







本文对上次的爬虫框架进行了改进,原本是直接使用Python的Request库发送请求进行爬取,这里使用了Scrapy框架,提高了爬取效率,简化了爬取流程。
分析网页
牛客招聘数据:
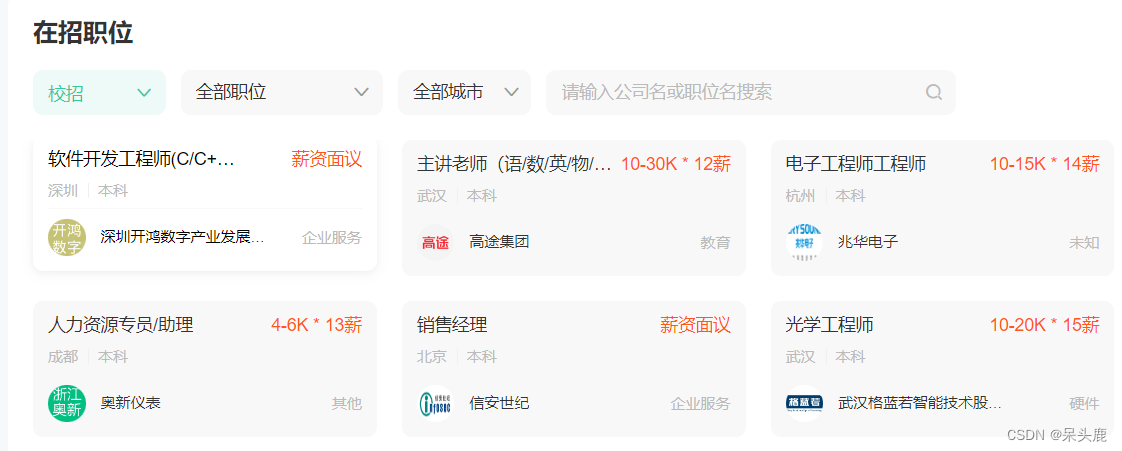
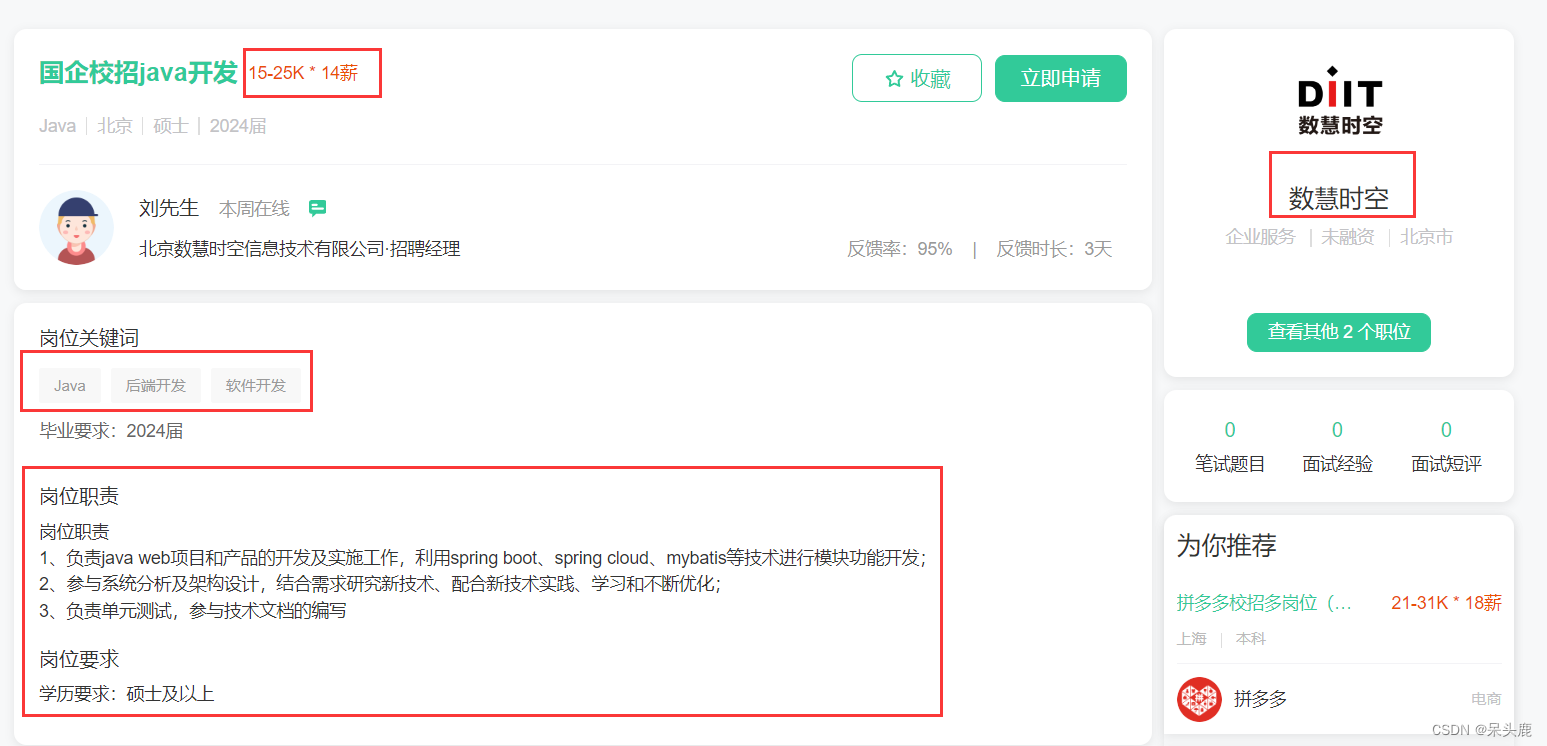
详情页:
Scrapy框架
项目结构如下:
首先在items.py中新建类,用于存放爬到的数据,用于管道输出,包括公司名,工资,城市,教育要求,工作,详细要求等字段。
class EmployItem(scrapy.Item):
company = scrapy.Field()
salary = scrapy.Field()
city = scrapy.Field()
education = scrapy.Field()
job = scrapy.Field()
details = scrapy.Field()在spiders目录下新建一个newCoderSpider.py,用于发送请求和解析返回的HTML网页。start_urls是开始请求的URL,返回的数据会在parse()方法中解析。
class ExperienceSpider(scrapy.Spider):
name = "espider"
allowed_domains = ["nowcoder.com"]
start_urls =
["https://www.nowcoder.com/feed/main/detail/3364c82e4c3b4eac9dfca2ee92100b06"]
def parse(self, response):
item = EmployItem()
item["company"] = response.xpath("//div[@class='company-card card-container']/div//text()").extract()[0]
salary = response.xpath("//div[@class='salary']//text()").extract()[0]
if salary == '薪资面议' or salary is None:
item["salary"] = None
else:
strs = salary.strip().strip("薪").split('*')
months = int(strs[1])
s_min, s_max = strs[0].strip().strip("K").split("-")
item["salary"] = months * 0.5 * (int(s_min) + int(s_max)) * 1000
infos = response.xpath("//div[@class='extra flex-row']")
item["city"] = infos.xpath("//span[@class='el-tooltip']//text()").extract()[0]
item["education"] = infos.xpath("//span[@class='edu-level']//text()").extract()[0]
item["job"] = response.meta["category"]
item["details"] = '\n'.join(response.xpath("//div[@class='job-detail-infos tw-flex-auto']//text()").extract())
