






接上篇
8、时间
8.1 datetime
datetime 模块提供了用于处理日期和时间的类。
from datetime import datetime dt = datetime(2024, 5, 19, 16, 45, 30) print(dt) print(dt.date()) # 输出: 2024-05-19 print(dt.time()) # 输出: 16:45:00
8.2 Timestamp
Timestamp 是一个特殊的 datetime 类型,用于表示单个时间点。它是 pandas 时间序列功能的核心组件,提供了丰富的方法和属性来处理日期和时间数据。
import pandas as pd
# 从日期字符串创建
ts = pd.Timestamp('2024-05-19 16:45:00')
print(ts)
# 从时间戳创建
ts = pd.Timestamp(1652937700) # Unix 时间戳
print(ts)
8.3 日期解析
pd.to_datetime() 方法用于将字符串或其他格式的日期转换为 Pandas 的 Datetime 对象。
案例:
import pandas as pd
# 将字符串转换为 Datetime 对象
date_str = '2023-10-01'
date_obj = pd.to_datetime(date_str)
print(date_obj)
# 获取当前时间
print('当前时间:')
print(datetime.now())
8.4 date_range
date_range() 函数用于生成一个固定频率的日期时间索引(DatetimeIndex)。这个函数非常灵活,可以用于生成各种时间序列数据。
语法:
pandas.date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False, name=None, closed=None, **kwargs)
参数:
-
start:
-
类型:字符串或日期时间对象,默认为 None。
-
描述:起始日期时间。
-
-
end:
-
类型:字符串或日期时间对象,默认为 None。
-
描述:结束日期时间。
-
-
periods:
-
类型:整数,默认为 None。
-
描述:生成的日期时间索引的数量。
-
-
freq:
-
类型:字符串或日期偏移对象,默认为 None。
-
描述:时间频率。常见的频率包括 'D'(天)、'H'(小时)、'T' 或 'min'(分钟)、'S'(秒)等。
-
-
tz:
-
类型:字符串或时区对象,默认为 None。
-
描述:指定时区。
-
-
normalize:
-
类型:布尔值,默认为 False。
-
描述:是否将时间归一化到午夜。
-
-
name:
-
类型:字符串,默认为 None。
-
描述:生成的日期时间索引的名称。
-
-
closed:
-
类型:字符串,默认为 None。
-
描述:指定区间是否包含起始或结束日期时间。可选值为 'left'、'right' 或 None。
-
案例:
import pandas as pd # 生成从 2023-01-01 到 2023-01-10 的每日日期时间索引 date_index = pd.date_range(start='2023-01-01', end='2023-01-10', freq='D') print(date_index) # 生成从 2023-01-01 00:00:00 到 2023-01-01 23:00:00 的每小时日期时间索引 date_index = pd.date_range(start='2023-01-01', periods=24, freq='H') print(date_index)
8.5 时间差
Timedelta 是一个用于表示时间间隔的对象。它可以表示两个时间点之间的差异,或者表示某个时间段的长度。Timedelta 对象可以用于时间序列分析、日期运算等场景。
创建 Timedelta
1.使用字符串表示
import pandas as pd
td1 = pd.Timedelta('1 days 2 hours 30 minutes')
