






前言
我有一个图片,他上面的文字我觉得对我有用,我想把它摘下来,但是,我懒,不想一个一个手巧,又不想借助其他的软件进行识别,就想自己写串代码实现图片的文字识别,怎么办呢?来瞅瞅这篇文章吧(此文章最好用于截图之类规范文章的图片)。
一、模块pytesseract实现图片文字OCR识别过程
1.了解
OCR(Optical character recognition,光学字符识别)是一种将图像中的手写字或者印刷文本转换为机器编码文本的技术,可以将图片,纸质文档中的文本转换为数字形式的文本。
pytesseract是基于Python的OCR工具, 底层使用的是Google的Tesseract-OCR 引擎,支持识别图片中的文字,支持如下格式。
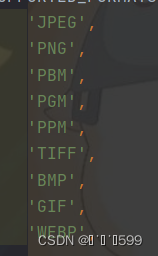
2.下载
传送门点击进入
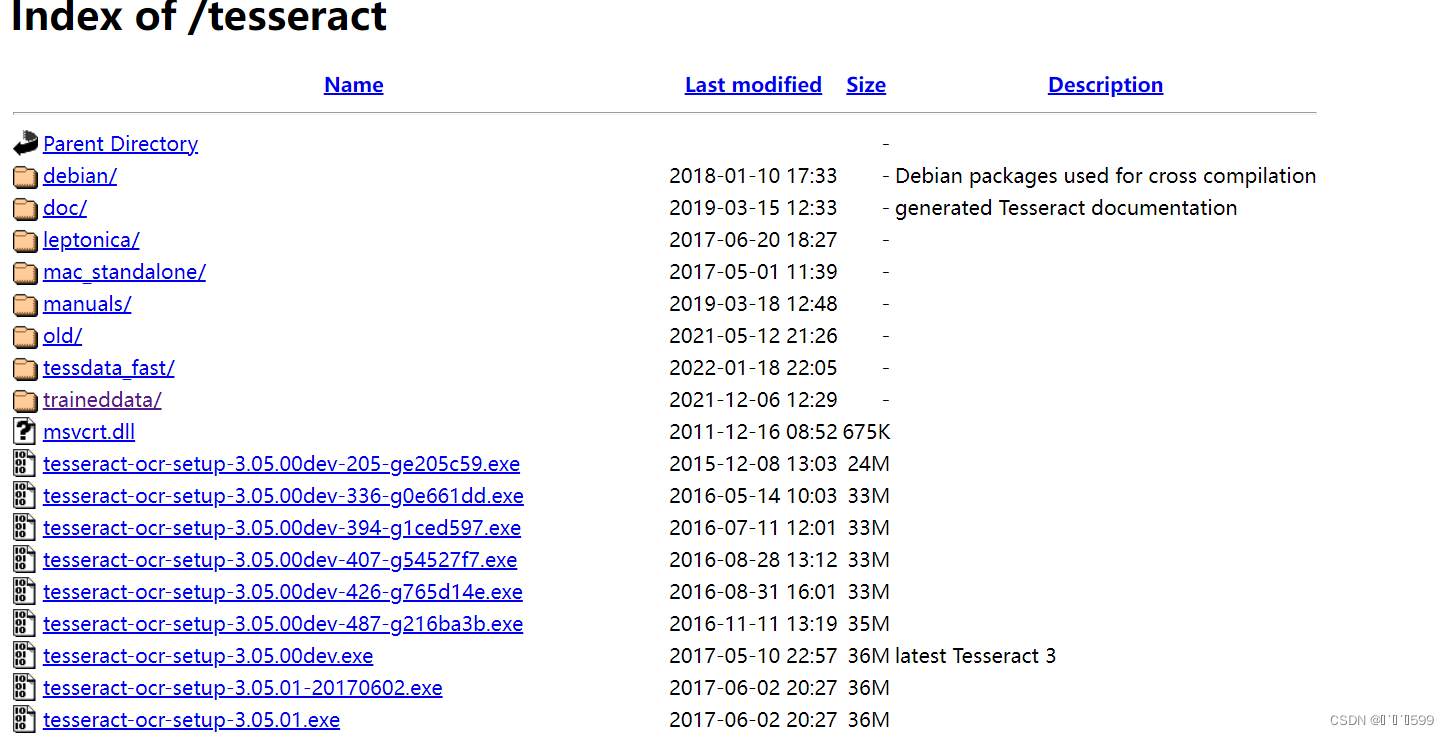
在这里面,往下翻找下图这种,已经完成的。