yield item原本使用scrapy框架是要在Terminal输入指令的,为了使用更方便,还能直接在PyCharm上进行调试,我们在爬虫项目的根目录下新建应该run.py:
from scrapy import cmdline
name = 'espider'
cmd = 'scrapy crawl {0}'.format(name)
cmdline.execute(cmd.split())
直接启动run.py就可以启动爬虫项目。
反爬机制
牛客有几个反爬的机制:
直接用默认的Scrapy爬取牛客网的页面会出现滑块验证,导致无法正常爬取数据:
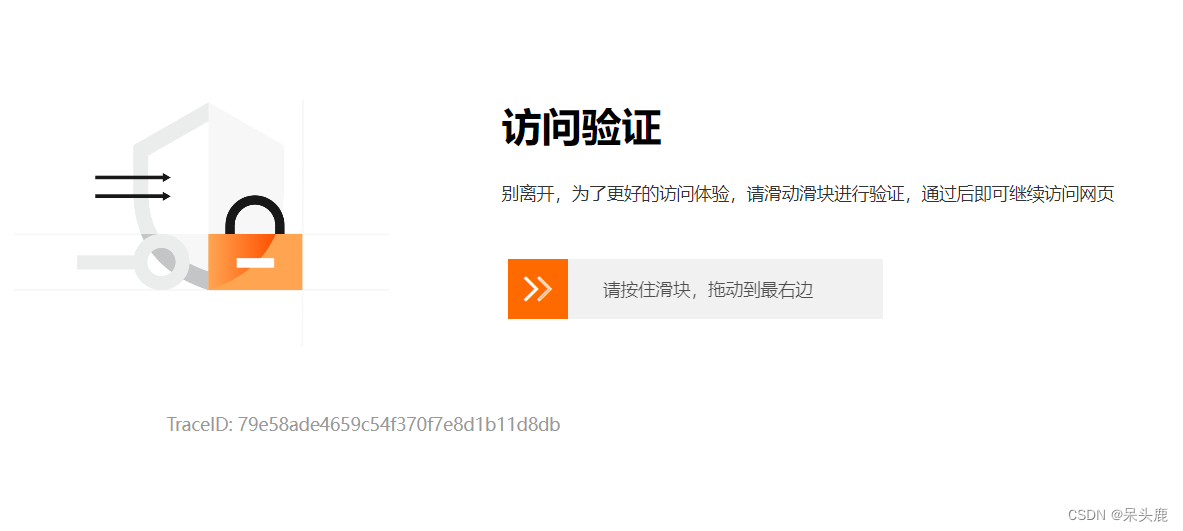
我认为问题出在了User-Agent上,人为设置User-Agent,防止被识别为爬虫。
在settings.py中启用DOWNLOADER_MIDDLEWARES:
DOWNLOADER_MIDDLEWARES = {
'newcodeSpider.middlewares.MyUserAgentMiddleware': 543,
}在middle.py中添加对Request预处理的设置,每次随机选择一个请求头:
class MyUserAgentMiddleware(UserAgentMiddleware):
def __init__(self, user_agent=''):
self.user_agent = user_agent
def process_request(self, request, spider):
ua = UserAgent()
request.headers['User-Agent'] = ua.random用这个方法果然可以骗过网站,但是出现了另外一个问题:
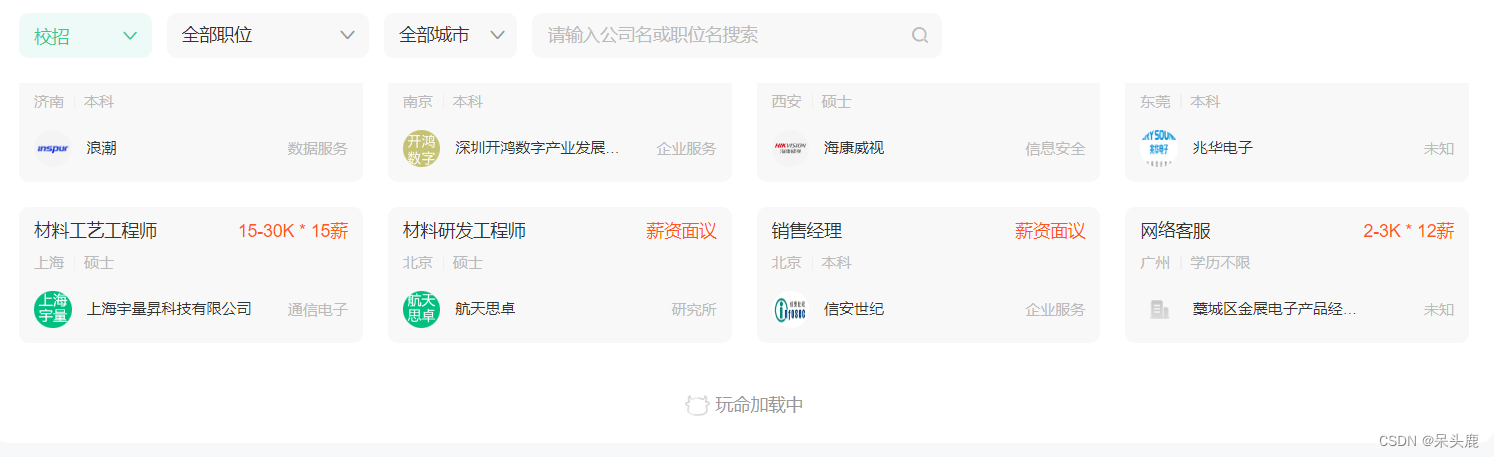
用鼠标拖动到最底下,发现牛客是动态加载的,同时这里还有选择按钮,点击之后也是动态加载:
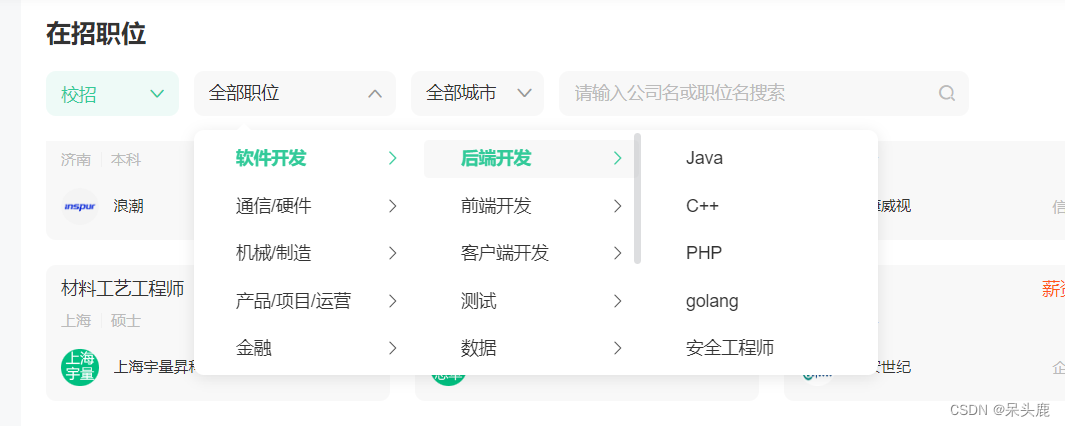
这个我用selenium解决:
完整的newCoderSpider.py代码:
import logging
import scrapy
from selenium.webdriver.common.by import By
from webSpider.items import EmployItem
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver import Keys
import time
from lxml import etree
from selenium.webdriver.support.ui import Select
class ExperienceSpider(scrapy.Spider):
name = "espider"
allowed_domains = ["nowcoder.com"]
# start_urls = ["https://www.nowcoder.com/feed/main/detail/3364c82e4c3b4eac9dfca2ee92100b06"]
def __init__(self):
"""
包含链接的页面是用Ajax动态渲染的,先使用selenium模拟浏览器爬取
"""
super(ExperienceSpider, self).__init__()