print(td1) # 输出: 1 days 02:30:00
2.使用参数
td2 = pd.Timedelta(days=1, hours=2, minutes=30) print(td2) # 输出: 1 days 02:30:00
3.使用整数和单位
td3 = pd.Timedelta(5, unit='days') # 5天 print(td3) # 输出: 5 days 00:00:00
4.时间差加减
import pandas as pd
td1 = pd.Timedelta('1 days 2 hours 30 minutes')
print(td1) # 输出: 1 days 02:30:00
ts = pd.Timestamp('2024-01-01')
new_ts = ts + td1
print(new_ts) # 输出: 2024-01-02 02:30:00
8.6 时间日期格式化
strftime 用于将日期时间对象转换为指定格式的字符串,而 strptime 用于将字符串解析为日期时间对象。
from datetime import datetime
# 创建一个日期时间对象
date_obj = datetime(2023, 10, 1, 14, 30, 45)
# 将日期时间对象转换为字符串
date_str = date_obj.strftime("%Y-%m-%d %H:%M:%S")
print(f"Formatted date string: {date_str}")
# 将字符串解析为日期时间对象
parsed_date_obj = datetime.strptime(date_str, "%Y-%m-%d %H:%M:%S")
print(f"Parsed datetime object: {parsed_date_obj}")
时间日期符号: 符号 说明 %y 两位数的年份表示(00-99) %Y 四位数的年份表示(0000-9999) %m 月份(01-12) %d 月内中的一天(0-31) %H 24小时制小时数(0-23) %I 12小时制小时数(01-12) %M 分钟数(00=59) %S 秒(00-59) %a 本地英文缩写星期名称 %A 本地英文完整星期名称 %b 本地缩写英文的月份名称 %B 本地完整英文的月份名称 %w 星期(0-6),星期天为星期的开始 %W 一年中的星期数(00-53)星期一为星期的开始 %x 本地相应的日期表示 %X 本地相应的时间表示 %Z 当前时区的名称 %U 一年中的星期数(00-53)星期天为星期的开始 %j 年内的一天(001-366) %c 本地相应的日期表示和时间表示
9、随机抽样
语法:
DataFrame.sample(n=None, frac=None, replace=False, weights=None, random_state=None, axis=None)
参数:
-
n:要抽取的行数
-
frac:抽取的比例,比如 frac=0.5,代表抽取总体数据的50%
-
replace:布尔值参数,表示是否以有放回抽样的方式进行选择,默认为 False,取出数据后不再放回
-
weights:可选参数,代表每个样本的权重值,参数值是字符串或者数组
-
random_state:可选参数,控制随机状态,默认为 None,表示随机数据不会重复;若为 1 表示会取得重复数据
-
axis:示在哪个方向上抽取数据(axis=1 表示列/axis=0 表示行)
案例:
import pandas as pd
def sample_test():
df = pd.DataFrame({
"company": ['百度', '阿里', '腾讯'],
"salary": [43000, 24000, 40000],
"age": [25, 35, 49]
})
print('随机选择两行:')
print(df.sample(n=2, axis=0))
print('随机选择一列:')
print(df.sample(n=1, axis=1))
print('总体的50%:')
print(df.sample(axis=0, frac=0.5))
10、空值处理
10.1 检测空值