接着下载安装到想要安装的磁盘,我就默认安装到了c盘
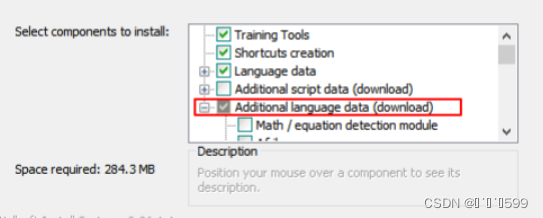
记得勾选想要的而语言
安装完后添加系统环境变量
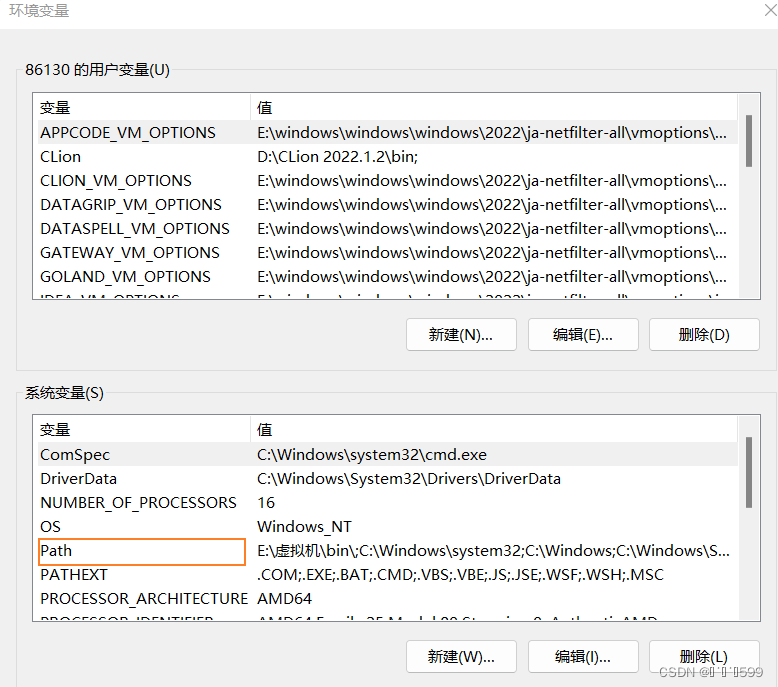
新创建一个如下图添加。

确认完后,接着按住win+r输入cmd回车,在里面输入
tesseract -v
出现版本号之类的为安装配置成功
tesseract --list-langs
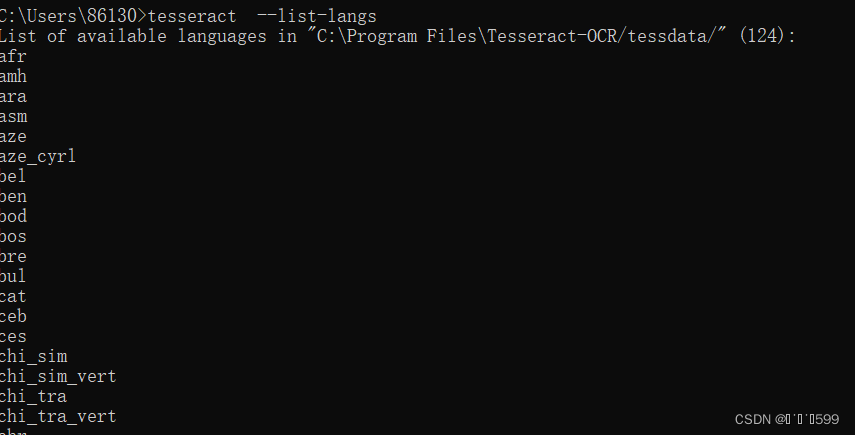
出现上图为语言
3.后续添加语言
传送门打开往下拉,选择下载,下载下来的文件放到最开始安装pytesseract-ocr的文件夹下的tessdata目录下,如图

