







一、爬取目标
牛客网面试经验
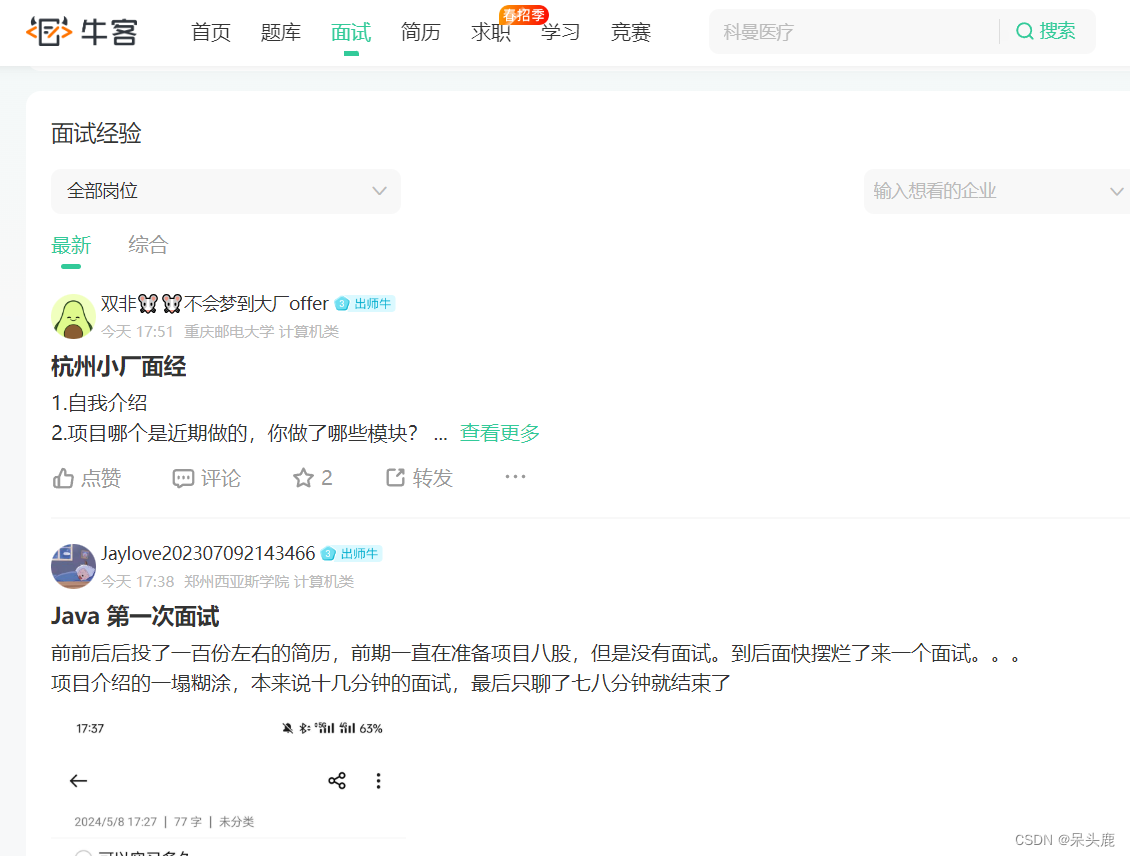
包括面试经验的标题,内容,URL等,保存在csv文件中。
二、网页分析
观察面试经验网页的URL,发现主要有两类
一种是feed/main/detail。

标题和内容分别在这两个节点下,可以使用xpath解析

一种是discuss
![]()
这种标题和内容分别在这两个节点下,也可以使用xpath解析
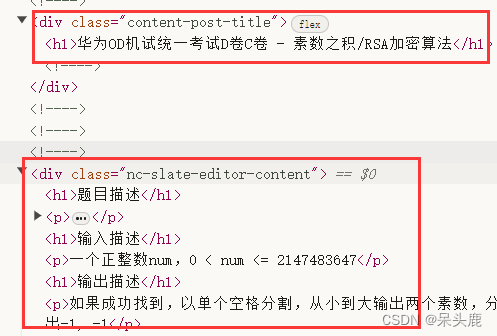
由于这两种网页的结构不同,我分别写了两个函数爬取
三、代码实现
由于网页使用Ajax动态加载,在没有鼠标滚动的情况下是没有数据的,所以我使用了python的selenium库,模拟鼠标滚轮,使页面内容全部加载出来:
def getIndexPage():
driver = webdriver.Chrome()
# 这个是牛客网java实习面经的界面,可以根据自己的需要,找好网页,然后将连接复制到这里来
driver.get("https://www.nowcoder.com/discuss/experience?tagId=639&order=3&companyId=0&phaseId=1")
time.sleep(3)
js = "return action=document.body.scrollHeight"
height = driver.execute_script(js)
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
time.sleep(5)
t1 = int(time.time())
num = 0
# 将滚动条拉到最下面,直到所有内容都加载出来
while True:
t2 = int(time.time())
if t2 - t1 < 30:
new_height = driver.execute_script(js)
if new_height > height:
time.sleep(1)
driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
height = new_height
t1 = int(time.time())
elif num < 3:
time.sleep(3)
num = num + 1
else:
print("滚动条已经处于页面最下方!")
driver.execute_script('window.scrollTo(0, 0)')
break
content = driver.page_source
# 将内容保存到本地文件
with open('index_page.html', 'w', encoding='utf-8') as file:
file.write(content)
return content上面的函数返回了一个包含所有URL链接的页面,然后就需要从中获取数据的URL:
def scrape_url_list():
html = etree.parse("index_page.html", etree.HTMLParser())
hrefs = html.xpath('//a[@data-v-d89ade80]')
url_list = []
for a in hrefs:
href = a.get('href')
url_list.append(BASE_URL + href)
return url_list最后写两个页面解析函数,从页面中提取我们需要的数据并返回:
def parse_detail(response):
html = etree.HTML(response)
title = html.xpath('//div[@class="tw-flex" and @data-v-009b564e]/h1//text()')
content = html.xpath("//div[contains(@class, 'feed-content-text')]/text()")
return {"title": title, "content": content}
def parse_discussion(response):
html = etree.HTML(response)
title = html.xpath('//div[@class="content-post-title"]/h1//text()')
content_list = html.xpath("//div[@class='nc-slate-editor-content']//p//text()")
content_str = "\n".join(content_list)
return {"title": title, "content": content_str}在main函数中运行
if __name__ == '__main__':
# index_page = getIndexPage()
urls = scrape_url_list()
data = pd.DataFrame(columns=['title', 'content', 'url'])
parsed_res = {"title": None, "content": None, 'url': None}
for url in urls:
text = scrape_page(url)
if url.startswith("https://www.nowcoder.com/feed/main/detail"):
parsed_res = parse_detail(text)
elif url.startswith("https://www.nowcoder.com/discuss"):
parsed_res = parse_discussion(text)
parsed_res["url"] = url
data = data.append(parsed_res, ignore_index=True)
data.to_csv("java面经.csv")四、成果展示
最后爬取到的数据展示如下:
















 4900
4900

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