isnull()用于检测 DataFrame 或 Series 中的空值,返回一个布尔值的 DataFrame 或 Series。
notnull()用于检测 DataFrame 或 Series 中的非空值,返回一个布尔值的 DataFrame 或 Series。
案例:
import pandas as pd
import numpy as np
# 创建一个包含空值的示例 DataFrame
data = {
'A': [1, 2, np.nan, 4],
'B': [5, np.nan, np.nan, 8],
'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data)
# 检测空值
is_null = df.isnull()
print(is_null)
# 检测非空值
not_null = df.notnull()
print(not_null)
10.2 填充空值
fillna() 方法用于填充 DataFrame 或 Series 中的空值。
案例:
# 创建一个包含空值的示例 DataFrame
data = {
'A': [1, 2, np.nan, 4],
'B': [5, np.nan, np.nan, 8],
'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data)
# 用 0 填充空值
df_filled = df.fillna(0)
print(df_filled)
10.3 删除空值
dropna() 方法用于删除 DataFrame 或 Series 中的空值。
案例:
# 创建一个包含空值的示例 DataFrame
data = {
'A': [1, 2, np.nan, 4],
'B': [5, np.nan, np.nan, 8],
'C': [9, 10, 11, 12]
}
df = pd.DataFrame(data)
# 删除包含空值的行
df_dropped = df.dropna()
print(df_dropped)
# 删除包含空值的列
df_dropped = df.dropna(axis=1)
print(df_dropped)
三、读取CSV文件
CSV(Comma-Separated Values,逗号分隔值,有时也称为字符分隔值,因为分隔字符也可以不是逗号),其文件以纯文本形式存储表格数据(数字和文本);
CSV 是一种通用的、相对简单的文件格式,被用户、商业和科学广泛应用。
1、to_csv()
to_csv() 方法将 DataFrame 存储为 csv 文件
案例:
import pandas as pd
# 创建一个简单的 DataFrame
data = {
'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35],
'City': ['New York', 'Los Angeles', 'Chicago']
}
df = pd.DataFrame(data)
# 将 DataFrame 导出为 CSV 文件
df.to_csv('output.csv', index=False)2、read_csv()
read_csv() 表示从 CSV 文件中读取数据,并创建 DataFrame 对象。
案例:
import pandas as pd
df = pd.read_csv('output.csv')
print(df)
四、绘图
Pandas 在数据分析、数据可视化方面有着较为广泛的应用,Pandas 对 Matplotlib 绘图软件包的基础上单独封装了一个plot()接口,通过调用该接口可以实现常用的绘图操作;
Pandas 之所以能够实现了数据可视化,主要利用了 Matplotlib 库的 plot() 方法,它对 plot() 方法做了简单的封装,因此您可以直接调用该接口;
只用 pandas 绘制图片可能可以编译,但是不会显示图片,需要使用 matplotlib 库,调用 show() 方法显示图形。
import pandas as pd
import matplotlib.pyplot as plt
# 创建一个示例 DataFrame
data = {
'A': [1, 2, 3, 4, 5],