self.urls = {}
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
# driver = webdriver.Chrome(options=chrome_options)
driver = webdriver.Chrome()
driver.get("https://www.nowcoder.com/jobs/recommend/campus")
# 点击全部职位
driver.find_element(By.XPATH, "//div[@data-v-3683ca40]").click()
# element = driver.find_element(By.XPATH, "//div[@data-v-3683ca40]")
# driver.execute_script("arguments[0].click();", element)
time.sleep(1)
logging.info("Clicked All Jobs")
# 选择一级职位
category_elements = driver.find_elements(By.XPATH,
"//div[@class='el-scrollbar nowcoder-custom el-cascader-menu'][1]//li")
category = {c.text: c for c in category_elements if c.text != ""}
logging.info("Find job categories: " + category.keys().__str__())
# 循环点击一级职位
# for k, v in category.items():
for k, v in {"软件开发": category["软件开发"]}.items():
v.click()
# driver.execute_script("arguments[0].click();", v)
time.sleep(1)
logging.info("Clicked button " + k)
# 选择二级职位
sub_category_elements = driver.find_elements(By.XPATH,
"//div[@class='el-scrollbar nowcoder-custom el-cascader-menu'][2]//li")
sub_category = {c.text: c for c in sub_category_elements if c.text != ""}
logging.info("Find sub_categories: " + sub_category.keys().__str__())
# 点击二级职位
# for s_k, s_v in sub_category.items():
for s_k, s_v in {"后端开发": sub_category["后端开发"]}.items():
s_v.click()
# driver.execute_script("arguments[0].click();", s_v)
time.sleep(1)
logging.info("Clicked button " + s_k)
# 选择三级职位
sub_sub_category_elements = driver.find_elements(By.XPATH,