4.下载相应的库
pip install pytesseract
pip install Pillow # 用于处理图像
二、使用步骤
import pytesseract
# pillow 安装的库名与导入的包名是不一样的
from PIL import Image
# 找自己的tesseract.exe放在哪个目录下
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
# 1 加载图片
image = Image.open('图片.png')
# 2. 识别图片上的文字
string = pytesseract.image_to_string(image,lang='chi_sim')
# 3. 打印识别的文字
print(string)
图片如下
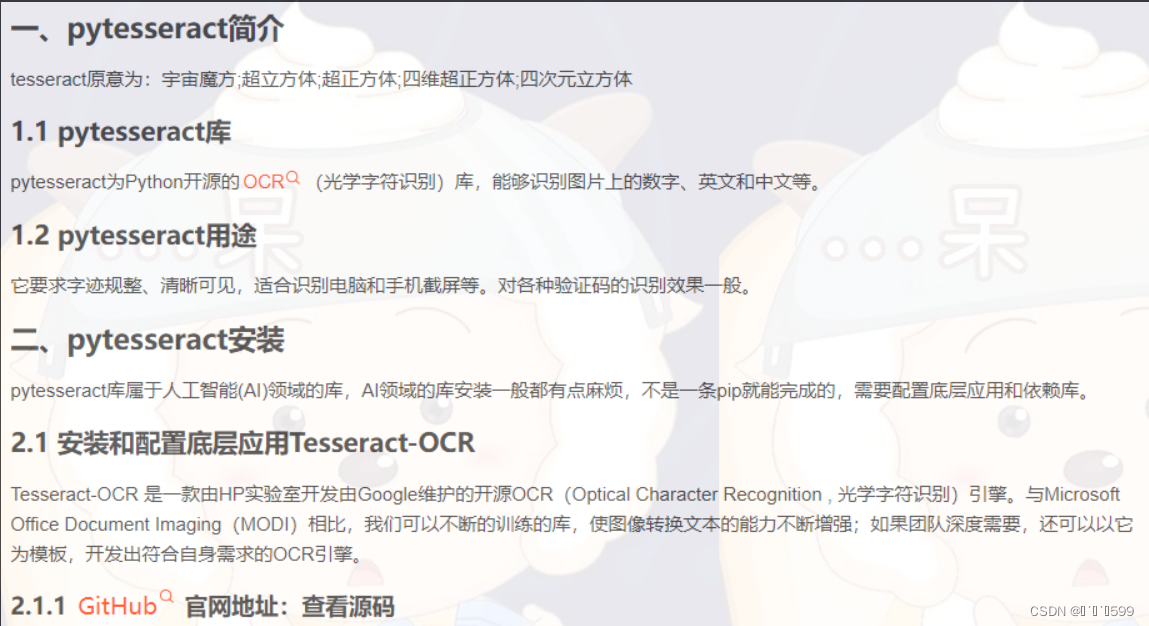
运行结果如下(有的识别不是很准确)
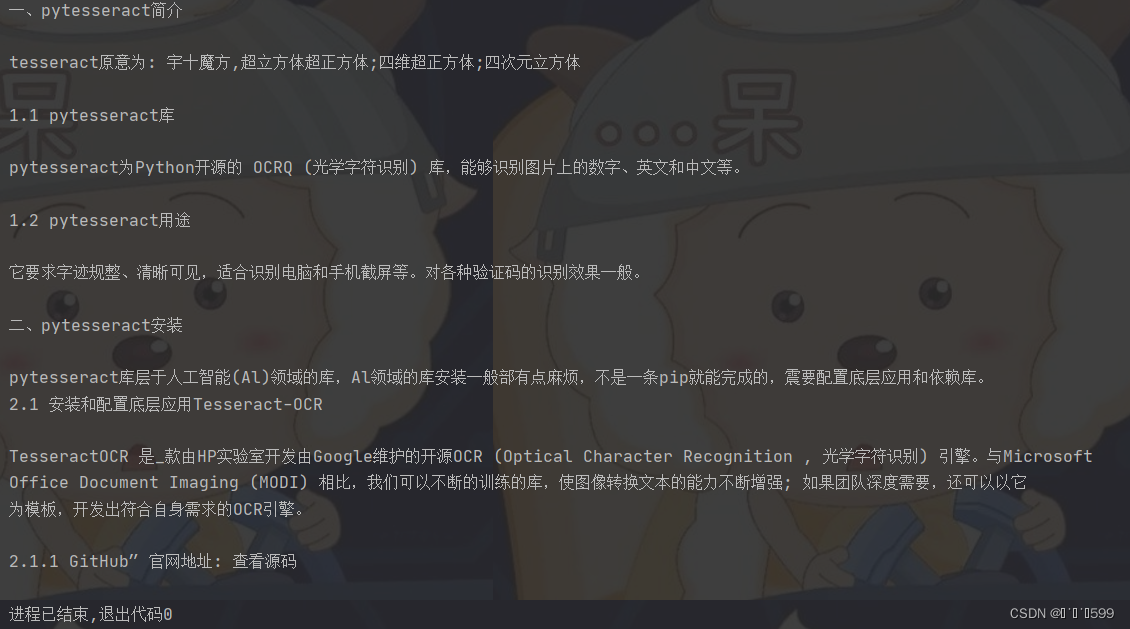
注: lang=’ ’ 根据图片的内容进行修改,本图片中文居多,所以用此,添加的内容在tessdata文件夹找,或查看目前所有语言进行使用
总结
首先要注意,此方法并不能很好的去识别一些图片,那秀娥图片可能需要经过图片的预处理然后使用,有关于py的问题,可以 点击传送门提问探讨。
















 3649
3649











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