'B': [10, 20, 25, 30, 40]
}
df = pd.DataFrame(data)
# 绘制折线图
df.plot(kind='line')
# 显示图表
plt.show()
# 绘制柱状图
df.plot(kind='bar')
# 显示图表
plt.show()
# 绘制直方图
df['A'].plot(kind='hist')
# 显示图表
plt.show()
# 绘制散点图
df.plot(kind='scatter', x='A', y='B')
# 显示图表
plt.show()饼图
# 创建一个示例 Series
data = {
'A': 10,
'B': 20,
'C': 30,
'D': 40
}
series = pd.Series(data)
# 绘制饼图
series.plot(kind='pie', autopct='%1.1f%%')
# 显示图表
plt.show()1.概念
数据结构是计算机科学中的一个核心概念,它是指数据的组织、管理和存储方式,以及数据元素之间的关系。数据结构通常用于允许高效的数据插入、删除和搜索操作。
数据结构大致分为几大类:
线性结构:数组、链表、栈、队列等。
非线性结构:树、二叉树、堆、图等。
散列:哈希表。
索引:B树、B+树等。
2.常见数据结构
2.1 栈
栈(stack),它是一种运算受限的线性表,遵循后进先出(Last In First Out,LIFO)原则的数据结构。
-
LIFO(last in first out)表示就是后进入的元素, 第一个弹出栈空间. 类似于自动餐托盘, 最后放上的托盘, 往往先把拿出去使用.
-
其限制是仅允许在表的一端进行插入和删除运算。这一端被称为栈顶,相对地,把另一端称为栈底。
-
向一个栈插入新元素又称作进栈、入栈或压栈,它是把新元素放到栈顶元素的上面,使之成为新的栈顶元素;
-
从一个栈删除元素又称作出栈或退栈,它是把栈顶元素删除掉,使其相邻的元素成为新的栈顶元素。
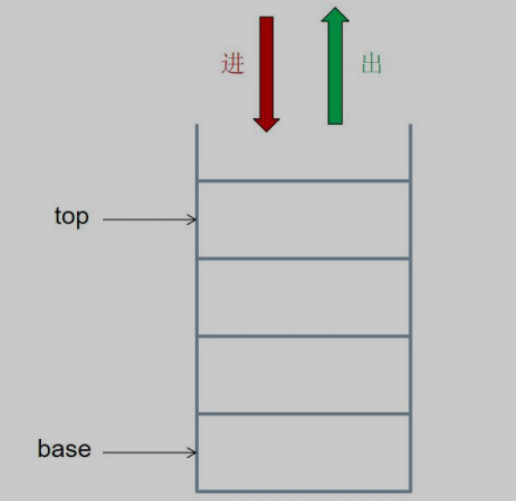
栈常见的操作
-
push(element): 添加一个新元素到栈顶位置.
-
pop():移除栈顶的元素,同时返回被移除的元素。
-
peek():返回栈顶的元素,不对栈做任何修改(这个方法不会移除栈顶的元素,仅仅返回它)。
-
isEmpty():如果栈里没有任何元素就返回true,否则返回false。
-
clear():移除栈里的所有元素。
-
size():返回栈里的元素个数。这个方法和数组的length属性很类似。
2.1.1 入栈
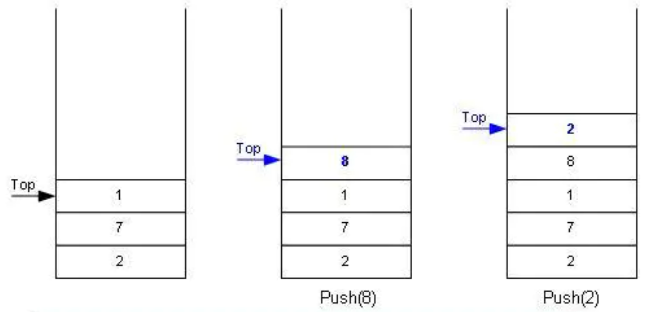
2.1.2 出栈
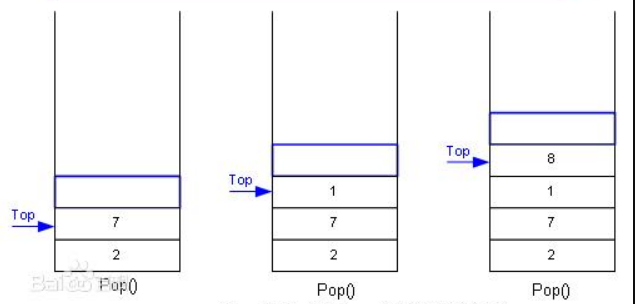
2.1.3 代码分析
-
使用数组来模拟栈
-
定义一个 空数组
-
入栈的操作,当有数据加入到栈时,判断数组长度是否达到阈值,是则抛栈已满的异常,否则将数据追加到数组的尾部;
-
出栈的操作,判断栈是否空,是则抛栈已空的异常,否则从数组尾部移除一个数据,并返回该数据;
代码实现:
class Stack:
def __init__(self, size):
self.items = []
self.size = size
def isFull(self):
return len(self.items) == self.size
def push(self, element):
if self.isFull():
raise Exception('stack is full')
self.items.append(element)
def pop(self):
if self.isEmpty():
raise Exception('stack is empty')
return self.items.pop()
def peek(self):
if self.isEmpty():
raise Exception('stack is empty')
return self.items[-1]
def isEmpty(self):
return len(self.items) == 0
def clear(self):
