Timedelta 是一个用于表示时间间隔的对象。它可以表示两个时间点之间的差异,或者表示某个时间段的长度。
import datetime as dt
import pandas as pd
def pd_timedelat():
# 使用字符串表示
td1=pd.Timedelta('1 days 2 hours 30 minutes')
print(td1)
# 使用参数
td2=pd.Timedelta(days=1,hours=2,minutes=20,seconds=11)
print(td2)
# 使用整数和单位
td3=pd.Timedelta(5,unit='D')
print(td3)
# 时间差加减
date_time=dt.datetime.now()
date_time1=date_time+td1
print(date_time1)1.8.6 时间日期格式化
strftime 用于将日期时间对象转换为指定格式的字符串
strptime 用于将字符串解析为日期时间对象。
时间日期符号:
符号 说明
%y 两位数的年份表示(00-99)
%Y 四位数的年份表示(0000-9999)
%m 月份(01-12)
%d 月内中的一天(0-31)
%H 24小时制小时数(0-23)
%I 12小时制小时数(01-12)
%M 分钟数(00=59)
%S 秒(00-59)
%a 本地英文缩写星期名称
%A 本地英文完整星期名称
%b 本地缩写英文的月份名称
%B 本地完整英文的月份名称
%w 星期(0-6),星期天为星期的开始
%W 一年中的星期数(00-53)星期一为星期的开始
%x 本地相应的日期表示
%X 本地相应的时间表示
%Z 当前时区的名称
%U 一年中的星期数(00-53)星期天为星期的开始
%j 年内的一天(001-366)
%c 本地相应的日期表示和时间表示
import datetime as dt
# 创建一个日期时间对象
date_obj = datetime(2023, 10, 1, 14, 30, 45)
# 将日期时间对象转换为字符串
date_str = date_obj.strftime("%Y-%m-%d %H:%M:%S")
print(f"Formatted date string: {date_str}")
# 将字符串解析为日期时间对象
parsed_date_obj = datetime.strptime(date_str, "%Y-%m-%d %H:%M:%S")
print(f"Parsed datetime object: {parsed_date_obj}")1.9 随机抽样
DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None):随机抽样,从总体样本中随机抽取一部分数据
参数:
- n:要抽取的行数
- frac:抽取的比例,比如 frac=0.5,代表抽取总体数据的50%
- replace:布尔值参数,表示是否以有放回抽样的方式进行选择,默认为 False,取出数据后不再放回
- weights:可选参数,代表每个样本的权重值,参数值是字符串或者数组
- random_state:可选参数,控制随机状态,默认为 None,表示随机数据不会重复;若为 1 表示会取得重复数据
- axis:示在哪个方向上抽取数据(axis=1 表示列/axis=0 表示行)
def sample_test():
df = pd.DataFrame({
"company": ['百度', '阿里', '腾讯'],
"salary": [43000, 24000, 40000],
"age": [25, 35, 49]
})
print(df.sample(2,axis=0))
print(df.sample(frac=0.8,axis=0))1.10 空值处理
1.10.1 检测空值
isnull():检测 DataFrame 或 Series 中的空值,返回一个布尔值。空:True;非空:False
notnull():检测 DataFrame 或 Series 中的非空值,返回一个布尔值。非空:True;空:False
import pandas as pd
import numpy as np
def pd_null():
data = {
'A': [1, 2, np.nan, 4],
'B': [5, np.nan, np.nan, 8],
'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data)
# 检测空值
is_null = df.isnull()
print(is_null)
# 检测非空值
not_null = df.notnull()
print(not_null)1.10.2 填充空值
fillna() :填充 DataFrame 或 Series 中的空值。
import pandas as pd
import numpy as np
def pd_fillna():
data = {
'A': [1, 2, np.nan, 4],
'B': [5, np.nan, np.nan, 8],
'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data)
df1=df.fillna(0)
print(df1)1.10.3 删除空值
dropna():删除 DataFrame 或 Series 中的空值。
2 读取CSV文件
1.to_csv():DataFrame存储为csv文件
参数:
- path:存储CSV文件相对路径,也可以是绝对路径
- index:=True表示将行索引保存到CSV文件中,False表示不存行索引
2.read_csv() :CSV文件中读取数据
import pandas as pd
def pd_csv():
# 创建一个简单的 DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# 将DataFrame导出为CSV文件,index=False:不存行标签
df.to_csv('7.1output.csv',index=False)
df1=pd.read_csv('7.1output.csv')
print(df1)3 绘图
Pandas 在数据分析、数据可视化方面有着较为广泛的应用,Pandas 对 Matplotlib 绘图软件包的基础上单独封装了一个plot()接口,通过调用该接口可以实现常用的绘图操作;
Pandas 之所以能够实现了数据可视化,主要利用了 Matplotlib 库的 plot() 方法,它对 plot() 方法做了简单的封装,因此您可以直接调用该接口;
只用 pandas 绘制图片可能可以编译,但是不会显示图片,需要使用 matplotlib 库,调用 show() 方法显示图形。
import pandas as pd
import matplotlib.pyplot as plt
# 创建一个示例 DataFrame
data = {
'A': [1, 2, 3, 4, 5],
'B': [10, 20, 25, 30, 40]
}
df = pd.DataFrame(data)
# 绘制折线图
df.plot(kind='line')
# 显示图表
plt.show()
# 绘制柱状图
df.plot(kind='bar')
# 显示图表
plt.show()
# 绘制直方图
df['A'].plot(kind='hist')
# 显示图表
plt.show()
# 绘制散点图
df.plot(kind='scatter', x='A', y='B')
# 显示图表
plt.show()
















 2956
2956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