"//div[@class='el-scrollbar nowcoder-custom el-cascader-menu'][3]//span[@class='el-cascader-node__label']")
sub_sub_category = {c.text: c for c in sub_sub_category_elements if c.text != ""}
logging.info("Find sub_sub_categories: " + sub_sub_category.keys().__str__())
# 点击三级职位
for ss_k, ss_v in sub_sub_category.items():
ss_v.click()
# driver.execute_script("arguments[0].click();", ss_v)
time.sleep(2)
logging.info("Clicked button " + ss_k)
# 将滚动条滑动到页面底部
while True:
# 模拟滑动操作
actions = ActionChains(driver)
actions.send_keys(Keys.END).perform()
# 等待页面加载
time.sleep(3)
# 检查是否已到达页面底部
if driver.execute_script(
"return window.pageYOffset + window.innerHeight >= document.body.scrollHeight"):
break
# 获取页面的源代码
content = driver.page_source
html = etree.HTML(content, parser=etree.HTMLParser())
self.urls[k + '-' + s_k + '-' + ss_k] = html.xpath(
'//a[@class="recruitment-job-card feed-job-card"]/@href')
driver.find_element(By.XPATH, "//div[@data-v-3683ca40]").click()
# element = driver.find_element(By.XPATH, "//div[@data-v-3683ca40]")
# driver.execute_script("arguments[0].click();", element)
time.sleep(1)
with open("urls.txt", "w", encoding='utf-8') as f:
f.write(self.urls.__str__())
driver.close()
def start_requests(self):
for category, urls in self.urls.items():
for url in urls:
yield scrapy.Request(url=url, callback=self.parse, meta={"category": category}, dont_filter=True)
def parse(self, response):
item = EmployItem()
item["company"] = response.xpath("//div[@class='company-card card-container']/div//text()").extract()[0]