self.items.clear()
if __name__ == '__main__':
stack = Stack(20)
stack.push(1)
stack.push(2)
print(stack.peek())
2.2 链表
链表是一条相互链接的数据节点表。每个节点由两部分组成:数据和指向下一个节点的指针。
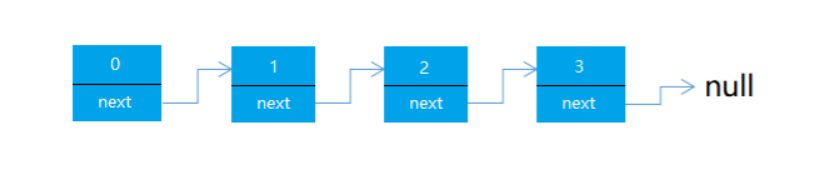
2.1 链表的优缺点
优点:
-
物理存储单元上非连续,而且采用动态内存分配,能够有效的分配和利用内存资源;
-
节点删除和插入简单,不需要内存空间的重组。
缺点:
-
不能进行索引访问,只能从头结点开始顺序查找;
-
数据结构较为复杂,需要大量的指针操作,容易出错。
2.2 单向链表
2.2.1 插入
尾部插入
从头结点开始逐个遍历链表,直到找到next=null,表示为最后一个节点,再将最后节点的next指向新增节点。
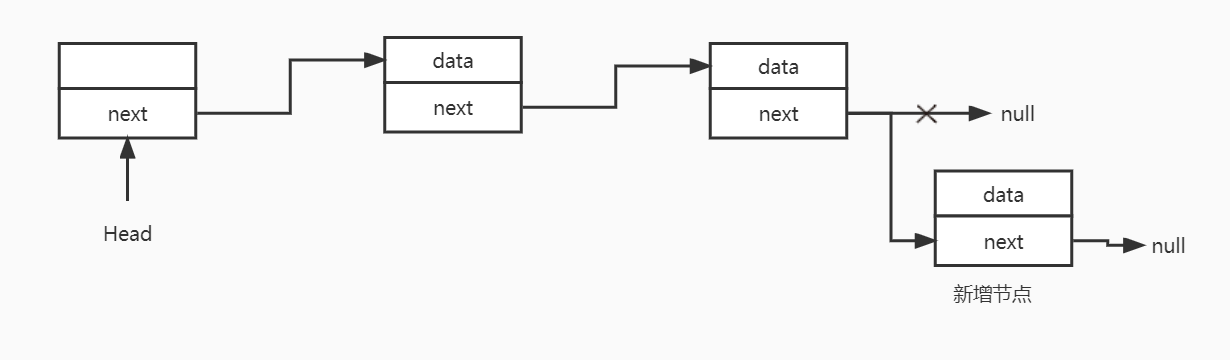
头部插入
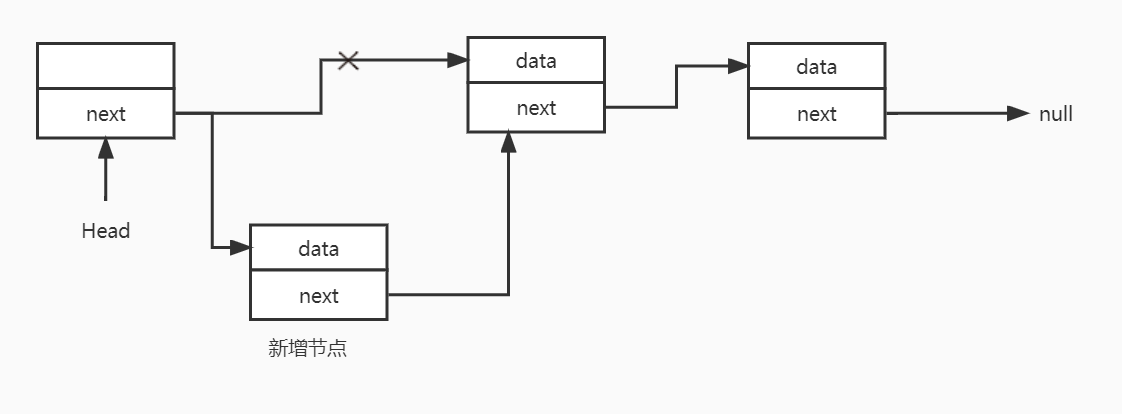
如果头节点的next=null表示链表为空,直接将头节点的next指向新增节点
如果头节点的next!=null,表示头节点后已存在后续节点,需要将新增节点插入到头节点和后续节点中间:
1.获取头节点的后续节点,定义一个临时节点,将该节点指向临时节点
2.将头节点的next指向新增节点
3.新增节点的next指向临时节点
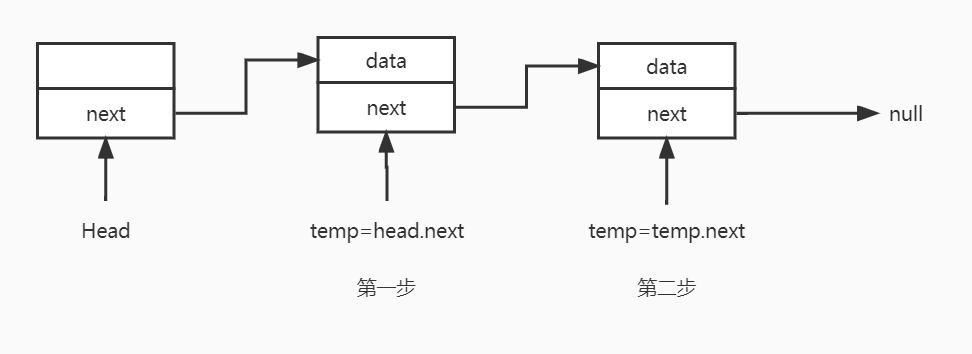
2.2.2 遍历
从头结点开始,通过next遍历,直到next=null
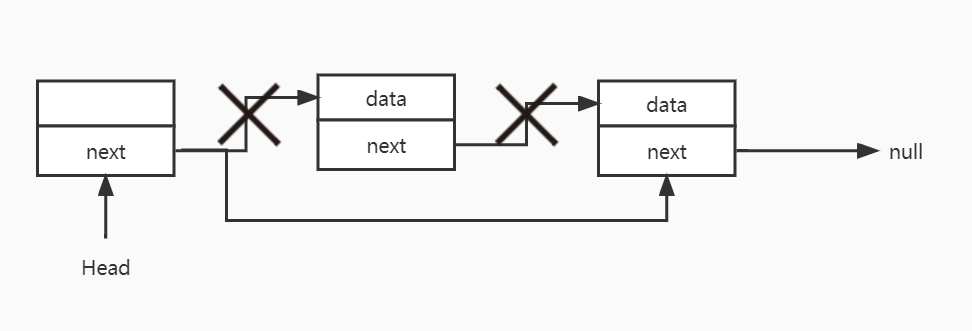
2.2.3 删除
2.2.4 代码实现
class Node:
def __init__(self, data=None):
if data is not None:
self.data = data
self.next = None
class LinkedList:
def __init__(self):
head = Node()
self.head = head
def append(self, data):
new_node = Node(data)
# 如果链表为空,则在头部后插入
if self.head.next is None:
self.head.next = new_node
else:
node = self.head.next
while node.next is not None:
node = node.next
node.next = new_node
def prepend(self, data):
new_node = Node(data)
if self.head.next is None:
self.head.next = new_node
else:
new_node.next = self.head.next
self.head.next = new_node
def remove(self, data):
if self.head.next is None:
raise Exception('Linked List is empty')
node = self.head
while node.next.data != data:
node = node.next
node.next = node.next.next
def display(self):
node = self.head.next
while True:
print(node.data)
if node.next is None:
break
node = node.next
if __name__ == '__main__':
list = LinkedList()
list.append(1)
list.append(2)
list.prepend(3)
list.display()

















 618
618

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