salary = response.xpath("//div[@class='salary']//text()").extract()[0]
if salary == '薪资面议' or salary is None:
item["salary"] = None
else:
strs = salary.strip().strip("薪").split('*')
months = int(strs[1])
s_min, s_max = strs[0].strip().strip("K").split("-")
item["salary"] = months * 0.5 * (int(s_min) + int(s_max)) * 1000
infos = response.xpath("//div[@class='extra flex-row']")
item["city"] = infos.xpath("//span[@class='el-tooltip']//text()").extract()[0]
item["education"] = infos.xpath("//span[@class='edu-level']//text()").extract()[0]
item["job"] = response.meta["category"]
item["details"] = '\n'.join(response.xpath("//div[@class='job-detail-infos tw-flex-auto']//text()").extract())
yield item
定义了__init__()方法,首先用selenium定位按钮元素,模拟鼠标点击,加载对应类别的页面,然后模拟鼠标滚轮一直滚到页面最下方,直到所有的数据都加载出来,就返回这个页面,一个一个把所有的类别都爬取下来,从中抽取详细页面的URL,写入文件中备用。
接着把所有的URL传给start_requests()方法,这个方法代替了最初的start_urls,所有的请求都是从这里了发出的,发出请求,收到返回数据后会调用parse()方法,解析页面内容,并输入管道,我们这里把管道中的数据保存到csv文件中。
在pipelines.py中新建一个类用于保存数据:
class CsvPipeline(object):
def __init__(self):
self.file = codecs.open('data.csv', 'w', encoding='utf_8_sig')
def process_item(self, item, spider):
fieldnames = ['company', 'salary', 'city', 'education', 'job', 'details']
w = csv.DictWriter(self.file, fieldnames=fieldnames)
w.writerow(item)
return item
def close_spider(self, spider):
self.file.close()
这样我们的全部工作就完成了,运行run.py就可以开始爬取。
爬取结果
爬取结果如下:
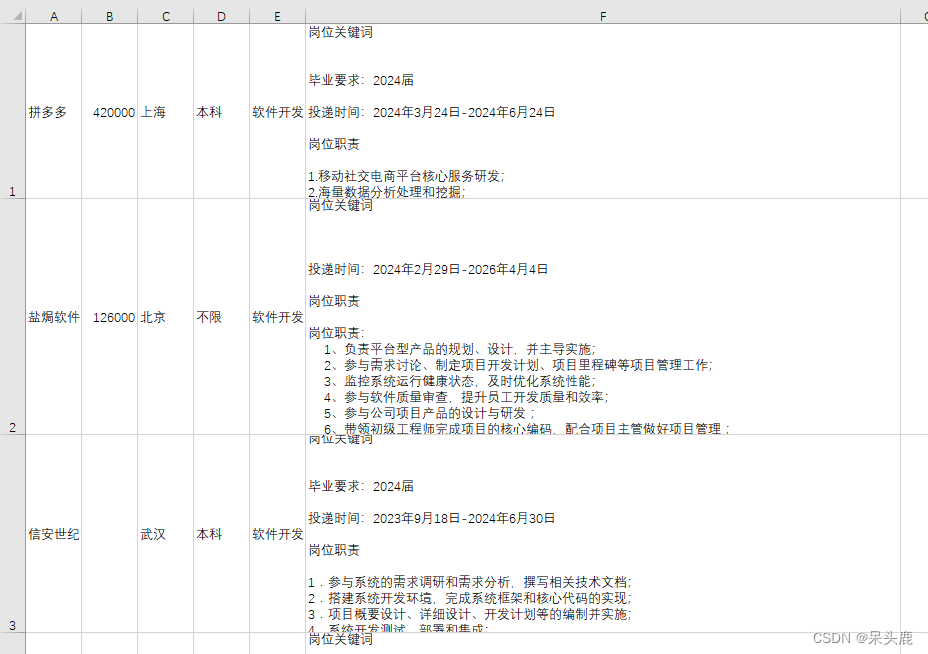















 1060
1060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









